
Abstract
Data is an indispensable asset in the AI ecosystem. This article investigates consumers’ lay understanding of the different types of data that AI systems use to generate recommendations, and how this understanding influences their likelihood of accepting those recommendations. Across one pilot study and four main studies, the authors establish consumers’ mental construction of three different data types and experimentally validate two mechanisms that shape recommendation acceptance: (1) perceived individuality threat associated with these data types and (2) their processing acceptability.
Data is the new gold, the new oil of the digital era, and is key not only to train large language models, such as ChatGPT (McLean, Osei-Frimpong, and Barhorst 2021; Poushneh 2021), but also to understand the attitudes and preferences of consumers (Nagulendra and Vassileva 2016; Turow, Feldman, and Meltzer 2005). With more than 10 billion connected devices serving as touchpoints and gateways for data collection (Transforma Insights 2025), marketers can now better track consumer characteristics and behaviors, gaining insights into preferences to provide more accurate recommendations. However, data collection practices have been characterized as both abusive and intrusive (Martin, Borah, and Palmatier 2017). As a result, policymakers prioritize safeguards to protect personal information against unauthorized access, collection, and distribution (Kamleitner et al. 2018; Mariani, Perez-Vega, and Wirtz 2022).
In this context, some companies are willing to disclose their data collection and processing practices, while others are more hesitant, fearing that such transparency could (1) dissuade consumers from engaging with their products and services (Brough et al. 2022) and (2) compromise their intellectual property (Burrell 2016). For instance, Netflix's recommendation algorithms drive more than 80% of the content watched on the platform, yet the company does not explicitly disclose much about these processes (Gomez-Uribe and Hunt 2015). Similarly, YouTube, Facebook, and Amazon do not provide much visibility into what data their algorithms process and how (Nagulendra and Vassileva 2016).
However, company choices on how to disclose data collection and processing practices have significant implications (Kim, Barasz, and John 2019). For example, both mechanistic explanations, which clarify how a system works, and teleological explanations, which describe why a system operates in a certain way, have been shown to ease consumer concerns and facilitate engagement (Querci et al. 2022; Tomaino et al. 2022), while, inversely, presence of explanations within privacy notices deters purchase intent (Brough et al. 2022; Kim, Barasz, and John 2021). Therefore, data collection and processing practices seem crucial in shaping consumers’ attitudes and responses.
This article examines consumer attitudes toward different data types used by AI systems to generate recommendations. Research has already established that consumers express differential concerns in relation to data types and categorizations (Aguirre et al. 2015; Chua, Ooi, and Herbland 2021; Martin and Murphy 2017; Phelps, D'Souza, and Nowak 2001). In this article, we introduce three types of data, making a theory-based distinction between demographics on one hand and individual-level and group-level behavioral descriptives on the other. This research tests the role of this data type distinction in driving recommendation acceptance based on two drivers: (1) the extent to which consumers sense a threat to their individual characteristics because of the data type being processed (dubbed “individuality threat”), and (2) the perceived acceptability of the data type being processed (dubbed “processing acceptability”). Furthermore, we unpack two distinct antecedents of processing acceptability: functional legitimacy and normative legitimacy, further clarifying the mechanisms that drive acceptance of AI-driven recommendations across data types. We conducted a pilot study to externally validate our data type classification and four experiments to test our proposed mechanisms. Together, these studies offer a well-defined understanding of the nuanced psychological factors that shape individuals’ acceptance of AI recommendations based on data types. Results consistently support that demographic data is the least favored data type to be processed to offer recommendations, compared with behavior-related data types. These findings are timely given the heightened public scrutiny of AI systems (Shin, Kee, and Shin 2022; Tomaino, Wertenbroch, and Walters 2023), emphasizing the importance of understanding lay mental heuristics that shape acceptance of AI recommendation across data type disclosures. In the following sections, we touch on the relevant algorithmic data processing and identity literature, introduce our theoretical model and experimental results, and conclude with our findings and implications.
