
Abstract
Logistic and probit
Keywords
1 Introduction
Robit regression models are similar to probit models, but the underlying normal distribution in the latter is replaced by a central Student’s t distribution with a zero median and ν degrees of freedom (d.f.). More formally, they can be defined as generalized linear models (GLMs) with a binomial family (usually Bernoulli) variance function and a robit link function with ν d.f.
The Student’s t distribution resembles a normal distribution in that it is symmetrical and bell shaped, but it has heavier tails. Thus, it has been advocated as an alternative to the normal distribution in defining regression models for continuous outcomes, without giving too much influence to outlying values. For example, this was done by Zellner (1976) and by Lange, Little, and Taylor (1989). These ideas were extended to regression models with binary outcomes (see, for example, Liu [2004]).
Compared with the better-known probit and logit link functions, the robit link gives less influence to observations that are highly unlikely given the values of the predictors. This property is discussed in Mudholkar and George (1978), Albert and Chib (1993), Liu (2004), and Kang and Schafer (2007) and is thought to make the robit link particularly suited for use in estimating probability weights.
Seaman and White (2013) recommended the use of robit models for computing inverse-probability weights to handle missing-at-random values, and they included this method in a list of useful techniques that are “not routinely available in most statistical software.” In the case of robit regression and Stata, this is no longer true. Here we present a command,
2 Methods and formulas
Robit models are a special class of GLMs. GLMs were introduced by McCullagh and Nelder (1989) and are implemented in Stata using the
In general, a link function η(µ) is an invertible monotonic transformation of the conditional mean µ, equal to a conditional probability in the case of a Bernoulli model. For instance, the logit link is defined as

and the probit link is defined as

where Φ(·) is the cumulative standard normal distribution function and Φ − 1(·) is its inverse. And both of these link functions have twice-differentiable inverses. To fit a GLM with a specified link function, we need to be able to generate variables containing the link function η(µ) from the conditional mean µ, the inverse link function µ(η) from the link function, and also the first two derivatives of µ with respect to η.
A robit link function (also known as a t-link function) with ν d.f. is defined by substituting an inverse cumulative t distribution function for the inverse cumulative standard normal distribution function in the probit link function, as

