
Abstract
There are now a number of reports in the literature that transposed letter (TL) priming effects emerge when two consonants are transposed (e.g., caniso-CASINO) but not when two vowels are transposed (e.g., cinaso-CASINO). In the present article, four masked priming lexical decision experiments, two in Italian and two in English, are reported in which TL priming effects involving the transposition of two adjacent consonants (e.g., atnenna-ANTENNA) were contrasted with those involving the transposition of a vowel and an adjacent consonant (e.g., anetnna-ANTENNA), a contrast not directly examined in the previous literature. In none of the experiments was there any indication that the priming effects were different sizes for the two types of transpositions, including Experiment 4 in which a sandwich priming paradigm was used. These results support the assumption of most orthographic coding models that the consonant–vowel status of the letters is not relevant to the nature of the orthographic code. The question of how to reconcile these results with other TL manipulations investigating vowel versus consonant transpositions is discussed.
In recent years, considerable research attention has been paid to “transposed letter” (TL) effects (Colombo, Sulpizio, & Peressotti, 2017; Frankish & Turner, 2007; Guerrera & Forster, 2008; Johnson, Perea, & Rayner, 2007; Kinoshita & Norris, 2009; Ktori, Kingma, Hannagan, Holcomb, & Grainger, 2014; Lupker, Perea, & Davis, 2008; Perea & Lupker, 2003a, 2003b, 2004; Schubert, Kinoshita, & Norris, 2018). The basic phenomenon is that TL nonwords (e.g., jugde) appear to be perceived as being more similar to their base words (i.e., JUDGE) than are nonwords created by substituting different letters for the transposed letters (e.g., “substitution letter” [SL] nonwords such as jupte).
Although TL effects have been reported in a number of experimental paradigms, the focus of the present research is the masked priming lexical decision paradigm (Forster & Davis, 1984), the paradigm used in the present experiments. In this paradigm, on each trial, a prime is initially presented for a very brief period of time (e.g., 50 ms), typically in lower case. Immediately following prime presentation, a (typically) upper case target is presented in the same location on the screen as the prime. The target serves as a backward mask for the prime with the result being that participants are rarely, if ever, aware of the prime’s existence. Participants then make a lexical decision to the target. With respect to TL effects, the specific phenomenon that is reported in this task is that responding to word targets is faster if the prime is a TL nonword than if it is an SL nonword.
As has been noted in most of the articles on this topic, this result is not one that was predicted by the older models of word recognition. Specifically, it was not predicted by models like McClelland and Rumelhart’s (1981) Interactive-Activation model, models that assume that letter positions are coded accurately and quickly. Partially in response to this situation, a number of newer models have emerged that do provide an explanation of TL effects (Adelman, 2011; Davis, 2010; Gómez, Ratcliff, & Perea, 2008; Grainger & van Heuven, 2003; Norris & Kinoshita, 2008, 2012; Whitney, 2001). What is important to note, however, is that essentially all of these models make no distinction between vowels and consonants. It was, therefore, somewhat of a surprise that Perea and Lupker (2004) were able to show that although transposing two nonadjacent consonants (e.g., caniso vs. caviro as primes for the target CASINO) produced a TL priming effect, transposing two vowels (e.g., cisano vs. cesuno as primes for the target CASINO) did not. This null TL priming effect when transposing two vowels has now been replicated a number of times in Spanish (e.g., Carreiras, Vergara, & Perea, 2009; Comesaña, Soares, Marcet, & Perea, 2016; Perea & Acha, 2009). There has also been one published replication of this pattern in English (Lupker et al., 2008).
If the consonant–vowel TL priming difference is real, it poses a clear challenge for the models of orthographic coding that do not distinguish between vowels and consonants. Several attempts have, therefore, been made to try to explain this pattern within the context of those models. For example, Lupker et al. (2008) suggested that the speed of position coding for letters may be frequency dependent. More frequent letters may be more rapidly coded into their correct positions. Therefore, the “i” and the “a” in a nonword prime like cisano would be tagged into the second and fourth letter positions very early in processing because “i” and “a” are very frequent letters. As a result, the nonword cisano would be no more similar to the word CASINO than an SL nonword like cesuno would be because in both cases two letter positions would definitely contain different letters than in the word CASINO. In support of this idea, Lupker et al. showed that transposing two high frequency consonants (e.g., pterext-PRETEXT) produced a smaller priming effect than transposing two low frequency consonants (sibazle-SIZABLE).
Although letter frequency, in terms of how fast letters are assigned to positions, may play a role in producing the consonant–vowel difference, results reported by Duñabeitia and Carreiras (2011) suggest that the complete explanation is likely to be somewhat more complicated. In their experiment, the set of consonants contained in a word was used as a prime (e.g., nml-ANIMAL). Except in the case of the initial letter (for some pairs), all letters in the prime would, as a result, be in a different letter position in the target. Therefore, if the more frequent letters were more likely to be assigned to their positions (positions 1, 2, or 3) in the orthographic code for the prime earlier than the less frequent letters were assigned to theirs, high frequency letter primes should be less effective primes than low frequency letter primes. Duñabeitia and Carrieras’s results, however, were that equal priming effects emerged regardless of whether the letters in the prime were high or low frequency.
Alternative explanations of consonant–vowel TL effects
An alternative way of explaining the consonant–vowel TL priming difference in the framework of current orthographic coding models would be to suggest that the difference may not be an orthographic coding phenomenon at all (Perea & Acha, 2009). This alternative idea derives support from examinations of TL effects in other paradigms. For example, a TL effect also arises when TL versus SL nonwords are presented as nonword targets in a simple (i.e., unprimed) lexical decision task (Carreiras, Vergara, & Perea, 2007; Colombo et al., 2017; Lupker et al., 2008; Perea & Lupker, 2004; Schubert et al., 2018), a task that requires dealing with later emerging codes. In contrast, a consonant–vowel TL difference does not arise in the masked priming same–different task (Perea & Acha, 2009), a task that seems to be mainly driven by the nature of orthographic codes while not involving higher level processes such as lexical access.
In the masked priming same–different task (Norris & Kinoshita, 2008), a reference stimulus is initially presented, followed by a masked prime followed by a target. The task is to decide whether the reference stimulus and target are the same. If the prime involves a transposition of two letters in the reference stimulus/target (which are the same stimuli on “same” trials), responding is facilitated. In three experiments, Perea and Acha (2009) demonstrated that the TL effects in that task did not show a consonant–vowel difference, that is, vowel TL nonwords produced just as large a priming effect as consonant TL nonwords. What these results suggest is that it is not the nature of the orthographic code that differs between vowel versus consonant TL nonword primes but how that code is used by higher level processes.
An account that builds on this idea would be one based on the concept of lexical constraint, that is, the constraint that the prime provides concerning possible targets (Carreiras, Gillon-Dowens, Vergara, & Perea, 2009; Duñabeitia & Carreiras, 2011; J. R. Perry, Lupker, & Davis, 2008). In masked priming lexical decision experiments, the reason that there is orthographic (form) priming is that primes are assumed to activate lexical representations for targets that are orthographically similar to those primes. The degree of activation they provide is, to a large extent, assumed to be a function of the degree of prime-target similarity. A second factor that determines the size of the priming effects, however, is how many similar targets are activated by a given prime. That is, lexical processing models assume that activated lexical representations compete with one another during lexical processing (e.g., Davis, 2010) which slows down target activation. Therefore, to the extent that a prime can cause activation to flow mainly to the target (i.e., to the extent that the prime’s activation is constrained to the target), there will be less competition and, hence, a larger priming effect.
The argument for how this idea could explain consonant–vowel differences in TL effects would be as follows. There are many more consonants than vowels in the alphabet. Thus, any identified consonants (e.g., during prime processing) provide much more useful information in terms of what lexical representations should be activated and what lexical representations should be inhibited. As a result, an SL prime like caviro would have the effect of not only providing reduced activation for CASINO but also providing activation for competitors that contain either a “v” or an “r” (in contrast to the impact of the consonant TL prime caniso). Identifying a vowel would have much less impact on the overall pattern of lexical activation as both the “e” and the “u” in the vowel SL prime cesuno and the “i” and the “a” in the TL prime cisano are contained in so many other words.
