
Abstract
In this paper, we propose a randomized point-block Schwarz preconditioner for a heterogeneous computing system consisting of both CPUs and GPUs. The preconditioner can be used to accelerate a Newton-Krylov method for solving nonlinear algebraic system of equations arising from the discretization of multi-component partial differential equations. Roughly speaking, GPUs consist of a large number of light-weighted processing cores for whom the synchronization cost is high. On such a processor, the traditional algorithms for the subdomain LU factorization and the triangular solves in the Schwarz method are no longer efficient since they require a large number of synchronizations for some or all of the processing cores. The key steps of the proposed method involve (1) a randomized iterative method for the LU factorization of a matrix; (2) a randomized iterative triangular solver for the upper and lower triangular systems of equations; (3) a symbolic inverse of point-block diagonal matrices whose size is determined by the Warp-size of the GPU. In the realization of these steps, we employ a warp-based thread partitioning strategy with an adjustable factor that controls the degree of parallelism for the randomized computation between threads. The target problems are matrices with block structures and the block size is small enough so that the inverses of diagonal blocks are obtained symbolically. Two representative applications covering the discretized incompressible Navier-Stokes and hyperelasticity equations verify the preconditioner’s performance in a Newton-Krylov solver, with a 12x + speedup on 8 GPUs over 8 CPU cores. The randomized method in the first case achieves 2x–5x gains over the deterministic cuSPARSE baseline and performs nearly comparable to the baseline in the second case. Cerebral artery blood flow simulation proves its superior scalability to the deterministic GPU implementation, attaining up to 45% parallel efficiency on 64 GPUs.
Keywords
1. Introduction
Architectural characteristics comparisons between a typical multi-core CPU and a typical GPU.

A CPU usually integrates up to hundreds of strong logic controlled cores offering limited parallelism, and supports complex thread manipulations with higher overhead on creation and scheduling. An accelerator is equipped with thousands of simple, light-weighted cores providing massive parallelism, and capable of switching concurrent threads with nearly negligible overhead. On a CPU, fine-grained, flexible, and system-wide thread synchronization can be readily achieved. In contrast, efficient synchronization operations are generally constrained to within local thread groups. A CPU has sophisticated branch prediction mechanism to minimize performance penalty for branches within a thread. But branches lead to significant performance penalties when a group of threads take different paths on an accelerator.
The Schwarz-type preconditioner, such as the additive Schwarz (AS) preconditioner studied by Cai and Sarkis (1999), contains the coarse-level parallelism fitting the CPU architecture naturally when a problem is divided into sub-problems by the domain decomposition step. However, the two building blocks, that is, computing the incomplete LU (ILU) factorization and solving the subsequent triangular systems fail to offer effective, fine-level parallelism if an accelerator is employed to solve a sub-problem. Specifically, performing one ILU factorization requires computing all the entries of the upper and lower factors in their sparsity patterns, but they must follow sequential elimination steps because the calculation of the current entry depends directly on the completion of calculations for entries at previous rows or columns. This creates a critical path of dependencies throughout the matrix, and thus the level of available parallelism is constrained by the elimination path. Sparse matrices with particular sparsity may have relatively weak data dependencies, but it still needs expensive global synchronizations to serialize different data levels containing parallelism. Similarly, in a substitution algorithm for solving triangular systems, each unknown component of the solution vector can only be calculated after all its predecessors are known. Also, parallel methods for sparse matrices are forced to synchronize while following the dependency path. Point-block matrices, which refer to sparsely partitioned matrices structured into small, fixed-size submatrices corresponding to individual mesh points or degrees of freedom in numerical simulations, arise naturally from multiphysics applications following the computational paradigm of performing operations in blocks. Such a structure enables centralized data management and computation, thereby offering considerable potential to narrow down the scope of synchronization.
For sparse kernels, both ILU factorization and triangular solves involve operating over non-zero elements by rows or columns, and the dispersion on row or column lengths makes the threads processing different rows (columns) diverge while checking the effective memory ranges. Furthermore, irregular, scattered addressing for sparse operations cause memory access divergence, impacting memory coalescing. Sparse matrices operated in scalar elements lead to more possibilities of branching because of the irregularity of non-zeros. Point-block matrices, in contrast, have locally dense blocks, and could reduce the possibility of branching because the computation pattern within each dense block is identical and make the threads take the same execution path. Moreover, dense blocks provide high data locality that makes the memory accessing coalesced.
Motivated by the main challenges on algorithm migrating for the Schwarz-type preconditioner from CPUs to accelerators, in this paper, we study a point-block randomized RAS (PB-R-RAS) preconditioner for multiphysics problems on multiple GPUs. We consider the randomization in each ILU-based subdomain problem with local, limited synchronizations. We take full advantage of the locally dense and globally sparse matrix properties to perform all computation in blocks, such as block-block, block-vector and block inversion with highly consistent instruction flows. Also, instead of running the randomized method using a small number of cores by Kashi and Nadarajah (2021), we extend the level of parallelism to thousands of cores on popular accelerators. In summary, the main contributions of this paper are: (1) Proposing a specialized point-block RAS preconditioner tailored for GPU architectures, which incorporates randomized characteristics within the domain decomposition framework, specifically targeting multiphysics problems with complex geometric domains discretized by unstructured meshes. (2) Developing a thread partition strategy that is well-suited to point-block structures and achieves a favorable balance between parallelism and convergence by leveraging abstracted software and hardware parameters of the GPU architecture. (3) Conducting thorough experimental comparisons and performance analyses using real-world applications, including evaluations against the state-of-art deterministic GPU baseline, scalability investigations, and parameter selection studies.
The remainder of this paper is structured as follows. Section 2 summarizes some related work about parallel preconditioning. Section 3 provides a brief overview of the RAS preconditioner in the point-block format. A PB-R-RAS preconditioner is proposed and its application in both linear and nonlinear problems are discussed in Section 4. Section 5 introduces some thread partitioning strategies and tuning techniques for multiple GPU implementations. Some numerical experiments for a fluid dynamics problem and a solid mechanics problem as well as the strong scalability are presented in Section 6. A summary is given in Section 7.
2. Related works
The parallelization strategies for the two building blocks have attracted great attention on several accelerator architectures. For a sparse matrix, level-scheduling schemes studied by Li and Saad (2003), Saad (2013), Pakzad et al. (1997), Naumov (2011), Kabir et al. (2015), and Park et al. (2014), exploit the sparsity of the matrix to group the computation into different levels, then the computations in each level are carried out concurrently while synchronizations are required only between levels. The NVIDIA’s cuSPARSE (2023) library has an efficient GPU implementation of the level-schemes. One drawback of this approach is that the pre-processing step that analyzes the sparsity to extract the desired parallelism is sometime quite expensive. Some pre-processing-free methods are proposed by Liu et al. (2016, 2017) for the sparse matrix expressed in the Compressed Sparse Column (CSC) format. Some inexact approaches, investigated by Anzt et al. (2012, 2015, 2016), Chow and Patel (2015), Chow et al. (2015, 2018), Tsai et al. (2022), Kashi and Nadarajah (2021), and Ma and Cai (2021), are proposed to seek more parallelism for computing ILU and solving triangular systems by sacrificing some exactness in the construction of the ILU-based preconditioners. Some fine-grained, iterative methods for the ILU factorizaiton on Intel MIC and GPU architecture are developed by Chow and Patel (2015) and Chow et al. (2015), and the methods are further investigated by Kashi and Nadarajah (2021) and Ma and Cai (2021) for point-block matrices.
For triangular systems, both synchronous and asynchronous iterative schemes without requiring forward and backward substitutions are developed by Anzt et al. (2015, 2016, 2012) and Chow et al. (2018), and they are quite effective preconditioners with higher parallelism, and are faster than traditional methods in terms of the compute time. One prominent feature in these methods is that the data dependency issue is “solved” by not considering the “read-after-write” criterion that is needed in all traditional approaches. In fact, the asynchronous technique makes the outputs runtime-determined, and this often leads to different results for different runs. Other types of parallel preconditioning including sparse approximate inverse (SAI), incomplete sparse approximate inverse (ISAI) can be found in Kashi and Nadarajah (2020), Kolotilina and Yeremin (1993), Duin (1999), Bertaccini and Filippone (2016), and Anzt et al. (2018). Other randomized solvers, such as asynchronous Schwarz method implemented by Nayak et al. (2020), Chaouqui et al. (2023), and Glusa et al. (2020), and GMRES method by Balabanov and Grigori (2022), are also presented.
Existing works on these two topics are either designed for non-GPU platforms with limited parallelism or mainly target general linear systems based on scalar matrices. This motivates us to direct our preconditioning investigations toward point-block structured matrices, as well as domain decomposition based algorithms on distributed multiple GPUs. The point-block format for sparse matrices is usually employed in problems from the discretization of multiphysics problems in which several variables are associated with a single mesh point. The discussions and applications related to point-block formatted matrices can be accessed in Kashi and Nadarajah (2021), Kashi and Nadarajah (2020), Ma and Cai (2021), and Balay et al. (2025). Different from general block matrices with an arbitrary block size, the block size in a point-block matrix equals to the total number of field variables assoicated with the physical problems. The block size is assumed to be very small (2, 3, 4, etc.), and all blocks are assumed to be dense. More importantly, all diagonal blocks are assumed to be non-singular, and their inverses are explicitly computed.
3. Standard RAS preconditioner for point-block matrices
We consider a linear system of algebraic equations arising from the implicit discretization of a multi-component partial differential equation defined on a computational domain Ω covered by a regular finite element mesh with N mesh points. To simplify the notations, in the rest of the paper, we also denote by Ω as the mesh, or the collection of mesh points. We assume that there are s variables associated with each mesh point, the system takes the form (1) the number of unknowns for all mesh points are the same (i.e., s), even though the algorithm to be discussed in the paper can be extended easily to the cases with different point-block sizes, but the software implementation can be different. (2) the block size s is so small that the inverse of the diagonal blocks can be written down explicitly using the determinant method (noted that the determinant method is practical only for very small matrices). (3) all operations of the algorithms are based on the matrix-matrix and matrix-vector operations of s × s matrices and s × 1 vectors.
To solve (1) on a distributed computing system, Ω is partitioned into K nonoverlapping subdomains 
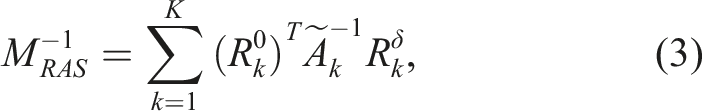
Using (3) as a right-preconditioner we have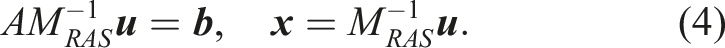
When (4) is solved by a Krylov subspace method, in each iteration, we need to multiply 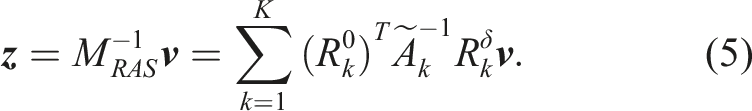
In order to obtain 
Once
To apply the preconditioner defined in (5) in a Krylov subspace solver, (6) is the most time consuming part. To simplify the discussion, we drop the sub- and super-scripts in (6). The traditional LU (or ILU) algorithm for approximately solving (6) consists of two steps. In the first step, a point-block ILU factorization is

The traditional factorization for solving (7) and the standard backward and forward substitution algorithms for (8) are inherently sequential but the RAS preconditioner fits the distributed CPU architecture very well because the level of parallelism between subdomains is sufficient, and further parallelization within a subdomain is not necessary. However, on a heterogeneous architecture with CPU + GPU for example, one needs to introduce another level of parallelism if the subdomain problem is solved on a GPU. In this paper, we propose a randomized algorithm with high parallelism for solving (6) on a GPU, without using the traditional factorization method for (7), and the backward and forward substitutions for (8).
4. Randomized RAS preconditioner
Parameters in hardware, threading and algorithmic levels.