Theoretical Framework
Algorithmic Acceptability and Data Processing
Consumer privacy and data transparency have become central themes in marketing management studies (Davenport et al. 2020; Martin, Borah, and Palmatier 2017; Martin and Murphy 2017), with AI systems often perceived as “black boxes” due to the opacity of their data processing and model characteristics (Rai 2020). Precisely, vague data collection practices and system complexity can exacerbate user concerns through loss of autonomy and control, preventing the adoption of such technologies (Park, Tung, and Lee 2021; Puntoni et al. 2021). Research has further explored user attitudes and behaviors toward algorithmic explainability and its impact on recommendations (Bonezzi and Ostinelli 2021; Cian, Longoni, and Krishna 2020; Kim, Barasz, and John 2021). Consumers often feel uninformed about how algorithms collect and process their personal data, which fosters reluctance to utilize these systems (Puntoni et al. 2021). However, disclosures related to targeting practices, such as the flow of personal information (Kim, Barasz, and John 2019) or data collection without explicit consent (Aguirre et al. 2015; Tsai et al. 2011), can backfire, resulting in lower click-through rates and purchase intent.
In this article, we unbundle the theory-based distinction between consumer demographics and behavioral descriptives. We differentiate between data representing one's individual behavior and data based on grouped behavior representing one’s social group. As a result, we propose the study of three different data types, labeled “demographic data,” “individual behavioral data,” and “social group behavioral data.”
Algorithmic Acceptability and Identity Threat
Beyond concerns about privacy, transparency, and disclosures, research on the psychology of automation highlights that consumers perceive algorithmic recommendations as lacking personalized value. This perception stems from several factors: that algorithms fail to capture unique human attributes (Dietvorst, Simmons, and Massey 2015; Longoni, Bonezzi, and Morewedge 2020), are too specialized and limit users’ ability to consider options outside of their past interests (Baccelloni et al. 2026), have opaque inner workings (Mols 2017), and are reductionistic in processing data (Bonezzi and Ostinelli 2021). In sum, being mischaracterized and reduced to a nonunique data point by an algorithm is problematic for self-identity. Prior research suggests that inaccurate group categorization diminishes an individual's sense of identity (Summers, Smith, and Reczek 2016); this effect is amplified when an individual feels reduced to a single group identity (Kim et al. 2023). Such categorization threats manifest when individuals’ sense of self is challenged in situations that (1) contradict personal values and beliefs, (2) go against one’s self-image, or (3) disregard unique characteristics (Branscombe and Wann 1994; Cavell 1985).
Building on these insights, we propose that a key distinction between consumer responses to recommendations based on processing of demographic versus behavioral data (differentiating also between responses to processing of individual and social group behavioral data) is the extent of individuality threat that they generate—arising from perceptions that AI misjudges individual characteristics when processing different data. Prior literature had already established that demographic data is closely tied to social identities and is an essential feature of the self (Haslam 2006). However, demographic data has also been shown to trigger psychological reactance (Van Doorn and Hoekstra 2013; White et al. 2008), feelings of intrusiveness (Newman, Fast, and Harmon 2020), and concerns about individual uniqueness (Longoni, Bonezzi, and Morewedge 2020), all of which negatively impact consumers’ behavior. Furthermore, the personalization–privacy paradox (Acquisti, John, and Loewenstein 2012) suggests that consumers simultaneously appreciate individualization while considering the limits of processing acceptability, reflecting doubts about the legitimacy of using certain data types. These two forces jointly shape consumers’ acceptance of algorithmic recommendations. To unpack this theoretical distinction, we propose a dual process (see Figure 1) explaining how these data types may influence recommendation acceptance. We predict that consumers will differ in their perception of processing acceptability for recommendations generated from individual behavioral data compared with those using demographic data. Similarly, we predict that individuality threat will be likely larger for recommendations arising from demographic data and lowest for those generated with individual behavioral data.
