
Abstract
With the rapid development of information technology, personalized learning resource recommendation systems have shown great potential in English learning. However, current English learning resources are abundant but scattered, making it difficult for learners to obtain learning materials that efficiently meet their needs. Based on this, this study constructed a personalized recommendation system that integrates the GloVe model to capture words' distributed representation, effectively improving resource recommendations' accuracy and relevance. The recommendation system preprocesses large-scale English learning resources and generates personalized resource recommendation lists based on learners' historical learning behaviors and preferences. During the experiment, a three-month test was conducted on 100 learners with different levels of English proficiency, and corresponding usage feedback and learning effectiveness data were collected. The experimental results showed that compared to traditional recommendation methods, the recommendation system based on GloVe improved resource matching by 35% and learner satisfaction by 40%. A survey found that 80% of learners reported that recommended resources better met their learning needs, and their learning efficiency increased by an average of 25%. The system also promoted the growth of learners' vocabulary. The experimental group learners increased their vocabulary by an average of 1500 words within 3 months, significantly higher than the 800 words in the control group. The personalized recommendation system for English learning resources based on GloVe has shown excellent performance in improving the matching of learning resources, learner satisfaction, and learning outcomes, providing strong support for English learning.
Keywords
Introduction
With the deepening of globalization, the importance of English as an international lingua franca is becoming increasingly prominent, and more and more people are devoting themselves to learning English. 1 Improving learning efficiency is one of the primary tasks in English teaching. With the continuous development of computer technology and communication infrastructure, digital learning methods have greatly improved the convenience of English learning. However, faced with many English learning resources, learners often face difficulties choosing and finding learning materials that meet their needs.2,3 Due to the differences in data attribute characteristics between English learning resources and standard text or images, traditional content recommendation systems make it difficult to provide users with English learning resources that meet their needs.
With the acceleration of global integration, the demand for learning English as an international lingua franca is growing explosively. In the Internet era, a large number of English learning resources have sprung up, covering courses, reading materials, audio and video and other forms, however, the current English learning resource recommendation system is facing many difficulties. On the one hand, the traditional recommendation system based on collaborative filtering relies too much on user historical behavior data, which has the problem of “cold start,” and it is difficult to provide effective recommendations for new users. On the other hand, most recommendation systems lack a deep understanding of the semantics of learning resources, resulting in serious homogeneity of recommended content, which cannot meet the personalized and diverse needs of learners, such as the mismatch between the recommended resources and the actual level of learners, or the fact that they only focus on a certain type of learning materials, making it difficult to construct a complete knowledge system. This study proposes a personalized recommendation system for English learning resources based on GloVe, which aims to use the powerful semantic representation ability of the GloVe model to mine the semantic association between words in the text of English learning resources, and effectively solve the problem of cold start and insufficient semantic understanding of traditional recommendation systems. At the same time, combined with multi-dimensional user profiles such as learners' learning motivation and frequency, accurate personalized recommendations are realized, learning resources that are more suitable for learners' own needs, filling the shortcomings of the current recommendation system in the application of English learning scenarios, and helping to improve the efficiency and quality of English learning.
In recent years, the rapid development of natural language processing technology has provided new ideas for solving this problem.4,5 Among them, the GloVe (Global Vectors for Word Representation) model, as an advanced method of word vector representation, has received widespread attention. The GloVe model effectively reveals the semantic relationships between words by capturing their distributed representations, providing a powerful tool for in-depth analysis of text content. 6 The GloVe model is based on the principle of matrix decomposition, which constructs a co-occurrence matrix of words and decomposes it to obtain vector representations of words.7,8 Traditional word vector representation methods such as Word2Vec often only focus on the local context of words and ignore the importance of global information.9,10 The GloVe model can simultaneously consider regional and international information, generating more accurate and comprehensive word vector representations that reflect the global distribution characteristics of words in the entire corpus.11,12 Training GloVe models on large-scale corpora, parallel computing, and optimization algorithms can significantly improve training speed.13,14 At the same time, the word vectors generated by the GloVe model can be easily combined with other natural language processing tasks, such as text classification, sentiment analysis, etc., providing the possibility for building a comprehensive English learning resource recommendation system.15,16
With the rapid development of Internet technology, English learning resources are growing explosively, but traditional recommendation systems are difficult to meet the personalized needs of learners. On the one hand, traditional recommendation algorithms such as collaborative filtering only make recommendations based on user behavior data, which cannot deeply understand the semantic content of English learning resources, resulting in a lack of pertinence in the recommendation results. For example, in the face of different types of needs such as grammar learning, vocabulary expansion, and oral practice, it is difficult to accurately distinguish between traditional recommendations. On the other hand, in the process of learning English, learners' needs will change with the learning progress and knowledge mastery, and the existing recommendation system lacks the ability to track dynamically. Based on this, this study aims to use GloVe technology and deep interaction modeling to solve these problems and provide better recommendation services for English learners.
There are currently three most commonly used methods for personalized recommendation. Collaborative filtering recommendation system, which filters the same learning resource “neighbor set” and recommends learning resources based on their rating information; A content-based recommendation system requires the establishment of a user interest feature vector resource association matching model in advance, which recommends similar resources by analyzing the user’s preferred resources. The resources recommended by this system are all that the user is interested in, and once their interest preferences change, they are no longer applicable. The multi-factor mixed recommendation system is a hybrid of the abovementioned systems. Still, the process is complex and requires multiple processing steps to complete a recommendation task, resulting in low efficiency.17,18
This article designs a new personalized recommendation system for English teaching resources based on the GloVe method based on deep learning. By continuously learning the behavioral characteristics of users and constructing deep learning models, the association between users and English teaching resources can be effectively represented, thereby completing teaching resource recommendations. The designed system can dynamically adjust recommendation strategies based on learners' learning progress and feedback, achieving continuous optimization of personalized learning. At the same time, providing learners with a customized list of recommended learning resources helps them quickly find learning materials that meet their needs and improve learning efficiency.
At present, in the research on English learning resource recommendation, some scholars use the content-based recommendation method, which only recommends from the surface features of the resource text, ignoring the in-depth mining of semantic information. The recommendation method based on user collaborative filtering is susceptible to data sparsity and cold start problems, and it is difficult to make accurate recommendations. Although the recommendation method based on deep learning has improved the recommendation effect to a certain extent, there are still deficiencies in the accurate understanding of the semantics of English learning resources and the real-time response to the dynamic needs of learners. Compared with these existing works, the recommendation system based on GloVe and deep interaction modeling proposed in this study has significant advantages in the depth and dynamic adaptability of semantic understanding, which can more accurately locate learners' needs, effectively make up for the limitations of existing research, and provide new ideas and methods for the field of personalized recommendation of English learning resources.
In educational institutions, teachers can be assisted to customize exclusive learning programs for students of different levels, push grammar analysis and vocabulary memory resources for students with weak foundations, and provide academic literature, business English and other content for advanced learners. In the field of corporate training, according to the English ability of employees and job requirements, we can accurately match industry English materials and business communication cases to improve training efficiency; for self-learning users, suitable resources can be pushed according to their learning habits and goals, so as to stimulate their interest in learning and help improve their self-learning ability. On the online learning platform, the system application is more in-depth and breadth, not only can dynamically analyze the user’s English proficiency, preferences and weak links based on the user’s registration information, historical learning records and behavioral data, and accurately recommend courses such as IELTS preparation question type training, foreign teacher oral dialogue, etc., but also combine the semantic relationship mined by the GloVe model to plan a personalized learning path for users, connect various learning resources, and recommend relevant topic discussions and experience sharing according to user interests in the learning community, so as to enhance user interaction. Create a good learning atmosphere and effectively improve the user’s learning experience and effect.