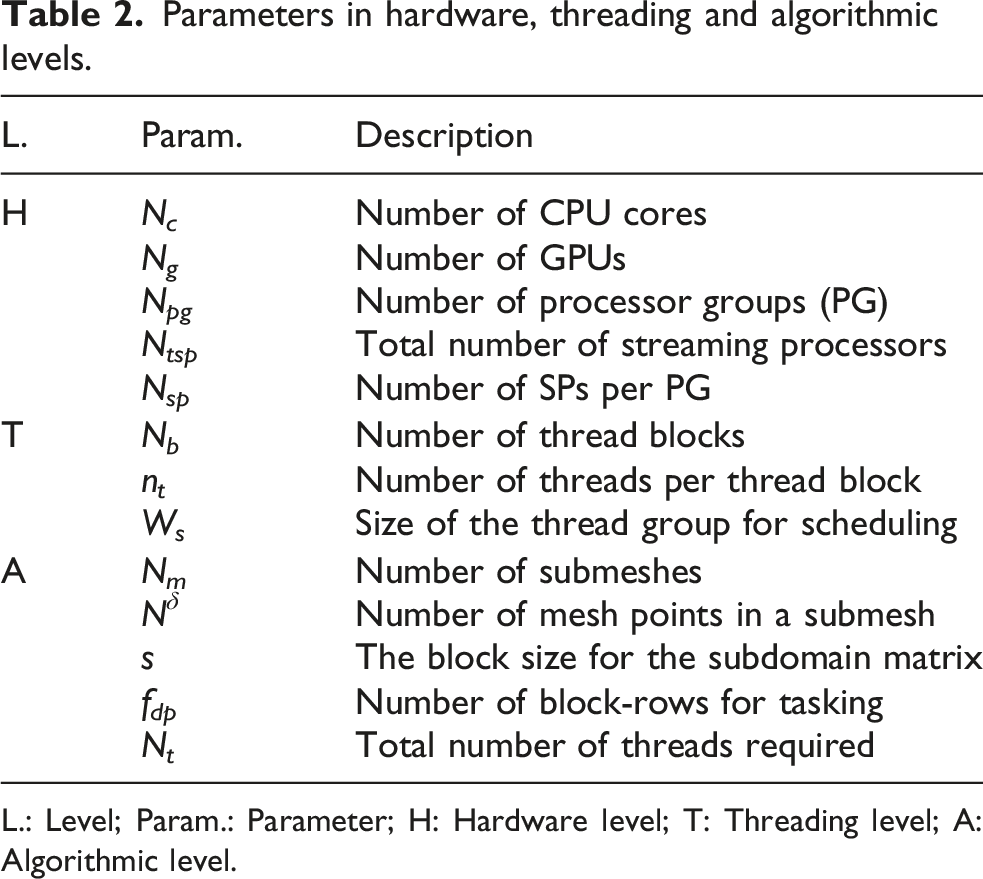
L.: Level; Param.: Parameter; H: Hardware level; T: Threading level; A: Algorithmic level.
A typical heterogeneous system comprises multiple computing nodes, each equipped with several multi-core CPUs and GPUs. We study the problem based on the MPI (Message Passing Interface) parallel environment (Guo et al., 2025; OpenMPI, 2025), and employ the standard one-to-one mapping strategy. That is a CPU core taking one MPI process interacts with one GPU as shown in Figure 1. One-to-one mapping strategy between the CPU cores and GPUs.
We assume the problem is defined on a conforming finite element mesh that is partitioned into overlapping submeshes, and each subproblem associated with the submesh is assigned to a GPU as indicated by the red arrows from Figure 2(a)–(c). Then we have N
m
= N
c
= N
g
, where N
c
and N
g
are the total number of CPU cores and GPUs for this problem and they are exactly the same as the number of submeshes, N
m
. The hardware parallelism offered by a GPU is represented by the total number of streaming processors (SP), denoted as N
tsp
. A typical GPU manages SPs in groups (for example, the group is called Streaming Multiprocessor in NVIDIA’s CUDA (2023) and Computing Unit in AMD ROCm (2024) and satisfies N
tsp
= N
pg
× N
sp
, where N
pg
is the number of processor groups (PG), and N
sp
is the number of SPs in a PG. An overview of the flow path for solving multiphysics problems on GPUs.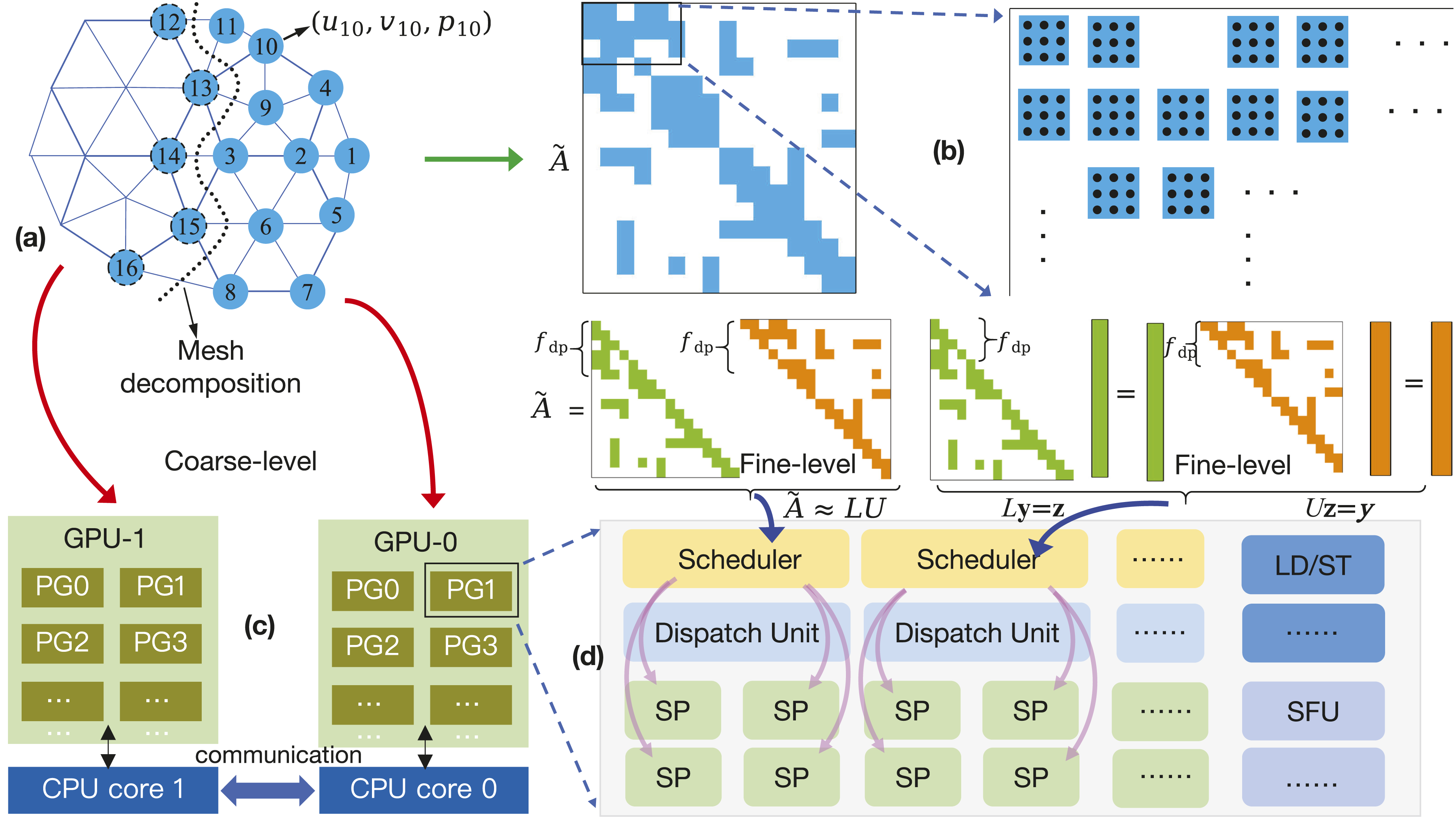
The calculations on a subproblem for the preconditioner are reflected by operating the N δ × N δ point-block subdomain matrix shown in Figure 2(b). The matrix arising from the multiphysics application is globally sparse with locally dense blocks. The block size, denoted s, is determined by the number of field variables associated with each mesh point. For example, in two-dimensional Navier-Stokes equations, each mesh point has two velocity components and one pressure component to solve, and the block size is 3. As shown in Figure 2(b) and (d), the two main tasks in the subdomain, ILU factorization and triangular solves, require fine-grained, thread-level algorithms to fit the massive parallelism on the accelerator.
At the algorithmic level, the main concern of designing the parallel algorithms is to determine the computing workload for a single thread or a group of cooperative threads. In this paper, our basic strategy is to map f dp block-rows of computing tasks in the ILU factorization and triangular solves to W s threads, where W s is the basic unit of scheduling and execution on a GPU. Thus, for a given point-block matrix of size N δ × N δ , the total number of threads required is N t = ⌈N δ /f dp ⌉ × W s . Once N t is determined, the algorithm can be realized by specifying how the required threads are managed in thread blocks using N b and n t , where n t is the number of threads in a thread block, N b is the number of thread blocks and n t × N b ≥ N t .
We note that s directly affects the workload that W s threads take. To avoid extreme cases, we assume s meet two criteria. First, the block size allows the inversion of the dense block to be hard-coded. Second, s2 ≤ W s , that is, the number of elements in a block is less than or equal to the basic unit of scheduling and execution. This ensures that at least one complete block is handled by W s cooperative threads.
4.1. Point-block randomized ILU
We use the asynchronously iterative method proposed in our previous work (Ma and Cai, 2021) for the point-block ILU on GPUs, which is summarized in Algorithm 1. In this method, all the entries of L and U are explicitly expressed as the constraint equations, and they are updated asynchronously in an iterative process by offering proper initial guesses. One notable feature of this method is that no attention is paid whether the values Li,j or Ui,j rely on are ready or not when Li,j or Ui,j are being updated, and these values are totally determined in runtime. In Algorithm 1, we use the superscript “curr” to describe the values that are only determined at the time when they are required by others. To some extent, it makes the output of the algorithm, that is, L and U factors, randomized or nondeterministic, and therefore we name Algorithm 1 point-block randomized ILU (PB-R-ILU).

Data dependency and parallelism are contradictory, and for the ILU with strong data dependency, the more parallelism we seek, the lower quality of the factors we may have. We upgrade the algorithm by introducing a factor f dp in Algorithm 1 to control the degree of parallelism. More specifically, the block-row indices set S idx (|S idx | = N δ ) are grouped into ⌈N δ /f dp ⌉ subsets, and the updates of the block-rows whose indices are in the same subset will be performed sequentially in the same computing unit. The essence of this consideration is to add some degrees of sequentiality to seek a maximum balance between data dependency and parallelism. Also, it will makes the algorithm adaptable on different generations of GPU architectures that offer a large range of parallelism.
4.2. Point-block randomized triangular solves
Once the lower and upper factors are obtained, similarly, we employ an iterative approach for (8) to avoid performing highly sequential operations in the forward and backward substitutions. By splitting L and U, we write (8) as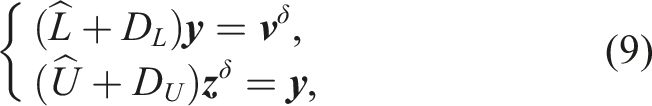
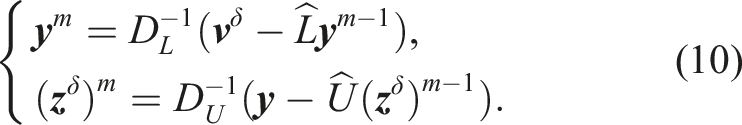

When the algorithm is realized on GPUs, the major operations are block-diagonal inverse and the block SpMV(Sparse Matrix-Vector Multiplication). We will discuss the implementation issues in the next section. The details are shown in Algorithm 2.
