
Abstract
Vocabulary learning is basic for mastering a foreign language. Many students learn foreign language (FL) vocabulary via instructional videos outside of traditional classrooms, as there is no limit to time or space. Cues (e.g. coloring, highlighting, arrows, and text) are design features in instructional videos that not only guide learners’ attention, but also facilitate the organization and integration of information. However, little is known about how visual cues and text cues influence FL vocabulary learning from instructional videos. In Experiment 1, we tested the effects of synonym text cues presented before the instructional video and visual cues during the video. Effects were measured in terms of participants’ judgments of learning and objective measures of learning performance (indicated by accuracy on immediate and delayed tests). Learners showed highest accuracy in the text cues condition, followed by the visual cues condition, and finally the no cues condition. In Experiment 2, we tested the neural oscillatory correlates of cues in FL vocabulary instructional videos based on electroencephalogram (EEG) evidence of frontal theta and frontal-parietal alpha power. Compared to visual cues during the video, text cues before the video elicited higher frontal theta power, suggesting higher working memory processing, at the early stage of learning from instructional videos. The results of this study have implications for designing effective FL vocabulary instructional videos with cues.
I Introduction
Vocabulary learning is essential for mastering a foreign language (FL), but it can be arduous for FL learners (Schmitt, 2008). Many learners acquire FL vocabulary via instructional videos outside of traditional classrooms, as there is no limit to time and space (Montero Perez et al., 2018; Pi, Zhang, et al., 2021; Pi, Zhu, et al., 2021). However, compared to other learning materials, the temporal change in a visual display may demand higher working memory load to extract thematically relevant information. According to cognitive load theory, learners’ working memory capacity is limited (Sweller, 2011). As a consequence, learners can only pay attention to a certain amount of information at one time while viewing instructional videos. To be successful in building high-quality mental models, learners have to exactly and in a timely manner pay attention to relevant information, organize this information into coherent mental representations in working memory, and integrate it with their prior knowledge contained in long-term memory (Mayer & Fiorella, 2022).
When learning new FL vocabulary, learners often have difficulty in concentrating on the target word and memorizing it (Laufer, 2005). Thus, researchers have explored approaches that can increase the salience of the new words to make them easier to notice (e.g. Y. Hsieh, 2020; Montero Perez, 2019; Teng, 2022). According to the signaling (or cueing) principle, learners learn better when cues are added to highlight the key information in the multimedia materials (van Gog, 2022). Cues (e.g. coloring, highlighting, arrows, and text) as design features in instructional videos not only quickly guide learners’ attention to the target word, but also facilitate learners’ organization and integration of knowledge (De Koning et al., 2009; Mautone & Mayer, 2001; Montero Perez, 2019; van Gog, 2022; X. Wang et al., 2020). As a consequence, cues can free up learners’ limited cognitive resources to engage in generative learning processes.
Visual cues and text cues are commonly used in FL vocabulary instructional videos, and they appear to play distinct roles in FL vocabulary learning (Y. Hsieh, 2020; Montero Perez, 2019; Montero Perez et al., 2014; Teng, 2022). To be specific, simple visual cues (e.g. coloring, highlighting, and arrows) are thought to help direct learners’ attention to those aspects of the learning materials that are most important, such as the target vocabulary word (van Gog, 2022). Simple visual cues make information more perceptually salient and they are used to emphasize the critical ideas in instructional videos. Therefore, adding visual cues to FL vocabulary instructional videos is particularly important in the first step of selecting information (i.e. locating the target vocabulary word). However, it may not be sufficient for learners’ organization and integration of information.
Unlike simple visual cues, text cues are thought to play a role not in directing learners’ attention, but in facilitating the organization and integration of information (X. Wang et al., 2020). In particular, adding text cues before presenting learning materials may increase the salience of the target word and facilitate learners’ cognitive processing, a phenomenon called the semantic priming effect (McNamara, 2005; Montero Perez, 2019; Pellicer-Sánchez et al., 2022). Semantic priming has been shown to help learners attend to the relevant information in a dynamic representation and to facilitate memory of subsequent learning materials (Belke et al., 2008; Moores et al., 2003). Therefore, we compared FL vocabulary learning in three conditions: text cues given before instructional videos, visual cues during instructional videos, and no cues either before or during the videos.
1 Simple visual cues during FL vocabulary instructional videos
Learners have been shown to automatically focus more on information with high perceptual salience than on information that is domain relevant (Arslan-Ari, 2018; Lowe, 2003). This tendency is in line with van Gog’s (2022) assertion that learning from instructional videos can be improved by adding visual cues. The effect of visual cues is an example of the well-known signaling (or cueing) principle of learning. Cues have many forms (Mautone & Mayer, 2001). Simple visual cues, such as coloring, highlighting, and arrows, are commonly used in instructional videos (Pi et al., 2017; X. Wang et al., 2020). Those cues are symbols that highlight important information but do not provide additional information (van Gog, 2022).
However, there have been inconsistent results regarding the learning effects of visual cues in instructional videos (Ibrahim et al., 2012; Pi et al., 2017; X. Wang et al., 2020). Some studies of learning from instructional videos have reported positive impacts of simple visual cues (Ibrahim et al., 2012; X. Wang et al., 2020). For example, X. Wang et al. (2020) used lines, highlighting, coloring, and dots as visual cues in the instructional video. Learners spent more time focusing on the areas with cues, and showed better learning performance, when they viewed a video with cues than when they viewed a video without cues. Another study on FL vocabulary learning from videos also found that highlighting the target words supported learning the word form (Y. Hsieh, 2020).
However, other studies have shown that simple visual cues did not improve learning from animations that were similar to instructional videos (Crooks et al., 2012; L. Lin & Atkinson, 2011; Montero Perez et al., 2014). For example, Montero Perez et al. (2014) reported that the use of highlighting in an instructional video did not boost the recall of FL vocabulary meaning. This null result might have been due to a competition between the attention to FL vocabulary’ form and meaning.
2 Text cues during and preceding instructional videos in learning FL vocabulary
Text cues are another form of cue used in instructional videos. Text cues include words, sentences, headers, summaries, captions, and subtitles that are inserted into learning materials for the purpose of guiding attention to the most important information (e.g. Barón & Celaya, 2022; Hayes & Reinking, 1991). Text cues are often presented along with the ongoing narration in instructional videos (Tarchi et al., 2021; X. Wang et al., 2020). Text cues do not add new information beyond what is provided by the learning materials (Mautone & Mayer, 2001). However, text cues can guide learners’ cognitive processes by making the semantic content and structure of an expository text more explicit (Mautone & Mayer, 2001). Therefore, text cues may not only guide learners’ attention toward essential information, but also help the learner organize and integrate information from different sources. A common example is the effect of captioning that is presented along with a video. Learners acquire verbal information by attending to captions and sounds; they acquire visual information from an external source such as text that complements the video. They organize the information from different sources, activate related prior knowledge as an internal source of information, and construct both a coherent propositional representation and a coherent mental model.
However, the empirical evidence has been inconsistent with regard to the effects of traditional text cues on learning from instructional videos. Teng (2019, 2022) found that captions as text cues in vocabulary instructional videos had two key benefits. Specifically, they enhanced the recognition of word form and meaning, and they improved recall of word meaning. However, Tarchi et al. (2021) found that adding captions as text cues to the ongoing narration in an instructional video did not improve learning performance. They concluded that subtitles are not effective because they overload the learners’ visual channel in automatically-paced instructional videos.
Text cues can also precede the learning materials and explain the upcoming learning tasks. Recent studies found that presenting text cues before the learning materials may be helpful because text cues increase the salience of the target word and facilitate learners’ cognitive processing (Montero Perez, 2019; Pellicer-Sánchez et al., 2022). Research on memory and cognition has shown that adding text cues before learning materials not only improves learners’ attention to subsequent learning materials, but also improves memory and recognition of the materials (Moores et al., 2003; Was et al., 2019). Several studies have shown better FL vocabulary learning from instructional videos when presented with text cues before the video (e.g. presenting the words that would be learned in the video) (Montero Perez, 2019; Teng, 2022; Webb, 2009).