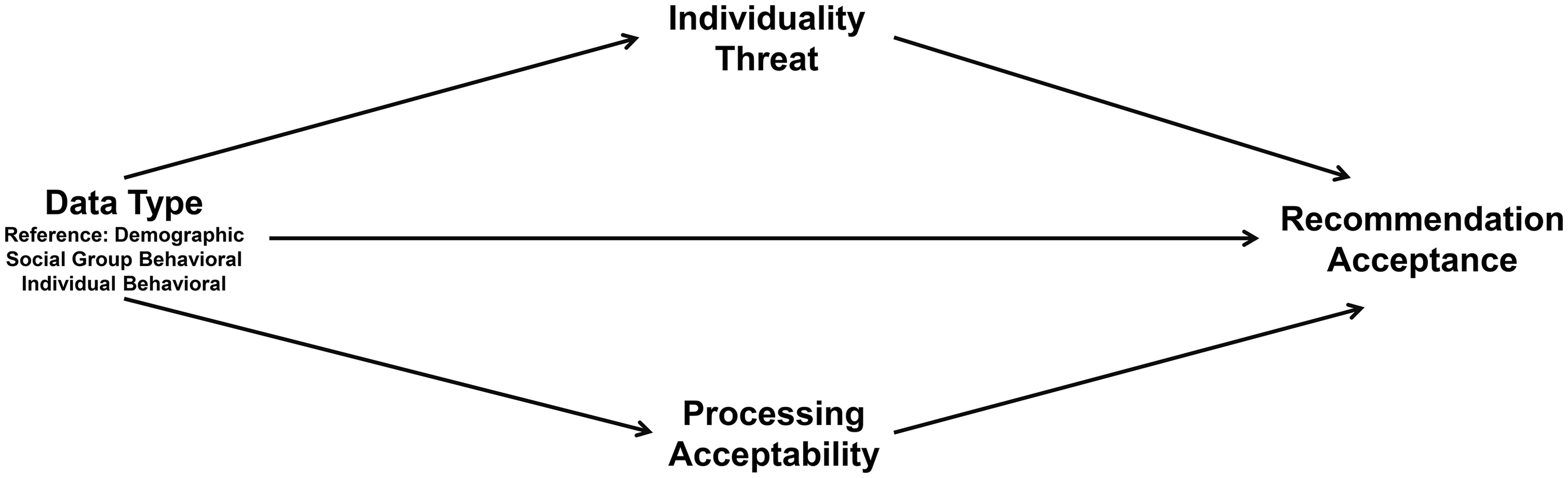
Overview of the Proposed Model.
Algorithmic Legitimacy
Examining the acceptability of processing different data types requires understanding its legitimacy antecedents. Legitimacy is commonly defined as a generalized perception that an entity or action is appropriate within a social framework of norms and values (Suchman 1995). Building on this foundation, Suddaby, Bitektine, and Haack (2017) distinguish three complementary concepts of legitimacy: legitimacy-as-property (conceived as a resource), legitimacy-as-process (an interaction), and legitimacy-as-perception (a sociocognitive evaluation). Recent work on algorithmic governance extends these ideas by identifying specific conditions that shape perceptions of legitimacy. For example, Waldman and Martin (2022) show that certain characteristics of data inputs, for example whether an input is considered discriminatory or arbitrary, influence whether algorithmic use is judged legitimate. Also, Waldman and Martin (2022) decompose legitimacy into input legitimacy (the appropriateness of data), output legitimacy (goal attainment), and process legitimacy (procedural fairness). To unpack acceptability of algorithmic processing in our setting, we propose legitimacy-related beliefs as key antecedents. Specifically, we operationalize two dimensions: functional legitimacy, reflecting the perceived usefulness and benefit of using particular data, and normative legitimacy, reflecting perceptions of the appropriateness and morality of such use.
Pilot Study: Confirming External Validity of Our Data Type Classifications
We ran a pilot study to confirm the external validity of our proposed data type classifications. To do so, we looked for publicly available data disclosures by leading search engines (e.g., Google), streaming platforms (e.g., YouTube, Netflix) and some of the most popular social networks (e.g., Facebook) based on Dixon's (2024) Statista report. We compiled descriptive statements explaining how their algorithms collect and process data to generate content recommendations. Additional relevant descriptions and explanations about data collection and processing were sourced from expert reports (e.g., Adisa 2023; Information Commissioner's Office 2022; Selerity SAS 2019; see Web Appendix A1, where statements sourced from expert reports are marked with “+”) to supplement our initial set, resulting in a total of 27 items. To make sense of the different items and derive insights from them, we recruited 140 participants from Prolific, of which 7 were excluded for failing attention checks (N = 133; 49.6% female, 48.9% male, 1.5% preferred not to say; Mage = 32.11 years, SD = 11.61). Participants rated acceptability of use of the 27 data processing items to generate recommendations on a seven-point scale (1 = “Very unacceptable,” and 7 = “Very acceptable”).
A principal components analysis with Varimax rotation yielded five factors, explaining 72.51% of the variance. Eight items lacking clear factor loadings were removed based on Aaker (1997). Repeating the analysis with 19 items generated four factors (Kaiser–Meyer–Olkin = .89; Bartlett's test of sphericity, p < .001) explaining 76.31% of the variance, with Cronbach's α = .95. These factors matched those labeled “individual behavioral data,” “social group behavioral data,” “demographic data,” and “device-temporal data” (see Web Appendix A2). The fourth data classification (“device-temporal data”) was excluded as being more situational. The analysis with three dispositional factors explained 75.45% of the variance (see Web Appendix A3).
