
Abstract
Task set selection is facilitated when people expect a partner to perform the same task, suggesting that the features of the partner’s performance are represented. However, it is unclear how similar the partner’s reactions must be to promote compatibility effects: does a partner have to imitate subjects’ specific actions or is it enough to perform the same task while responding to different stimuli with different actions? This present study investigated this question in a joint picture–word interference paradigm. Subjects either named pictures or read words, and a partner responded by performing the same or the competing task. In Experiment 1, the partner used the same picture–word combinations as the subject and thus compatible trials implied a complete imitation. Compatibility benefits were observed. In Experiment 2, the partner performed the same or the competing task on different stimuli, producing different actions. Compatibility effects were absent. To test whether this indicates that an overlap in abstract task features is insufficient or resulted from excessive task difficulty, Experiment 3 replicated Experiment 2 with a smaller stimulus set. Compatibility benefits were found. Taken together, the results suggest that a partner’s abstract task can be represented and affect task set selection processes even without an overlap in stimulus-response mappings.
Introduction
Goal-directed actions are selected through an anticipation of their sensory consequences (Hommel et al., 2001). Accordingly, action planning is supported by a presentation of compatible action effects. It is easier to perform actions when they produce effects that overlap with the action in terms of features, such as location (Kunde, 2001; Pfister, Janczyk, et al., 2014), duration (Kunde, 2003), or intensity (Kunde et al., 2004). Recent research has revealed that during joint action, anticipated partner reactions can serve the same function as inanimate action effects (Kunde et al., 2018; Müller, 2016; Pfister et al., 2013). It is easier to perform actions when knowing that a partner will imitate them, compared to situations in which the partner is expected to perform non-matching actions. Most research on the compatibility of anticipated partner reactions has focused on situations where subjects perform one of two specific actions while the partner’s reactions do or do not match this action in terms of its low-level features (e.g., location and duration). An issue that has rarely been addressed is whether and how anticipated partner reactions affect task set selection. This selection has been defined as follows (Rogers & Monsell, 1995, p. 207): To form an effective intention to perform a particular task, regardless of which of the range of task-relevant stimuli will occur, is to adopt a task-set. Familiar task-sets, such as naming, can be called up from memory. Novel ones can be specified by instructions or other forms of training.
Thus, in the context of anticipated partner reactions, the question arises whether it is easier to plan and perform a task (e.g., word reading, picture naming) when knowing that a partner will perform the same task. And if so, does this facilitation rely on an anticipation of the partner’s specific action or abstract task set?
Initial evidence suggests that anticipated partner reactions can play a role in task set selection (Müller & Jung, 2018). In a series of experiments, subjects performed conflicting tasks of asymmetric strength. They selected endogenously versus exogenously cued targets (Experiment 1) or named pictures versus read words (Experiments 2 and 3). After each reaction by the subject, a partner predictably performed either the same task (compatible) or the competing task (incompatible). Compatible partner reactions facilitated task set selection, although compatibility benefits were limited to the stronger task (i.e., exogenous selection and word reading). Critically, a large number of stimuli and responses were used—in Experiments 2 and 3, each trial even had its own unique stimulus and response—so that the influences of partner reaction compatibility cannot be ascribed to the formation of links between low-level action features and corresponding partner reaction features. However, the partner did not only perform the same task as the subject but also performed it on the same stimuli. Accordingly, in compatible trials, subject actions and partner reactions were identical. Therefore, it remains an open question whether compatible partner reactions also facilitate task set selection when they only match subjects’ abstract tasks but not their specific actions.
To provide a theoretical background for the present study, the following sections discuss the role of task sets in joint action and then present two lines of research on individual task performance that provide reason to assume that abstract task sets and not just specific stimulus-response (S-R) associations might play a role in the anticipation of partner reactions.
Task sets in joint action
Sharing one task
In the joint action literature, there is an ongoing debate whether and how people co-represent a partner’s task (e.g., Böckler et al., 2012; Dolk et al., 2014; Gambi et al., 2015; Liepelt et al., 2012; Sebanz et al., 2003; Wenke et al., 2011). Most studies have used paradigms, such as the Joint Simon task, in which two people share one task and each partner performs half of it. The common finding is that people show standard compatibility effects when performing half of the task in a joint condition but not when performing half of the task while the other half is not performed by anyone (i.e., go/no-go task). This has been taken to suggest that in the joint condition, people covertly co-perform the partner’s half of the task (Sebanz et al., 2003), 1 although there are alternative accounts that do not require any assumptions about co-representation. Instead, these accounts explain the findings by non-social factors, such as the salience of the spatial dimension (for a review, see Dolk et al., 2014). With a partner sitting next to them, people more readily code responses as “left” and “right” than when performing a task in isolation, and this is sufficient to produce Simon effects.
However, effects that suggest co-representation have also been observed in non-spatial tasks. For instance, similar conclusions have been drawn from studies of joint picture naming where people named several exemplars of object categories (e.g., furniture and fruits). When performing this task alone, the standard finding is cumulative semantic interference—naming latencies increase with each new exemplar of a category (Belke, 2013; Howard et al., 2006). Interestingly, this cumulative semantic interference also is found when the other exemplars were named by a partner (Kuhlen & Abdel Rahman, 2017), suggesting that subjects covertly name the partner’s pictures.
All studies mentioned so far have focused on situations in which two people share a set of stimuli, while the present study focuses on action effects in joint action. However, influences of the partner’s performance have also been shown to depend on action effects (Pfister, Dolk, et al., 2014). In a task comparable to the joint Simon task, subjects either shared the task with a partner or performed half of it alone and received either compatible or incompatible action effects. The compatibility of action effects only affected performance when the task was performed jointly but not when half of the task was performed in isolation.
Taken together, studies in which two people share one task have produced ample evidence that a partner’s actions affect people’s own performance. A common interpretation is that people covertly co-represent the partner’s task, including his specific actions, selecting his responses as if it were their own.
Taking turns on two tasks
However, there are paradigms in which people share two tasks (i.e., one partner performs Task 1 and the other performs Task 2). In such settings, usually no evidence for action co-representation is found (Liefooghe, 2016; Wenke et al., 2011; Yamaguchi et al., 2017b). For instance, Yamaguchi et al. (2017b) used a task switching paradigm in which one partner classified colours and another partner classified shapes. This joint condition was contrasted with a single condition in which people only performed one task, while nobody performed the other one. Task- and cue-switch costs were found after go trials but not after no-go trials, regardless of whether in no-go trials a partner had performed the other task. Several similar results seem to support the conclusion that “the task co-representation account does not seem to apply to dual-task situations in which participants handle distinct tasks rather than a complementary S–R mapping of a single task” (Liefooghe, 2016, p. 72).
However, for two reasons, the studies presented so far do not provide conclusive evidence that a partner’s task set cannot be represented when people perform two tasks. First, some studies did find effects of partner tasks in joint task switching. Dudarev and Hassin (2016) and Liefooghe (2016) reported switch costs after the partner had performed the other task. This result might be specific to the paradigms used, in which each partner only performed one and the same task throughout the experiment (cf. Yamaguchi et al., 2017b). However, in a paradigm similar to the one used by Yamaguchi et al. (2017b)—and thus in a situation where both partners performed each task in some trials—Yamaguchi et al. (2017a) found switch costs after no-go trials in a joint condition when the two partners experienced shared action effects. Second, the studies introduced above have used paradigms in which two people take turns performing two tasks (i.e., joint task switching). An alternative way of studying the influences of a partner’s task set is to use conflict paradigms, such as Stroop or picture–word interference, and have each partner perform one of the two competing tasks in each trial.
Within-trial conflict paradigms
Compared to turn-taking paradigms, within-trial conflict paradigms profoundly change the situation for subjects (for related arguments, see Sellaro et al., 2020). Co-representing the partner’s actions (i.e., using his stimuli and selecting his responses) would effectively turn the situation into a dual task in which subjects have to perform two competing tasks, while in turn-taking paradigms co-representing the partner’s actions in no-go trials only implies that subjects do not have to wait. Thus, in contrast to turn-taking paradigms, within-trial conflict paradigms provide good reason for subjects not to co-represent the partner’s actions, and thus provide a critical test of task set co-representation. A second benefit is that they allow for studying task set co-representation more directly through its impacts on current performance, rather than indirectly through sequential effects in subsequent trials (i.e., switch costs). However, they raise a problem. If subjects perceived the partner’s response just before or while producing their own response, this would obviously lead to massive interference. To deal with this dilemma, two strategies have been applied so far—using remote or ostensive partners and using non-distinguishable partner responses (e.g., keypresses while the partner’s hands are covered).