Essentially, the argument would be that, due to the nature of the lexicon, mismatching consonants in the prime (i.e., as with consonant SL primes) heighten the activation of more serious lexical competitors in comparison with consonant TL primes like caniso which do not contain mismatching consonants, producing a TL priming effect. Vowel TL and SL primes contain the same consonants (those contained in the target) and, therefore, activate essentially the same lexical representations. Hence, vowel TL and SL primes are equally effective primes. Thus, this type of account, which is a lexically based account, could explain the fact that consonant TL nonwords prime, whereas vowel TL nonwords do not (Perea & Lupker, 2004), within the context of current orthographic coding models, that is, within the context of models that do not propose any inherent differences in consonant versus vowel processing at the orthographic coding level.
This account would certainly be consistent with the data reported by New, Araújo, and Nazzi (2008) and New and Nazzi (2014) in French, and Soares, Perea, and Comesaña (2014) in European Portuguese. Those authors showed that the primes containing the target’s consonants (e.g., what we are calling vowel SL primes, duvo-DIVA) produce a priming effect (in comparison with an unrelated prime condition), whereas primes containing the target’s vowels (e.g., what we are calling consonant SL primes, rifa-DIVA) do not.
Unfortunately, this lexical constraint idea makes an additional prediction that is unsupported by essentially all of the available data. That is, if consonants are more important to the lexical access process than vowels, primes that contain all the relevant consonants in the correct order (i.e., both vowel SL and vowel TL primes) should be the best primes in a lexical decision task (i.e., the New et al., 2008; New & Nazzi, 2014; and Soares et al., 2014; pattern should hold for both prime types). None of the available data sets (Carreiras, Vergara, & Perea, 2009; Comesaña et al., 2016; Lupker et al., 2008; Perea & Acha, 2009; Perea & Lupker, 2004) support this prediction. Rather, the consonant TL primes (e.g., caniso for CASINO) were the most effective primes in all these experiments. Therefore, it seems unlikely that the lexical constraint idea would be able to provide a complete explanation of why TL primes are better than SL primes when consonants are being transposed but not when vowels are being transposed.
Is it possible that consonant–vowel status is represented in the orthographic code?
What also needs to be noted is that there are other word recognition models that may be able to provide alternative explanations for consonant–vowel TL differences in terms of priming. These types of models are based on the idea that the inherent differences between vowels and consonants, which are, to a large degree, phonologically based, are also coded orthographically, or, are reflected at the orthographic level (see Treiman, 1994, for this type of proposal).
Accounts of this sort note that consonants and vowels are phonological categories characterised by different systems of articulatory features (Caramazza, Chialant, Capasso, & Miceli, 2000). As Caramazza and Miceli (1990) argue, for example, “orthographic representations—the abstract mental representations of the spellings of words—include orthography-specific information regarding the consonant/vowel identity of the individual letters that make up a word’s spelling” (see also Buchwald & Rapp, 2003, 2006). This type of view suggests that, when we read words, the consonant–vowel status of the letters is encoded very early and is included in the orthographic representation that is formed from visual analysis, without the obligatory involvement of phonology.
The issue of there being different relative contributions of consonants and vowels in reading has been investigated a number of times although with contrasting results (see Berent & Perfetti, 1995; Colombo, 2000; Colombo, Zorzi, Cubelli, & Brivio, 2003; Lee, Rayner, & Pollatsek, 2002; New et al., 2008; New & Nazzi, 2014; C. Perry & Ziegler, 2002; Soares et al., 2014). For example, as noted, New et al. (2008) and Soares et al. (2014) reported priming for consonant-preserving primes (what we are calling vowel SL primes) but not for vowel-preserving primes (what we are calling consonant SL primes), compared with an unrelated prime condition, when the prime presentation time was 50 ms.
New and Nazzi’s (2014) results in a follow-up investigation were a bit more complex but still suggestive of a vowel–consonant difference at the orthographic level. With a 33 ms prime presentation time, consonant-preserving and vowel-preserving primes did not differ from each other, and nor did either differ from an unrelated prime condition (i.e., there was no priming). With a 66 ms presentation time, the advantage for consonant-preserving primes over vowel-preserving primes re-emerged. Unfortunately, the interpretation of this contrast is complicated by the fact that that difference was mainly due to there being inhibition for vowel-preserving primes compared with an unrelated prime condition, whereas no significant facilitation for consonant-preserving primes was observed (again, compared with an unrelated prime condition).
A second way of trying to establish the importance of the letter’s nature in the orthographic code can be found in experiments investigating the consonant-vowel structure of the prime and target. For example, in a lexical decision task in Spanish, Perea, Marcet, and Acha (2018) contrasted masked SL primes preserving the consonant–vowel (CV) structure of the target word (e.g., alusno-ALUMNO), masked SL primes not preserving the consonant-vowel structure (e.g., alueno-ALUMNO) and masked identity primes (e.g., alumno-ALUMNO). Expectedly, Perea et al. found a cost for both types of SL primes compared with the identity prime condition, however, the nature of the letter being replaced mattered, to at least some degree. When the letter being replaced was a consonant (as in the examples above in which the “m” is the letter being replaced), the cost was the same when that letter (i.e., “m”) was replaced by a consonant as when it was replaced by a vowel. However, when a vowel was replaced (e.g., the “u” in ALUMNO), the cost was less when the “u” was replaced by another vowel (i.e., the consonant-vowel structure was maintained as in alemno-ALUMNO) in comparison with being replaced by a consonant (i.e., the consonant-vowel structure was not maintained as in alsmno-ALUMNO). The latter result (the consonant-vowel difference when a vowel is the letter being replaced in the prime) would be consistent with the idea that establishing the target’s consonant-vowel structure by means of the prime is important. The former result (no consonant-vowel difference when a consonant is being replaced in the prime) is not. Hence, Perea et al. conclusion was that what is activated in the early stages of word activation may not be the consonant-vowel structure, but rather something like a consonant grid.
Research by Chetail and collaborators (Chetail & Content, 2012, 2013, 2014; Chetail, Drabs, & Content, 2014), however, would appear to make an even stronger case for the idea that consonant-vowel status is important early in processing. In their view, vowels and vowel clusters (i.e., a cluster involves two or more adjacent vowels, hence, the word bouquet contains two vowel clusters) form early pre-lexical perceptual (vowel-centred) units in word recognition. These researchers found evidence in support of their view in a number of paradigms: syllable counting, cross-case matching, estimating the physical length of stimuli. Chetail et al. (2014), for example, used the unprimed same–different task and examined situations in which the reference stimulus and target did or did not share vowel-centred units on “different trials”. For example, transposing two letters (u and r) in FOUREIL (FORUEIL) preserves the number of vowel-centred units, whereas transposing those same two letters in BOUDLET (BODULET) does not. Their results indicated that detecting a mismatch between the reference stimulus and target was much faster in the latter case, i.e., when the number of vowel-centred units is not preserved. Based on these results, they argued that orthographic processing involves initially identifying abstract letter identities followed by a pre-lexical process that requires parsing the letter string into vowel-centred units. When a target does not respect the CV organisation of the reference stimulus based on this principle, it should, therefore, be easier to decide that the two stimuli are not identical.
To sum up, the literature on this subject presents a rather complex picture, although it does contain support for the ideas that (1) there is a different status for consonants and vowels and (2) the status of letters as either consonants or vowels may be relevant in the orthographic code.