Synonyms are commonplace text cues. These are words that have the same meaning as the target word. Presenting synonyms before learning can activate learners’ prior knowledge and help them develop a conceptual framework to process the subsequent learning materials (Li, 2014; McNamara, 2005; Moores et al., 2003). Therefore, presenting synonyms might have a semantic priming effect without overloading the learners’ visual channel (Belke et al., 2008; Moores et al., 2003). Learners respond more quickly and/or accurately to the target word when they have pre-processed semantically related information (e.g. synonyms) than when they have pre-processed semantically unrelated information (McNamara, 2005). For example, when ‘start’ is used as the priming stimulus, it will facilitate learners’ response to ‘initiation’ (the target stimulus), but there will be no benefit if the word ‘start’ is replaced with the unrelated word ‘bread’.
The benefits of text cues before learning are related to memory and recognition of the proceeding materials. The benefits can be explained by the retrieval hypothesis. This hypothesis postulates that text cues before learning are beneficial because they trigger the retrieval of previously learned information from long-term memory (Koh et al., 2018; Lachner et al., 2020). Retrieving information from memory may foster learning through a process of consolidation (Waldeyer et al., 2020), as retrieval intensifies potential retrieval cues (Rowland, 2014) and helps learners build up new retrieval cues as a function of spreading activation (Carpenter, 2009; Endres et al., 2017; Rowland, 2014). However, despite considerable research on attention and memory, it is still not clear how text cues presented before an FL vocabulary instructional video can affect learning processes and learning performance.
3 Using electroencephalogram (EEG) technology to study the effects of cues on learning from instructional videos
EEG signals at certain frequencies provide indirect evidence of various cognitive processes related to memory and attention in real time, and they are key components of building high-quality mental models (Fink & Benedek, 2014; Pi, Zhu, et al., 2021; C. Wang et al., 2016). In particular, frontal theta band (4–8 Hz) oscillations are an indicator of working memory processing, and an increase in frontal theta power is positively related to increased working memory storage demands (Solomon et al., 2021). Converging evidence on domain-general cognitive control also indicates that frontal theta power increases during performance of various cognitive tasks involving top-down processing (e.g. go/no-go visuo-spatial task, extrinsic affective Simon task, Stroop task; Cavanagh & Frank, 2014; Fellrath et al., 2016; Jia et al., 2020).
Furthermore, frontal and posterior parietal alpha band (8–12 Hz) oscillations are an indicator of internal attention and inhibition of sensory (bottom-up) processing (Benedek et al., 2011). Specifically, frontal alpha power has been shown to increase during performance of internal attention tasks (e.g. creative idea generation, a Sternberg-like task) (Benedek et al., 2011), whereas parietal alpha power has been shown to increase during the suppression of distracting information flow from the visual system (Jensen et al., 2002). Frontal alpha power exerts top-down control over posterior regions, a process that might be mediated by functional coupling between these brain regions (Klimesch et al., 2007).
There is an emerging literature on the neural mechanisms of learning from instructional videos. Some of these studies have used EEG technology to measure learners’ cognitive load, memory encoding, internal attention, and inhibition of distracting information (Castro-Meneses et al., 2020; Pi, Zhang, et al., 2021). For example, a recent study conducted by Pi, Zhang, et al. (2021) tested theta power and alpha power in learners who used either a generative learning strategy (explaining to oneself or explaining to a peer) or a passive viewing strategy while viewing FL vocabulary instructional videos. The researchers observed that compared to the passive viewing strategy, the generative learning strategy enhanced theta power and alpha power in most regions. They attributed the greater oscillations in the theta band and alpha band to the working memory and internal attention processes required by generative learning. Two other studies on instructional videos found higher theta power when the video was linguistically complex, and when the instructor in the video could be heard but did not appear on the screen (Castro-Meneses et al., 2020; X. Wang et al., 2020). The results suggest that theta was a consistent indicator of cognitive load when viewing instructional videos.
4 The current study
The present study aimed to test the effects of cues presented during and before FL vocabulary instructional videos. We raised the research question: What are the effects of the cues, i.e. visual and text cues, on learning FL vocabulary? We conducted two experiments. In Experiment 1, we tested the effects of visual cues during the video and text cues presented before the video on learner behavior. We used color as a visual cue (during the video) and used synonyms as text cues (before the video). The effects on learners were assessed by their judgments of learning, as well as immediate and delayed learning performance. In Experiment 2, we tested the effects of cues on EEG assessments of theta and alpha power.
II Experiment 1
1 Aim and hypotheses
In Experiment 1 we examined whether visual cues in FL vocabulary instructional videos, and text cues preceding FL videos, enhanced subjective judgement of learning and objective learning performance. There were three conditions in a repeated measures design: (1) a set of short FL vocabulary instructional videos with visual cues, (2) a set of short FL vocabulary instructional videos preceded by text cues, and (3) a set of short FL vocabulary instructional videos without cues. Subjective judgment of learning was measured by the Judgment of Learning Scale (Serra & Dunlosky, 2010), and learning performance was separately assessed by immediate and delayed tests. Based on the semantic prime effect and the retrieval hypothesis, we assumed that text cues prior to videos would not only guide learners’ attention to subsequent learning materials, but also activate learners’ prior knowledge and facilitate their organization and integration of information; these benefits could be expected to exceed those from visual cues.
Therefore, we hypothesizedthat:
Hypothesis 1: Learners’ judgment of learning would be highest when text cues preceded the video; followed by when the video included visual cues; and finally when there were no cues before or during the video.
Hypothesis 2: Learners would show the best immediate and delayed learning performance (indicated by accuracy) when text cues preceded the video; followed by when the video included visual cues; and finally when there were no cues before or during the video.
2 Method
a Participants and design
The participants in Experiment 1 were 30 university students (20 females and 10 males) recruited from a Chinese university. They were between 20 and 26 years old (M = 22.6, SD = 1.54). All had passed the College English Test 6 (CET-6; a national English examination), which was important because the learning content was English vocabulary words from the Graduate Record Examination (GRE). All of the participants signed the consent forms and received a small reward (20 Chinese Yuan, CNY) at the end of the experiment. The study was approved by the local ethics committee.
A within-participants design was used for Experiment 1. Each participant was asked to watch an instructional video made up of 90 short video clips to learn 90 English vocabulary words (three sets of 30 words; Pi, Zhu, et al., 2021), under three different conditions: the visual cues condition (cues presented during the video), the text cues condition (cues presented before the video), and the control condition. The different instructional videos were assigned to each participant in a random order to counterbalance the video order.
b Video clips
We created 90 short video clips, each of which focused on one of 90 English vocabulary words (Pi, Zhang, et al., 2021; Pi, Zhu, et al., 2021; see Appendix 1, Table 2, Table 3, and Table 4). English is a foreign language for Chinese (Pi, Zhang, et al., 2021; Pi, Zhu, et al., 2021; Zhou & Wang, 2021). The clips were randomly divided to create videos for use in the visual cues condition, text cues condition, and control condition (30 short video clips for each condition; videos for three conditions can be found at https://osf.io/usgeh/?view_only=7b914b0398334b439fb9ce335c9e25e8). The result of one-way ANOVA showed no difference in the length of the words among the three conditions, F(2, 87) = 2.19, p = .118, ηp2 = 0.05. Twenty volunteers were invited to rate the three sets of words on two dimensions. The volunteers rated the word’s difficulty from 1 (extremely easy) to 7 (extremely difficult). They rated the word’s familiarity from 1 (extremely (extremely unfamiliar) to 7 (extremely familiar). No differences were observed in difficulty, F(1.27, 24.20) = 2.54, p = .118, ηp2 = 0.12 (Greenhouse–Geisser corrected for non-sphericity) or familiarity, F(2, 38) = 2.92, p = .066, ηp2 = 0.13. In addition, two English professionals reported that the three sets of words had similar orthography.
The duration of one video clip ranged from 6 s to 16 s in the visual cues condition, from 6 s to 14 s in the text cues condition, and from 7 s to 14 s in the control condition. In each video clip, the same female teacher orally explained, along with slides, the target FL word’s pronunciation, part of speech, corresponding Chinese meaning, an example sentence using the word, and the word’s synonyms (i.e. frequently used words that had a similar meaning to the target word, selected from the Corpus of Contemporary American English; Pi, Zhang, et al., 2021; Pi, Zhu, et al., 2021; Pi et al., 2022, 2023).
In the visual cues condition, participants first viewed a blank slide for 3,000 ms. Afterwards, they viewed a short FL word video clip that included the target word in red and three extra words in black; see Figure 1a. It should be noted that the four words included in the clip (one in red, three in black) were all selected from the 30 vocabulary words for that condition. Therefore, each word appeared the same number of times in each condition.
