
Abstract
Background:
Effective patient education materials on prehabilitation are essential for optimising patients before surgery. With the growing use of generative artificial intelligence (AI) chatbots in health care communication, it is important to evaluate their suitability compared with established human-generated resources. We aimed to compare patient education materials on prehabilitation, generated by artificial intelligence chatbots (ChatGPT-4o, Gemini 2.5, and DeepSeek V3) with a National Health Service leaflet, assessing factual accuracy, readability, and emotional tone.
Methods:
A comparative observational study design was used. All four patient education materials were blinded and evaluated by ten experts using a 10-point Likert-type scale. Readability was assessed using the Flesch Reading Ease and the Flesch-Kincaid Grade Level. Sentiment analysis was done using an online tool. Patient Education Materials Assessment Tool for Printable Materials (PEMAT-P) scores were calculated.
Results:
National Health Service patient education material showed the highest mean ± SD accuracy scores 9.8 ± 0.3 from experts outperforming all artificial intelligence models (p = 0.000). Among artificial intelligence, Gemini scored highest. For readability, ChatGPT and the National Health Service were comparable. Sentiment analysis showed varying tones across all models. Patient Education Materials Assessment Tool for Printable Materials scores showed high understandability across all patient education materials (>75%), but actionability was highest for the National Health Service (93.3%).
Conclusion:
Artificial intelligence chatbots can generate readable and promising patient education materials. Traditional materials remain superior in accuracy and completeness. A hybrid ‘human-in-the-loop’ approach is recommended for effective patient education.
Keywords
Introduction
Prehabilitation is an important part of perioperative care before major surgery and anaesthesia, particularly within oncological surgeries, aiming at optimising patients’ functional status prior to major intervention. Effective patient education is key to prehabilitation, helping patients to understand and actively engage in preparation for surgery and anaesthesia (Moran et al 2016, Silver 2015).
Usually, such information is given through institutionally made patient information materials (PEMs), which are trustworthy and detailed but can present limitations such as static content, difficult to read, and lack of personalisation (AlSammarraie & Househ 2025, Hunt & McGrath 2016, Papadakos et al 2021).
The recent advances in generative artificial intelligence (AI) chatbots have begun to change how patient information can be shared. AI-driven platforms can rapidly make complex medical guidance into easy and understandable language, making the information easier and interactive (Esteva et al 2019). Some early studies in other areas of health care show that AI-generated materials might be as good as traditional PEMs, in how easy they are to read, and how well they connect with patients. AI has the ability to boost accuracy, cut costs, and save time and is transforming health care. AI is being used in personalised medicine and for managing population health; it even helps create health guidelines and provide virtual and mental health support. This technology also enhances patient education and improves trust between patients and physicians. However, there are still concerns about whether the AI information is always accurate, complete, and reliable, especially when it comes to important and detailed topics like prehabilitation before surgery (Alowais et al 2023, Goodman et al 2023).
With the continuous advancement in digital health tools, there is a need for systematic evaluation of AI-generated educational materials in direct comparison to existing traditional PEMs. This study aims to comprehensively compare PEMs generated by leading generative AI models with the National Health Service (NHS), focusing on factual accuracy, readability, emotional tone, understandability, actionability, and overall suitability for the prehabilitation. Through blinded expert reviews and standardised assessment tools, we want to evaluate the strengths and limitations of each approach, guiding the integration of novel technologies into patient-centred perioperative education.
Methodology
Study design
A comparative observational design was used to systematically evaluate PEMs on prehabilitation for cancer surgery, focusing on traditional NHS-authored materials versus AI-generated content. The aim was to assess and compare key qualitative metrics – accuracy, readability, sentiment, understandability, and actionability – across all sources.
