
Abstract
Serverless computing offers automatic resource management and pay-per-use execution, but autoscaling remains difficult due to cold-start latency, inter-function dependencies, and highly dynamic workloads. Many existing approaches scale functions independently or rely on a single predictor, which can reduce robustness and cost efficiency. We present a dependency-aware autoscaling framework that unifies bottleneck identification, short-horizon demand forecasting, and cost-aware control in an end-to-end pipeline. We model applications as directed dependency graphs and prioritize high-impact functions using degree centrality. For these bottlenecks, near-term demand is predicted using lightweight supervised models, whose outputs are fused via a performance-weighted probabilistic ensemble inspired by Bayesian model averaging to improve stability under workload variability. The controller also accounts for cold starts and filters candidate actions through a cost-comparison mechanism to balance latency and operational efficiency. Experiments on real workload traces show improved prediction accuracy and more stable scaling decisions than representative baselines; supervised forecasting also consistently outperforms unsupervised clustering for generating autoscaling actions. The primary contribution is a practical system-level design that integrates dependency analysis, ensemble-based prediction, and cost-aware decision-making for robust serverless autoscaling.
Keywords
Introduction
Serverless computing allows developers to deploy event-driven functions without managing infrastructure, offering automatic provisioning and pay-per-use billing. Its fine-grained autoscaling adjusts function instances to workload variations, but accurate control remains challenging due to bursty demand, cold-start latency, and inter-function dependencies (Jonas et al., 2019; Tari et al., 2024; Tournaire et al., 2023; Wen et al., 2023). Unlike VM- or container-based systems, serverless applications often execute as chains of dependent function invocations. Congestion at one function can propagate along execution paths, increasing end-to-end latency and cost (Bibal Benifa and Dejey, 2019). Autoscalers that treat functions independently may overlook structurally critical bottlenecks, while aggressive scale-down can increase cold starts and degrade performance. To address these challenges, we propose a dependency-aware autoscaling framework that integrates structural bottleneck identification, multi-model demand forecasting, cold-start awareness, and cost-comparison control within a unified pipeline. Workflows are represented as directed dependency graphs, and bottleneck functions are prioritized using degree centrality. Near-term demand for these functions is predicted using lightweight supervised models (MLP, LSTM, and CNN), and predictions are combined via a performance-weighted probabilistic ensemble inspired by Bayesian model averaging to reduce model-specific bias and improve stability. The controller also incorporates cold-start awareness and a cost-comparison step to balance latency and operational efficiency. We evaluate the framework on real workload traces and compare it with standard autoscaling baselines and learning-based approaches. Results show improved prediction accuracy and more stable scaling behavior, and a unified comparison indicates that supervised forecasting substantially outperforms unsupervised clustering for autoscaling decision generation.
The main contributions of this work are as follows:
Graph-based bottleneck identification Lightweight multi-model forecasting Cold-start aware and cost-comparison scaling
The remainder of the paper is organized as follows. Section 2 provides essential background. Section 3 reviews related work and identifies open gaps. Section 4 describes the proposed framework and implementation details. Section 5 reports experimental results and evaluation. Section 6 concludes the paper, and Section 7 presents future research directions.
Background knowledge
This section briefly introduces the concepts necessary to understand the proposed autoscaling framework. We summarize the serverless execution model, describe dependency modeling through graph representation, and outline the learning paradigms used for demand prediction.
Serverless execution model
Serverless computing is commonly implemented through function-as-a-service (FaaS), where the cloud provider manages provisioning, scaling, and billing of function instances (Manner, 2023; Shafiei et al., 2022). As shown in Figure 1, responsibility progressively shifts from the customer to the provider across deployment models, from on-premises to infrastructure-as-a-service (IaaS), platform-as-a-service (PaaS), FaaS, and software-as-a-service (SaaS). In FaaS, developers primarily manage application logic and data, while the provider controls the runtime, operating system, virtualization layer, and hardware. Serverless functions are typically stateless and event-driven, and are billed according to execution time and allocated memory (Song et al., 2024; Xu et al., 2023). A distinguishing feature is scale-to-zero capability, which releases resources during idle periods. While this improves cost efficiency, reactivating a function may introduce cold-start latency due to runtime initialization (Wen et al., 2022). These characteristics make autoscaling both fine-grained and highly dynamic, requiring decisions that balance responsiveness, latency, and cost under rapidly changing workloads.