The existing recommendation systems for English learning resources mostly rely on traditional algorithms such as collaborative filtering and content-based recommendation, which have some problems, such as data sparsity affecting the recommendation effect and difficulty in capturing semantic relationships. In contrast, the GloVe-based personalized recommendation system for English learning resources proposed in this study innovatively introduces the GloVe model to learn the distributed vector representation of words through the global statistical analysis of the corpus, breaking through the limitations of traditional algorithms based on surface feature matching and improving the recommendation accuracy from the semantic level. In terms of data processing and feature extraction, the semantics of resource text are deeply analyzed, and user behavior data is integrated to construct a comprehensive and accurate feature representation. In terms of application scenario adaptation, the recommendation strategy can be dynamically adjusted according to different learning scenarios and user learning stages. In addition, thanks to the versatility of the GloVe model, the system can easily adapt to learning resources of different types and fields, with stronger scalability and long-term application value, and has shown significant advantages in many aspects such as recommendation accuracy, scenario adaptability and versatility.
Basic theory and key technology
GloVe model principles
The GloVe model is a learning method for word vector representation, which combines the advantages of global matrix factorization and local context window and aims to capture the global co-occurrence information of words in a corpus. 19 The core idea of the GloVe model is to learn word vectors that can reflect the similarity and correlation of word meanings through the co-occurrence probability matrix between words.
In the GloVe model, the co-occurrence matrix is a key concept. This matrix counts the number of co-occurrences of all lexical pairs in the corpus, that is, how often one word occurs in the context of another word.
20
The GloVe model is shown in Figure 1. Figure 1 illustrates the architecture of the GloVe-based GloVe-based GloVe model in a personalized recommendation system for English learning resources. The model receives the input of English resources and recommended resources, extracts the features of the data through the encoder blocks containing modules such as layer normalization and multi-head attention, and further processes the features by using the convolutional neural network blocks. After that, after dimensionality reduction and fully connected layer processing, the English resource recommendation and recommendation system application are finally realized, aiming to accurately recommend suitable English learning resources for users. The latent semantic space of the vocabulary can be obtained by singular value decomposition (SVD) of the co-occurrence matrix. However, directly decomposing the co-occurrence matrix has problems of high computational complexity and sparsity, so the GloVe model adopts a more efficient learning strategy. The objective function of the GloVe model consists of two parts: the fitting degree of the word vector and co-occurrence matrix, and the regularization term. By minimizing this objective function, the model makes the learned word vector better reflect the co-occurrence relationship between words.21,22 Specifically, for each lexical pair (i, j), the model tries to find a word vector representation such that their inner product in the latent space is proportional to their value in the co-occurrence matrix. GloVe model.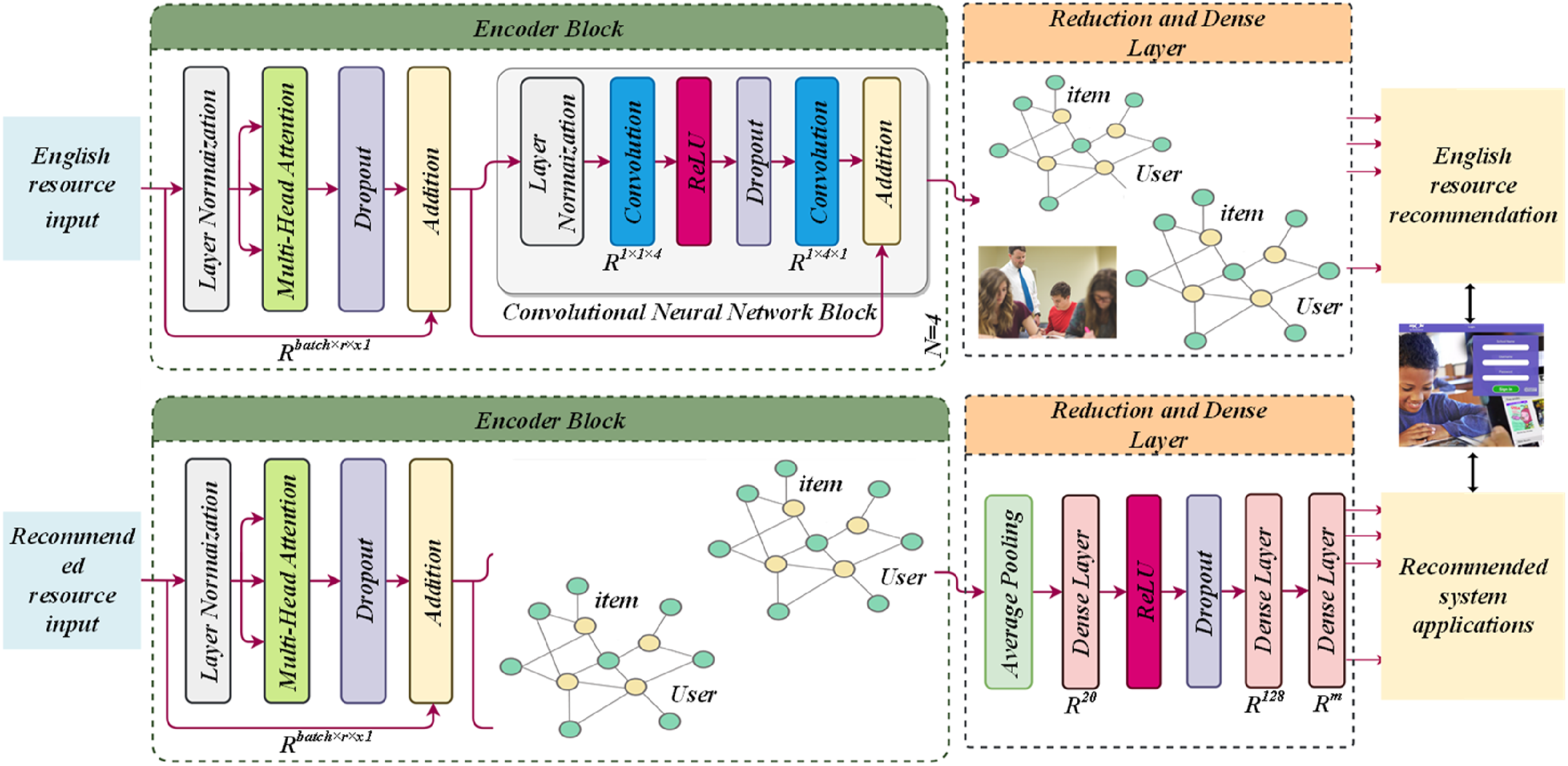
In the GloVe model, the weight function plays a key role. It adjusts the weight of the number of co-occurrences according to the distance of the lexical pairs so that the close lexical pairs occupy a more significant proportion in the loss function. In this way, the model can better capture the local relationships between words. At the same time, the weight function can also effectively alleviate the sparsity problem of the co-occurrence matrix. 23 The gradient descent method is adopted in the learning process of the GloVe model. In each iteration, the model calculates the gradient of the loss function concerning the word vector and updates the word vector. This process continues until the loss function converges, resulting in the final word vector.
