
Abstract
Longitudinal zero-inflated count data frequently arise in various fields such as medicine and social sciences. Standard hurdle models separate zero and positive counts, but fail to directly infer marginal means, limiting their ability to assess overall covariate effects. This paper introduces overall marginalized hurdle random effects models (OMHREMs) for zero-inflated count data, which extends the traditional hurdle model by directly modeling the marginal mean while considering random effects to account for heterogeneity. OMHREMs enable population-average effects of covariates like odds ratio, providing how covariates influence the overall mean in zero-inflated count data. Through simulation studies, we evaluate the performance of OMHREMs. Furthermore, we apply our approach to systemic lupus erythematosus data to compare its effectiveness against existing models.
Introduction
In fields of medical and social sciences, it is common to encounter zero-inflated count data, which often signify infrequent occurrences such as lottery wins or specific disease diagnoses. A widely adopted method for analyzing this type of data is the zero-inflated Poisson (ZIP) model. 1 A key challenge with the ZIP model is that its parameters related to zero inflation can be difficult to interpret intuitively because zero outcomes can arise from either a binary decision or a count process, reflecting its mixed distribution structure. Moreover, the ZIP model faces significant limitations when data display zero deflation (fewer zeros than expected), as its binary component's parameter may diverge to infinity,2,3 causing estimation problems.
In contrast, the hurdle model 4 provides a more adaptable and stable framework. It addresses count data by distinctly partitioning it into two components: a binary model that differentiates between zero and nonzero observations, and a separate truncated count model that describes only the positive outcomes. This design allows the hurdle model to effectively manage both zero-inflated and zero-deflated data, making it a more dependable choice for analysis. While many discussions on choosing between hurdle and ZIP models focus on model fit statistics, some researchers, including Gilthorpe et al. 5 and supported by Neelon et al. 6 and Buu et al., 7 suggest that an understanding of the underlying data-generating mechanism should inform this decision. For example, applications where all zeros are understood to stem from a single process point towards the use of a hurdle model, rather than a ZIP model, which posits that zeros can originate from two different processes.
Analyzing longitudinal zero-inflated count data presents unique challenges, especially when interpreting the conditional mean with models like the hurdle model, where parameters often relate to distinct subpopulations. Several methods have been proposed to address this. Min and Agresti 2 introduced a two-part random effects model, referred to in this paper as the hurdle random effects model (HREM), which features a binary component for zero occurrences as a truncated count model for positive values. Neelon et al. 6 presented a Bayesian strategy for analyzing such data. Recognizing that the Poisson distribution assumes equidispersion, which limits the zero-inflated hurdle model's ability to compute the mean-variance relationship, Zhu et al. 8 extended these models by including heterogeneous random effects. This extension allows the variance to be modeled as a function of covariates in longitudinal data. Additionally, Kang et al. 9 extended the Poisson hurdle model to a longitudinal Bayesian mixed effects hurdle Conway–Maxwell–Poisson (CMP) model, utilizing a Bayesian generalized linear mixed model approach.
In the analysis of longitudinal zero-inflated data, marginal model approaches are preferred when the primary interest lies in the marginal probability of the zero component and the marginal mean of the count component. Hall and Zhang 10 developed a marginal modeling approach combining generalized estimating equations (GEEs) with the expectation–maximization (EM) algorithm to account for data correlation without requiring additional model assumptions.
However, their GEE framework has notable limitations: it does not allow for separate regression parameters for the zero-inflated and positive count components, and it is inapplicable under the missing at random (MAR) assumption. To overcome these constraints, Lee et al. 11 proposed a marginalized HREM (MHREM) and marginalized negative binomial (NB) hurdle model for clustered data. While these models specify the marginal relationship between responses and covariates using random effects to explain clustered dependence, a key limitation remains: the marginal probability and mean are still conditional on the count being zero or positive, respectively.
This methodological gap is critical because, in clinical and health services research, marginal means are essential for providing covariate-adjusted, population-average outcomes. These outcomes are directly interpretable and serve as key metrics for quantifying disease burden and healthcare utilization, making them ideal for answering population-based research questions. Even with skewed data, the mean remains fundamental for estimating average hospitalizations, which is a vital step for resource allocation and policy planning.
When evaluating overall covariate effects, standard hurdle models—and similarly, standard zero-inflated models 12 —distinguish between zero and positive counts. However, this distinction often lacks clinical relevance and limits direct inference on the overall mean response. To address this, Long et al. 13 proposed marginalized ZIP models, which enable direct inference by averaging over the two ZIP model processes. Although Long et al. 14 extended this to accommodate longitudinal zero-inflated count data by modeling the subject-specific response mean given random effects, the covariate effects on the marginal probability of excess zeros were still not explained directly, as they were modeled using conditional logistic regression. In contrast, Lee et al. 15 proposed overall marginalized ZIP random effects models (MZIPREMs) for longitudinal zero-inflated count data. These new models not only directly capture marginal covariate effects on the overall mean but also rigorously account for heterogeneity through random effects, providing a more robust framework for clinical research.
In this paper, we adapt the overall MZIPREM approach proposed by Lee et al. 15 to the hurdle model framework. The primary aim is to simultaneously account for covariate effects on both the marginal mean and the marginal probability of excess zero for longitudinal zero-inflated count data. Our goal is to analyze both zero-inflated and zero-deflated longitudinal count data using overall marginalized hurdle random effects models (OMHREMs). These proposed models are designed to capture marginal covariate effects on the overall marginal mean, account for subject-specific heterogeneity via random effects’ covariance, and ultimately provide interpretable population-average effects of covariates on the count response.
The structure of this paper is as follows: Section 2 introduces the motivating example using the Lupus dataset. Section 3 provides a comprehensive review of relevant literature on hurdle models. In Section 4, we introduce overall marginalized hurdle Poisson models with random effects (OMHREM), designed for longitudinal zero-inflated count data, and incorporate a heterogeneous covariance structure to capture marginal covariate effects. The likelihood approach for the OMHREM is further detailed in this section. Section 5 presents simulation studies to evaluate the bias and efficiency of our proposed estimation method. In Section 6, the OMHREM is applied to the Lupus dataset. Finally, Section 7 presents a discussion and concluding remarks.