Three studies are of particular relevance to the present study. First, Sellaro et al. (2020) used a picture–word interference paradigm in which subjects named pictures and were told that a partner in another room would take care of the conflicting word task. This led to a reduction of interference from the words (although only when they were printed in alternating upper and lower case letters and thus were harder to read). An important conclusion from this study is that the partner’s abstract task set seems to be represented, while the observed benefits speak against the possibility that subjects co-represented the partner’s specific actions, which would obviously have led to interference rather than benefits.
Second, Gambi et al. (2015) used a joint picture-naming paradigm in which subjects named pictures and were told that a partner in another room named the same pictures, different pictures, performed an unrelated categorization task, or did nothing. In a series of four experiments, they found that picture naming was slower when subjects believed the partner was concurrently naming pictures as well, rather than categorising pictures or not responding. However, subjects’ performance was unaffected by whether the partner named pictures in the same or opposite order. Again, this provides evidence that subjects represent the partner’s task set but not his specific actions.
Third, Böckler et al. (2012) used a joint Navon task in which subjects reacted to the global or local dimension of compound letter stimuli, while a partner reacted to the same or the conflicting dimension. Interference was found in the latter condition but was independent of the congruency between the subject’s and the partner’s letters. The authors concluded that the partner’s task set interfered with selecting or maintaining one’s own focus of attention. Although this study used a turn-taking (go/no-go) paradigm, its overall conclusions are in line with those of the previous two studies. In conflict paradigms, people do not seem to co-represent the partner’s specific actions, but still the partner’s abstract task set affects their own task set selection processes.
Interim conclusion
The studies presented in the previous section (Böckler et al., 2012; Gambi et al., 2015; Sellaro et al., 2020) provide evidence that performance can be affected by a partner’s task set without being affected by his specific S–R mappings. This notion is relatively new in the joint action literature, where the question has usually been whether people do or do not co-represent a partner’s actions. Some authors conclude from their results that people do co-represent them (e.g., Baus et al., 2014; Demiral et al., 2016; Dudarev & Hassin, 2016; Kuhlen & Abdel Rahman, 2017; Sebanz et al., 2003), while others conclude that they do not (e.g., Dolk et al., 2014; Liepelt et al., 2012; Saunders et al., 2017; Wenke et al., 2011; Yamaguchi et al., 2017b). Most alternative accounts of the mechanisms underlying seemingly social phenomena are “task-content-free.” For instance, they suggest that people use the partner as a spatial reference (Dolk et al., 2014) or that they represent who is going to respond (Wenke et al., 2011) and when the partner is going to respond (Liepelt et al., 2012). Thus, they do not speak to the possibility that an absence of action co-representation can still mean that people represent something about the content of what the partner is doing. Instead, the literature on individual task performance provides evidence that representations can go beyond specific S–R mappings. Some of this evidence is presented in the following sections.
Abstract task sets and generalised representations
Influence of task sets on action selection
Task sets play a special role in action control that cannot be reduced to a formation of S–R associations (for an overview, see Hazeltine & Schumacher, 2016). They influence task switching performance regardless of low-level features (Mayr & Bryck, 2005). Even when responses, stimuli, and attended stimulus attributes are repeated across trials, repetition benefits are only observed when the abstract task set is repeated as well. For instance, when trial n required responding to a top left circle on a 2 × 2 grid with a right keypress and then trial n + 1 presents the same stimulus and requires the same response, responding is facilitated only when both trials use the same transition rule (e.g., horizontal) but not when they use different transition rules (e.g., horizontal in trial n and clockwise in trial n + 1). This suggests that task sets are integrated into event representations and influence performance beyond the impact of S–R associations.
Why do people represent task sets? An important function of task sets is to shield goals against distraction from irrelevant stimulus features (Dreisbach & Haider, 2008). They determine what stimulus features are attended and which can be ignored. For instance, when subjects have a task set available to categorise stimuli, they are less distracted by semantically unrelated distractors (i.e., distractors that have nothing to do with the current task set) while still being susceptible to distractors that are semantically related to the current task set (Dreisbach & Haider, 2009). This indicates that task sets focus stimulus processing onto the attributes relevant to the current situation. Applied to joint action settings, it might indicate that representing a partner’s task set could draw subjects’ attention to this task set and shield them from interference by alternative task sets.
Generalisation of action–effect associations
Anticipated partner reactions as investigated in the present study are a special form of action effects (Kunde et al., 2018). Thus, when asking whether the task set underlying a partner’s anticipated response will affect task set selection, this is analogous to asking how specific an action–effect representation needs to be to influence performance. Up to date, very little research is available on this question. Hommel et al. (2003) studied the generalisation of action–effect associations in a two-stage action–effect acquisition paradigm (Elsner & Hommel, 2001). A category group learned to associate keypresses with category effects (e.g., left → animal, right → furniture), while an exemplar group learned to associate keypresses with exemplar effects (e.g., left → dog, right → chair). In a subsequent test phase, all subjects performed keypresses in response to category stimuli (i.e., animal and furniture) with mappings that were compatible or incompatible with those used in the acquisition phase. Compatibility benefits were observed even in the exemplar group, indicating that action–effect links generalise to semantically related stimuli. In two additional experiments, Hommel et al. (2003) found that generalisation also occurred across exemplars of the same category and across stimuli that share features but do not belong to the same category. Converging evidence stems from a study in which subjects experienced action effects at different levels of compatibility in a flanker task (Hubbard et al., 2011). Effects either were perceptually identical to the target or were different but would have required the same response if presented as targets. Response latencies were similar in both conditions, and smaller than when effects would have required a different response. In sum, the results suggest that action–effect links can operate on a more abstract level than specific S–R mappings.
Generalisation of action–effect links is not always found. Foeldes et al. (2018) used an action–effect compatibility paradigm (Kunde, 2001) in which subjects uttered words for animals, and these words were followed by compatible or incompatible effect words (i.e., same vs. different animal). In a specific condition, effects were presented in the same language and thus were either identical to the correct or incorrect response. In an abstract condition, effects were presented in another language. Compatibility benefits were restricted to the specific condition. However, before interpreting this result as evidence against a generalisation of action effects, it would be desirable to clarify the role of confounding factors, such as transfer effects between dominant and non-dominant languages (Meuter & Allport, 1999), and to investigate whether subjects actually represented the concepts of words presented in another language. Still, the results show that even when in principle action–effect links might be able to generalise, the conditions for generalisation are not understood sufficiently. Moreover, previous studies have only addressed generalisation as a spread of activation to other stimuli (semantically related or presented in a different format) but not examined whether influences of action effects can operate on more abstract levels of representation (i.e., abstract task sets instead of specific action–effect links).
Present study
The available research suggests that an influence of partner tasks does not necessarily require action co-representation, that task sets in individual action are represented beyond specific S–R mappings, and that action effects can generalise beyond specific action–effect links. Using a social action–effect paradigm, the present study contributes to investigating the hypothesis that a partner’s task set can be represented and affect people’s own performance even when they do not covertly act out his S–R mappings. More specifically, it tests under what conditions the compatibility of anticipated partner reactions facilitates task set selection. Do compatibility benefits only occur when the partner imitates the subject’s actions or also when he applies the same task set to his own stimuli? Three experiments used a version of the picture–word interference paradigm.
In this task, subjects see pictures of objects superimposed with words and either have to name the picture or read the word. Naming pictures is comparably hard because it requires the lexical selection of a name. Accordingly, name selection times are longer for objects that provide several naming alternatives (Lachman, 1973), that are presented while hearing the names of semantically related objects (Schriefers et al., 1990), or that have low-frequency names (Oldfield & Wingfield, 1965). In contrast, word reading is easy because the name is directly presented and reading is a highly overlearned activity. Therefore, in picture–word interference paradigms, picture naming is severely impaired (e.g., Caramazza & Costa, 2000). However, the easy word-reading task can also be affected by the content of concurrently presented pictures. Word reading is subject to interference from previous selection episodes that required naming the picture while ignoring the word (Waszak et al., 2003). This interference becomes apparent when the word-reading task needs to be re-selected, for instance, after a task switch. Picture–word interference has previously been used to investigate the impact of task sets (Dreisbach & Haider, 2009). When subjects used a task set to categorise words (instead of learning them by heart), they were less distracted by pictures that were semantically unrelated to this task set, while still being distracted by pictures that were semantically related to it.