A one-way within-subjects ANOVA revealed a significant difference in acceptability ratings across the three data types, with individual behavioral data being perceived as more appropriate than both social group behavioral data and demographic data (Mind = 5.63, SD = 1.05; Mgroup = 4.67, SD = 1.58; Mdemo = 3.89, SD = 1.71; F(2, 131) = 102.21, p < .001,
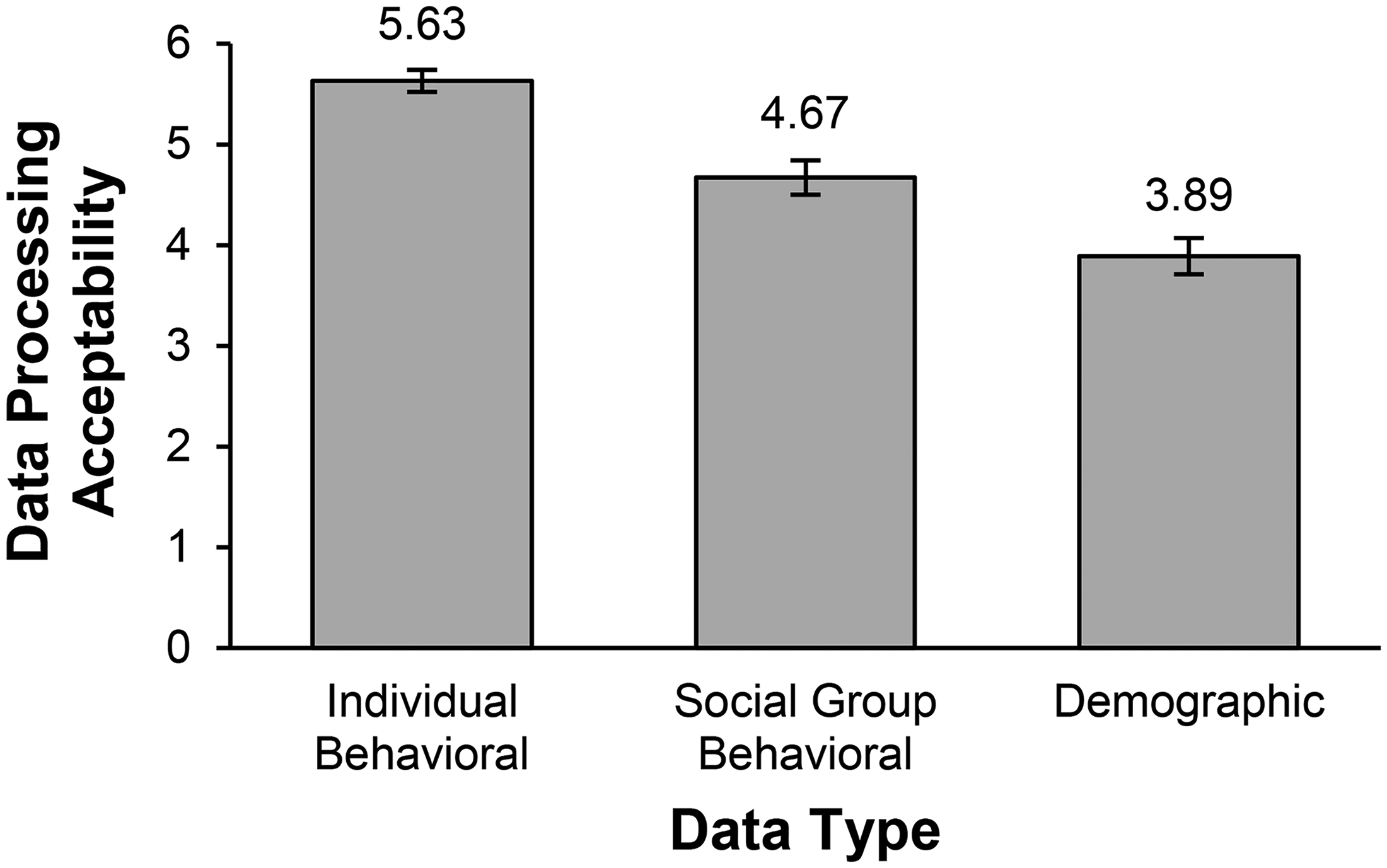
Level of Acceptability of Algorithmic Data Processing Across Data Types.