Motivating data: Lupus data
The systemic lupus erythematosus (SLE) dataset utilized in this study is a longitudinal cohort with repeated measurements on individuals from a 10-year period (2008–2018). It was sourced from the Korean National Health Insurance Service (NHIS), a public health program covering approximately 98% of the Korean population. The NHIS database serves as a valuable resource for population-based research, providing comprehensive healthcare data, including patient sociodemographic characteristic, diagnostic codes, healthcare utilization SLE is a chronic autoimmune disease characterized by dysregulation of immune responses, inflammation, and the formation of immune complexes, potentially affecting any organ or tissue. Its symptoms vary widely among patients and fluctuate over time, making diagnosis particularly challenging. 16 SLE flare-ups can lead to permanent organ damage, with approximately 50% of patients experiencing such outcomes within a decade of diagnosis. 17 The global incidence and prevalence of SLE are increasing, and the disease is associated with a mortality rate two to three times higher than that of the general population. Despite the availability of treatments, over half of SLE patients demonstrate poor medication adherence. These challenges highlight the critical importance of early detection and timely intervention. 18
The NHIS dataset has been widely applied in recent literature: Kim et al. 17 estimated direct healthcare costs for newly diagnosed patients, Han et al. 19 assessed cardiovascular risks, and Jang et al. 20 addressed outliers in longitudinal cost data using multivariate linear models. Building on these studies, our research aims to identify factors associated with hospitalization frequency in severe SLE patients by analyzing annual hospitalization counts over a 10-year period (2008–2017).
2.1 Hospitalization variable
The primary response variable is the annual number of hospitalizations. Figure 1(a) illustrates the distribution of overall hospitalizations aggregated across all years, showing that 61.7% of the observations are zero, which indicates substantial zero inflation. The non-zero subset (6814 observations) is highly skewed, with most counts concentrated at low values (Figure 1(b)).
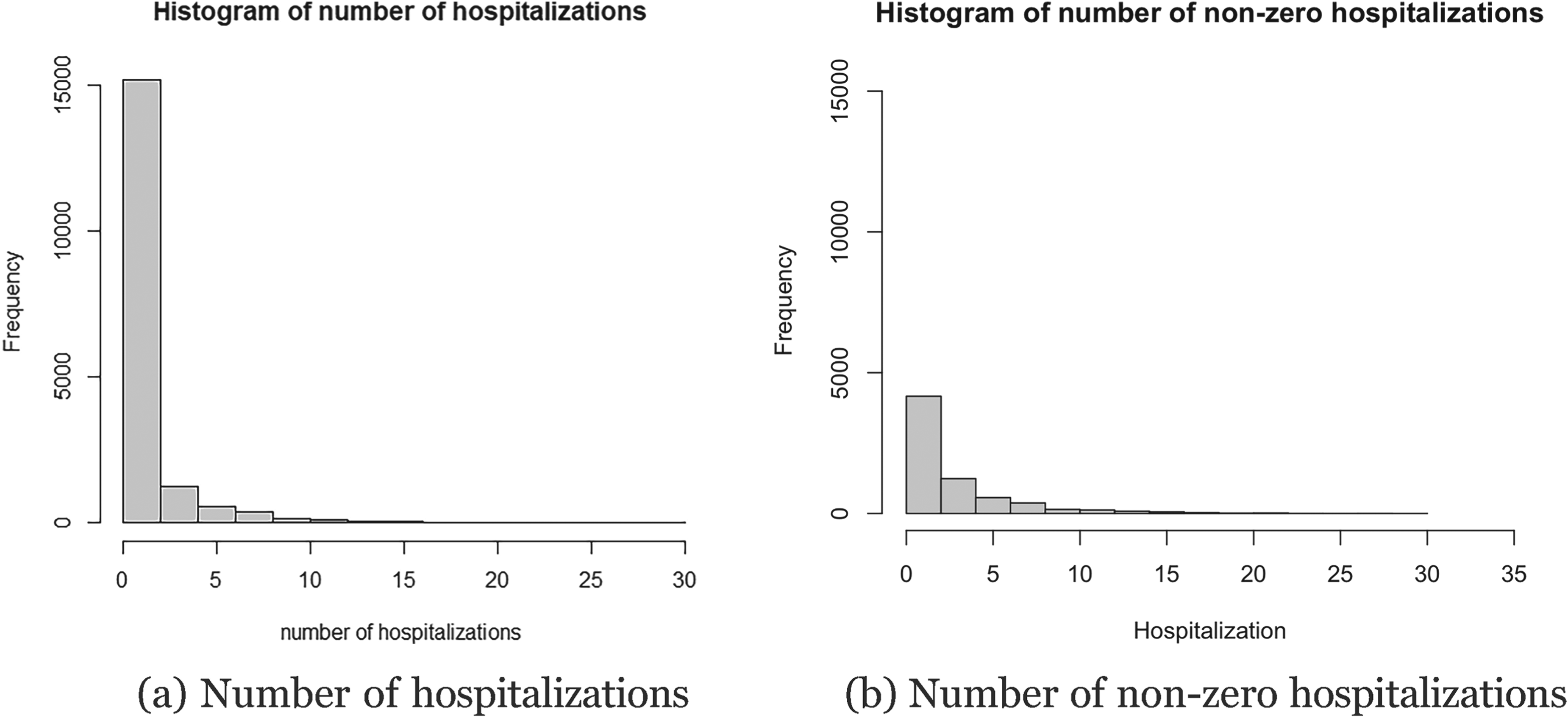
Histograms of the number of hospitalizations: (a) zero counts and (b) non-zero counts over time, highlighting the frequency of non-zero observations. (a) Number of hospitalizations. (b) Number of non-zero hospitalizations.
By examining only the non-zero counts in Figure 1(b), we can see a highly skewed distribution. This subset of data, which has a reduced sample size of 6814 compared to the original 17,736 observations, shows that most nonzero hospitalizations are concentrated at low values.
As shown in Figure 2, the overall mean change in hospitalization over the years shows a distinct pattern. The first year exhibits the highest overall mean at 2.87, which may be attributed to heightened attention during the initial phase. A sharp reduction is evident in the second year, where the mean plummets to 0.93. Thereafter, the mean gradually decreases with minimal fluctuations, suggesting a stabilization of hospitalization trends in the later years.