Selection of patient education materials
Four PEMs were evaluated; three AI-generated PEMs were created using standardised prompts on ChatGPT-4o by OpenAI, Gemini 2.5 by Google, and DeepSeek V3 by DeepSeek. Only the first complete output from each tool was included, mirroring typical user behaviour and maintaining real-world relevance (Supplementary Materials 1–4). A detailed web search by the authors was done for online available PEMs on prehabilitation for major surgery and anaesthesia. Five PEMs were selected based on clinical relevance and public availability. Two experts independently evaluated the patient education materials for readability and comprehensibility. Following the independent assessments, any discrepancies were discussed between the evaluators until a consensus was reached. The evaluators consisted of a consultant surgical oncologist and oncological anaesthetist with experience in oncological perioperative care, each with more than 10 years of clinical experience and active involvement in health communication. Both evaluators routinely manage a high volume of patients in outpatient and preoperative settings, addressing patient queries and concerns related to prehabilitation, thereby ensuring both clinical and educational perspectives in the assessment process. As the evaluation was qualitative and consensus-driven, formal inter-rater reliability statistics were not calculated. Among the five, NHS Wales PEM was finalised after consensus among the experts based on clarity, reach, and understandability.
To minimise evaluator bias, all materials were anonymised and assigned unique identification numbers. A simple randomisation technique was used to determine the order of presentation. Specifically, a computer-generated random number sequence was used to randomise the materials, and they were distributed to the evaluators accordingly. All identifying information regarding the source of the materials was removed prior to evaluation to ensure blinding. PEMs were assessed by a panel of ten independent clinical experts: five oncological surgeons and five oncological anaesthetists. Each has at least 10 years of experience in their respective fields and is actively involved in patient education routinely. Each expert was blinded both to the origin of the leaflet and to the evaluations of other panel members.
For accuracy assessment, experts rated the accuracy of each PEM using a standardised 10-point Likert-type scale, judging concordance with current clinical guidelines and the inclusion of essential prehabilitation content. A scoring rubric was provided to each expert, ensuring a standardised format to be followed by all reviewers and thus removing bias (Supplementary Material 5).
Readability was measured by classic indices: the Flesch Reading Ease (FRE) and the Flesch–Kincaid Grade Level (FKGL). Scores were computed using online readability tools, with lower FKGL and higher FRE indicating easier comprehension for the public. FRE is used to evaluate how easy a text is to read and ranges from 0 to 100; scores above 60 are easier to read. FKGL grades the complexity of a text into a US school grade level and ranges from 0 to 12; scores ⩽8 are easier to read (Supplementary Material 5).
The sentiment of each PEM was objectively evaluated using established sentiment analysis tools, with scores indicating the degree of positivity or seriousness. Scores ranged from −100 to −25 (negative/serious) to +25 to +100 (positive/enthusiastic) and −25 to +25 as neutral tone (Supplementary Material 5).
The Patient Education Materials Assessment Tool for Printable Materials (PEMAT-P) was used to evaluate the understandability (clarity, organisation, word choice) and actionability (how readily a reader can identify actionable steps) of the selected materials. The PEMAT-P is a validated instrument developed to systematically assess patient education resources. The tool has demonstrated good reliability and validity in its original development study (Shoemaker et al 2014). In addition, subsequent studies have supported its psychometric properties and applicability across different languages and health care contexts, including cross-cultural validation studies (Furukawa et al 2025, Shan et al 2023). Scores are expressed as percentages; ⩾80% is considered high quality for patient education (Supplementary Material 5).
Data collection and statistical analysis
All ratings and scores were tabulated using Microsoft® Excel® 2021 and analysed by statistical software Jamovi 2.6.44. Normality of expert scores was checked via the Shapiro–Wilk test; homogeneity of variance was checked by Levene’s test. Parametric data are reported as mean ± standard deviation (SD). Analysis of variance (ANOVA) was done for multisample comparisons, with post hoc Tukey’s honestly significant difference (HSD) tests for pairwise differences. Statistical significance was defined as p < 0.05.
Ethics declaration
This study analysed online PEM available in the public domain and popular generative chatbots for comparative evaluation. No patient was directly involved; no sensitive data were collected or stored. In view of the nature of the study, a formal ethical approval was deemed unnecessary. All ethical guidelines were followed in the conduct of the study.
Results
The readability of the text generated by AI language chatbots (ChatGPT, Google Gemini, DeepSeek) and the NHS patient education material was evaluated using established readability metrics (Table 1).
