
Abstract
The Common European Framework of Reference for Languages (CEFR) provides widely used proficiency labels, but these labels do not specify how grammar is materially distributed, sustained, or reweighted across school textbooks. This study profiles vertical grammar salience in Taiwan’s CEFR-referencing K–12 English-as-a-foreign-language (EFL) textbook ecology by examining the relationship between English Grammar Profile (EGP) benchmark placement and textbook distributional salience. The corpus consisted of 57 ministry-approved student books from multiple textbook series across primary, junior-secondary, and senior-secondary stages, comprising 234,134 cleaned English tokens. An EGP-derived inventory of A1–B2 grammar points (GPs; N = 602) was consolidated, operationalized as corpus-queryable patterns, and searched in the textbook corpus. Frequencies were normalized as frequencies per million words, transformed as ln(FPM + 1), and standardized as z scores to estimate distributional input intensity. Two complementary clustering analyses were conducted. Level-based clustering identified within-level salience bands for A1, A2, B1, and B2 GPs, whereas stage-based clustering examined how the attested inventory was redistributed within each school stage. Dispersion across books and persistence across stages were used as interpretive complements to frequency-based intensity. The results showed that 12.9% of the benchmarked A1–B2 inventory was unattested in the corpus, that all four CEFR levels contained internal salience stratification, and that senior-secondary materials displayed a compressed distribution in which the largest group of A1–B2 items fell into the lowest salience band. This senior-stage pattern is interpreted cautiously as possible selective recycling of lower-level grammar, while also allowing for the alternative possibility that A1–B2 items recede within more advanced textual input beyond the study’s inventory. The study contributes a transparent, distribution-sensitive framework for diagnostic review of CEFR-referencing textbook systems. Its findings index materials-based availability and distributional prominence, not instructional salience, classroom enactment, or learner acquisition.
Keywords
1. Introduction
The Common European Framework of Reference for Languages (CEFR) has become an influential reference point for language education because it supports comparability across curricula, assessments, and materials (Council of Europe, 2020; North, 2014). Its level labels, such as A2 or B1, help institutions describe broad proficiency expectations in a shared language. However, the CEFR was not designed to function as a grammar syllabus. Its descriptors are intentionally broad, action-oriented, and language-neutral; they do not specify which grammar points (GPs) should receive greater attention in textbooks, how often they should recur, or how grammatical content should be distributed across several years of schooling (Council of Europe, 2020; North, 2014). For CEFR-referencing school systems, this creates a practical implementation problem: a level label can support external alignment, but it cannot by itself determine materials-level grammar allocation.
This problem is particularly important in K–12 English-as-a-foreign-language (EFL) education, where grammar is not encountered within a single course but across a long sequence of textbooks, grades, and school stages. A grammar item assigned to a CEFR level may be introduced briefly, recycled across many books, concentrated in one stage, or carried forward into later materials with varying intensity. These different patterns cannot be captured by coverage alone. A textbook system may include a benchmarked GP, yet the item may remain weakly represented, narrowly distributed, or absent from later stages. Conversely, another item at the same benchmark level may become highly prominent because it is useful across textbook discourse, classroom routines, and communicative tasks. The central issue is therefore not only whether CEFR-linked grammar appears in textbooks, but how it becomes distributed and weighted within a materials system.
One influential resource for making CEFR-linked grammar more explicit is the English Grammar Profile (EGP), which associates grammatical features with CEFR levels on the basis of learner-corpus evidence and criterial-feature logic (Hawkins & Buttery, 2010; Hawkins & Filipović, 2012; O’Keeffe & Mark, 2017). The EGP offers a more concrete grammar-oriented benchmark than the CEFR alone, and recent work has further shown the value of empirically examining the structure of EGP level assignments (Verratti-Souto et al., 2025). Yet benchmark placement and textbook realization are different constructs. The EGP indicates where a construction is positioned in a CEFR-linked grammar inventory; it does not show how strongly that construction is represented in a particular textbook ecology. In addition, EGP benchmark placement should not be treated as wholly independent of textbook design. Because CEFR-referencing materials may themselves be influenced by CEFR- or EGP-informed assumptions, some degree of benchmark-material circularity is possible. The EGP is therefore used in this study as an externally interpretable reference inventory, not as a fully neutral or prescriptive grammar syllabus.
This study responds to the gap between CEFR-linked benchmark placement and textbook realization by profiling vertical grammar salience in Taiwan’s CEFR-referencing K–12 EFL textbooks. The term salience is used here in a restricted, distributional sense. It refers to the extent to which a GP becomes materially prominent in textbooks through normalized frequency, spread across books, and persistence across school stages. This usage is deliberately narrower than instructional salience or acquisitional salience. Distributional salience can be estimated from corpus evidence; instructional salience would require analysis of explicit grammar explanation, exercise design, metalinguistic focus, teacher guides, and classroom use; acquisitional salience would require learner data. The present study therefore examines materials-based availability and prominence, not classroom enactment or learner uptake.
This distinction matters for both research and textbook evaluation. Frequency-based evidence can show how much opportunity for encounter a textbook system provides, and corpus-based measures can reveal whether a GP is widely dispersed or concentrated in a narrow part of the materials (Biber & Reppen, 2002; Brezina, 2018; N. C. Ellis, 2002). However, frequency does not automatically indicate that an item is taught explicitly, noticed by learners, or acquired. A frequent construction may occur mainly as part of reading input, while a less-frequent construction may receive focused explanation in grammar sections. For this reason, the statistical bands developed in the study are interpreted as distributional bands rather than direct instructional bands. They show how textbook materials allocate linguistic input, not how teachers prioritize grammar or how learners develop grammatical competence.
Textbooks provide an appropriate empirical site for this inquiry because they are stable, shared, and often officially approved carriers of curriculum in EFL systems (Richards, 2001, 2014; Valverde et al., 2002). In Taiwan, school textbooks operate within a ministry-approved, multiseries ecology. The national curriculum provides a common framework, while publishers retain space to organize content, texts, activities, and language input in different ways. This one curriculum, multiple textbooks context makes it necessary to examine the system-level availability of grammatical content across approved series rather than assume that a single textbook series represents the whole curriculum. In this study, the analysis is therefore framed as an examination of Taiwan’s ministry-approved K–12 EFL textbook ecology, not as a reconstruction of any individual learner’s exposure path.
Corpus-informed textbook research has developed strong methods for examining pedagogic language, including vocabulary load, lexical patterning, text difficulty, and discourse features (Biber et al., 1998; Khojasteh & Mukundan, 2025; Le Foll, 2022, 2024; Nelson, 2022). Grammar-focused textbook research has also shown the importance of moving beyond impressionistic claims about alignment. However, CEFR-referencing grammar evaluation often remains close to a coverage logic: whether a target item is present, whether it belongs to a level, or whether a textbook broadly reflects a proficiency framework. Such questions are useful but incomplete. They do not explain how items within the same CEFR level are differentially weighted, nor do they show how a benchmarked grammar inventory is redistributed across primary, junior secondary, and senior secondary materials.
The present study addresses this problem through a corpus-and-clustering design. It combines an EGP-derived A1–B2 grammar inventory, a 57-book Taiwan K–12 EFL textbook corpus, query-based corpus retrieval, and two complementary clustering perspectives. Level-based clustering identifies distributional salience bands within each CEFR level, showing whether broad level labels contain internal weighting structures. Stage-based clustering examines how the attested inventory is redistributed within each school stage, showing how benchmarked items become more central or more peripheral at different points in the textbook ecology. Dispersion across books and persistence across stages are used as interpretive complements to normalized frequency. Sensitivity analyses further examine whether the clustering patterns are robust under alternative frequency floors and K specifications.
This design does not claim to model fine-grained grammar sequencing in the sense of unit-by-unit ordering, classroom instruction, or learner developmental sequence. Instead, it profiles stage-level distributional salience: how CEFR-linked GPs are materially represented, intensified, dispersed, and sustained across the textbook system. The purpose is diagnostic. By distinguishing benchmark placement from textbook distributional salience, the study offers a way to examine how broad CEFR-linked grammar categories are translated into actual materials-based patterns of availability.
The study was guided by the following research questions.
2. Literature Review
2.1. CEFR, Reference Level Descriptions, and CEFR-Linked Grammar Profiling
In CEFR-related literature, the framework is generally positioned as a proficiency-description system rather than a language-specific content inventory. Its contribution lies in offering a common metalanguage for comparing learning outcomes across educational systems, examinations, and curriculum traditions (Council of Europe, 2020; North, 2014). This orientation explains both its portability and its incompleteness for materials design: the CEFR establishes broad proficiency reference points, while decisions about language-specific content, including grammar, require additional specification.
One response to this gap has been the development of reference level descriptions (RLDs). RLDs were intended to connect the CEFR’s broad action-oriented descriptors with the linguistic resources needed for particular languages and contexts (Council of Europe, 2020; North, 2014). They therefore occupy an intermediate position between proficiency description and curriculum implementation. Rather than replacing the CEFR, they make its levels more usable for language-specific planning, assessment specification, and materials development. Similar forms of localization can be seen in CEFR-referencing systems where broad level descriptors are linked to national standards, local curricula, or language-specific scales (Tono, 2019; Zhao et al., 2017).
For English, the EGP represents a major attempt to specify grammar development in CEFR-linked terms. Building on learner-corpus evidence and criterial-feature research, it assigns grammatical features to CEFR levels and thus provides a more explicit grammar-oriented reference than the CEFR alone (Hawkins & Buttery, 2010; Hawkins & Filipović, 2012; O’Keeffe & Mark, 2017). This makes the EGP useful for research that requires a principled inventory of level-linked GPs. It also allows grammar alignment to be examined empirically rather than through intuition or textbook labels alone.
At the same time, EGP-based profiling should be interpreted with caution. The assignment of a GP to a CEFR level indicates benchmark placement, not the amount or distribution of that item in a specific textbook system. A GP may be associated with A2 or B1 in the EGP but receive very different degrees of recurrence, dispersion, or emphasis in school materials. Recent quantitative work has also shown the importance of empirically examining EGP level assignments rather than treating the profile as self-validating (Verratti-Souto et al., 2025).
A further methodological caution concerns the relationship between the benchmark and the materials being evaluated. CEFR-referencing textbooks may themselves be influenced by CEFR- or EGP-informed assumptions. The EGP should therefore not be treated as a wholly independent or pedagogically neutral standard. In other words, the analysis does not evaluate whether textbooks conform to the EGP. Instead, it uses the EGP as a benchmarked reference inventory and examines how those benchmarked GPs are materially realized within one textbook ecology.
2.2. Grammar Sequencing, Teachability, and the Limits of Benchmark Labels
Grammar sequencing has long been central to syllabus design because grammar teaching involves more than selecting forms. It also requires decisions about pacing, recurrence, cumulative load, and relative emphasis (Burton, 2022; Celce-Murcia et al., 1999; Larsen-Freeman, 2009). A usable grammar syllabus must therefore address two related issues: which forms belong within a learning pathway, and which forms should receive stronger or lighter treatment within that pathway. CEFR labels can help define a broad proficiency space, but they cannot determine these more local decisions on their own.