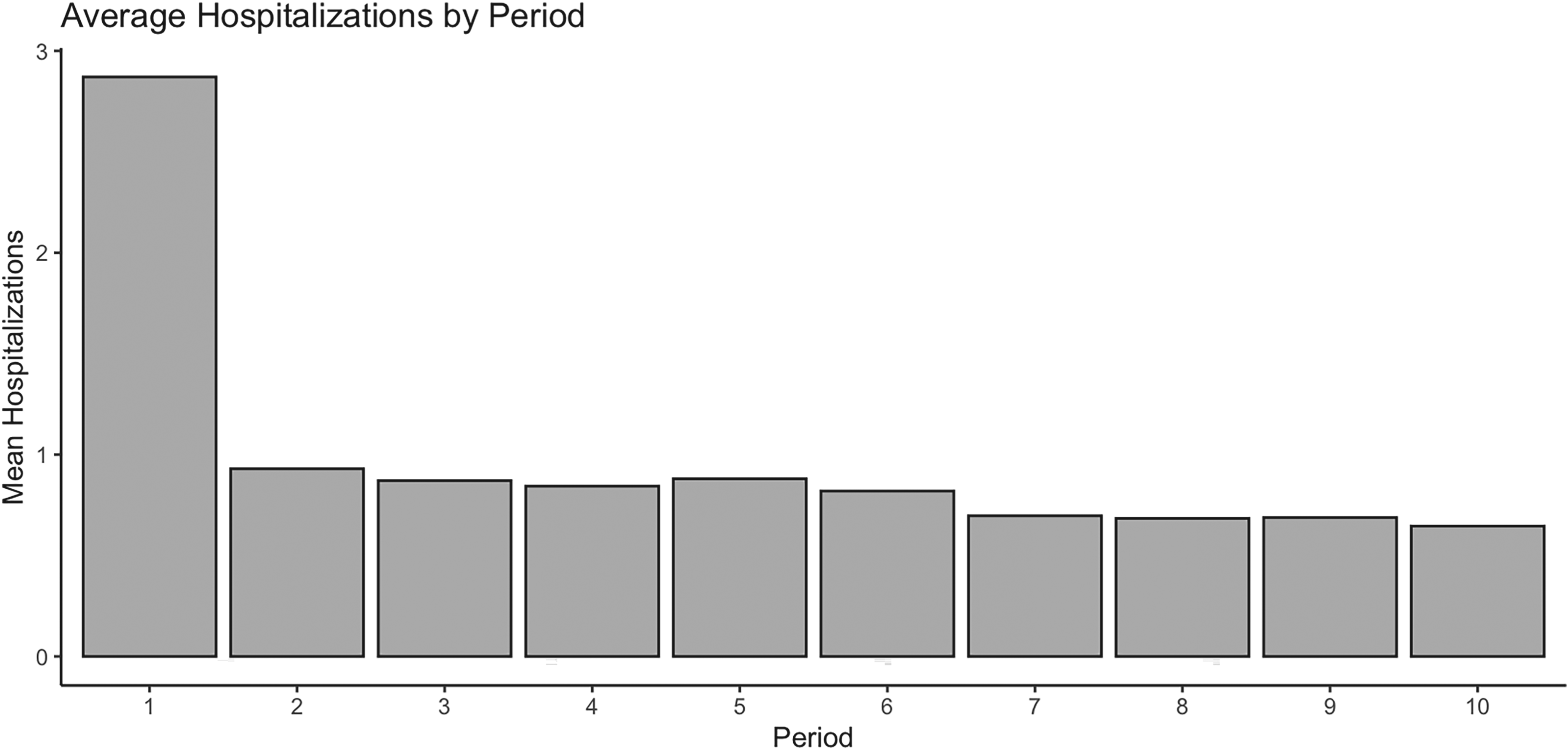
Average hospitalization by period.
2.2 Explanatory variable
The key explanatory variables are gender (0 = male, 1 = female), age, and Charlson's comorbidity index (CCI). For analysis, age was log transformed to
The baseline characteristics of the explanatory variables are presented in Table 1. Hospitalization in severe SLE is a clinically significant and costly outcome that varies by patient demographics and comorbidities. The repeated measures, count-based nature of the outcome, and high proportion of zero counts necessitate a modeling framework capable of simultaneously accounting for longitudinal structure and zero inflation. Accordingly, this study identifies predictors of hospitalization frequency by applying a marginal means approach, as described in Section 6, to ensure that the results are directly interpretable for population-level clinical and policy decisions.
Baseline characteristics of the explanatory variables.

In this section, we present a detailed description of statistical methods for analyzing zero-inflated count data. The discussion begins with the standard hurdle model and its extension for longitudinal studies, the HREM. We then review a marginalized hurdle model which offers a distinct approach by directly modeling the impact of covariates on the marginal mean response.
3.1 Hurdle model
The hurdle model, originally proposed by Mullahy, 4 is a two-part mixture model designed for count data exhibiting excess zeros in cross-sectional studies. The model assumes that all zeroes are from one structural source, with the first part being a binary model that determines whether the count is zero or positive, while the second part models the positive counts using a zero-truncated Poisson or truncated NB distribution.
Let 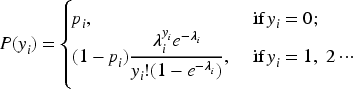
Where the model components are assumed as follows:
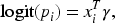
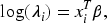
The Hurdle model is capable of addressing both zero inflation and zero deflation in count data. When
3.2 Hurdle random effects model
Min and Agresti
2
proposed the HREM to accommodate longitudinal zero-inflated count data by incorporating subject-specific random effects. Let 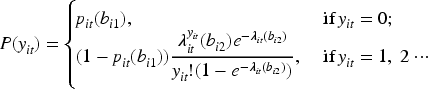


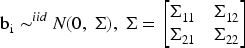
In many practical applications, a simple random intercept model provides sufficient flexibility for capturing subject-specific variability. Min and Agresti
2
considered the case where both random effects, 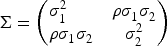
Note that Zhu et al.
8
proposed incorporating a subject-specific positive-definite covariance matrix
Estimating parameters in HREMs typically employs either likelihood-based or Bayesian approaches. Neelon et al. 6 proposed a flexible Bayesian method for longitudinal zero-inflated count data that accommodates correlated random effects and uses prior information for effective inference. A key limitation of Bayesian methods, however, is their high computational cost, particularly when using Markov Chain Monte Carlo (MCMC) algorithms.
The likelihood-based approach presents a distinct computational challenge, as it necessitates integrating over the random effects. This issue is generally resolved through approximation techniques such as Laplace approximation,
22
adaptive Gaussian quadrature,
23
or penalized quasi-Newton methods, which facilitate the approximation or direct maximization of the marginal likelihood.