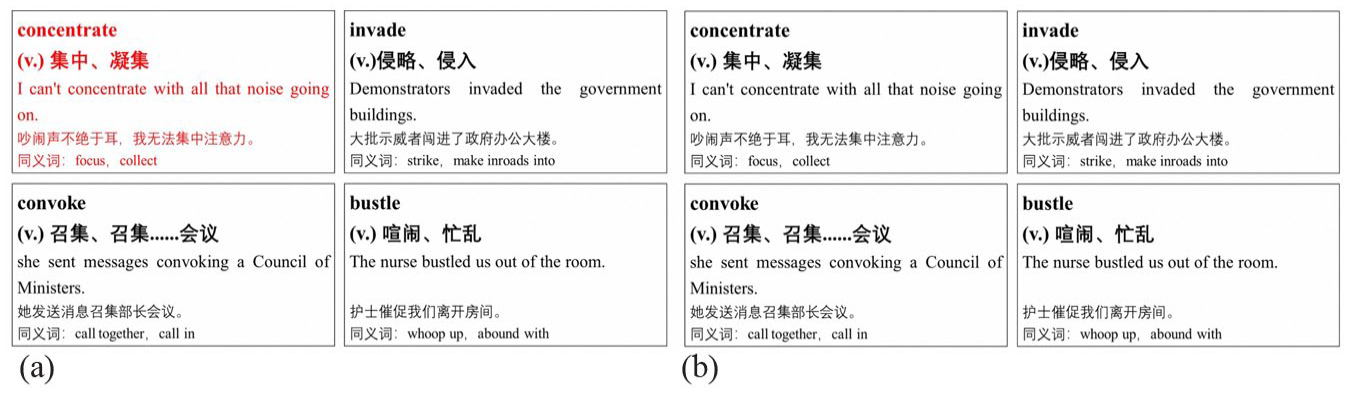
Examples of video clips under each condition: The color red is the visual cue; (a) visual cues condition; and (b) text cues and control conditions.
In the text cues condition, participants first viewed a slide presenting one target word and its synonyms (Figure 2) for 3,000 ms. Participants learned the synonyms during secondary and undergraduate study and frequently used them. Then they viewed a short FL word video clip presenting four words in black: the target word and the other three words; see Figure 1b. In each video clip, four vocabulary words were presented on the screen and the word in red was the one to be learned (the visual cues condition) or cued by text preceding the video clip (the text cues condition). In the control condition, participants first viewed a blank slide for 3,000 ms. Then they viewed a short FL word instructional video clip presenting four words without coloring (one target word to be learned and the other three words as distractors).
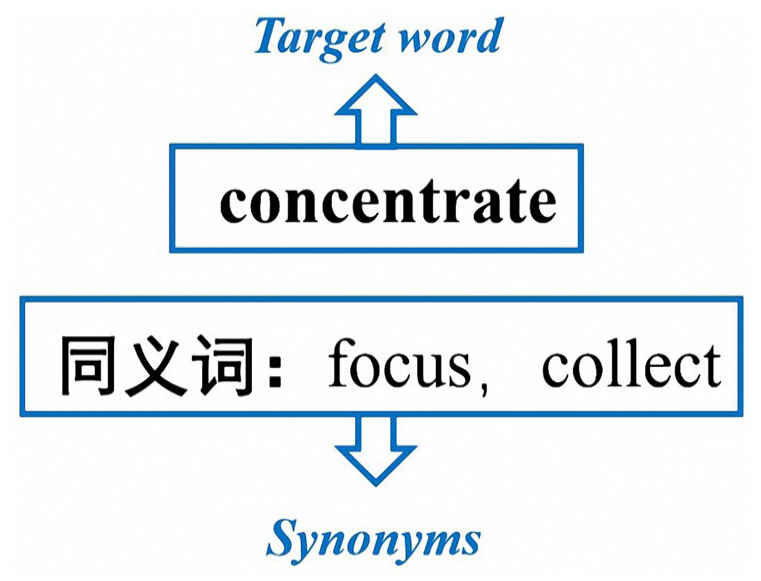
Example of text cues.
c Measures
Judgment of learning (JOL)
The three-item Judgment of Learning Scale (Serra & Dunlosky, 2010) was used to measure participants’ beliefs about their ability to perform the task (e.g. ‘How confident are you in answering the subsequent questions correctly?’). Participants rated all items from 1 (not at all confident) to 100 (extremely confident). The higher the score, the more confident the participants were in their ability to perform the task. Cronbach’s alpha for the scale was 0.96.
Learning performance tests
Three immediate tests and three delayed tests developed by two university professors of English were used to assess learning performance, defined as the participants’ mastery of the FL vocabulary in each condition. Each test included 30 multiple-choice questions with four alternative answers, only one of which was correct, and the three incorrect choices were words that were also learned in the videos. For example: _________ is the lack of symmetry. A. Asymmetry; B. Rudimentary; C. Redemption; D. Noxious.
To choose the correct answer, participants were required to memorize the English vocabulary words and understand their meaning. Participants were given five points for each correct answer and no points for each incorrect answer. Participants could score up to 30 points on each learning performance test. The internal reliabilities of each immediate test and delayed test were satisfactory (immediate test of visual cues condition, Cronbach’s α = 0.85; delayed test of visual cues condition, Cronbach’s α = 0.79; immediate test of text cues condition, Cronbach’s α = 0.75; delayed test of text cues condition, Cronbach’s α = 0.77; immediate test of control condition, Cronbach’s α = 0.86; delayed test of control condition, Cronbach’s α = 0.82). Accuracy was used as an explicit indicator in the immediate and delayed learning performance tests.
d Procedure
Participants individually completed the experiment in about 60 minutes in a computer laboratory. Before starting the experiment, all participants filled out the demographic information form and learned about the experimental procedure. After viewing the 30 short FL vocabulary instructional video clips under one condition, they immediately filled out the JOL scale and the corresponding immediate FL vocabulary performance test. This procedure was repeated for the FL words in the other two conditions. One week later, all participants completed three delayed FL vocabulary performance tests (one for each of the three conditions).
3 Results
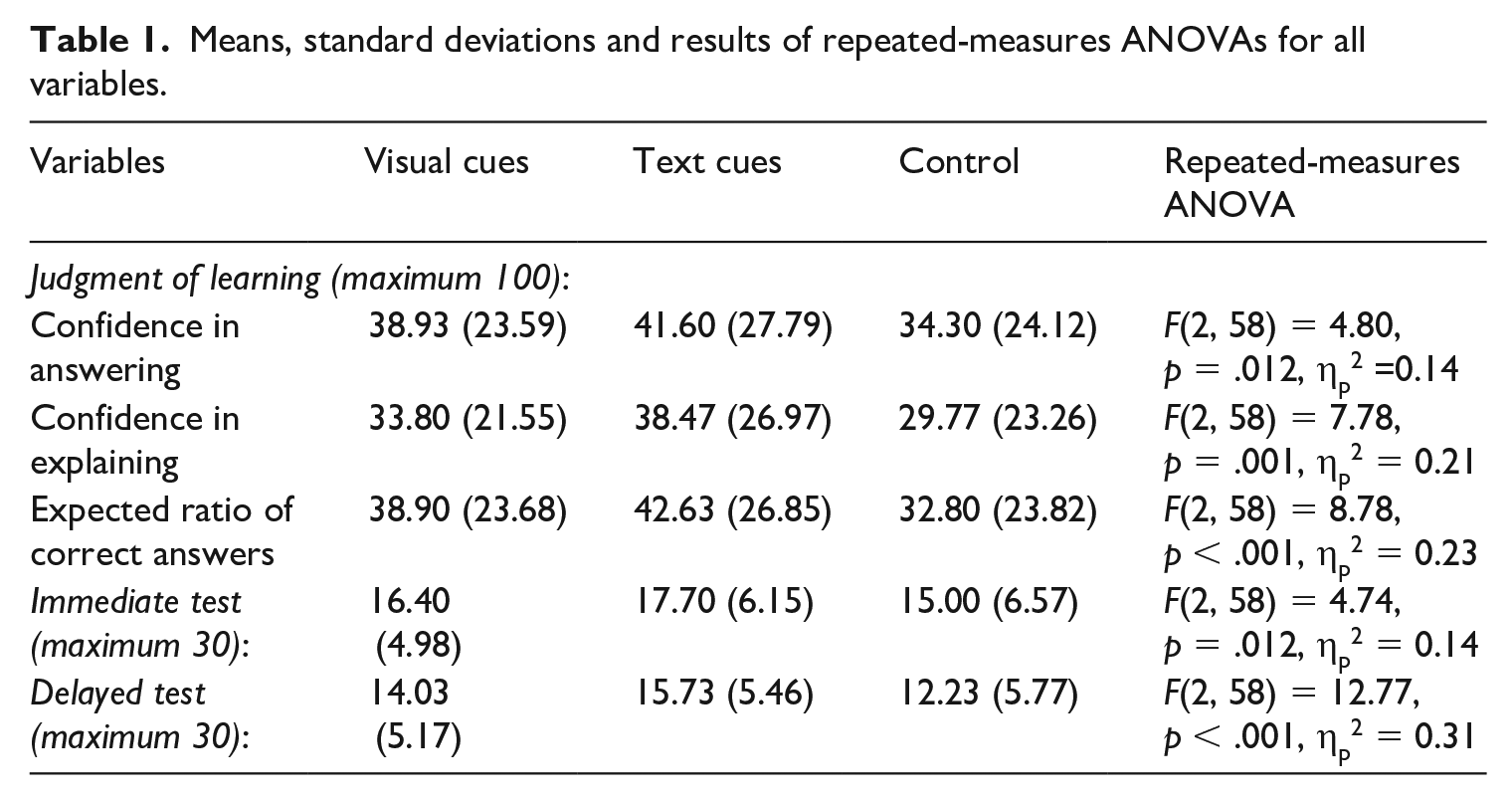
Five repeated-measures ANOVAs were conducted to test for differences in JOL (three items) and accuracy (immediate and delayed) across the three conditions (visual cues vs. text cues vs. control). The descriptive statistics and results of the repeated-measures ANOVAs for all variables are shown in Table 1.
