
Abstract
Clover (Trifolium) plants with rich protein, fiber and nutrient contents provide high forage yield, essential for efficient animal production. They also offer further ecological benefits including erosion control, soil reclamation, pollinator support, and urban greening. Wild clover species possess vital genetic traits to adapt to adverse growing conditions including drought, heat stress, and diseases. Thus, precise and quick identification of clover species can significantly aid successful plant breeding and sustainable agriculture. Human-based evaluations may not always be objective, while laboratory genetic analyses require significant amount of time, labor, and cost. The present work is the first study to accurately classify wild Trifolium species by using near infrared (NIR) reflectance spectroscopy and machine learning (ML) algorithms. NIR reflectance data (4000–10,000 cm-1) of 146 dried-ground plant samples belonging to nine Trifolium species were used for the classification along with four data pretreatment methods and six ML algorithms. Three different data sets were utilized in the analysis: (a) the data with no dimensional reduction, (b) the data with dimensional reduction by using principal component analysis (PCA), and (c) the data with dimensional reduction by using linear discriminant analysis (LDA). The most successful result was obtained with the LDA data coupled with multiplicative scatter correction (MSC) and K-nearest neighbors (KNN) algorithm with 98% test classification accuracy. The results of this study showed that the NIR spectroscopy coupled with ML algorithms can be utilized to correctly identify the Trifolium species needed for effective plant breeding and conservation strategies.
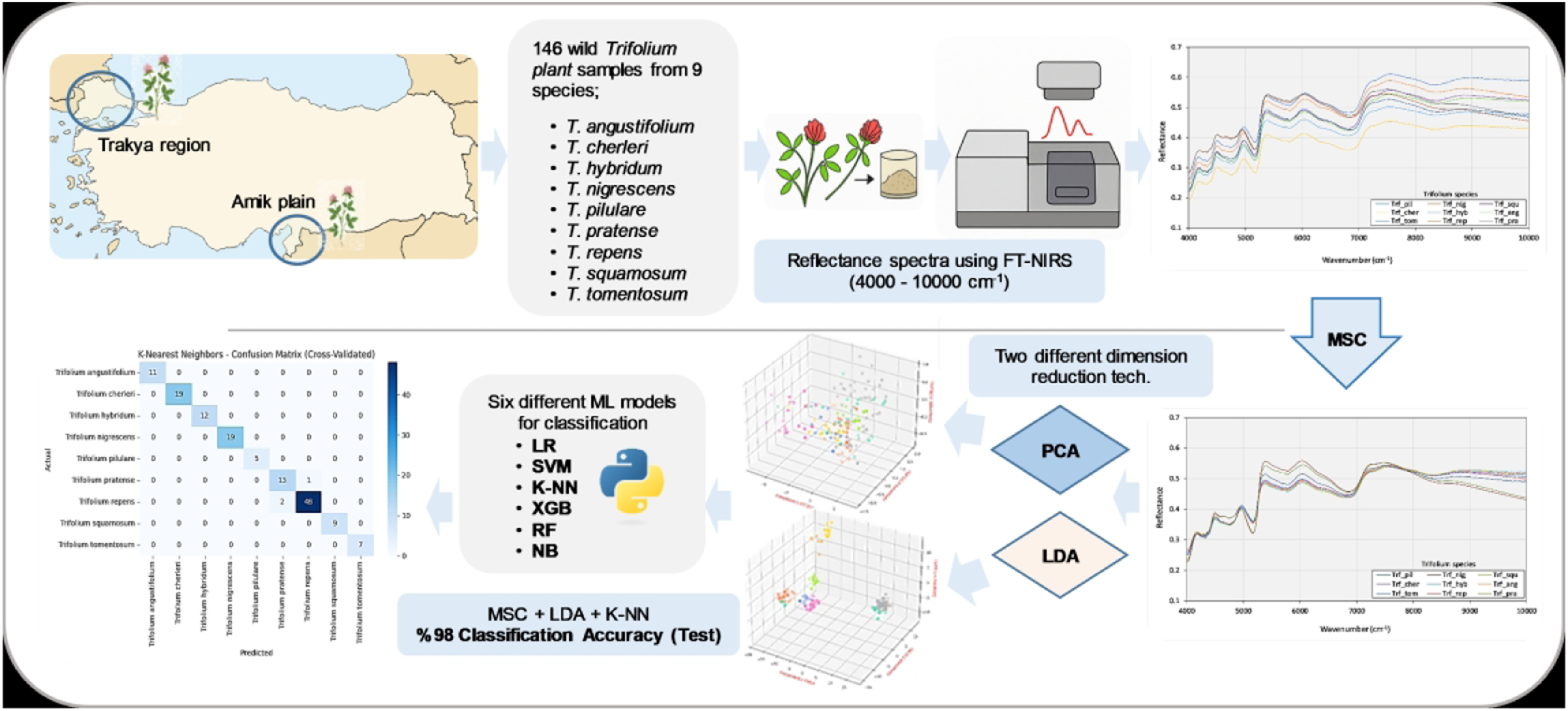
Introduction
Humanity is in a critical period in history, marked by converging crises of climate change, environmental pollution, biodiversity loss, and global food insecurity.1,2 The world population is expected to rise by 2.2 billion, and farmers need to grow about 70% more food, by 2050. 3 This challenge coincides with alarming trends in habitat degradation, loss of plant biodiversity and genetic erosion, which are diminishing the pool of plant genetic resources essential for sustainable crop improvement through plant breeding.4,5 This decline threatens the adaptive capacity of a species and highlights the urgency of conserving intra-species diversity as a critical component of ecosystem resilience and agricultural sustainability.2,6 Thus, the conservation and effective use of plant genetic resources are foundational for effective plant breeding and sustainable food security. 4 Furthermore, zero hunger, mitigating biodiversity loss (life on land), and responsible consumption and production are among the United Nations’ 2030 sustainable development goals. 7
Among the most promising yet underutilized plant resources are wild forage legumes, especially the Trifolium (clover) genus, which harbors adaptive traits shaped by evolutionary pressures in marginal and diverse ecosystems. Cultivated clover species, especially the perennials, play a pivotal role in sustainable agriculture due to their nitrogen-fixation capacity, adaptability to diverse environments, suitability to some adverse soil conditions, and high forage yield and quality.8,9 These species are widely used in pasture systems, rotational cropping, and as green manure, contribute to soil fertility, reducing input costs, improving ruminant feeding through high nutrition and digestibility. 10 For example, with its high content of protein (8-25%) and crude fiber (12-39%) on dry basis, red clover (Trifolium pratense L.) hay is a vital feed source in animal husbandry. 11 Clover is named as “king of fodder” in some countries due to its high yield, rich nutrient content, a long harvest season of five to six months. 12 White clover (Trifolium repens L.) is also a valuable plant as a source of pollen for honey production.13,14 Moreover, clovers serve in non-agronomic roles such as erosion control, soil reclamation and regeneration, pollinator support, and urban greening due to their low-input requirements and ground-covering ability.13–15 The main white clover growing areas are in the temperate regions of western Europe, the United States, New Zealand and South America. 13 From a commercial perspective, clover seed production and trade form a significant component of the global forage seed industry. In 2023, the global market for clover seeds for sowing was valued at about USD203 million, showing a 17.1% increase over the previous year, while Italy and Germany were the top exporter and top importer, respectively. 16
The Mediterranean Basin, recognized as a global biodiversity hotspot, plays a central role in the plant diversity context. Türkiye, situated at the eastern edge of this basin with exceptional floristic richness, is home to almost half of the 200+ Trifolium species found worldwide.14,17 Wild Trifolium species, though rarely cultivated, possess a suite of traits, including drought tolerance, rapid establishment, adaptivity to adverse soil conditions, and persistence under grazing, that are increasingly valuable for breeding resilient forage crops used as a feed source in livestock production.10,13 These traits are particularly critical in light of the growing challenges associated with climate change and the need for sustainable land use in dry and semi-arid environments and marginal regions.
The conservation and utilization of the rich genetic resources have been threatened by urbanization, overgrazing, and monoculture expansion in recent decades. 6 Numerous wild legume populations have been lost or fragmented in the last several decades. Efforts to safeguard this diversity are further complicated by the taxonomic ambiguity inherent in Trifolium. Many species exhibit convergent morphologies, making field identification unreliable. As a result, misclassification in plant gene banks and underuse in plant breeding programs remain as significant barriers leading to economic and time losses.