Although the SpMV in Algorithm 2 can offer enough parallelism on GPUs, it may not be superior in convergence because all updated components in 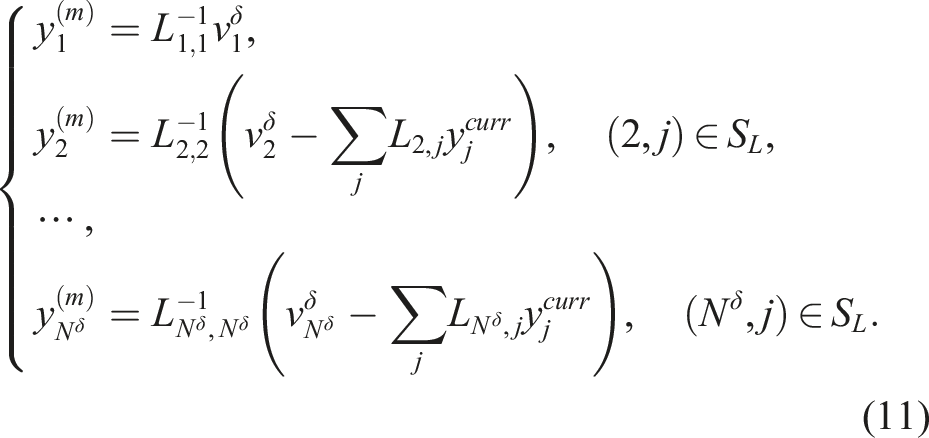
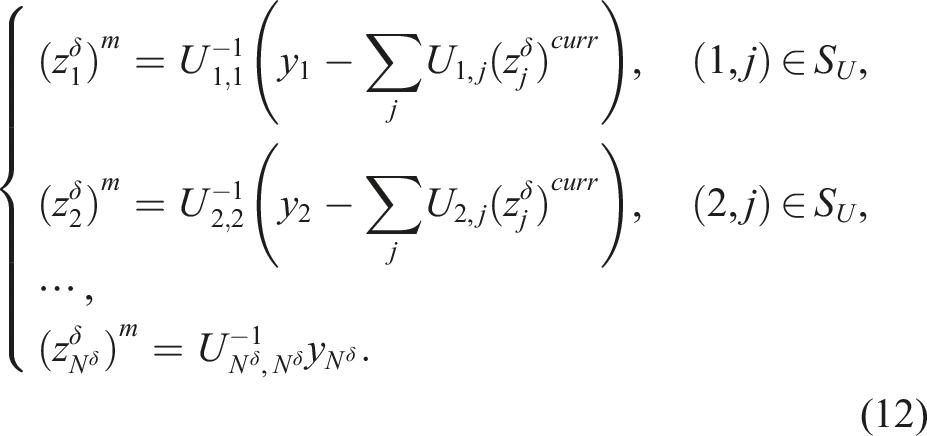
In order to save the computation cost, in Algorithm 3, we simply use the maximum number of iterations, denoted γ, instead of the SpMV-based norm checking at the end of each iteration to determine when the processes should stop. As a result, the solutions could be inaccurate, but they are usually acceptable when used for preconditioners. Similar to Algorithm 1, the factor f
dp
is also provided in Algorithm 3 to control the overall degree of parallelism by grouping the elements in
4.3. Point-block randomized RAS preconditioner
As mentioned before, the point-block ILU and triangular solves are two indispensable blocks for building the RAS preconditioner in a Krylov subspace solver. Therefore, if either or both of them are of randomized feature, the RAS preconditioner becomes randomized, which we call point-block randomized RAS (PB-R-RAS) preconditioner. The process for applying PB-R-RAS to a Krylov subspace solver is given in Algorithm 4.
The algorithm consists of two key parts. One part is performed outside the Krylov subspace solver, which is required to compute only once. Firstly, each subdomain performs a subdomain-to-subdomain communication via the local-global index set (i.e.,

5. Thread partition strategy
In this section, we discuss the thread partition strategy in the implementation of the proposed algorithms. In Algorithms 1 and 3, we mention the computing unit in a logical level, and it could be any type of logical units that execute the computational task. For example, on the GPU, a computing unit could be a thread, a warp (bunch of threads) or a thread-block (divided into several warps in the execution) depending on how the user-defined parallel strategy that maps the task to the logical unit works. In our previous work (Ma and Cai, 2021), the warp-based thread-task mapping strategy is used to comply the coalesced memeory access principle on the GPU, which ensures the adjacent threads read or write adjacent data. It can also be applied to the implementation of Algorithm 3. Next we focus on the realization of Algorithm 3 on the GPU.
Since the ILU and triangular solves involve strong data dependency, we partition Illustration of the warp-based thread-task mapping strategy.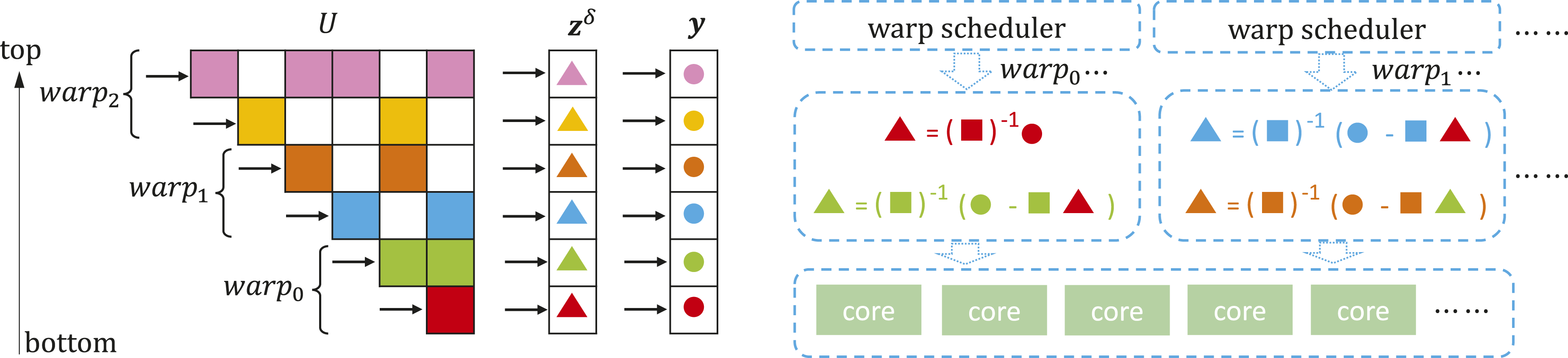
Figure 4 use the top block-row as an example to show more details of Figure 3 on how a warp accomplish the task. The basic strategy is mapping threads with consecutive identifiers to consecutive blocks in the block-row. In the case where the total number of scalar elements (not including the elements in the diagonal block) in a block-row exceeds the warp size, the warp will conduct several cycles until all non-zero blocks are included. In this way, each thread only performs fine-grained scalar-scalar multiplication locally. One key step for handing the local results from threads is that reductions are required at the corresponding rows. As the reduction operation needs data sharing between threads, we perform the summations in the shared memory. Once the reduction has completed, the first s threads preform a vector subtraction and block-vector multiplication locally to obtain the final results. Accumulating the block-vector multiplication in shared memory; Local block-verctor operations through register-shared interaction.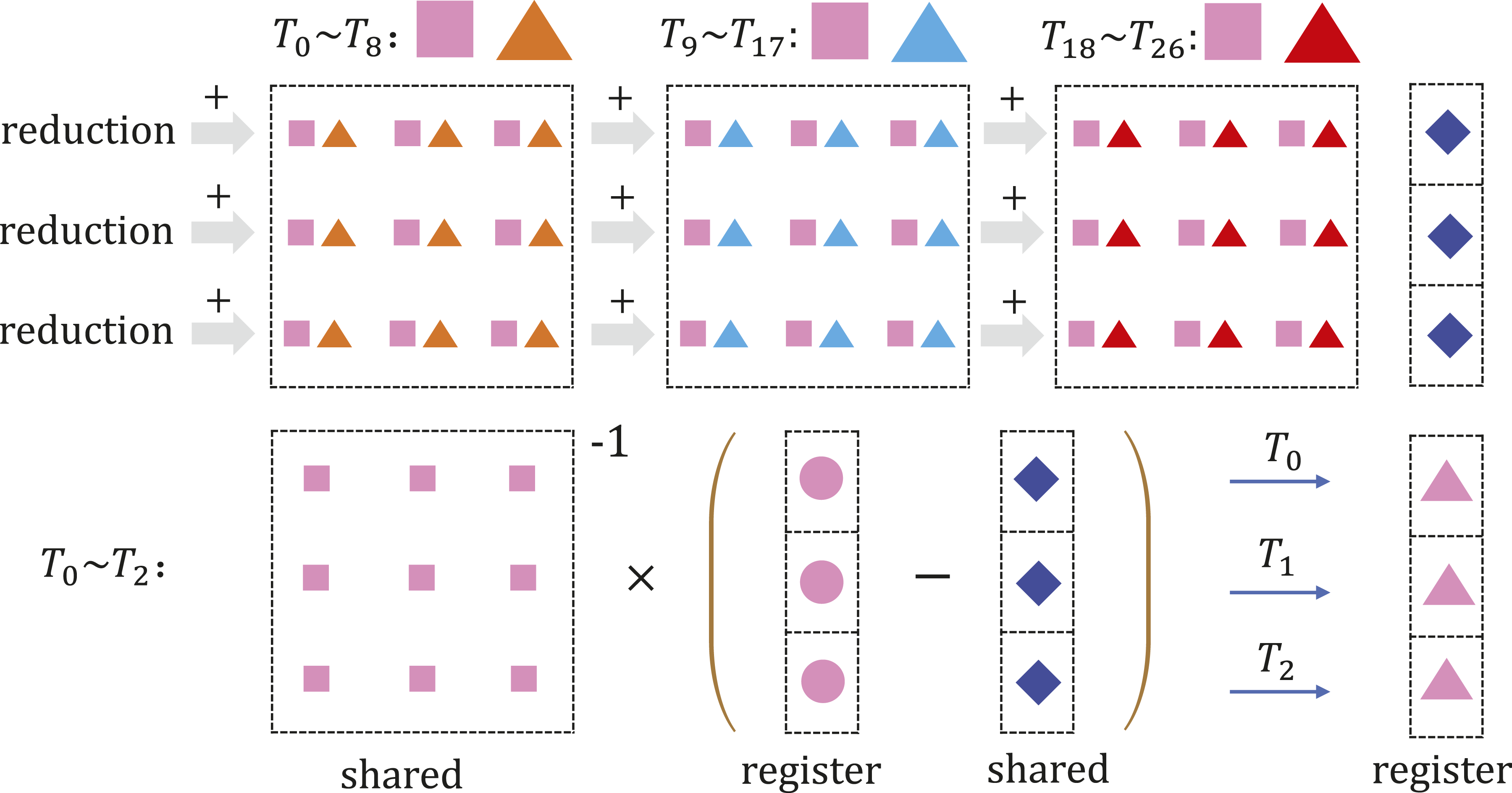
We notice that block inverses have to be computed in both Algorithms 1 and 3. The inverses of Uj,j are varying, and required by each Li,j(i > j) at every iteration in Algorithm 1, and our previous work on point-block ILU (Ma and Cai, 2021) proposed a “compute-on-demand” method for the update of Uj,j based on the hard-coded inverses. On the contrary, the inverses of Uj,j are fixed in the iterative process of Algorithm 3. In the implementation, we perform an in-place inversion for the block-diagonal of U as an pre-processing step before the iterative process starts. We also adopt a warp-based thread-task mapping strategy in which a thread in a warp is mapped to a single element in a block and hard-code the result at the same position of the block-inversion. Therefore, a CUDA kernel is developed to make a warp handle ⌊W
s
/s2⌋ blocks in total. Figure 5 shows how the first nine threads from a warp hard-code a 3 × 3 block in parallel. Fine-grain hard-code the inverse of a 3 × 3 block.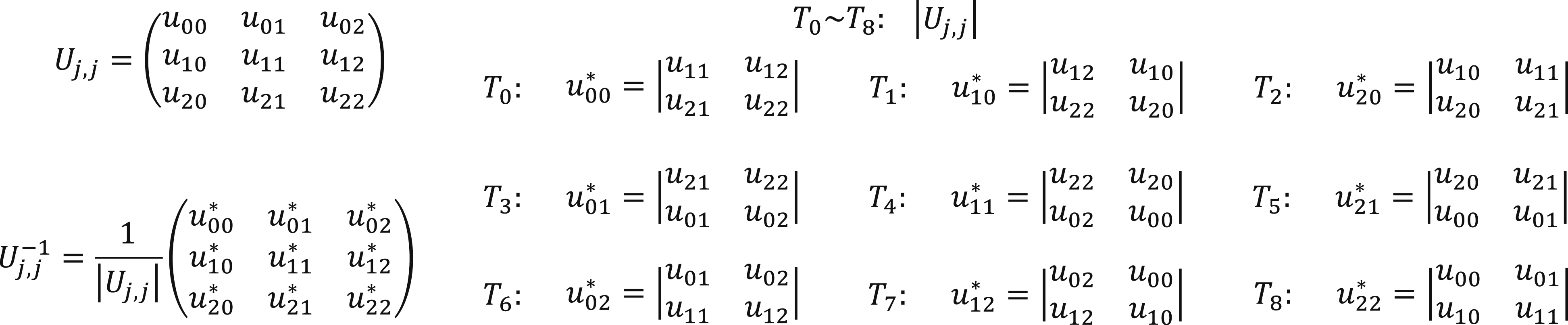
6. Numerical results
In this section, we present some numerical results for both a fluid and a solid simulation by using the proposed PB-R-RAS preconditoner and make various comparisons between different algorithms.