where Ft
(
ν
)(·) is the cumulative Student’s t distribution function with ν d.f. and
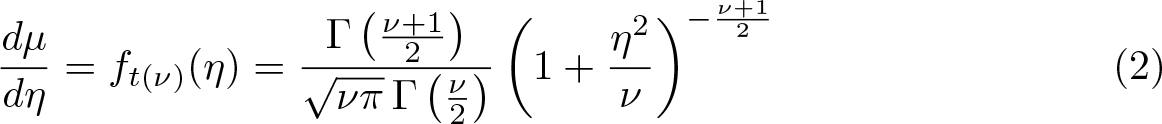
where ft ( ν )(·) is the density function for the t distribution with ν d.f. Therefore, differentiating (2) with respect to η, defining u = 1 + η 2/ν, and using the chain rule, we have the second derivative of µ with respect to η as
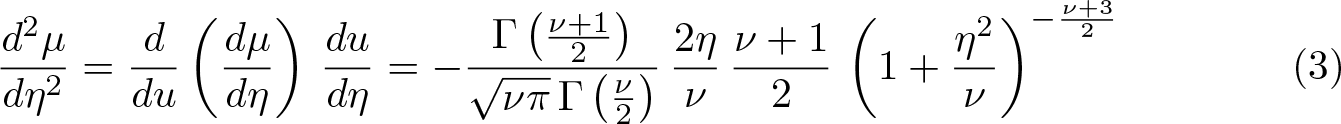
The formulas (1), (2), and (3) define the variables that we need to generate for
Figure 1 shows the inverse robit link functions (also known as t distribution functions) with d.f. 1, 4, and 10, together with the inverse probit link function (also known as the normal distribution function or as a t distribution function with infinite d.f.). Note that the fewer d.f. there are, the further µ(η) is from 0 (in the case of negative η) or from 1 (in the case of positive η).
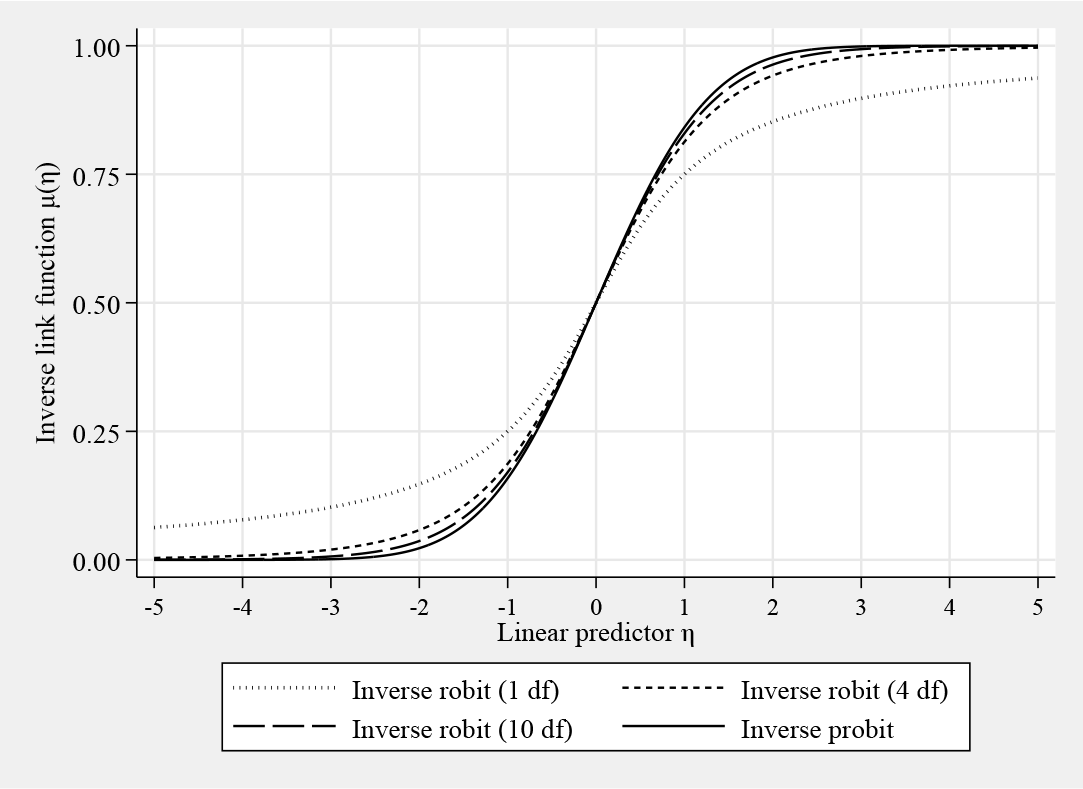
Inverse robit and probit link functions µ(η)
The choice of d.f. for robit models still seems to be an open question. Kang and Schafer (2007) recommended 4 d.f., and, commenting on this article, Ridgeway and McCaffrey (2007) discuss and demonstrate the possibility of 1 d.f. Liu (2004) described 7 d.f. as being an excellent approximation to the logit link function but less influenced by model outliers. Albert and Chib (1993) discussed the case of 8 d.f. Robit with 9 d.f. was mentioned by Mudholkar and George (1978) as having a similar kurtosis to the logit link function. In general, robit link functions with fewer d.f. are influenced less by outliers than those with more d.f. In the limit, as ν tends to infinity, the robit model with ν d.f. becomes the probit model. The d.f. of a robit model can be either prespecified by the user (for computational simplicity, as implemented in our
Note that the t distributions used by our packages are all standard t distributions, specified uniquely by their d.f. Chapter 15 of Gelman, Hill, and Vehtari (2021) discusses the possibility of defining robit link functions using generalized t distributions (with added scale parameters) to modify the units in which the parameters are expressed. Generalizations of the t distribution are reviewed, for example, in Li and Nadarajah (2020).
3 The robit command
3.1 Syntax
depvar is a dependent variable that must be binary.
3.2 Description
3.3 Options
3.4 Remarks
3.5 Stored results