Readability, sentiment, and expert analysis of patient education materials
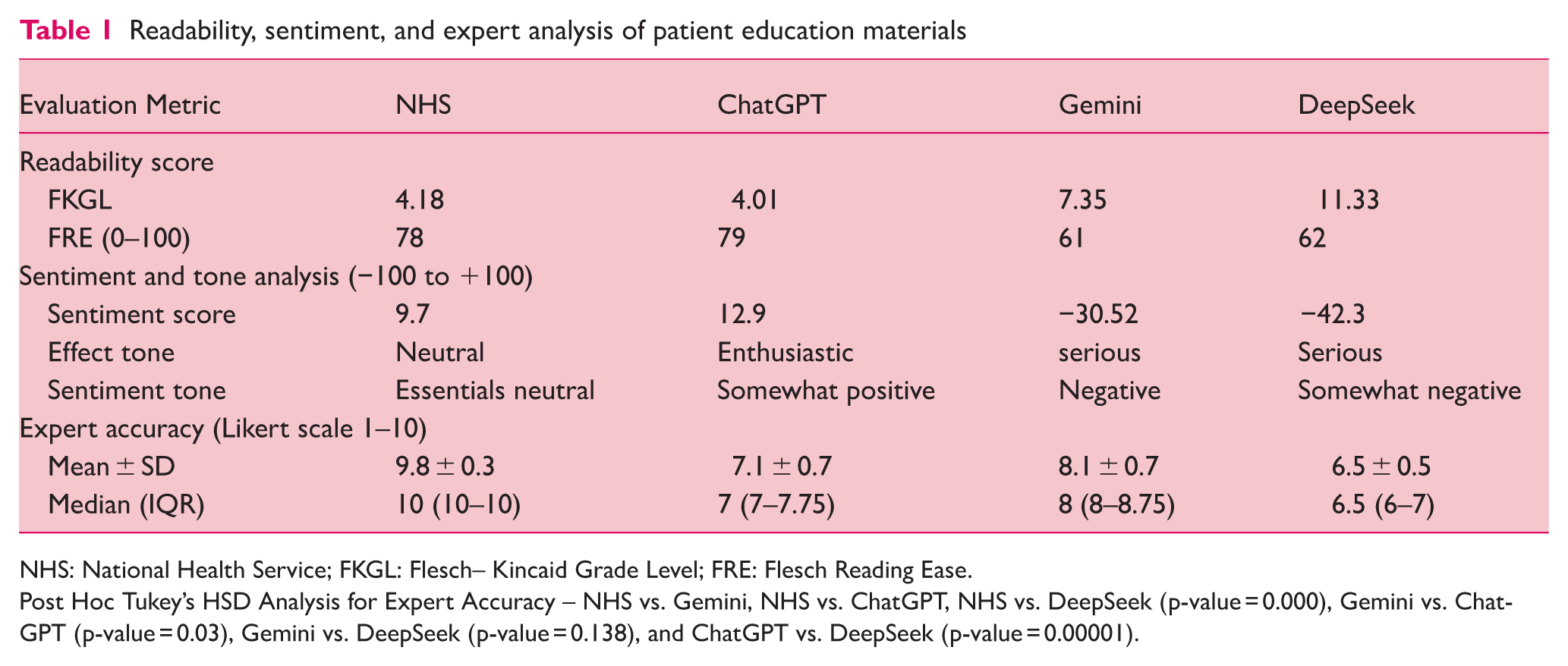
NHS: National Health Service; FKGL: Flesch– Kincaid Grade Level; FRE: Flesch Reading Ease.
Post Hoc Tukey’s HSD Analysis for Expert Accuracy – NHS vs. Gemini, NHS vs. ChatGPT, NHS vs. DeepSeek (p-value = 0.000), Gemini vs. ChatGPT (p-value = 0.03), Gemini vs. DeepSeek (p-value = 0.138), and ChatGPT vs. DeepSeek (p-value = 0.00001).
ChatGPT demonstrated the lowest FKGL score of 4.01, suggesting easier readability, followed by NHS (4.18), Gemini (7.35), and DeepSeek (11.33). NHS demonstrated the highest FRE score (78), followed closely by ChatGPT (79), Gemini (61), and DeepSeek (62). Higher FRE scores indicate easier readability.
The sentiment analysis of the text generated by ChatGPT, Google Gemini, DeepSeek, and NHS revealed varying emotional tones (Table 1). DeepSeek exhibited the lowest sentiment score of −42.3, indicating a serious tone with a somewhat negative sentiment. Gemini showed the sentiment score of −30.52, suggesting a serious effect tone and negative sentiment. ChatGPT demonstrated a sentiment score of +12.9, showing an enthusiastic effect tone and somewhat positive sentiment. The NHS had a sentiment score of +9.7, indicating a neutral effect tone and essentially neutral sentiment.