The present study used a version of the picture–word interference paradigm that Müller and Jung (2018) had adapted from Mayr et al. (2014). Subjects alternated between single task blocks of picture naming and word reading. In one half of the experiment, a partner performed the same task as the subject (compatible), and in the other half, he performed the competing task (incompatible). Between experiments, it was manipulated in what way partner reactions were compatible or incompatible with subjects’ actions. In Experiment 1, the partner performed his task on the same stimuli as the subject, while in Experiment 2, he performed it on different stimuli. In Experiment 3, the partner also used different stimuli but the subject’s task was made easier.
Different accounts of how partner tasks are represented, lead to different hypotheses concerning compatibility effects. First, if subjects do not represent anything about the content of the partner’s task, compatibility effects should be absent in all three experiments. This is because accounts that postulate mechanisms free of task content, such as referential coding in terms of spatial dimensions (Dolk et al., 2014) or actor co-representation (Wenke et al., 2011), neither predict an influence of the partner’s specific actions nor his abstract task set. Second, if subjects co-represent the partner’s actions, compatibility benefits should be observed in Experiment 1 because in compatible trials, action co-representation would activate the response required by the subject’s own task, while in incompatible trials, it would activate an incorrect response. Critically, this account predicts no compatibility effects in Experiments 2 and 3, where co-representing the partner’s actions would activate an incorrect response regardless of compatibility. Finally, if subjects represent the partner’s abstract task set without representing his specific actions, compatibility benefits should occur in all three experiments because in compatible trials, representing the partner’s task set would always activate the currently relevant task set.
Experiment 1
The first experiment served as a replication of Experiment 3 by Müller and Jung (2018) with the stimulus material used in the present study. In compatible blocks, following the subject’s response the partner performed the same task, reacting to the same attribute of the same stimulus (e.g., after the subject had read the word, the partner read the same word). Conversely, in incompatible blocks, the partner performed the competing task (e.g., after the subject had read the word, the partner named the picture of the same stimulus). In addition to the main task, an interruption task appeared on the screen after one-fourth of the trials. This task was intended to induce task set selection conflict in post-interruption trials (Mayr et al., 2014). However, the interruption factor did not interact with the other factors in any of the analyses. We cannot explain this absence of interruption effects on task set selection. These effects had been found in several previous experiments (Mayr et al., 2014; Müller & Jung, 2018), and we are not aware of any meaningful differences between Experiment 1 of the present study and Experiment 3 of our previous study. At present, it is unclear whether the absence of interactions with the interruption factor in the present study is a chance finding, and further research is needed. However, for now, it was decided to exclude interruption from the analyses and not discuss it any further in this article.
Subjects were required to attend to the partner’s reactions as they needed to press a key in case of a deviant reaction that occurred in about 10% of the trials. The latter was done because our previous experiments (Müller & Jung, 2018) had suggested that subjects strategically ignored partner reactions in the weaker task. If subjects chose to ignore the partner in the present study, chances would be high that they would not even notice whether he performed the same or a different task in Experiment 2 with only abstract task set overlap.
In our previous study, only a single picture–word combination was presented in each trial. Accordingly, the paradigm could not reveal whether compatibility effects were due to the partner performing the same specific action or the same abstract task because these two factors were confounded. Therefore, in Experiment 1, two stimuli were presented in each trial. The subject’s picture–word combination was located on the left side of the screen, while on the right side, a picture–word combination was presented that was irrelevant in Experiment 1. However, this combination will be used by the partner in Experiment 2, and therefore, it was included in Experiment 1 as well to make sure that the differences between experiments cannot be ascribed to differences in the stimulus material.
Taken together, Experiment 1 attempted to replicate Müller and Jung’s Experiment 3 while using slightly different stimulus material. Only when a compatibility effect of specific partner reactions can be found in this setting, it makes sense to ask whether this effect generalises to situations in which the partner only uses the same task set (Experiment 2). Based on Müller and Jung’s findings, it was hypothesised that compatible partner reactions would lead to shorter verbal reaction times, although this effect should only be present in the stronger word-reading task. No predictions were made with regard to the main effect of compatibility and the interaction of task and compatibility. That is, a compatibility benefit was expected to occur in the word-reading task and not in the picture-naming task, but it was irrelevant for current purposes whether the difference between the two tasks would be either weak enough to leave an overall compatibility effect intact or strong enough to drive an interaction between task and compatibility.
Methods
Subjects
In total, 24 subjects (17 females) from the TU Dresden’s participant pool took part in the experiment in exchange for course credit or €5 per hour. A power analysis was calculated based on the effect size
The experimenter acted as the partner for all subjects. Each experiment was run by one of three experimenters (R.M. and two student assistants). To rule out systematic effects of partner identity, the assignment of partners to the orders of experimental conditions was controlled (i.e., partners performed the different orders equally often) and each partner ran the same condition orders in all three experiments. 2
Apparatus and stimuli
Stimuli were presented on a 19″ monitor with a resolution of 1024 × 768 pixels. Subjects’ speech was recorded with the SR Research Experiment Builder’s voice key (SR Research Ltd., Ontario, Canada). Subjects were seated directly in front of the screen while the partner was sitting to their right side.
Each stimulus screen contained two picture–word combinations presented on a black background, one on the left side and one on the right (i.e., subject’s and partner’s side). A picture–word combination measured 500 × 360 pixels (18.8 × 13.6 cm) and was positioned on the horizontal midline of the screen, with a distance of 8 pixels between them and a distance of 8 pixels to the left and right sides of the screen, respectively. Words were placed centrally in the picture (white font with black outline, Calibri, 32 pt). All pictures and words referred to familiar objects that were easy to name (e.g., apple, bear, and airplane), and words were presented in German and consisted of one to four syllables.
The entire set of picture–word combinations included 672 items, 640 of which were used for subjects. Subjects saw the exact same picture–word combinations used by Müller and Jung (2018). The set contained two subsets of 320 picture–word combinations, and concepts that were pictures in one subset were words in the other. Each experimental session used only one of these subsets so that subjects never saw one and the same concept as both a picture and a word. Presenting a unique picture–word combination in each trial was necessary to make sure the results were not affected by the long-term priming of task sets through their respective stimuli (Waszak et al., 2003). In this paradigm, such stimulus-specific task priming would differ between compatible and incompatible blocks. In compatible blocks, only one stimulus attribute (either picture or word) would have been associated with a task set twice (i.e., once while subjects perform the task and once while they observe the partner perform it), while in incompatible blocks, both stimulus attributes would have been associated with a task once.
The stimulus material was not controlled for potentially important features, such as the number of letters and syllables, the frequency of words, the number of naming alternatives for pictures, or the semantic relatedness between pictures and words. These factors can influence performance in picture–word interference paradigms. Therefore, it was important to make sure that they did not systematically differ between the experimental conditions. This was done by randomly assigning the 320 picture–word combinations to the experimental conditions for each subject individually. In this way, the risk of systematic effects was extremely low.
In addition, 32 new picture–word combinations were constructed, which were irrelevant in Experiment 1 but served as stimuli for the partner in Experiments 2 and 3. They were presented on the right side of the screen. While subjects saw a new picture–word combination in each trial, the same set of 32 combinations was presented on the right side of the screen in each block. This was done because it was impossible to create a whole new set of 640 new concepts which at the same time referred to well-known objects that are easy to name. Also, using only 32 picture–word combinations for the partner and repeating them across blocks ensured that there were no stimulus-specific differences between the experimental conditions because the same stimuli were used in each condition. As the reaction times of the partner were not of interest, it did not matter that this created confounds that make reaction times hard to interpret (which is why no repetitions were used for subjects, see above). Within the set of 32 additional combinations, each concept was used both as a word and a picture, but never at the same time (i.e., all combinations were incongruent). This was done to avoid stimulus-specific effects (e.g., subjects perceive that the partner uses highly salient concepts only as words but not as pictures) because with the low number of just 32 combinations, it cannot be safely assumed that these effects will average out. Again, it did not matter that this created possible confounds for reaction times as the partner’s reaction times were not of interest. None of the pictures and words was ever used for the subject’s tasks.
For the interruption task (see in the following), subjects saw a centrally positioned grid of 3 × 3 grey squares, with each square having a side length of 70 pixels (2.6 cm). The squares contained the digits 1–9 (black font, 30 pt), and their mapping corresponded to that of the number block on a computer keyboard. On clicking one of the squares with the mouse, a purple frame appeared around it and remained visible for 300 ms.
