
Abstract
Conjunctive analysis of case configurations (CACC) is a recent innovative approach developed by Miethe, Hart, and Regoeczi that bridges the gap between traditional quantitative- or qualitative-based studies approaches. CACC was initially designed for large sample application of exploratory and confirmative studies in criminology and criminal justice. However, as this special issue demonstrates, its application has since broadened. In this introductory article, we provide background material of conjunctive analysis by (a) presenting information on how to conduct a CACC study and (b) describing the conceptual and methodological framework surrounding this type of case comparative method. With this foundation, readers can better appreciate the distinct and unique contributions of the five pieces of CACC research making up this special issue.
Most empirical research within criminology can be classified as either quantitative- or qualitative-based studies. These two approaches vary widely in the analytic methods, assumptions about the proper focus of research endeavor, and the relative emphasis on cases and variables. To date, research in criminology and criminal justice uses one of the two approaches exclusively. On rarer occasions, research includes both approaches.
A recent innovative approach developed by Miethe, Hart, and Regoeczi (2008) suggests one need not chose one or the other, as it bridges the gap between these approaches: Conjunctive analysis of case configurations (CACC). The CACC method was initially designed for large sample application of exploratory and confirmative studies in criminology and criminal justice. However, as this special issue on CACC demonstrates, its application has since broadened.
The purpose of this introductory article is twofold. First, it provides a brief summary of the method of conjunctive analysis by providing background material on (a) how to conduct a CACC study and (b) the conceptual and methodological framework surrounding this type of case comparative method. Second, this introductory article seeks to assist the reader in recognizing the unique contributions of each article in this special issue. To that end, this introductory piece concludes with a brief summary of each articles found in this special issue.
Background
Ragin (2013) argues that quantitative analytic techniques can be described as variable-oriented in their approach to understanding causality. He suggests that the aim of this type of research is to study a small number of independent variables, across a large number of observations, in an attempt to identify the causal variables that explain as much variation as possible in the dependent variable. This is accomplished by constructing a generic representation of relationships between focal variables, based on patterns observed across many records.
Variable-oriented approaches used in criminological research often reflect an additive-linear view of causation. When statistically specified within the common “main effects” model, the influence of any particular variable is assumed to be constant across different contexts. This “main effect” model provides the most parsimonious account of the relationship between an independent and dependent variable, but it grossly misrepresents the causal complexity that often underlie the interrelationships among variables in criminological research (Miethe et al., 2008).
Unlike variable-oriented approaches, the goals of qualitative or case-oriented approaches are to (a) examine many aspects of an individual case or relatively few number of cases and (b) attempt to construct a representation of each individual from the interrelated aspects of these “sets” (Ragin, 2013). Within this framework, causation is viewed as a set of combinations or “conjuncturals” that are believed to combine in different and sometimes contradictory ways to generate the same outcome (Ragin, 2013).
Bridging the Gap: CACC
CACC bridges this gap between these traditional approaches in several ways. First, it focuses on situational contexts constructed using relevant variables. It focuses on neither exclusively, but rather benefits from both. Second, it is useful for both very large and very small sample sizes. Third, it evaluates the nature and magnitude of conjunctive relationships, which may best represent the complex social phenomena that are studied in criminology and criminal justice. Third, CACC offers the ability to identify main effects and contextual effects (i.e., whether a variable’s influence is stable or varies across contexts). Fourth, CACC focuses on the identification and analysis of situational contexts that have actually occurred within a particular research study and explores the nature and magnitude of the clustering of particular sets of conjunctive causes within them.
Conducting CACC
Similar to qualitative comparative analysis (QCA) methods developed and described by Ragin (1987), CACC can be summarized in a series of easy-to-follow steps:
CACC begins by constructing and populating a data matrix of case configurations (also referred to as situational contexts) of observations and variables from an existing data file that contains nominal- and/or ordinal-level data.
Case configurations contained in the matrix are then examined for patterns of situational clustering (i.e., are some combinations of case attributes far more common in the data than others?)
Sources of contextual variability within case configurations are then identified by noting the relative prevalence of different contexts that lead to particular case outcome.
Collectively, CACC shifts attention away from the net effects of predictor variables and the shared variance between independent and dependent variables. Instead, it focuses on uncovering unique causal recipes or pathways that are necessary or sufficient to produce an outcome of interest.