Second language acquisition research also cautions against treating level placement as a sufficient guide to teachability. Learners’ ability to process and use grammatical structures is shaped by developmental readiness, processing constraints, prior knowledge, and the amount and distribution of exposure and practice opportunities (DeKeyser, 2017; R. Ellis, 2006; Pienemann, 1989). Two GPs assigned to the same CEFR level may therefore require different kinds of pedagogic support. One may be easily recycled across many classroom contexts, while another may need delayed treatment, narrower framing, or repeated guided practice.
This issue becomes more complex in K–12 education, where grammar is distributed across years rather than taught within a short course. In such systems, a level label such as A2 or B1 may contain items that function quite differently within the materials sequence. Some may form a durable core, some may appear as supporting resources, and others may be previewed only lightly or revisited selectively. Within-level differentiation is therefore necessary if broad benchmark categories are to be interpreted in relation to actual materials use.
At the same time, the present study does not infer teachability directly from corpus frequency or clustering results. It treats textbook frequency, dispersion, and stage persistence as evidence of institutionalized opportunity for encounter. These indicators can show how a textbook ecology distributes grammatical input, but they do not show whether an item is easy to learn, explicitly taught, successfully noticed, or acquired. The distinction is important because the study profiles distributional salience, not developmental sequence or classroom pedagogy.
2.3. Textbooks as Institutionalized Pedagogic Input
Textbooks matter because, in many EFL systems, they are not merely optional classroom resources. They are institutional carriers of curriculum that mediate policy goals into lessons, texts, examples, tasks, and review opportunities (Richards, 2001, 2014; Valverde et al., 2002). They help determine which language features learners are likely to encounter repeatedly and which features remain peripheral. For this reason, textbooks are a legitimate site for examining how grammar is materially allocated across an instructional trajectory.
This role is especially important in ministry-approved or regulated textbook systems. When multiple approved series coexist under a common curriculum, formal alignment does not guarantee identical linguistic input. One series may foreground a GP across several stages, while another may include it only briefly. The issue is therefore not only what one publisher includes, but what the approved textbook ecology as a whole makes available. This distinction is relevant to Taiwan’s curriculum-based, multiseries textbook system, where nationally guided curriculum goals are implemented through different publisher series. The detailed corpus composition and selection rationale are reported in Section 3; the theoretical point here is that a multiseries ecology requires system-level analysis rather than reliance on any single series.
Corpus-informed textbook evaluation offers a way to examine such patterns systematically. Corpus methods have been used to study vocabulary load, text difficulty, collocation, discourse features, and pragmatic input in instructional materials (Biber et al., 1998; Le Foll, 2022, 2024; Nelson, 2022). Methodological reviews have also emphasized the importance of transparent corpus construction, explicit retrieval procedures, and reproducible reporting in textbook research (Khojasteh & Mukundan, 2025). Grammar, however, poses special challenges because GPs often involve form–function relations, multiword patterns, and overlapping constructions rather than easily countable word forms. A corpus-based grammar study must therefore make its operational decisions explicit. The present study addresses this challenge by using a query-based GP inventory and by documenting how GPs are operationalized, validated, normalized, and interpreted.
2.4. Frequency, Recurrence, Dispersion, and Distributional Opportunity
Frequency is relevant to textbook grammar because repeated encounters with linguistic patterns can support noticing, strengthening, and gradual entrenchment of form–meaning mappings (Bybee, 2006, 2008; N. C. Ellis, 2002). From a usage-based perspective, recurrence is not a trivial property of materials. It affects how often learners are given opportunities to process a construction and how visible that construction becomes within the input. In textbook analysis, frequency can therefore indicate how strongly a materials system makes a GP available.
However, frequency cannot be treated as a direct proxy for learning. The relation between exposure and acquisition is mediated by attention, task design, prior knowledge, working memory, and the nature of the target structure (Denhovska et al., 2016; N. C. Ellis, 2002). A high-frequency GP is not automatically acquired, and a low-frequency GP is not necessarily unimportant or unteachable. Frequency-based prominence is also not the same as instructional salience. Instructional salience depends on how a textbook explains a form, how exercises direct attention to it, whether it is presented metalinguistically, how tasks require its use, and how teachers mediate it in classrooms (R. Ellis, 2006; Larsen-Freeman, 2009).
For this reason, frequency needs to be interpreted together with distribution. Biber and Reppen (2002) argue that frequency evidence can inform grammar teaching by showing which structures learners are likely to encounter, but such evidence is most useful when it is interpreted cautiously. A GP that appears many times in one isolated unit is not equivalent to a GP that appears across several books and stages. Research on distributed exposure similarly suggests that repeated encounters across time can support retention and accessibility, although effects vary across contexts and targets (Kim & Webb, 2022; Webb & Chang, 2015).
In the present study, textbook distributional salience is therefore operationalized primarily through normalized input intensity, while book-level dispersion and cross-stage persistence serve as interpretive complements. These measures describe how a textbook ecology organizes opportunities for encounter and return. They do not validate instructional quality or learner outcomes. Their purpose is to make materials-based prominence empirically visible so that CEFR-linked grammar can be evaluated as a distributional phenomenon rather than as a simple checklist of included items.
2.5. Why Vertical Salience Profiling is Needed in CEFR-Referencing Textbook Systems
The preceding literature points to the need for a vertical perspective on CEFR-linked textbook grammar. In CEFR-referencing systems, the curricular task is not only to assign grammatical content to broad proficiency levels. It is also to determine how that content is distributed across grades, books, series, and school stages. A static alignment question, whether a GP appears at an appropriate level, is useful but incomplete. It does not show whether the GP is strongly represented, widely dispersed, sustained across stages, or only lightly attested.
Vertical salience profiling addresses this limitation by asking how benchmarked GPs move through a materials ecology. Some items may become durable cross-stage resources; others may be concentrated in one stage; still others may remain present but weakly distributed. Without a vertical view, these differences remain hidden behind the apparent unity of level labels. A2 or B1 may appear to be a single benchmark category, even though the GPs within that category occupy very different positions in the textbook system.
A vertical perspective is particularly important in multi-series contexts. A single textbook series can show one publisher’s design choices, but a full approved ecology can show what the system recurrently foregrounds and what it leaves peripheral. In this sense, vertical analysis is diagnostic rather than prescriptive. It does not claim that high-frequency items are necessarily better taught, nor that low-frequency items are necessarily deficient. Instead, it identifies where materials-based prominence accumulates, where distribution is thin, and where benchmark placement does not translate into sustained textbook availability.
The present study builds on this rationale through a two-way analytic design. Level-based clustering examines within-level distributional salience across the K–12 sequence, while stage-based clustering examines how the attested A1–B2 inventory is reweighted within primary, junior secondary, and senior secondary materials. Read together, these perspectives make visible the relationship between two constructs that are often conflated: the benchmark position of a GP on a CEFR-linked scale and its distributional prominence in institutional materials. This distinction provides the conceptual basis for the corpus procedures and clustering analyses described in the following section.
3. Methodology
3.1. Design Overview and Analytic Stance
This study adopts a corpus-based textbook-analytic design to profile vertical grammar salience as the relationship between CEFR-linked benchmark placement and textbook distributional prominence. The analysis is curricular and methodological rather than acquisitional. It examines how an EGP-derived grammar inventory is materially realized in Taiwan’s ministry-approved K–12 EFL textbook ecology, and it restricts its claims to system-level textbook availability, distributional prominence, and stage-level reweighting. It does not model individual learner exposure, classroom enactment, textbook pedagogy, or learner acquisition outcomes (N. C. Ellis, 2002; Richards, 2001).
Two complementary clustering analyses were conducted. First, level-based clustering examined the macrostructure of within-level salience. Within each CEFR level from A1 to B2, GPs were clustered according to standardized stage-level input-intensity profiles. This analysis asked whether broad CEFR levels contain internal distributional bands rather than treating each level as a flat category. Second, stage-based clustering examined the microstructure of school-stage weighting. Within each school stage, GPs were clustered according to book-level intensity profiles to identify how the attested A1–B2 inventory was redistributed from relatively central to relatively peripheral positions.
A supplementary distributional analysis was conducted to support interpretation. Book-level dispersion and stage persistence were calculated for each GP, but these indicators were not treated as co-equal clustering inputs. They were used to clarify whether high-intensity items were broadly distributed or locally concentrated, and whether lower-intensity items were absent, isolated, or sustained across stages. This analytic stance keeps frequency-based salience separate from instructional salience: the study identifies patterns of materials-based opportunity, not direct evidence of teaching quality or learning.
3.2. Empirical Context, Textbook Corpus, and Corpus Composition
The corpus was drawn from Taiwan’s ministry-approved K–12 EFL textbook system, in which commercial publishers develop textbooks under the 12-year Basic Education curriculum framework and schools select from approved series (Ministry of Education, 2021). The study focused on student books because these materials provide the learner-facing textual input most directly shared across classrooms. The analyzed corpus included primary, junior secondary, and senior secondary textbooks. At each stage, three approved textbook series were represented: Kanghsuan (KH), Hanlin (HL), and HESS (HE) at the primary stage; HL, KH, and Nan-I (NI) at the junior secondary stage; and HL, Longteng (LT), and Sanmin (SM) at the senior secondary stage. The selected series and corpus composition are reported in Appendix A1 in the Supplemental Material.
The sampling principle was full-stage coverage within the selected ministry-approved series rather than partial sampling of isolated books. This design allowed the analysis to examine system-level grammar availability across a multi-series textbook ecology. The resulting corpus consisted of 57 student books, 234,134 cleaned English tokens, and 20,653 sentences. Table 1 reports the corpus composition by school stage and provides the token base used for frequency normalization. The counts should be interpreted as properties of the approved textbook ecology, not as the exposure history of any individual learner.
Corpus Composition and Token Counts after Cleaning.