The PEMAT-P scores for understandability (U) and actionability (A) are summarised in Table 2. PEMAT-P-based evaluations demonstrated comparable performance across the four chatbots for both understandability and actionability domains (Figure 1). For understandability, mean scores ranged from 75.7% (Gemini) to 90.9% (ChatGPT). The Kruskal–Wallis test revealed no statistically significant difference in scores across chatbots, χ2(3) = 6.73, p = 0.081, with mean ranks of 7.17 for DeepSeek, 2.17 for Gemini, 9.00 for ChatGPT, and 7.67 for NHS Wales.
PEMAT-P
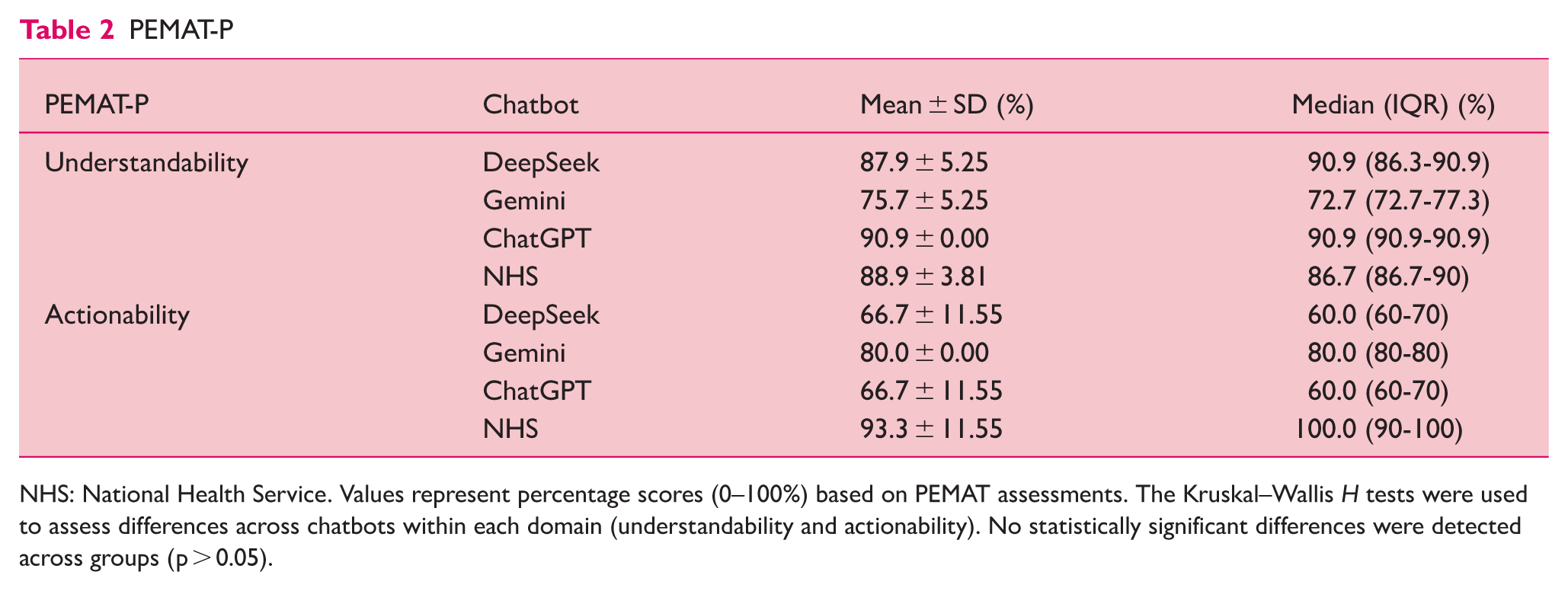
NHS: National Health Service. Values represent percentage scores (0–100%) based on PEMAT assessments. The Kruskal–Wallis H tests were used to assess differences across chatbots within each domain (understandability and actionability). No statistically significant differences were detected across groups (p > 0.05).