Constructing and Populating a CACC Data Matrix
The first step in CACC involves constructing a data matrix—also referred to as a truth table—that contains all combinations of the nominal- and ordinal-level variable attributes contained in an existing data file. This truth table is similar to multivariate contingency table that contains all extant combinations of the categories underlying the entire set of variables in the analysis.
Table 1 provides a visual illustration of a hypothetical data matrix, containing information about the focal outcome variable (Y) and three predictor variables (X1, X2, and X3), all of which are dichotomized as “0” or “1” in this example. Each row of the matrix—identified by their profile number in Table 1—reflects all unique combinations (i.e., case configurations or situational contexts) of predictor-variable attributes observed in the existing data file. For example, if three independent variables are included in a CACC and each has two attributes (i.e., “0” or “1”), then a total of eight profiles could be observed in the data matrix (i.e., 23) that is constructed.
Hypothetical CACC Data Matrix With Eight Case Profiles.
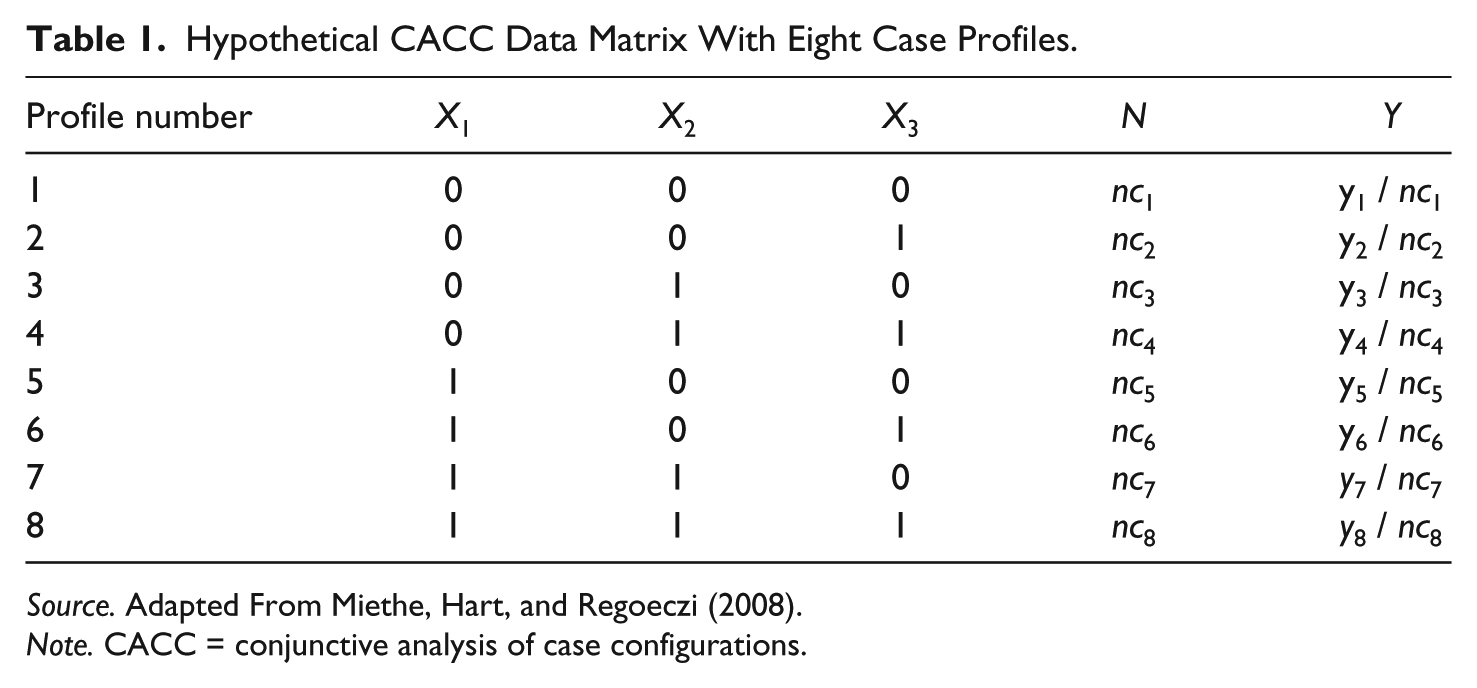
Source. Adapted From Miethe, Hart, and Regoeczi (2008).