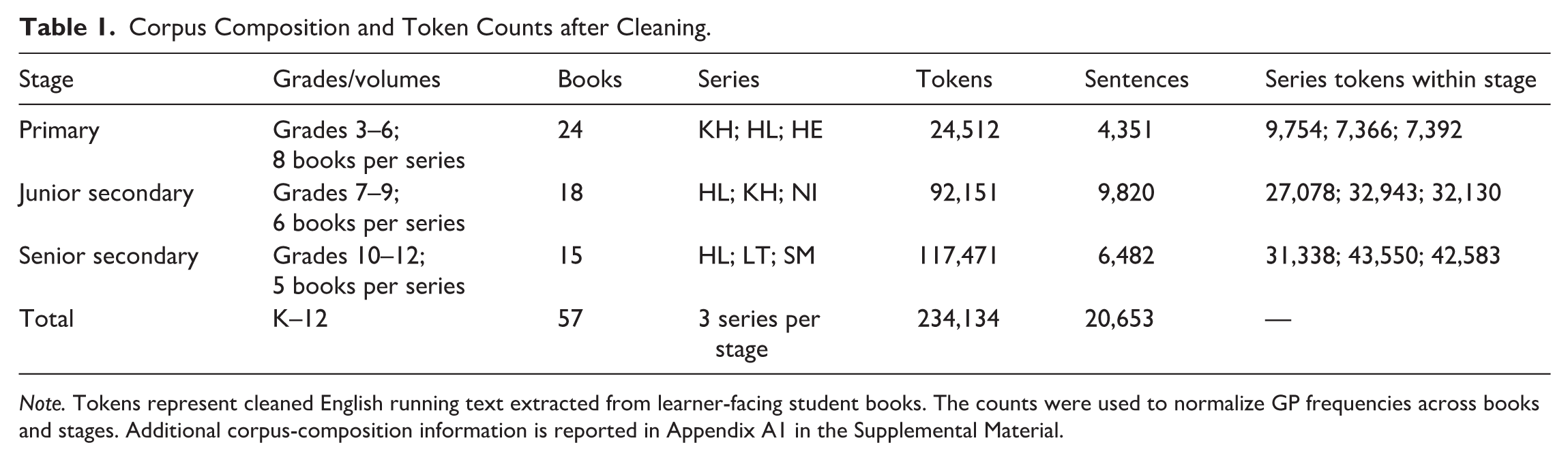
Note. Tokens represent cleaned English running text extracted from learner-facing student books. The counts were used to normalize GP frequencies across books and stages. Additional corpus-composition information is reported in Appendix A1 in the Supplemental Material.
The primary-stage subcorpus was substantially smaller than the junior and senior subcorpora. Because one occurrence in the primary subcorpus corresponds to approximately 40.8 FPM, rare GPs at this stage are especially sensitive to one or two occurrences. This issue was addressed through minimum-frequency sensitivity checks using n ⩾ 3 and n ⩾ 5 thresholds, as described in Section 3.10 and reported in Appendix B1 in the Supplemental Material.
3.3. Text Extraction, Cleaning, and Token-Counting Procedures
The corpus was constructed from publisher digital files and digitized PDF/scanned sources. When embedded text layers were unavailable or unreliable, optical character recognition (OCR) was used to extract text. Manual transcription was not used as the primary data-entry method; however, OCR outputs and extracted text were manually checked against the source pages to correct obvious recognition errors, remove layout artifacts, and verify section boundaries.
Only learner-facing English content in student books was retained. Included materials comprised dialogues, reading passages, example sentences, sentence-pattern presentations, grammar explanations, exercise prompts, communicative practice items, and other instructional text that learners were expected to read, process, or use. Excluded materials included answer keys, glossaries, indexes, page headers and footers, repeated layout strings, publisher metadata, and duplicated formatting content. The purpose of these rules was to preserve instructional input while avoiding artificial inflation from repeated paratext.
Token counts were based on English running tokens after cleaning. Punctuation and layout symbols were excluded from token counts. Contractions were retained in the text and handled consistently by the tokenizer and query procedures. Repeated headings and duplicated section labels were removed when they served layout rather than instructional functions. Each retained text segment was assigned deterministic metadata for stage, series, book, unit, and section. This section-level coding allowed the same corpus to support stage-level profiling, book-level dispersion, and later inspection of query outputs. A fuller extraction and cleaning workflow is provided in Appendix A2 in the Supplemental Material.
3.4. Grammar Inventory and Analytic Scope
The analytic inventory was derived from the EGP and restricted to A1–B2. This scope was adopted because the study examines GPs most plausibly represented in K–12 school English and because the EGP-derived inventory provides a benchmarked basis for comparison across these levels. The restriction also defines a boundary of interpretation. Senior-secondary textbooks may contain advanced academic discourse, complex syntax, or C1+ language beyond the A1–B2 inventory; such language is outside the main analytic scope and is considered when interpreting senior-stage compression.
After descriptor consolidation and aggregation, the benchmark inventory contained 602 GPs: 73 at A1, 175 at A2, 201 at B1, and 153 at B2. A GP was defined as a pedagogically interpretable form–function target associated with one CEFR level and operationalized through one or more corpus-queryable patterns. This definition was necessary because many grammar descriptors cannot be retrieved through a single surface string. Some require part-of-speech (POS) constraints, lemma restrictions, multiword patterns, or exclusion rules to distinguish target uses from superficially similar nontarget instances.
Zero-occurrence GPs were retained for coverage reporting but excluded from intensity-based clustering because they contributed no variance to the clustering matrices. To contextualize the interpretation of senior-secondary results, a supplementary A1–B2 scope check was also included. This check summarized the recurrence of validated A1–B2 GP query hits in the senior-secondary corpus and helped evaluate whether low A2–B2 salience reflected selective recycling, backgrounding within more advanced input, or both. The inventory flow is summarized in Table 2 and documented in Appendix A3 in the Supplemental Material.
Inventory Flow and Analysis Datasets.
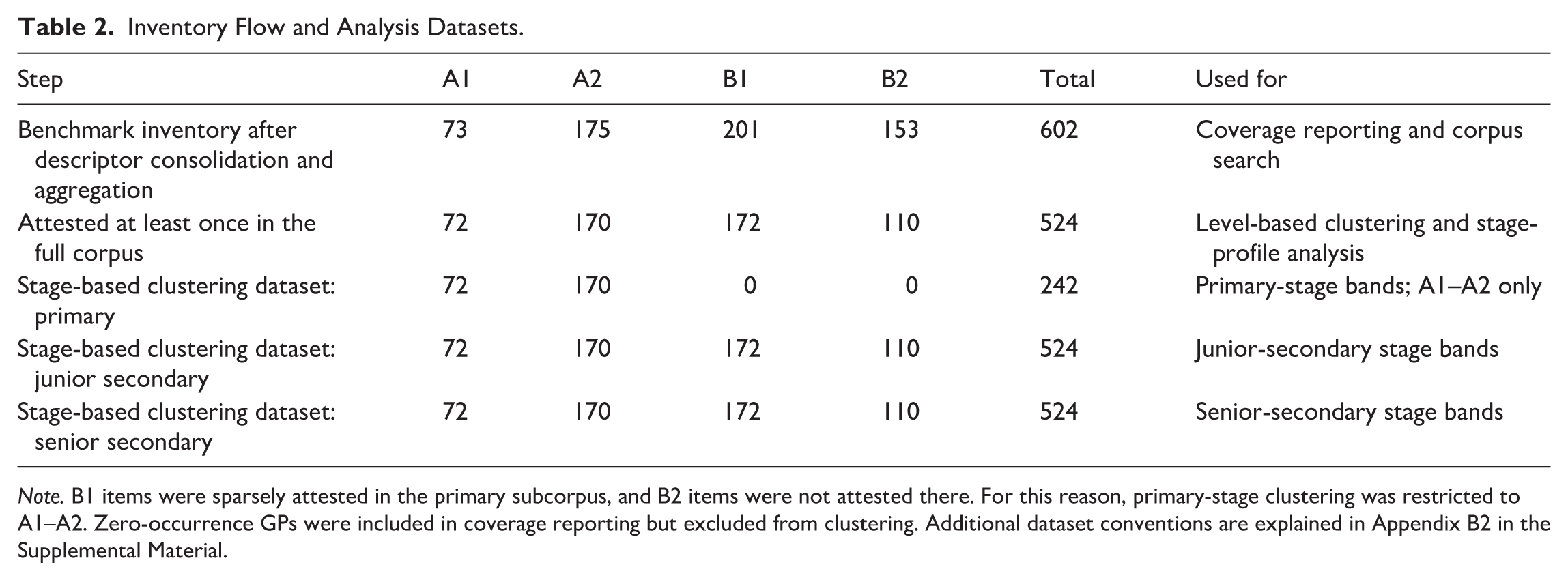
Note. B1 items were sparsely attested in the primary subcorpus, and B2 items were not attested there. For this reason, primary-stage clustering was restricted to A1–A2. Zero-occurrence GPs were included in coverage reporting but excluded from clustering. Additional dataset conventions are explained in Appendix B2 in the Supplemental Material.
3.5. Descriptor Consolidation and Inventory Reliability
The EGP descriptors were not transferred mechanically into the final GP inventory. Descriptor consolidation was required because some EGP entries were blank, duplicated, overlapping, lexical-only, too diffuse for reliable retrieval, or different only in polarity or clause type. The consolidation process followed eight rules: removal of blank entries, merging of exact duplicates, merging of near-equivalent descriptors, subsumption of narrower descriptors under broader GPs, removal of lexical-growth-only items, merging of form-only descriptors into function-specified GPs, removal of diffuse umbrella descriptors already represented by more specific entries, and unification of polarity or sentence-type variants.
Because consolidation involved interpretive decisions, a reliability check was conducted on 20% of the descriptor-consolidation decisions. A second coder with expertise in English language teaching and linguistics independently evaluated the sampled decisions using the consolidation codebook. Inter-rater agreement reached Cohen’s κ = .87, indicating strong consistency in applying the consolidation rules (Cohen, 1960). Disagreements were reviewed against the codebook, and decision rules were clarified where needed. The final descriptor-to-GP mapping preserved traceability from the original EGP descriptors to retained, merged, subsumed, or excluded GPs. Appendix A4 in the Supplemental Material reports the consolidation principles and reliability procedure.
3.6. Corpus Operationalization, POS Tagging, and Query-Bank Construction
Each GP was operationalized as one or more corpus-queryable patterns. The annotated corpus was indexed with the IMS Open Corpus Workbench and queried using Corpus Query Processor (CQP) syntax (Evert & Hardie, 2011). Positional attributes included word form, lemma, and POS. Structural attributes encoded stage, series, book, unit, and section information, which allowed queries to be restricted or summarized by curricular location.
Before indexing, texts were processed through sentence segmentation, tokenization, lemmatization, POS tagging, and dependency parsing. The annotation workflow used Stanza v1.10.1 and spaCy v3.7.2 to support token-level annotation and downstream query design (Honnibal et al., 2020; Qi et al., 2020). Because automatic tagging may be less stable in short textbook sentences, fragments, headings, and pedagogic examples than in ordinary prose, query outputs were not accepted automatically. Concordance-line inspection was used to validate target retrievals, identify recurring false positives, and refine query guard conditions.
Query construction prioritized interpretive precision over maximal recall. Closed-class constructions were often retrieved through lemma- and POS-constrained patterns. Fixed expressions and discourse routines required multitoken patterns. Clause-linking structures and complementation patterns required additional constraints such as adjacency, sentence boundaries, or approximate clause-boundary cues. When a single GP had several common realizations, multiple query patterns were used and then deduplicated at the matched-span level.
Representative descriptor-to-query mappings are presented in Appendix A5 in the Supplemental Material. Because the raw textbook corpus is based on copyrighted third-party materials and the full query inventory contains extensive project-specific disambiguation rules developed through close inspection of those materials, the complete 602-GP query bank cannot be openly released in full. To support transparency while respecting copyright and data-use constraints, Appendix A5 in the Supplemental Material provides 40 representative query mappings, with 10 examples from each CEFR level. These examples illustrate the main query-design decisions used in the analysis, including lemma constraints, POS constraints, multiword patterns, exclusion rules, and function-sensitive retrieval decisions. The data-availability position is stated in Appendix A6 in the Supplemental Material.