This pilot study confirms that individuals tend to categorize data-related disclosures into our three different data types under study. This is particularly important when evaluating the acceptability of their processing to provide recommendations. These results indicate that people draw meaningful distinctions between demographic and behavioral forms of data.
Overview of Studies
Our pilot study confirmed our theoretically motivated data types: (1) individual behavioral data, (2) social group behavioral data, and (3) demographic data. Four follow-up studies examine the underlying mechanisms (individuality threat and processing acceptability) that drive the effect of data types on the acceptance of algorithmic recommendations. In Study 1 we test our model in a hypothetical setting, which we replicate in Study 2 using a more consequential choice context. In Study 3 we test legitimacy antecedents of processing acceptability to better understand the reasons behind the variation in acceptability across different data types. Lastly, in Study 4, we test whether our proposed mediating framework (individuality threat and processing acceptability) robustly explains acceptance of algorithmic recommendations. In all these studies, we use demographic data as the baseline since this data type represents the benchmark case for both individuality and privacy threat. We report sample size, all data exclusions (if any), all manipulations, and all measures used (with sources from which they were adapted) in all our studies. Sample size was determined for a small-to-medium effect and three experimental conditions: G*Power recommended 50–100 participants per group.
Study 1: Data Type and Recommendation Acceptance (Hypothetical Scenario)
Study 1 provides evidence for the mediating role of individuality threat (participants’ belief that the processed data type poses a threat to their individuality and distinctive characteristics) and processing acceptability (participants' judgment of whether the processing of that data type is acceptable) in the relationship between data types and recommendation acceptance.
Procedure
We employed a hypothetical scenario related to an audio streaming app called Audio-GO, with a unique logo and a backstory. A total of 200 Prolific users were recruited, and after exclusion of 5 participants that failed both attention and manipulation checks, the final sample consisted of 195 participants (54.9% female, 42.5% male, 2.6% would rather not say; Mage = 37.52 years, SD = 12.79). Participants were presented with brief details about Audio-GO and its functionalities and then were randomly assigned to one of the three data conditions, each describing a different data type that would be processed to provide recommendations (refer to Web Appendices B1, B2, and B3). Subsequently, participants rated the extent to which each data type posed a threat to their individuality, how acceptable it was to be processed, and their likelihood of accepting recommendations. Control measures included technological affinity, familiarity with algorithms, and usage frequency. Lastly, participants were presented with filler questions capturing demographics and attention checks (refer to Web Appendix B4 for key measures).
Results
Results showed that data type has a significant effect on recommendation acceptance, individuality threat, and processing acceptability (refer to Web Appendix B5 for visual results).
Recommendation acceptance
Results revealed a significant effect of data type on recommendation acceptance (Mind = 4.67, SD = 1.52; Mgroup = 4.37, SD = 1.36; Mdemo = 3.66, SD = 1.64; F(2, 192) = 7.82, p < .001,
Individuality threat
Results revealed a significant main effect of data type on individuality threat (Mind = 2.52, SD = 1.36; Mgroup = 3.35, SD = 1.67; Mdemo = 4.01, SD = 1.85; F(2, 192) = 13.99, p < .001,
Processing acceptability
Results revealed a significant main effect of data type on processing acceptability (Mind = 5.22, SD = 1.41; Mgroup = 4.88, SD = 1.58; Mdemo = 4.01, SD = 1.81; F(2, 192) = 10.07, p < .001,
Mediation analysis
We ran a parallel mediation analysis using PROCESS (Hayes 2013; Model 4) with 5,000 bootstrap iterations at a 95% confidence interval, with data type as the independent variable, individuality threat and processing acceptability as parallel mediators, and recommendation acceptance as the dependent variable. The indirect effect of data type comparisons through both individuality threat and processing acceptability was significant for demographic data (reference) versus individual behavioral data and versus social group behavioral data. See Table 1 (refer to Web Appendix B6 for results including controls).
Path Analysis (Parallel Mediation).

Discussion
Our findings provide evidence that participants are more likely to accept algorithmic recommendations based on individual behavioral data and social group behavioral data compared with demographic data. This is attributed to heightened individuality threat and reduced processing acceptability of demographic data compared with the other two data types. We replicate these results in Study 2 using a more consequential context.