High-throughput digital phenotyping has emerged as a transformative tool in regards to overcome possible plant misclassification problems. Advances in digital phenotyping technologies are revolutionizing how plant genetic resources are characterized, monitored, and utilized, particularly in breeding programs targeting complex traits such as drought tolerance, persistence, and forage quality. When combined with advanced data analysis techniques including machine learning (ML) algorithms, the high-dimensional complex datasets allow for the detection of subtle, non-linear patterns, thereby enhancing predictive modeling and trait-based selection. In particular, spectral analysis techniques such as chromametry, spectroradiometry, near infrared (NIR) spectroscopy, hyperspectral imaging (HSI), and chlorophyll fluorescence imaging enable the acquisition of precise and repeatable phenotypic data across diverse environments and developmental stages, critical for discriminating closely related taxa. In particular, NIR spectroscopy has been utilized to capture species-specific spectral “fingerprints” reflecting differences in biochemical composition including protein, fiber, lignin, and cellulose, enabling the classification of plant, vegetable and fruit cultivars in a rapid and inexpensive manner. 18
Various studies have been carried out to classify plant species by using digital measurement systems (chromameters, spectrophotometers, spectroradiometers, NIR spectroscopy, HSI) combined with classical (such as principal component analysis, PCA) and/or advanced data analysis techniques including ML algorithms such as partial least squares-discriminant analysis (PLS-DA), linear discriminant analysis (LDA), support vector machine (SVM), generalized linear model: (GLM), decision trees (DT), naive Bayes (NB), and artificial neural networks (ANN). Regarding NIR spectroscopy, researchers have used various data pretreatment methods including normalization, mean centering, standard normal variate (SNV), Savitzky Golay (SG) first and second derivatives, or multiplicative scatter correction (MSC) to increase the accuracy of the data analysis results.18,19 San Nicolas et al. 20 applied NIR HSI to classify six cannabis varieties of three chemotypes (I, II, and III) from the whole plant images with an accuracy of 92-100% by using PLS-DA and HPLS-DA. Migacz et al. 21 categorized six Eucalyptus tree species at four different ages by using Vis/NIR spectra and color parameters of fresh leaves by employing the PCA and LDA with the accuracy values of up to 100%. A hand-held spectrometer was utilized by Sohn et al. 22 to classify six different Amaranthus species with an accuracy of 71-100% by using SVM, GLM, DT, and NB methods. Borraz-Martinez et al. 23 employed NIR spectroscopy to discriminate six almond tree varieties from their fresh and dried-ground leaves by using PLS-DA with an accuracy of 90-100%. In another study on the classification of three types of Miscanthus plants, 24 Vis-NIR spectroscopy was employed with LDA, PLS, and LS-SVM data analysis techniques providing an accuracy of 88-99%. Chen et al. 25 identified three different Chrysanthemum varieties from dried-powdered samples by using the NIR spectroscopy and PLS-DA obtaining 86-95% accuracy. Dale et al. 26 discriminated three taxonomic plant families (Poa, Faba, Other) comprised of 27 grassland species from dried-powdered samples by using the HSI combined with the PLS-DA achieving an accuracy of 96-100%.
Accurate and rapid identification of plant species is a crucial evaluation procedure for an effective and successful plant breeding required for sustainable agriculture. Traditionally, experienced human assessors conduct the evaluations but sometimes it may not be possible to find an appropriate expert. Furthermore, human-based evaluations may not be objective enough in some cases especially in the lack of experienced assessors while the evaluation accuracy may be variable from person to person. 27 It is possible to use genetic analyses for the assessments4,28–30 but these require considerable amount of time, labor, and cost and they also pose risks to laboratory staff due to the chemicals involved. 31 There have been numerous studies that employed NIR spectroscopy to predict various chemical and nutritional contents of clovers including protein, fiber, carbohydrate, organic matter, lipid, fat, starch, lignin, cellulose, digestibility, energy, mineral elements.8,10,11,32–37 However, there has been no work on the rapid and accurate discrimination of Trifolium species and this is the first study to examine their classification by using NIR spectroscopy and ML data analysis methods, to the best knowledge of the authors. Therefore, in this study, NIR spectroscopy and supervised ML algorithms were employed to discriminate wild Trifolium species collected from two different regions of Türkiye. The objectives in the present work were two-fold; first: to evaluate the potential of this combined approach (NIR spectroscopy and ML) for the accurate in situ species identification and second: to contribute to the broader goals of conserving plant genetic resources and enhancing their utilization in plant breeding programs aimed at resilience, adaptability, and high forage quality needed for sustainable animal production.
Methodology
Clover plant samples
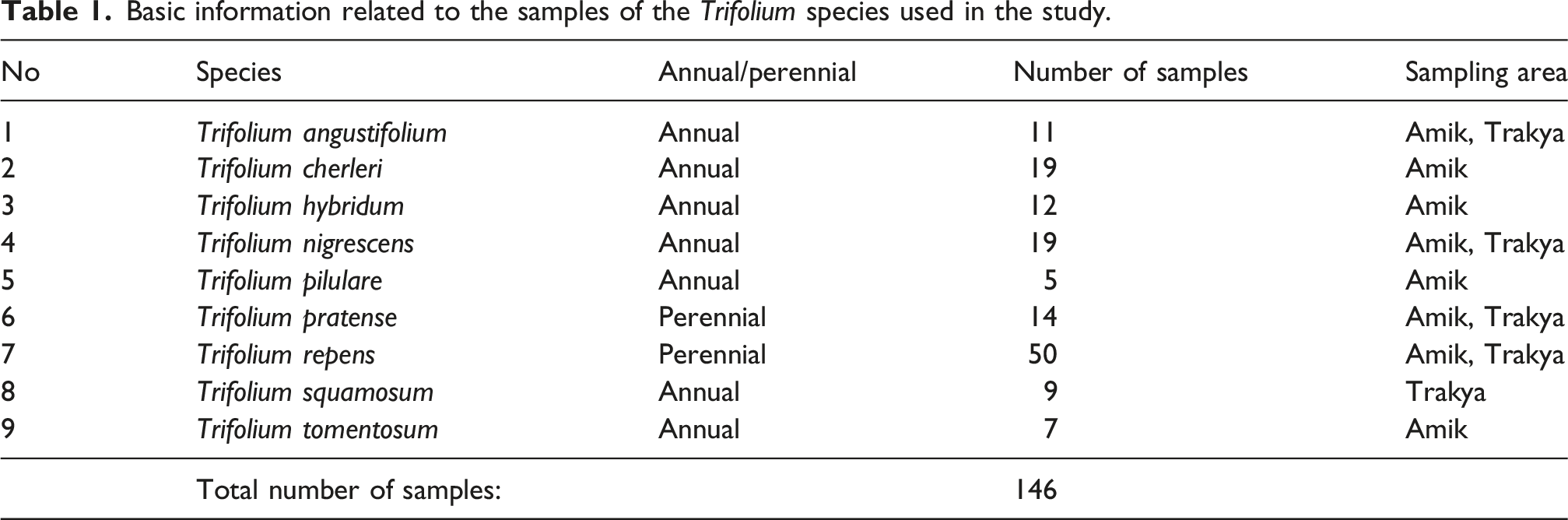
The wild clover (Trifolium sp.) plant samples used in the present study were handpicked from their natural habitats in two ecologically-distinct regions. The first sampling area was the “Amik Plain”, located in the Hatay Province in the eastern Mediterranean zone of Türkiye (36°19ʹ–36°25ʹ N; 36°13ʹ–36°23ʹ E; elevation ∼85 m). The Hatay province is characterized by typical Mediterranean climate, with hot-arid summers and mild-wet winters. The mean monthly temperature peaks at 28.3°C in August and declines to a minimum monthly average of 8.2°C in January, with a mean annual temperature of 18.6°C with seasonal precipitation, mostly between November and April (MGM 2025a). The average annual total precipitation is about 1124 mm with the highest monthly average in December (189 mm) and lowest in August (5.4 mm). 38 The second sampling area was in the “Trakya region” of Türkiye which includes the provinces of Tekirdag, Kirklareli, and Edirne, along with parts of Istanbul and Canakkale provinces located in the northwestern part of the country (40°40ʹ–41°50ʹ N; 26°40ʹ–28°35ʹ E; elevation: ∼0–300 m), where the samples were collected from systematically-distributed transects spaced 10–15 km apart. The Trakya region is characterized by a climate similar to the Mediterranean climate, featuring hot-arid summers and mild-wet winters with slightly cooler temperature compared to the Amik plain. The Tekirdag province near the center of the region has a mean monthly temperature peaks at 24.8°C in August decreasing to a minimum monthly average of 5.2°C in January, with a mean annual temperature of 14.5°C. 39 Precipitation is lower in the summer compared to the winter; the average annual total precipitation is about 601 mm with the highest monthly average in October (82 mm) and lowest in August (16 mm). 39
Basic information related to the samples of the Trifolium species used in the study.