Note. CACC = conjunctive analysis of case configurations.
It is important to note that once a data matrix is generated, it only contains case configurations that are actually observed in the data file. CACC focuses on what has actually occurred in the data versus what can theoretically occur (even if extremely unlikely). More importantly, if strong contextual relationships among variables in the truth table exist, case configurations will cluster among a substantially smaller number of empirically observed configurations than theoretically possible. By examining the pattern of these observed case configurations and their relative prevalence, CACC builds complex causal pathways from existing data, which reflect empirically observed patterns of causality (Miethe et al., 2008).
The process of constructing a truth table is easily accomplished through standard software used in social science research. Miethe et al. (2008) provide the programming command languages to conduct a conjunctive analysis in SPSS, STATA, and SAS computer packages. Here is an example of the SPSS syntax for conducting CACC for three independent variables (X1, X2, and X3) and a dependent variable (Y), using the Sort Cases and Aggregate functions:
SORT CASES BY X1(A) X2(A) X3(A).
AGGREGATE
/OUTFILE = ‘cacc_file’
/BREAK = X1 X2 X3
/Y_mean = MEAN(Y)
/N_Cases = N.
When the above syntax is run against an existing data file, the multiple observations or records it contains are aggregated into unique case configurations, in this case, in a single data matrix file called “cacc_file.”
Detecting Situational Clustering Among Case Configurations
The next step in CACC involves examining the distribution of case configurations contained in the data matrix. For example, the frequency of unique case configurations (see column N in Table 1) can be evaluated to determine whether observed likelihoods differ significantly from what is expected. In doing so, the presence or absence of situational clustering can be established. When situational clustering within a single data matrix is assessed, a chi-square goodness-of-fit test can be used to test the distribution of observations among case profiles. Differences in the overall rank orders of observed case configurations between two data matrix tables could also be tested, using Friedman’s two-way ANOVA (Hart & Miethe, 2015).
As an illustration of this analytic process, Hart and Miethe (2015) recently use CACC to determine the extent to which street robberies occurred within unique behavior settings that were defined by the presence or absence of (a) eight different activities nodes, (b) two types of land use areas (i.e., residential and nonresidential), and (c) 2 days of the week (i.e., weekends, weekdays). They began by constructing a data matrix that contained 1,024 observable behavior settings (i.e., unique combinations of the 10 dichotomous variable attributes [i.e., 210]). Next, they identified significant clustering within their data matrix, noting that all robbery incidents occurred within less than 15% of the case configurations that defined all theoretically observable microenvironments of street robbery locations.
To further understand patterns of situational clustering, dominant case configurations can be identified and analyzed. To do this, decision rules for defining dominant case configurations are established. For example, when CACC data matrix is based on moderately large samples (n = 100-1,000), dominant case configurations are often defined by a minimize frequency rule of five cases (Hart, 2014). However, the threshold for defining a dominant case configuration is typically 10 or more observations for larger samples (Hart, 2014). After applying these decision rules, uncommon case profiles are removed, leaving a data matrix with one row for each dominant case configuration that is empirically observed in the existing data file. Statements can then be made about the extent to which situational clustering is observed among these most common situational profiles.
In a recent study of Australian first-nation defendants and judicial decision making, for example, Lockwood, Hart, and Stewart (2015) found that 97% of all lower court case outcomes were explained by only 18% of all dominant case configurations (N ≥ 5). Similar patterns of situational clustering among dominant case configurations were also observed when the outcomes of high court cases were analyzed: 82% of all cases were explained by only 5% of dominant profiles. Collectively, these findings enabled the research team to demonstrate how judicial decisions can be influenced by a complex causal receipt of legal- and extra-legal factors.
Identifying Sources of Contextual Variability
Assessing the relative influence of individual factors contained within dominant case configurations is the final step of CACC. To do this, boxplots are commonly used to visually display the differences in the likelihoods of outcomes between matched pairs of case profiles (Tukey, 1977). For example, in Table 1, Profile Numbers 1 and 2, 3 and 4, 5 and 6, and 7 and 8 are all identical profiles, except for the values associated with one predictor variable (i.e., X3). The impact that a change in X3’s value has across matched profiles represents the “main effect” of X3 on the outcome variable Y. Once differences in the likelihood of outcome Y associated with the matched profiles are calculated, these four values (i.e., [y1 / nc1] − [y2 / nc2]; [y3 / nc3] − [y4 / nc4]; [y5 / nc5] − [y6 / nc6]; and [y7 / nc7] − [y8 / nc8]) can be illustrated as a boxplot. This provides a way to visually display the contextual variability of each predictor variable and can provide visual evidence of some of the limitations of traditional variable-oriented approaches to data analysis.