Means, standard deviations and results of repeated-measures ANOVAs for all variables.
a JOL
To follow up on the significant repeated measures analysis for each of the JOL items (see Table 1), we compared the mean scores obtained in each condition (see Figure 3). Post hoc tests (LSD) showed higher confidence in answering the subsequent questions correctly in the visual cues and text cues conditions than in the control condition (respectively, MD = 4.63, p = .053; MD = 7.30, p = .004). Concerning the confidence in explaining, the text cues condition had higher scores than the visual cues and control conditions (respectively, MD = 8.70, p < .001; MD = 4.67, p = .060). Likewise, the visual cues and text cues conditions showed a higher expected ratio of correct answers than the control condition (respectively, MD = 6.10, p = .019; MD = 9.83, p < .001). No other significant difference was found. The results partly supported Hypothesis 1.
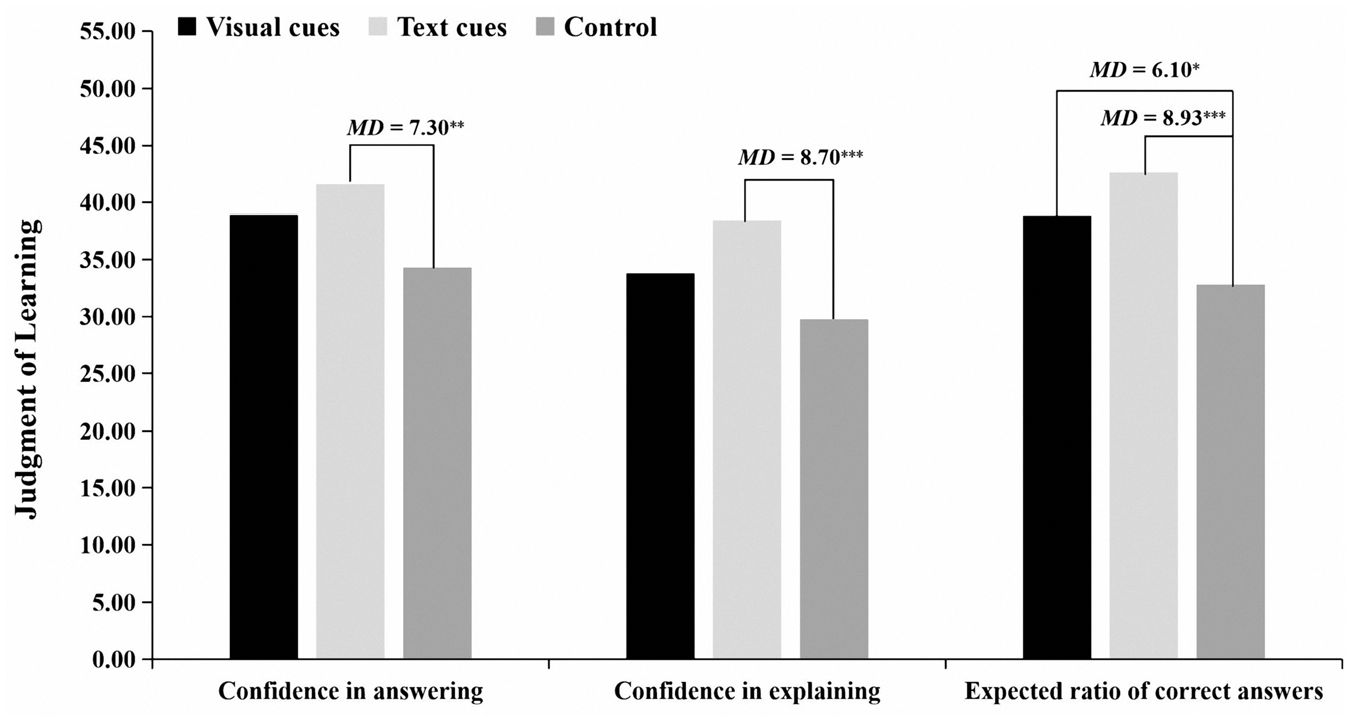
Mean scores on each of the three Judgment of Learning Scale items, in three conditions.
b Accuracy
To follow up on the significant repeated measures analysis for the immediate accuracy test scores (see Table 1), we compared the mean scores obtained in each condition (see Figure 4). Post hoc tests found higher immediate test accuracy in the text cues condition than in the control condition (MD = 2.70, p = .010). No other significant difference was found (ps > .05).
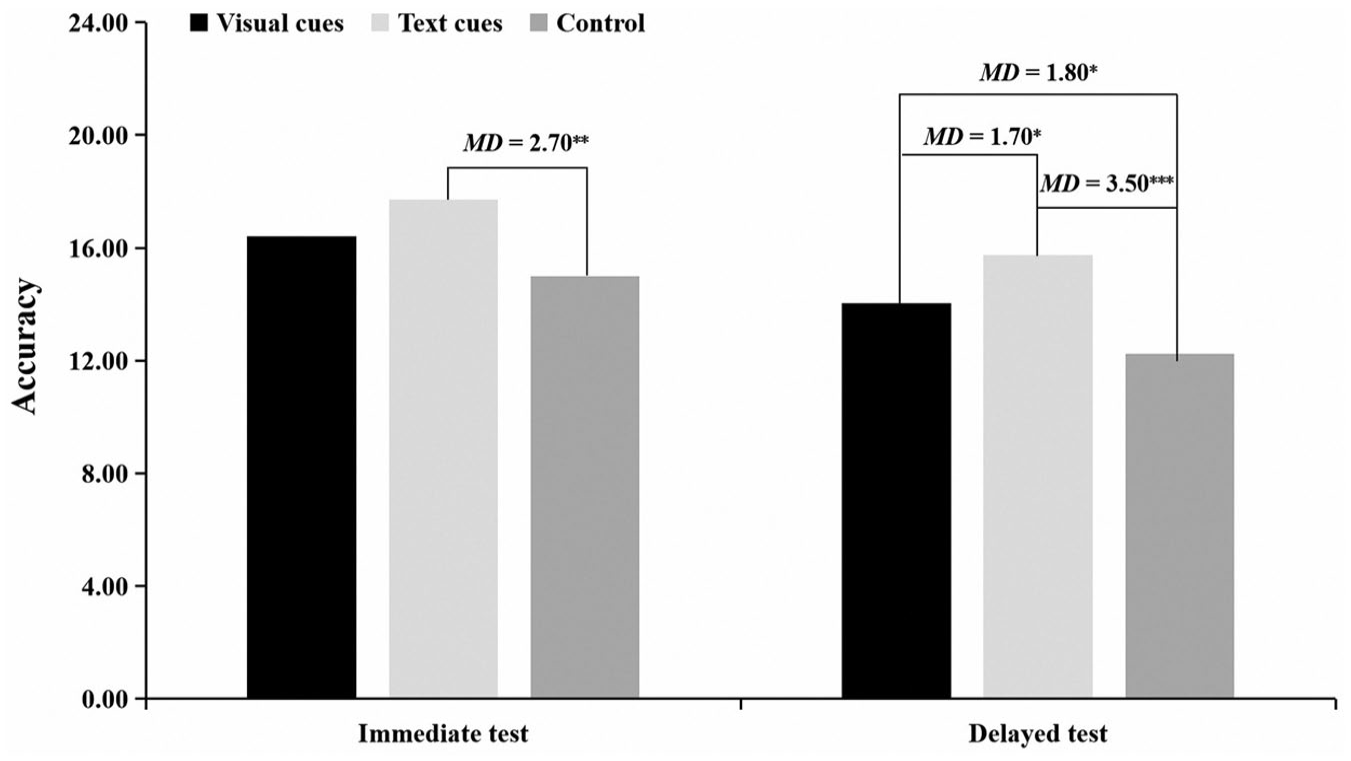
Differences in immediate and delayed accuracy across three conditions.