Study 2: Data Type and Recommendation Acceptance (Consequential Context)
In this study, we replicate Study 1 in an incentive-compatible context: Participants had the option of receiving the item recommended by the AI system. Additionally, the data type manipulation was operationalized differently: Participants were asked to input, in response to designated prompts, examples of specific types of data as if requested by a recommendation system (refer to Web Appendix C).
Procedure
Participants were invited to participate in a lab study in exchange for course credit. Following standard procedure, participants reviewed a consent form including an overview of the experiment. Participants were asked to provide personal examples of one of the following three data types (randomized): (1) demographics (age, gender, location, and ethnicity), (2) their recent online behavior (searches, comments, ratings, and shares), or (3) recent online behavior of close/similar social groups (searches, comments, ratings, and shares). At that point, they were informed that AI would be processing this data to provide a gum flavor recommendation from a set of four gum flavors, which they would receive as they exited the lab. They could either accept the suggested flavor or get a random flavor from the four options, each with an equal probability. In total, 135 participants were recruited, of which 3 were excluded (2 failed the attention checks and 1 did not finish the experiment), resulting in a sample of 132 participants (42.4% female, 57.6% male; Mage = 19.81 years, SD = 2.35).
Results
Results of this study replicate those of Study 1, demonstrating that data type had a significant main effect on recommendation acceptance, individuality threat, and processing acceptability.
Recommendation acceptance
A one-way ANOVA revealed a significant effect of data type on recommendation acceptance (Mind = 5.82, SD = 1.22; Mgroup = 4.63, SD = 1.43; Mdemo = 3.86, SD = 1.27; F(2, 130) = 25.48, p < .001,
Individuality threat
A one-way ANOVA revealed a significant main effect of data type on individuality threat (Mind = 3.13, SD = 1.27; Mgroup = 4.12, SD = 1.41; Mdemo = 4.43, SD = 1.13; F(2, 130) = 12.65, p < .001,
Processing acceptability
A one-way ANOVA revealed a significant main effect of data type on processing acceptability (Mind = 5.27, SD = 1.26; Mgroup = 4.63, SD = 1.07; Mdemo = 4.39, SD = 1.20; F(2, 130) = 6.56, p < .001,
Mediation analysis
We again ran a parallel mediation analysis using PROCESS (Hayes 2013; Model 4) with 5,000 bootstrap iterations at 95% confidence interval, with data type as the independent variable, individuality threat and processing acceptability as parallel mediators, and recommendation acceptance as the dependent variable. The indirect effect of data type comparisons through both individuality threat and processing acceptability was again significant for demographic data (reference) versus individual behavioral data but not versus social group behavioral data. See the path analysis in Table 2.
Path Analysis (Parallel Mediation).

Discussion
In this study, we replicated the finding that demographic data yields significantly lower recommendation acceptance compared with the other two data types. This effect was partially driven by processing acceptability and individuality threat when using individual behavioral instead of demographic data but not when using social group behavioral data.
Study 3: Perceived Legitimacy of Data Types
Study 3 unpacks the legitimacy antecedents of processing acceptability to provide a better understanding of the observed differences in acceptability across data types.
Procedure
Using the same design as Study 1 (Audio-GO streaming app), we recruited a total of 180 Prolific users. Three were excluded due to failed attention and manipulation checks, resulting in a final sample size of 177 participants (54.2% female, 41.8% male, 4.0% would rather not say; Mage = 39.23 years, SD = 14.60). Participants were randomly assigned to one of the three data type conditions, and focal variables were measured (see legitimacy measures in Web Appendix D).
Results
Again, results showed significant differences between data types for recommendation acceptance (Mind = 5.41, SD = 1.08; Mgroup = 4.66, SD = 1.48; Mdemo = 4.33, SD = 1.63; F(2, 174) = 8.95, p < .001,
Functional legitimacy
Results revealed a significant main effect of data type on functional legitimacy (Mind = 5.17, SD = 1.26; Mgroup = 4.97, SD = 1.61; Mdemo = 4.27, SD = 1.44; F(2, 174) = 6.35, p = .002,
Normative legitimacy
Results showed no significant effect of data type on normative legitimacy (Mind = 5.04, SD = 1.28; Mgroup = 5.05, SD = 1.52; Mdemo = 4.58, SD = 1.43; F(2, 174) = 2.11, p = .55,
Mediation analysis
Replicating prior findings, demographic data showed significantly lower recommendation acceptance and processing acceptability and higher individuality threat compared with the other two data types. As for antecedents of processing acceptability (i.e., legitimacy factors), the results showed that functional legitimacy is significantly lower for demographic data compared with both individual behavioral data and social group behavioral data, whereas we found no significant differences in normative legitimacy across the different data types. Running a parallel mediation analysis using PROCESS (Hayes 2013; Model 4) with similar specifications as in our previous studies, we observed similar indirect effects. See Table 3 (refer to Web Appendix E for results including controls).