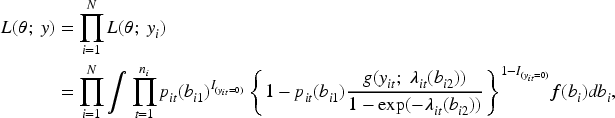
where
HREMs have been extended in several ways. First, to relax the assumption of normally distributed random effects, Molas and Lesaffre 24 proposed a h-likelihood approach that can accommodate a wider range of distributions. Second, to better account for unobserved heterogeneity, Park et al. 25 proposed a nonparametric Bayesian Poisson hurdle model, which uses nonparametric techniques to provide more flexibility in the random effects distribution. Third, addressing the standard Poisson distribution‘s assumption of equidispersion, Kang et al. 9 extended the Poisson hurdle model with the CMP distribution. The CMP distribution is particularly useful because it includes an extra parameter to flexibly model underdispersion, equidispersion, or overdispersion, thereby improving the model's ability to capture the mean-variance relationship in real-world data.
3.3 Marginalized random effects model
While HREMs are useful for capturing subject-specific variability, they do not directly produce marginal means, which are often the primary focus for population-level inference. To address this, Lee et al.
11
proposed the MHREM, using a likelihood-based estimation method. These models provide a direct and interpretable way to analyze how covariates affect the marginal means of both the binary and non-zero count responses. In the following subsection, we will review the MHREM.
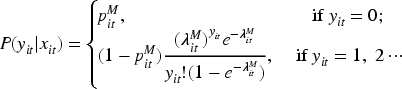
The model components are assumed as follows:


The conditional hurdle model is extended by incorporating random effects to handle the serial correlation often present in repeated measurements. Specifically, let 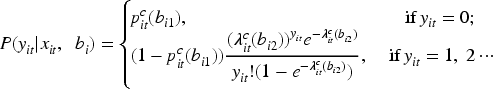


From Equations (8), (9), (11) and (12), the deterministic intercepts 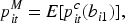
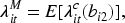
Using these relationships,
3.4 Classification of models
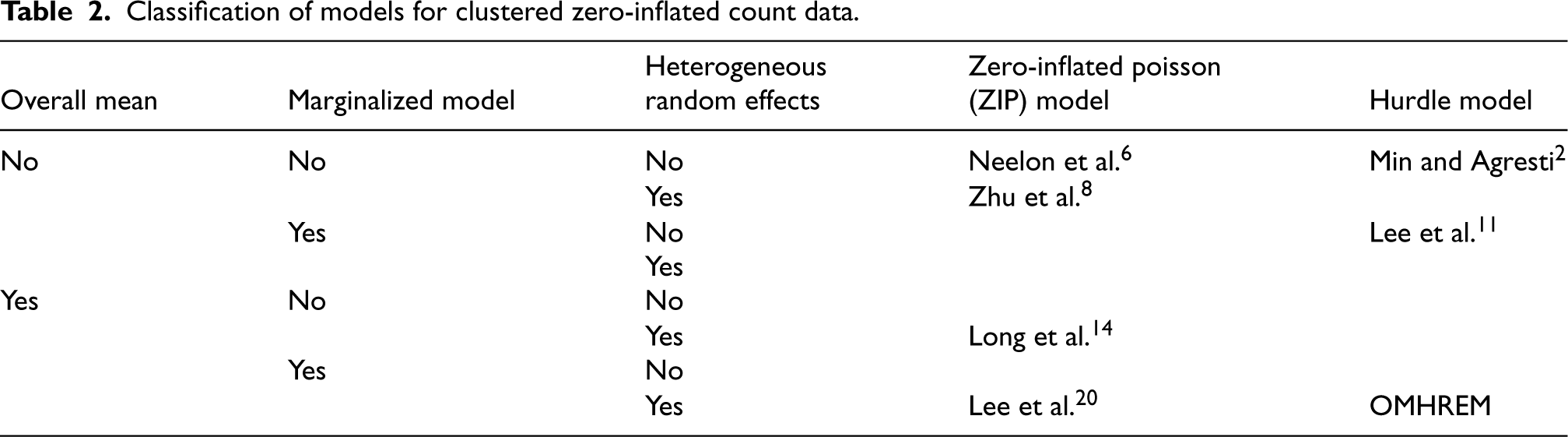
To summarize and clarify the models in this section, we present Table 2, which provides a hierarchical cross-classification of existing studies to identify the specific methodological gaps addressed by our work. Following the suggested guiding principles, we categorize the literature based on (i) the target of inference (overall mean effects versus latent class interpretations), (ii) the presence of random-effect marginalization, and (iii) the homogeneity or heterogeneity of the random-effect covariance matrix.
Classification of models for clustered zero-inflated count data.
In this section, we adapt Long et al.
13
's overall marginalized ZIP model to accommodate longitudinal zero-inflated count data within a hurdle model framework. Denote
4.1 Proposed model
We extend the MHREM presented in Lee et al. 11 to account for the overall marginal effect of covariates, and refer to the resulting model as the OMHREM. This model captures both the Poisson mean and the probability of a zero count, as in traditional hurdle models, while enabling marginal interpretations of covariate effects.
The OMHREMs comprise three components: the marginal model, the dependence model, and the overall mean model. The marginal model adopts a standard Poisson hurdle structure and is the same as (7) in the marginalized random effects model. We also consider the model components in (8) and (9). This specification allows for a latent class interpretation of the likelihood by distinguishing between the zero-count group and the positive-count group.
To account for the serial correlation in repeated count data, we consider the dependence model (10) in the marginalized random effects model to incorporate subject-specific random effects. In our proposed model, the conditional model components are specified differently using generalized linear models:


The subject-specific random effects 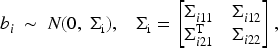
We consider a specific case with random intercepts bi1 and bi2 by setting 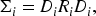
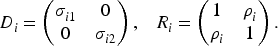
This parameterization allows for heteroskedastic variances and subject-specific correlation while ensuring that 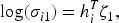
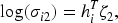
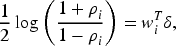
Note that the random effects covariance matrix in our proposed model incorporates hetergeneous SDs
From equations (8), (9), (13), and (14), we derive the following relationships between the marginal and conditional components:


Given that the parameters 

Consider the overall marginal mean of 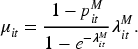
Note that the overall marginal mean µit is a function of covariates and parameters associated with 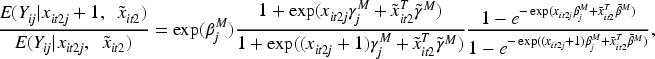
From the result in (22), unless 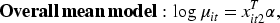
Based on models (21) and (23), we obtain the following relationship:
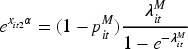
4.2 Estimation
Let 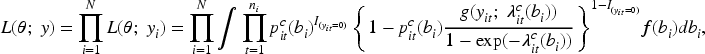
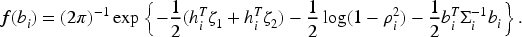
The corresponding log-likelihood function is:
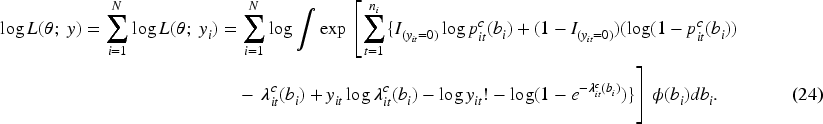
Because the integral in (24) does not have a closed-form solution, we employ Gauss-Hermite quadrature to numerically integrate out the random effects.