The present research
The goal of the present research was to provide a further examination of these issues. One point to note is that the transpositions used in most of the prior experiments investigating consonant–vowel differences, particularly those experiments using the masked priming lexical decision task, inevitably involved nonadjacent transpositions. In some sense, this is an odd choice as the original TL effects in masked priming involved adjacent transpositions (Forster, Davis, Schoknecht, & Carter, 1987; Perea & Lupker, 2003a, 2003b), as did the earlier work on TL effects using other paradigms (e.g., Andrews, 1996; Chambers, 1979; Holmes & Ng, 1993; O’Connor & Forster, 1981; Taft & van Graan, 1998). However, one of the reasons for researchers being hesitant to use nonadjacent transpositions, at least in English experiments, may be that adjacent vowel–vowel transpositions inevitably involve a graphemic change that creates a change in phonology (i.e., “ae” is virtually always pronounced qualitatively differently than “ea”). Note, however, that Lupker, Acha, Davis, and Perea (2012) have reported that transpositions that involved breaking up a grapheme behaved no differently than transpositions that altered any two other letters.
The specific contrast investigated here was between consonant-consonant (CC) transpositions and both consonant–vowel (CV) transpositions and vowel–consonant (VC) transpositions. In Experiment 1 (in Italian), CC transpositions were contrasted with transpositions involving one consonant and one vowel. To create the latter condition, both CV and VC transpositions were used. In Experiment 2 (in Italian) and Experiment 3 (in English), a balanced number of targets were used in CC, VC, and CV priming conditions. In Experiment 4 (in English), a sandwich priming paradigm (Lupker & Davis, 2009) was used with the primes and targets from Experiment 3 to increase the sizes of the priming effects for the three prime types, and consequently, the likelihood of finding differential priming effects.
Based on previous results, it is likely that CC transpositions will prime the corresponding target words (in comparison with SL primes). However, it is not clear whether either CV or VC transpositions will prime to any measurable degree. For example, based on the premise that the consonant–vowel status is established early in processing and is crucially important as a guide for lexical access (e.g., Caramazza & Miceli, 1990), CV and VC transpositions would create primes that are different from their targets in terms of consonant–vowel structure, whereas CC transpositions would not. Thus, models based on the assumption that consonant–vowel status is assigned very early in processing would seem to predict that VC and CV transpositions would create less effective primes than CC transpositions. If so, it should be the case that, because both related and unrelated primes involving CV and VC transpositions create an (identical) change of consonant-vowel structure, responses to targets primed by those primes might be slower overall than responses to targets primed by both related and unrelated CC primes (i.e., primes that do not alter the target’s consonant-vowel structure). That is, there would be an overall letter type effect. Whether this pattern emerges or not, there may still be TL priming effects from CV and VC primes (measured against the corresponding SL prime conditions). In contrast, it is also possible that the prime must maintain the consonant-vowel structure of the target for any priming effects to emerge. Thus, unlike CC transpositions that maintain the target’s consonant-vowel structure, CV and VC transpositions, transpositions that disrupt that structure could, in theory, produce a complete lack of priming.
At present, there appears to be only one investigation (in English) in which CV, VV, and CC transpositions were contrasted (Blythe, Johnson, Liversedge, & Rayner, 2014). Blythe et al.’s Experiment 2 involved the contrast between CC, VV, and CV adjacent letters (sytsem from system, faeture from feature, and fromat from format, respectively). The TL stimuli were either included in a reading task with a sentence context in which those stimuli were presented in the periphery before being changed to the correct spelling when the word was fixated (a boundary technique) or presented in isolation in a misspelling decision task. In the reading task, Blythe et al. found evidence in total reading times and in number and duration of regressions for a greater difficulty with CV than with CC and VV transpositions. In the misspelling decision task, longer latencies were associated with CV strings than the other two stimulus types. As only CV transpositions changed the consonant-vowel structure of the word, those authors concluded that there is evidence for an influence of consonant-vowel structure.
What should be noted, however, is that in their reading task, although an overall effect of letter transposition (peripheral presentations involving transpositions versus those involving no transpositions) was apparent in early measures of processing (e.g., first fixation durations), the relative difference between CC, VV, and CV conditions was not. Those differences only emerged on later measures of processing. Blythe et al. (2014) concluded, therefore, that the effect of consonant-vowel status only emerges at the phonological level.
If Blythe et al.’s (2014) conclusion is correct, we may observe no differences among the three primes types. In any case, the existence of prime type differences of the sort investigated in the present experiments is an empirical question and, to this point, there have been no investigations of this question using adjacent transpositions in masked priming, lexical decision experiments. The present experiments were an effort to begin filling this gap.
Experiment 1
The goal of Experiment 1 was to determine whether not only adjacent CC transpositions (e.g., puslante-PULSANTE; button) but also adjacent transpositions involving one consonant and one vowel (either CV transpositions, for example, pulasnte-PULSANTE, or VC transpositions, for example, pulsnate-PULSANTE) produce priming effects in a masked priming lexical decision task in Italian and, if so, whether those priming effects differ in magnitude.
Method
Participants
Forty students (22 males) from the University of Padua participated in this experiment (age = 19–32 years, M = 22) for course credit. All were native speakers of Italian and had normal or corrected-to-normal vision.
Materials
Italian words were extracted from PhonItalia (Goslin, Galluzzi, & Romani, 2014) to serve as target words. Nine of them had to be removed from the analyses due to typos in the primes associated with them (see below), so we report the characteristics of the remaining 55. Their mean length is 7.65 letters (range = 6–9) and their mean word frequency (per million) is 48.69 (range = 1.21–349.11). Four nonwords were created to serve as their primes. TL primes based on the target words were created in two ways, by (1) transposing two adjacent consonants (e.g., puslante-PULSANTE, the CC transposition condition) and (2) transposing a consonant and a subsequent adjacent vowel or a vowel and a subsequent adjacent consonant (e.g., pulasnte-PULSANTE or plusante-PULSANTE, the CV/VC transposition condition). In the original list of 64 targets, 26 were in the CV prime condition and 38 were in the VC prime condition. SL primes based on the TL primes were created in two ways, by (1) replacing the transposed consonants in the CC transposition primes with other consonants (e.g., purmante-PULSANTE, the CC substitution condition) and (2) replacing the transposed vowel and consonant in the CV/VC transposition primes with another vowel and another consonant, respectively (e.g., pulucnte-PULSANTE, the CV/VC substitution condition). Transpositions never involved the first or the last letter of the word, and CC and CV/VC transpositions were matched on the position of the first transposed/substituted letter (M = 3.87 and M = 3.80, respectively). The word targets and their primes in all experiments are listed in the online Supplementary Material.
In all, 64 orthographically legal nonwords were created to serve as nonword targets. CC and CV/VC transposition and substitution primes were created for the nonword targets in the same way as they were created for the word targets.
The targets were divided into four sets of 16, and each set was primed by primes from one of the four prime conditions. Four lists, with 64 target words and 64 target nonwords each, were created for an appropriate counterbalancing and participants were randomly (and equally) assigned to one of those lists.
Procedure
Participants were tested individually in a quiet room. E-prime 2.0 (Psychology Software Tools, Pittsburgh, PA; see Schneider, Eschman, & Zuccolotto, 2002) was used for stimulus presentation and data collection. Each trial began with a lower-case prime presented for 60 ms followed by the target, which was presented in upper case for 2000 ms or until a response was made. All stimuli were presented in Courier New-18 pt. font centred on the screen. Participants were instructed to respond as quickly and as accurately as possible as to whether the upper-case letter string was a real Italian word or not by pressing the “M” and “Z” keys, respectively, on a QWERTY keyboard. Participants were not informed of the presence of the primes. Participants completed 24 practice trials followed by a randomised list of all of the experimental trials.