Near infrared spectral data
Each dried-ground Trifolium plant sample (∼10 g) was evenly distributed on a glass Petri dish (100 × 20 mm) to ensure homogeneous surface coverage and consistent optical path length. Reflectance spectra of the samples were acquired using a Fourier transform near infrared (FT-NIR) spectrometer (NIRFlex N-500, Büchi Labortechnik AG, Flawil, Switzerland) equipped with a rotating solid sample cell designed for diffuse reflectance measurements. Spectra were collected in the 4000–10,000 cm-1 (1000–2500 nm) range with a spectral resolution of 4 cm-1, yielding 1501 spectral variables per sample. Each measurement consisted of 32 co-added scans and spectral uniformity was ensured by acquiring three replicate measurements while manually rotating the sample holder between scans. All of the NIR spectroscopy measurements were collected at ambient laboratory conditions and averaged replicates were used to reduce instrumental noise and improve signal robustness.
NIR spectral data pretreatments
Prior to multivariate classification data analysis, the raw NIR spectra were subjected to various mathematical preprocessing to eliminate baseline drifts, particle size effects, and light scatter phenomena which are common challenges in reflectance-based NIR spectroscopy.18,19 Four pretreatment techniques were evaluated in the current study including Z-score standardization (Std), Savitzky-Golay first derivative (SG1D) and second derivative (SG2D), and multiplicative scatter correction (MSC) as recommended in recent NIR chemometric studies.18,19 The Z-score standardization transforms the reflectance variables so that they have a mean of zero and a standard deviation of one and the SG1D and SG2D preserves the structure of the signal while reducing noise while MSC reduces the effects of multiple scattering caused by factors such as reflection differences, sample density or measurement conditions.
42
The average reflectance data of the nine Trifolium species without pretreatment and the reflectance data with the MSC pretreatment are shown in Figure 1. It was observed that the raw NIR spectra exhibited pronounced baseline shifts, noise, and overlapping peaks, due to scattering effects and sample heterogeneity. The MSC pretreatment significantly reduced these problems and improved spectral consistency, highlighting chemically relevant signals enabling more accurate data analysis, in line with previous findings.42,43 The average NIR spectra for the nine clover species (top: original data; bottom: data after the application of MSC pretreatment).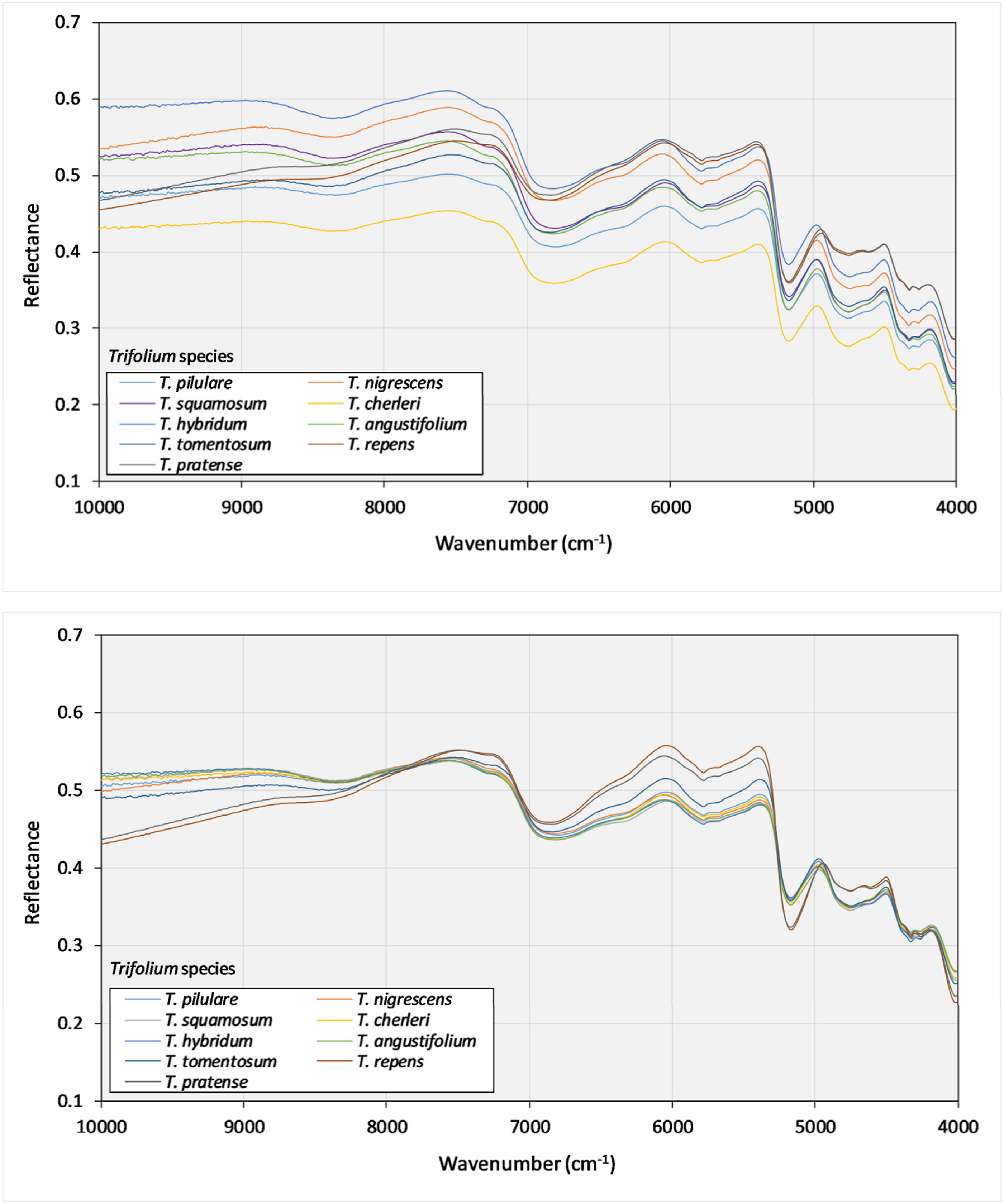
Machine learning (ML) classification algorithms
Six different ML models were used in the classification of the nine different Trifolium species in the present study including: logistic regression (LR), support vector machine (SVM), K-nearest neighbors (KNN), XGBoost (XGB), random forests (RF) and naive Bayes (NB). The LR algorithm uses a sigmoid function to estimate the probabilities with an assumption of linearity between the dependent and independent variables and works well when the dataset can be separated linearly but it can overfit high-dimensional datasets. 44 The SVM method is effective in high-dimensional spaces by constructing hyper-plane(s) and can behave differently based on selected mathematical functions (kernels); it does not perform well when the data set contains noise, such as overlapping target classes. 44 The KNN algorithm classifies new data points based on similarity measures computed from a simple majority vote of the K-nearest neighbors of each point while it is quite robust to noisy training data and its accuracy depends on the optimal number of K parameter. 44 The RF algorithm uses “parallel ensemble” of multiple decision tree classifiers on different data sub-samples and uses averages for the final result minimizing over-fitting problems and increasing accuracy. 44 The XGBoost method, like the RF algorithm, is an ensemble learning technique that generates a final model based on a “series” of individual models, typically decision trees. 44 The NB modelling, based on the Bayes’ probability theorem, can be used for both binary and multi-class categories but its performance may be affected by its strong assumptions on features’ independence. 44
Python programming language coupled with “scikit-learn” library was used in the analysis.