3.7. Retrieval Validation and Reliability
Retrieval validation was conducted in two stages. First, candidate queries were internally checked through concordance-line inspection across stages and series. This step identified systematic overgeneration, such as strings that matched the surface pattern but not the intended GP, and undergeneration, such as attested target constructions missed by an overly narrow pattern. Queries were revised iteratively until their behavior aligned with the form–function definition of the relevant GP.
Second, an independent validation check was conducted on a stratified 20% sample of the GP inventory. The sample was stratified by CEFR level and retrieval complexity so that both frequent and less-frequent patterns were represented. A second trained analyst examined sampled query outputs at the concordance level using the same inclusion and exclusion criteria. Agreement for valid versus invalid retrieval decisions reached Cohen’s κ = .92, indicating very strong reliability. Disagreements were adjudicated against the coding manual, and revised patterns were rechecked where necessary.
This validation procedure applies specifically to retrieval decisions, not to descriptor consolidation. Consolidation reliability was addressed separately in Section 3.5. In the Supplemental Material, Appendix B3 provides the retrieval-validation protocol and Appendix B4 reports agreement statistics by decision layer.
3.8. Frequency Normalization and Salience Measures
Raw counts were not directly comparable because books and stages differed in length. GP frequencies were therefore normalized as frequencies per million words:
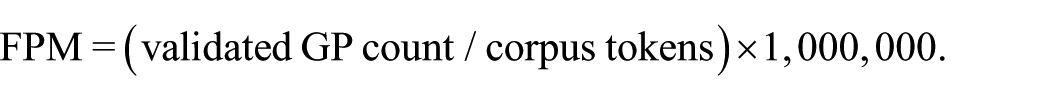
To reduce the strong right skew typical of corpus frequency data, normalized frequencies were transformed as ln(FPM + 1). Adding 1 allowed zero values at the book or stage level to remain mathematically defined after transformation. For clustering, transformed values were standardized as z scores within the relevant feature matrix so that GPs could be compared on a common scale (Brezina, 2018).
For each GP i and clustering feature j, the standardized value was calculated as

where
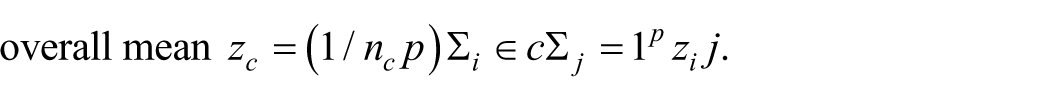
where
Two additional distributional indicators were calculated for interpretation. Book dispersion was defined as the proportion of the 57 books in which a GP occurred at least once. Stage persistence was defined as the number of school stages, from zero to three, in which a GP was attested. These indicators helped distinguish GPs that were frequent but locally concentrated from those that were sustained across the textbook ecology. They were used as interpretive complements to intensity, not as direct evidence of instructional salience or learner acquisition (Biber & Reppen, 2002; N. C. Ellis, 2002).
3.9. Clustering Analyses and Diagnostics
Level-based clustering was used to identify within-level distributional salience bands. Within each CEFR level, each GP was represented by its standardized stage-level ln(FPM + 1) profile. A1 and A2 items were modeled with three stage-level features: primary, junior secondary, and senior secondary. B1 and B2 items were modeled with two features: junior secondary and senior secondary. K-means clustering was applied separately within each level. The selected solutions were A1 = 3 bands, A2 = 4 bands, B1 = 3 bands, and B2 = 2 bands.
The number of clusters was selected separately by level because the goal of this analysis was to identify meaningful within-level structure rather than impose identical categories across CEFR levels. Cluster selection was guided by silhouette scores, within-cluster sum of squares, K − 1 / K / K + 1 comparisons, random-seed stability assessed through the Adjusted Rand Index (ARI), and agreement with Ward’s hierarchical clustering (Hair et al., 2009). Numerical diagnostics for the level-based solutions are reported in Appendix B7 and K-means/Ward agreement and random-seed stability are summarized in Appendix B8 in the Supplemental Material. Because K differed by CEFR level, the resulting bands are interpreted as within-level salience structures. A high-salience A1 band should not be treated as numerically equivalent to a high-salience B2 band.
Stage-based clustering was used to examine how the attested inventory was redistributed within each school stage. Unlike level-based clustering, which prioritized level-specific fit, stage-based clustering prioritized comparability across primary, junior-secondary, and senior-secondary materials. For that reason, K was fixed at 4 across stages. This fixed four-band frame allowed the analysis to compare core–periphery configurations across stages, but it was not interpreted as the naturally optimal K for every stage.
Band labels were assigned by ordering clusters according to mean standardized intensity, with Band 1 representing the highest-intensity group. Diagnostics for stage-based clustering included silhouette scores, within-cluster sum of squares, empty-band checks, random-seed stability, and comparison with Ward’s hierarchical clustering. These diagnostics are reported in Appendixes B8 and B9 in the Supplemental Material. The final K = 4 senior-secondary solution did not produce an empty band after filtering to the globally attested A1–B2 inventory; however, its distribution remained compressed, with the largest group concentrated in the lowest salience band. The K = 4 frame was therefore retained for cross-stage comparability rather than interpreted as the uniquely optimal senior-stage structure.
For clarity, the stage-based solutions reported in Section 4 were generated after the final analytic-dataset conventions had been applied. Primary-stage clustering used the A1–A2 analysis-ready matrix (N = 242), whereas junior-secondary and senior-secondary clustering used the globally attested A1–B2 inventory (N = 524). For the senior-secondary solution, each GP was represented by its book-level standardized ln(FPM + 1) profile within the senior-secondary subcorpus. This final analysis-ready matrix was also used for the K = 3 senior-secondary sensitivity check reported in Appendix B10 in the Supplemental Material.
3.10. Sensitivity Analyses
Several sensitivity analyses were conducted to evaluate whether the main patterns depended on corpus size, rare counts, or a single clustering specification. First, minimum-frequency floor checks were applied using n ⩾ 3 and n ⩾ 5 thresholds. These checks were especially important for the primary stage, where the token base was small and one or two occurrences could produce large FPM values. The sensitivity results are reported in Appendix B1 in the Supplemental Material.
Second, senior-secondary clustering was also analyzed with K = 3 and compared with the fixed K = 4 solution. This analysis examined whether the interpretation of senior-stage compression depended on the fixed 4-band frame. The K = 3 sensitivity check confirmed that the main pattern did not depend on K = 4: senior-secondary A1–B2 items remained unevenly distributed, with the largest group located in the lowest salience band. The comparison is reported in Appendix B10 in the Supplemental Material.
Third, K-means solutions were compared with Ward hierarchical clustering to assess whether the banding patterns were dependent on one clustering algorithm. Agreement was summarized numerically and reported with the clustering diagnostics. Fourth, random-seed stability was evaluated through repeated K-means runs and summarized using the ARI. These diagnostics are reported in Appendix B8 in the Supplemental Material.
Finally, the supplementary A1–B2 scope check examined the recurrence of validated A1–B2 GP query hits in the senior-secondary corpus. This check was included to support cautious interpretation of the senior-stage compression pattern. Because it measures query-hit recurrence rather than token or sentence coverage, it is used only to contextualize the senior-secondary pattern. The distribution of query hits across A1–B2 levels is reported in Appendix B11 in the Supplemental Material and is interpreted in relation to possible selective recycling and backgrounding within more advanced textual input in the Discussion.
4. Results
4.1. Corpus Coverage and Excluded GPs
The first analysis examined how fully the EGP-derived A1–B2 benchmark inventory was realized in the textbook corpus. Across the 602 benchmarked GPs, 78 items (12.9%) had no validated occurrence in the full corpus. These zero-occurrence items were retained for coverage reporting but excluded from intensity-based clustering because they contributed no variance to the clustering matrices.
Coverage decreased as benchmark level increased. A1 showed near-complete realization: 72 of 73 GPs were attested at least once in the corpus. A2 also showed high overall coverage, with 170 of 175 GPs attested. Coverage became more selective at the B levels: 172 of 201 B1 GPs and 110 of 153 B2 GPs were attested. This pattern indicates that the benchmark inventory did not map fully onto the realized textbook inventory, especially at higher CEFR levels.
Stage-level coverage further showed that lower-level GPs were more widely distributed across the school sequence than higher-level GPs. At A1, 69 GPs occurred in primary materials, 71 in junior secondary, and 72 in senior secondary. At A2, 99 items occurred in primary, 159 in junior secondary, and 160 in senior secondary. B1 coverage was much more limited in primary materials: although 45 of 201 B1 items were attested there, this represented only 22.4% of the benchmarked B1 inventory and the retrieved instances were sparse. By contrast, 136 B1 items occurred in junior secondary and 162 in senior secondary. B2 items were not attested in primary materials; 74 occurred in junior secondary and 84 in senior secondary.
These findings support two methodological decisions. First, the level-based clustering analysis was based on the 524 GPs attested at least once in the full corpus. Second, primary-stage clustering was restricted to A1–A2 because B1 realization in primary materials was too sparse, and B2 realization was absent. This restriction was also important because the primary subcorpus was relatively small; rare items at this stage could be disproportionately affected by one or two occurrences. The primary-stage results are therefore interpreted as descriptive evidence of realized textbook availability rather than as stable estimates of higher-level grammar weighting in early schooling.
4.2. Within-Level Distributional Salience Clustering
The level-based clustering analysis identified distinct within-level salience structures across A1–B2, as summarized in Table 3. The clustering used standardized ln(FPM + 1) profiles and identified separate solutions for each CEFR level: A1 = 3 bands, A2 = 4 bands, B1 = 3 bands, and B2 = 2 bands. The different K values reflect level-specific data structure rather than an attempt to impose identical banding across CEFR levels. For this reason, the bands should be interpreted as level-internal salience structures. A high band at A1, for example, should not be treated as numerically equivalent to a high band at B2. Cluster-selection diagnostics are reported in Appendix B7 in the Supplemental Material.
Within-Level Salience Bands from Level-Based Clustering.