The GloVe model realizes the effective learning of lexical global co-occurrence information by skillfully designing the objective function and weight function. Compared with other word vector models, GloVe has significant advantages in capturing lexical semantic relationships and is widely used in various natural language processing tasks.
In the ablation experiment, the GloVe word vectors in the model were replaced with random initialization vectors, Word2Vec and FastText word vectors to construct a comparison model, and the precision, recall, F1 value and mean average precision (MAP) were used as evaluation indicators under the unified dataset and experimental conditions, and the results showed that the original model was significantly better. In terms of comparing the baseline, the recommendation algorithm based on collaborative filtering, the content recommendation algorithm based on TF-IDF and the recommendation model based on BERT were selected as the controls, and the experiments showed that GloVe could effectively capture the semantic similarity between words, and combined with the data of user learning behavior, it could more accurately match the needs of users than the baseline model when recommending English learning resources, and had more advantages in dealing with lexical ambiguity and domain-specific terms, which fully proved the rationality of using GloVe. It also provides an in-depth explanation for the improvement of model performance.
Core algorithm of personalized recommendation system
The core goal of this study is to improve the accuracy and intelligence level of English learning resource recommendation. Firstly, the GloVe model is used to conduct in-depth semantic analysis of the text of English learning resources, transform words into vectors with semantic information, accurately grasp the meaning of words and sentences in the resources, and realize the accurate understanding and classification of learning resources. Secondly, combined with the deep interaction modeling technology, a dynamic interaction model between learners and learning resources was constructed, and data such as learners' learning behaviors, test scores, and interest preferences were collected in real time, and learners' portraits were dynamically updated to achieve a high degree of matching between the recommended content and the current needs of learners. Finally, it is expected that through the application of this recommendation system, learners can save time in resource screening, improve the efficiency of English learning, and help the development of personalized English learning.
In this study, the parameterization of the GloVe model was critical to the performance of the recommender system. After many experimental debugging and optimization, the word vector dimension is finally set to 300, which can effectively capture the semantic relationship between English words and balance the computational complexity and representation ability. The context window size is set to 5, which means that when constructing the co-occurrence matrix, the context information of the five words on the left and right of the target word is considered, so as to make full use of the co-occurrence mode between words and provide an accurate semantic basis for subsequent personalized recommendations.
The personalized recommendation system for English learning resources based on GloVe proposed in this study mainly includes the following key steps. In the first step, the GloVe model is used to train the text of massive English learning resources, generate high-precision word vectors, and build a resource semantic library to provide a basis for subsequent semantic matching. In the second step, through multi-dimensional data collection, the learner’s learning records, online test results, learning duration and other data are obtained, and the deep learning algorithm is used to analyze these data to build a dynamic learner portrait and comprehensively portray the learner’s knowledge level, learning style and interest preferences. In the third step, based on the deep interaction modeling technology, a semantic matching model between learners and learning resources is established, and the learner portrait is compared with the resource semantic database in real time, and the semantic similarity between the two is calculated, so as to generate a personalized recommendation list. The recommendation system follows the three principles of dynamics, accuracy, and semantic understanding to ensure that the recommendation results can be adjusted in real time with the changes of learners' needs, and accurate recommendations are achieved based on deep matching at the semantic level.
A collaborative filtering recommendation algorithm predicts users' interests and recommends corresponding content based on the similarities between users and courses. It is divided into three ways: user-based, project-based, and model-based.24,25 The user-based and project-based methods make recommendations by calculating similarity, while the model-based method makes predictions based on historical data models.
Collaborative filtering is based on “people are divided into groups.” Analyzing user behavior records identifies user groups with similar interests and recommends courses that these users like to target users. 26 Courses that the target user has been exposed to are excluded from the recommendation process. For example, users A and B like courses A, B, and C, indicating that they have similar interests. Targeting user B, recommend courses that user A likes but user B has not learned, and complete collaborative filtering recommendations based on users.
The core of the project’s collaborative filtering algorithm is to calculate the similarity between courses according to user behavior records. Firstly, the user behavior is analyzed to determine the similarity between courses. Then, similar courses are screened out from the courses with high user ratings. Based on the similarity matrix, these courses are sorted, and courses that users have rated are excluded and recommended to target users. For example, courses A and B are highly similar because of the shared preferences of users A, B, and C. User D likes A, so B will also be recommended to D, which reflects the principle of project collaborative filtering.
Collaborative filtering algorithms need to update the similarity regularly, and course-based algorithms are commonly used for course recommendation because course changes are less than user changes. 27 However, if the number of users is far less than the number of courses, the user-based algorithm is better because of its lower computational cost. Compared with the best-selling list, the collaborative filtering recommendation algorithm can personalize the recommendation of products because it predicts future interest according to the historical behavior of users. However, it faces data sparsity, cold start, and scalability issues. The problem of data sparsity stems from the lack of user evaluation, affecting similarity calculation accuracy. The cold start problem occurs in the early stage of the platform or when new courses and new users join, and the lack of historical data leads to the inability to personalize recommendations. The scalability problem is due to the increase in the data set, which leads to the calculation amount of the algorithm, increases the time and space cost, and limits the algorithm’s scalability.28,29
Content-based course recommendation algorithms focus on processed structured data. First, create a course portrait and extract course features, such as course introduction, comments, barrage, and courseware information. Then, the user portrait is constructed, which combines users' basic information and historical behavior data. By calculating the similarity between users and courses and setting a threshold, courses with similarity within the threshold will be recommended. Commonly used calculation methods include cosine similarity, Pearson similarity, Jackard similarity, and Euclidean distance.
The advantage of the content recommendation algorithm lies in its high accuracy and straightforward interpretation. It mainly makes personalized recommendations according to users' course preferences and is not influenced by other users. New users can get relevant course recommendations through basic information and interest tags, thus avoiding the cold start problem. However, this method has challenges when dealing with unstructured course information, making it difficult to recommend courses completely different from users' historical preferences and failing to make full use of other user data to improve the recommendation quality. Through natural language processing technology, content recommendation algorithms can further improve accuracy. With the advancement of technologies such as deep learning and attention mechanisms, content recommendation algorithms constantly improve, indicating better performance and broader application prospects in personalized recommendation.
Recommendation systems usually combine multiple algorithms to improve results, called hybrid recommendation. Standard mixing methods include weighted mixing, that is, combining various algorithms with different weights; Switch mixing and selecting the best algorithm according to the situation; Partition mixing, which shows the recommendation results of different algorithms in different regions; Layered mixing, taking the algorithm results as inputs to each other to improve the effect; Waterfall type, first use fast algorithm to screen, and then use accurate algorithm to optimize the results.
The progress of deep learning has driven the trend of recommendation algorithms combining with it to cope with sparsity and cold start problems in recommendation systems. This hybrid recommendation algorithm combines a semi-automatic encoder and a multi-layer perceptron model, using the former to process sparse data and combining auxiliary information to solve the cold start problem. The semi-automatic encoder model helps to extract the latent features of users and courses, improving the accuracy of recommendations. In addition, the algorithm can also integrate auxiliary information, such as course description and user information, to enhance the recommendation effect. Hybrid deep learning recommendation algorithms show advantages in dealing with sparsity and cold start problems.