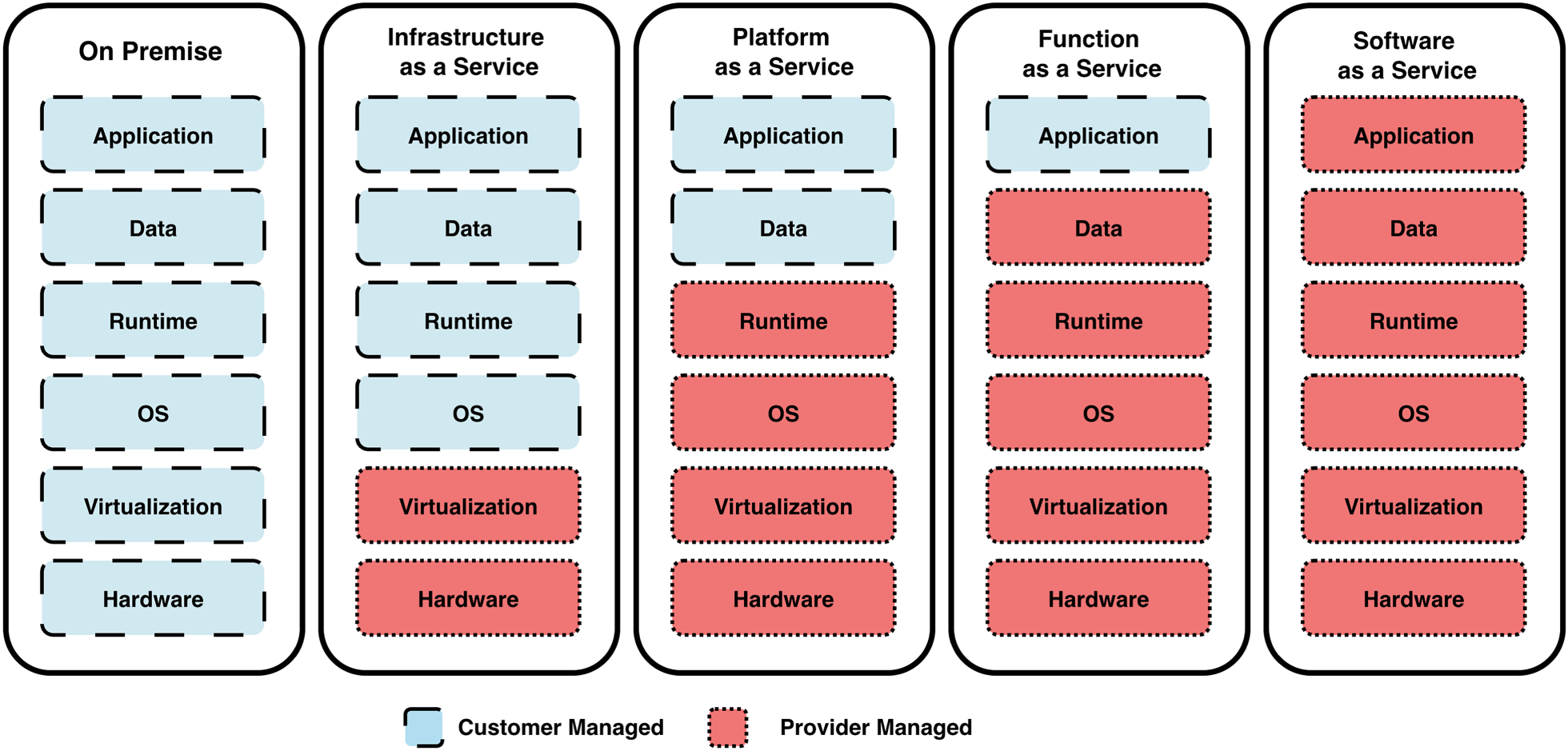
Responsibility distribution across cloud service models. Blue indicates customer-managed components and red indicates provider-managed components. In FaaS, users manage primarily application logic, while the provider controls the underlying infrastructure (Mampage et al., 2022).