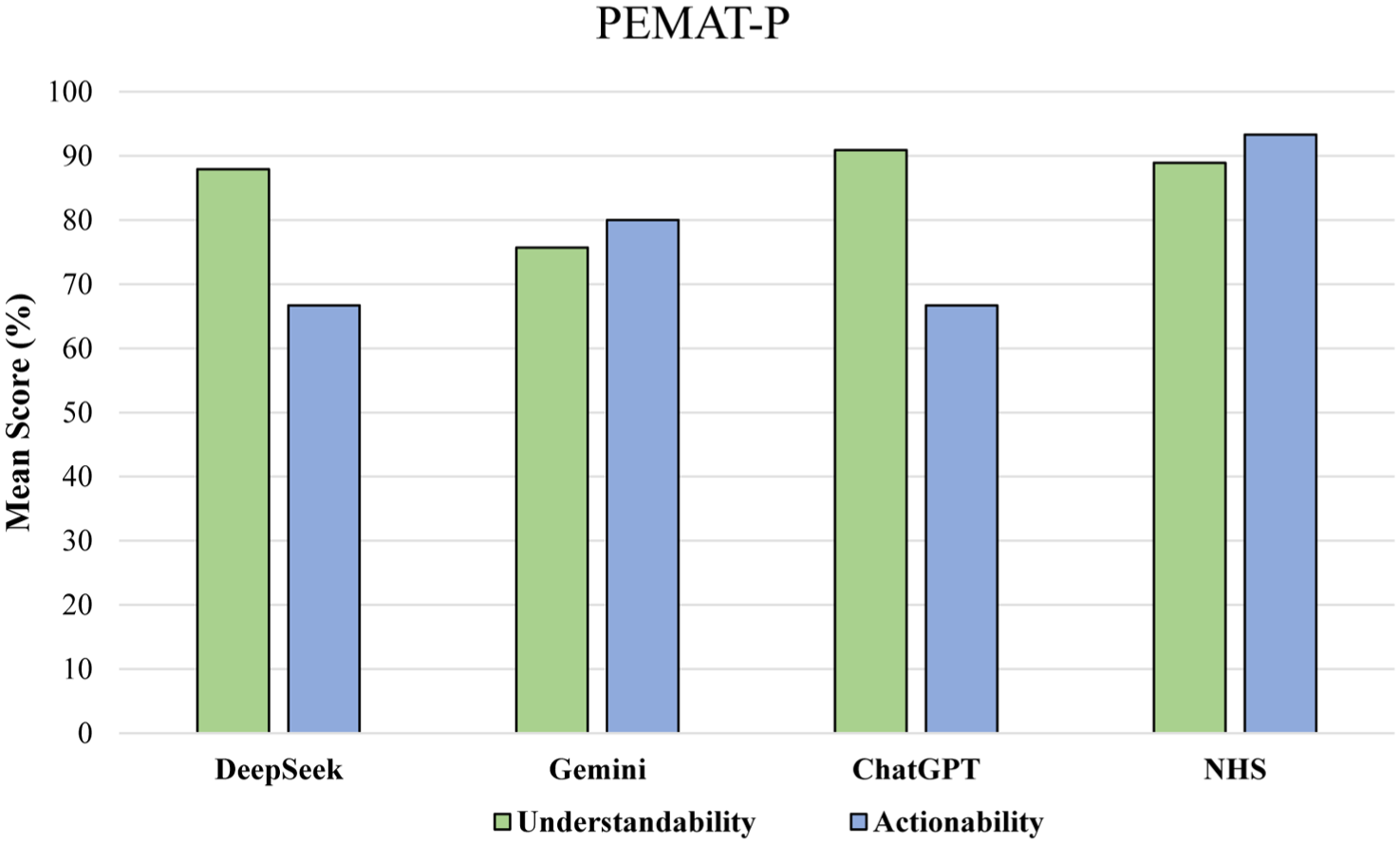
Mean percentage scores for PEMAT-P, understandability (green) and actionability (blue) of patient education materials from DeepSeek, Gemini, ChatGPT, and NHS
For actionability, scores ranged from 66.7% (DeepSeek and ChatGPT) to 93.3% (NHS Wales). The Kruskal–Wallis test similarly indicated no significant difference across chatbots, χ2(3) = 6.97, p = 0.073, with mean ranks of 4.17 for DeepSeek, 7.50 for Gemini, 4.17 for ChatGPT, and 10.17 for NHS Wales. Given the absence of statistically significant differences, post hoc pairwise testing was not pursued.