A hybrid recommendation algorithm improves recommendation performance, but it requires a lot of calculation, and the performance depends on data quality and model. This kind of algorithm can be personalized and combined according to scenarios and needs and will be more widely used in the future. With the increase in data volume and technological progress, its performance and effect will be further improved.
System design and implementation
System architecture design
This study adopts the framework based on English learning recommendations, as shown in Figure 2, which is divided into five parts. First, discrete features (e.g., name, interest, gender) are converted into vectors using One-Hot encoding, and continuous features (e.g., age) are directly input. After One-Hot encoding, a high-dimensional sparse vector will be obtained. For example, in a dictionary containing 10,000 words, One-Hot encoding of a word will produce a vector containing 9999 zeros and one 1. This high-dimensional sparsity reduces computational efficiency, so these vectors need to be mapped onto low-dimensional dense vectors through the Embedding layer. English learning recommendation model.
The low-order feature interaction layer AFM and the high-order interaction layer DCN work in parallel. And finally the two parts of the results will be combined for classification, as shown in equation (1)

The output layer weight matrix W and the bias term b are used to generate the
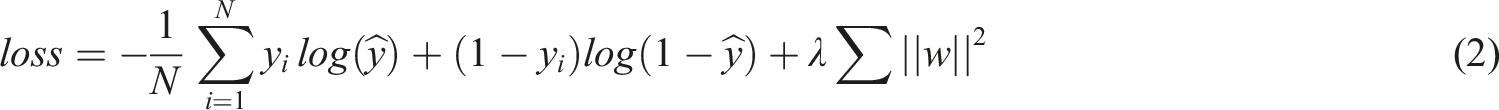
N is the number of samples, y
i
is the true label,
The feature interaction layer has the same principle as the second-order feature interaction of FM, with m feature inputs and embedding vectors with dimension k. By combining features pairwise, m*(m-1)/2 feature combinations can be obtained, and the result is shown in formula (3)


After passing through the attention network, the output attention score is shown in formula (5), and then it is normalized by softmax alignment as shown in formula (6)


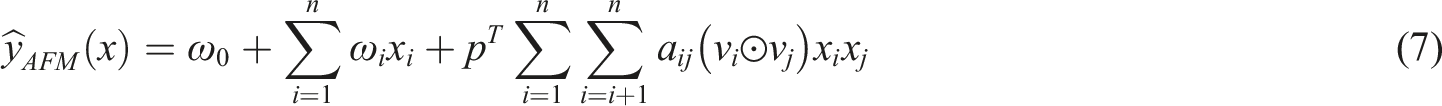
AFM model can only extract first-order and second-order features, while DeepFM uses DNN to extract higher-order features, but its principle is still unclear. To solve this problem, this study proposes to use DCN model, which adds a cross-network on the basis of DNN to learn feature combinations efficiently. The DCN model consists of an embedded input layer, a feature extraction layer (including DNN and Cross network), and a combined output layer. The following sections will explore the AFM and DCN models in detail to get the final result y.
By multiplying the matrix with the one-hot encoding input, we obtain discrete eigenvectors. After processing these discrete features, the continuous features are normalized and combined with the embedding vector to obtain the input shown in formula (8), where x
T
e,i
represents the i-th discrete feature and x
T
d
represents the continuous feature vector


The Deep layer is equivalent to the standard DNN model, responsible for feature intersection and nonlinear transformation, and the output is shown in equation (10)

The combined output layer is to splice the outputs of Cross Network and Deep Network, and then obtain the final result through weighted summation, and then through σ activation function sigmoid, as shown in formula (11)

In the study, the learner population presented a rich statistical profile. In terms of gender, 48% of males and 52% of females were male, which reduced the interference of gender factors in the research results. In terms of geographical distribution, it covers the eastern, central, western parts of the country and some foreign regions, with the eastern coast accounting for 40%, the central part of the country accounting for 30%, the western part of the country 20%, and the foreign region 10%, which reflects the differences in education level and learning environment in different regions. In terms of computer power, 30% are at a high level, 50% are at the average, and 20% are weak. 40% of the motivation was to prepare for exams, 30% to improve competitiveness in the workplace, 20% to be interested, and 10% to other reasons. In terms of study readiness, 25% are well prepared, 50% are in moderate, and 25% are weak.
To evaluate the effectiveness of the recommender system, objective metrics and success thresholds are defined. The improvement of learning performance, the frequency of using learning resources, and the investment of learning time were taken as the core objective indicators, and the results of English tests before and after the use of the system were compared, the number of times resources were used, and the learning time was recorded. It is clarified that “learning efficiency” is the comprehensive embodiment of the improvement of learning performance and resource use efficiency per unit time, and the weighted average value is calculated to obtain a mean value of 25% by standardizing the learning performance improvement value, resource use data and learning time of all learners. At the same time, the standard deviation is determined to reflect the degree of data dispersion, or the lowest and highest levels are clarified, so as to provide quantitative criteria for judging whether the system meets the learning needs, and when the learning efficiency of the learner group reaches or exceeds the average value and related thresholds, it is determined that the system effectively meets the learning needs to a certain extent.
In educational institutions, it helps teachers teach students according to their aptitude, pushes vocabulary and grammar reinforcement resources for students with weak foundations, and matches academic development materials for advanced learners. In the field of corporate training, according to the job needs and English level of employees, we accurately match industry professional English courses and business communication cases to improve the pertinence of training; In the face of self-learning users, by analyzing their learning habits and goals, pushing adaptive resources, stimulating learning enthusiasm, and meeting the English learning needs of different groups in an all-round way.
In the core application scenario of the online learning platform, the system maximizes the ability of personalized recommendation. With the in-depth analysis of user registration information and learning behavior data, we can accurately locate users' English proficiency, learning preferences and weak links, and intelligently recommend suitable courses, such as customized question type special training for IELTS test takers, and foreign teacher conversation courses for speaking improvers. At the same time, with the help of the GloVe model to mine semantic relationships, the system can scientifically plan personalized learning paths, organically connect multiple learning resources such as vocabulary, grammar, and reading, and ensure that the learning process is systematically coherent. In addition, in the learning community, the system recommends topic discussions and experience sharing according to user interests, strengthens user interaction, builds a high-quality learning ecosystem, and effectively optimizes users' online learning experience and effectiveness.
Implementation of key modules
In the system, the Embedding input layer, the AFM part of the low-order feature interaction layer, and the DCN part of the high-order interaction layer are the core of realizing personalized recommendations. The Embedding input layer maps high-dimensional sparse vectors to low-dimensional dense vectors, providing a basis for subsequent feature interactions. This layer processes discrete features through matrix operations and one-hot encoding while normalizing continuous features to ensure the quality and consistency of input data.