Maximizing the log-likelihood with respect to 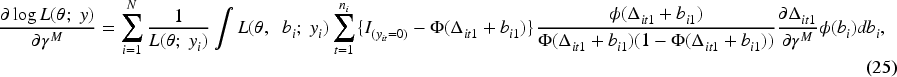
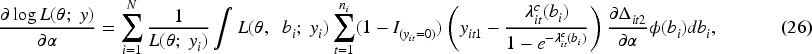
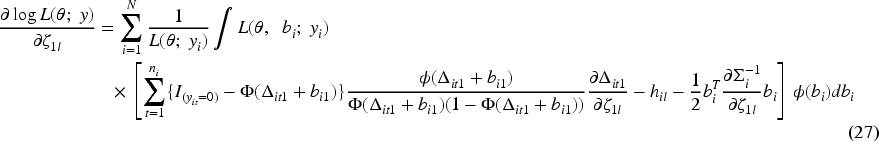
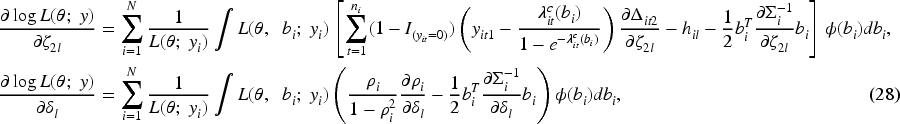
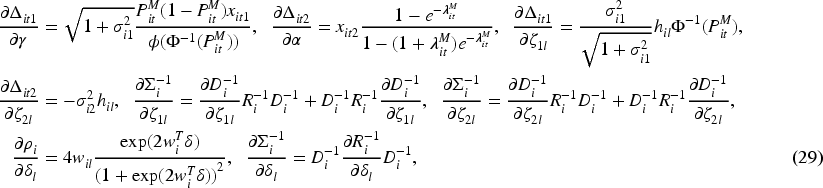
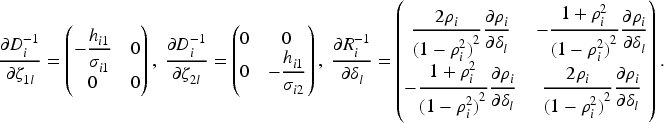
The second derivatives of the log-likelihood are analytically intractable. However, the sample covariance of the individual score functions provides a consistent estimator of the information matrix, relying only on first derivatives. Consequently, the Quasi-Newton method can be used to solve the likelihood equations. Unlike the classical Newton-Raphson method, the Quasi-Newton approach approximates the Hessian matrix using gradient information, thereby avoiding the need for exact second derivatives.
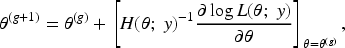
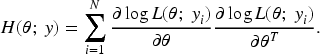
A simulation study was conducted to evaluate the performance of the OMHREM's parameter estimation. A total of 500 datasets were generated under its framework, with varying sample sizes (300, 500, and 700) and a fixed number of four repeated measurements per individual (
For each time point 


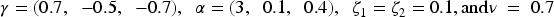
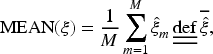
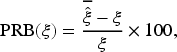
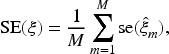
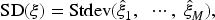
To provide an overall summary of the estimation performance across all parameters, we report the average of the absolute PRBs (APRBs), the ASEs, and the average of the SDs (ASD). These summary measures are calculated as follows:
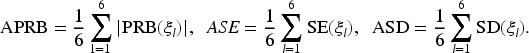
Lastly, to evaluate the accuracy of the estimated random effects covariance matrix 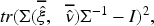
Table 3 summarizes the simulation results for MLE performance across sample sizes N = 300, 500, 700. The estimated parameters are generally close to their true values. As the sample size increases, the SEs, SDs, and PRBs of the estimates diminish, suggesting increased precision and lower bias. The overall performance metrics (APRB, ASE, and ASD) also show substantial decreases with larger sample sizes, indicating improved estimation accuracy. Furthermore, the Frobenius norms decrease as N increases, demonstrating that the estimated covariance matrices converge towards the true structure.
Simulation study results from the OMHREM model are evaluated using the mean estimate (MEAN), PRB, average SE, SD of 500 estimates, frobenius norm (FROB), APRB, and ASE and ASD.