45
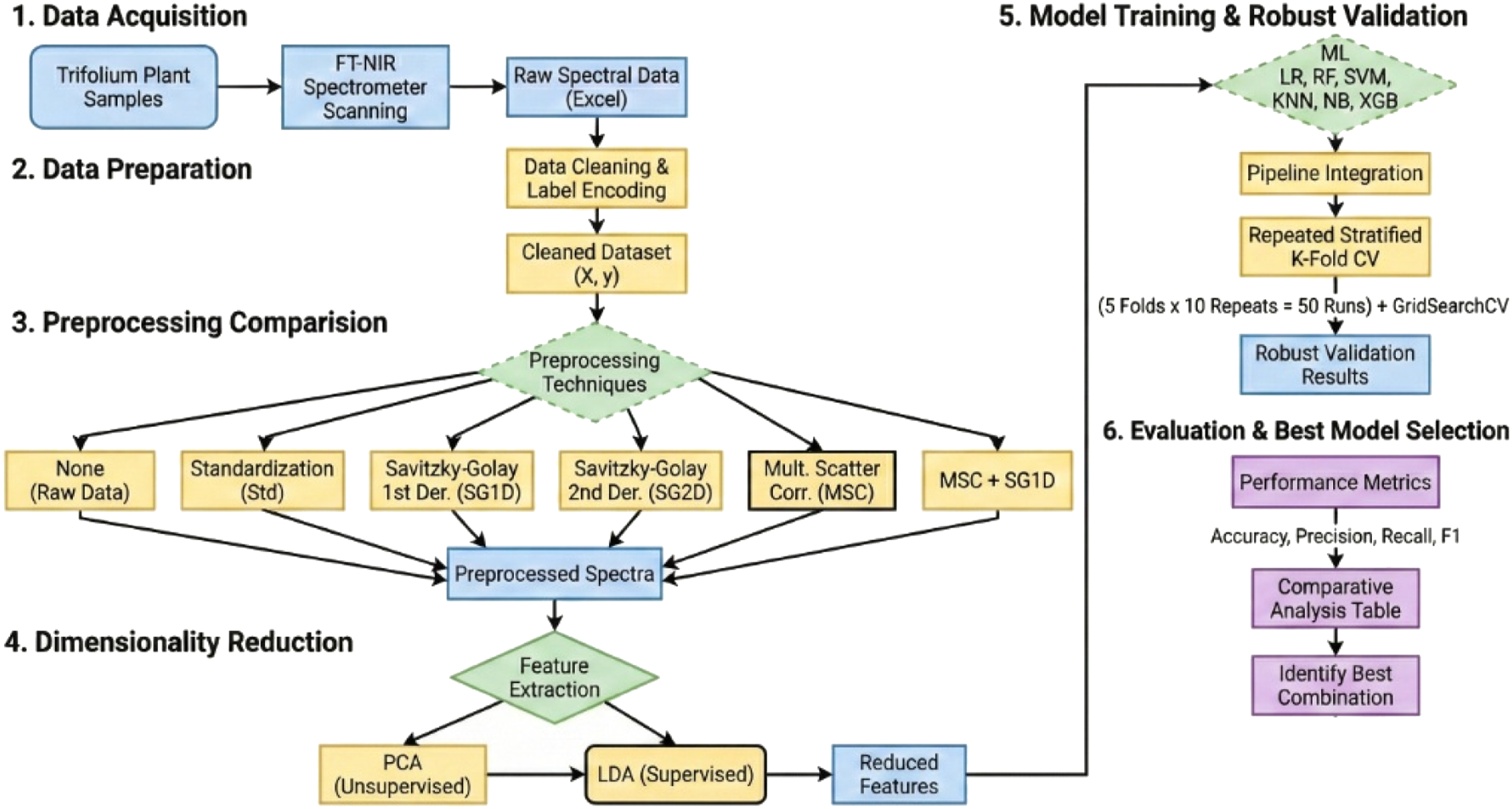
Hyperparameters of the ML models were optimized with GridSearchCV method and thus, model parameters most suitable for the data set were used instead of default parameters.45,46 Two different dimension reduction techniques, principal component analysis (PCA) and linear discriminant analysis (LDA) were also employed in the study. Classification process was carried out with three different systematic techniques and data sets by applying the ML algorithms: • The data with no dimensional reduction, • The data with dimensional reduction by using PCA, and • The data with dimensional reduction by using LDA.
Non-reduced dataset
Classification was performed directly by using the six ML algorithms for the nine Trifolium species in the dataset without applying dimensionality reduction. Four different data pre-processing methods (Std, SG1D, SG2D and MSC) were applied in the modeling process. Hyperparameter optimization was performed with the GridSearchCV method and the most appropriate parameter combination was used for each model. Model validation was performed with the K-fold cross validation (K = 5) method.
Dataset dimensionally-reduced by the PCA
PCA is a statistical method that models the data with fewer independent new components by eliminating the correlations between variables in high-volume data sets including the NIR spectroscopy data.
47
It minimizes the loss of information in the data and reduces the dimension of the data set while preserving the basic variance structure.
47
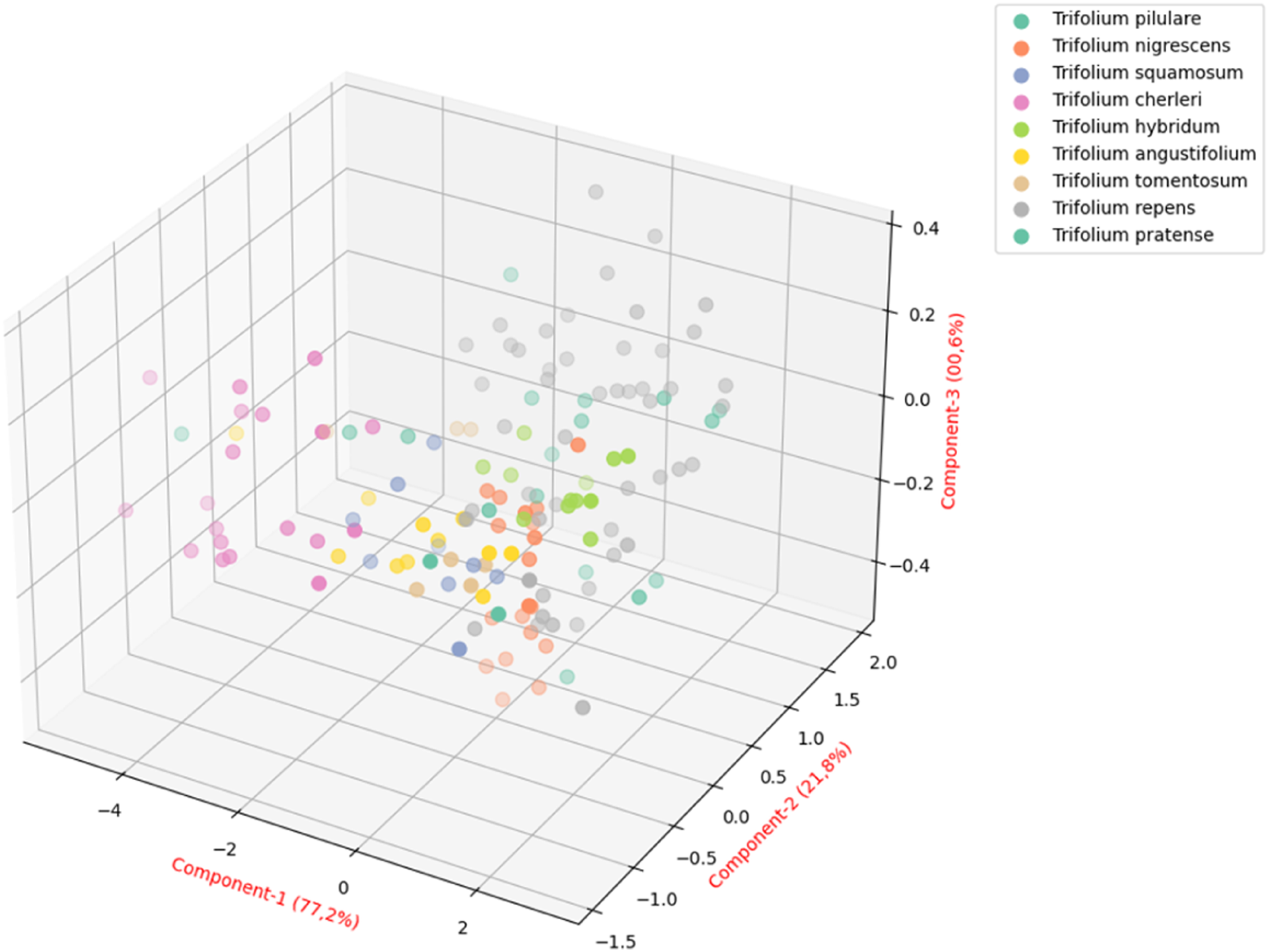
In the dimension reduction process by using the PCA in the current study, it was first determined how many components best explained the variance of the data set. According to the results, 99.9% of the total variance could be explained with five components (Figure 2). The PCA based classification models were systematically tested using 2, 3, and 4 PCs, sequentially, within the same cross-validation and pipeline structure. The classification process was applied within the “scikit-learn” pipeline structure using four data preprocessing methods (Std, SG1D, SG2D and MSC) and six ML algorithms. The GridSearchCV method was applied for the hyperparameter optimization and the K-fold cross validation (K = 5) method was applied for the model validation. It was determined that the models obtained with three PCs (n = 3) provided the best classification performance (based on the Accuracy and F1 score) and generalization ability. The distribution of the Trifolium samples with first three components is illustrated in Figure 3. The explained variance graph obtained from the PCA method. The distribution of the Trifolium species with the first three components obtained from the PCA.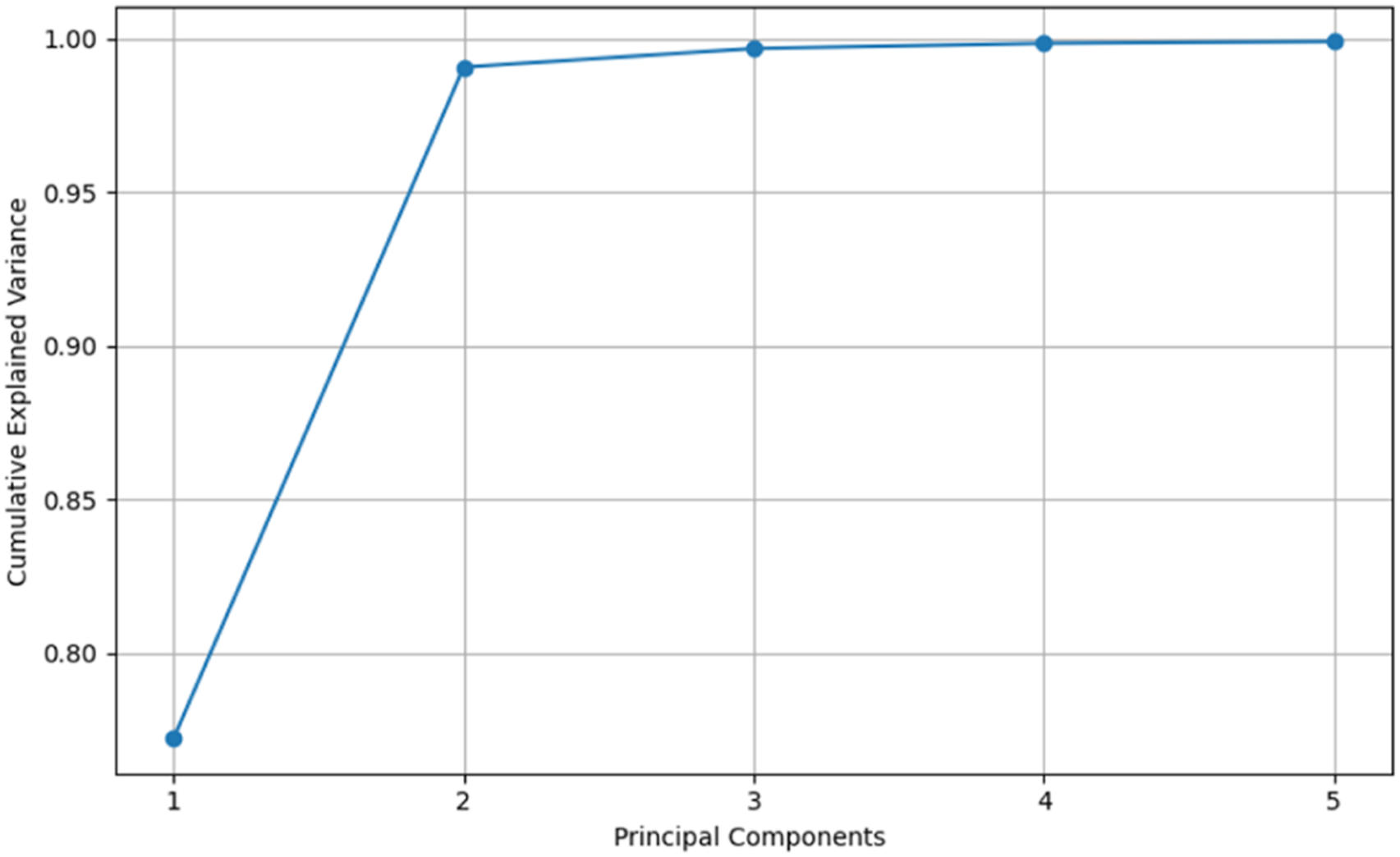