Procedure
Before starting with the actual experiment, subjects performed one practice block of word reading and one of picture naming. Practice blocks were almost identical to the experimental blocks, and the only difference was that during practice, the partner did not participate in performing the task (to avoid practice benefits for a particular compatibility condition). The main function of these practice blocks was to provide subjects with sufficient experience with the two tasks as a prerequisite for strong task set selection conflict (Mayr et al., 2014). The main experiment consisted of eight single task blocks (i.e., picture naming or word reading), the task alternated between consecutive blocks, and half of the subjects started with the picture-naming task, while the other half started with the word-reading task. Compatibility was manipulated between the two halves of the experiment and counterbalanced across subjects. Each block consisted of 32 trials and 8 interruptions, resulting in a total number of 256 trials and 64 interruptions per experiment.
The events within a trial are shown in Figure 1. A trial started with the presentation of a stimulus that included two picture–word combinations next to each other. According to the current block’s task, subjects either had to name the picture or read the word of the left stimulus, while always ignoring the right stimulus. Responses were performed verbally and recorded by voice key. Each correct response of the subject was followed by a partner reaction that was initiated after the subject had finished his utterance (with a delay that the partner aimed to keep constant across conditions, see below). Importantly, in Experiment 1, the partner performed all reactions on the same stimulus element as the subject (i.e., the picture–word combination on the left side of the screen). In compatible trials, this means that she named the same picture or read the same word as the subject. Accordingly, partner reactions were a complete imitation of subjects’ actions. In incompatible trials, the partner performed the currently irrelevant task again on the same stimulus element (e.g., reading the word that the subject just had to ignore).
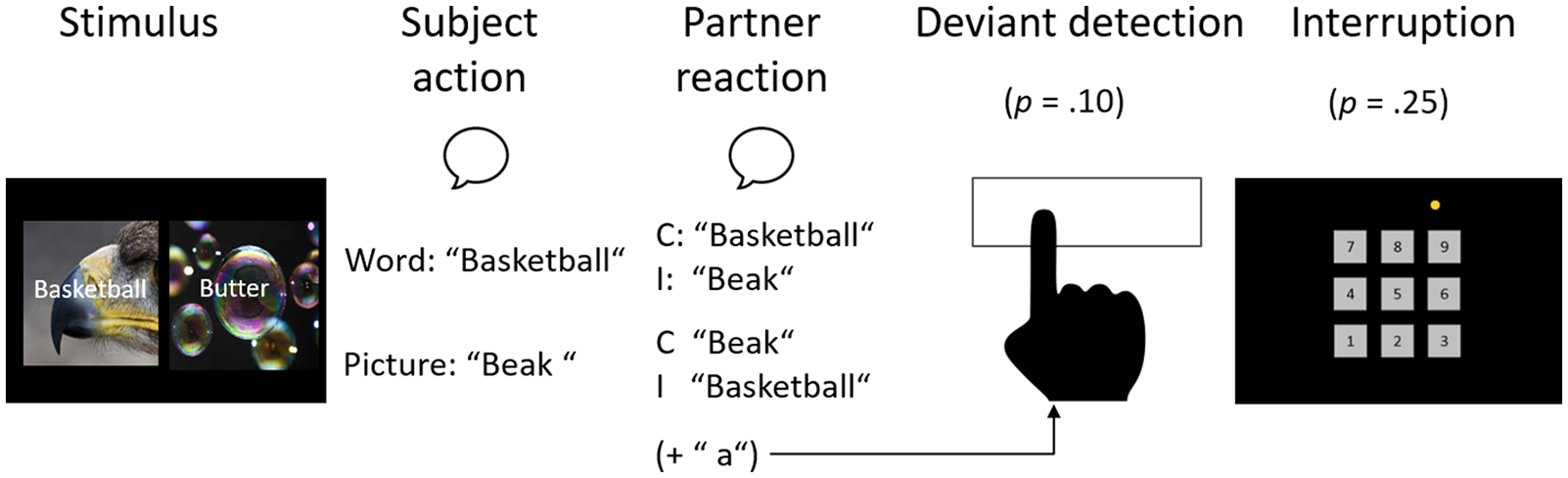
Events within a trial in Experiment 1. In the actual experiment, German instead of English words were used. C = compatible, I = incompatible.
While performing her verbal reaction, the partner pressed a key to manually classify the subject’s response as correct, erroneous, or invalid or to classify the trial as containing a deviant (see below). After this keypress, the stimulus remained on the screen for 1,000 ms in correct standard trials and until the subject’s manual response in deviant trials, and then was replaced by the interruption task or the stimulus for the next trial. Trials were classified as an error when the subject performed the wrong task (e.g., word reading instead of picture naming). In these trials, the partner’s keypress triggered an immediate abortion of the trial and the stimulus screen was replaced by an error message (German word for error) for 2,000 ms. No partner reaction was provided in error trials as such a reaction would necessarily have forced the partner to either commit an error as well (e.g., read the word when she should have named the picture) or to violate the compatibility relations of the respective block (e.g., select the correct task but thereby perform an incompatible reaction in a compatible block). In correct trials, the partner synchronised her keypress with her verbal utterance to provide an estimate of her reaction time. These partner reaction times are not reported in the “Results” section as they cannot provide a reliable measure for two reasons. First, it is unclear how precise the partner was in synchronising her manual actions with her verbal utterances, and second, the partner reaction was calculated from the onset of the subject’s verbal utterance but only initiated after the end of the subject’s utterance, thus depending on word length. However, partner reaction times were analysed between the experimental sessions to make sure they did not systematically vary with the experimental conditions. If they did, the partner compensated for this in the following sessions, creating comparable delays in all conditions.
During the experiment, subjects were made to attend to the partner’s reactions through a secondary task. They were instructed to press the space bar as quickly as possible whenever the partner added the letter “a” to her utterance (e.g., saying “basketballa” instead of “basketball”). Deviants occurred in two to four randomly selected trials per block (9.29%). These trials were selected spontaneously by the experimenter because it was impossible to provide her with a cue. Visible cues on the screen would have been visible for the subject as well, auditory cues could not be applied as the headphones were used by the subject, and endogenous cues in the form of a prospective memory task would have deteriorated the experimenter’s primary task performance. The task was chosen to make sure subjects attended to the partner’s utterances while making it completely unnecessary to know what task she was performing. In this way, the preview benefit gained from attending to the partner’s task (and processing her stimuli in Experiments 2 and 3) was minimised.
The interruption task was presented eight times in each block (p = .25). Its position was selected randomly, with the constraints that interruptions could not occur in two consecutive trials and in the first or last trial of a block. Interruptions were completely unrelated to the main task but required attention to the partner. Subjects had to watch the partner click a random four-number sequence on a number block on the screen, and subsequently type the same sequence with the number block of their keyboard. When the partner clicked one of the numbers, a purple frame was drawn around it and remained on the screen for 300 ms to enhance the visibility of the clicks. Subjects could start entering their sequence once the partner had clicked her last number. If subjects made an erroneous keypress, the interruption task was aborted. An error message appeared for 2,000 ms and then the next trial started.
Results
Subjects’ verbal reaction times were computed, as the time difference from stimulus onset to the triggering of the voice key, and were statistically compared between the experimental conditions. Initial ANOVAs, including the factors task, trial type, and compatibility, revealed that there were no interactions of trial type (maintenance, post-interruption) with compatibility in any of the experiments, all Fs < 1. Therefore, the factor trial type was dropped from all subsequent analyses to give the article a stronger focus. Accordingly, mean verbal reaction times were analysed with a 2 (task: picture naming, word reading) × 2 (compatibility: compatible, incompatible) repeated measures ANOVA. All pairwise comparisons were performed with Bonferroni correction. The first trial within a block, trials in which the voice key did not trigger correctly, trials in which subjects produced task-irrelevant utterances, erroneous trials (i.e., performing the currently irrelevant task), trials following an error, and trials with reaction times exceeding 3,000 ms were excluded from the analysis (22.45% of the data). 3 Hardly any errors were committed (.19%, 13 errors across all 24 subjects), and therefore, error rates were not analysed.