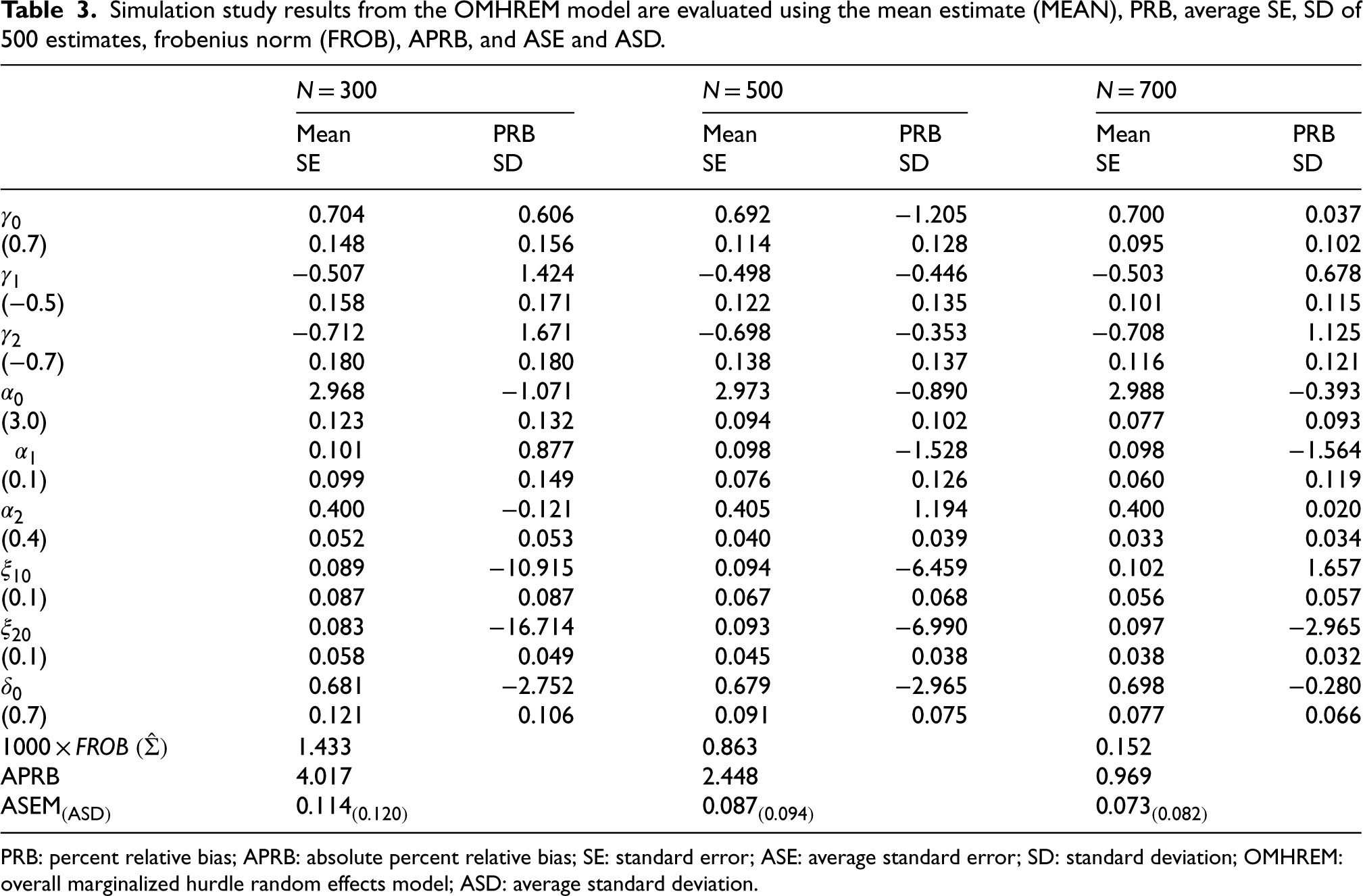
PRB: percent relative bias; APRB: absolute percent relative bias; SE: standard error; ASE: average standard error; SD: standard deviation; OMHREM: overall marginalized hurdle random effects model; ASD: average standard deviation.
Table 4 summarizes the model convergence across sample sizes of N = 300, 500, and 700. The convergence rate is defined as the ratio of 500 successful convergences to the total number of simulations. For N = 300, a total of 930 runs were required, while 785 and 710 runs were needed for N = 500 and 700, respectively. This indicates that the convergence rate improves as the sample size increases, leading to more stable model performance.
The convergence rate of the overall marginalized hurdle random effects model (OMHREM) is defined as the ratio of 500 converged runs to the total number of iterations needed.

We conducted another simulation study to compare the proposed OMHREM with the standard HREM incorporating random effects. 2 The HREM was implemented using the glmmTMB R package, a widely utilized tool for such models. Model performance was evaluated based on the Akaike information criterion (AIC) and the maximized log-likelihood value (MLLV). As summarized in Table 5, the OMHREM consistently yielded higher MLLVs and lower AIC values across all sample sizes. These results demonstrate a clear advantage in model fit, confirming the superiority of our method when the OMHREM is the true model.
The average AIC and maximized log-likelihood were calculated over various sample sizes and 500 simulated datasets.
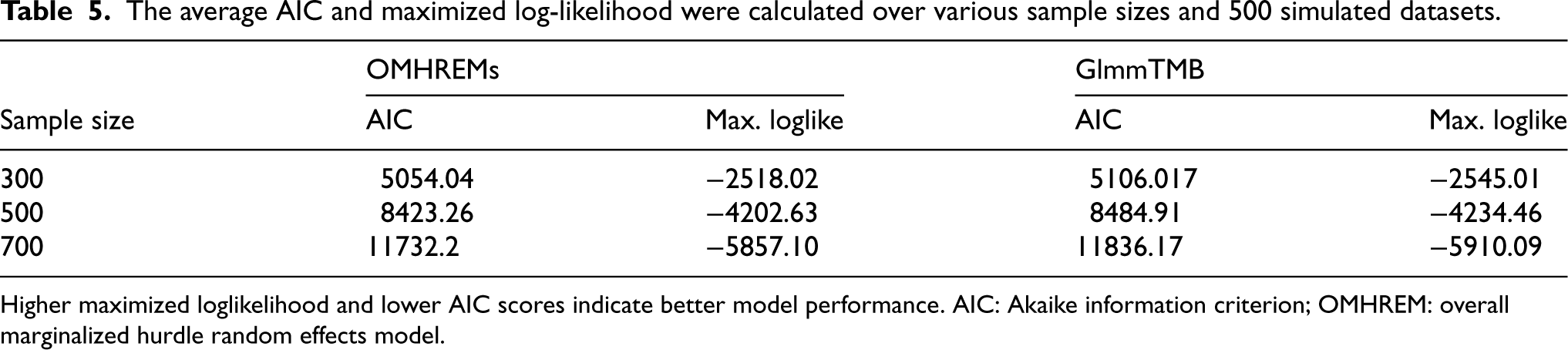
Higher maximized loglikelihood and lower AIC scores indicate better model performance. AIC: Akaike information criterion; OMHREM: overall marginalized hurdle random effects model.
Simulation study results from the OMHREM model with heteroskedastic covariate are evaluated using the mean estimate (MEAN), PRB, ASE, ASD of 500 estimates, frobenius norm (FROB), average APRB, and ASE and ASD.