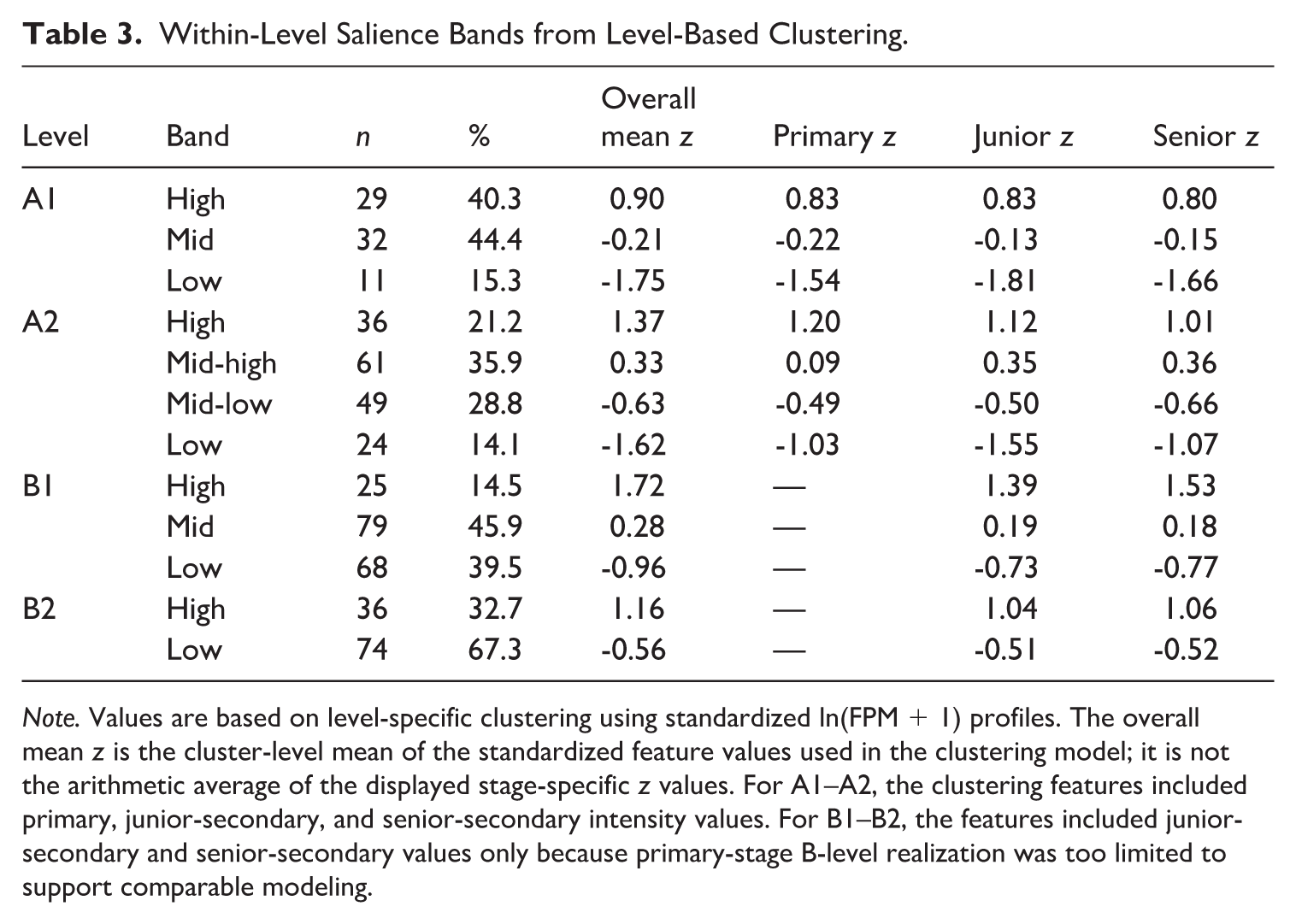
Note. Values are based on level-specific clustering using standardized ln(FPM + 1) profiles. The overall mean z is the cluster-level mean of the standardized feature values used in the clustering model; it is not the arithmetic average of the displayed stage-specific z values. For A1–A2, the clustering features included primary, junior-secondary, and senior-secondary intensity values. For B1–B2, the features included junior-secondary and senior-secondary values only because primary-stage B-level realization was too limited to support comparable modeling.
The results show that none of the CEFR levels was distributionally flat. At A1, the attested inventory formed 3 bands: high (n = 29, 40.3%), mid (n = 32, 44.4%), and low (n = 11, 15.3%). The overall mean z values of these bands were 0.90, -0.21, and -1.75, respectively. This pattern indicates a clear three-tier structure, with only a small peripheral group separated from two more strongly represented groups. The stage-specific z values were also relatively consistent across primary, junior secondary, and senior secondary, suggesting that highly salient A1 GPs remained broadly prominent across the school sequence.
A2 showed a more differentiated 4-band structure. The high band contained 36 GPs (21.2%), followed by mid-high (n = 61, 35.9%), mid-low (n = 49, 28.8%), and low (n = 24, 14.1%). This graded structure suggests that A2 was not organized around a simple core–periphery split. Instead, the textbook corpus distributed A2 items across several levels of prominence, with some items strongly sustained and others only weakly represented.
B1 returned to a 3-band structure but showed a more uneven distribution. Only 25 B1 GPs (14.5%) were assigned to the high band, whereas 79 (45.9%) were assigned to the mid band and 68 (39.5%) to the low band. This pattern suggests a long-tail distribution in which a limited subset of B1 items received strong distributional support, while many others remained moderately or weakly represented. Because primary-stage B-level realization was too limited to support comparable modeling, B1 clustering was based on junior-secondary and senior-secondary profiles only.
B2 showed the most compressed internal structure. The attested B2 inventory was divided into 2 bands: high (n = 36, 32.7%) and low (n = 74, 67.3%). This binary division indicates that B2 textbook salience was concentrated in a relatively small supported group, while most attested B2 GPs remained low in distributional prominence.
Figure 1 summarizes the proportional differences across the four benchmark levels. The visual pattern makes clear that the lower levels contained broader upper- and middle-salience distributions, whereas the B levels, especially B2, were more strongly skewed toward lower salience. A1 and B1 both formed 3-band profiles, but their internal distributions differed substantially: A1 was dominated by high and mid bands, whereas B1 was weighted toward mid and low bands. A2 showed the most finely graded 4-band profile, while B2 collapsed into a 2-band core–periphery structure.
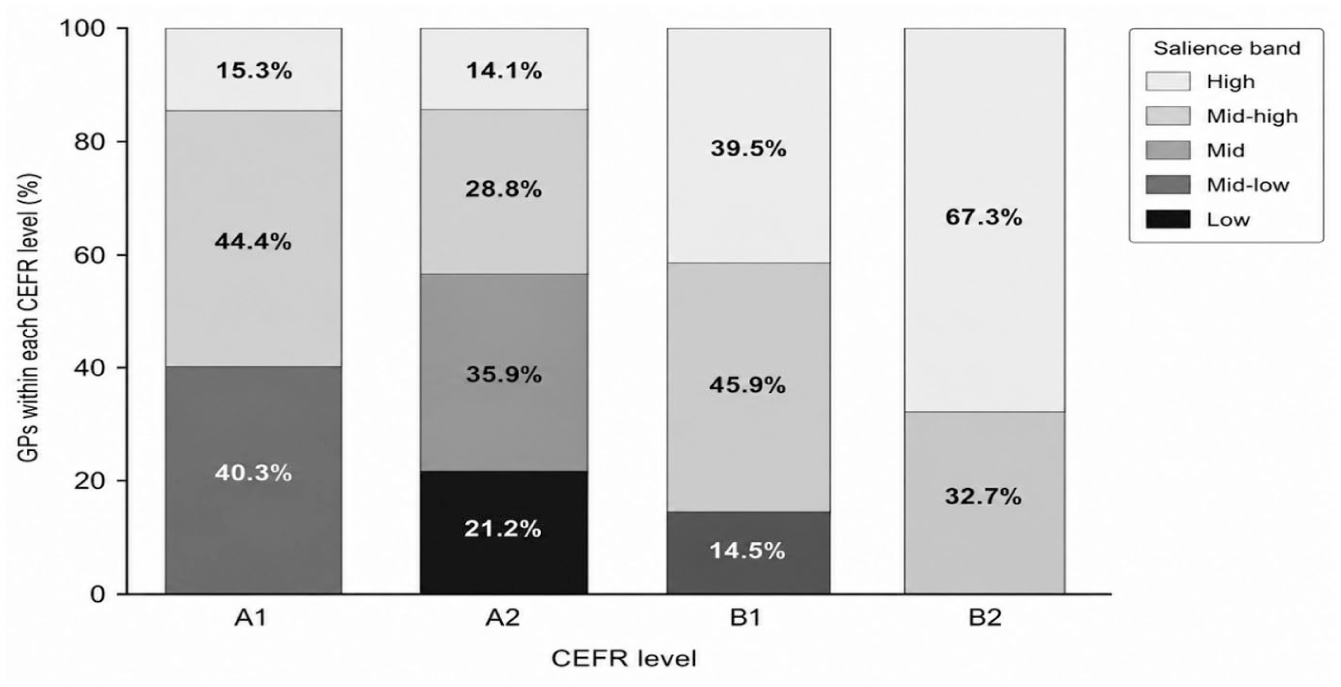
Within-level salience bands across A1–B2.
Taken together, the level-based results show that CEFR benchmark labels did not correspond to homogeneous textbook groupings. Each level contained an internal salience hierarchy, and the shape of that hierarchy differed across A1–B2. These findings support the need to distinguish benchmark placement from textbook distributional salience.
4.3. Stage-Based Salience Bands and Senior-Stage Compression
The second clustering analysis reversed the perspective by examining how the attested inventory was redistributed within each school stage. Table 4 reports the stage-based clustering results using a fixed K = 4. Bands are ordered by standardized intensity within each stage, with Band 1 representing the highest-intensity group and Band 4 the lowest. The fixed 4-band frame was used to support cross-stage comparison; it should not be interpreted as the naturally optimal K for every stage.
Stage-Based Salience Bands by School Stage.

Note. Stage-based bands are ordered within each stage by standardized intensity, with Band 1 representing the highest-intensity group and Band 4 the lowest. Primary-stage clustering was restricted to A1–A2 because B-level realization was too limited for meaningful stage-based clustering. The final K = 4 senior-secondary solution did not produce an empty band, but the distribution remained compressed, with the largest group in Band 4. The senior-secondary K = 4 and K = 3 solutions used the same final analysis-ready matrix of 524 globally attested A1–B2 GPs.
The primary stage showed a concentrated profile. Of the 242 A1–A2 GPs included in the primary-stage matrix, more than half were assigned to Band 4, while only 60 GPs were placed in Bands 1 and 2 combined. This indicates that primary materials gave relatively strong distributional support to a limited subset of GPs, while the largest group remained weakly represented. Because the primary subcorpus was comparatively small, this profile is best interpreted as descriptive evidence of realized textbook availability rather than as a stable estimate of early-stage grammar weighting for all possible low-frequency items.
Junior secondary showed a more differentiated four-band profile. Across the 524 attested A1–B2 GPs, 139 items were assigned to Bands 1 and 2, and 128 items were assigned to Band 3. Although Band 4 remained the largest group, junior-secondary materials distributed many items across upper and middle salience bands. This pattern suggests that junior secondary was a key stage for reweighting the benchmarked inventory across a wider range of distributional positions.