Results
Data from nine word targets were removed due to typos in one or more of their primes, leaving 55 word targets that were primed by CC primes (all 55) and either CV (21) or VC (34) primes. In this and the following experiments, nonword data were not analysed. Incorrect responses (3.07%) and response latencies below 250 ms or above 1,750 ms (0%) were removed from the latency analyses. Latency and error analyses were conducted using generalised linear mixed-effects modelling in R version 3.5.1 (R Core Team, 2018), treating subjects and items as random effects and treating Letter type (CC vs. CV/VC) and Prime type (transposition vs. substitution) as within-subject and within-item fixed effects (Baayen, 2008; Baayen, Davidson, & Bates, 2008). Prior to running the model, R-default treatment contrasts were changed to sum-to-zero contrasts (i.e., contr.sum) to help interpret lower-order effects in the presence of higher order interactions (Levy, 2014; Singmann & Kellen, 2018). The model was fit by maximum likelihood with the Laplace approximation technique. The lme4 package, version 1.1-18-1 (Bates, Mächler, Bolker, & Walker, 2015) was used to run the generalised linear mixed-effects model. The function Anova in the car package version 2.1-2 (Fox & Weisberg, 2011) was used to obtain estimates and probability values for the fixed effects.
In the latency analysis, a generalised linear mixed-effects model was used instead of a linear mixed-effects model because generalised linear models, unlike linear models, do not assume a normally distributed dependent variable and can, therefore, better accommodate the typically positively skewed distribution of RT data (Balota, Aschenbrenner, & Yap, 2013; Lo & Andrews, 2015). We decided to use the generalised linear mixed-effects model and analyse raw RTs rather than the more common practice of using linear mixed-effects models and normalising raw RTs with a reciprocal transformation (e.g., invRT = −1000/RT). The reason is that nonlinear transformations systematically alter the pattern and size of interaction effects, rendering such transformations inappropriate when the research interest lies in interactions, as in the present case (Balota et al., 2013; Cohen-Shikora, Suh, & Bugg, 2018; Yang, Chen, Spinelli, & Lupker, 2019). 1
A Gamma distribution was used to fit the raw RTs, with an identity link between fixed effects and the dependent variable (Lo & Andrews, 2015). Note that, in the current version of lme4, convergence failures for generalised linear mixed-effects models, especially more complex models, are frequent, although many of those failures reflect false positives (Bolker, 2018). To limit the occurrence of convergence failures, for this and for the following analyses, we kept the random structure of the model as simple as possible by using only random intercepts for subjects and items. 2 The statistical model for the latency analysis was as follows: RT = glmer (RT ~ letter_type * prime_type + (1|subject) + (1|item), family = Gamma (link = “identity”)). The statistical model for the error rate analysis was as follows: Accuracy = glmer (accuracy ~ letter_type * prime_type + (1|subject) + (1|item), family = “binomial”). 3
As noted, our main research interest concerns whether priming for CC transpositions might differ from priming for CV/VC transpositions, that is, a Letter type by Prime type interaction. However, null-hypothesis significance testing does not allow one to draw strong conclusions if the effect of interest is not statistically significant. Thus, we also conducted a Bayes factor analysis to quantify the statistical evidence in favour or against a Letter type by Prime type interaction. This analysis was conducted using the Bayesian information criterion (BIC) approximation of the Bayes factor (Wagenmakers, 2007). Specifically, the Bayes factor BF01 was computed using the BIC values obtained for the model without the interaction (interpreted as the null hypothesis H0) and for the model with the interaction (interpreted as the alternative hypothesis H1) using the formula BF01 = exp((BIC(H1) – BIC(H0))/2) (Wagenmakers, 2007, p. 796). Note that BF01 < 1 would suggest evidence in support of H1 (i.e., the presence of the interaction), whereas BF01 > 1 would suggest evidence in support of H0 (i.e., the absence of the interaction; BF01 = 1 would suggest equal evidence for the two hypotheses). Jeffreys’s (1961) classification (as reported in adjusted form by Lee & Wagenmakers, 2013) was used to help interpret the size of the Bayes factor.
The mean response times and error percentages based on the by-subject data are presented in Table 1. For this and for the following experiments, the raw data and the scripts used for the analyses are publicly available at https://osf.io/7dgyh/.
Mean lexical decision times (in ms) and percentage of errors (in parentheses) for word targets in Experiment 1.
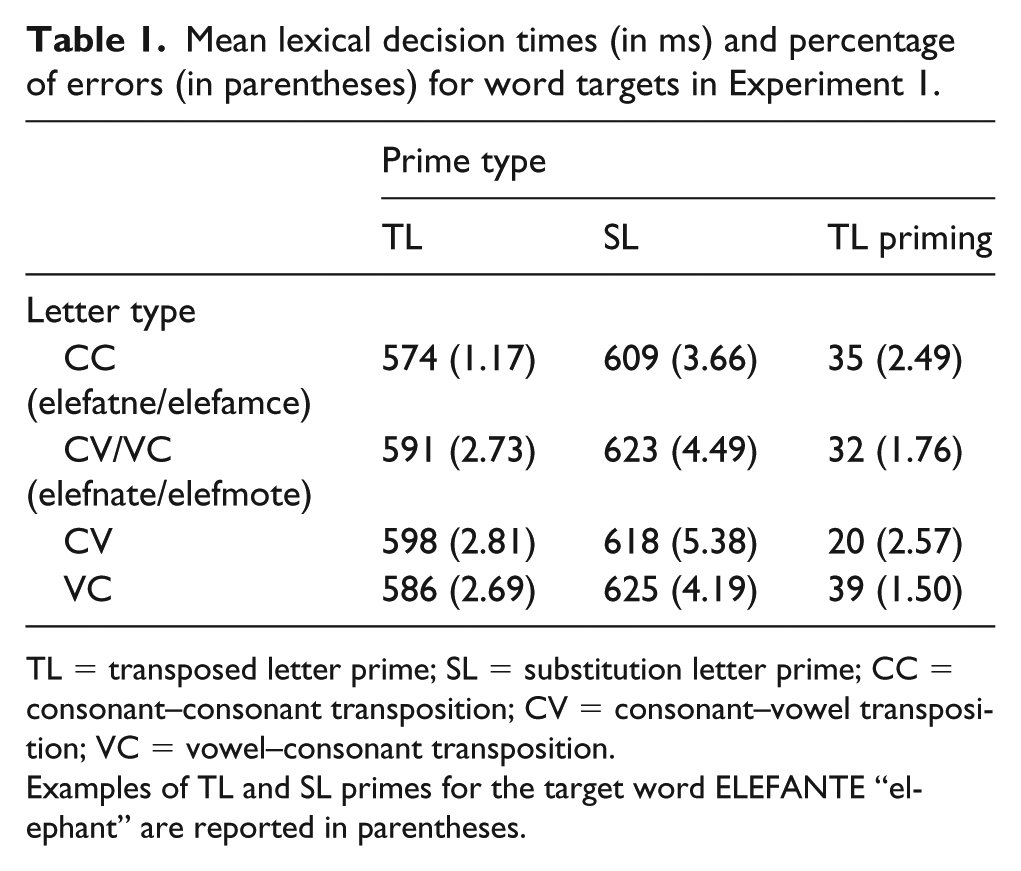
TL = transposed letter prime; SL = substitution letter prime; CC = consonant–consonant transposition; CV = consonant–vowel transposition; VC = vowel–consonant transposition.
Examples of TL and SL primes for the target word ELEFANTE “elephant” are reported in parentheses.
The latency data revealed a main effect of Letter type, χ2 = 9.25, p = .002, with faster responses to targets preceded by CC primes (591 ms) than to targets preceded by CV/VC primes (607 ms). The main effect of Prime type was significant as well, χ2 = 49.94, p < .001, with faster responses to targets preceded by transposition primes (583 ms) than to targets preceded by substitution primes (616 ms). The two factors, however, did not interact, χ2 = .001, p = .97. The Bayes factor for the comparison between the model with and the model without the interaction was BF01 = 46.15, meaning that the data were 46.15 times more likely to occur under the hypothesis of no interaction than under the hypothesis of an interaction. In Jeffreys’s (1961) classification scheme, this value would suggest “very strong” evidence for the absence of the interaction.
In the error data, the main effect of Letter type did not reach significance, χ2 = 2.75, p = .097. The main effect of Prime type was significant, χ2 = 8.28, p = .004, indicating that error rates were lower when targets were preceded by a transposition (1.98%) than a substitution prime (4.09%). Again, the two factors did not interact, χ2 = 1.11, p = .29, with the Bayes factor, BF01 = 26.51, indicating “strong” evidence for the absence of the interaction.