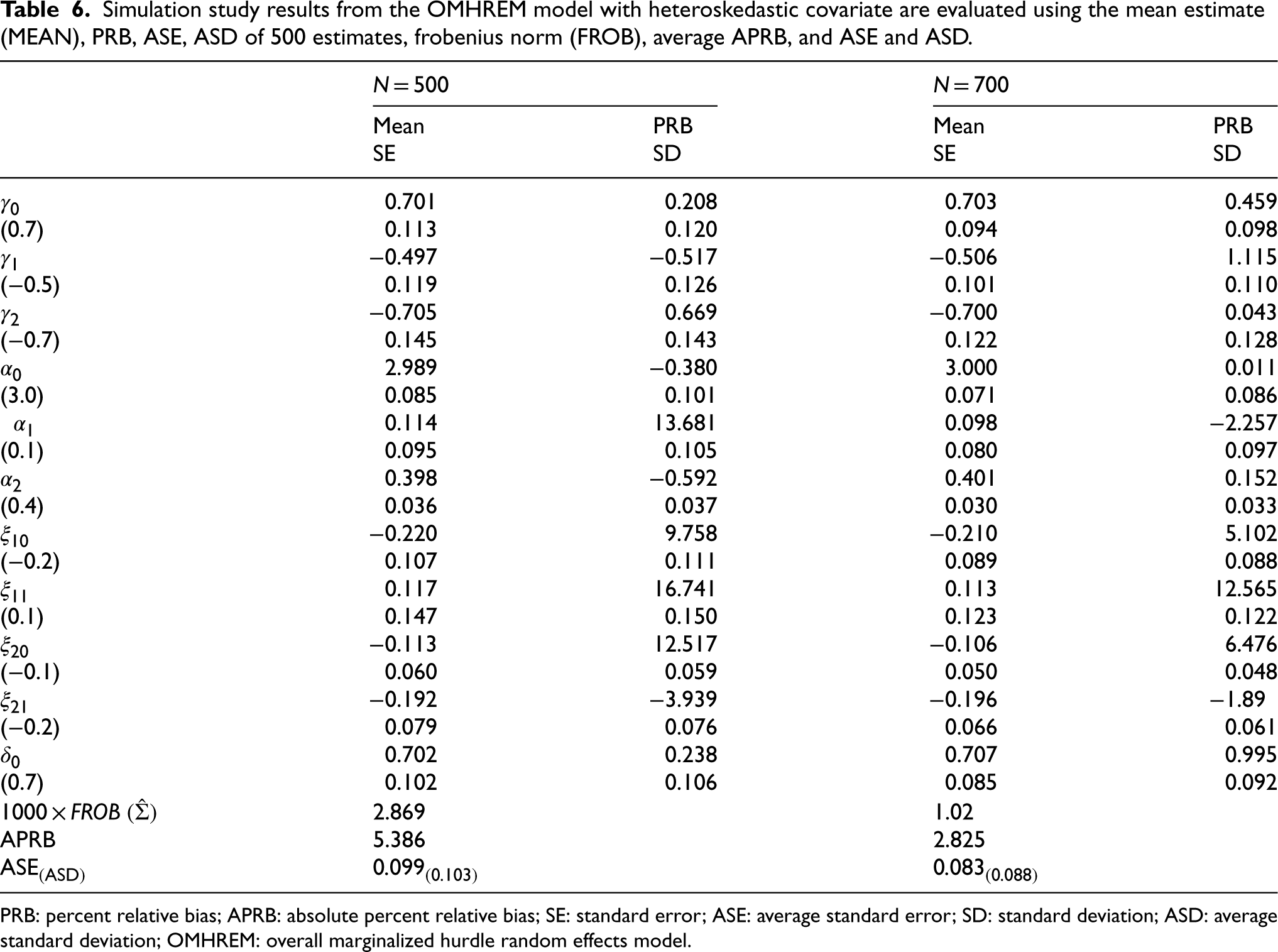
PRB: percent relative bias; APRB: absolute percent relative bias; SE: standard error; ASE: average standard error; SD: standard deviation; ASD: average standard deviation; OMHREM: overall marginalized hurdle random effects model.
It should be noted, however, that while the OMHREM and HREM are members of the same hurdle model family, they employ different likelihood formulations. Therefore, the AIC and log-likelihood comparisons presented here should be interpreted with caution as approximate indicators of empirical fit, rather than an exact information-theoretic comparison across equivalent likelihoods.
Further simulation studies were conducted to compare the performance of the OMHREMs under the same marginal model specifications, (30) and (31), and heteroskedastic random effects covariances. Similar to the homogeneous case, we generated 500 datasets from OMHREMs incorporating heterogeneous random effects covariance structures, specified as follows:
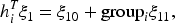
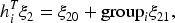
Table 6 summarizes the simulation results for the MLE performance of OMHREMs with heterogeneous
This study examines the number of hospitalizations as a longitudinal response variable to identify factors that influence hospitalization frequency among patients with severe SLE, using data that are heavily zero-inflated.
6.1 Model fit
The OMHREMs are compared to existing models where the covariance structure is allowed to vary based on gender, age, and CCI for each subject over time. Table 7 details the models used in this comparison. Model 0 is an OMHREM with a homogeneous random effects covariance matrix. Models 1–3 are OMHREMs with random effects covariance structures that depend on gender, gender and age, and gender and CCI, respectively. Model 4 is the overall MZIPREM with a homogeneous random effects covariance matrix, as proposed by Lee et al. 15
The models for
and
are presented for the SLE data.

The models for
OMHREM: overall marginalized hurdle random effects model; SLE: systemic lupus erythematosus; MZIPREM: marginalized zero-inflated Poisson random effects model.
Table 8 shows the maximized log-likelihood and AIC for each model. The OMHREMs (Models 0–3) demonstrate superior performance compared to Model 4. Among the OMHREMs, Model 3 has the lowest AIC, suggesting it provides the best fit to the data.
Maximized log likelihoods and akaike information criterions (AICs) for models.

Table 9 presents the MLEs and their associated SEs for Models 0–4. The results indicate that most covariates across all models are statistically significant at the 5% level, suggesting strong associations between age, gender, CCI, and SLE hospitalizations. It should be noted that Model 4 is an MZIPREM, where the zero model distinguishes between structural zeros and Poisson zeros. Unlike conditional models, all models presented here directly estimate marginal population-average effects. By better accounting for complex between-subject heterogeneity and within-subject dependence, this innovative framework provides clinicians with more readily interpretable metrics.
Maximum likelihood estimates of the parameters of models 1–4 for SLE data. Standard errors are displayed in parentheses.