There was a main effect of task, F(1, 23) = 583.294, p < .001,
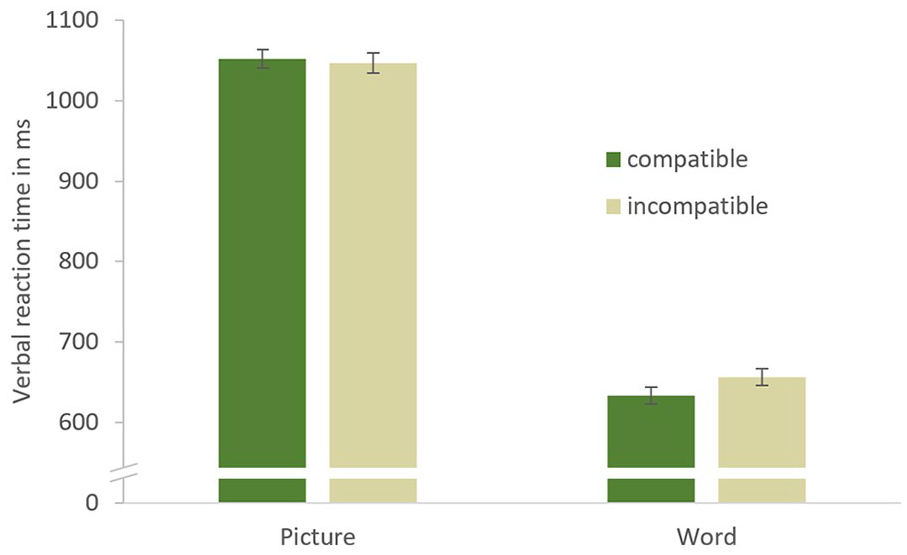
Verbal reaction times in Experiment 1, depending on task and compatibility. Error bars represent standard errors of the mean corrected for within-subjects comparisons (Morey, 2008).
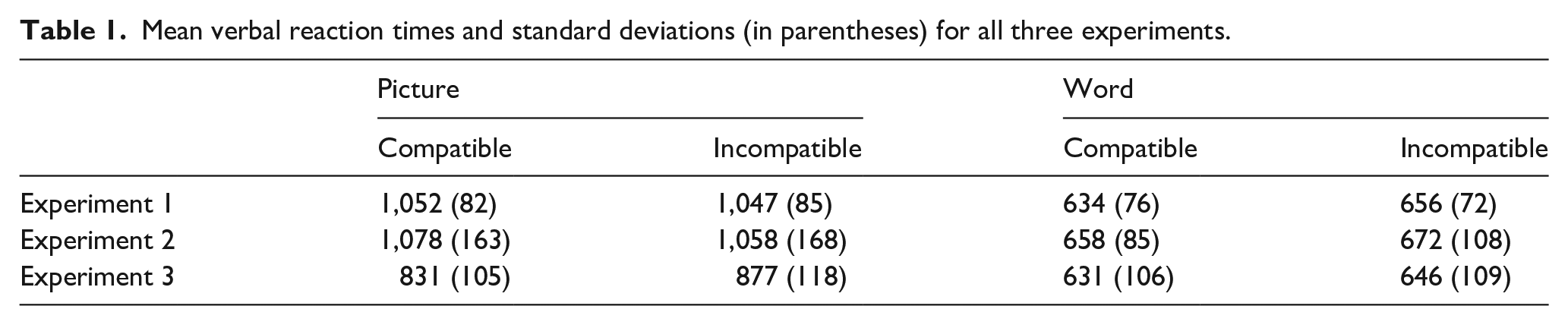
Mean verbal reaction times and standard deviations (in parentheses) for all three experiments.
Discussion
Experiment 1 attempted to replicate our previous findings (Müller & Jung, 2018, Experiment 3) with the stimulus setup to be used in Experiments 2 and 3. In line with the previous results, verbal reaction times in the stronger word-reading task were shorter in compatible than in incompatible trials, reflecting a compatibility benefit. There was no main effect of compatibility, and the interaction of compatibility and task just reached significance. These results can be traced back to the absence of compatibility effects in the weaker picture-naming task. This difference between task types and the possible reasons for it were examined in detail in our previous study (Müller & Jung, 2018) and thus are not discussed here.
The experiment revealed that when the partner’s reaction is a complete imitation of subjects’ actions and thus overlaps with them in specific stimulus and response features, task set selection is facilitated. This cannot be explained by accounts denying that the contents of partner tasks are processed. Task-irrelevant features of the partner (e.g., spatial position) cannot have influenced responding as responses were neither distinguished spatially nor by any other grouping feature. Instead, each stimulus required a unique verbal response. Moreover, there was no overlap of low-level features between the two participants that could explain the results. Their responses had plenty of task-irrelevant overlapping features (e.g., verbal, nouns, German) and distinctive features (e.g., voice) but none of them varied with compatibility. Therefore, it is unclear how a difference between compatible and incompatible blocks could be explained without considering the contents of a partner’s task. However, the results are in line both with accounts assuming co-representation of the partner’s actions and with accounts assuming that only the partner’s abstract task is represented. To differentiate between these options, Experiment 2 investigated whether compatibility effects also occur when only the abstract task set is compatible.
Experiment 2
In Experiment 2, the exact same stimulus material and procedure were used as in Experiment 1, with the only difference being that the partner now performed the tasks on her own stimuli, which were presented on the right side of the screen. Thus, while partner reactions could either be compatible or incompatible with those of the subject in terms of task set, the low-level features never coincided.
If compatibility benefits rely on a specific match between low-level action features (i.e., require complete imitation), compatibility should not have any effects in Experiment 2. Instead, if a match of the partner’s abstract task set is sufficient to facilitate task set selection, Experiment 2 should replicate the results of Experiment 1—compatibility benefits should emerge in the word-reading task. Again, no compatibility effects were expected in the picture-naming task, but it is irrelevant for current purposes whether differences between the two tasks suppress the main effect of compatibility or are strong enough to drive an interaction of task and compatibility.
Methods
Subjects
In total, 24 subjects (23 females) from the TU Dresden’s participant pool took part in the experiment in exchange for course credit or €5 per hour. Their age varied between 18 and 57 (M = 25.5, SD = 9.7) years, and all were native German speakers. One subject was replaced due to reaction times more than three standard deviations above the mean of the others. Like in Experiment 1, the role of the partner was taken by the experimenter and the assignment of condition orders to partners was controlled.
Apparatus and stimuli
The apparatus and stimulus material was identical to that of Experiment 1.
Procedure
The procedure was identical to that of Experiment 1, with the exception that the partner now performed her tasks using the 32 picture–word combinations presented on the right side of the screen. Again, subjects were made to attend to the partner’s verbal utterances (but not her stimuli or task set) as they had to press the space bar when the partner added an “a” to the end of her utterances, which occurred in 9.47% of the trials, selected randomly.
The partner used the same 32 picture–word combinations in each block. A disadvantage of this is that each stimulus gets associated with different tasks, which can lead to long-term priming effects (Waszak et al., 2003). When perceiving a stimulus again, it will activate the task set that had previously been associated with it. If such priming generalises to partner reactions, it is possible that perceiving a partner’s stimulus again will activate the task set that the partner had previously performed on it, resulting in interference with the subject’s own task. However, due to the alternating block sequence, subjects experienced both tasks with each partner stimulus early on and equally often. Thus, while it cannot be ruled out that subjects learned to associate specific partner stimuli with the partner’s task set, such associations should be equally strong for both tasks.
Results
Mean verbal reaction times were analysed with a 2 (task: picture naming, word reading) × 2 (compatibility: compatible, incompatible) repeated measures ANOVA. All pairwise comparisons were performed with Bonferroni correction. Exclusion criteria were the same as in Experiment 1 and led to an exclusion of 23.78% of the data. Again, error rates were very low (.36%) and therefore were not analysed.
The main effect of the task was highly significant, F(1, 23) = 317.675, p < .001,
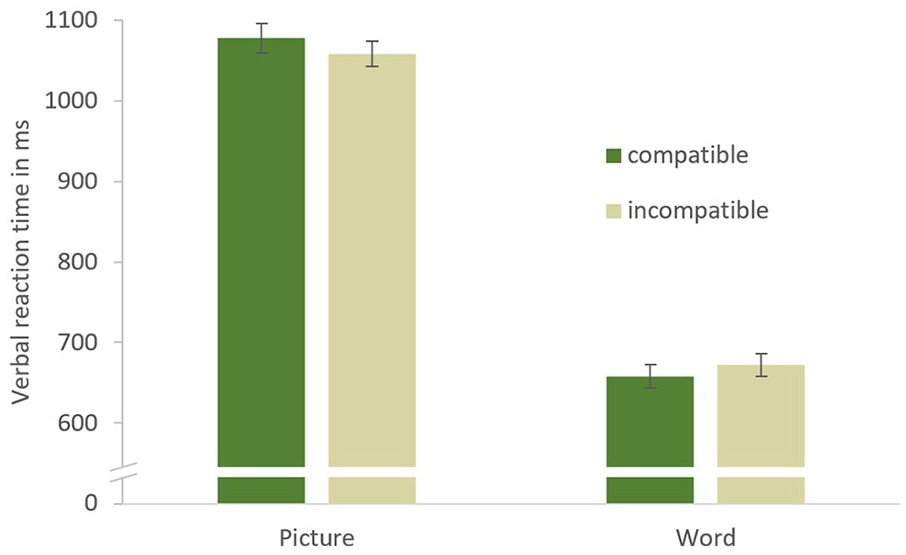
Verbal reaction times in Experiment 2, depending on task and compatibility. Error bars represent standard errors of the mean corrected for within-subjects comparisons (Morey, 2008).