The accuracy of the responses provided by NHS, ChatGPT, Google Gemini, and DeepSeek were meticulously evaluated by ten experts (Table 1 and Figure 2). Each response was individually rated on a Likert-type scale, ranging from 1 to 10, with higher scores meaning higher levels of accuracy. The normality of the scores was checked using the Shapiro–Wilk test; parametric descriptive analysis revealed the highest score for NHS median (IQR) 10 (10–10), followed by Gemini 8 (8–8.75), ChatGPT 7 (7–7.75), and DeepSeek 6.5 (6–7).
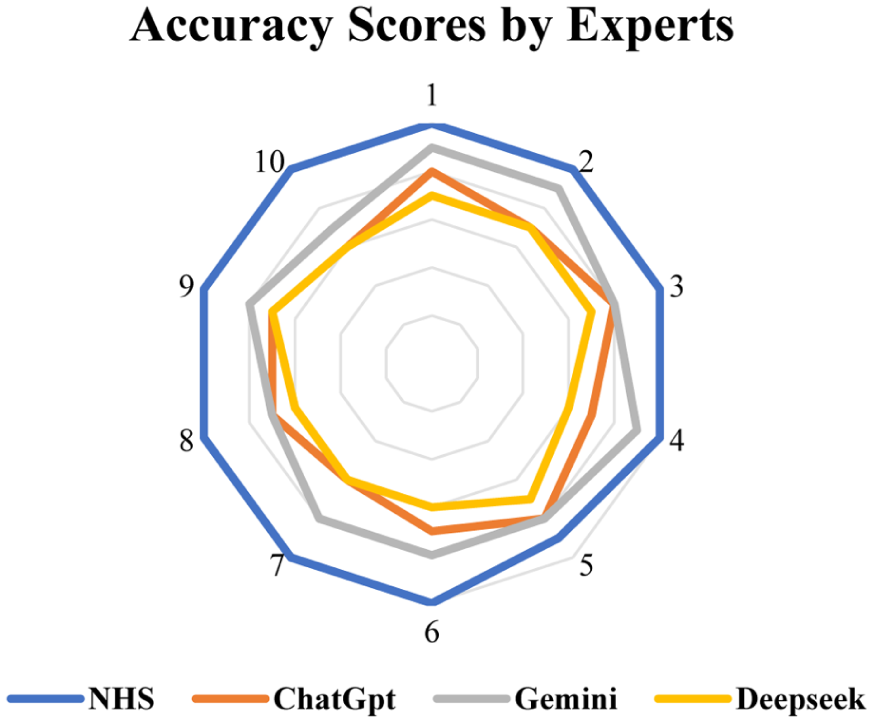
A radar plot showing the accuracy ratings (Likert-type scale 1−10). NHS consistently received the highest scores, significantly outperforming all AI models
Post Hoc Tukey’s HSD Analysis
Significant differences in accuracy were observed between NHS and Gemini (p = 0.00), NHS and ChatGPT (p = 0.00), and NHS and DeepSeek (p = 0.00). A significant difference was found between Gemini and ChatGPT (p = 0.03) and between ChatGPT and DeepSeek (p < 0.001). No significant difference was observed between Gemini and DeepSeek (p = 0.138).
Discussion
Prehabilitation is now widely seen as an essential part of surgical care, optimising postoperative outcomes by preparing both physically and mentally before surgery. Accessible, trustworthy, and practical information is key for motivating patients for lifestyle and behaviour changes that make prehabilitation effective.
In this comparative evaluation, we found clear differences between AI-generated educational materials (from ChatGPT, Gemini, and DeepSeek) and traditional NHS resources across several core areas: readability, tone, accuracy, completeness, and the overall quality of communication aimed at patients.