4 Examples
4.1 Creating an outlier in a simulated dataset
We illustrate the use of our

(See Buis [2007] for more about simulating binary and other discrete models.) In the second scenario (the outlier scenario), we introduced an outlier by switching the outcome of an extreme
Of the 200 subjects, 52 had the disease in the base scenario, increasing to 53 in the outlier scenario (because the outcome of one observation was switched from 0 to 1). We fit 3 binary regression models: a logit model for the base scenario, regressing a logit model for the outlier scenario, regressing a robit model with 4 d.f. for the outlier scenario, regressing
We used Huber (or “robust”) variances for consistency throughout because not all the models were correctly specified, although we knew that the first one was, having carried out the simulation under it. For each of the three models, we estimated the probability of having the disease as a function of
The logit model for the base scenario gave the following results:
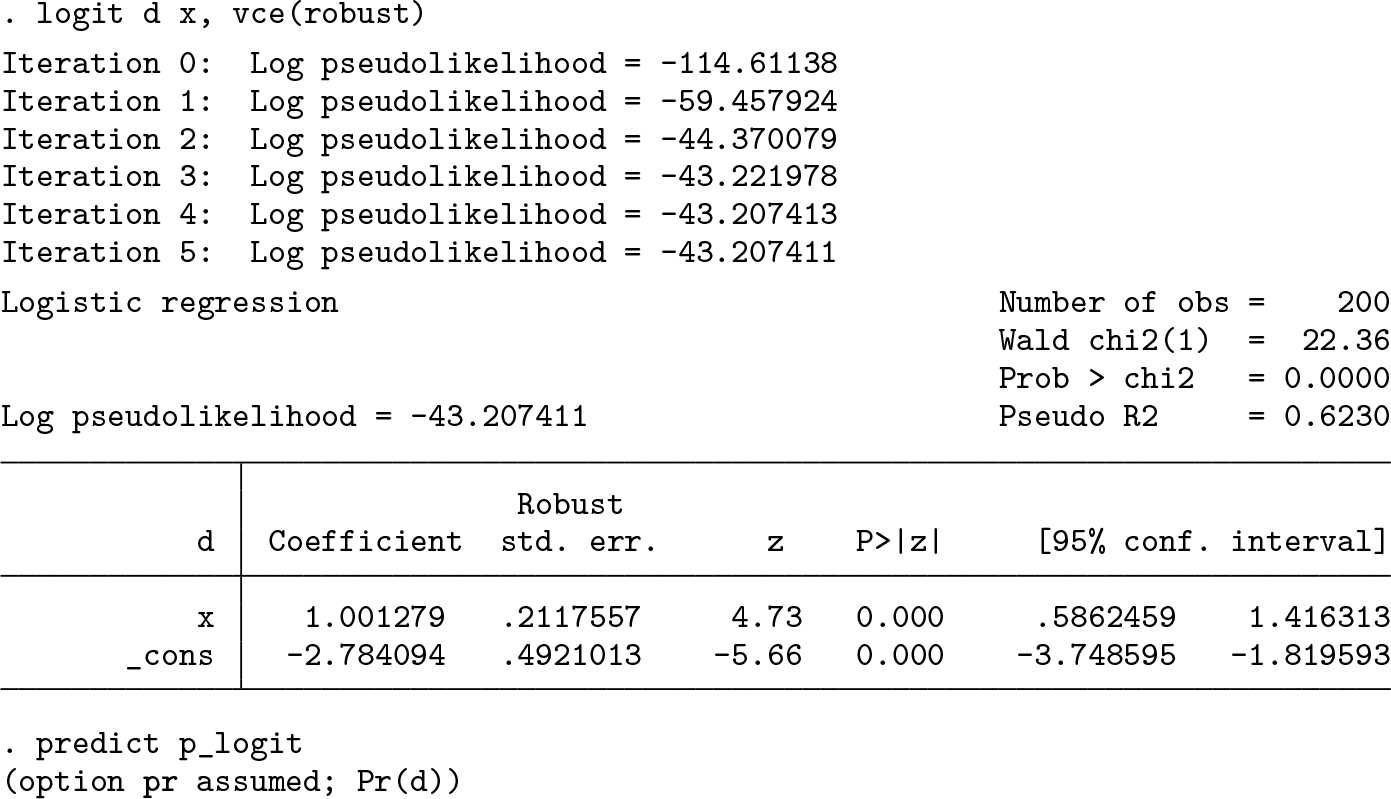
We see that the estimated log odds-ratio is 1.001 per unit of
The logit regression in the outlier scenario produced the following output:

This time, the log odds-ratio per
The robit model under the outlier scenario produced output as follows:

This time, the regression coefficient of

Predicted disease probabilities from the three models plotted against
4.2 Creating an outlier in propensity-score analysis
In the real world, robits are sometimes recommended for generating treatment-propensity scores (Ridgeway and McCaffrey 2007) or completeness-propensity scores (Seaman and White 2013). In both settings, the aim is to prevent outlying propensity weights. These may be encountered in a treatment-propensity setting if a treated subject has a very high predicted probability of being untreated, or vice versa, or in a completenesspropensity setting if a subject with complete data has a very high predicted probability of having missing values. Hereafter, we will describe an example of how robit regression can be used in the context of Rubin’s causal model.
The Rubin method of confounder adjustment, in its 21st-century version described by Rubin (2008), is a two-phase method for estimating the causal effect of a proposed intervention, using observational data. In phase 1 (“design”), we fit a regression model to the sample data, predicting the exposure (that we propose to intervene to change) from confounders (expected to be unaffected). This model is used to define a propensity score, predicting exposure probability as a function of the confounders. In phase 2 (“analysis”), we add in the outcome data and use the propensity score in a second regression model to estimate a propensity-adjusted exposure effect on the outcome. This adjusted effect is interpreted as a difference between mean outcomes in two scenario populations with the same propensity distribution but different exposure levels. This is frequently done using inverse-propensity weighting.
As an example, we use the dataset of Cattaneo (2010) (see [TE]

We will concentrate on the binary maternal smoking status (
In the Rubin causal model, we are allowed to find a propensity model by trial and error in the exposure and confounder data, as long as we apply it to the outcome data afterward and write it up for publication unconditionally on whether it gives the answer we wanted to hear. We want the propensity model to predict the exposure and, at the same time, to generate propensity weights that remove (or at least reduce) any imbalance in confounder values between the two exposure groups (self-reported smoking and nonsmoking mothers). We would also like this to be done in a way that does not lose too much power to detect a contrast in outcome between the exposure groups. And it is also important to define the kind of contrast that we aim to measure between the two exposure groups.
We will summarize our trial-and-error process by running the Rubin causal sequence for four candidate designs, based on the covariates of Original dataset (without outliers), logit model. Original dataset, robit model with 2 d.f. Outlier dataset (with one observation altered to produce an outlier), logit model. Outlier dataset, robit model with 2 d.f.
(The 2 d.f. robit was itself chosen by trial and error, which we are allowed to do in the context of a Rubin causal design phase.) We will start by demonstrating the Rubin causal design phase in detail with the first design (original dataset, logit model) and then proceed to presenting the other designs in less detail. The methods used will be similar to those presented in Newson (2016).
We start by fitting the logit propensity model in the original dataset as follows:

We then compute the propensity score, which for each subject is equal to the estimated probability of smoking for that subject:
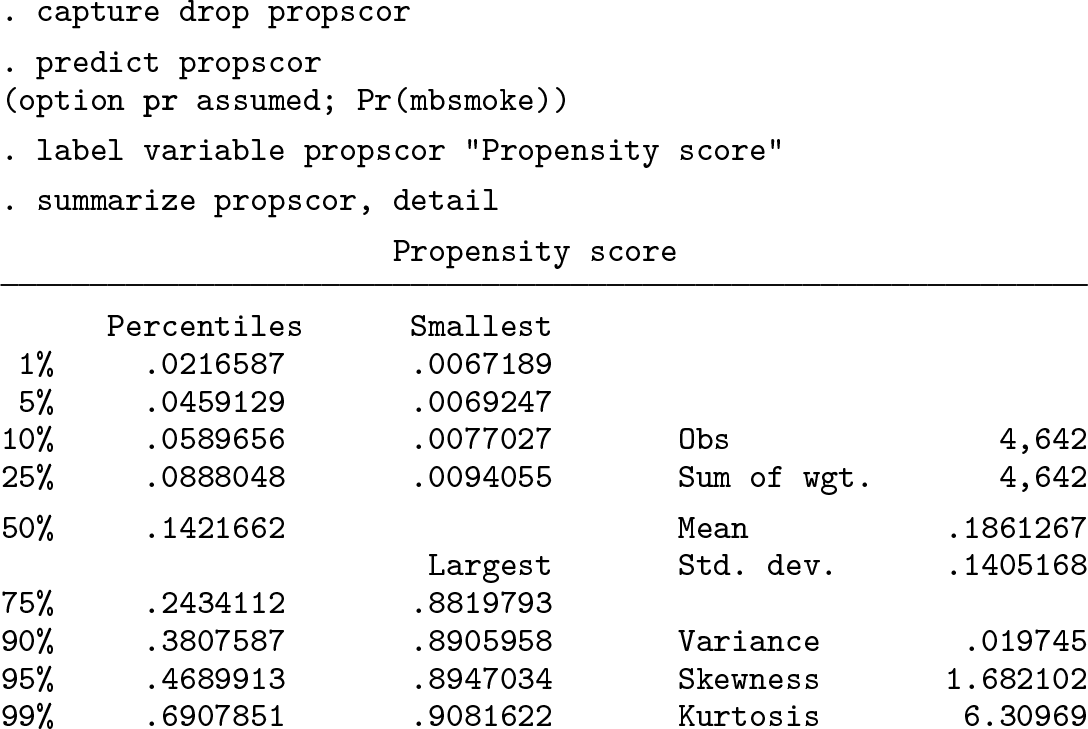
We see that subjects in the dataset have fitted probabilities of smoking ranging from 0.0067 to 0.9082. We would like to estimate average treatment effect (ATE) weights, sometimes known simply as inverse probability of treatment weights. These can be used to estimate the difference in mean birthweight between two fantasy scenarios defined as alternative versions of the dataset: one where all mothers admit to smoking during pregnancy and one where no mothers admit to smoking during pregnancy, both with other covariate values the same as in the original dataset. These weights are computed as follows:

We see that the propensity ATE weights vary from 1.007 to 38.671.
To check whether these weights balance out the association of smoking with the propensity score and its component covariates, we will use Somers’s D statistic for these associations, unweighted and weighted by the propensity ATE weights. Somers’s D is discussed in Newson (2006, 2002b) as an asymmetric measure of association, on a scale from −1 to 1, and related to Harrell’s c-index c(V |X) (also known as the receiver operating characteristic area of V with respect to X) by the formula D(V |X) = 2c(V |X)−1, where X is the binary exposure variable and V can be an outcome variable, a propensity score, or a confounder. In a propensity balance-checking context, it has advantages over the more commonly used standardized exposed-unexposed differences, used by official Stata’s
In our case, we measure the unweighted Somers’s D values of the propensity score and its component covariates with respect to the exposure, using the command

and the corresponding propensity-weighted Somers’s D values using the command

Instead of trying to digest the printed
Has the balancing power been won at the cost of inflating the CIs for the outcome effects? We can answer this question using the SSC package