Similarly, to follow up on the significant repeated measures analysis for the delayed test (see Table 1), we compared the mean accuracy scores obtained in each condition (see Figure 4). Post hoc tests revealed that the visual cues and text cues conditions had higher delayed test accuracy than the control condition (respectively, MD = 1.80, p = .014; MD = 3.50, p < .001). Moreover, there was higher accuracy in the text cues condition than in the visual cues condition (MD = 1.70, p = .021). Taken together, the above results were largely consistent with Hypothesis 2.
4 Experiment 1 discussion
This experiment focused on whether visual cues in FL vocabulary instructional videos and text cues preceding these videos affected learners’ subjective judgment of learning and objective accuracy. As partially expected, when visual cues were presented on the screen during ongoing narration, and when text cues were presented before viewing videos, learners viewed themselves as learning better than when no cues were presented. They also showed higher accuracy on a delayed vocabulary learning test.
The impact of cues on FL vocabulary learning differed in the immediate and delayed accuracy tests. As expected, learners’ accuracy on the immediate test was higher in the text cues condition than in the control condition. Contrary to expectation, learners’ accuracy was not significantly higher in the visual cues condition than in the control condition on the immediate test. More importantly, the expected results were found in the delayed test. Learners showed the best delayed performance when they were in the text cues condition, followed by the visual cues condition, followed by the control condition. Taken together, the findings suggest that cues had stronger benefits for delayed performance than for immediate performance. It is possible that delayed performance is more sensitive to differences caused by the design of cues. Similarly, a recent study conducted by Horovitz and Mayer (2021) showed that the design of an instructor’s positive emotional state did not affect immediate performance, but improved delayed performance.
The results were consistent with the signaling (or cueing) principle, the semantic priming effect, the retrieval hypothesis, and the results of previous studies on visual and text cues (Mautone & Mayer, 2001; Moores et al., 2003; van Gog, 2022). The signaling (or cueing) principle predicts that adding simple visual cues in instructional videos can guide learners’ attention to the cued information, and reduce their unnecessary visual search on the screen (van Gog, 2022). As a consequence, adding such cues facilitates learners’ selection in the first phase of learning from instructional videos, and it frees up cognitive resources to engage in organization and integration. In the current study, learners not only reported higher judgments of learning, but also showed better delayed performance, after viewing the videos with visual cues than after viewing the videos without cues. Similarly, X. Wang et al. (2020) found that learners were directed by visual cues to spend more time focusing on the cued areas in instructional videos, and they showed better learning performance.
Unlike traditional text cues, which are presented along with the narration (e.g. as captions), text cues in the current study were the target word and its synonyms, presented before viewing the instructional videos. The synonyms were frequently used words that participants would have learned during secondary and undergraduate study. According to the semantic priming effect and the retrieval hypothesis, text cues preceding FL vocabulary instructional videos can not only direct learners’ attention to subsequent learning materials, but can also activate learners’ prior knowledge and facilitate the organization and integration of this knowledge, benefits that are beyond those provided by visual cues (Koh et al., 2018; McNamara, 2005; Moores et al., 2003). Therefore, it is reasonable to expect that text cues preceding FL vocabulary instructional videos are superior to simple visual cues. The text cues can activate learners’ prior knowledge related to the synonyms and help them develop a conceptual framework for top-down processing (Li, 2014). The results on learning performance confirmed our hypothesis. However, despite extensive research on cues, we know little about how cues affect learning processes (e.g. working memory activity, attention, and cognitive load) in learning FL vocabulary from instructional videos. This issue was addressed in Experiment 2.
III Experiment 2
1 Aim and hypotheses
Experiment 2 used EEG methods to investigate the neural oscillatory correlates of cues when learning from FL vocabulary instructional videos. Participants’ EEG data were recorded while they viewed the instructional videos. The two cues conditions were the same as in Experiment 1: (1) visual cues during the video and (2) text cues preceding the video. Previous studies on general cognition have shown that theta and alpha oscillations are related to various cognitive activities (e.g. working memory, attention) that are key components of learning (Fink & Benedek, 2014; C. Wang et al., 2016). Therefore, we compared the neural oscillatory correlates of visual cues and text cues using time-frequency analysis and power-spectral analysis. Based on the signaling (or cueing) principle, semantic priming effect, the retrieval hypothesis, and the findings from Experiment 1, we hypothesized that there would be greater frontal theta power, and greater frontal and parietal alpha power, in the text cues condition than in the visual cues condition.
2 Method
a Participants and design
The participants were 30 undergraduate and graduate students (24 females and 6 males) from a Chinese university. They were right handed, had normal or corrected-to-normal vision and hearing, and had no history of neurological or psychiatric disorders by self-declaration. Their ages ranged from 19 to 29 years (M = 21.83, SD = 2.70). Participants were required to have passed the CET-6; see Experiment 1. All participants provided written informed consent after being told about the experimental procedure. Participants received 70 CNY at the end of the experiment.
The experiment used a within-participants design. Each participant was asked to watch 60 short video clips to learn 60 FL vocabulary words (30 words per condition) under visual cues and text cues conditions. The vocabulary words were the same as those used in Experiment 1. Two FL vocabulary instructional videos were assigned to each participant in a counterbalanced order.
b Video clips
The FL (English) vocabulary video clips of visual cues and text cues conditions were identical to those in Experiment 1 (see Appendix 1). As in Experiment 1, the two sets of words did not differ in difficulty, t(19) = 1.34, p = .195, Cohen’s d = 0.15, familiarity, t(19) = 1.89, p = .074, Cohen’s d = 0.27. In addition, two professionals reported that the two sets of words had similar orthography.
c EEG recording
A Neuroscan 64-channel Ag/AgCl Quikcap with a central site reference between Cz and CPz was used for waking recordings. Prior to EEG analysis, all EEG recordings were re-referenced offline to M2/2. Hardware filters used to record EEG data were DC to 100 Hz. Stimuli were delivered using STIM software (Neuroscan, Inc., El Paso) and presented on a computer screen.
In order to acquire participants’ top-down or down-top process in viewing FL vocabulary video clips, scalp sites (see Figure 5) were mounted in a cap using the 10–20 system (Homan et al., 1987). Four additional electrodes were placed about 1 cm from the medial and lateral canthi of the dominant eye to record the horizontal and vertical electrooculogram (EOG) data. The GND (ground) electrode served as the ground and the CPz electrode was used as a reference. Electrode impedance was kept under 10 kΩ for all signal recordings.