Discussion
As expected, a standard TL priming effect was obtained. Targets were responded to more rapidly when preceded by TL primes than by SL primes. More centrally, however, there was no evidence that this effect was larger for CC primes than for CV/VC primes, a finding that may seem a bit surprising when contrasted with previous research on consonant–vowel differences in Spanish (e.g., Carreiras, Vergara, & Perea, 2009; Comesaña et al., 2016; Perea & Lupker, 2004; Perea & Acha, 2009), a language that is much like Italian. That research, showing no priming for nonadjacent VV transpositions, might suggest that CV/VC transpositions (i.e., transpositions involving a vowel) would produce smaller priming effects than CC transpositions (i.e., transpositions not involving a vowel).
Note that in Experiment 1, we did not differentiate between CV and VC transpositions because no extant model of letter position coding suggests that the two types of transpositions should differ in any respect. However, there is some evidence that suggests that the magnitude of TL effects might be sensitive to the specific nature and context of the letters being transposed (Schubert et al., 2018). For example, although not directly related to the present situation, Schubert et al. found that in the unprimed same-different task, nonwords created by transposing nonadjacent consonants were harder to reject on different trials if one of the transposed consonants was involved in a consonant cluster (e.g., alhocol from ALCOHOL) than if neither of them was (e.g., lutanic from LUNATIC). Therefore, a reasonable question to ask is whether the more specific nature of the TLs mattered, that is, whether the magnitude of the TL priming effect was equivalent for CV and VC primes.
It should be noted, of course, that the present experiment was not designed to contrast CV and VC transpositions because one set of targets was associated with CV primes and another set of targets was associated with VC primes. Thus, any potential difference between the two conditions might simply reflect differences in the priming effects for the two different sets of targets. Nonetheless, we conducted a post hoc analysis breaking down the CV/VC condition into CV and VC primes as an initial step in exploring this question.
Out of the 55 targets being analysed, 21 were primed by CV primes and 34 were primed by VC primes. The two target sets did not differ on length, position of the first transposed/substituted letter, or word frequency. The mean response times and error percentages from the subject analyses are presented in Table 1. Both dependent variables were submitted to a generalised linear mixed-effects model with Letter type (CV vs. VC) as a within-subject and between-item fixed effect and with Prime type (transposition vs. substitution) as a within-subject and within-item fixed effect.
In the latency analyses, no main effect of Letter type was obtained, χ2 = 0.08, p = .77, whereas a main effect of Prime type was obtained, χ2 = 22.77, p < .001. Importantly, the interaction between Letter type and Prime type did not reach significance, χ2 = 2.11, p = .15. In addition, the Bayes factor analysis still suggested “strong” evidence for the model without the interaction, BF01 = 11.91., None of the effects reached significance in the error data (all ps > .10). Therefore, statistically, the evidence suggests that there is no difference between CV and VC primes. Numerically, however, the TL priming effect was noticeably smaller for CV primes (20 ms) than for VC primes (39 ms), a result that at least raises the question of whether such differences might emerge in a situation where the difference between CV and VC primes is examined in a more controlled fashion.
A final point to note is that there was a Letter type effect. Overall, targets in the CC condition were responded to 16 ms faster than those in the CV/VC condition. This result is consistent with the idea that primes are better primes when their CV structure matches that of the target. As with the CV vs. VC contrast discussed above, Experiment 2 allowed for a more controlled examination of this issue.
Experiment 2
Experiment 1 showed that TL priming effects are equivalent for transpositions involving two consonants and transpositions involving one consonant and one vowel. At the same time, there was a clear tendency in the data suggesting a potential difference between CV and VC transpositions, the former producing a numerically smaller TL priming effect than the latter, as well as a significant overall latency difference favouring the CC condition over the CV/VC condition. The aim of Experiment 2 was to provide a further examination of these issues by using the same set of targets for all primes—CC, CV, and VC. Because each target was primed by all three prime types across participants, this manipulation allows one to draw stronger conclusions about the relative magnitude of TL priming effects and about any overall latency differences produced by the three different types of transpositions.
Method
Participants
Thirty-six students (10 males) from the University of Padua participated in this experiment (age = 21–38 years, M = 24) for course credit. All were native speakers of Italian and had normal or corrected-to-normal vision.
Materials
Ninety-six Italian words were selected from PhonItalia (Goslin et al., 2014) to serve as target words. Their mean length is 8.03 letters (range = 7–10) and their mean word frequency (per million) is 47.91 (range = 0–579.64). TL and SL primes were created in the same manner as in Experiment 1, except that six, rather than four, different nonword primes were created for each target word: (1) CC transposition (puslante-PULSANTE), (2) CC substitution (purmante-PULSANTE), (3) CV transposition (pulasnte-PULSANTE), (4) CV substitution (pulucnte-PULSANTE), (5) VC transposition (plusante-PULSANTE), and (6) VC substitution (prosante-PULSANTE). As in Experiment 1, transpositions never involved the first or the last letter of the targets words, and CC, CV, and VC transpositions were matched on the position of the first transposed/substituted letter (M = 4.73, M = 4.67, and M = 4.72, respectively). Orthographic neighbourhood size (Coltheart, Davelaar, Jonasson, & Besner, 1977) and bigram frequency were also matched across all six primes to rule out the possibility of an influence of ease of prime processing on the magnitude of priming effects.
Ninety-six orthographically legal nonwords were created to serve as nonword targets. They were associated with CC, CV, and VC transposition and substitution primes created in the same way as was done in the parallel conditions for the word targets.
The targets were divided into six sets of 16 and each set was primed by primes from one of the six prime conditions. Six lists were created to complete the counterbalancing, and participants were randomly (and equally) assigned to one of those lists.
Procedure
Although there is no reason to believe participants in Experiment 1 were aware of the existence of the primes, the masking procedure used in that experiment did deviate slightly from the conventional masked priming procedure in word recognition research (Forster & Davis, 1984). To ensure that the primes were effectively masked in Experiment 2, we adopted the conventional masking procedure developed by Forster and Davis (1984) by applying two changes to the stimulus presentation sequence. First, the prime was preceded by 10 hashtags centred on the screen and displayed for 500 ms, and second, the prime duration was reduced slightly to 50 ms. The procedure was the same as that of Experiment 1 in all other respects.
Results
Incorrect responses (6.42%) and response latencies below 250 ms or above 1750 ms (0.20%) were removed from the latency analyses. The mean response times and error percentages from the subject analyses are presented in Table 2. The analyses were conducted in the same way as for Experiment 1, the only difference being that Letter type was a within-subject and within-item fixed effect with three levels (CC vs. CV vs. VC). Post hoc analyses, when necessary, were conducted using the emmeans package, version 1.3.1 (Lenth, 2018), with Tukey’s honestly significant difference (HSD) adjustment for multiple comparisons.
Mean lexical decision times (in ms) and percentage of errors (in parentheses) for word targets in Experiment 2.