Path Analysis (Parallel Mediation).

We then ran a serial-parallel mediation analysis using PROCESS (Hayes 2013; Model 6) with 5,000 bootstrap iterations at a 95% confidence interval, with data types as the independent variable, individuality threat and processing acceptability as parallel mediators, functional and normative legitimacy as antecedents of processing acceptability, and recommendation acceptance as the dependent variable. Results showed that functional legitimacy has a significant effect on processing acceptability, while normative legitimacy does not. See Table 4 (See Web Appendix E for results with controls).
Path Analysis (Serial-Parallel Mediation).

Discussion
We unpacked two forms of legitimacy that contribute to our theoretical model: normative and functional, serving as antecedents of processing acceptability. Results indicate that functional legitimacy significantly impacts processing acceptability, whereas normative legitimacy does not. Thus, compared with demographic data, using either individual behavioral or social group behavioral data is perceived to have higher functional legitimacy, hence increasing processing acceptability and resulting in higher recommendation acceptance.
Study 4: Predicting Acceptability of Full Theoretical Model
The goal of Study 4 is to test the predictive validity of our full theoretical framework. This study was preregistered (https://aspredicted.org/x2ut57.pdf; ResearchBox #5282).
Procedure
A total of 300 Prolific users were recruited (52.8% female, 46.2% male, 1.0% would rather not say; Mage = 45.71 years, SD = 13.15, no exclusions) and asked to rate nine sanitized statements (see Web Appendix F) representing our three different data types (three items each) across our variables of interest (recommendation acceptance, processing acceptability, and individuality threat) on a seven-point scale (1 = “Not at all,” and 7 = “Very much”). Following that, we ran a linear mixed-effects model with random intercepts for participants and data type items to test the extent to which recommendation acceptance is predicted using our two process variables (Web Appendix G for model specification and variables).
Results
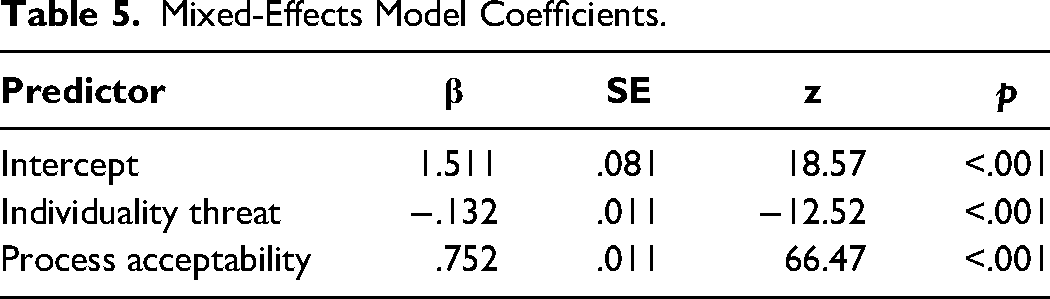
The model results (see Table 5) confirm the predictive power of both process variables in explaining recommendation acceptance (β = −.13, SE = .01, p < .001, for individuality threat, and β = .75, SE = .01, p < .001, for process acceptability; see Table 5 for details).
Mixed-Effects Model Coefficients.
Discussion
This analysis demonstrated that participants’ acceptance of algorithmic recommendations is systematically shaped by process acceptability and individuality threat. Based on the different statements representing data types, higher process acceptability consistently predicted greater recommendation acceptance, whereas higher individuality threat predicted lower recommendation acceptance. The inclusion of random intercepts for both participants and items revealed meaningful variability in baseline acceptance across individuals and data items. Nevertheless, the fixed effects remained robust, confirming that these two psychological dimensions reliably account for differences in acceptance judgments. Together, the findings support the validity of our proposed framework.