Discussion
Does the compatibility of anticipated partner reactions facilitate task set selection when only the partner’s abstract task set matches that of the subject, while the specific S–R mappings differ? The present results do not support this assumption. There neither was a main effect of compatibility nor an interaction of compatibility and task. More importantly, no compatibility effects were observed in the word-reading task, which is where they would have been expected if a match of the partner’s task set influenced subjects’ own task set selection. This result appears incompatible with an account assuming that the partner’s abstract task is represented and compatible with an action co-representation account. The latter does not predict compatibility effects in this setup because co-performing the partner’s response selection would activate an incorrect response in compatible and incompatible trials alike.
However, before concluding that the compatibility of partner reactions at the level of tasks sets is non-consequential, an alternative explanation needs to be considered. Any effects of compatibility might have been prevented by the excessive task difficulty that resulted from using a new picture–word combination in each trial. High task difficulty can eliminate the influence of action effects (Müller & Jung, 2018). Moreover, a similar concern has been raised by Liefooghe (2016) who suggested that the absence of partner influences in turn-taking paradigms with two tasks might be due to excessive demands. While he referred to the demands associated with representing two task sets and monitoring two types of cues, in the present study, task demands resulted from the need to process a new stimulus in each trial.
This alone cannot explain why compatibility effects were found in Experiment 1 but not in Experiment 2 as both experiments used the same stimulus material—and in fact, the similar reaction times suggest that task difficulty had been similar (see Table 1). However, in Experiment 1, the action effects (i.e., partner reactions) had been more salient as they were directly related to the subjects’ specific actions and not just to their abstract task sets. It is possible that in Experiment 2, task difficulty was too high in relation to the weak action effects, so that subjects had insufficient capacity to process these effects. In other words, when action effects get weaker, the task must become easier for them to remain effective. That is, to study the effects of a partner’s abstract task set, it is important to make sure that the main difficulty lies in selecting the appropriate task and not in identifying a new picture or word in each trial. Therefore, in Experiment 3 the task was made easier by reducing the number of stimuli.
Experiment 3
Experiment 3 attempted to reduce task difficulty by reducing the number of picture–word combinations that subjects needed to process. Just like the partner in Experiment 2, subjects in Experiment 3 saw only 32 picture–word combinations that were used once per block and repeated across blocks. Such a reduction of the stimulus set would not be possible in a low-level overlap condition, such as Experiment 1, because it would lead to systematic differences in stimulus processing between compatible and incompatible blocks (see “Procedure” section of Experiment 1). However, with only abstract task set overlap, this reduction is possible because the partner does not use subjects’ stimuli.
If the results of Experiment 2 represented a general constraint and compatibility benefits were impossible when only the partner’s abstract task set overlaps with that of the subject, Experiment 3 should not find any influences of compatibility, either. Instead, if the absence of compatibility effects in Experiment 2 was a consequence of the task being too difficult in relation to the weak action effects, Experiment 3 should reveal compatibility benefits. In this setting, compatibility benefits were not only expected for the stronger word-reading task but also for the weaker picture-naming task. This is because the reduction of subjects’ stimulus set was expected to mainly affect the picture-naming task, making it much easier as subjects do not have to search a name for a new picture in each trial anymore but can simply retrieve this name from their memory about previous trials. These direct associations between pictures and names should reduce the asymmetry between tasks. In our previous research (Müller & Jung, 2018, Experiment 4), we found that when task asymmetry is reduced, compatibility effects are present in both tasks.
Methods
Subjects
In total, 24 subjects (20 females) from the TU Dresden’s participant pool took part in the experiment in exchange for course credit or €5 per hour. Their age varied between 18 and 48 (M = 24.1, SD = 6.5) years, and all were native German speakers. One subject was replaced due to reaction times more than 3 SD above the mean of the others. Like in Experiments 1 and 2, the role of the partner was taken by the experimenter and the assignment of condition orders to partners was controlled.
Apparatus and stimuli
Subjects only saw 32 picture–word combinations. These were selected according to the criterion that they did not cause picture-naming difficulties in the previous experiments. The partner’s stimulus material was identical to that used in Experiment 2.
Procedure
The procedure was identical to that of Experiment 2, with the following exception. While subjects saw a unique picture–word combination in each trial of a block, combinations were repeated across blocks. The order in which subjects’ stimuli were presented in each block was randomised independently from that of the partner to make sure that subjects could not form associations between their own stimuli and those of the partner. Just like in the previous experiments, subjects were required to attend to the partner’s utterances as they had to detect deviants occurring in 9.58% of the trials.
Results
Mean verbal reaction times were analysed with a 2 (task: picture naming, word reading) × 2 (compatibility: compatible, incompatible) repeated measures ANOVA. All pairwise comparisons were performed with Bonferroni correction. Exclusion criteria were identical to those from Experiments 1 and 2 and resulted in an exclusion of 24.42% of the data. Error rates were very low (.59%) and therefore were not analysed.
Again, there was a main effect of task, F(1, 23) = 293.108, p < .001,
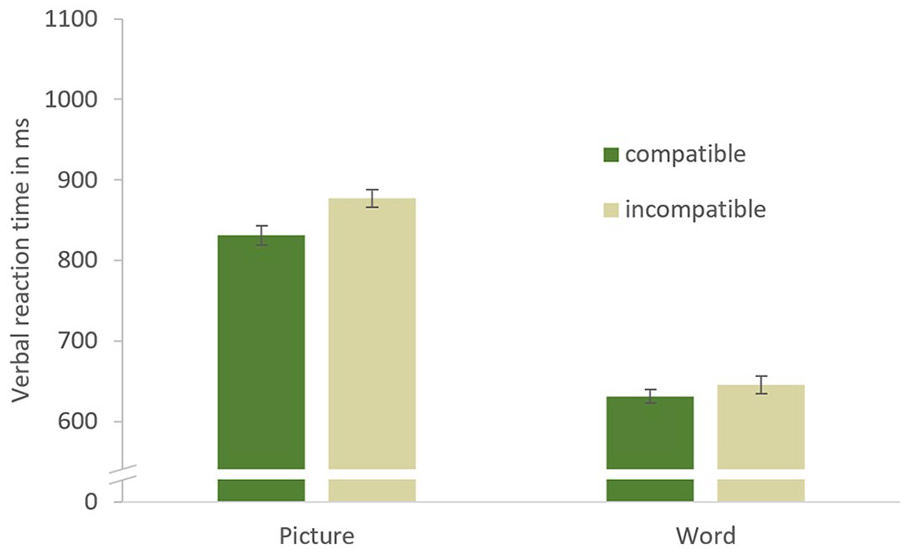
Verbal reaction times in Experiment 3, depending on task and compatibility. Error bars represent standard errors of the mean corrected for within-subjects comparisons (Morey, 2008).
Discussion
Experiment 3 investigated whether the compatibility of anticipated partner reactions on the abstract level of task sets can influence task set selection processes when conditions are more favourable than in Experiment 2. Therefore, subjects’ stimulus set was held constant across blocks to reduce task difficulty and give the weak action effects (i.e., partner reactions) a realistic chance to influence task set selection. A main effect of compatibility indicated that compatibility can affect task set selection even when it is not defined with regard to low-level action features but merely encompasses the partner’s abstract task set. This issue will be taken up again in the “General Discussion.”
Contrary to the hypotheses and our previous findings (Müller & Jung, 2018), compatibility benefits were restricted to the weaker picture-naming task. In fact, compatibility effects in this task had been expected in Experiment 3 as a consequence of reduced task asymmetry. However, compatibility benefits had also been expected to remain stable in the word-reading task, which clearly was not the case. How to account for this puzzling result? A first possibility is that using the same stimuli in each block might have made word reading too easy, which in some circumstances can eliminate compatibility effects (Wolfensteller & Ruge, 2014), namely when response selection is circumvented. However, a closer look at the data refutes this possibility as reaction times in the word-reading task of Experiment 3 were comparable to those in Experiment 1 where compatibility effects were observed (638 and 645 ms, respectively), and a mean reaction time of more than 600 ms certainly does not indicate that response selection was circumvented. A more plausible explanation is that with picture naming becoming much easier, word reading became harder (in relative terms) as it was affected by between-task conflict more strongly. When a picture strongly primes the naming task as a consequence of memory retrieval from previous trials, word reading gets harder than it would have been without such interference (Waszak et al., 2003).