The two columns of the listed output matrix contain inflation factors for the variances and SEs, respectively. And the two rows correspond to the two parameters estimated, namely, the smoking effect (the ATE) and the intercept estimating mean outcome for babies with nonsmoking mothers. We see that if the confounders predict only smoking and not birthweight, then, for the ATE, variances (and therefore sample numbers required for a specified power) will be inflated by a factor of 1.499, and SEs (and therefore CI widths) will be inflated by a factor of 1.224.
We might decide, in light of this design phase, to proceed to the analysis phase and to measure the effect of smoking on birthweight, adjusted for the confounders. If we do this, then we fit a regression model of the outcome
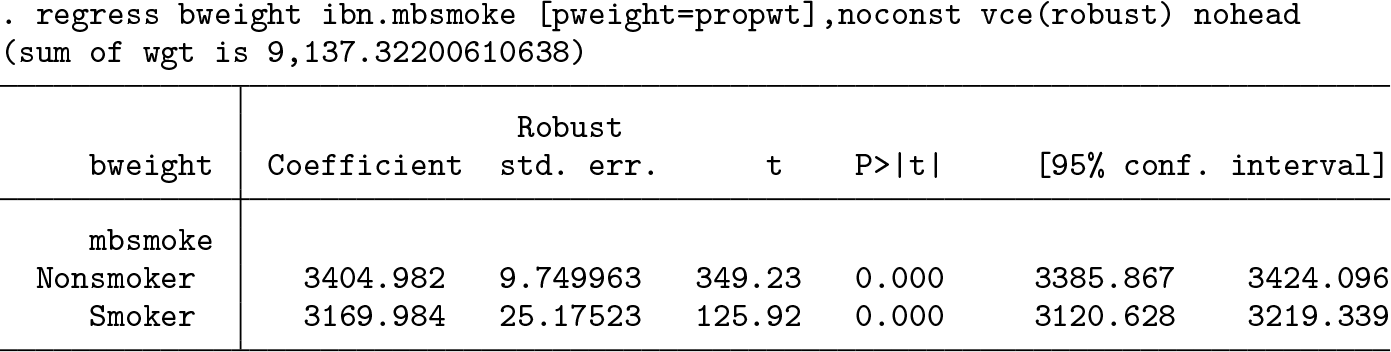
The parameters here are the counterfactual scenario means for the dream scenario (where no mothers smoke) and the nightmare scenario (where all mothers smoke). We see that the mean birthweight is 3404.982 grams in the dream scenario and 3169.984 grams in the nightmare scenario. The nightmare-dream scenario difference is the ATE and can be estimated using the SSC package