All the experiments are conducted on a heterogeneous cluster with 16 computing nodes. Each node is configured with 2 Intel(R) Xeon(R) CPU E5-2640 v4@2.4GHz, with a total number of 20 CPU cores, 128 GB physical memory and 4 Nvidia Tesla Volta 100 SXM2 GPU cards. Each Tesla V100 card is equipped with 5120 CUDA cores and 640 tensor cores, 16 GB 4094-bit HBM2 memory with a bandwidth of 897 GB/s and 80 streaming multiprocessors (SMs). It delivers the peak single-precision and double-precision floating point performance of 15.7 TFLOPS and 7.8 TFLOPS, respectively.
Abbreviations for the algorithms for performance comparisons.
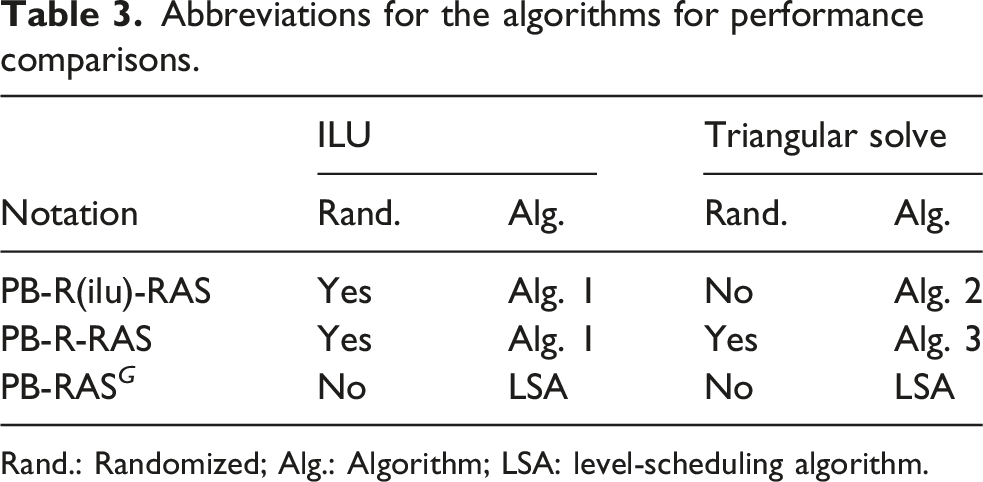
Rand.: Randomized; Alg.: Algorithm; LSA: level-scheduling algorithm.
Since our preconditioner is randomized and its application may vary at runtime, in all experiments, we use the right-preconditioned flexible GMRES (FGMRES) (see Saad, 2003) which is designed to accommodate variable, iteration-dependent preconditioning without losing convergence guarantees, as the linear solver. For each experiment, we report the compute time of FGMRES in millisecond until convergence, denoted T g , the compute time of the ILU facatoriztion in millisecond, denoted T f , and the total number of FGMRES iterations until convergence, denoted I g . Note that the point-block ILU is locally performed in each subdomain which could be different in size, therefore T f is reported as the maximum compute time between all GPUs. And all the data presented are the averages obtained from three independent runs.
6.1. A two-dimensional driven cavity fluid problem
We consider a two-dimensional driven cavity flow problem as a benchmark case. It is modeled by the incompressible Navier-Stokes equations in the velocity-vorticity formulation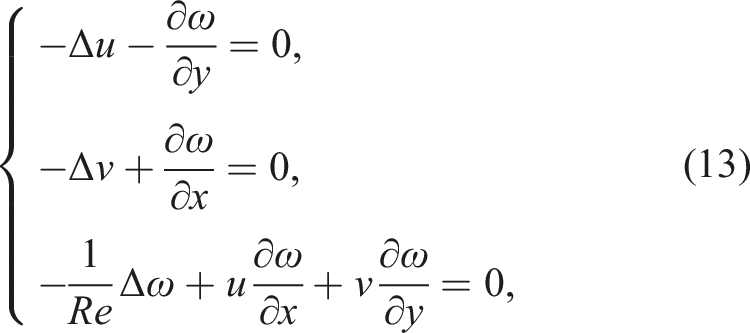
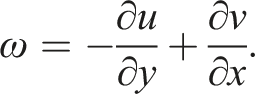
We use the five-point central differencing scheme to discretize (13). The discretized system is solved by an inexact Newton method, and in each Newton step, the linearized Jacobian system is solved by a right-preconditioned FGMRES algorithm. We arrange all the variables associated with a mesh point in the order of u, v, and ω in the discretized system, and the resulting Jacobian matrix is of the point-block format with the block size of 3. The stopping condition for the nonlinear solver is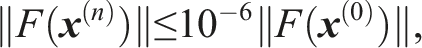
The problem is first solved on a 600 × 600 mesh with Re = 1.0 on 4 GPUs. The FGMRES(30) with the PB-R(ilu)-RAS preconditioner is used as the linear solver in the nonlinear Newton process. The fill-in level for the randomized ILU factorization is 1, and the factor f
dp
that controls the degree of parallelism is set to 8. Figure 6 shows the performance and effect of the preconditioner with varying η and γ in Algorithms 1 and 2. The performance of FGMRES(30) in terms of I
g
and T
g
using PB-R(ilu)-RAS preconditioner with varying η and γ (NT represents the Newton step).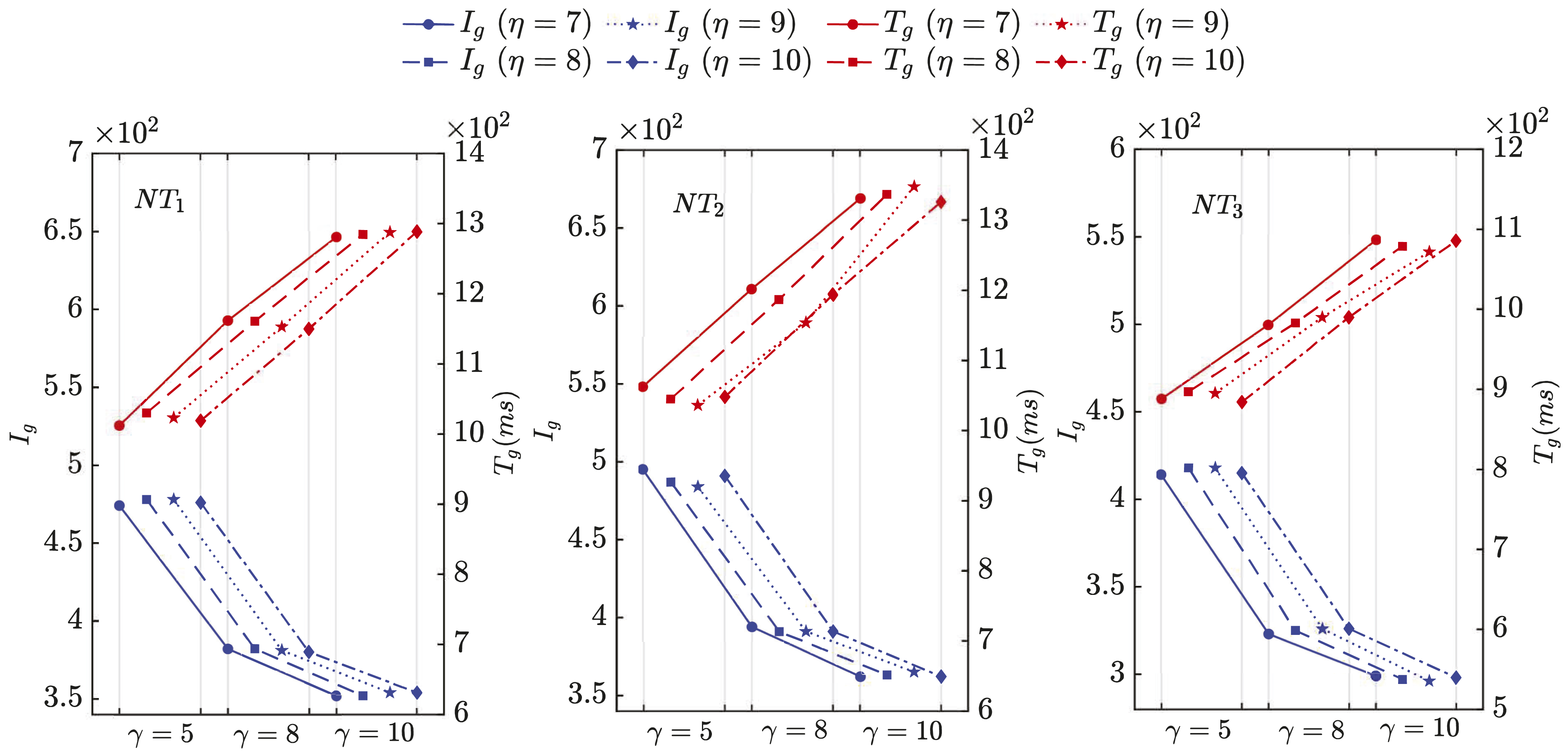
It can be observed from Figure 6 that when η for ILU is fixed while γ for triangular solves increases, the number of FGMRES(30) iterations decreases correspondingly. This is to be expected, because more number of iterations for the triangular systems improves the exactness of the solution and then provides the preconditioner with higher quality. However, the larger γ makes the compute time for a single preconditioning step increase, thus leads to the increases of T g even though I g is reduced. By keeping γ fixed and observing scattered data within the same interval, we don’t observe I g and T g fluctuate widely as η increases. This indicates that a few number of iterations for ILU is enough for constructing an effective preconditioner and simply increasing η is unlikely to improve the quality of RAS.
I g and T g of FGMRES(30) using PB-RAS C and PB-RAS G preconditioners.