Senior secondary also showed an uneven profile. The final K = 4 solution did not produce an empty band, but the distribution remained skewed toward lower salience: Band 4 contained 259 of the 524 GPs, making it the largest group. At the same time, 178 GPs were assigned to Bands 1 and 2 combined, indicating that senior-secondary materials did not simply marginalize the entire A1–B2 inventory. Rather, they concentrated stronger support on a subset of items while leaving many others low in relative salience. A K = 3 sensitivity check further confirmed that this interpretation of senior-stage compression did not depend on the fixed 4-band frame.
Figure 2 summarizes the proportion of GPs assigned to Bands 1 and 2, the upper-salience tiers, within each school stage. The figure helps clarify a pattern that is less immediately visible from the full 4-band distribution in Table 4: upper-band allocation increased from primary to junior secondary and was highest in senior secondary. However, this increase should be read alongside the fact that Band 4 remained the largest group in senior secondary. Later-stage presence, therefore, did not amount to evenly distributed reinforcement across the A1–B2 inventory.
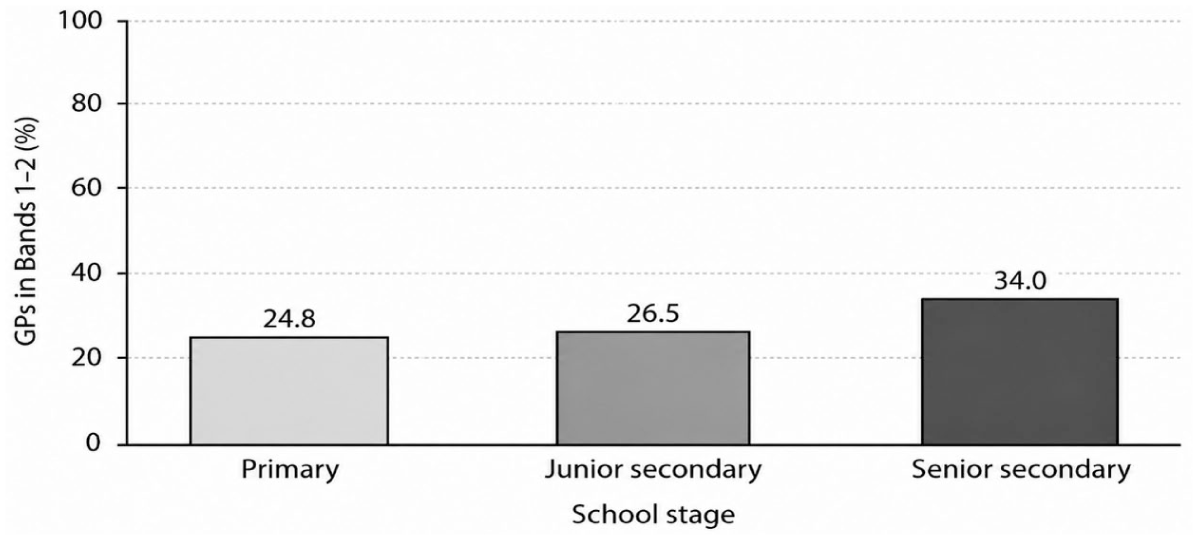
Share of GPs in Bands 1 and 2 by school stage.
The senior-stage pattern should therefore be interpreted within the study’s analytic scope. The concentration of many A1–B2 items in lower-salience bands may reflect selective recycling of lower-level grammar in senior-secondary materials. It may also reflect the increasing presence of advanced academic discourse, complex syntax, or lexicalized patterns beyond the A1–B2 inventory. The A1–B2 query-hit scope check in Appendix B11 in the Supplemental Material showed that the senior-secondary subcorpus contained 113,519 validated A1–B2 GP query hits, but that these hits were heavily weighted toward A1 items. This suggests that A1–B2 grammar remained recurrent in senior-secondary materials, while much of that recurrence was concentrated in A1 items. Many A2–B2 GPs may therefore have become relatively backgrounded within more advanced textual input. For this reason, the senior-stage compression finding is interpreted as a distributional pattern within the study’s analytic scope, not as direct evidence of inadequate recycling.
4.4. Representative GPs and Macro–Micro Interaction
Representative GPs were examined to make the clustering results interpretable in linguistic terms. For each CEFR level, one item was selected from a high within-level macro band where broad stage attestation was available, and one item was selected from a low macro band that remained peripheral. Table 5 aligns each GP’s within-level macroposition with its stage-specific band assignments under the final K = 4 stage-based solutions.
Representative GPs Illustrating Macrobands and Stage-Based Bands.
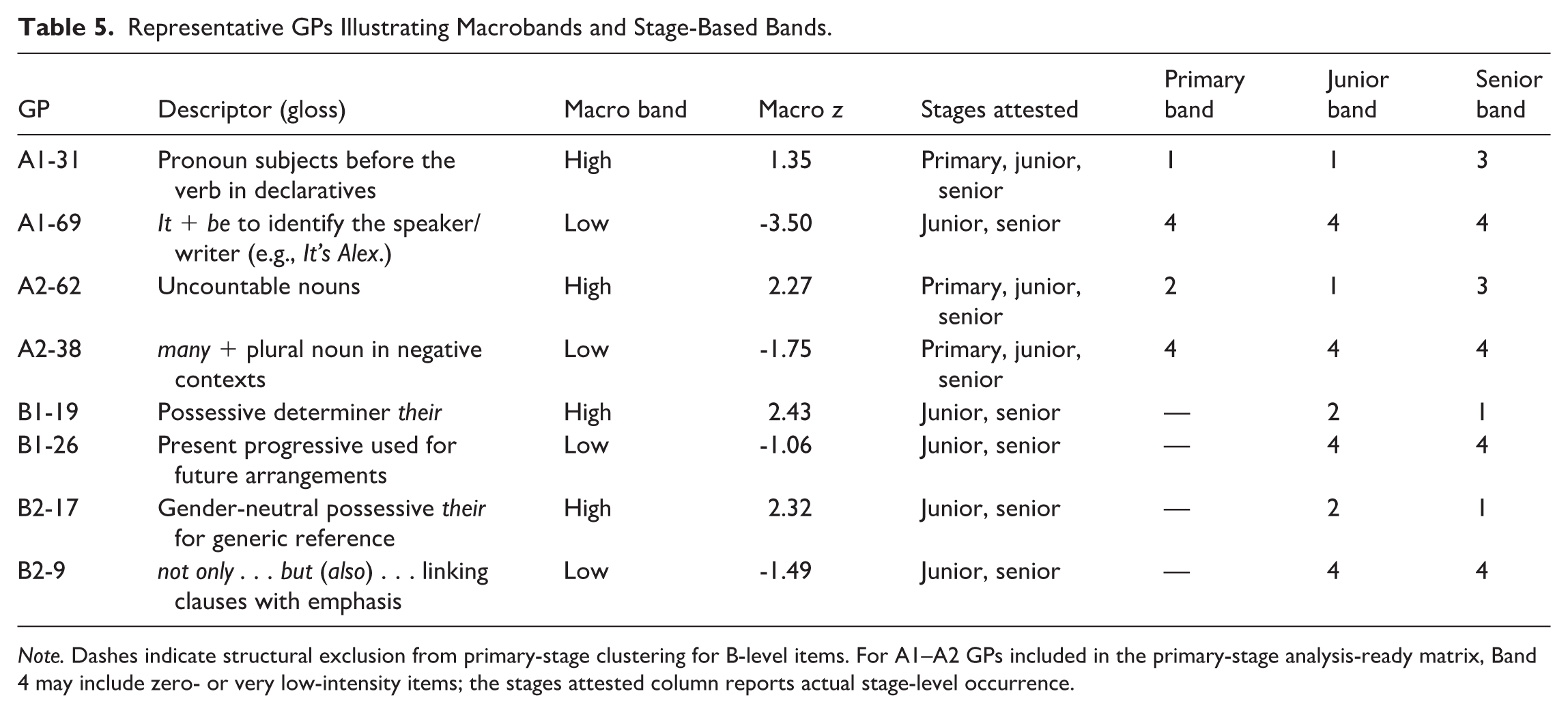
Note. Dashes indicate structural exclusion from primary-stage clustering for B-level items. For A1–A2 GPs included in the primary-stage analysis-ready matrix, Band 4 may include zero- or very low-intensity items; the stages attested column reports actual stage-level occurrence.
The examples show that macro salience and stage-based salience were related but not identical. High-macro items were generally more widely attested and more likely to appear in upper stage-based bands, but their relative prominence still varied across school stages. A1-31, pronoun subjects before the verb in declaratives, remained in Band 1 in both primary and junior-secondary materials but shifted to Band 3 in senior-secondary materials. A2-62, uncountable nouns, showed a similar cross-stage shift, moving from Band 2 in primary materials to Band 1 in junior secondary and Band 3 in senior secondary. These examples indicate that a GP can be central within its CEFR level while receiving weaker relative distributional support in a later stage.
Low-macro items showed a more consistently peripheral profile. A2-38, many + plural noun in negative contexts, and B2-9, not only . . . but (also) . . ., remained in Band 4 wherever they were included in the stage-based analysis. This pattern suggests that some low-salience GPs were not merely low in the level-based macroprofile but also weakly represented across the relevant school-stage profiles.
The B-level examples qualify the senior-secondary compression pattern. B1-19, possessive determiner their, and B2-17, gender-neutral possessive their for generic reference, were both high-macro items and moved from Band 2 in junior-secondary materials to Band 1 in senior-secondary materials. Thus, although senior secondary was compressed overall, selected B-level GPs still became highly prominent. These examples clarify that within-level centrality does not guarantee identical stage-level prominence, and that a compressed stage profile can still contain a small set of strongly supported GPs.
4.5. Dispersion and Persistence beyond Frequency
Because frequency-based intensity does not show whether a GP was broadly distributed or locally concentrated, book dispersion and stage persistence were examined as interpretive complements. Book dispersion measured the proportion of the 57 books in which a GP was attested at least once, while stage persistence measured the number of school stages in which it occurred. These indicators were not used as clustering inputs; rather, they were used to evaluate whether the intensity-based salience bands also reflected broader distribution across the textbook ecology.
Figure 3 summarizes mean book dispersion by within-level salience band. The overall pattern supports the intensity-based clustering results: dispersion generally declined as macro salience decreased. High-band GPs tended to occur across more books, whereas low-band GPs were more narrowly distributed. This pattern indicates that highly salient items were not only frequent in normalized terms but also more widely spread across the 57-book corpus.