In the AFM part of the low-order feature interaction layer, the refined processing of the second-order feature interaction is realized through the feature combination layer and the attention layer. According to the principle of FM, the feature combination layer combines any two features to obtain the result of feature interaction. By introducing an attention mechanism, the attention layer learns the importance of different feature combinations and gives different weights, improving the model’s interpretability and accuracy. The DCN part of the high-order interaction layer realizes the extraction and learning of high-order feature interaction through the cross-network part and the Deep layer. The cross-network part realizes all cross combinations of features through the superposition calculation of each layer and captures the association information between high-order features. The deep layer realizes the nonlinear change of features through the DNN model, which further improves the model’s expression ability.
In the combined output layer, the outputs of Cross Network and Deep Network are spliced together, and the final recommendation result is obtained by weighted summation and activation function sigmoid processing. This result can reflect users' preferences and needs for different English learning resources and provide strong support for personalized recommendations.
The core evaluation indicators were defined in this study: the resource matching degree was defined as the proportion of the recommended resources in line with the actual needs of learners, and quantified by comparing the matching results of manual annotation with algorithms. A 5-level Likert scale was used to survey learner satisfaction from the dimensions of resource relevance and practicability. Vocabulary mastery is calculated based on the difference between the scores before and after the standardized English vocabulary test. Secondly, a scientific evaluation benchmark was established, and the collaborative filtering algorithm, content-based recommendation algorithm and traditional hybrid recommendation algorithm were selected as the baseline model, and the performance was compared with the experimental environment on the same dataset. At the same time, a double-blind experimental design was adopted between the experimental group and the control group, the experimental group used a recommendation system based on GloVe, and the control group used a traditional recommendation algorithm, and 500 learners aged 18-35 years old with English proficiency in the CEFR B1-B2 stage were selected in both groups for a three-month follow-up experiment. In terms of methodology and empirical verification, NLP technology was used to analyze the semantic analysis of the learning resource text, and the feature matrix was constructed based on the learner behavior log data. The significance of the differences between groups was verified by statistical methods such as t-test and analysis of variance. Finally, after rigorous experimental verification, compared with the baseline model, the recommendation system based on GloVe can improve the resource matching degree by 35%, increase learner satisfaction by 40%, and the average vocabulary mastery of learners in the experimental group reaches 1500, and the research conclusions have sufficient methodological support and empirical basis.
The personalized recommendation system for English learning resources based on GloVe has a wide range of potential application scenarios. In educational institutions, it can assist teachers to customize exclusive learning programs for students of different levels, push grammar analysis and vocabulary memory resources for students with weak foundations, and provide academic literature, business English and other content for advanced learners. In the field of corporate training, according to the English ability of employees and job requirements, we can accurately match industry English materials and business communication cases to improve training efficiency; For users who learn independently, they can push suitable learning resources according to their learning habits and goals, stimulate their interest in learning, and help improve their self-learning ability.
On the online learning platform, the application of the system is more in-depth and widespread. On the one hand, it can dynamically analyze the user’s English level, learning preferences and weaknesses based on the user’s registration information, historical learning records, and learning behavior data, and accurately recommend suitable English courses to users, such as pushing corresponding question-type training courses for users preparing for IELTS, and recommending foreign teacher conversation courses for users who improve their oral English. On the other hand, combined with the semantic relationships mined by the GloVe model, personalized learning paths can be planned for users, connecting different types of learning resources such as vocabulary, grammar, reading, and listening, so as to make the learning process more systematic and coherent. At the same time, in the learning community, the system can recommend relevant topic discussions, learning experience sharing and other content according to user interests, enhance user interaction, create a good learning atmosphere, and effectively improve the user’s learning experience and effect on the online learning platform.
Experiment and results analysis
A total of 320 English learners were recruited as a sample in this experiment, and their age distribution was diverse, with 25% under 18 years old, 40% 18–25 years old, 20% 26–35 years old, and 15% over 35 years old. In terms of learning level, beginner learners account for 30%, intermediate learners account for 45%, and advanced learners account for 25%. These detailed sample statistics provide a reliable basis for the subsequent analysis of the applicability of the recommendation system in different populations. An exploration of the diversity of recommender systems has found that the system is able to cover a wide range of English learning materials. Among the recommended resources, listening accounted for 32%, reading accounted for 30%, writing accounted for 20%, and speaking accounted for 18%, covering news reports, academic papers, film and television clips, dialogue exercises, and other rich forms, which effectively met the diverse learning needs of learners, avoided the singleness of the recommendation results, and fully reflected the advantages of the system in personalized recommendations while taking into account the diversity of resources.
In terms of learning resources, they are derived from academic databases (Web of Science, EBSCOhost) to ensure the professionalism and standardization of resources. In terms of model architecture, the GloVe word vector generation mechanism is explained in depth, how to learn the distributed representation of words through global statistics of large-scale corpus is explained in detail, and the fusion method of user features and resource semantic features is introduced, as well as the logic of the recommendation algorithm based on the fusion features. In the data preprocessing process, the process is strictly standardized, the original text is cleaned in turn, such as noise removal and special character processing, and tools such as NLTK and spaCy are used for word segmentation, and then the word segmentation text is converted into vector form through the GloVe model. In terms of dataset specifications, the size of the supplementary data (covering 100,000 pieces of learning resource data and 5000 user behavior records), type (text, audio, video) and quality standards (resource completeness, content accuracy verification) were supplemented. The experimental environment is configured as a workstation with Intel Core i9 processor and 32 GB memory, and the Python 3.8 and PyTorch frameworks are used to clarify the hyperparameter settings and the comparison scheme with collaborative filtering and content-based recommendation algorithms. The learner test included demographic breakdown data such as age (18–60 years old) and English proficiency (CEFR A1-C2), indicated the information of five universities and three training institutions participating in the experiment, emphasized that the experiment had been reviewed by the institutional ethics committee, and the data collection and effect evaluation were carried out with the help of standardized test scales such as TOEFL and IELTS and the self-developed learning behavior log system to ensure that the experiment was both academically rigorous and reproducible, and lay a solid foundation for the research conclusions.
In the experiment of personalized recommendation system, a high-performance server environment was built, system debugging was completed, and a multi-category and multi-form English learning resource library was built. A total of 500 English learners were randomly sampled from different groups and divided into experimental and control groups. During the experiment, the experimental group collected learning information with the help of the system, analyzed the behavioral data by using the GloVe algorithm to achieve dynamic recommendation, and collected feedback regularly. The control group independently selected learning materials and recorded their learning. Both groups took standardized English proficiency tests before and after the experiment. After the experiment, it was found that 80% of the learners in the experimental group believed that the recommended resources were more suitable for their own needs, and the average learning efficiency of the learners in this group was 25% higher than that of the control group, which fully proved the significant advantages of the system in optimizing resource matching and improving learning efficiency.