We see that the ATE is −234.998 grams (95% CI [−287.926 to −182.071 grams]). Note that the regression model is the same as the one assumed when we used
Alternatively, we might not proceed immediately to the analysis phase but instead try out other designs. For the second design (original data, robit model), instead of using
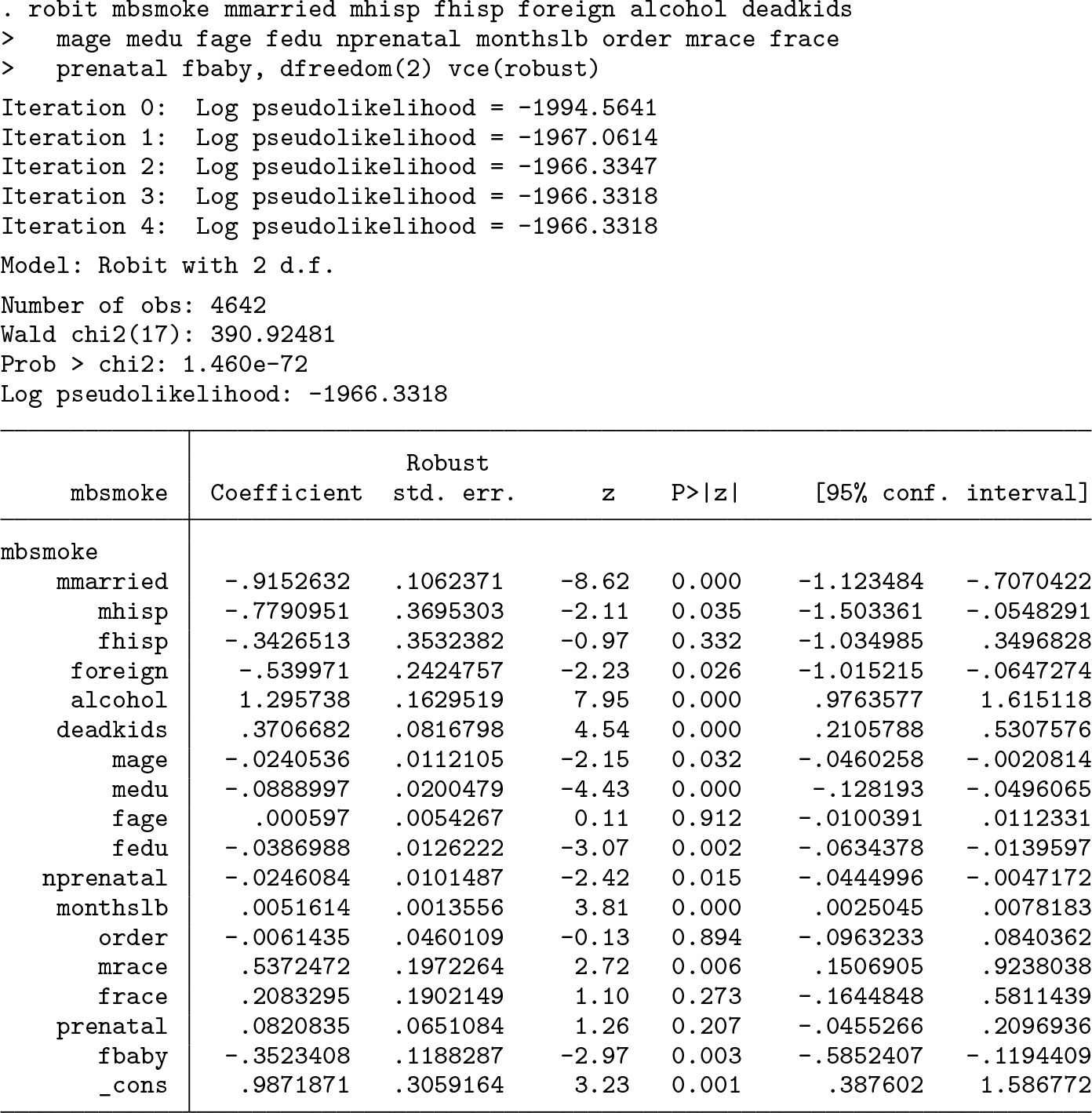
This time, the parameters are even harder to understand because they are expressed in robit units with 2 d.f. However, we can still compute propensity scores and ATE weights and do balance checks and variance inflation checks as before.
For the outlier designs, we identify a candidate outlier in the original dataset by choosing the subject with the lowest smoking propensity score under the logit model:

We see that the candidate outlier (identified by the indicator variable

We have revised this pregnancy (which already had a low smoking propensity) so that both the mother and father are 40 years old, have 30 years of full-time education (being perpetual students), and bother their doctor sufficiently to have 40 prenatal visits (the maximum observed in the original data). All of these features will probably predict high social and educational ranks and a low smoking propensity because people with such features do not often smoke. However, we then make them smokers. As very atypical smokers, they will probably have a high propensity ATE weight. (These fantasy parents are possibly living off trust funds and smoking ganja weed.) Having created our pregnancy record with exceptional but credible parents, we can rerun our logit and robit propensity models, doing the balance and variance inflation checks as before.
The balance checks for the four designs are done by plotting the unweighted and ATE-weighted Somers’s D statistics as reported in figures 3, 4, 5, and 6, respectively. We see that the robit model on the original dataset balances the propensity score and the covariates similarly to the logit model on the original dataset. However, the logit model on the outlier dataset is a disaster because a lot of weighted Somers’s D indices are large in either direction and the weighted Somers’s D for the propensity score is actually negative. The robit model on the outlier dataset, by contrast, balances the covariates and its propensity score similarly to the logit and robit models on the original dataset.