Dataset dimensionally-reduced by the LDA
LDA is a supervised statistical method that provides dimensionality reduction by maximizing the separation between classes. It projects the data according to classes so that the samples belonging to the same class are close and the different classes are far away. In this way, effective and discriminatory features are obtained to increase the classification accuracy.
48
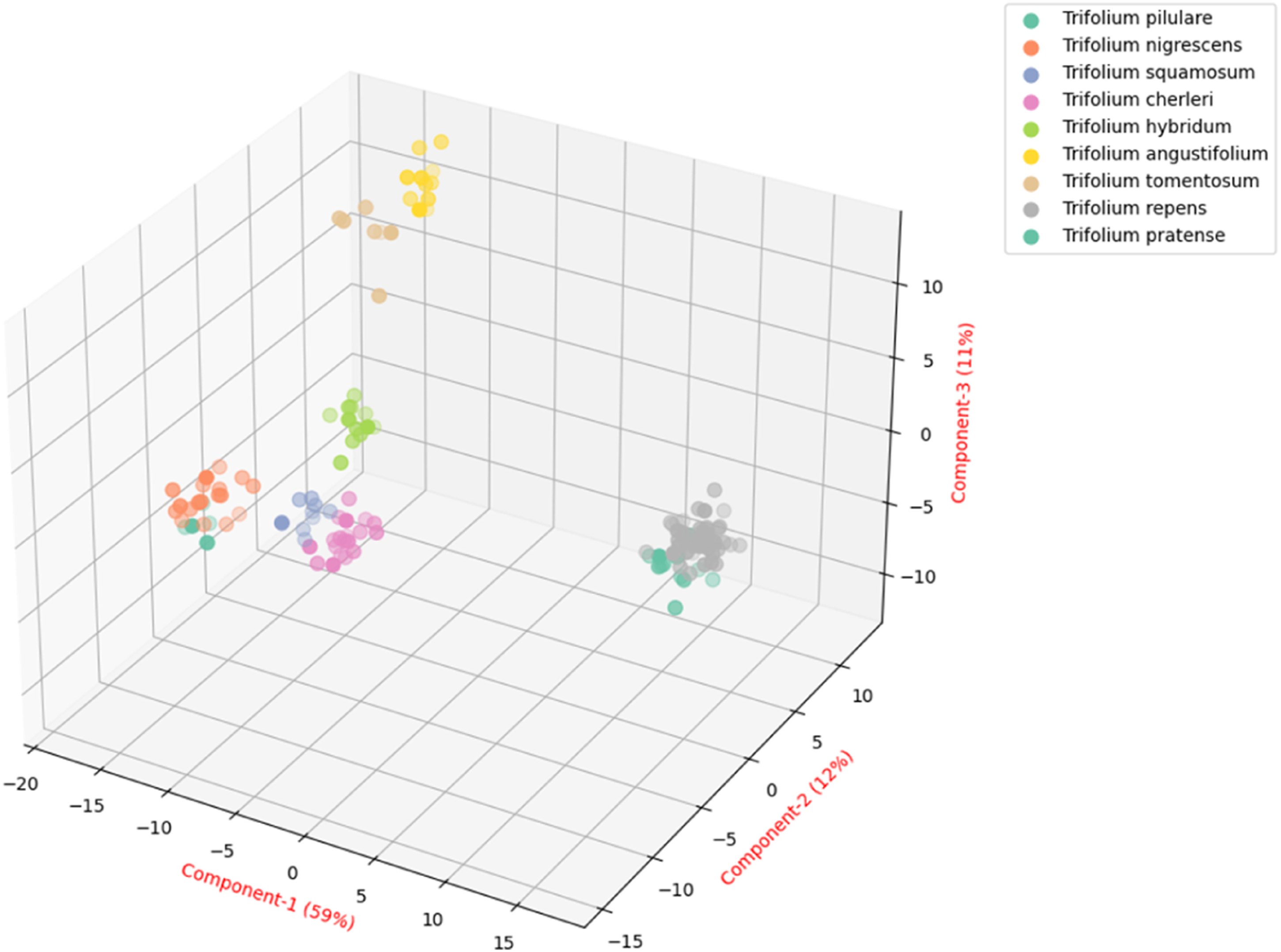
The first step in the LDA process is to determine the number of components that best represent the separation between the classes in the data set. It creates linear components that maximize the class separation. The LDA conducted in the present study revealed that a total of eight components (n = 8) could explain all (100%) of the variability in the data set (Figure 4). The distribution of the clover samples obtained by this method is shown in Figure 5. After determining the number of components (n = 8), the classification process was applied within the “scikit-learn” pipeline structure using the four data preprocessing methods (Std, SG1D, SG2D and MSC) and six ML algorithms. The GridSearchCV and K-fold cross validation (K = 5) was applied for the hyperparameter optimization for the model validation, respectively. The data analyses process employed in the present study is presented as a flow chart in Figure 6. The explained variance graph obtained from the LDA method. The distribution of the Trifolium species with the first three components obtained from the LDA. The flow chart depicting the summary of the data analysis process used in the present study.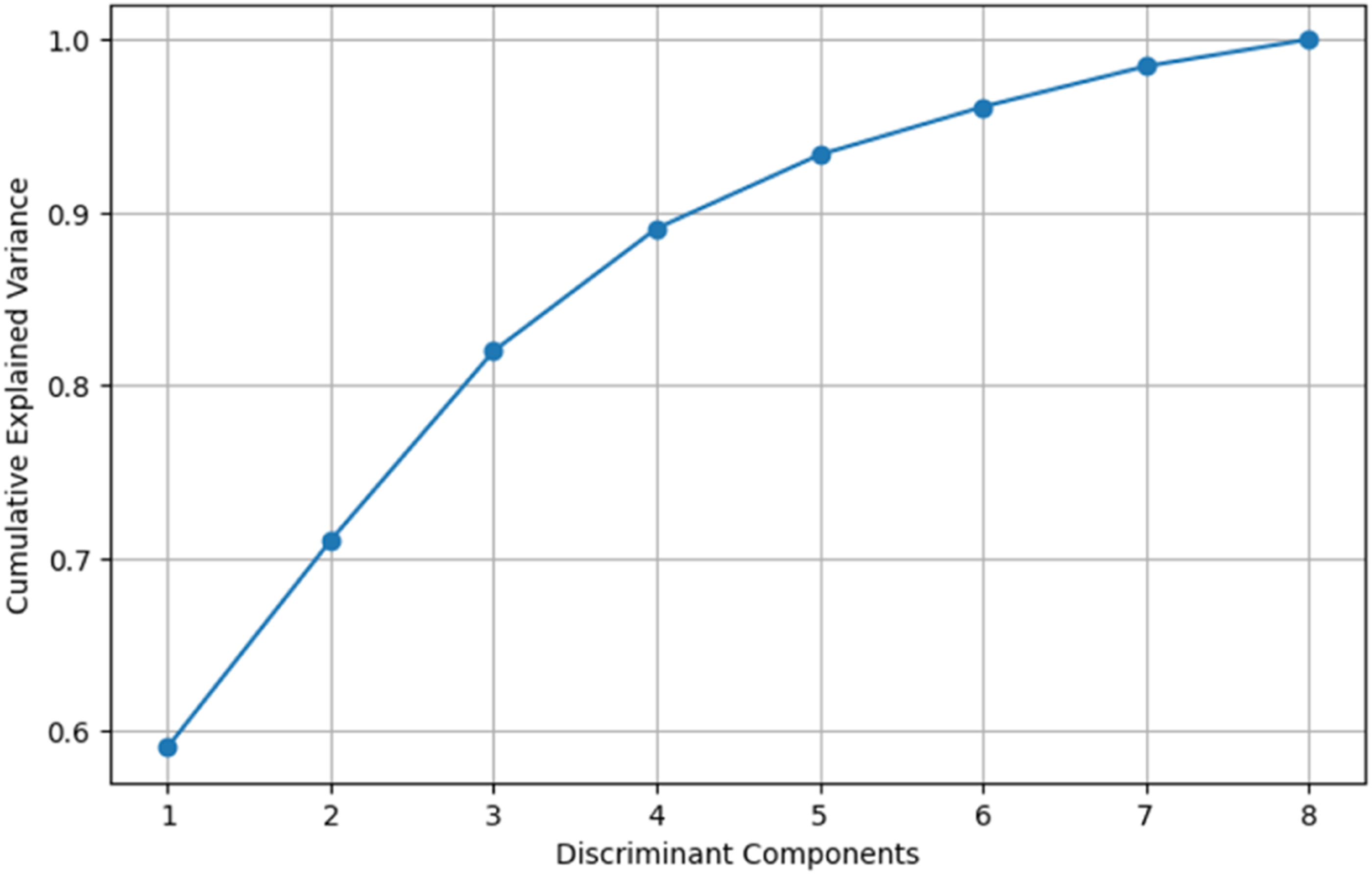
Model validation procedure
Due to the limited number of samples in each clover plant species in the data set (n = 5 to 50), the K-fold cross validation method (K = 5) was preferred in the model validation process in the current study. In this method, the data set is divided into K equal parts, one part is used as the test set in each step, while the remaining K-1 parts are used for model training. This process is repeated K times and the validation process is completed. Thus, the generalization ability of the model is tested more reliably. 