Readability analysis showed both the ChatGPT and NHS PEMs stood out for their ease of reading. In contrast, Gemini-generated content was moderately more complex, and DeepSeek was the most challenging to read, often requiring advanced literacy typical of college-level readers (Table 1). Similar results were observed by Guven et al, who reported that ChatGPT 3.5 and ChatGPT 4.0, and Google Gemini, produced AI-generated dental health responses which were well above the usual recommendation for patient facing content (Guven et al 2025). Similarly, Pompili et al observed that PaLM 2 (Google Bard) produced leaflets at a 9th-grade reading level (age 14–15), and Llama 2 generated the most difficult language (11th grade, age 16–17) (Pompili et al 2024). These findings suggest that while AI chatbots may simplify language, but can also produce academically dense text, making readability optimisation crucial in future AI health communications (Chen et al 2025, Esteva et al 2019).
Our sentiment analysis revealed meaningful differences in the emotional tone of the materials. DeepSeek responses were more negative and had a serious tone; ChatGPT was enthusiastic and positive, while NHS PEM remained neutral and informative. Gemini, interestingly, showed a markedly negative sentiment (Table 1). These findings highlight the importance of emotional tone in influencing patient engagement and trust, as observed by Sharma et al, in generative AI outputs on end-of-life care, which can encourage more hope and trust, but negative or excessively clinical language may unintentionally raise anxiety or may decrease involvement (Sharma et al 2024). Emotional resonance, even if subtle, matters for motivating people to act on the advice.
PEMAT-P provides helpful insight into not just whether people could read the material but also whether they could actually understand and act on it. For understandability, ChatGPT and NHS were followed by DeepSeek. Gemini has a lower score among all, suggesting that its more complex language affected understanding. However, there was more difference noted in actionability. The NHS PEM scored highest, followed by Gemini, with both DeepSeek and ChatGPT lagging behind (Figure 1). This pattern is consistent with earlier findings in AI-generated PEMs in other medical specialities, such as eye surgery and palliative care, where AI chatbots sometimes matched or exceeded traditional PEMs for clarity, but still lagged in providing specific, practical next steps (Gondode et al 2024a, 2024b). This underlines that AI remains less reliable in guiding practical patient actions, especially for complex, multidisciplinary topics like prehabilitation.
The traditional NHS PEM achieved the highest ratings from experts on accuracy and completeness, significantly outperforming all AI models. Among the AI-generated PEMs, Gemini showed better scores than ChatGPT or DeepSeek (Figure 2). Previous research has shown that well-established, peer-reviewed PEMs routinely outperform AI-generated literature in terms of subject accuracy and the breadth of information offered. Traditional PEMs benefit from multidisciplinary review and real-world experience, something AI systems, even with advanced prompts and vast training data, are not able to replicate. Generative AI is powerful for drafting and scaling information but requires expert validation to ensure accuracy to catch factual inaccuracies or subtle hallucinations (Esteva et al 2019, Kim et al 2025).
The clinical implications of these findings are particularly important in the perioperative context. Inaccurate or incomplete prehabilitation information may lead to inappropriate exercise, nutritional preparation, or misunderstanding of perioperative risks, potentially affecting surgical outcomes. Unlike general health information, perioperative education demands precise, evidence-based guidance, as even minor inaccuracies may adversely influence recovery (Moran et al 2016, Silver 2015).
The lower accuracy observed in AI-generated materials may be attributed to the inherent limitations of large language models. These systems are prone to hallucinations, generating plausible yet incorrect information. Furthermore, their outputs are not consistently grounded in specific clinical guidelines unless explicitly directed, increasing the risk of omissions or oversimplifications. Variability related to prompt design and model architecture further contributes to inconsistency in content quality (Goodman et al 2023, Kim et al 2025, Singhal et al 2023).
Implications and future directions
Our findings suggest that AI-generated educational materials are valuable for quickly generating drafts and tailoring information. However, these technologies function best within a workflow in which AI is used to create and customise materials, followed by clinician validation to ensure accuracy and clinical relevance before use. This is particularly important in the perioperative medical field which is multidisciplinary and sensitive, where miscommunication or oversights can have real consequences.
We need to assess how well people understand and use the information in the real world, not only by how well experts rate it. Advanced prompt engineering and more user iterations could help AI outputs develop better. Ongoing research and multidisciplinary validation are important as these technologies continue to evolve so rapidly. Algorithmic mistakes, knowledge gaps, and training data biases still pose risks.