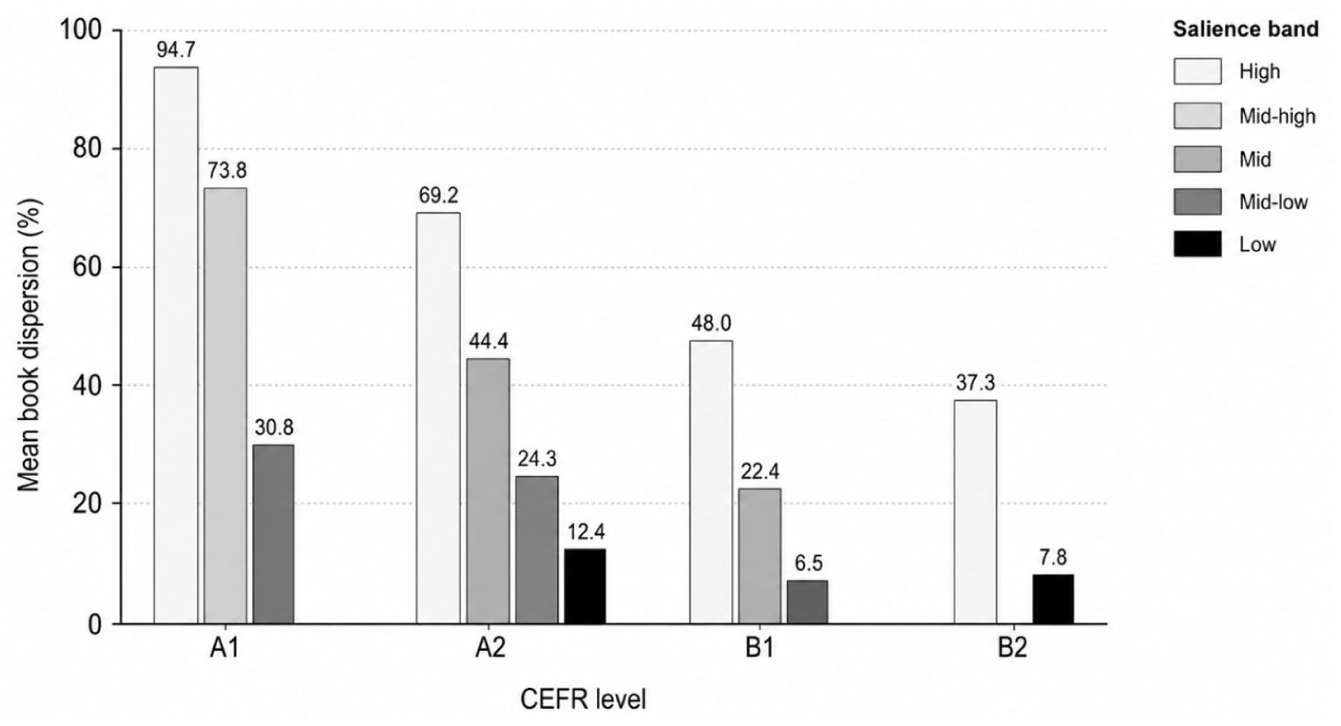
Mean book dispersion by within-level distributional salience band.
Stage persistence showed a comparable tendency. High-salience bands tended to remain attested across more school stages, whereas low-salience bands showed weaker continuity. The gradient was especially clear at A2, where mean stage persistence declined from 2.94 in the high band to 1.58 in the low band. Similar, though less steep, declines were observed at B1, from 2.00 to 1.54, and at B2, from 1.97 to 1.42. The corresponding mean book-dispersion and stage-persistence values by level and salience band are reported in Appendix B6 in the Supplemental Material.
These indicators reinforce the interpretation of the salience bands as distributional categories, but they do not transform them into measures of instructional salience. A GP that is frequent, dispersed, and persistent is more visible in the textbook ecology; the present analysis does not show whether it was explicitly taught, noticed by learners, or acquired. Dispersion and persistence therefore clarify materials-based prominence while preserving the distinction between distributional salience and instructional or acquisitional claims.
4.6. Sensitivity Checks and Robustness
To assess the stability of the observed patterns, sensitivity checks were conducted for rare counts, alternative K specifications, and clustering-algorithm dependence. Detailed diagnostics and sensitivity results are reported in Appendixes B1 and B7–B11 in the Supplemental Material. The results are summarized here because they affect the interpretation of the primary-stage and senior-stage findings.
First, minimum-frequency floor checks using n ⩾ 3 and n ⩾ 5 were applied to examine whether rare occurrences drove the clustering patterns. As noted in Section 4.1, this check was especially important for primary materials, where rare occurrences could have disproportionate effects after FPM normalization. The sensitivity results showed that the broad primary-stage pattern remained concentrated: a limited number of A1–A2 items continued to account for the upper bands, while the largest group remained in the lower band. However, some individual low-frequency items shifted or dropped out under stricter thresholds, confirming that fine-grained primary-stage rankings should be interpreted cautiously.
Second, the senior-secondary solution was rerun with K = 3. This sensitivity check examined whether the interpretation of senior-stage compression depended on the fixed K = 4 specification. The K = 3 solution provided a simpler structure and a slightly stronger silhouette value than K = 4, but it preserved the same substantive pattern. The senior-secondary profile remained skewed toward the lowest salience group, confirming that the compression finding was not an artifact of the fixed 4-band frame.
Third, K-means solutions were compared with Ward hierarchical clustering. The comparison supported the broad separation between higher- and lower-salience groups, although boundary cases differed across algorithms. This is expected in sparse or skewed corpus data and reinforces the interpretation of the clusters as descriptive salience bands rather than uniquely determined latent categories. Random-seed checks also supported the stability of the major banding patterns, with most instability concentrated among items near band boundaries. Together, these robustness checks support the main descriptive findings while limiting the interpretation of marginal cases.
Finally, the senior-secondary pattern was interpreted with attention to the A1–B2 scope of the study. Because senior materials may contain advanced academic language beyond the study’s inventory, the compression pattern should be read as a result within the A1–B2 analytic boundary. This issue is taken up again in Section 5.
4.7. Summary of Results
The results provide three main findings. First, benchmark placement did not guarantee textbook realization. A total of 78 benchmarked A1–B2 GPs were unattested in the corpus, and coverage became more selective at higher levels. This confirms that a CEFR-linked inventory and a realized textbook inventory are related but not identical.
Second, the level-based analysis showed that each CEFR level contained internal salience stratification. Rather than functioning as homogeneous textbook categories, A1–B2 displayed distinct distributional profiles.
Third, school stages redistributed the inventory differently. Primary materials concentrated support on a limited A1–A2 subset, while junior secondary showed broad differentiation across upper, middle, and lower salience bands. Senior secondary showed a compressed A1–B2 profile: although the final solution did not produce an empty band, the largest group remained concentrated in the lowest salience band. The K = 3 sensitivity check further confirmed that this compression pattern was not an artifact of the 4-band frame. Overall, the findings describe system-level materials allocation rather than instructional salience, classroom enactment, or learner acquisition.
5. Discussion
5.1. From Broad CEFR Levels to Within-Level Distributional Profiling
The findings show that broad CEFR-linked grammar levels are not distributionally flat once they are examined through a textbook corpus. Each level separated into internal salience bands, and the shape of this stratification differed across A1–B2. A1 formed a relatively stable 3-band structure, A2 showed the most differentiated 4-band profile, B1 displayed a long-tail pattern, and B2 was compressed into a 2-band core–periphery profile. These results suggest that CEFR benchmark labels define a useful reference space, but they do not show how GPs are materially weighted in a textbook system.
This distinction is important for CEFR-referencing curriculum work. The CEFR supports comparability across contexts, and the EGP provides a grammar-oriented benchmark for level placement (Council of Europe, 2020; Hawkins & Filipović, 2012; O’Keeffe & Mark, 2017). However, neither framework determines how strongly each GP is represented in a particular set of school materials. The present findings therefore add a distributional layer to CEFR-linked grammar profiling. They show that items sharing the same benchmark level may occupy very different positions in the realized textbook inventory.
The value of within-level profiling is diagnostic rather than prescriptive. It does not show which GPs should be taught first, nor does it identify a universal teaching order. Instead, it makes visible how a textbook ecology has already allocated attention. For example, a high-salience A2 item is not necessarily more important than a low-salience A2 item in linguistic or pedagogical terms. It is, however, more strongly institutionalized in the materials. Such evidence can support textbook review by showing where broad level labels conceal substantial differences in materials-based prominence.
5.2. Benchmark Placement and Textbook Salience as Nonequivalent Constructs
A central implication of the study is that benchmark placement and textbook salience should be treated as related but non-equivalent constructs. Benchmark placement refers to the position of a GP within a CEFR-linked reference inventory. Textbook salience refers to the extent to which that GP is realized, intensified, dispersed, and sustained in an actual textbook corpus. The former is classificatory; the latter is distributional.
This distinction helps explain why coverage alone is insufficient for textbook evaluation. A GP may be included in a textbook system but appear only once or in a narrowly localized context. Another GP at the same CEFR level may recur across books, series, and stages. Both items are covered, but they do not receive the same degree of materials-based support. The clustering results make this difference visible by separating broad benchmark categories into empirically observed salience bands.
The findings also show that higher benchmark level does not automatically correspond to stronger later-stage support. Some lower-level GPs remained highly visible across the K–12 sequence, whereas many B-level GPs were only weakly represented. This pattern is consistent with the nature of school textbooks, where reusability across topics, routines, and communicative functions may shape distributional prominence as much as formal level assignment. A GP may become central because it is repeatedly useful in textbook discourse; another may remain peripheral because it is context-bound, discourse-specific, or less easily recycled.
However, low salience should not be interpreted as low value. A peripheral GP may still be benchmark-appropriate, instructionally important, or useful for particular discourse functions. It may also be supported through teacher explanation, supplementary materials, or classroom practice that is not visible in the student-book corpus. The present analysis therefore identifies how textbooks allocate distributional prominence, not what the curriculum ought to prioritize.
5.3. Textbook Distributional Salience is Not Instructional Salience
The study deliberately distinguishes distributional salience from instructional salience. Distributional salience was operationalized through normalized frequency, book dispersion, and stage persistence. These indicators show how often and how widely a GP appears in the textbook ecology. Instructional salience, by contrast, depends on whether the item is explicitly explained, highlighted metalinguistically, practiced through focused exercises, required in tasks, revisited in review sections, or mediated by teachers. These dimensions were outside the scope of the present corpus analysis.
This distinction is necessary because frequency-based evidence can easily be overinterpreted. A frequent GP may occur mainly in reading passages or dialogue input without being the target of explicit instruction. Conversely, a less-frequent GP may receive focused explanation or concentrated practice in a grammar section. Therefore, the statistical bands reported in this study should be read as distributional bands, not as direct instructional bands.
The same caution applies to acquisition. Repeated exposure may support noticing and entrenchment, and frequency-sensitive research has shown that recurrence can shape learning opportunities (Biber & Reppen, 2002; Bybee, 2006; N. C. Ellis, 2002). Yet exposure does not guarantee uptake. Learning depends on attention, prior knowledge, task conditions, memory, developmental readiness, and classroom mediation (DeKeyser, 2017; R. Ellis, 2006; Pienemann, 1989). The findings therefore describe the organization of textbook input rather than learner development.
This limitation does not weaken the value of the analysis. Instead, it clarifies what kind of evidence textbook corpora can provide. Corpus-based salience profiles are useful because they show how institutional materials make grammar available. They can identify highly recurrent items, weakly distributed items, and gaps between benchmark inventories and realized textbook input. These are important findings for materials review, but they should be integrated with task analysis, teacher-guide analysis, classroom observation, and learner data before stronger pedagogical claims are made.