This explanation is supported by the results summarised in Table 1, which show almost no reaction time decrease for word reading in Experiment 3 relative to the other two experiments. Accordingly, word reading was not facilitated by the reduction of the stimulus set, and at the same time, the action effects (i.e., partner reactions) remained as weak as they had been in Experiment 2. Accordingly, there is no reason why the influence of these action effects on word reading (or the lack thereof) should change. That said, compatibility benefits restricted to the weaker task are inconsistent with all results from several of our previous experiments and thus should be interpreted cautiously and replicated before drawing conclusions.
Another aspect to consider when comparing Experiments 3 and 1 is that they created somewhat different situations for subjects. In Experiment 1, subjects did not only perform a unique action but also experienced a unique partner reaction in each trial. Experiment 3 used a limited set of stimuli for subjects as well as the partner, and thus, subjects experienced the same partner reactions repeatedly. In consequence, partner reactions might have become more familiar, which might either have increased or decreased their salience and thereby changed their impact in unknown ways. As explained before, it is not possible to make Experiment 1 more similar to Experiment 3 by using the same stimuli in each block. An alternative would be to make Experiment 3 more similar to Experiment 1. This could be done by letting subjects use the same stimuli in each block to keep task difficulty low but have the partner use a different picture–word combination in each trial. However, as a direct, quantitative comparison between Experiments 1 and 3 is not a focus of the present study, such an experiment was not conducted.
General discussion
Do people represent the tasks they expect a partner to perform? By what mechanisms do partner tasks affect task set selection? Three experiments investigated the specificity or abstraction of partner task representation in a picture–word interference paradigm. Subjects performed alternating single task blocks while a partner responded to subjects’ actions by performing either the same or the competing task. Experiment 1 replicated our previous paradigm and results (Müller & Jung, 2018, Experiment 3), revealing compatibility benefits in the stronger word-reading task. However, the partner’s performance of the same task in compatible blocks also implied a match between the subject’s and partner’s specific S–R mappings: the partner fully imitated subjects’ actions. Experiments 2 and 3 went a step further to determine whether such specific matches are necessary to bring about the benefits of compatible partner reactions. In these experiments, the partner performed the same or competing task but used different stimuli and produced different responses. Experiment 2 revealed no evidence for compatibility benefits in either task. To test whether this meant that an overlap restricted to abstract task sets is inconsequential, Experiment 3 attempted to reduce task difficulty through a smaller stimulus set. Compatibility benefits were found, although only in the picture-naming task. Taken together, the results replicate previous findings that a partner’s anticipated task set can facilitate task set selection when it matches the subject’s task set (Müller & Jung, 2018) and extend these findings by showing that at least under some circumstances, this also holds without an overlap of S–R mappings. This suggests that representations of the partner’s forthcoming task set are formed and contribute to the selection of a person’s own task set. The following sections first discuss the present results in the light of different accounts for representing a partner’s task in joint action, compare them to previous findings, and finally relate them to the literature on action–effect anticipation.
Mechanisms underlying the influences of a partner’s task set in joint action
Some accounts of joint action assume that people co-represent the partner’s actions and thus co-perform his response selection process (e.g., Baus et al., 2014; Demiral et al., 2016; Dudarev & Hassin, 2016; Kuhlen & Abdel Rahman, 2017; Sebanz et al., 2003), while alternative accounts suggest they do not and instead provide alternative explanations for seemingly social phenomena that do not assume people to represent the contents of a partner’s task (Dolk et al., 2014; Liepelt et al., 2012; Wenke et al., 2011). Recently, intermediate accounts have emerged which suggest that the content of a partner’s task is represented but not necessarily on the very specific level of S–R mappings (Böckler et al., 2012; Gambi et al., 2015; Sellaro et al., 2020). Instead, these accounts assume that a partner’s performance of a certain task draws attention towards or away from task-specific dimensions of conflict stimuli. The results of the present study, particularly the compatibility benefits observed in Experiment 3, are in line with such intermediate accounts. Subjects seem to represent the partner’s abstract task set, which facilitates task set selection when it matches the subject’s own task set and creates selection conflict when it does not match.
Complex or abstract?
Some accounts of task set representation in individual and joint action assume that task sets are integrated into event representations, together with low-level features of the stimuli and responses (Hazeltine & Schumacher, 2016; Mayr & Bryck, 2005; Prinz, 2015; Schumacher & Hazeltine, 2016). That is to say that event representations are assumed to be quite complex and presumably hierarchical. Conversely, in explaining the present compatibility effects, we do not assume any complex representations of the partner’s actions (e.g., compound representations of the partner’s S–R mappings in relation to his task set). Rather, we suggest that subjects merely represent the type of a partner’s task instead of his S–R mappings. Thus, the way in which our current explanation differs from some previous accounts of co-representation is in terms of abstraction rather than complexity.
Generality of accounts
Is this selection conflict account likely to replace previous accounts and explain all joint action phenomena that so far have been attributed to action co-representation or representations free of task content? Of course not. In using a within-trial conflict paradigm, the present study created a very specific situation—one in which it would be highly counterproductive to co-represent the partner’s actions, and in which, at the same time, the partner’s incompatible reactions were in conflict with the subject’s task as they corresponded to a stimulus dimensions that strongly competed for attention. Thus, it might well be that under different conditions, people do in fact co-represent a partner’s actions. For instance, joint cumulative semantic interference (Kuhlen & Abdel Rahman, 2017) is hard to explain without assuming that people covertly name the partner’s pictures because in these paradigms, very specific contents of the partner’s stimuli and responses affect subjects’ performance. Presumably, this can neither be explained by accounts free of task content nor by the present account that merely assumes a representation of the partner’s abstract task set.
Therefore, the intended contribution of the present study is not to settle the general argument of whether people do or do not co-represent a partner’s actions by co-performing his response selection or whether they do or do not experience selection conflict due to a partner’s task set. Instead, we want to emphasise that the mechanisms underlying joint action can be much more varied and situation-specific than a decision of whether people do or do not co-represent contents from a partner’s task. The implication of the present study is just that action co-representation may not always be necessary to explain joint action phenomena. Sometimes more deflationary accounts can do, even without denying all representation of the partner’s task content. Thus, an interesting challenge for future research is to better understand the situational factors determining the influences from a partner’s task set. In the following sections, some initial suggestions are provided.
Comparing the present results to studies using two task sets
Previous studies using two tasks instead of sharing a single task have found little evidence for influences of a partner’s task (Liefooghe, 2016; Saunders et al., 2017; Wenke et al., 2011; Yamaguchi et al., 2017b). Which differences between the present study and other studies can account for this divergence in results? One is that this study used a more direct measure than switch costs after no-go trials. The latter rely on response processes (Schuch & Koch, 2003) and it is questionable whether covertly co-representing a partner’s actions can be a sufficient replacement for actually responding. Thus, in this study, influences of a partner’s task might have been easier to detect than in some previous studies. A related difference is that this study made it easier for subjects to attend to the partner using a blockwise manipulation of compatibility. Unpublished research from our laboratory has shown that influences of a partner’s anticipated task set were absent in a task switching paradigm. Thus, perhaps it is not just the number of tasks that determines whether people are influenced by the partner’s task set but also the possibility to monitor the partner and strategically adjust the processing of his actions. In line with this demand-related suggestion, even turn-taking paradigms with two tasks can reveal influences of a partner’s task when making the situation easier by using shared effects (Yamaguchi et al., 2017a). An explanation related to task demand also is in line with this study not finding partner influences in the picture-naming task of Experiment 1 but then finding them when the task was made easier in Experiment 3. Taken together, detecting influences of a partner’s task set seems to presuppose that sufficient resources are available for partner monitoring (for a related argument, see Liefooghe, 2016).
Moreover, most other studies used partner actions that were either hard to perceive and differentiate (i.e., keypresses) or completely impossible to perceive (i.e., remote or ostensive partners). The present study could use overt and easily perceivable partner reactions as they only occurred after the subject had already emitted his response and thus they could not disrupt responding. However, a consequence is that finding influences of the partner’s task set might have been comparably easy in the present study as subjects could easily monitor which task the partner was performing by listening to his verbal utterances. Taken together, the present study probably created a situation highly favourable for partner task monitoring.