General Discussion
Based on theoretical distinction, further confirmed by consumers’ own mental categorization of data statements used by media companies (pilot study), we identify three categories of consumers’ data: individual behavioral, social group behavioral, and demographic data. Through three studies we provide evidence of two drivers influencing how the acceptance of AI-generated recommendations may be driven by the data type used: (1) the acceptability of the data being processed and (2) the potential threat to one's individuality. These two mechanisms are rooted in the literature, which establishes that algorithms fundamentally generalize beyond the data points in the training set (Domingos 2012) and then identifies the personalization–privacy paradox (Acquisti, John, and Loewenstein 2012): Demographic data is closely tied to social identities (Haslam 2006) but has been shown to trigger psychological reactance (Van Doorn and Hoekstra 2013; White et al. 2008). In fact, our results support that consumers’ responses to recommendations based on behavioral descriptives are generally more positive than those based on demographic data. Study 1 confirmed that when recommendations are based on demographics instead of on individual behavioral or social group behavioral data, this is likely to trigger individuality threat and, interestingly, be considered less appropriate for processing, ultimately decreasing recommendation acceptance. Study 2 replicated this pattern in a more consequential context. In Study 3 we unpacked the antecedents of processing acceptability, focusing on functional legitimacy (the benefit of processing a specific data type) and normative legitimacy (moral appropriateness of processing a specific data type). We find that demographic data is seen as significantly less appropriate because of its functional legitimacy compared with both individual behavioral and social group behavioral data. However, no significant differences were observed for normative legitimacy, indicating that ethical judgments do not drive differences across data types. Finally, Study 4 tested the predictive validity of our full theoretical framework. Results confirm that individuality threat is a robust driver of acceptance across different data types, but process acceptability can have an even stronger explanatory value.
Theoretical Implications
Our research contributes to ongoing discussions on consumer reactions to different data types (Kim, Barasz, and John 2019), to privacy notices (Brough et al. 2022) and to AI disclosures (Querci et al. 2022; Tomaino et al. 2022). It also adds to the literature characterizing the tension between consumers’ reactance to identity threat from being categorized (White and Argo 2009) and the questionable legitimacy companies have when using personal data (Martin and Waldman 2023; Waldman and Martin 2022). We emphasize that although demographic data is believed to be closely tied to social identities and self attributes (Haslam 2006), it is perceived as imposing greater individuality threat and seen as less acceptable to be processed. This is because behavioral descriptors (particularly when individualized) are understood as having the highest predictive value when processed for recommendation generation and, unexpectedly, do not elicit a moral concern. Overall, demographic data is perceived as the most challenging to individuality, the least capable of providing functional benefits, and the least acceptable when processed, which evidently results in a reduction in recommendation acceptance.
Managerial Implications, Limitation and Future Research
Our findings offer valuable insights for both managers and AI developers. For example, our evidence supports that users are much more averse to having their demographic than their behavioral data processed for generating recommendations because they favor functional over moral value. In fact, consumers perceive that there is a lower threat to their individuality when recommendations are made using personal behavioral data. Consequently, managers and developers should redefine their approach to communicating data processing practices given that users often prioritize convenience and pragmatism over moral and ethical considerations.
Although our results provide a starting point to understanding the impact of data types used to provide recommendations on acceptance, we do acknowledge that our studies have limitations due to their context and settings. Our findings may not hold for personally relevant or embarrassing contexts. However, they may be augmented for high-stakes information/decisions. We advocate for future research to explore these numerous contexts and settings in which the types of data used to make recommendations may differentially influence consumer responses.
Supplemental Material
sj-pdf-1-jnm-10.1177_10949968261423544 - Supplemental material for Theory of Machine: Lay Beliefs About Algorithmic Data Processing Drive Recommendation Acceptance
Supplemental material, sj-pdf-1-jnm-10.1177_10949968261423544 for Theory of Machine: Lay Beliefs About Algorithmic Data Processing Drive Recommendation Acceptance by Alcheikh Edmond Kozah and Ana Valenzuela in Journal of Interactive Marketing
Footnotes
Acknowledgments
The authors would like to thank Kimia Latifi for her comments, and the participants at the SIM Doctoral Colloquium (Rimini), EMAC 2024 (Bucharest), and ACR 2025 (Washington, DC) for their helpful feedback on a working version of this article.
Coeditor
Peeter Verlegh
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors acknowledge the funding received to the second author by Project PID2023-150757NB-I00, financed by MICIU/AEI/10.13039/501100011033 and by FEDER, UE.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.