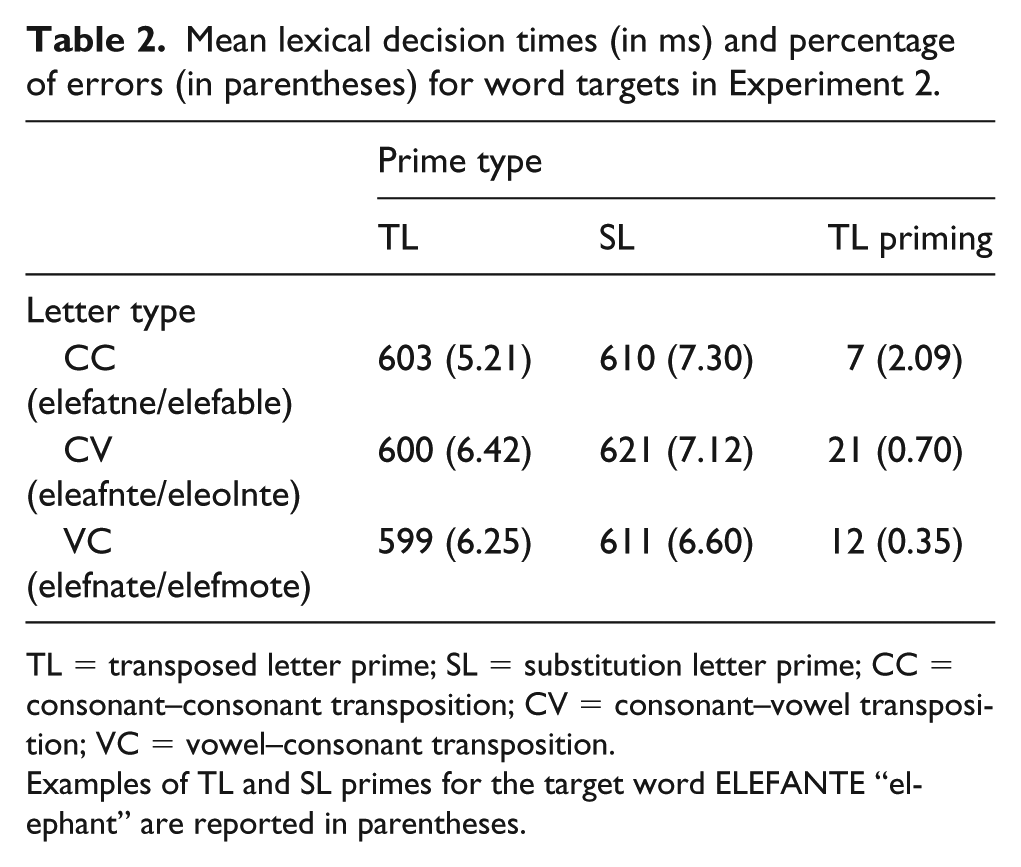
TL = transposed letter prime; SL = substitution letter prime; CC = consonant–consonant transposition; CV = consonant–vowel transposition; VC = vowel–consonant transposition.
Examples of TL and SL primes for the target word ELEFANTE “elephant” are reported in parentheses.
In the latency analyses, there was a main effect of Prime type, χ2 = 11.26, p < .001, with faster responses to targets preceded by transposition primes (605 ms) than to targets preceded by substitution primes (619 ms). The main effect of Letter type was not significant, χ2 = 1.55, p = .46, and neither was the interaction, χ2 = 3.67, p = .16. Indeed, the Bayes factor, BF01 = 648.23, indicated “extreme” evidence for the absence of the interaction. 4 None of the effects reached significance in the error data (all ps > .1).
Discussion
The data pattern most relevant to the present issues was replicated. As in Experiment 1, there was a significant TL priming effect, although it was a bit smaller than the parallel effect in Experiment 1. More importantly, its magnitude did not vary as a function of the letters involved in the transposition.
It is worth noting that the tendency suggested by the post hoc analysis of Experiment 1 (i.e., a smaller priming effect for CV than VC transpositions) was not confirmed here, as priming for CV transpositions was in fact numerically larger than priming for VC transpositions. It is also worth noting that the Letter type effect observed in Experiment 1 (i.e., faster overall latencies following CC primes than following CV or VC primes) was not replicated here. In sum, there is no convincing evidence up to this point that transpositions of adjacent consonants and transpositions of one vowel and an adjacent consonant differ in terms of the magnitude of the priming effects, or the overall latencies, that they produce.
Experiment 3
Because letter transposition effects do not generalise across all languages (Velan & Frost, 2003), one obvious question is whether the results reported so far would replicate in a different language. Experiment 3 was aimed at investigating this question by using the same design as used in Experiment 2 with English, a language in which there is some evidence for a consonant–vowel difference in TL priming (Lupker et al., 2008).
Method
Participants
Seventy-seven students (36 males) from the University of Western Ontario participated in this experiment (age = 17–23 years, M = 19) for course credit. All were native speakers of English and had normal or corrected-to-normal vision.
Materials
Ninety-six English words from the CELEX database (Baayen, Piepenbrock, & van Rijn, 1993) were selected to serve as target words (see the online Supplementary Material). Their mean length is 7.63 letters (range = 7–8) and their mean word frequency (per million) is 11.87 (range = 0–101.23). Six nonword primes were created for each of word targets in the same way as Experiment 2. CC, CV, and VC transposition and substitution primes were again matched on the position of the first transposed/substituted letter (M = 3.99, M = 4.01, and M = 3.99, respectively), as well as orthographic neighbourhood size (Coltheart et al., 1977) and bigram frequency. Ninety-six orthographically legal nonwords and their transposition and substitution primes were created as well.
The targets were again divided into six sets of 16, and each set was primed by primes from one of the six prime conditions. The participants whose data were included in the analyses were randomly (and equally) assigned to one of the six lists.
Procedure
The procedure was the same as that of Experiment 2, except that the forward mask consisted of eight hashtags and the target stimulus was presented for 2500 ms or until a response was made. In addition, all stimuli were presented in Courier New-10 pt. font and responses to words and nonwords were made by pressing the right and the left shift keys, respectively. The experiment was run using the DMDX (Forster & Forster, 2003) software.
Results
Five participants were removed from the analyses because their error rates were above 25%, leaving 72 participants. Incorrect responses (4.44%) and response latencies below 250 ms or above 1,750 ms (1.07%) were removed from the latency analyses. The mean response times and error percentages from the subject analyses are presented in Table 3. The same generalised linear mixed-effects model was used to analyse the results as in Experiment 2. For both the latency and the error analyses, the model failed to converge. However, convergence was obtained once model estimation was restarted from the apparent optimum. 2 We report the results from the restarted model.
Mean lexical decision times (in ms) and percentage of errors (in parentheses) for word targets in Experiment 3.
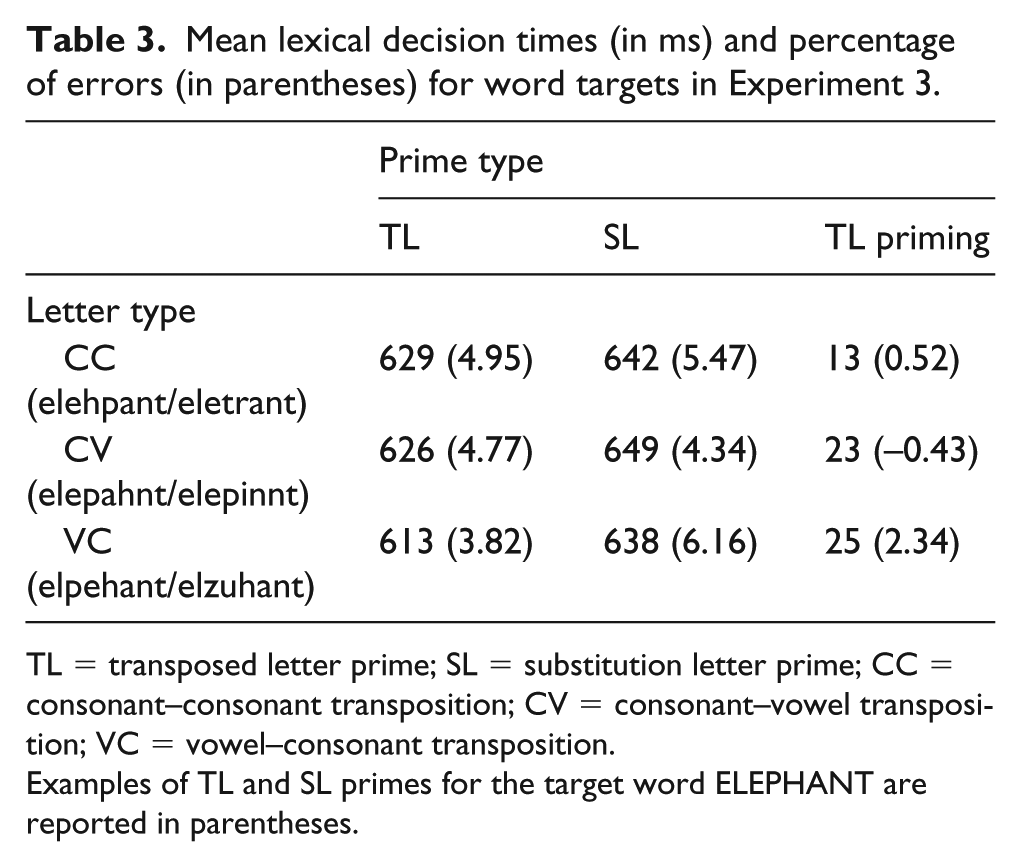
TL = transposed letter prime; SL = substitution letter prime; CC = consonant–consonant transposition; CV = consonant–vowel transposition; VC = vowel–consonant transposition.