Limitations
Our study has several limitations. First, this study’s focus on prehabilitation for cancer surgery may limit how well the findings apply to other medical subspecialities. Second, the lack of direct patient involvement is a key limitation, and this study should be viewed as a preliminary validation of generative AI outputs before clinical application. While standard measures were used, they might not fully capture patients’ feelings or understanding. Third, using only one response from each AI tool reflects typical use but misses chances for improvement with better prompts. Fourth, expert ratings bring valuable information, but they might also be biased and limited by the small reviewer group. In addition, as the evaluation was qualitative and consensus-driven, formal inter-rater reliability statistics were not calculated, which may limit the objectivity and reproducibility of the assessment. Fifth, the rapid developments in AI and the inherent potential for bias due to the Blackbox effect or AI hallucinations, if any, cannot be ruled out completely and hence present significant challenges to lasting trustworthiness, particularly in health care. Future studies should investigate patient experiences more thoroughly.
In conclusion, popular generative AI chatbots can generate promising PEMs for prehabilitation. AI offers advantages in scalability and adaptability; nevertheless, traditionally available PEMs scored better for accuracy, completeness, and actionability in guiding the patient for prehabilitation. The best way to move forward, on the important front of patient education in prehabilitation, is to maintain a balance between adaptive technology (such as generative AI) and human expertise and empathy. HITL (human in the loop) is necessary to make sure AI-generated content is safe, relevant, and really ready to help patients through difficult health journeys.
Supplemental Material
sj-docx-1-ppj-10.1177_17504589261454163 – Supplemental material for Comparative evaluation of traditional versus generative AI patient education material on prehabilitation
Supplemental material, sj-docx-1-ppj-10.1177_17504589261454163 for Comparative evaluation of traditional versus generative AI patient education material on prehabilitation by Aritra Kundu, Armanullah Khan, Sourav Saha and Prakash Gondode in Journal of Perioperative Practice
Supplemental Material
sj-docx-2-ppj-10.1177_17504589261454163 – Supplemental material for Comparative evaluation of traditional versus generative AI patient education material on prehabilitation
Supplemental material, sj-docx-2-ppj-10.1177_17504589261454163 for Comparative evaluation of traditional versus generative AI patient education material on prehabilitation by Aritra Kundu, Armanullah Khan, Sourav Saha and Prakash Gondode in Journal of Perioperative Practice
Supplemental Material
sj-docx-3-ppj-10.1177_17504589261454163 – Supplemental material for Comparative evaluation of traditional versus generative AI patient education material on prehabilitation
Supplemental material, sj-docx-3-ppj-10.1177_17504589261454163 for Comparative evaluation of traditional versus generative AI patient education material on prehabilitation by Aritra Kundu, Armanullah Khan, Sourav Saha and Prakash Gondode in Journal of Perioperative Practice
Supplemental Material
sj-docx-5-ppj-10.1177_17504589261454163 – Supplemental material for Comparative evaluation of traditional versus generative AI patient education material on prehabilitation
Supplemental material, sj-docx-5-ppj-10.1177_17504589261454163 for Comparative evaluation of traditional versus generative AI patient education material on prehabilitation by Aritra Kundu, Armanullah Khan, Sourav Saha and Prakash Gondode in Journal of Perioperative Practice
Supplemental Material
sj-pdf-4-ppj-10.1177_17504589261454163 – Supplemental material for Comparative evaluation of traditional versus generative AI patient education material on prehabilitation
Supplemental material, sj-pdf-4-ppj-10.1177_17504589261454163 for Comparative evaluation of traditional versus generative AI patient education material on prehabilitation by Aritra Kundu, Armanullah Khan, Sourav Saha and Prakash Gondode in Journal of Perioperative Practice
Footnotes
Authors’ note
Presentation: 102nd KoreAnesthesia 2025, Incheon, Korea.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Ethical approval and informed consent statements
This study involved the analysis of publicly available patient education materials and generated content from artificial intelligence chatbots. No human participants, patient data, or identifiable information were involved. In view of the nature of the study, formal ethical approval was deemed unnecessary. All ethical guidelines were followed in the conduct of the study. Informed consent was not applicable, as no patients or human participants were involved.
Data availability statement
The data supporting the findings of this study are derived from publicly available patient education materials and outputs generated from artificial intelligence chatbots using predefined prompts. All relevant data are included within the article and its supplementary materials. Additional details regarding the prompts and generated outputs will be provided by the corresponding author upon reasonable request.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.