49 The important point in a validation process is to prevent data leakage. In this context, the “pipeline” tool that organizes the modeling process of the “scikit-learn” library was used. 45 In this way, four preprocessing methods (Std, SG1D, SG2D and MSC), two dimensional data reduction methods (PCA and LDA) and six ML algorithms were applied to the training data selected in K-1 parts in each K step. The same process was applied to the test set only with the parameters learned in training stage. In this way, the test set remains unseen and thus the performance of the ML algorithms is measured more accurately. The data were analyzed by employing the RepeatedStratifiedKFold Python library. In this context, the results were tested with 50 different cycles (5 × 10 = 50) by setting K = 5, n_repeats = 10, and random state = 42. Using “random state” ensured that the same layer structure was maintained in all analyses, guaranteeing the randomization and repeatability of the results. Furthermore, the “stratified” approach ensured that the class distributions in each cross-validation layer were balanced to reflect the overall distribution of the dataset. Therefore, the results did not reflect random fluctuations resulting from different cross-validation assignments.
Results and discussion
The NIR reflectance data of the 146 plant samples belonging to nine different Trifolium species were classified by using four data pretreatment methods, two data reduction methods, and six ML algorithms. The classification accuracy results are presented in Table 2. Classification was carried out with three different systematic data sets: • The data with no dimensional reduction, • The data with dimensional reduction by using PCA, and • The data with dimensional reduction by using LDA. Classification results of nine Trifolium species by using four data pretreatment methods and six ML algorithms and two data dimensional reduction methods of PCA and LDA. *PCA: principal component analysis, LDA: linear discriminant analysis. *LR: logistic regression, RF: random forest, SVM: support vector machine, KNN: K-nearest neighbors, NB: naive Bayes, XGB: XGBoost. *Std: Z-score standardization, SG1D: Savitzky-Golay 1st derivative, SG2D: Savitzky-Golay 2nd derivative, MSC: multiplicative scatter correction. *Pr: Precision, Rc: Recall, F1s: F1-score, Acc: Accuracy (test). The numbers in bold format indicate the best model.