5.4. Senior-Secondary Compression and Alternative Interpretations
The senior-secondary findings require particular caution. The final K = 4 stage-based solution did not produce an empty band, but it showed a compressed distribution in which the largest group of A1–B2 GPs was concentrated in the lowest salience band. The K = 3 sensitivity check confirmed that this pattern remained visible under a simpler clustering specification. The substantive point, therefore, is not that senior-secondary materials require a fixed number of salience bands, but that the A1–B2 inventory is unevenly distributed in the senior-stage corpus.
One possible interpretation is selective recycling. Under this reading, senior-secondary textbooks continue to include lower- and mid-level grammar but concentrate stronger distributional support on a smaller set of reusable items. Many other A1–B2 GPs remain present with weaker salience, suggesting that later-stage materials do not evenly reinforce the full benchmark inventory. This interpretation is plausible because advanced school materials often allocate more space to reading, academic topics, test-oriented discourse, and complex communicative tasks than to systematic recycling of earlier grammar.
A second interpretation is backgrounding within more advanced input. Senior-secondary textbooks may contain substantial academic discourse, dense lexis, complex syntax, and C1+ features that fall outside the A1–B2 inventory used in this study. If so, the lower relative salience of many A1–B2 GPs may not indicate under-recycling alone. It may also show that benchmarked lower- and mid-level grammar recedes into the background as the materials shift toward more advanced textual demands.
These interpretations are not mutually exclusive. Senior-secondary materials may both recycle selected lower-level GPs and introduce or foreground language beyond the A1–B2 scope. For this reason, the senior-stage result should be described as a compressed distribution of A1–B2 grammar within the study’s analytic boundary, not as direct evidence of inadequate materials design. Future research should extend the inventory to C1 and above, examine discourse-level grammar, and compare grammar salience with task type and explicit instructional focus in senior-secondary textbooks.
5.5. Transferability beyond Taiwan’s Textbook Ecology
Although the empirical corpus was drawn from Taiwan’s ministry-approved K–12 EFL textbook ecology, the underlying problem is not limited to Taiwan. Any educational system that adopts broad proficiency labels must still decide how benchmarked content is distributed across grades, books, and stages. The present study therefore does not claim that the specific salience patterns found in Taiwan will generalize to other systems. Rather, its transferable contribution lies in the analytic distinction between benchmark placement and textbook distributional salience.
This distinction can inform textbook evaluation in other CEFR-referencing contexts. Alignment should not be treated only as a checklist question of whether level-linked items are present. A more informative question is how those items are represented across the materials system. Which GPs are unattested? Which are frequent but locally concentrated? Which are dispersed across books and stages? Which remain peripheral despite belonging to the target benchmark range? Such questions move evaluation from alignment-as-coverage toward alignment-as-distribution.
The multiseries nature of the Taiwanese corpus also points to a broader methodological issue. In systems where several approved textbook series coexist, one series cannot fully represent the curriculum ecology. A system-level analysis can show which patterns are recurrent across approved materials and which may be publisher-specific. This approach is especially useful for CEFR-referencing systems because it allows researchers to examine how shared benchmark frameworks are translated into concrete textbook input across different materials pathways.
At the same time, transferability should be understood carefully. The method is more portable than the findings. Other contexts may show different levels of coverage, different within-level band structures, or different stage-based profiles. These differences would not weaken the framework; they would illustrate how CEFR-linked grammar is locally mediated through curriculum policy, textbook approval systems, publisher practices, and school-stage priorities.
5.6. Implications for Materials Review and Syllabus Investigation
The findings suggest several directions for materials review and syllabus investigation. First, within-level tiering should be examined rather than assumed. The results show that items within the same CEFR level may receive very different degrees of textbook support. Materials developers and curriculum reviewers can use salience profiles to ask whether such tiering is intentional, pedagogically justified, and consistent with the aims of the course or school stage.
Second, recycling should be reviewed as a distributional trajectory. A GP may be introduced at one stage but receive little later support. Conversely, a lower-level GP may remain visible across the full school sequence because it is useful for repeated communicative work. Salience profiles can help identify these trajectories and support questions about whether a GP should be densely recycled, periodically revisited, or only selectively exposed. These decisions should be based not only on corpus evidence but also on pedagogical purpose, task design, and learner needs.
Third, dispersion should be treated as an important complement to frequency. A GP that occurs many times in one narrow location is not equivalent to a GP that appears across books, stages, and series. For materials design, this means that high frequency should be checked against spread. Broad dispersion may indicate sustained curricular presence, whereas local clustering may indicate concentrated treatment in a single unit or topic.
Fourth, the findings can support teacher decision-making, but only cautiously. A low-salience GP may signal a need for teacher-led review, supplementary practice, or additional recycling if the item is important for a local curriculum goal. A high-salience GP may already receive substantial exposure in the textbook system, but teachers may still need to provide explicit explanation or guided practice depending on learner difficulty. Salience profiles therefore offer diagnostic information; they do not replace professional judgment or classroom evidence.
5.7. Methodological Contribution and Limitations
The main methodological contribution of this study is the integration of three components into a vertical textbook-analysis framework: an externally interpretable CEFR-linked grammar inventory, corpus-based indicators of textbook distributional salience, and a dual clustering design that captures both within-level differentiation and stage-specific reweighting. This framework makes it possible to examine not only whether benchmarked GPs are present, but how strongly and widely they are represented in a K–12 textbook ecology.
The framework also contributes to transparent textbook evaluation by making key analytic decisions explicit. The study documents the corpus ecology, text extraction and cleaning procedures, descriptor consolidation, query-based operationalization, retrieval validation, frequency normalization, clustering decisions, and sensitivity checks. These procedures are important because grammar retrieval is more interpretive than lexical counting. Many GPs involve form–function distinctions, optional elements, and context-sensitive meanings that require validation beyond surface matching.
Several limitations define the scope of the findings. First, the primary-stage subcorpus was relatively small. Because one occurrence in the primary corpus corresponds to approximately 40 FPM, rare items may have unstable normalized values. The minimum-frequency sensitivity checks partly address this issue, but fine-grained primary-stage rankings should still be interpreted cautiously.
Second, the senior-secondary clustering illustrates the importance of sensitivity checks. Although the final K = 4 solution did not produce an empty band, the K = 3 comparison showed that the broader interpretation of senior-stage compression was stable across specifications. This supports the use of the 4-band frame for cross-stage comparison while cautioning against treating the resulting bands as uniquely determined latent classes.
Third, the analysis is based on query-derived estimates. Although retrieval validation showed strong agreement, query-based grammar identification remains an approximation. Some constructions are polyfunctional, some require contextual interpretation, and some may be difficult to capture fully through CQP-style patterns. The counts should therefore be read as validated distributional estimates rather than exact representations of all possible target uses.
Fourth, the full query bank and textbook corpus cannot be openly released in full because of copyright and data-use constraints. The study addresses this limitation by providing representative query mappings, a data-availability statement, validation procedures, and reliability evidence. This supports transparency, but it does not provide the same level of open reproducibility as a fully public corpus and query archive.
Fifth, EGP benchmark placement is not a wholly independent standard. CEFR-referencing textbooks may themselves be influenced by CEFR- or EGP-informed assumptions, creating a degree of benchmark-material circularity. The analysis therefore treats the EGP as an interpretable reference inventory rather than as a neutral external criterion.
Sixth, the study is restricted to A1–B2 GPs. This is appropriate for examining much of K–12 school English, but it limits interpretation of senior-secondary materials, where advanced academic language and C1+ features may become more prominent. Finally, the study does not analyze textbook pedagogy, teacher mediation, classroom enactment, or learner acquisition. Future research should connect distributional salience with task-level grammar treatment, teacher guides, classroom use, learner production, and finer unit- or volume-level sequencing.
6. Conclusion
This study examined vertical grammar salience in Taiwan’s CEFR-referencing K–12 EFL textbook ecology. Using a corpus of 57 ministry-approved student books comprising 234,134 cleaned English tokens, the study traced how an EGP-derived inventory of 602 A1–B2 GPs was realized across primary, junior-secondary, and senior-secondary materials. The analysis distinguished CEFR benchmark placement from textbook distributional salience and examined this relationship through coverage analysis, level-based clustering, stage-based clustering, dispersion, persistence, and sensitivity checks.
Three findings stand out. First, the benchmark inventory did not fully map onto the realized textbook inventory: 78 A1–B2 GPs were unattested in the corpus. Second, broad CEFR levels contained internal salience stratification, showing that A1, A2, B1, and B2 were not distributionally homogeneous categories in the textbook system. Third, school stages reweighted the inventory differently. Junior secondary showed broad redistribution across salience bands, whereas senior secondary showed a compressed A1–B2 profile, with the largest group of items concentrated in the lowest salience band. This pattern remained visible in the K = 3 sensitivity check and should be interpreted cautiously as possible selective recycling, backgrounding within more advanced input, or both.
The study contributes a distributional profiling framework for CEFR-referencing textbook evaluation. Its main contribution is not to prescribe a teaching order, but to make the relationship between benchmark placement and textbook salience empirically inspectable. This framework can help researchers and materials reviewers examine whether textbook systems merely include benchmarked grammar or provide sustained and dispersed opportunities for encounter.
The findings should be interpreted within clear limits. They describe materials-based availability, not instructional salience, classroom enactment, or learner acquisition. Future research can extend the framework to task-level grammar treatment, teacher mediation, learner production, C1+ discourse features, cross-context comparison, and finer grade- or unit-level sequencing.
Supplemental Material
sj-docx-1-ltr-10.1177_13621688261460188 – Supplemental material for Beyond Level Labels: Profiling Vertical Grammar Salience in Taiwan’s CEFR-Referencing K–12 EFL Textbooks
Supplemental material, sj-docx-1-ltr-10.1177_13621688261460188 for Beyond Level Labels: Profiling Vertical Grammar Salience in Taiwan’s CEFR-Referencing K–12 EFL Textbooks by Tzu-Fen Nellie Yeh and Mei-Chen Julia Chu in Language Teaching Research
Footnotes
Acknowledgements
The authors would like to extend heartfelt thanks to Chia-Hsiang Ma, Wan-Yun Chung, and Yu-Rong Chang for their generous assistance in building the textbook corpus and for their support with data organization and statistical analysis.
Ethical Considerations
Ethics approval was not required for this study because the research did not involve human participants, personal data, or identifiable private information. The analysis was based on published textbook materials and corpus-derived distributional data.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The full dataset is not publicly available because it is derived from copyrighted textbook materials. To support methodological transparency, the article provides detailed documentation of the corpus design, inventory flow, descriptor consolidation, retrieval validation, clustering settings, and representative descriptor-to-query mappings in the appendixes in the Supplemental Material. Additional aggregated analytical outputs may be available from the corresponding author upon reasonable request, subject to copyright and institutional constraints.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.