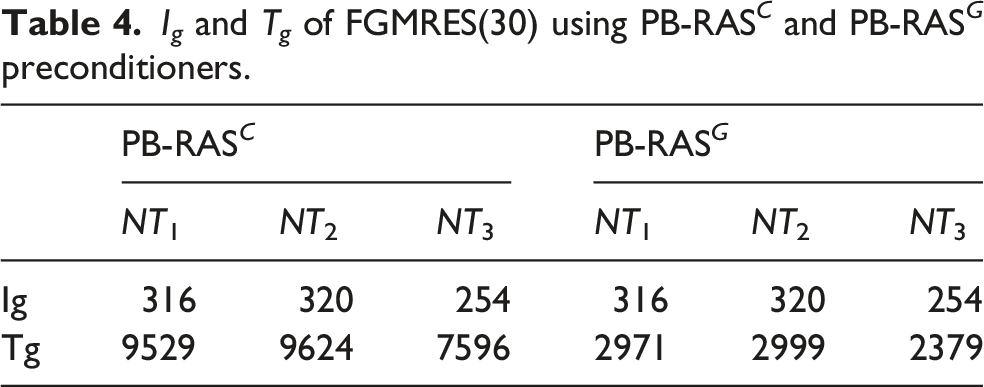
We notice from Figure 6 that even though the number of iterations for triangular solves is increased to 10, it still requires 10%∼18% more number of FGMRES(30) iterations by PB-R(ilu)-RAS than that by PB-RAS
C
or PB-RAS
G
. Figure 7 shows the obvious convergency improvement by applying PB-R-RAS where both the randomized ILU and triangular solves are employed. When γ = 8 or γ = 10 is configured, the number of FGMRES(30) iterations I
g
in each Newton step is very close to the result obtained by PB-RAS
C
, with a difference of only 1–4 iterations. When γ = 5, I
g
using PB-R-RAS is also significantly reduced compared to I
g
using PB-R(ilu)-RAS. This is because the randomized triangular solves make better use of the updated values by the asynchronized execution of the updating process. Even better than that, T
g
is also reduced correspondingly as a result of our efficient kernel implementation on GPUs. And the speedup increases to 15.0 if PB-R-RAS is used compared to using PB-RAS
C
. Taking PB-RAS
G
as the deterministic GPU performance baseline, PB-R-RAS achieves a speedup of approximately 4.6 over PB-RAS
G
. The performance of FGMRES(30) in terms of I
g
and T
g
using PB-R-RAS preconditioner with varying η and γ (NT represents the Newton step).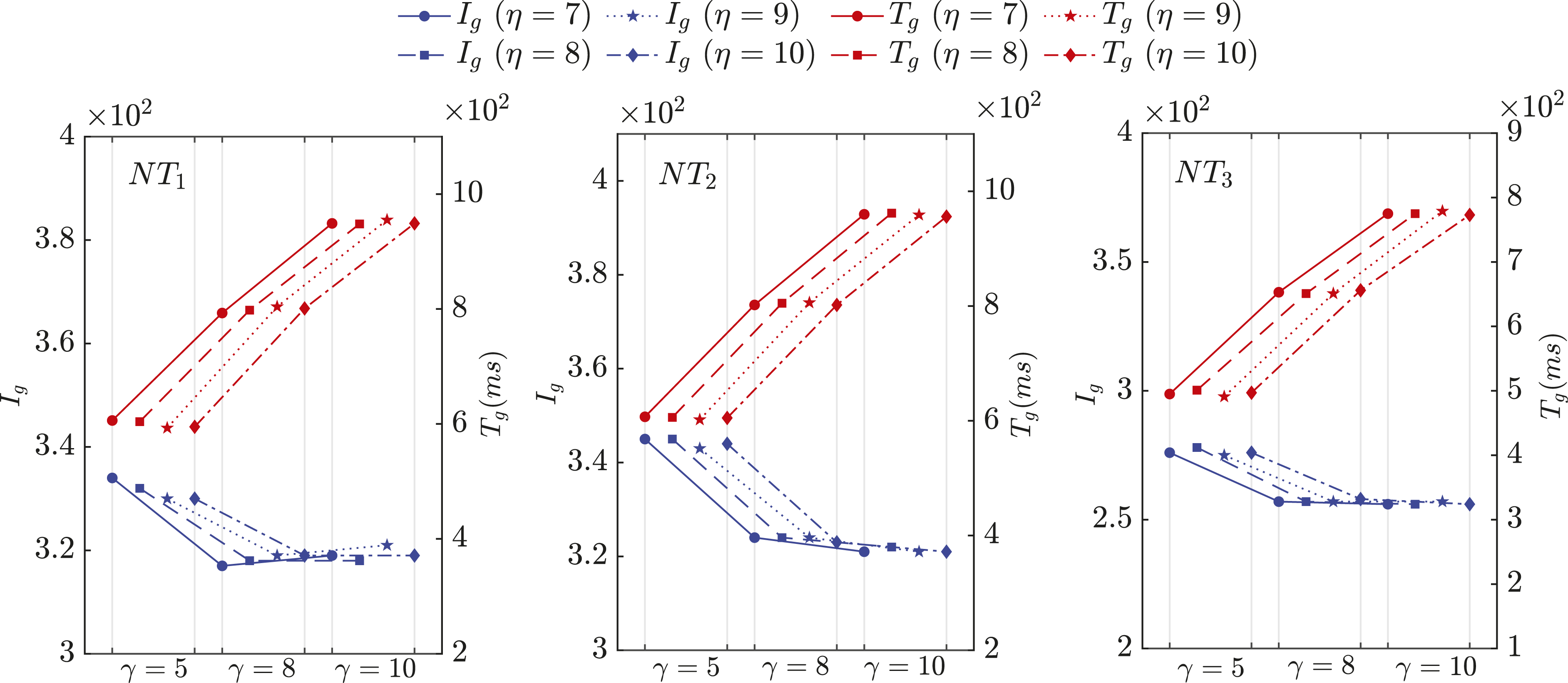
To test the stability of the proposed randomized method, we increase the mesh size to 1200 × 1200 and Re to 10.0 to make the problem harder to solve. Eight GPU cards on two computing nodes are used, and the FGMRES(100) and ILU(2) are employed. However, the randomized ILU(2) failed to provide effective factors because of lacking proper initial guesses for the positions in the sparsity pattern of ILU(2) / ILU(0). Since the ILU is executed only once for solving each linear system, and also T f is a tiny percentage of the total compute time for the problem, we perform an exact ILU(2) in the first Newton step and starting from the second Newton step, the randomized ILU(2) is used with the initial guesses from the last factorization.
Figure 8 shows the comparisons of I
g
and T
g
between PB-R(ilu)-RAS and PB-R-RAS. It can be observed that PB-R-RAS with the randomized triangular solves (dashed lines) generally makes FGMRES(100) have an advantage in terms of both number of iterations and compute time when comparing with the deterministic methods. Larger γ makes PB-R-RAS has almost the same effect as the exact one (shown in Table 5) in terms of I
g
. By varying f
dp
from 8 to 16 to increase the degree of sequentiality, we see that there is an obvious improvement on the convergency in terms of I
g
, and I
g
for all γ increasing from 10 to 20 are nearly the same. This is anticipated, as the increased degree of seriality enhances the quality of the triangular solve. However, the improvement in convergency is achieved at the expense of increasing the overhead per preconditioning step. From the standpoint of compute time, as f
dp
increases, whether T
g
demonstrates superiority mainly depends on the magnitude of the reduction in I
g
brought by the quality improvement on the preconditioner. For example, in the second Newton step, an increase in f
dp
to 16 can reduce the number of iterations from 575 to 492 compared with f
dp
= 8, representing an approximate 14% reduction. The magnitude of this reduction only makes the T
g
basically equal to that of f
dp
= 8, thus failing to show advantage on both T
g
and I
g
. Compared to I
g
and T
g
using PB-RAS
C
in Table 5, a speedup of 13.0 can be obtained by PB-R-RAS with the configuration of η = 8, f
dp
= 16 and γ = 10. Even with a certain degree of parallelism sacrificed for accuracy by increasing f
dp
, PB-R-RAS still reduces the computation time by a factor of two compared with PB-RAS
G
. Performance comparisons of FGMRES(100) using PB-R(ilu)-RAS and PB-R-RAS with different configurations (NT represents the Newton step). I
g
and T
g
of FGMRES(100) using PB-RAS
C
and PB-RAS
G
preconditioners.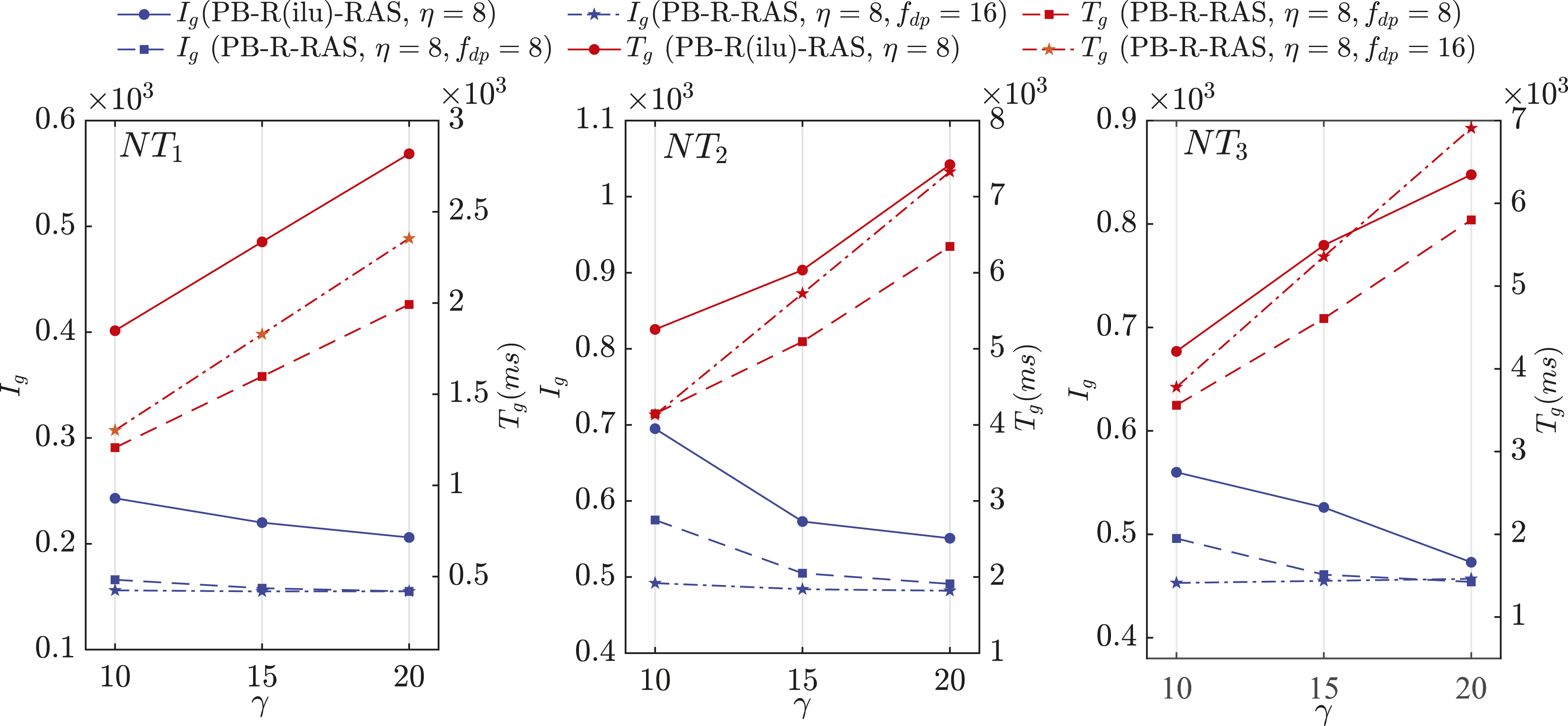
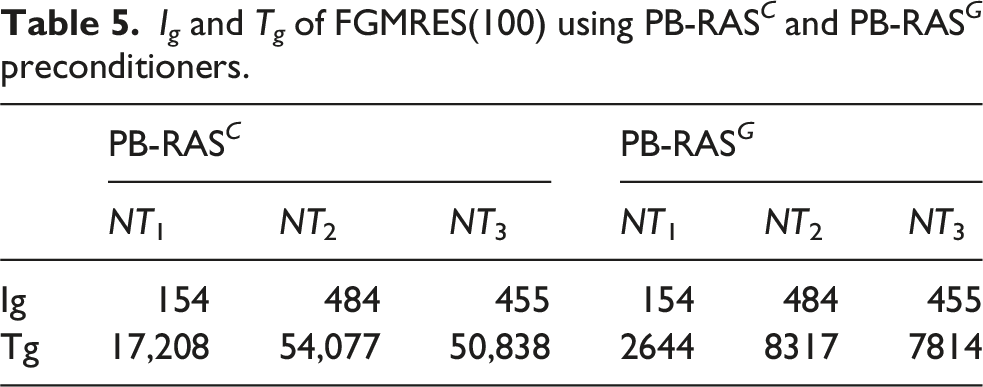
Next we make η fixed and vary f
dp
and γ to observe their impacts on T
g
and I
g
, and the results are shown in Figure 9. It is found that the influence of f
dp
on the number of iterations is quite dependent on γ. When γ is relatively small, γ = 10 for example, blindly increasing f
dp
(i.e., increasing the degree of seriality or decreasing the degree of parallelism) can reduce the number of iterations to a certain extent, but it is not very stable. For instance, when f
dp
increases to 32, I
g
could rise due to the randomness of the algorithm. An increase in f
dp
combined with a moderately larger value of γ can make I
g
more stable, which is illustrated by the dashed lines for I
g
in all three Newton steps. The impacts on T
g
and I
g
by varying f
dp
and γ.
From the perspective of compute time, an increase in f dp may reduce the number of iterations but inevitably leads to a rise in the per-step expense, therefore the trend of T g depends primarily on the magnitude of the reduction in I g as a result of the increase in f dp . Notably, for γ = 10, I g exhibits wide-ranging fluctuations with f dp getting larger, consequently, T g rises relatively slowly. For γ = 15 and γ = 20, I g remains much stable, leading to a continuous increase in T g . In most cases, I g obtained by the randomized approach is, at best, comparable to that achieved by the exact preconditioner. Therefore, once our randomized algorithms attain an iteration count near to that of exact algorithms, further increasing f dp yields diminishing returns.