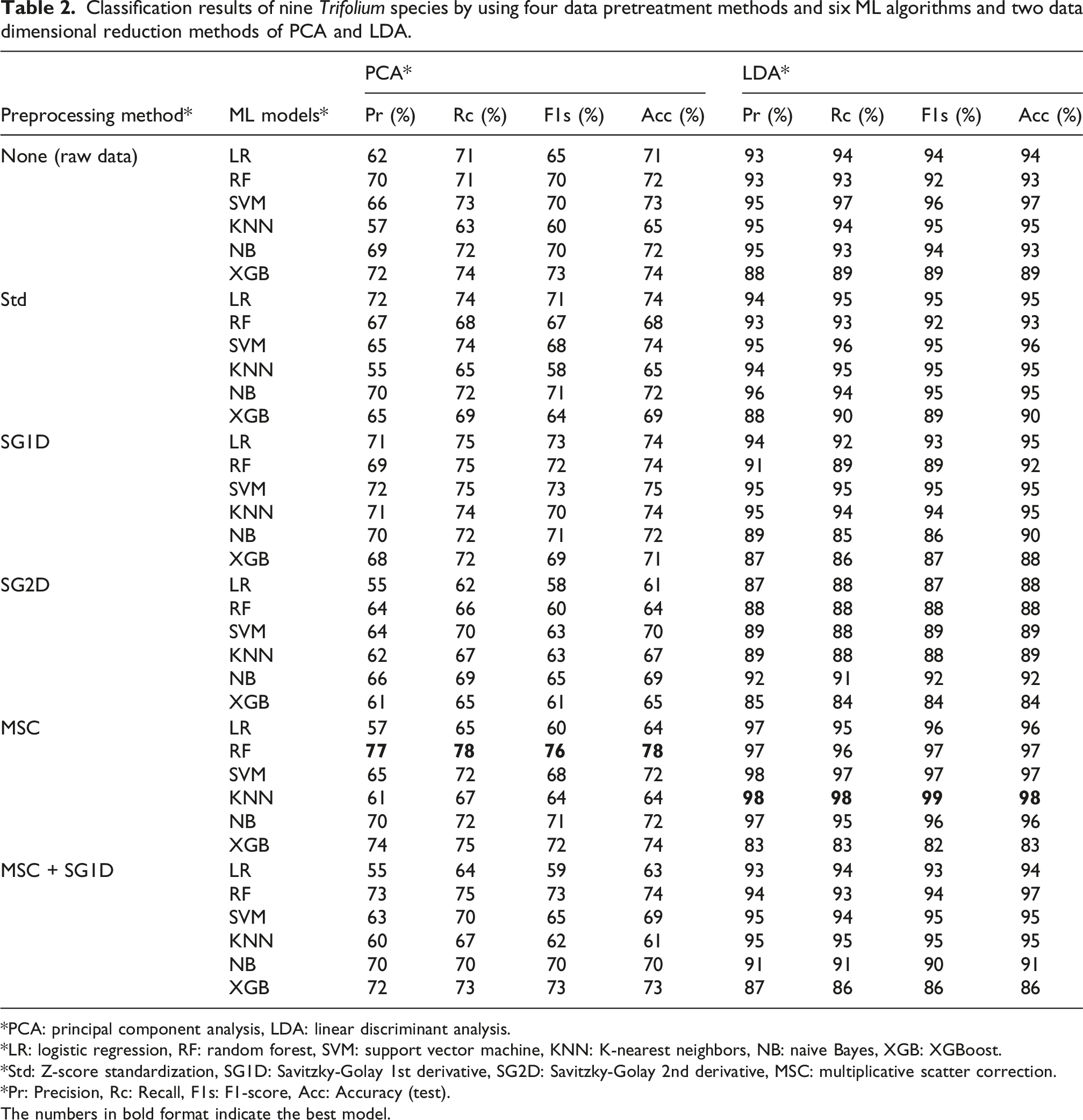
In the analysis of the data set without dimensional reduction, it was observed that the model performances were quite low (data not shown). The reason for this finding was that there was a tendency for overfitting during model training due to the large number of independent variables (n = 1501 wavenumbers) and the limited number of samples (n = 5 to 50; total: 146). 69 This case was clearly evident especially in XGB, KNN, RF and NB algorithms, which had a training success rate of 100%, but have a much lower test (validation) success rates as 65-65-60-49%, respectively. Regarding the LG and SVM models, their training success rates were found to be 78-79% with the test success rates of 74-73%, respectively which were considerably higher compared to those of the previous four models. These results showed that the overfitting effect was less in these two models. The main reason for this was that both models prevented overfitting by limiting the effect of a large number of independent variables with the L2 (Ridge) penalty term in the hyperparameter optimization process. These findings indicated the necessity of the use of dimensionality reduction methods to increase the overall performance of the model. Therefore, in the next stage of the analysis, the data was reduced dimensionally with two different methods (PCA and LDA) and then the classification process was repeated.
Regarding the data set whose dimension was reduced with the PCA method, it was observed that the most successful result (79%) was with the MSC preprocessing and RF model (Table 2). It was seen that the classification performances of the ML models with the data set on which dimension reduction was applied by the PCA increased in some models compared to the previous approach (without dimensional reduction), but still remained limited. The main reason for this was that the PCA was an unsupervised dimension reduction technique. 50
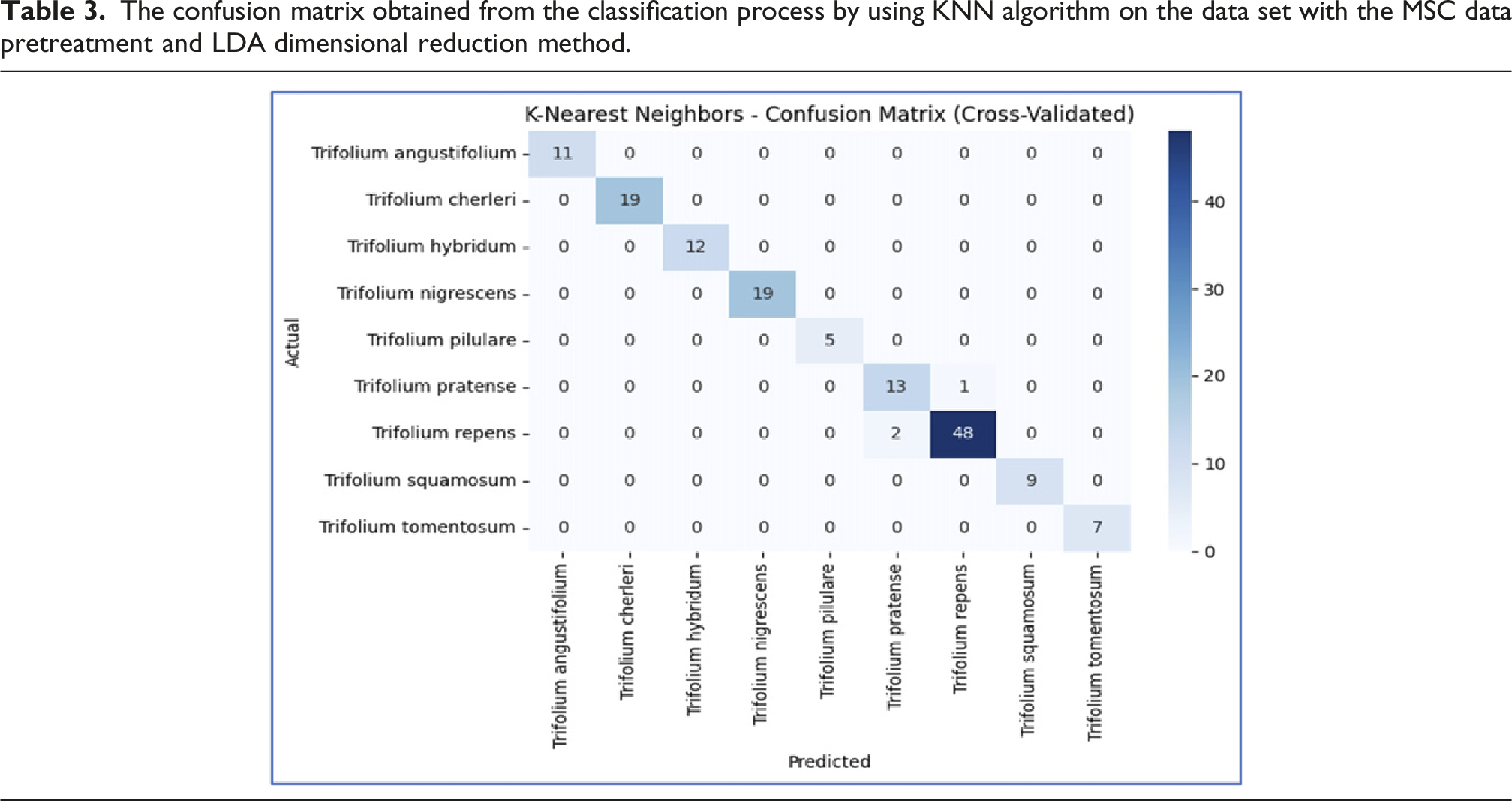
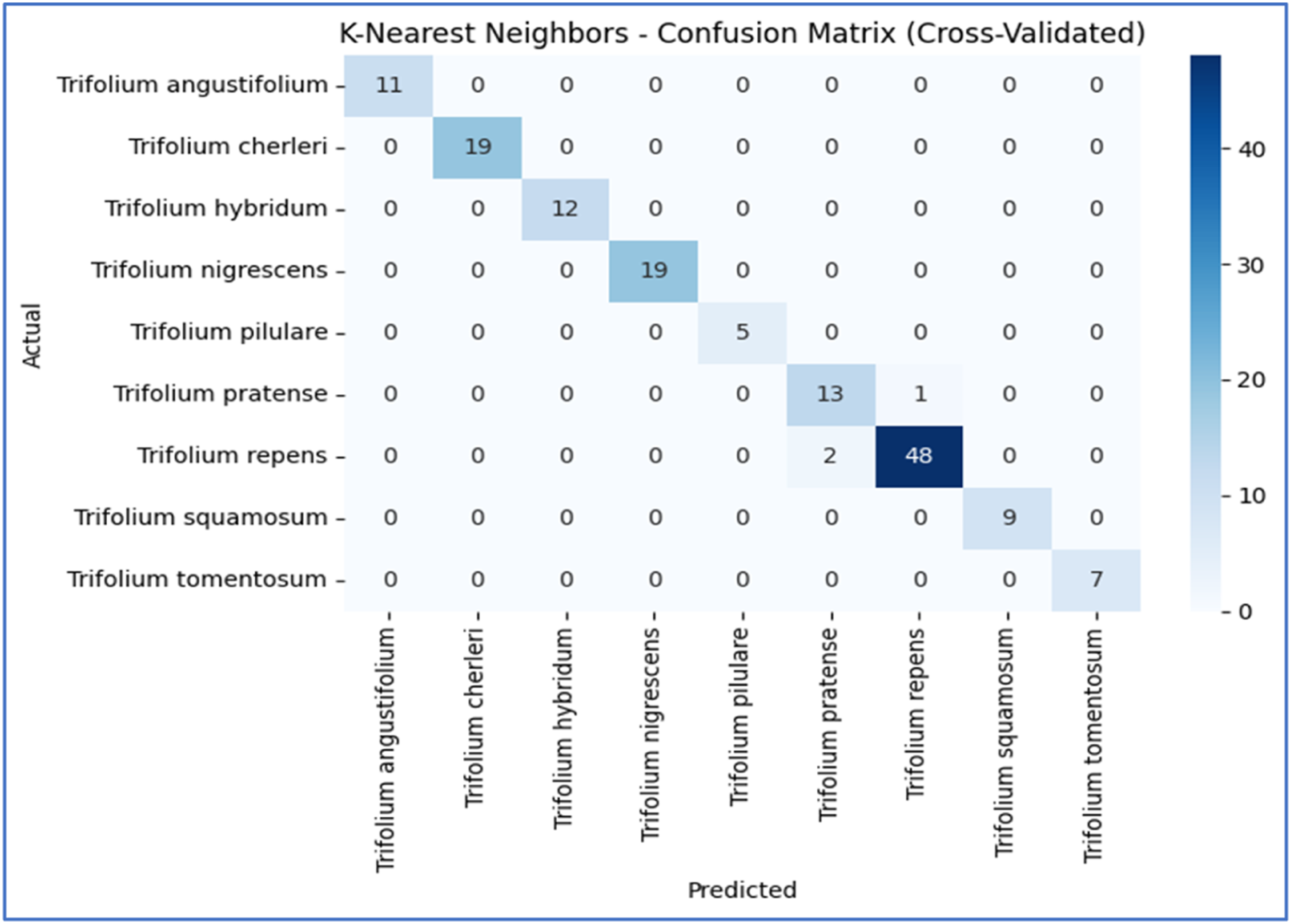
The confusion matrix obtained from the classification process by using KNN algorithm on the data set with the MSC data pretreatment and LDA dimensional reduction method.