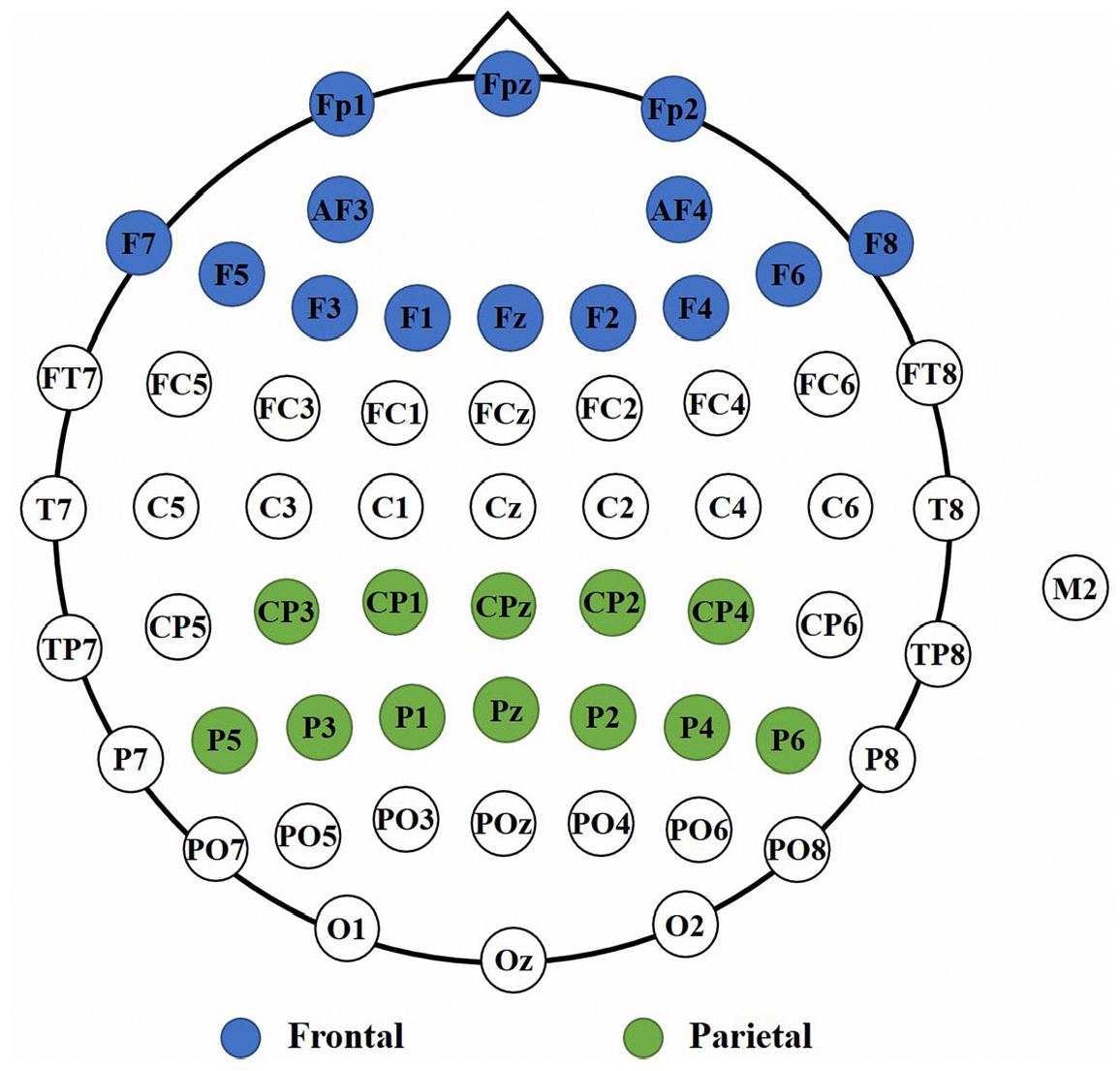
The clustered scalp electrodes.
d EEG data analysis
Preprocessing
Curry 8 software was used to analyse the EEG data (Finnigan et al., 2011). In the preprocessing, all of the original EEG data were re-referenced offline to the M2/2 to prevent a laterality bias (Teplan, 2002). First, a 0.1 Hz high pass filter and a 30 Hz low pass filter were applied. Then, we removed EOG components from the EEG signals. Third, algorithms in the software were used to flag and remove epochs that contained artifacts. Then baseline correction was performed using the pre-video interval (−200 – 0 ms). We clustered the scalp electrodes according to two corresponding brain regions for outcome analysis (see Figure 5): (1) Frontal region: Fpz, Fp1, Fp2, AF3, AF4, Fz, F1, F2, F3, F4, F5, F6, F7, and F8; (2) Parietal region: CPz, CP1, CP2, CP3, CP4, PZ, P1, P2, P3, P4, P5, and P6 (Jahng et al., 2017).
Time-frequency analysis
Time-frequency analysis was conducted on the EEG data within −200 ms pre-video to 6,000 ms post-video to compare the difference in energy between visual cues and text cues conditions in different frequency bands. Single-trial signals were transformed into time-frequency representations using wavelet convolution by multiplying the power spectrum of the EEG obtained via Short Time Fast Fourier Transform (STFFT).
Power-spectral analysis
EEG epochs were re-segmented into a time window of 6,200 ms (−200 ms pre-video to 6,000 ms post-video) for spectral analysis. FFT was used to analyse the EEG data spectrally, and the power was computed as μV2 for theta (4–8 Hz) and alpha (8–12 Hz) frequency bands by averaging the power of all scalp electrodes (Fink et al., 2005; Jacobs et al., 2006). A series of repeated-measures ANOVAs was conducted to examine the differences between text and visual conditions in power in frontal and parietal brain regions during three time periods (0–1 s vs. 1–6 s vs. 0–6 s).
e Procedure
Before starting the experiment, all participants washed their hair to lower the impedance. Then they filled out the demographic information form (i.e. age, gender, and major) and learned about the experimental procedure. They then watched two sets of 30 short FL vocabulary video clips under each condition. EEG oscillations were recorded while the participants watched the videos. After a 5-min rest, another condition was conducted. The whole experiment lasted 60 minutes (see Figure 6).
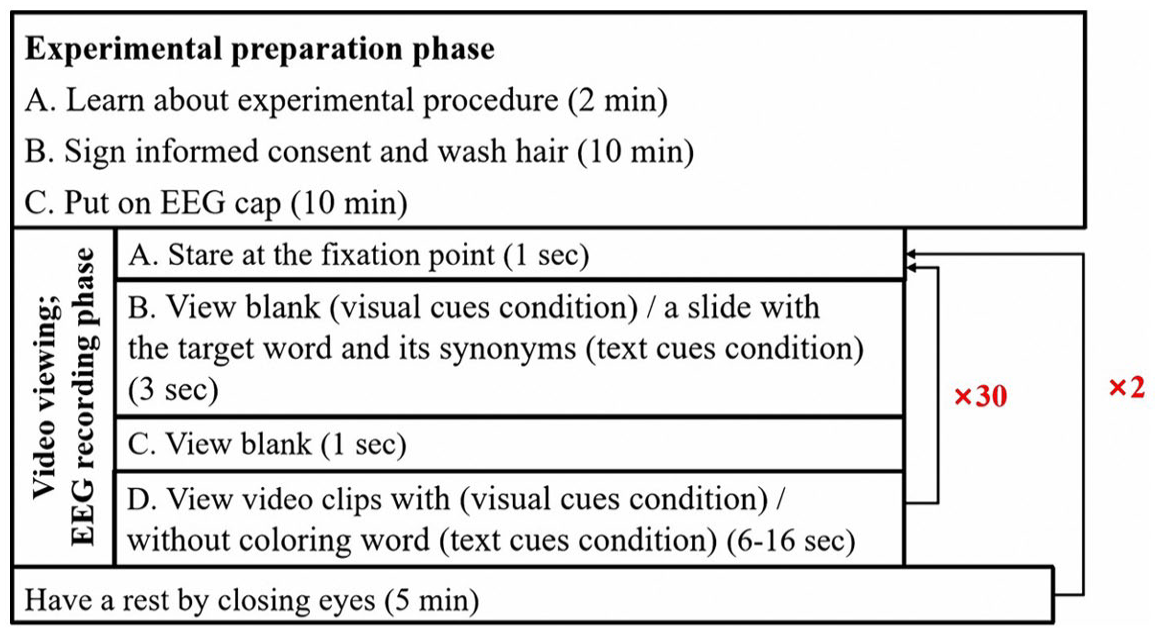
Experimental procedure.
3 Results
a Time-frequency analysis
As shown in Figure 7, in the first second of the video, the frontal theta power in the text cues condition was higher than in the visual cues condition, but the frontal alpha power showed the opposite pattern. In addition, we observed that the parietal region of interest (ROI) showed significantly higher alpha power in the text cues condition than in the visual cues condition.