Examples of TL and SL primes for the target word ELEPHANT are reported in parentheses.
In the latency analyses, there was a main effect of Letter type, χ2 = 8.55, p = .014, as overall latency in the VC condition (626 ms) was faster than the latency in the CV condition (638 ms), β = 10.98, SE = 3.89, z = 2.82, p = .013, and marginally faster than the latency in the CC condition (636 ms), β = 8.23, SE = 3.80, z = 2.16, p = .078. There was a main effect of Prime type, χ2 = 36.69, p < .001, with faster responses to targets preceded by transposition primes (623 ms) than targets preceded by substitution primes (643 ms). There was again no interaction, χ2 = 1.82, p = .40. The Bayes factor, BF01 = 3,053.75, suggested that there was “extreme” evidence for the absence of the interaction.
None of the effects reached significance in the error data, although the interaction between Letter type and Prime type was marginal, χ2 = 5.67, p = .059. This latter result was due to the fact that the TL effect in the error data was numerically larger in the VC condition than in the CC or CV conditions. However, in this case as well, the Bayes factor favoured the model without the interaction, suggesting that there was, in fact, “extreme” evidence for the absence of the interaction, BF01 = 390.75.
Discussion
In English as well as in Italian, no significant differences were found in the magnitude of TL priming effects across CC, CV, and VC transposition conditions. The data from these two languages thus provide converging evidence that prime transpositions involving two adjacent consonants and transpositions involving one consonant and one adjacent vowel provide equivalent benefits in terms of speed of word recognition. In addition, as in Experiment 2, there was no evidence that overall latencies were shorter in the CC conditions.
A potential concern about the findings reported so far is that the magnitude of the priming effects might be too small to generate appreciable differences across transposition types. Indeed, overall TL priming effects were somewhat smaller than it is generally reported in the masked priming literature, at least in Experiments 2 (14 ms) and 3 (20 ms). Experiment 4 was designed to address this concern by using the sandwich priming technique (Lupker & Davis, 2009) to increase the sizes of the TL priming effects.
The sandwich priming technique was created by Lupker and Davis (2009) with the specific goal being to allow the orthographic relationship between the prime and target to have a stronger impact on the observed priming effect. The task involves inserting a very brief (imperceptible) presentation of the target just before the prime of interest on all trials. According to Davis’s (2010) spatial-coding model, doing so produces two benefits. The first is that, by pre-activating the target, the impact of lexical competition on target processing is diminished. The second is that target decay is slowed after the target’s initial pre-activation by the presentation of an orthographically similar prime (see Davis, 2003, for a more complete explanation of the processes that are presumed to be affected in a masked priming situation). This task has now been used to investigate a number of form/orthographic priming effects that are small in size in the conventional task with the inevitable result being a noticeable increase in the size of those priming effects in the sandwich priming task (e.g., Davis & Lupker, 2017; Lupker, Zhang, Perry, & Davis, 2015).
Experiment 4
Method
Participants
Sixty-two students (22 males) from the University of Western Ontario participated in this experiment (age = 17–21 years, M = 18) for course credit. All were native speakers of English and had normal or corrected-to-normal vision.
Materials
The materials were the same as in Experiment 3.
Procedure
Each trial consisted of a sequence including an eight-hashtag forward mask displayed for 500 ms, the (upper case) target displayed for 33 ms, the (lower case) prime displayed for 50 ms, and the (upper case) target displayed for 2,500 ms or until the participant responded. All stimuli were centred on the screen. The procedure was otherwise identical to that of Experiment 3.
Results
One participant was removed from the analyses because her error rate was above 25% and another participant was removed due to an equipment malfunction, leaving 60 participants. Incorrect responses (4.11%) and response latencies below 250 ms or above 1,750 ms (1.41%) were removed from the latency analyses. The mean response times and error percentages from the subject analyses are presented in Table 4. The same generalised linear mixed-effects model used in Experiments 2 and 3 was used to analyse the results. The model for the latency analysis failed to converge, but convergence was obtained when model estimation was restarted from the previous fit. 2 . We report the results from the restarted model.
Mean lexical decision times (in ms) and percentage of errors (in parentheses) for word targets in Experiment 4.

TL = transposed letter prime; SL = substitution letter prime; CC = consonant–consonant transposition; CV = consonant–vowel transposition; VC = vowel–consonant transposition.
Examples of TL and SL primes for the target word ELEFANTE “elephant” are reported in parentheses.
The latency analyses showed a main effect of Prime type, χ2 = 90.74, p < .001, with faster responses to targets preceded by transposition primes (648 ms) than to targets preceded by substitution primes (681 ms). The main effect of Letter type was not significant, χ2 = .40, p = .82, and neither was the interaction, χ2 = .37, p = .83. Once again, the Bayes factor, BF01 = 4,695.61, suggested that there was “extreme” evidence for the absence of the interaction.
The error data mirrored the latency data. There was a main effect of Prime type, χ2 = 12.04, p < .001, with fewer errors to targets preceded by transposition primes (3.72%) than to targets preceded by substitution primes (5.56%). Neither the main effect of Letter type nor the interaction was significant (all ps > .10).
Discussion
The sandwich priming technique succeeded in increasing the magnitude of the TL priming effect, which was now 33 ms compared with the 20 ms of Experiment 3. However, just like in the previous experiments, the TL priming effect was not modulated by transposition type. Priming effects were once again equivalent for CC, CV, and VC transpositions. Furthermore, there was no evidence that overall latencies were shorter following CC primes.
General discussion
The goal of the present experiments was to investigate the impact in a masked priming lexical decision task of transposing an adjacent vowel and consonant in comparison with the transposition of two adjacent consonants. Previous research (Carreiras, Vergara, & Perea, 2009; Comesaña et al., 2016; Lupker et al., 2008; Perea & Acha, 2009; Perea & Lupker, 2004) has suggested that, when transposing nonadjacent letters, CC transpositions (e.g., caniso) produce priming effects, whereas VV transpositions (e.g., cinaso) do not. This result appears to have no obvious explanation in the context of most current models of orthographic coding. More specifically, because most models do not distinguish between vowel and consonant letters, there would be no reason for CC transposition primes to be effective when VV transposition primes are not.
In the Introduction, we reviewed several potential accounts of this pattern while noting that none were able to successfully explain it. Therefore, the question of whether and how consonant–vowel status affects masked priming appeared to need additional investigation. In the present experiments, we examined this general issue by comparing priming effects when one letter is a consonant and the other is a vowel versus when both letters are consonants (with the transpositions involving adjacent letters).
In four experiments, two in Italian and two in English (one of those experiments involving the sandwich priming paradigm), the priming effects produced by CV and VC transpositions were identical to those produced by transposing two adjacent consonants. These results would be quite consistent with the predictions of most of the current models of orthographic coding, models that do not distinguish between vowel and consonant letters. For example, in the open-bigram model of Schoonbaert and Grainger (2004), the letters of the prime activate the appropriate open bigrams and those bigrams activate the lexical representation of the target. The priming effect is produced by the overlap in the open bigrams between prime and target irrespective of the consonant–vowel status of the TLs. In the spatial-coding model (Davis, 2010), input letters are matched to the whole word representations, and no role of consonant–vowel status is assumed. Given that the priming effects were essentially the same size for CC, CV, and VC transposition primes in the present experiments, the apparent conclusion is that, consistent with these models, little, if any, role is being played by consonant–vowel status in the processes producing adjacent TL priming effects.