Somers’s D indices with respect to maternal smoking under design 1

Somers’s D indices with respect to maternal smoking under design 2

Somers’s D indices with respect to maternal smoking under design 3

Somers’s D indices with respect to maternal smoking under design 4
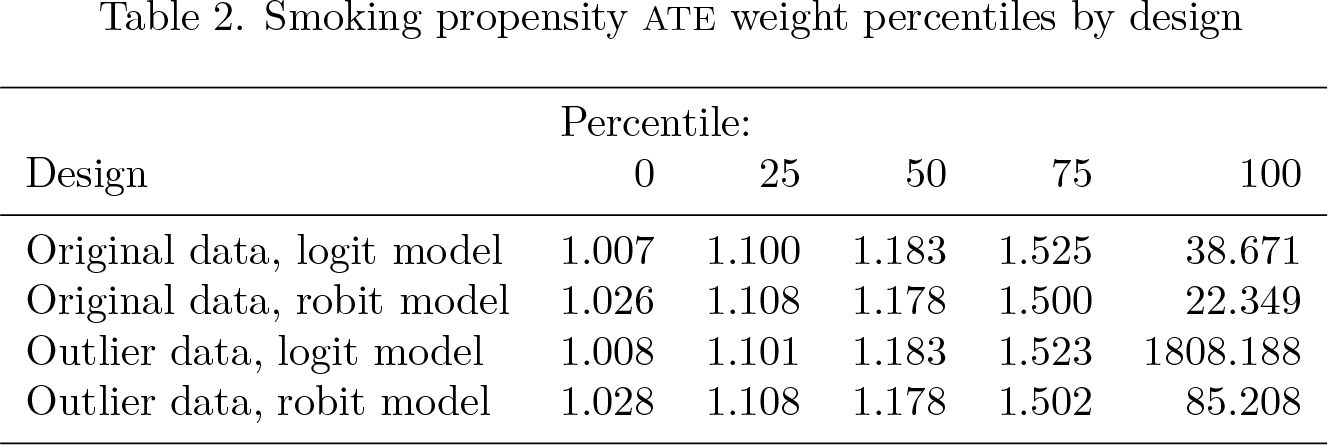
The smoking propensity-score percentiles for the four designs are given in table 1. The corresponding smoking ATE weight percentiles are given in table 2. We see that there is an enormous maximum ATE weight of 1808.188 for the logit model in the outlier dataset that belongs to our generated outlier. This is probably important in preventing these weights from balancing. By contrast, the maximum ATE weight for the robit model in the outlier dataset is “only” 85.208, which does not seem to compromise the balance.
Smoking propensity-score percentiles by design

Smoking propensity ATE weight percentiles by design
The variance inflation factors for the smoking ATE are given in table 3. These are nonspectacular for all sets of weights except for the weights from the logit model in the outlier scenario. The problem here is probably the outlier again. Outliers may or may not compromise the balance but usually inflate the variance, at least if the covariates predict only the exposure and not the outcome conditionally on the exposure.
Variance and SE inflation factors for the smoking ATE by design

Based on these design-stage results, we might choose to proceed to the analysis stage with either the robit or the logit for the original dataset, but we would definitely prefer the robit for the outlier dataset. So the robit seems to rein in the effect of outlying pregnancies without doing any damage in the absence of outlying pregnancies.
The ATE estimates for smoking on birthweight in grams for the four designs (with confidence limits and p-values) are reported in table 4. These are all similar to each other, except for the one for the logit model in the outlier dataset, which we would have rejected in the design phase.
Smoking ATE estimates for birthweight (grams) by design

5 Conclusions
We have developed a new user-friendly command (
Robit models have been described in the literature as a simple robust alternative to logistic and probit models. In particular, they have been recommended for the estimation of inverse-probability weights to adjust for missing-at-random values or for deriving propensity scores for causal inference. Further work to evaluate the performance of robit models under various scenarios in these settings would be helpful.
We hope that our
7 Programs and supplemental materials
Supplemental Material, sj-zip-1-stj-10.1177_1536867X231195288 - Robit regression in Stata
Supplemental Material, sj-zip-1-stj-10.1177_1536867X231195288 for Robit regression in Stata by Roger B. Newson and Milena Falcaro in The Stata Journal
Footnotes
6 Acknowledgment
This article has benefited from helpful discussions with our colleague Professor Peter Sasieni of King’s College London.
7 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.