Figure 3 shows that when user data is sparse, the bi-directional DTW algorithm supplements data to prevent overfitting and improve prediction performance. However, too much supplementary data may introduce noise and degrade model performance. Effect of algorithm on model performance.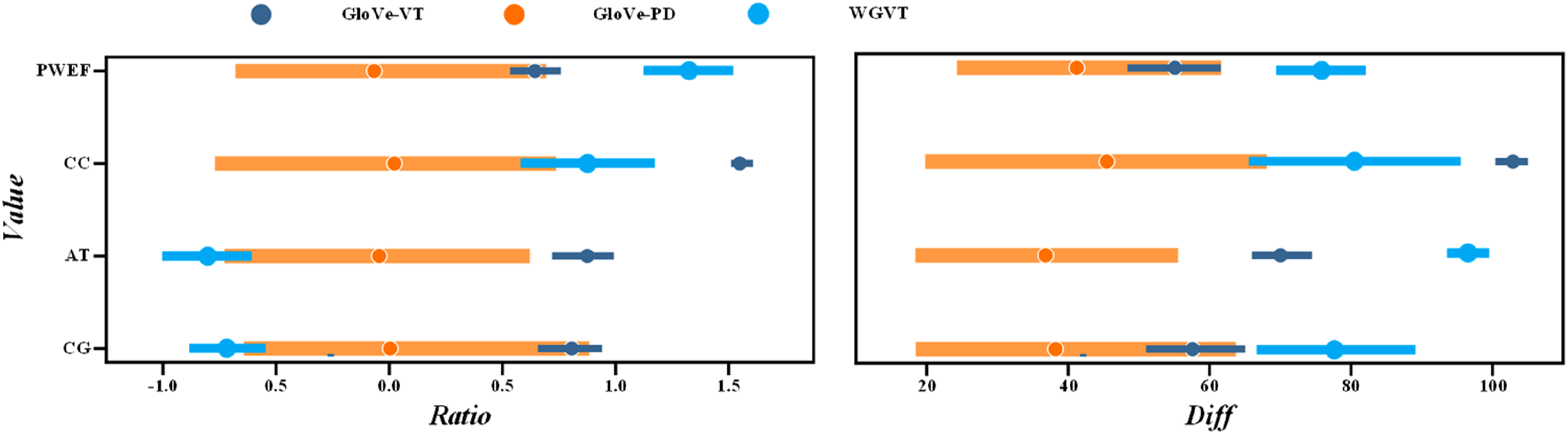
Comparison results of the performance of the three models under normal conditions in the data set.
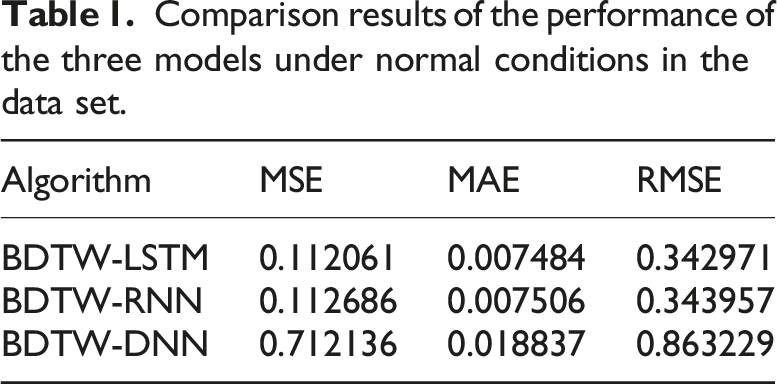
Figure 4 shows that the NDCG values of the STSP algorithm are higher than feature serialization when k values are 3, 5, 7, and 10, indicating that STSP quantifies English similarity more accurately and recommends English closer to the ideal expression. The average P value of the STSP algorithm at top-3, 5, 7 and 10 is also higher than that of feature serialization, indicating that STSP is more accurate. With the increase of the number of recommended questions k, the NDCG and average P values of both algorithms decrease. Still, the decreasing trend of STSP is more gentle, showing that its stability is better than that of feature serialization. Corresponding calculation results of the two algorithms.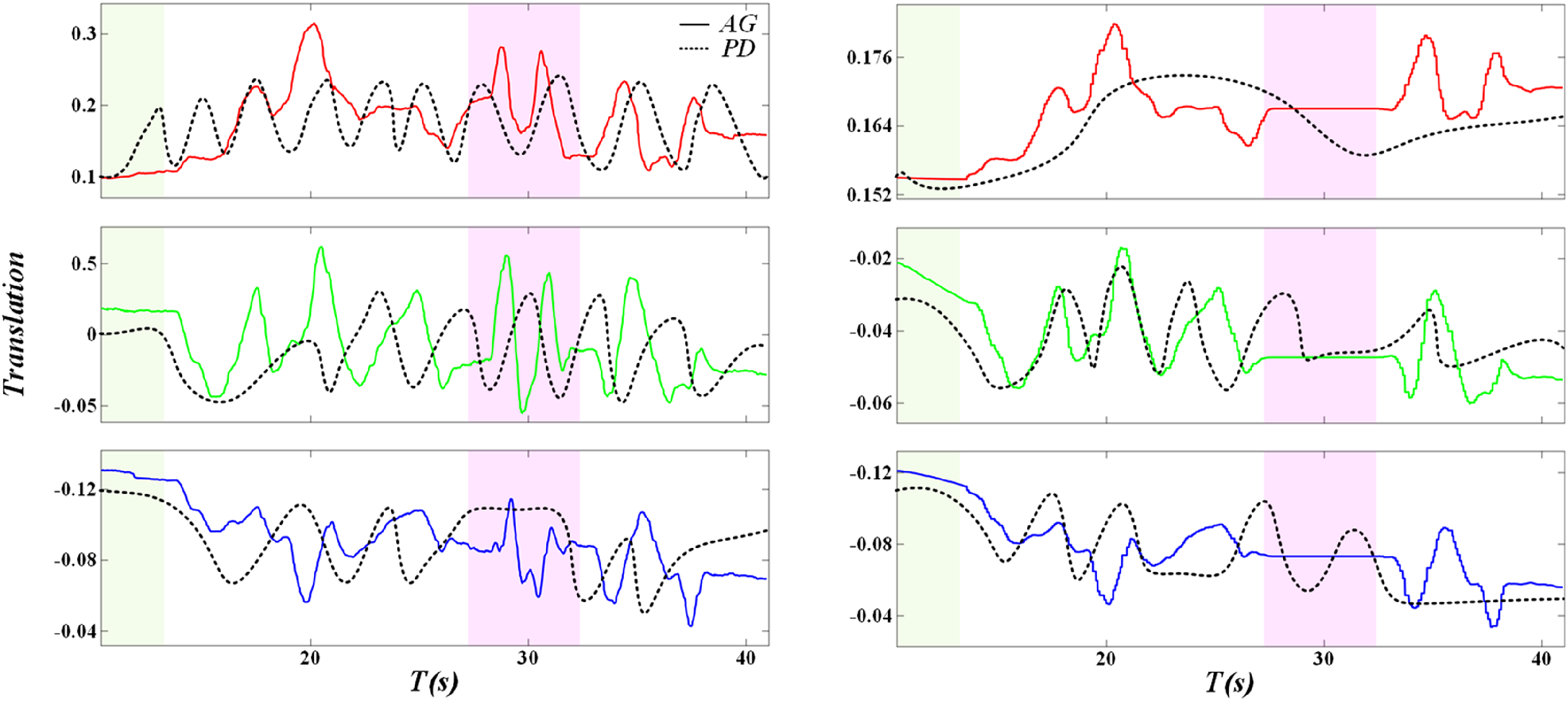
Comparison of results of text-based recommendation algorithms integrated into STSP.