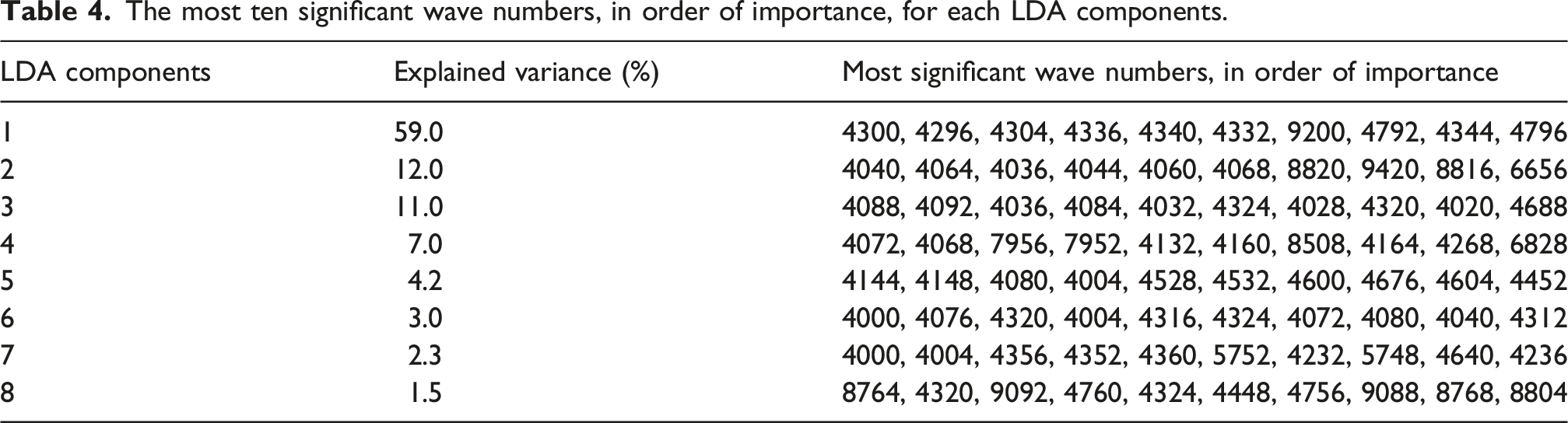
The most ten significant wave numbers, in order of importance, for each LDA components.
The NIR spectroscopy systems have been utilized to predict various chemical and nutritional contents of various clover species including protein, fiber, carbohydrate, organic matter, lipid, etc.65–67 However, no study has been found on the fast and precise categorization of the Trifolium species before to the best knowledge of the authors; thus, the current study was the first research work to examine the classification of these plants by using the NIR spectroscopy technique and ML data analysis methods. We combined the NIR spectroscopy technique with four data pretreatment methods (Std, SG1D, SG2D, and MSC), two data dimensional reduction methods (PCA and LDA) and six supervised ML algorithms to discriminate nine different wild Trifolium species. The results of this study indicated that NIR spectroscopy data set which was dimensionally-reduced by the LDA method coupled with MSC and KNN algorithm could be used to correctly classify the Trifolium species with 98% test accuracy (Table 2). Regarding the two data reduction methods employed in the present study (the PCA and LDA), it was observed that the LDA method gave better results compared to the PCA (Table 2). The LDA usually gives enhanced outcomes compared to the PCA in most of the ML processes involving classification since it can project the data in the direction where it maximizes the between-class variability while minimizing the within-class variability compared to the PCA which concentrates on the maximum retention of the data variances.68,70 Thus, the LDA showed better results compared to the PCA. Various studies have been previously carried out to classify other plant species by using digital measurement systems that provide rapid assessments including cannabis varieties (San Nicolas et al. 20 ), Eucalyptus tree species (Migacz et al. 21 ), Amaranthus species (Sohn et al. 22 ), almond tree varieties (Borraz-Martínez et al. 23 ), Miscanthus plants (Jin et al. 24 ), Chrysanthemum varieties (Chen et al. 25 ), and various taxonomic plant families (Dale et al. 26 ) with an accuracy ranging from 71 to 100%. It was observed from the review of the literature that the findings of the present study were in parallel with the results of these previous studies. In sum, the combination of the NIR spectroscopy system and ML algorithms is promising to effectively classify the wild Trifolium species. This result is important in terms of rapid and accurately identification of these plants that can be used by plant breeding industry to improve the commercial Trifolium species to obtain higher yield and better quality required for the sustainable animal production and to achieve non-agronomic benefits such as soil reclamation, urban greening, and beekeeping (pollen resources), etc.13–15
Conclusion
NIR reflectance data of 146 dried-ground Trifolium (clover) plant samples from nine different species were classified by using four different data pretreatment methods and six machine learning (ML) algorithms in this study. The data set was also dimensionally-reduced by two different methods, the PCA and LDA, to increase the classification accuracy. This is the first study that intended to rapidly classify clover species by using the NIR spectroscopy and ML techniques. The most successful classification result was obtained with the data set which was dimensionally-reduced by the LDA method with eight components coupled with multiplicative scatter correction (MSC) and K-nearest neighbors (KNN) algorithm with 98% test classification accuracy. The LR, RF and SVM classification algorithms also produced slightly lower but similar results compared to the KNN modeling. Additionally, the LDA-based dimensional reduction process significantly increased the classification accuracy compared to the PCA. The outcomes of this research shows that the NIR spectroscopy coupled with ML algorithms can be utilized to accurately and rapidly classify clover species which is a basis for a successful conservation and plant breeding process needed for a more sustainable farming of these plant species.
Footnotes
Acknowledgements
The clover plant samples originated from the Trakya region were collected within the framework of TUBITAK project (number: 119O950). The authors thank Dr Ibrahim Ertekin from the Department of Field Crops, Faculty of Agriculture, Hatay Mustafa Kemal University for his assistance in the plant sample collection.
Author contributions
Nafiz Celiktas: Supervision, Conceptualization, Methodology, Investigation, Project administration, Data collection, Data curation, Writing & editing; Muharrem Keskin: Data analysis, Validation, Writing the original draft & reviewing & editing; Yunus Emre Sekerli: Data analysis, Visualization, Writing & editing; Taner Gunduz: Data analysis, Visualization, Validation, Formal analysis, Software; Adnan Orak: Conceptualization, Funding acquisition, Project administration, Data collection, Data curation
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: We gratefully acknowledge the funding support for this study (Project number: 119O950) and article processing charge provided by the TUBITAK (The Scientific and Technological Research Council of Türkiye).
Declaration of conflicting interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Data Availability Statement
The datasets generated and analyzed in the current study along with the Python codes are available from the corresponding author on reasonable request.