Figure 1 shows a series of boxplots illustrating the likelihood that defendants in state courts are sentenced to prison (Hart, Miethe, & Regoeczi, 2014). Outcomes are associated with seven matched predictors and reflect the magnitude of contextual variability in sentencing outcomes by the extent to which the boxplots are stretched over the x axis. Note that all factors analyzed are related to situations that both increase and decrease the likelihood of receiving a prison sentence, depending on the specific combination of contextual factors.
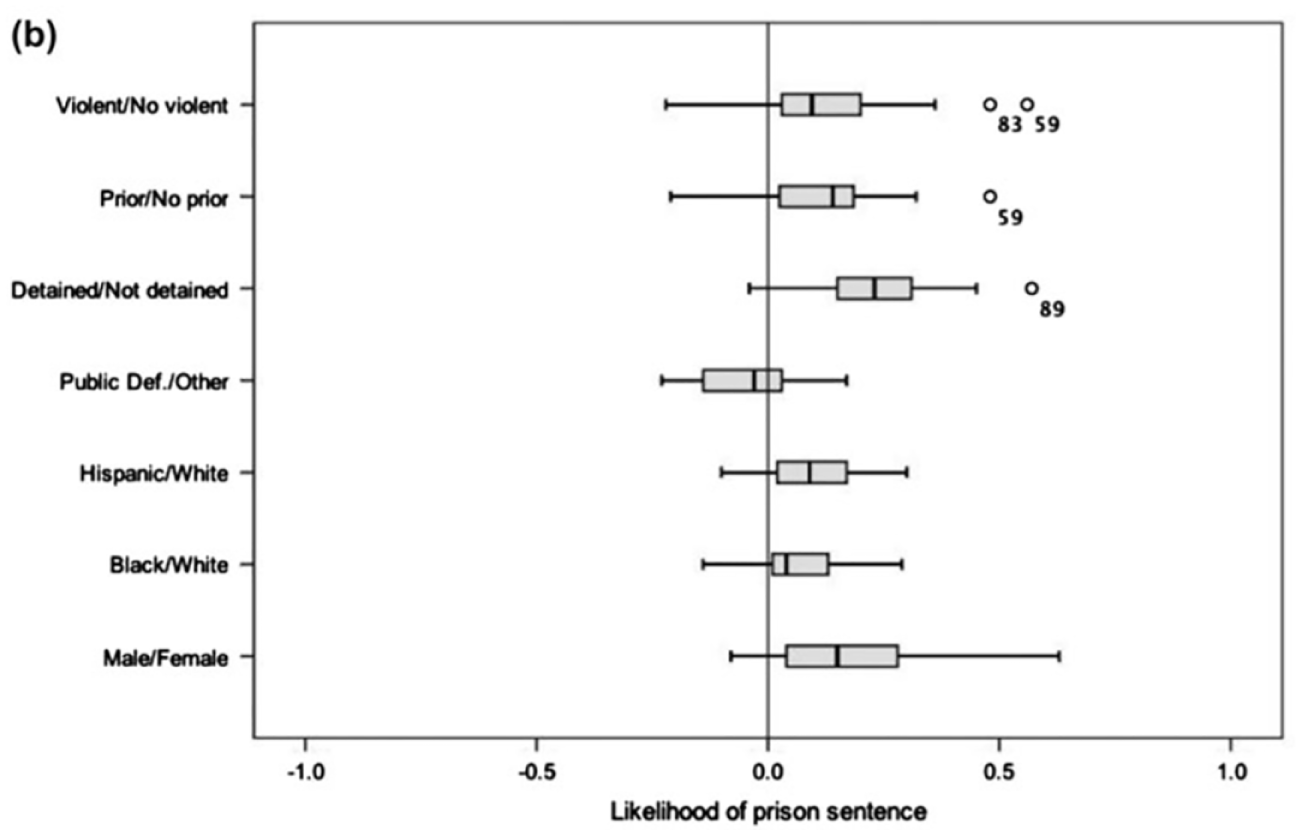
Hart, Miethe, and Regoeczi’s (2014) illustration of contextual variability of group differences in the likelihood of prison sentence in states’ mandatory sentencing guidelines.