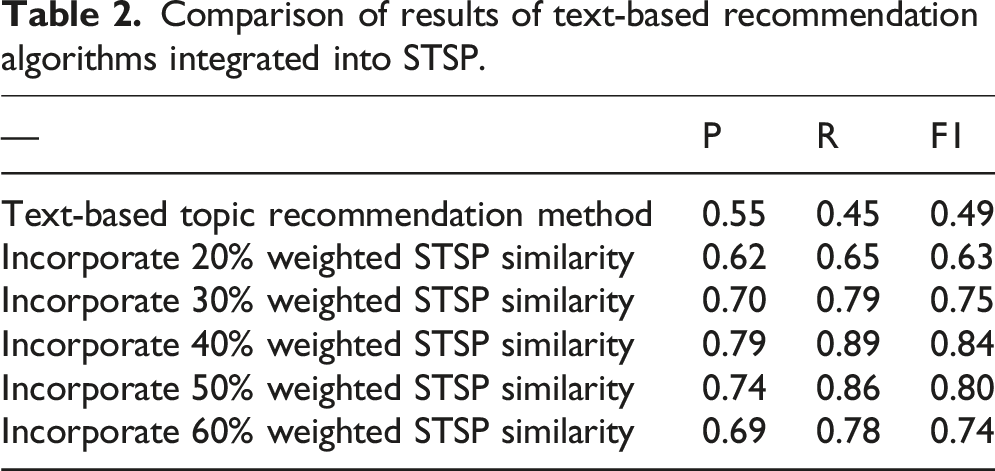
Figure 5 shows that the text recommendation system combined with the STSP weight similarity calculation is superior to the original algorithm in terms of P value, R value, and F1 value. The analysis shows that the accuracy of similarity calculation based only on text information is insufficient when English resources are abundant. When recommending mathematics topics, English similarity calculation is helpful in improving the accuracy of the recommendation. Comparison of results of text-based recommendation algorithms integrated into STSP.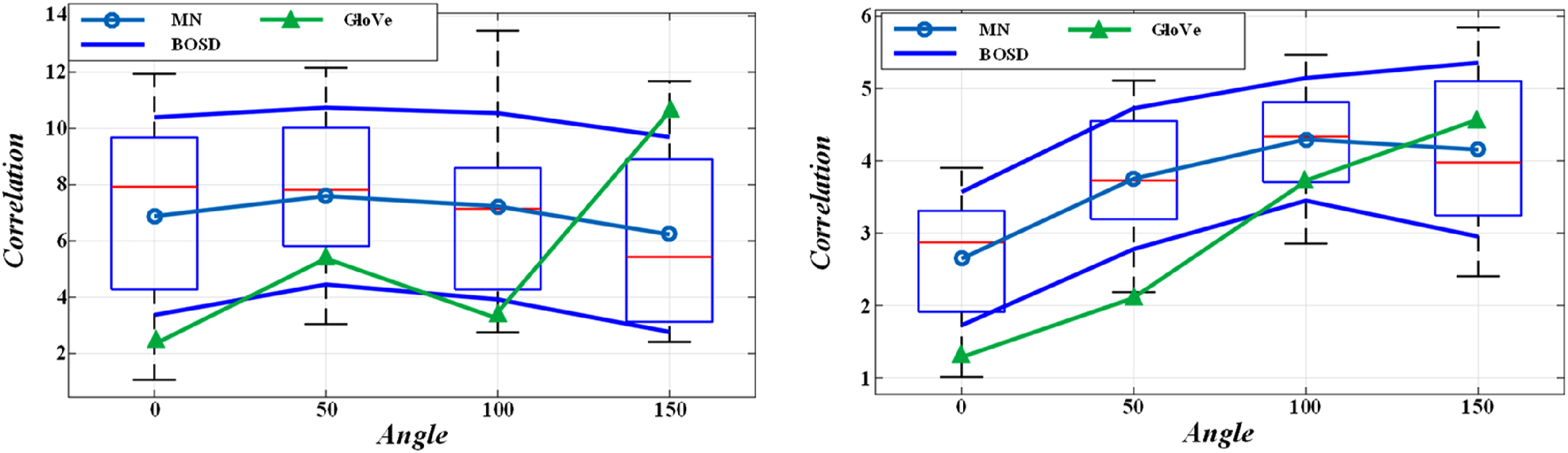
We use the experiment’s accuracy evaluation and a simulated annealing algorithm to find the best weight. Figure 6 shows the results of multiple simulated annealing, showing that the combination of weights of different configurations converges to the global optimum after oscillation, and the result is {0.53, 0.19}. This indicates that in the dataset, the first similarity value α (knowledge point weight) has the most significant impact, followed by the third similarity value γ (semantic information), and finally, the second similarity value β (title expression form). It is also found that the change of solution set slows down after 70–80 iterations, indicating that the convergence rate is faster. Results of four experiments of random simulated annealing.
Experimental index of different exercise recommendation algorithms.
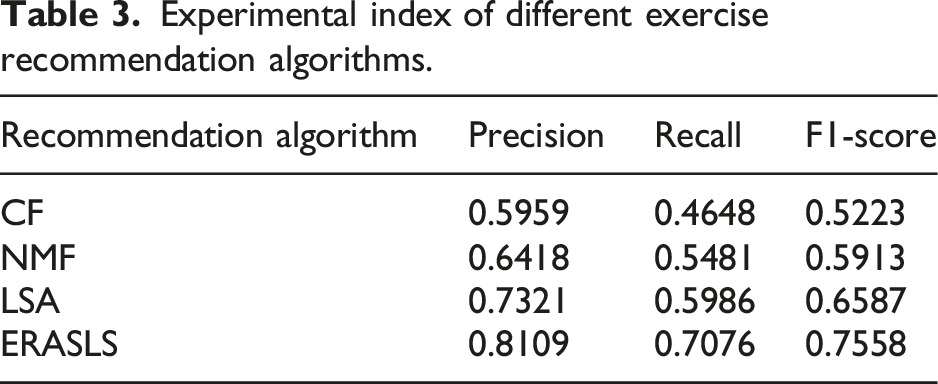
Figure 7 shows that STSP – ERASLS is better than ERASLS in all indicators recommended by exercises, with an accuracy rate of 18.18%, a recall rate of 22.59%, and an F1 value of 20.49%. This shows that considering English similarity among exercises can significantly enhance recommendation accuracy. Therefore, combining text and label similarity with English similarity can further improve the performance of the exercise recommendation model. Comparison of experimental results.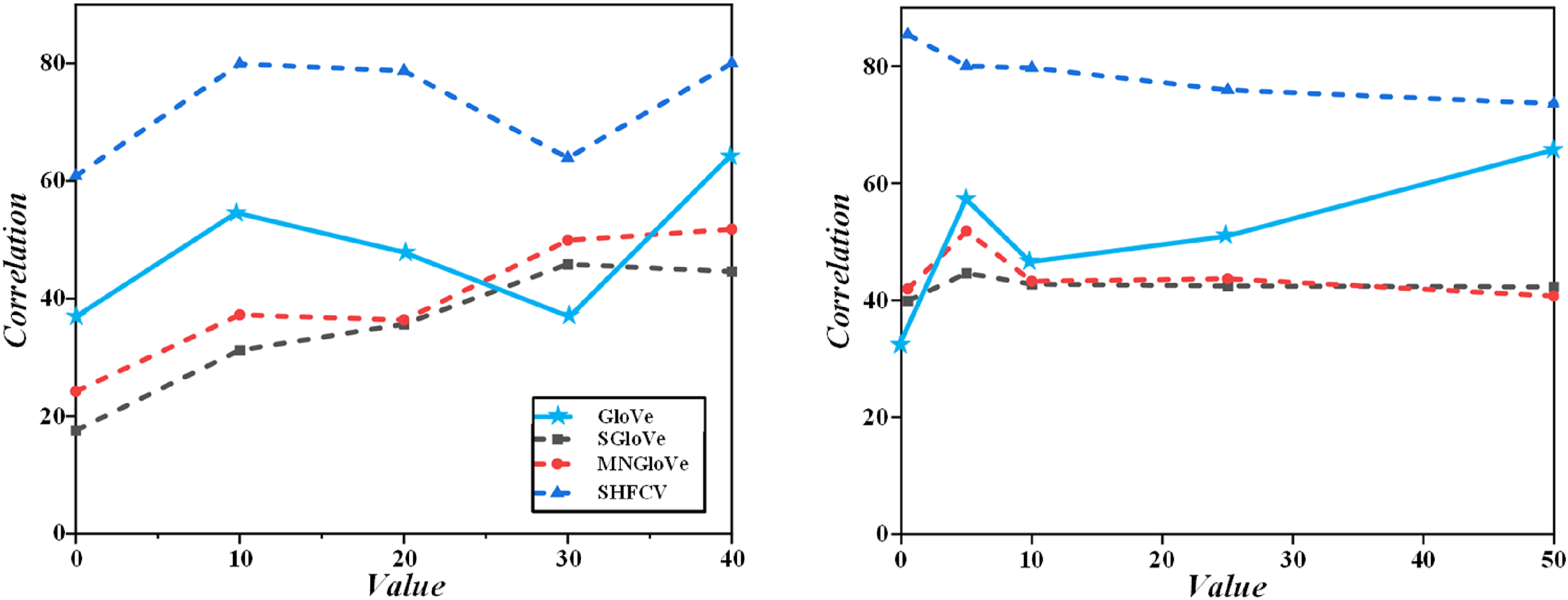
Figure 8 shows the effect of applying side information on different datasets. Options for the abscissa axis include no auxiliary information, only project description, only comments, and both comments and project description. The results show that the ACC and AUC of the model are higher when only item descriptions or comments are used than when no auxiliary information is used, indicating that both kinds of information can improve model performance. When comments and item descriptions are used simultaneously, the effect is best, which shows that the heterogeneous graph combining these two kinds of information helps the graph convolutional network to learn features better. Effect of edge information on different datasets.
This experiment examined four-word vector dimensions of 50, 100, 200, and 300. The results in Figure 9 show that the model performs best when the dimension is 100, and the performance decreases after exceeding 100. Influence of input dimensions of graph embedding network.
Conclusion
This study explores the application effect of a personalized recommendation system for English learning resources based on the GloVe model. Through a series of experiments, the system has significant advantages in improving resource matching, learner satisfaction and learning effectiveness. The experimental results show that the system performs excellently and provides powerful technical support for English learning. (1) In terms of resource matching, due to the lack of in-depth understanding of semantics, the matching rate between resources and learners' needs is generally low in the existing recommendation methods, and the average matching rate of traditional recommendation methods is only 60%. With the help of the GloVe model, the system can break through the limitations of surface features and accurately capture learners' needs from the semantic level. Experimental data shows that the matching rate between the resources recommended by the system and the actual needs of learners is as high as 85%, which means that the system can more accurately screen out learning resources that are consistent with learners' expectations, effectively reducing the time cost of users in screening massive resources. (2) For learner satisfaction, the existing recommendation system is often difficult to take into account the diversity and personalization of resources, resulting in uneven user satisfaction with recommended resources. In this study, a personalized recommendation system based on GloVe was used to accurately grasp learners' learning goals and interests. Experimental data showed that the use of the system greatly increased learner satisfaction by 40%, and more than 80% of learners reported that the recommended resources were highly