Comparing the present results to other studies supporting task selection accounts
The notion that people represent a partner’s task without co-representing his actions and co-performing his response selection process has been put forward before (Böckler et al., 2012; Gambi et al., 2015; Sellaro et al., 2020). However, while reaching the same general conclusion, two of these studies found effects that at first glance seem opposite to the present results. Instead of compatibility benefits, they found benefits when the partner performed a conflicting task (Sellaro et al., 2020) or costs when he performed the same task (Gambi et al., 2015). A possible reason for these differences is that the conflict created by the stimuli, the partner’s responses, and the tasks was lower than in the present study.
First, in both studies, the stimulus material had much less potential to create interference. They either used two different pictures instead of picture–word combinations (Gambi et al., 2015) or picture–word combinations with the words printed in alternating upper and lower case letters, making them harder to read (Sellaro et al., 2020). Indeed, without such degradation (and thus in a condition more similar to the present study), Sellaro et al. found no benefits of the partner performing the competing task. Second, no partner was actually present and subjects were only informed that a person in another room would take care of the conflicting task (Gambi et al., 2015) or concurrently perform the picture-naming task, no task, or an unrelated task (Gambi et al., 2015). In contrast, subjects in the present study were confronted with highly salient verbal utterances by the partner in each trial. Presumably, in a situation where subjects do not ever experience the partner performing the competing task, interference from his performance of this task is not particularly strong. Third, task set selection conflict is likely to have been lower. In both studies, subjects only performed one and the same task (i.e., picture naming) throughout the experiment. This is important as a large proportion of conflict effects stems from a retrieval of previous episodes of selecting the other task (Mayr et al., 2014). With lower selection conflict, conflicting partner reactions are likely to play a smaller role.
Overall, it is hard to compare the results of these two studies to the present ones because they either did not include a condition with the partner performing the same task (Sellaro et al., 2020) or performing a competing task (Gambi et al., 2015). Instead, both studies compared their results to performance in an unrelated task using the same stimuli (i.e., colour classification or semantic categorization of pictures). Interestingly, Gambi et al. found lower interference in this condition than when the partner performed the same task as the subject. It would be interesting to explicitly contrast performance of an unrelated task with the compatible condition of the present study. While compatibility benefits would support the account proposed here (i.e., activation of the relevant task set), compatibility costs might indicate that increased partner monitoring for related tasks impedes subjects’ own task processing.
So far, only one study using a conflict paradigm seems sufficiently similar to the present study in most of the attributes discussed above. In a joint Navon task, Böckler et al. (2012) observed interference from a partner performing the competing task but no evidence for action co-representation. In summary, the latter finding seems quite common in conflict paradigms, but the direction and size of effects are likely determined by subtle differences in the experimental setups. It will be an interesting challenge for future research to investigate the exact determinants of such differences to better understand the mechanisms underlying a task set selection account of co-representation.
Action effects in social and non-social settings
The role of feature overlap
Are task set compatibility effects driven by the same mechanisms responsible for standard action–effect compatibility phenomena? The latter are assumed to result from dimensional overlap between the features of an action and its effects (Hommel et al., 2001). However, the partner reactions in all of the present experiments and in the experiments by Müller and Jung (2018) differed from previous studies’ action effects (e.g., Janczyk et al., 2015; Kunde, 2001; Pfister, Janczyk, et al., 2014) and partner reactions (e.g., Müller, 2016; Pfister et al., 2013) in that our subjects had no chance to associate these partner reactions (i.e., social action effects) with any specific action. Thus, compatibility effects cannot be explained by a formation of links between the low-level features of a previously performed action and low-level features of a previously encountered effect.
Dimensional overlap might still explain the observed influences of task set compatibility, assuming that task sets are integrated into event files as just another feature in individual performance (Hazeltine & Schumacher, 2016; Mayr & Bryck, 2005; Schumacher & Hazeltine, 2016) and joint action (Prinz, 2015). Following this argument, a match between a person’s own task and the partner’s task can create dimensional overlap just like low-level event features do. Consequently, compatibility effects can emerge even in the absence of low-level feature matches. It becomes easier to select a task set when it is primed by the task of the partner forming one feature of event anticipations.
In that sense, the present results contribute to answering the question whether action–effect links can generalise and are in line with previous findings of generalisation to semantically related effects (Hommel et al., 2003; Hubbard et al., 2011). At the same time, they add a new aspect to the generalisation of action–effect representations. Previous research on this topic has compared identical action effects either to action effects that were conceptually different but related semantically (Hommel et al., 2003) or related by means of a shared response (Hubbard et al., 2011), or to action effects that were conceptually identical but presented in a different format (Foeldes et al., 2018; Koch & Kunde, 2002). In contrast to all previous studies, in Experiment 3, the responses’ semantics did not play any role and yet task set compatibility effects were observed, pointing to another form of generalisation that has not received much empirical attention so far.
Anticipation or carryover of activation
The present paradigm was motivated by research on the impacts of compatible action effects on individual action planning (Kunde, 2001, 2003; Kunde et al., 2004; Pfister, Janczyk, et al., 2014) and joint action (Kunde et al., 2018; Müller, 2016; Pfister et al., 2013). However, effect anticipation is not the only mechanism that can explain the compatibility effects observed in the present study. This is because the paradigm cannot differentiate between an anticipation of a partner’s forthcoming task and the experience of his task performance in previous trials. All three experiments used single-task blocks, and thus, in compatible blocks, subjects always experienced the partner performing the same task in the previous trial as well. Consequently, remaining activation might facilitate task set selection in the current trial, without any need for anticipation. There is compelling evidence for the impact of remaining activation carried over from previous trials (Allport et al., 1994; Altmann, 2005; Kikumoto et al., 2016; Ruthruff et al., 2001). This option is especially likely in the abstract conditions of Experiments 2 and 3, because in the absence of stimulus and response overlap, there is nothing that links a subject’s action to the following partner reaction in the current trial any more strongly than linking it to the partner reaction in the previous trial (except perhaps the fact that both picture–word combinations are presented on the same screen and reactions are temporally closer).
While it is plausible that compatibility effects are at least partly influenced by previous compatibility, our earlier results (Müller & Jung, 2018) make it unlikely that this can fully explain compatibility effects as they were strongest in trials following an interruption. In such post-interruption trials, the previous trial is temporally separated from the subject’s action by an intervening secondary task. Accordingly, carryover of activation from the previous trial should be diminished instead of increased. In the present experiments, the interruption factor did not interact with compatibility effects, but this also means that it did not diminish them, which would be expected from an explanation merely based on carryover of activation. A related alternative explanation is that the compatibility of an entire block drove compatibility effects. In principle, this explanation holds for all experiments manipulating the compatibility of action effects between blocks (e.g., Kunde, 2001, 2003; Kunde et al., 2002). However, it has been shown that compatibility effects also emerge when compatibility is manipulated between trials (Pfister, Janczyk, et al., 2014). Whatever the role of anticipation versus carryover, it is not critical with regard to the aim of the present study. Even an account based on carryover would be consistent with the assumption that two people’s task sets mutually influence each other.
Conclusion and outlook
The present results suggest that the task set underlying a partner’s reaction influences subjects’ task set selection process. A particularly critical test of the limits of this account would be to have partners perform a different task while using the same stimuli and responses as the subject. In individual performance, it has been shown that changes in task set reduce or eliminate the benefits of stimulus and response repetitions (Dreisbach & Haider, 2008; Schuch & Koch, 2004) even when the task is performed on the same stimulus attribute (Mayr & Bryck, 2005). In the context of partner reactions, such procedures would make it possible to pit the compatibility of specific actions against the compatibility of abstract task sets and manipulate both factors independently. For instance, in the picture–word interference paradigm, the stimulus attributes to be used by the partner could be flipped around relative to those used by the subject (e.g., the concept presented as a picture for the subject could be a word for the partner, and thus, the partner would produce the same response despite performing the competing task). This would require presenting the partner’s stimulus only after subjects have already uttered their response because otherwise subjects could simply perform the easier task on the partner’s stimulus (i.e., reading the partner’s word instead of naming their own picture).
Another interesting issue for future research is whether compatibility effects are driven by an anticipation of being imitated in compatible trials or an anticipation of the partner performing the conflicting task set in incompatible trials. The first option is supported by the finding that non-helpful, incompatible action effects can strategically be ignored and thus do not impair performance relative to neutral effects (Hommel, 2004). However, the literature on cognitive control and task switching provides evidence for the disruptive influence of competing task sets on task set selection, suggesting that in the context of joint action, incompatible partner tasks should not yet be ruled out as an influence on a person’s own task performance.
Footnotes
Acknowledgements
The author thanks Stefanie Hillig and Susanne Jaster for assistance in data collection.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.