We also should note that these equivalent priming effects, per se, would also not necessarily be inconsistent with models that are based on the notion that the consonant–vowel structure of the letter string being read is represented in the orthographic code. Transposing a consonant and its adjacent vowel alters that consonant–vowel structure. However, our control (i.e., SL) primes experienced the same structural alteration. Therefore, these models would not necessarily predict that CV or VC primes would show a smaller TL priming effect than CC primes (in which the target’s structure is maintained in both TL and SL primes).
What would, potentially, be more relevant for these models would be the comparison between primes in the CC condition and primes in the CV/VC conditions. The former type of prime (both TL and SL) maintains the consonant–vowel structure of the target, whereas the latter type (both TL and SL) does not. Therefore, one might expect that overall latencies in the CC condition might be faster than in the CV/VC conditions due to the CC primes establishing/activating the correct consonant–vowel structure of the target. The data from the present Experiment 1 are consistent with this expectation, however, there is not even a hint of this pattern in the other three experiments.
Another account based on the idea that consonants and vowels have a different status is the hypothesis put forward by Chetail and colleagues (Chetail et al., 2014; Chetail, Ranzini, De Tiège, Wens, & Content, 2018) that vowel-cluster units are a main determinant of orthographic similarity. We already noted that CV and VC transpositions change the CV structure of the primes, in some cases producing a change in the nature of vowel-cluster units and in some cases not. In particular, in Experiment 2, whereas all the CC primes (both TL and SL) matched their target in terms of vowel-cluster units, 43% of the CV primes and 21% of the VC primes (both TL and SL) did not do so. Similarly, in Experiments 3 and 4, all CC primes (both TL and SL) matched their targets in terms of vowel-cluster units, whereas 25% of the CV primes and 31% of the VC primes did not do so. If a match in vowel-cluster units matters in that target recognition is facilitated when such a match occurs, we would have expected faster latencies following CC primes (both TL and SL) than following VC or CV primes. As noted, such was not the case in either experiment.
What must be noted is that none of the studies reported by Chetail and collaborators used a masked priming lexical decision task. It is likely, therefore, that the different results may be attributable to different processes involved in the different experimental paradigms. The overall conclusion, however, seems to be that although the consonant–vowel structure of the letter string being processed is undoubtedly represented at some level, the present data provide no evidence for the idea that that structure is represented at the level of the orthographic code (see also Perea et al., 2018).
Given that the present experiments produced no evidence that the type of TL priming investigated here varied as a function of the transposed letters’ consonant–vowel status, what implications can one draw concerning the lack of priming from VV TL primes in masked priming lexical decision tasks (e.g., Carreiras, Vergara, & Perea, 2009; Comesaña et al., 2016; Perea & Acha, 2009 in Spanish; Lupker et al., 2008 in English)? The most basic conclusion offered by the present results, of course, is that because both VC and CV transpositions involved vowels and yet they produced the same size priming effect as that generated by CC transpositions, it would appear that it is not the involvement of a vowel in the prime, per se, that prevents priming effects from emerging.
What’s also worth noting, however, is that the consonant–vowel distinction is not an unimportant one in word recognition, as both the results of Chetail and colleagues (Chetail et al., 2014; Chetail et al., 2018) and those of Perea et al. (2018), just to mention the most recent ones, demonstrate, although in apparently contrasting directions. That is, the results in the former papers suggest that the important units are vowels, whereas the results in the latter paper suggest what is crucial is the consonant grid. Also worth noting is that Perea and Lupker (2004), using Spanish stimuli, reported that although both consonant (caniso) and vowel (cisano) TL nonwords were harder to reject than SL nonwords (i.e., both showed a TL effect) in an unprimed lexical decision task, the effect was larger for consonant TL nonwords than vowel TL nonwords. Importantly, Lupker et al. (2008) replicated this pattern using English stimuli and Schubert et al. (2018) have replicated Lupker et al.’s results (using Lupker et al.’s stimuli), indicating that that pattern is not language dependent.
Perhaps the, apparently, reliable consonant–vowel difference in those unprimed lexical decision tasks is the place to start in thinking about these issues. Although what produces the consonant–vowel difference in those tasks is not entirely clear, a reasonable possibility is that it is due to the impact of phonology (Colombo et al., 2017; Frankish & Barnes, 2008; Frankish & Turner, 2007). That is, virtually by definition, the consonant–vowel status of a word is a distinction that would be represented at the phonological level, and the phonological level would be likely to influence responding when discriminating words from nonwords (i.e., in a lexical decision task), particularly when those nonwords are orthographically similar to known words (i.e., TL nonwords). The masked priming paradigm, in contrast, taps into processing that arises during the first 50 ms or so after stimulus presentation, a time at which phonological information is only weakly represented (see also Ferrand & Grainger, 1992, 1993). Hence, much less evidence of an impact of phonology in masked priming experiments would be expected.
This line of reasoning, however, does not necessarily provide an answer the question of why consonant–vowel differences have been reported in the masked priming lexical decision task, in particular, the different patterns of priming effects for consonant-preserving and vowel-preserving primes obtained in the studies by New and colleagues (New et al., 2008; New & Nazzi, 2014) and Soares et al. (2014) discussed in the Introduction and, more central to the present research, the absence of priming from VV TL primes in Spanish studies (e.g., Carreiras, Vergara, & Perea, 2009; Comesaña et al., 2016; Perea & Acha, 2009) as well as in one English study (Lupker et al., 2008). As noted, results from masked priming tasks are presumed to mainly reflect the nature of the orthographic code, not the nature of phonological representations. Therefore, the CC vs. VV TL priming difference does seem to imply that consonant–vowel status is somehow relevant to the nature of the orthographic code, an idea that appears to be inconsistent with the present data.
What should also be noted, however, is that a number of attempts to replicate the only English study showing a null priming effect from nonadjacent VV TL primes (Lupker et al., 2008) have been unsuccessful even when Lupker et al.’s original stimuli were used (Yang & Lupker, in review). Potentially, therefore, the null VV TL priming effect is idiosyncratic to Spanish, a language that has a very shallow orthography (in fact, one that appears to be at least as shallow as Italian). As a result, potentially, Spanish readers are able to activate phonology sufficiently rapidly that phonology comes to play a larger role in masked priming lexical decision tasks than that experienced by even Italian readers. Hence, the Spanish pattern in masked priming lexical decision may be one that is also due to the impact of phonology. Before drawing any definitive conclusions, however, and given the similarity between Spanish and Italian, it would be useful to replicate the conditions of the Spanish experiments in Italian, using nonadjacent letters.
In conclusion, the present results are generally inconsistent with the idea that consonant–vowel status affects the orthographic level of processing, the level that appears to be tapped by masked priming. This conclusion is consistent with the basic assumptions made by most of the present models of orthographic coding. The impact of consonant–vowel status and other phonologically based factors are, however, clearly important to the reading process. How and where in the process their effects arise, therefore, remain crucial issues for subsequent research.
Supplemental Material
Supplementary_Material – Supplemental material for The impact of consonant–vowel transpositions on masked priming effects in Italian and English
Supplemental material, Supplementary_Material for The impact of consonant–vowel transpositions on masked priming effects in Italian and English by Lucia Colombo, Giacomo Spinelli and Stephen J Lupker in Quarterly Journal of Experimental Psychology
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was partially supported by Grant DOR (Dotazione Ordinaria per Ricerca, Università degli Studi di Padova–2017) to Lucia Colombo, by Natural Sciences and Engineering Research Council of Canada Grant A6333 to Stephen J. Lupker, and by the Ontario Trillium Scholarship to Giacomo Spinelli.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.