We complete statistical analysis of the proposed algorithm by performing 30 independent repeated tests using the parameter setting of η = 10, γ = 5 and f
dp
= 8, and the results are presented in Figure 10. It can be observed that both the number of iterations and the solution time exhibit an overall stable variation trend. The fluctuation in the number of iterations is constrained within 2, and the minimum deviation in solution time is 2 ms, while the maximum deviation is 72 ms. Moreover, the algorithm achieves successful convergence in all 30 repeated tests with zero failure rate. Statistical results of T
g
and I
g
over 30 independent tests.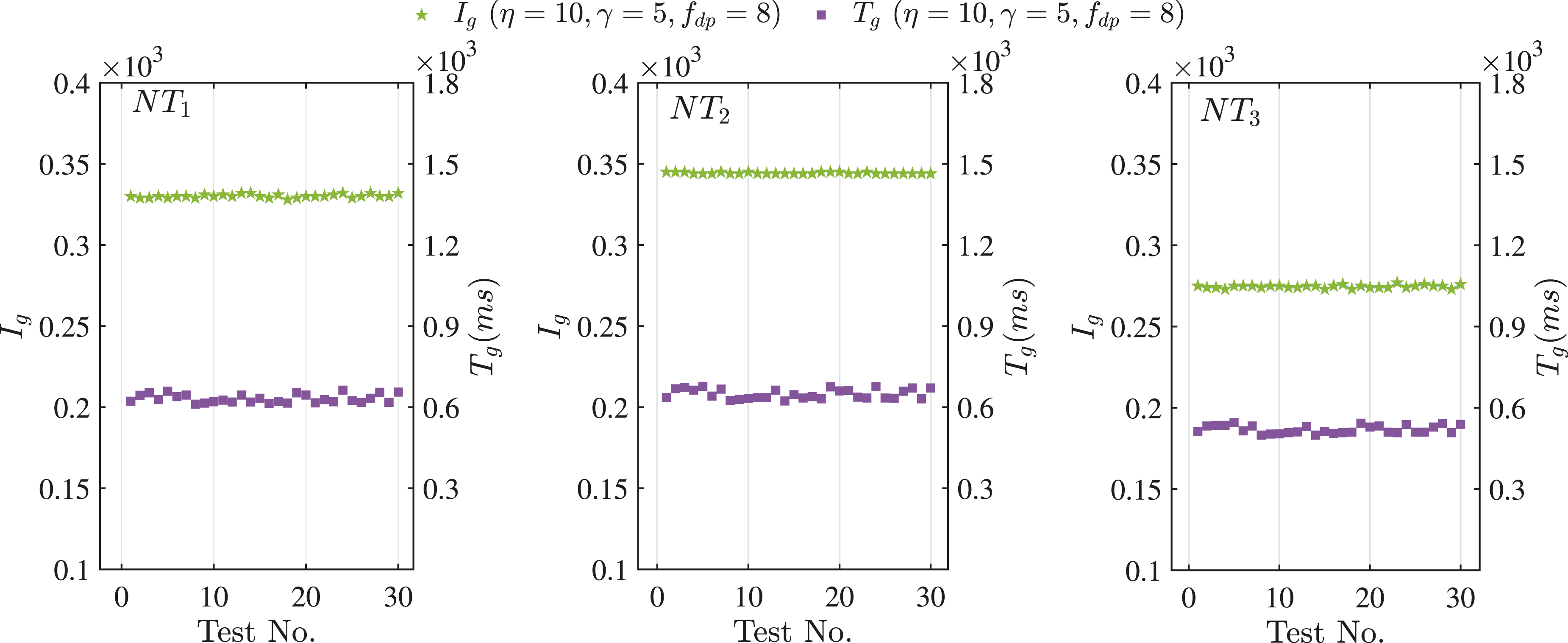
6.2. A three-dimensional elastodynamic problem for left ventricle simulations
We consider a three-dimensional elastodynamic system for the simulation of the left ventricle by Jiang et al. (2020) A left ventricle with the unstructured tetrahedral mesh.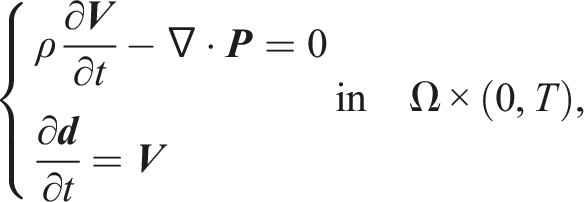
We apply the algorithms to solve the Jacobian system extracted from the second Newton step at the third time step. When three velocity components of
Figure 12 provides a detailed comparison of the performance between PB-R(ilu)-RAS and PB-R-RAS preconditioners in terms of I
g
and T
g
with varying η and γ. Each subfigure corresponds to a fixed value of η, and we have the same conclusion as in the previous case that the effect of preconditioning is almost unaffected by η. This is evident from the fact that there are almost no significant changes among these four subfigures. Then we take a closer look at each subfigure. In terms of I
g
, regardless of the value taken by γ, the randomized algorithm shows a very obvious advantage over the deterministic one. In terms of T
g
, γ = 7 acts as a critical value for the deterministic algorithm. When γ ≤ 7, T
g
decreases accordingly due to the considerable reduction in the number of iterations. However, when γ ≥ 7, the reduction in I
g
becomes less significant. As a result, the time saved by the reduction in the number of iterations is not enough to offset the additional overhead brought by each preconditioning step with increasing γ, making T
g
begin to go up. By choosing the optimal T
g
to compare with that by PB-RAS
C
preconditioner shown in Table 6, PB-R(ilu)-RAS can accelerate FGMRES(100) by a factor of 11. I
g
and T
g
comparisons using PB-R(ilu)-RAS and PB-R-RAS with varying η and γ. I
g
and T
g
of FGMRES(100) using PB-RAS
C
and PB-RAS
G
preconditioners.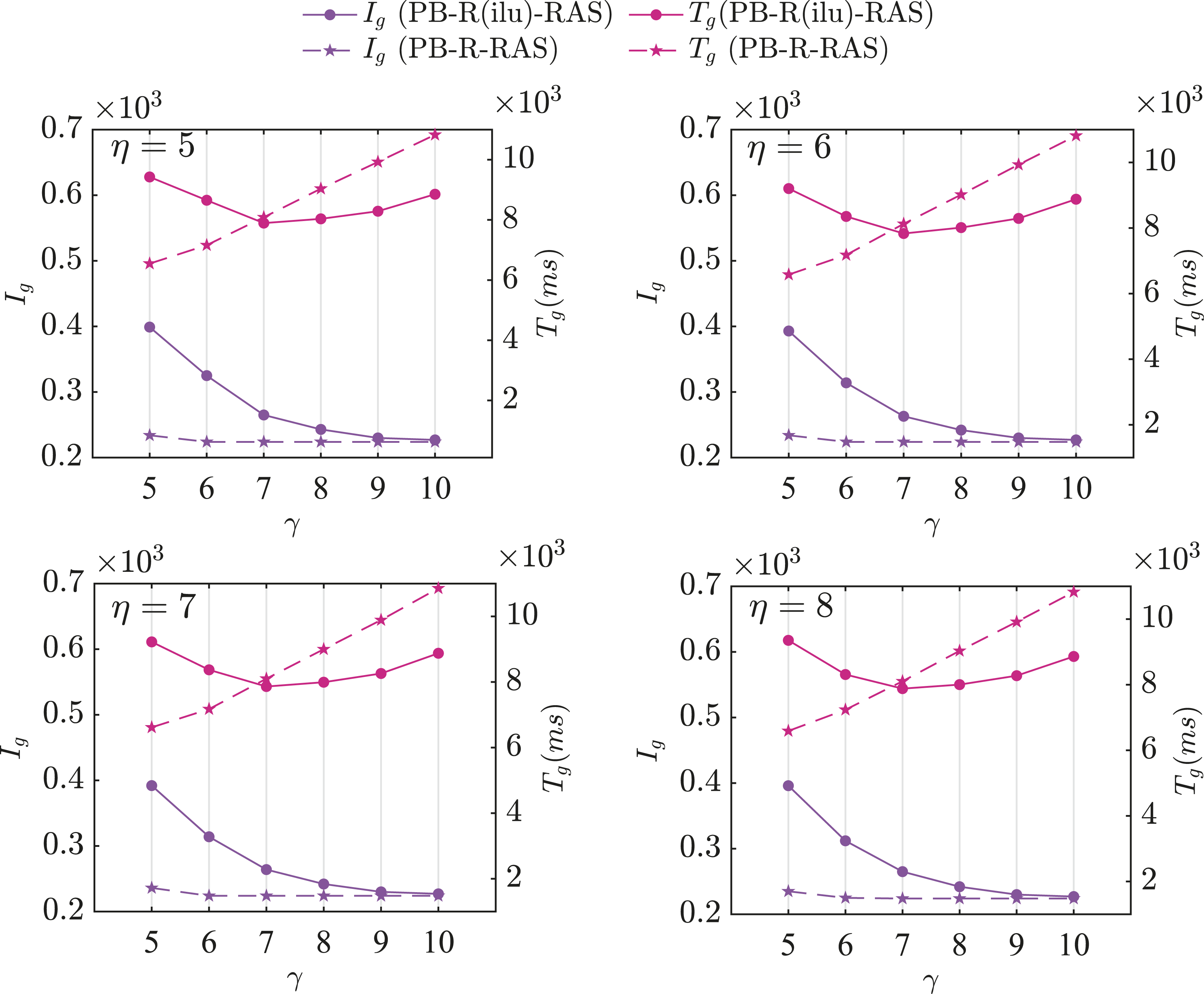
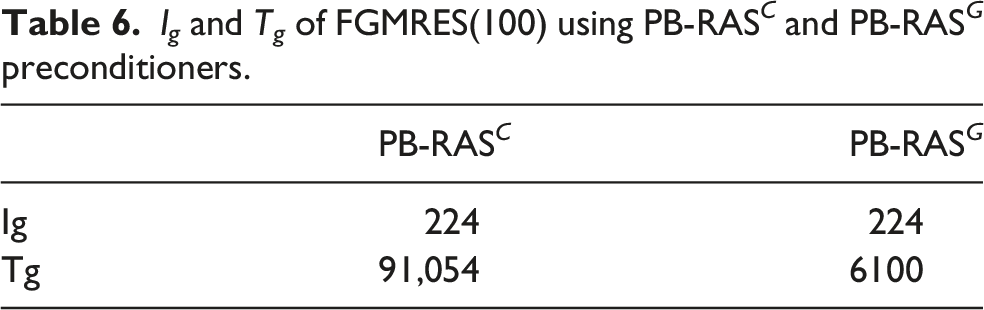
The results of the randomized algorithm shown in Figure 12 are obtained by setting f dp = 8 because f dp = 8 is the minimal value to make the randomized ILU work. It can be observed that I g fluctuates slightly with the increase of γ. Particularly, when γ ≥ 6, the trend of I g appears as a straight line, and its value no longer changes, which is completely consistent with the exact number of iterations by PB-RAS C or PB-RAS G . However, PB-R-RAS with γ = 5 results in the best T g even though it requires 10∼12 more iterations to make FGMRES converge. The level-scheduling based algorithm implemented by the efficient cuSPARSE library, PB-RAS G , exhibits very good performance with a total executing time of 6100 ms, which is even slightly less than that of the randomized algorithm by approximately 6.8%. This benefits from the sparsity pattern containing enough levels of high parallelism. When PB-R-RAS is compared with PB-RAS C , it remains competitive and can provide a speedup of 13.9.