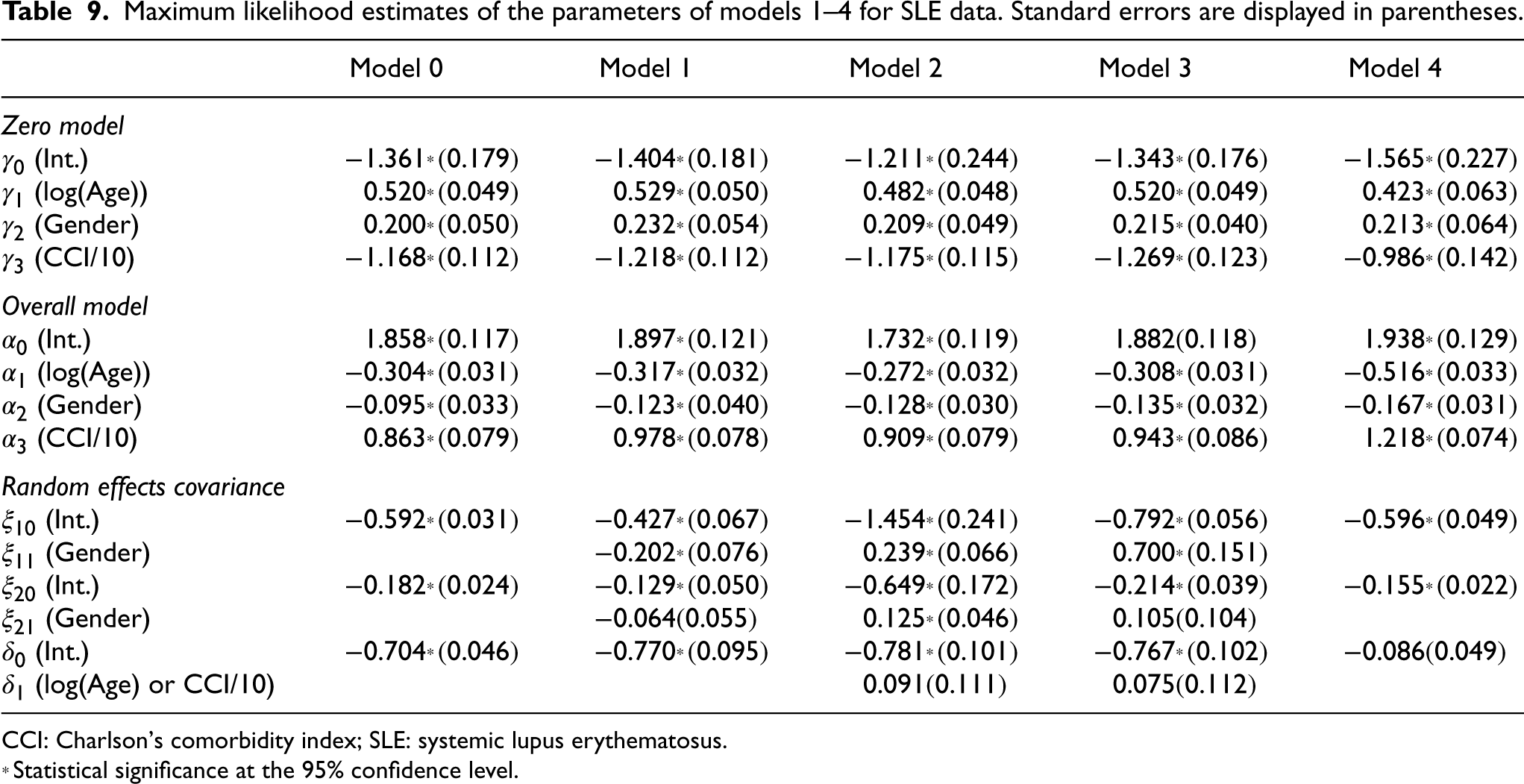
CCI: Charlson's comorbidity index; SLE: systemic lupus erythematosus.
∗ Statistical significance at the 95% confidence level.
Based on the model selection criteria, Model 3 was identified as the optimal model for our analysis. The estimated equations for the marginal probability of hospitalization and the overall marginal mean, derived from Model 3, are presented as follows:
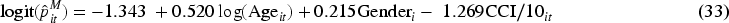
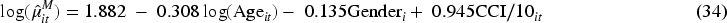
Based on (33) and (34), the estimated probability of non-hospitalization increased with age, was higher for females than males, and decreased with CCI. Conversely, the estimated log of the overall mean count decreased with age, was lower for females than males, and increased with CCI.
The estimated SD of the random effects in the logit model was 0.912 for women
For a subject with an average log-transformed age (log Age) of 3.637, the estimated correlation between the random effects was calculated as 0.135 using the following formula:
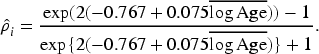
Based on equation (16), the estimated random effects covariance matrices for women and men with 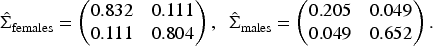
The results indicate that the random effects covariance matrices differ between genders. Females show larger variances for both zero and positive count components, suggesting greater subject-level variation in both outcomes. Conversely, males tend to have lower variability but a weaker covariance in the positive count component.
This paper proposes an overall marginalized Poisson HREMs (OMHREMs) for the analysis of longitudinal zero-inflated count data. The OMHREMs framework consists of three submodels: a marginal hurdle model capturing population-averaged responses for the binary zero outcome and the positive counts, a dependence model employing a hurdle structure with random effects to account for within-subject heterogeneity, and an overall mean model utilizing a loglinear structure to model the direct impact of covariates on the logarithm of the overall marginal mean. A key advantage of OMHREMs over conventional hurdle models is their capacity to provide direct population-level interpretations of the marginal mean, a feature absent in traditional approaches that restricts their ability to assess overall covariate effects. Furthermore, the random effects covariance matrix is assumed to be heteroskedastic, allowing for subject-specific variability.
Model parameters are estimated using a Quasi-Newton algorithm. Following this, the marginal likelihood is calculated by evaluating integrals by Gauss-Hermite quadrature across the random effects. The resulting algorithm demonstrates both computational efficiency and robustness.
Simulation results demonstrate that as the sample size increases, the SEs, SDs, and PRBs of the estimates decrease, showing convergence toward the true parameter. The decreasing Frobenius norms suggest that improved accuracy and convergence towards the true covariance structure.
In the analysis of the SLE data, the OMHREM provided the best fit among the models considered. Within this framework, the log of the overall mean count was negatively associated with age, lower for females, and positively associated with the CCI. Conversely, the probability of non-hospitalization showed a positive association with age, was higher in females, and was negatively associated with the CCI.
Although Gauss-Hermite quadrature is frequently applied for marginal likelihood in low-dimensional settings, its computational cost grows exponentially with increasing dimensionality due to the rapid increase in quadrature points. 11 To overcome this limitation, alternative approaches such as Monte Carlo integration or extensions within a Bayesian framework utilizing MCMC methods for posterior inferences can be considered.
One limitation of our proposed model is the restrictive assumption of the Poisson regression model that the mean and variance of the count variables are equal. When overdispersion is present, the Poisson model may lead to underestimated SEs. To address this, alternative distributions such as the NB are used to allow for greater variability. 26 Addressing this limitation is an ongoing work.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Basic Science Research Program through the National Research Foundation of Korea (KRF) funded by the Ministry of Education, Science and Technology (RS-2024-00407300 for Keunbaik Lee).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.