Applications of CACC in the Current Issue
CACC is a very flexible tool that provides an alternative method of examining research questions within criminology and criminal justice. As a group, articles in this special issue illustrate various ways that conjunctive methods address these research questions and identify “causal” relations that are not easily discerned within the framework of traditional quantitative methods. A summary of each of these articles is presented below.
Drawve, Thomas, and Hart (2017) use CACC to conduct a reanalysis and extension of the research published by Drawve, Thomas, and Walker (2014). In the 2014 piece, Drawve et al. applied routine activity theory (RAT) to examine whether measures of offender motivation, target suitability, and guardianship influence the likelihood of an offender’s arrest in incidents of aggravated assault. Their findings offered “a moderate to strong level of support” for the use of RAT to account for variability in the likelihood of an offender’s arrest (Drawve et al., 2014, p. 450). The reanalysis begins with an estimation of the basic main-effect model used in the original article, followed by a series of conjunctive analyses to evaluate the contextual variability within each variable in the model. Findings demonstrate that the main effects identified are similar in their nature and magnitude to those obtained in the original study. However, using CACC revealed substantial context-specific effects that call into question the utility of the results from the previous main-effect modeling. This article offers an excellent example some limitations of traditional quantitative analysis, and the utility of CACC for future exploratory and confirmatory studies.
Caplan, Kennedy, and Barnum (2017) incorporate Risk Terrain Modeling (Caplan, Kennedy, & Miller, 2011) and conjunctive analysis to explore the dynamics among certain risk factors’ spatial influences and how they create unique behavior settings for criminogenic microenvironments, demonstrating how by focusing on microlevel environmental crime contexts, CACC can build on popular crime analysis techniques in ways that enable police to more efficiently target their resources and further enhance place-based approaches to policing that fundamentally address environmental features that produce ideal opportunities for crime.
Miethe, Troshynski, and Hart (2017) apply CACC to study macrolevel theories of punishment and the social conditions typically used to explain national imprisonment rates over place and time. Specifically, they use the formal logic standards of necessity and sufficiency to evaluate the empirical merits of these widely assumed causal relations. They also test these principles using both crisp set and fuzzy set representations of group membership within categories of predictor and outcome variables.
The research presented by Venger (2017) uses conjunctive methods in a cross-national study of the impact of a free press on measures of nations’ effective governance. It specifically addresses the important CACC principles of causal complexity and causal asymmetry and empirically demonstrates the multiple causal pathways in which nations’ level of media freedom and other social conditions influence their likelihood of protecting human rights, controlling corruption, and maintaining political stability.
And finally, Rennison and DeKeseredy (2017) shows how basic questions can be addressed using CACC for undeveloped research topics such as rural violence. Their use of CACC offers illustrates the nature of violence in rural American, and that it is frequently gendered. Findings indicate that the common or dominant situational contexts of rural violence are clustered into relatively few contexts. In fact, 25% of all rural violence is found among only 15 situational contexts of the 605 contexts found in the data. Results also reveal that males commit more violence and commit violence in a greater array of contexts. The problem of intimate violence is also evident as contexts revealed that every male perpetrated context of violence against women (except on) occurred between intimates. Finally, their work provided additional evidence for the notion of horizontal violence, especially when females commit the violence.
In conclusion, this special issue would not have been possible without the hard work of all individuals whose research appears in this special issue. Terry Miethe and Tim Hart were especially generous in regard to time, ideas, and comments on the articles found here. In fact, without their work, along with Wendy Regoeczi on CACC, this issue would not exist. Their extraordinary contributions to the topic and to this special issue explain the somewhat unorthodox author ordering of this introductory piece. Whereas Rennison may be the special editor of this issue, Miethe and Hart’s contributions were vital to its success. Others without whom the special issue would not be possible include the anonymous reviewers who provided very thoughtful critiques on the submitted manuscripts in a very timely fashion. We also wish to acknowledge those who submitted manuscripts that did not make it into this special issue. We worked with a strict page limit which meant some excellent research is not published here. Hopefully, these manuscripts will appear in another journal very soon.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.