Under identical parameter settings, Figure 13 quantitatively presents the mean and standard deviation of T
g
and I
g
obtained from 10 independent tests. The variation ranges of T
g
and I
g
are indicated by error bars, which are overall small in magnitude. Notably, the values of I
g
remain consistent across all 10 tests when γ ≥ 7, yielding a standard deviation of zero, and thus no error bars are shown. Mean and standard deviation of T
g
and I
g
with varying γ from 10 independent tests.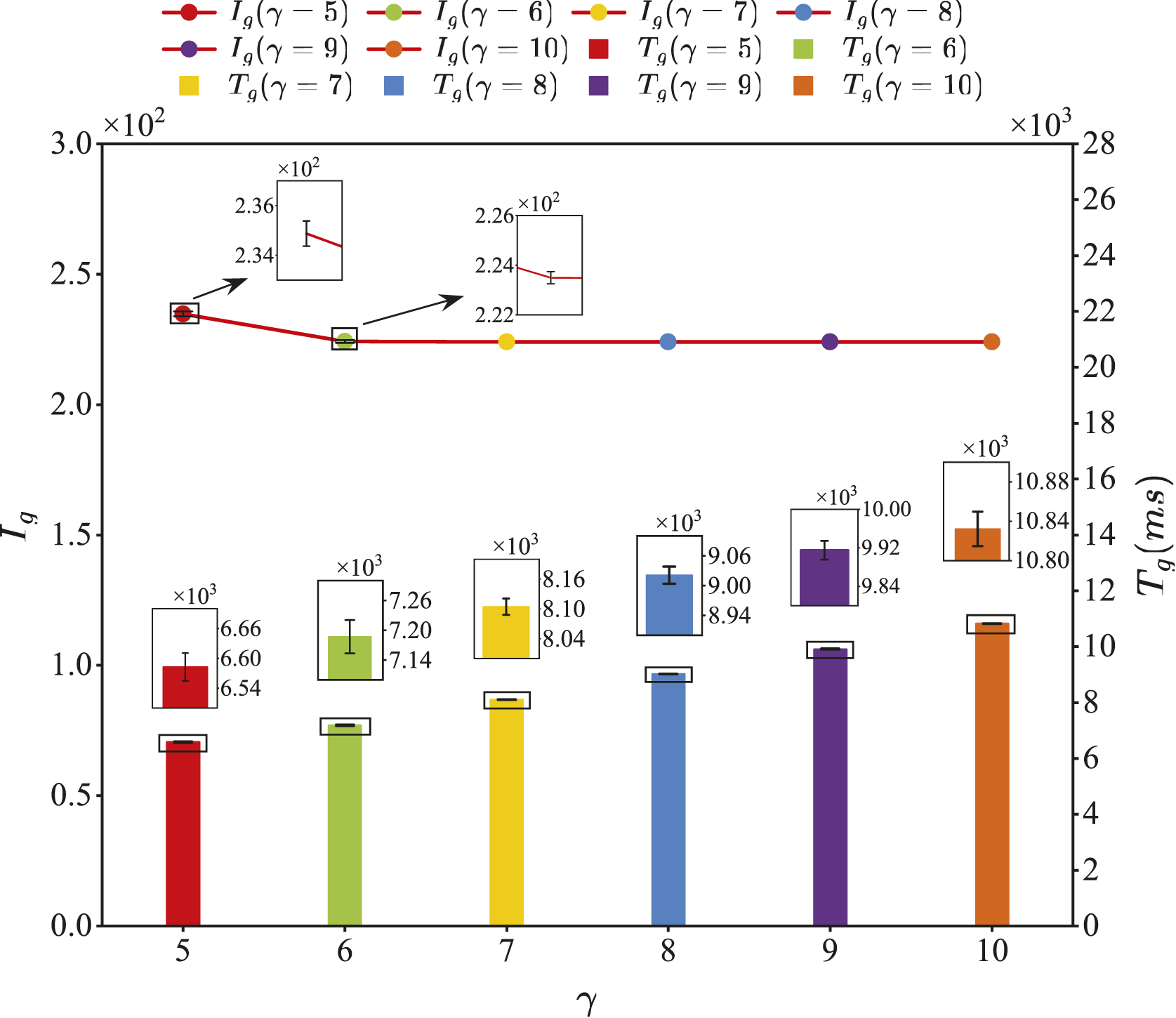
6.3. An unsteady incompressible Navier-Stokes problem for the simulation of cerebral arterial blood flow
We consider the unsteady incompressible Navier-Stokes problem in a cerebral artery 
Figure 14 gives an overview of a patient-specific artery with the fully unstructured tetrahedral mesh for the computational domain. The equations are discretized on the mesh and then solved by the Newton-Krylov-Schwarz method (Liu et al. (2023)). In each Newton step, the Jacobian system is formed and solved. The linear system consists of 1,497,225 block rows and columns with a block size of 4, having a total of 21,279,963 non-zero blocks. This is equivalent to 340,479,408 scalar entries. We use the FGMRES(200) with the randomized RAS as the right preconditioner to solve it. The overlap for the RAS is set to 1 and the relative tolerance for convergence is set to 10−4. In each subdomain, a point-block randomized ILU(2) factorization are preformed before the FGMRES(200) starts. f
dp
= 8 is employed for both the randomized ILU(2) and the triangular solves. A patient-specific artery with the fully unstructured tetrahedral mesh.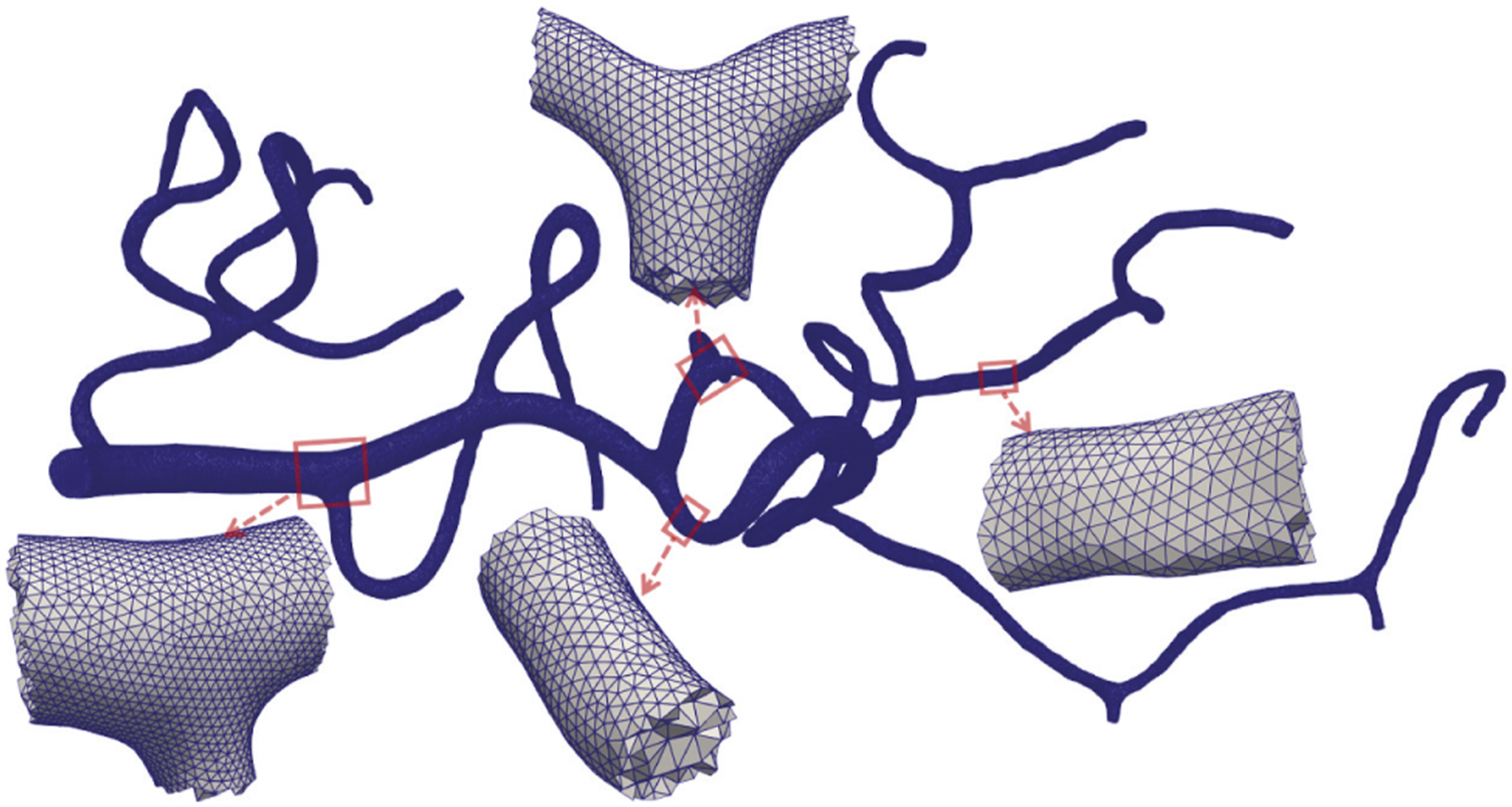
Figure 15 shows the overall times of FGMRES using PB-RAS
C
and PB-RAS
G
preconditioners with N
c
and N
g
varying from 8 to 64. We can achieve a speedup that drops from 7.8 to 2.4 using the level-scheduling based PB-RAS
G
over the pure CPU implementation. The main reason for the sharp decline in the speedup ratio with increasing N
g
is that the scalability of PB-RAS
G
is much worse than PB-RAS
C
. T
g
using PB-RAS
C
and PB-RAS
G
preconditioners with varying N
c
and N
g
.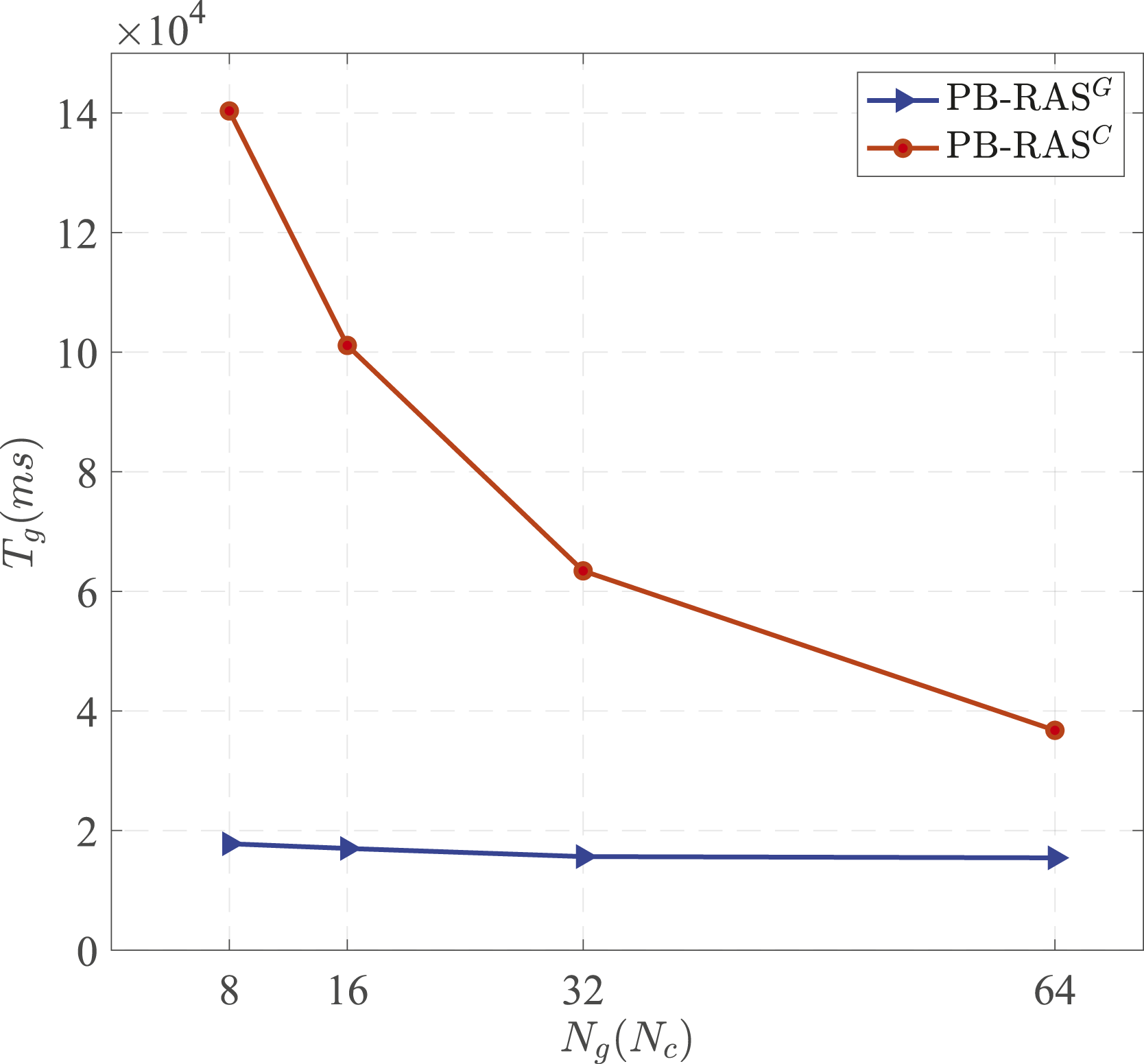
Figure 16 shows the statistical results of T
g
and I
g
over 10 independent tests under different values of N
g
and γ for robustness studies. The bars represent the mean values of T
g
, with the standard deviation error bars indicating the degree of data dispersion. In each subplot, it is expected that larger number of iterations for randomized triangular solves leads to larger T
g
, and this trend is nearly consistent across all subplots. In contrast to the minor fluctuations observed in T
g
across multiple tests, no variations in I
g
are detected, and hence no error bars are displayed in the line plots. As γ = 5 results in the minimal value of T
g
, this parameter setting is adopted for the speedup evaluation, and employing the PB-R-RAS preconditioner on 64 GPUs yields speedups of 6.3 and 15.1 compared with PB-RAS
G
and PB-RAS
C
, respectively. Robustness analysis for PB-R-RAS preconditioner over 10 independent tests with varying N
g
and γ (from 5 to 10).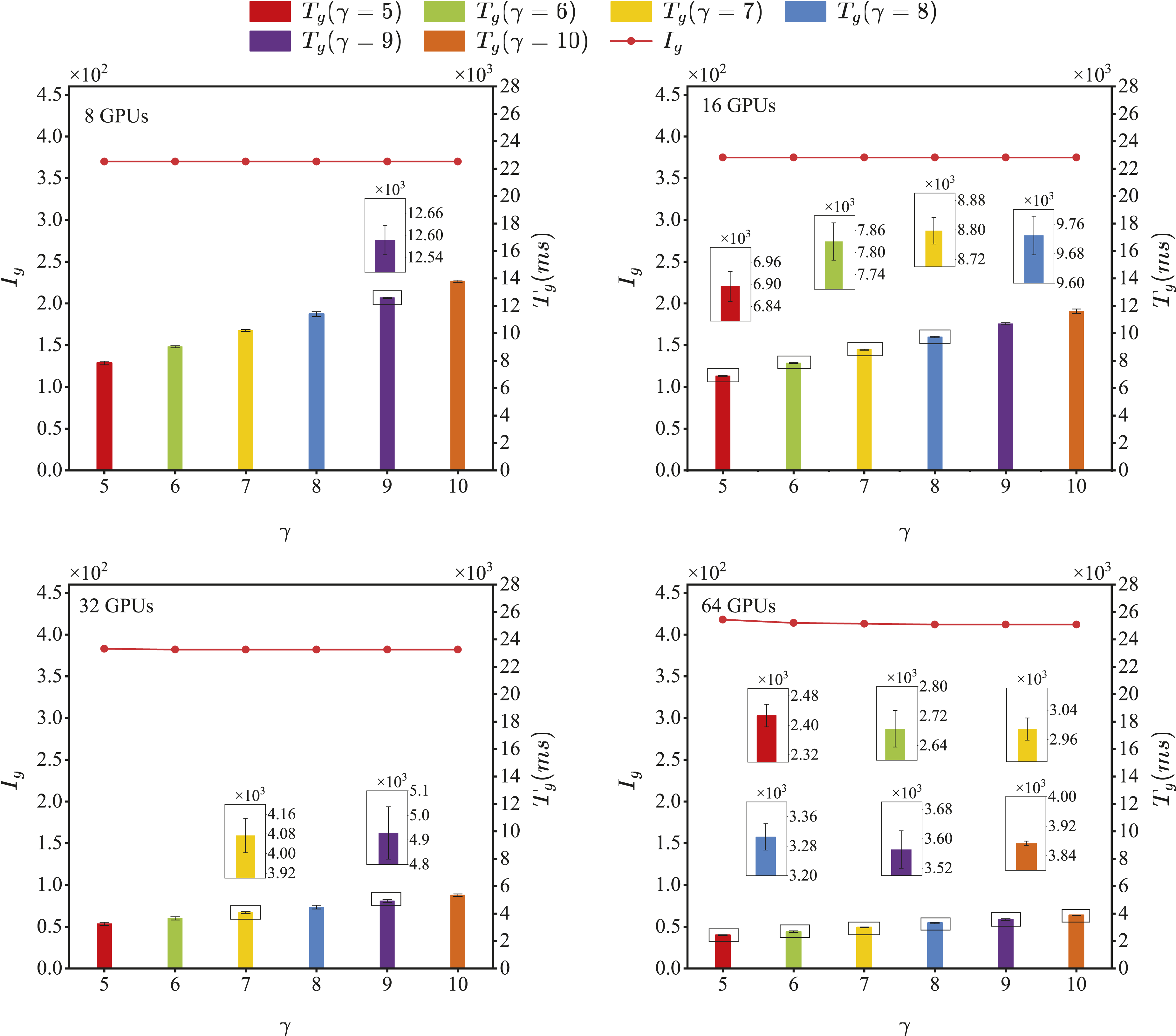
The strong scalability of different preconditioners are summarized in Figure 17. The parallel efficiencies are evaluated as N
g
increasing from 8 to 64, and N
g
= 8 is the baseline. We notice that the parallel efficiency for PB-R-RAS preconditioner using 16 GPUs (59%) is lower than that using 32 GPUs (65%). This is mainly due to the imbalance communication caused by the imbalance off diagonal patterns in the sparse matrix-vector multiplication operations. The fact can be also observed in Figure 15 where T
g
does not decrease significantly when N
g
(N
c
) = 16 compared to N