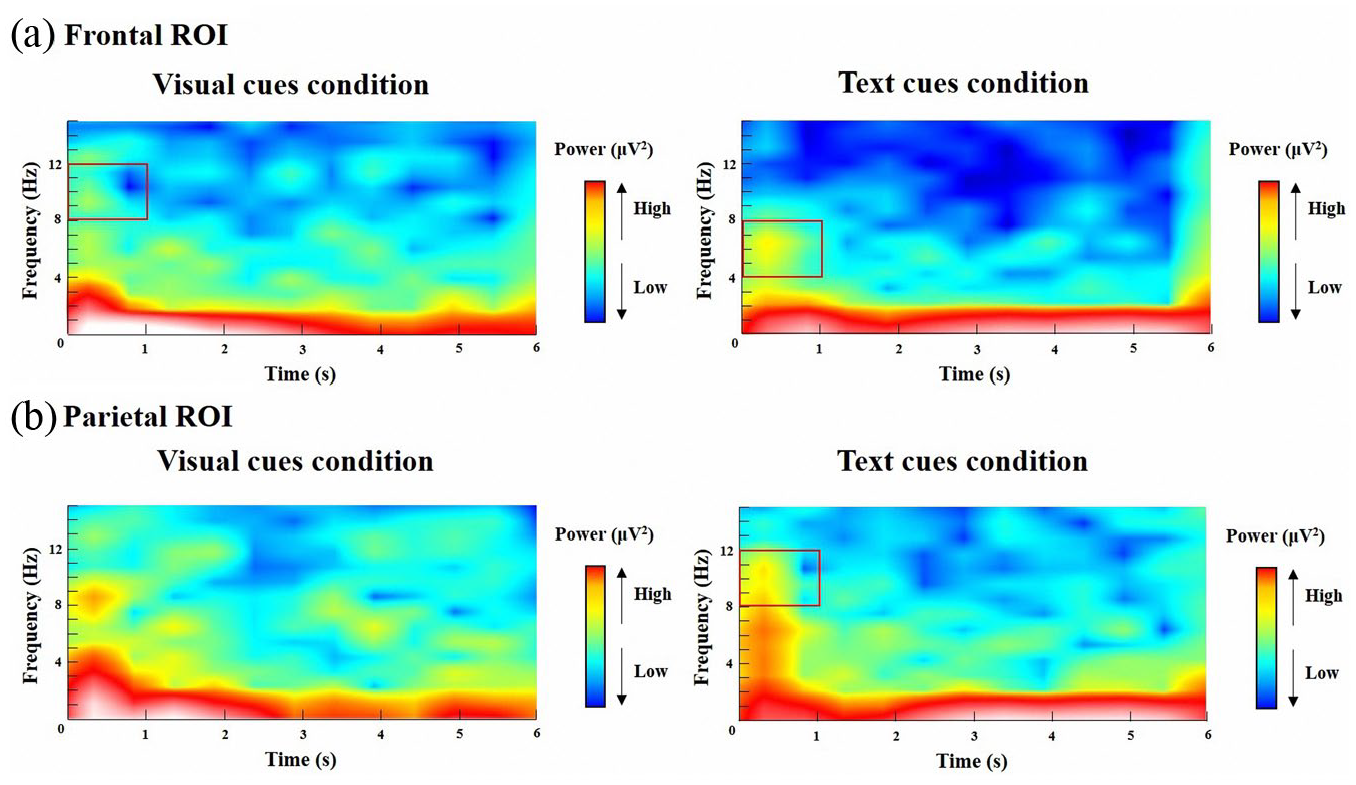
Grand-averaged time-frequency representations of total power of oscillatory activity (1–15 Hz) in (a) the frontal region (averaged across the electrodes Fpz, Fp1, Fp2, AF3, AF4, Fz, F1, F2, F3, F4, F5, F6, F7, and F8), and (b) the parietal region (averaged across the electrodes CPz, CP1, CP2, CP3, CP4, PZ, P1, P2, P3, P4, P5, and P6) for both conditions.
b Power-spectral analysis
Frontal theta power (4–8 Hz)
To test our hypothesis, a two-way repeated-measures ANOVA was conducted with the within-participant factors of Condition (visual cues vs. text cues) × Time (0–1 s vs. 1–6 s vs. 0–6 s), and the frontal theta power as the dependent variable. Significant main effects of Condition, F(1, 29) = 5.25, p = .029, ηp2 = 0.15 and Time, F(2, 28) = 86.05, p < .001, ηp2 = 0.86 were found. More importantly, the interaction effect was significant, F(2, 28) = 5.17, p = .012, ηp2 = 0.27. A simple effect test showed that in 0–1 s, the frontal theta power was significantly higher in the text cues condition than in the visual cues condition (MD = 0.78, p = .029; see Figure 8). The results largely support our hypothesis.
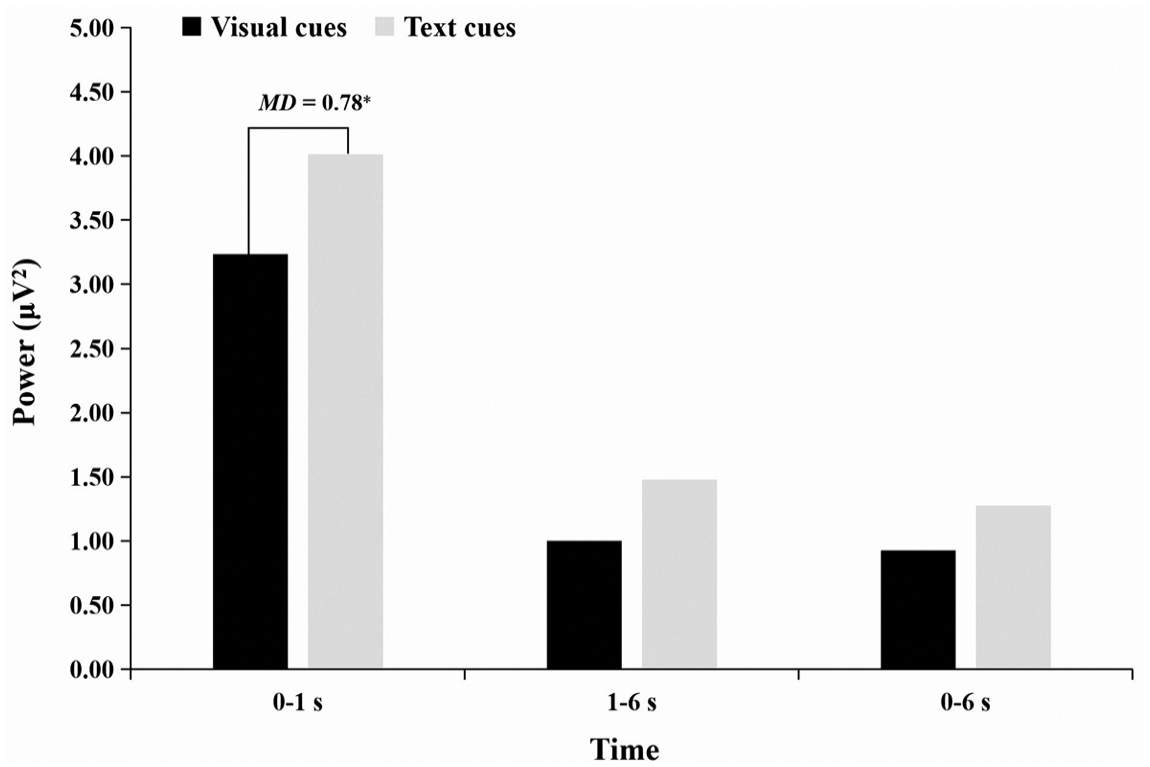
Frontal theta power under two conditions in three time periods (0–1 s vs. 1–6 s vs. 0–6 s).
Frontal and parietal alpha power (8–12 Hz)
A three-way repeated-measures ANOVA was conducted with the within-participant factors of Condition (visual cues vs. text cues) × Time (0–1 s vs. 1–6 s vs. 0–6 s) × Region (frontal vs. parietal), and alpha power as the dependent variable. Significant main effects were found for Time, F(2, 28) = 50.97, p < .001, ηp2 = 0.79 and Region, F(1, 29) = 5.71, p = .024, ηp2 = 0.17, but not Condition, F(1, 29) = 2.31, p = .139, ηp2 = 0.07. No interaction effects were significant (ps > .05). These results indicated that there was no significant difference between the two conditions in alpha power, which was not consistent with our hypothesis.