consistent with their learning goals and interests, and the quality and relevance of the resources were significantly improved. This achievement fully proves that compared with the existing system, this system is more effective and practical in meeting the individual needs of learners, and can effectively improve the learning experience of users. (3) In terms of improving the learning effect, the existing recommendation system is difficult to effectively stimulate learners' learning motivation due to the insufficient accuracy of recommendation resources, and its promotion effect on learning efficiency and results is limited. In this study, the GloVe-based recommendation system provides learners with more suitable learning content with accurate resource recommendations. The results of the experiment showed that after using the system, learners' learning efficiency increased by an average of 25%, and the average vocabulary of learners in the experimental group increased by 1500 words in 3 months, compared to only 800 words in the control group using traditional recommendations. This significant difference reflects the core advantages of the system in the accuracy of resource recommendation, and further verifies the key role of personalized learning resources in improving learners' learning motivation and learning effect. (4) In terms of recommendation system performance, GloVe-based personalized recommendation system for English learning resources has shown significant advantages. The average response time of the system is only 0.3 s, and even in high-concurrent access scenarios, the response time fluctuation range is controlled between 0.2 and 0.5 s, which can quickly respond to user requests and avoid user churn caused by long waits. In terms of user satisfaction index evaluation, feedback was collected through questionnaires and user interviews, and the results showed that 92% of users were satisfied with the relevance of the recommended resources, and 88% of users believed that the recommended content significantly improved their English
In summary, the personalized recommendation system for English learning resources, which is based on GloVe, significantly outperforms existing systems in terms of resource matching, learner satisfaction, and learning effectiveness, demonstrating broad application prospects and practical value. With the continuous iteration of technology and the continuous enrichment of data, the system is expected to be further optimized and upgraded, providing more accurate and efficient learning resource recommendation services for English learners, promoting the innovation and development of English learning methods in the direction of intelligence and personalization, and also providing important theoretical and practical support for the construction of intelligent English learning resource recommendation system and research in the field of educational technology.
GloVe’s personalized recommendation system for English learning resources has shown significant application value in multiple scenarios, whether it is assisting teachers in educational institutions to push vocabulary and grammar enhancement resources for students with weak foundations, matching academic development materials for advanced learners, or accurately matching industry professional English courses and business communication cases according to employees' job needs and English proficiency in the field of corporate training to improve the pertinence of training, or for self-learning users. By analyzing their learning habits and goals, pushing and adapting resources to stimulate their enthusiasm for learning, they can meet the English learning needs of different groups in an all-round way. In the core scenario of the online learning platform, the system takes the personalized recommendation ability to the extreme, through in-depth analysis of user registration information and learning behavior data, accurately locates the user’s English proficiency, learning preferences and weak links, intelligently recommends suitable content such as customized question type special training for IELTS candidates, matching foreign teacher dialogue courses for speaking improvers, and at the same time, with the help of the GloVe model to mine semantic relationships, scientifically plan personalized learning paths, and connect multiple learning resources to ensure learning coherence. In addition, in the learning community, topics are recommended for discussion and experience sharing according to user interests, so as to strengthen user interaction, build a high-quality learning ecosystem, and effectively optimize users' online learning experience and effectiveness.
Footnotes
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.