g
(N
c
) = 8. As depicted in Figure 17, it is observed that the parallel efficiency increases from 40% to 45% with the growth of γ. This trend is readily comprehensible, given that an increase in γ leads to a higher proportion of computational time being allocated to the concurrent subdomain calculations. It is also demonstrated that PB-R-RAS preconditioner has much better strong scalability than PB-RAS
G
on multiple GPUs. Parallel efficiency comparisons between different preconditioners.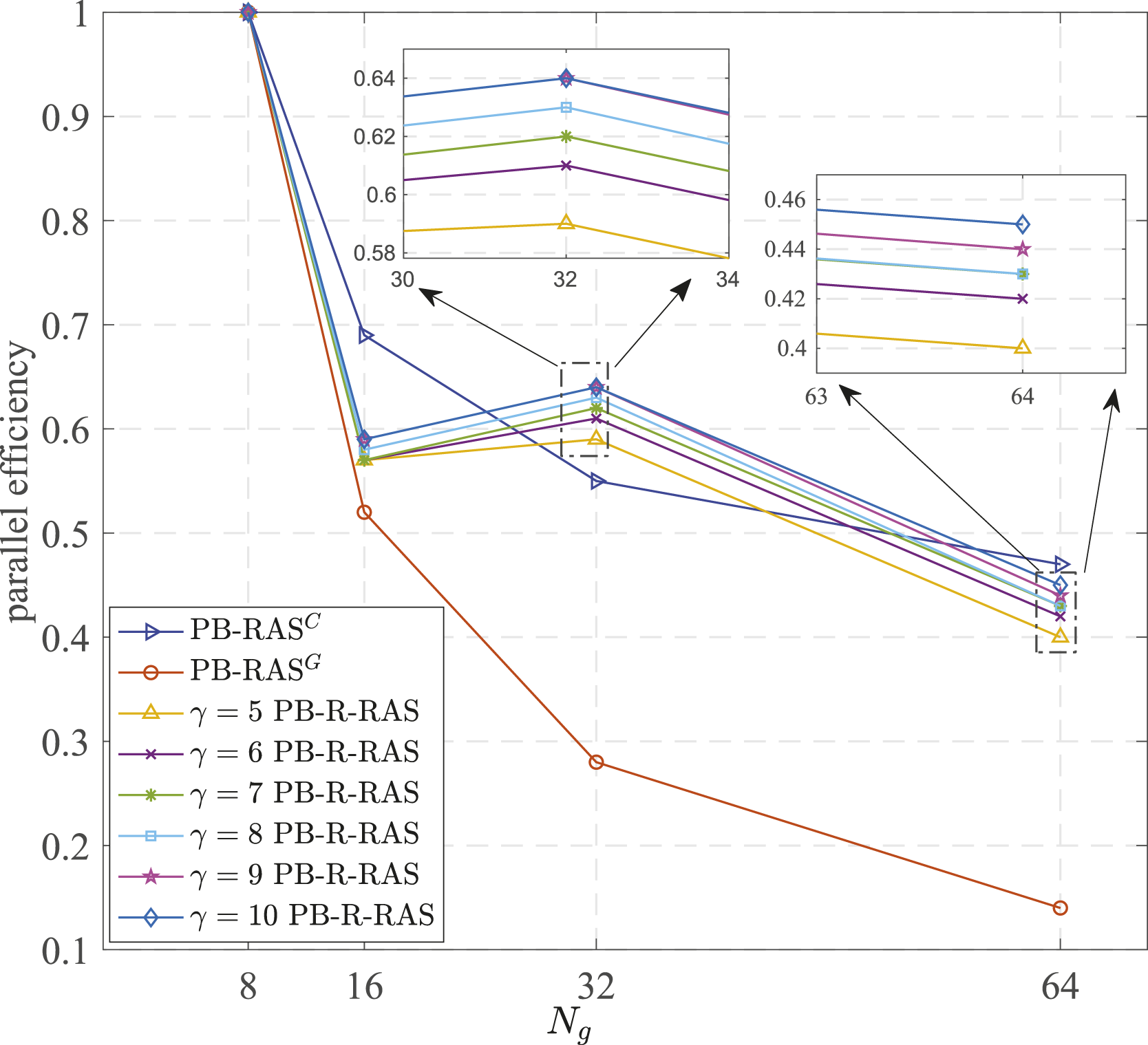
6.4. Remarks on parameter settings
When applying domain decomposition-based Schwarz preconditioners on GPUs, the efficiency of ILU-based subdomain solvers directly determines the performance of the entire preconditioner and the Krylov linear solver. Our algorithm serves as a effective alternative when the independent levels extracted from the matrix sparsity pattern using the level scheduling algorithm do not provide sufficient parallelism on GPUs. Based on the experimental results, we summarize several practical guidelines for parameter selection of this algorithm: (1) For the randomized ILU factorization and triangular solve on subdomains, 5∼8 iterations are necessary. However, simply increasing the number of ILU iterations does not lead to better convergence of the linear solver. (2) If ILU(p) with p ≥ 2 is to be employed, we recommend using an exact ILU factorization combined with a randomized triangular solve. In particular, when this preconditioner is used within the NKS algorithm, it is advisable to adopt an exact ILU factorization on each subdomain to obtain a good initial guess, while switching to a randomized ILU factorization in subsequent nonlinear steps. This represents the optimal strategy considering both performance and stability. (3) To fully utilize the performance of GPUs, it is reasonable to keep the submatrix size on each subdomain within hundreds of thousands. And the default value of f
dp
can be set to 8. Increasing f
dp
raises the sequential degree, sacrificing some preconditioner performance in exchange for improved accuracy.
7. Conclusion
We propose and implement a point-block randomized restricted additive Schwarz preconditioner for the efficient use of the heterogeneous architecture with different levels of parallel features, and apply the method in a Krylov subspace solver for solving fluid and solid problems. In the face of the challenge that the ILU-based subdomain solver has a naturally high degree of seriality, the randomized approach can balance both parallelism and effectiveness and is capable of adapting to a range of multiphysics problems and different generations of accelerators by offering a tuning factor controlling the degrees of parallelism. In contrast to standalone ILU-based preconditioning, the proposed RAS preconditioning with parallel, randomized subdomain solves introduces both local randomization within subdomains and global randomization across the domain decomposition framework, yielding a fundamentally distinct preconditioning strategy. The experimental results show that the randomized approach can serve as an efficient alternative for generating effective preconditioners on GPUs, especially in scenarios where the deterministic GPU algorithm struggle to perform well.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work of the first author is supported by the Science and Technology Research Project of Henan Province (No. 252102210219) and the Natural Science Foundation of Henan Province (No. 262300420295). The work of the corresponding author is supported in part by FDCT Macau – Science and Technology Development Fund (0146/2024/R1A2, 0135/2025/R1A2), and University of Macau (MYRG GRG2025-00122-FST).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.