4 Experiment 2 discussion
This experiment focused on the neural oscillatory correlates of visual cues in FL vocabulary instructional videos and text cues presented before the videos. The results showed that theta power in the frontal EEG sensors was statistically significantly higher when text cues were provided before the video than when visual cues were presented in the video. This finding supports our hypothesis that the FL vocabulary instructional videos with text cues would elicit higher frontal theta power at the early stage of instructional videos (0–1 s).
The results suggested that compared with visual cues, text cues had more benefits in the first stage of processing and the early stage of FL vocabulary learning. This finding corroborates previous studies that found prestimulus theta activity as ongoing top-down preparation for the performance of subsequent tasks (Min & Park, 2010). The prestimulus mental state has been shown to present an appropriate target to explore differences in top-down regulation in advance of performance on different tasks (Min & Herrmann, 2007).
The frontal theta power is positively related to enhanced attention and sustained neuronal activity reflecting active maintenance of working memory (Castro-Meneses et al., 2020; Roux & Uhlhaas, 2014). Theta activity also reflects top-down regulation in information memory systems (Cavanagh & Frank, 2014; Cavanagh et al., 2010). We expected that the text cues would not only direct learners’ attention but also activate their prior knowledge. That is, the text cues should guide FL vocabulary learning processes, whereas passive viewing should not. Therefore, we conclude that theta power modulations reflect an increase in working memory demands.
It is important to highlight that neural oscillations in the alpha range failed to identify the differences between the FL vocabulary instructional videos with two types of cues. Similarly, a recent study conducted by X. Wang et al. (2020) on learning from instructional videos showed that alpha in the parietal lobe failed to identify the differences in cognitive load across videos with different presentation formats. Our findings, along with those of X. Wang et al. (2020), lead us to conclude that alpha power might not be a consistent indicator of neural oscillation correlates of correlates of cognitive processes involved in learning from FL vocabulary instructional videos.
IV General discussion
1 Empirical contributions
Although simple visual cues and text cues are commonly used in FL vocabulary instructional videos, the effects of these cues have not been tested until now. The main contribution of this study is that it documented better learning performance and more neural activation related to memory and attention when visual cues were added during FL vocabulary instructional videos, and when text cues were provided prior to the videos. Furthermore, it showed that the benefits of text cues prior to the videos were stronger than the benefits of adding visual cues during the videos. Together, the results of the two experiments indicated that pre-video text cues produced the highest learning performance (especially delayed performance), followed by visual cues during the video, and finally videos without cues. We also found that when viewing the FL vocabulary instructional videos after text cues, learners showed higher frontal theta power than when viewing the videos with visual cues. Overall, the results are consistent with the larger body of research on cues, which has shown that adding cues (e.g. coloring, highlighting, arrows, and words) can improve learners’ attention and learning performance (Ibrahim et al., 2012; Y. Hsieh, 2020; Teng, 2019, 2022). This is the first study to examine the effects of text cues preceding FL vocabulary videos and the first to use EEG to provide insight into the neural processes underlying the effects of visual cues and text cues in this educational context.
2 Theoretical contributions
The results have implications for understanding the signaling (or cueing) principle and the semantic priming effect. The findings support the signaling (or cueing) principle (van Gog, 2022) in that learners learned better when there were simple visual cues in instructional videos than when there was an absence of cues. Learners in the visual cues condition not only believed more strongly that they could learn well from FL vocabulary instructional videos with visual cues, but also showed better learning performance on the delayed test. The findings are also consistent with the semantic priming effect and the retrieval hypothesis: adding text cues before learning not only enhanced learners’ attention to subsequent learning materials, but also improved memory and recognition of the FL materials (Koh et al., 2018; Lachner et al., 2020; Moores et al., 2003; Teng, 2019, 2022; Was et al., 2019). Learners showed the best FL vocabulary learning performance and the most brain activation related to memory and attention in the text cues condition, compared to the visual cues condition and the control condition.
In addition to these theoretical implications, the study has important implications for researchers who want to measure neural mechanisms in FL vocabulary instructional videos. To our knowledge, EEG is a relatively novel approach in the study of cognitive processes when learning from instructional videos. The current study is the first one to simultaneously use behavioral evidence along with EEG evidence to determine the difference in neural mechanisms when learning from FL vocabulary instructional videos with and without cues. The results suggest that because neural activity provides an indirect estimate of working memory processing and attention, the EEG method can improve our understanding of the mechanism that underlies cue design in FL vocabulary instructional videos. The EEG data suggest that theta oscillations could serve as a direct and reliable measurement of neural oscillations. The findings of the current study suggest that text cues guide learners’ attention and activate their prior knowledge, an assumption that is in line with existing empirical evidence that theta power increases with working memory storage demands (L.T. Hsieh & Ranganath, 2014; J.J. Lin et al., 2017). EEG measures of neural oscillations were useful in helping us understand why learners learn FL vocabulary better with text cues than with visual cues, and in explaining the underlying processes by which learners learn from FL vocabulary instructional videos. The neural evidence extends the results of previous behavioral studies (Mautone & Mayer, 2001; X. Wang et al., 2020).
3 Limitations and future directions
This study has some limitations, and they can be addressed in future research. First, we did not measure participants’ prior knowledge (e.g. English level and vocabulary size), and so could not test this as a moderator of the relationship between cue design and FL vocabulary learning from instructional videos. Previous studies have documented expertise reversal effects of cues in animation (Arslan-Ari, 2018; Johnson et al., 2015; Kalyuga, 2007; Khacharem, 2017). That is, learners with low prior knowledge needed cues to guide their attention to the essential information, and they gained more benefits from cues in FL vocabulary instructional videos than learners with high prior knowledge. Therefore, future research should test the expertise reversal effects of visual cues and text cues in FL vocabulary instructional videos.
Second, although each word appeared the same number of times in each condition, we used the FL vocabulary words to be learned and these words’ synonyms as text cues. As a consequence, our design did not allow us to separate the effects of the semantic priming and the effects of repetition priming. Previous studies have shown that semantic distance is a determining factor in semantic priming because conceptual knowledge is stored in a network of interconnected nodes (Collins & Loftus, 1975; Kenett et al., 2017). Furthermore, repetition priming and semantic priming have different roles in enhancing attention and memory (Chng et al., 2019; Rogers, 2017). Further research is needed to examine the effects of different types of text cues on FL vocabulary learning from instructional videos.
Third, although we controlled the learning time in the different conditions, the time needed to process the information was greater when text cues were presented before the learning materials. The learning time for each word in the text cues condition included 3 s for the text cues slide, as seen in Figure 2, and 6 s to 14 s for the video clip, as seen in Figure 1b. By contrast, the learning time for each word in the visual cues condition and control condition included 3 s for a blank slide and 6 s to 16 s for the video clip. Therefore, future research should separate the effect of exposure time and the effect of text cues.
Finally, in order to eliminate the interference of learners’ individual differences (e.g. English level and vocabulary size) on the results, the study adopted a within-participants design, in which each student experienced all experimental conditions and learned 90 words in Experiment 1 or 60 in Experiment 2. Although we provided them with a 5-min rest time between conditions, there might have been a fatigue effect, as suggested by the high cognitive load reported by students. Therefore, future work should consider reducing the sense of fatigue by increasing the rest time after each video clip.
4 Practical implications
With the popularity of online learning and blended learning, instructional videos are becoming more and more common as a way to learn FL vocabulary. Our findings about visual cues and text cues have implications for designing FL vocabulary instructional videos. First, adding text cues preceding FL vocabulary instructional videos appears to provide effective scaffolding for learning. Compared to learning from FL vocabulary instructional videos without cues, learning from videos with text cues appears to engage more working memory and to use more top-down attentional processing, resulting in higher learning performance. Therefore, educators are encouraged to add text cues prior to FL vocabulary instructional videos. Second, educators are encouraged to add visual cues for learners who lack prior knowledge, as adding visual cues to the instructional video can also improve their learning performance relative presenting videos without visual cues.
Footnotes
Appendix 1
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China under Grant [62007023]; and the Fundamental Research Funds for the Central University of China under Grant [GK202205022; 2022JYZD04]. We would like to thank Mr Dong Yang and Ms Zhuoming Jin, Shaanxi Normal University, for kindly being experimental assistants during conducting this study.
Data availability statement
The data used to support the findings of this study are available from the corresponding author upon request.