Serverless applications commonly consist of multiple interacting functions connected through invocation relationships. A single request may traverse several functions, forming execution paths whose combined behavior determines end-to-end latency and resource consumption. To capture this structure, we represent the application as a directed dependency graph, where nodes correspond to functions and edges represent invocation dependencies (Madsen, 2022). This abstraction enables analysis of structural influence across the workflow. Graph analysis can identify functions that occupy critical positions within execution paths and are therefore more likely to accumulate workload pressure or propagate latency (Li et al., 2025). Prioritizing these structurally influential functions provides a principled basis for targeted autoscaling decisions.
Learning-based demand prediction
Learning-based approaches are widely used in autoscaling to estimate near-term resource demand under dynamic workloads. In this work, supervised models generate actionable scaling decisions, while unsupervised techniques are evaluated only as comparative baselines.
Unsupervised learning (baselines)
Unsupervised methods identify patterns in data without labeled outputs. Principal component analysis (PCA) reduces dimensionality by projecting data onto directions that capture maximum variance (Abdi and Williams, 2010; Denton et al., 2021; Ma∼kiewicz and Ratajczak, 1993). Clustering techniques, such as k-means, partition observations into similarity-based groups (Ahmed et al., 2020; Berahmand et al., 2025; Ling and Weiling, 2025; Rokach and Maimon, 2006), while self-organizing maps (SOM) provide topology-preserving clustering and visualization (Abdelsamea et al., 2014; Florida et al., n.d; Qu et al., 2021). We also use t-SNE for the visualization of high-dimensional workload patterns (Chang, 2025; Mittal et al., 2024). Although these techniques reveal structural patterns in resource traces, they do not directly produce stable real-time scaling decisions. Therefore, they are used only to evaluate whether pattern discovery alone can approximate autoscaling actions.
Supervised learning (decision models)
Supervised learning models learn mappings from observed resource metrics to future demand or scaling actions. MLP captures nonlinear relationships through fully connected layers (Popescu and Balas, n.d; Rana et al., 2018; Singh and Banerjee, 2019). LSTM networks model temporal dependencies in sequential workload data (Landi et al., 2021; Lu and Salem, 2017; Pulver and Lyu, 2017; Siami-Namini et al., 2019; Smagulova and James, 2019; Yao et al., n.d; Zhao et al., 2020). CNN extract local patterns from sliding windows of time-series inputs (Alzubaidi et al., 2021; Elngar et al., 2021; Purwono et al., 2022; Sahu and Dash, 2021). In the proposed framework, these complementary models serve as candidate predictors, and their outputs are later combined using Bayesian-inspired model averaging to improve robustness.
Auto-scaling overview
Autoscaling dynamically adjusts compute resources to maintain performance objectives while controlling operational cost. The control granularity varies across platforms, including virtual machines and containers in instance-based clouds (Chen et al., 2019; Hu et al., 2025; Roy et al., n.d; Wang et al., 2024), service replicas in microservices architectures (Nunes et al., 2024; Semerikov et al., 2024), and individual function instances in serverless systems (Mampage et al., 2023). Figure 2 presents a taxonomy view of the proposed framework across four dimensions: objectives, information sources, core modeling choices, and control characteristics. The framework aims to achieve accurate demand prediction, robust consensus-based decision-making, cold-start-aware behavior, and cost comparison-based scaling. Scaling decisions are guided by runtime signals and workflow dependencies; demand is forecast using supervised models aggregated via Bayesian-inspired consensus; and candidate scaling actions are evaluated through a cost-comparison component before execution.
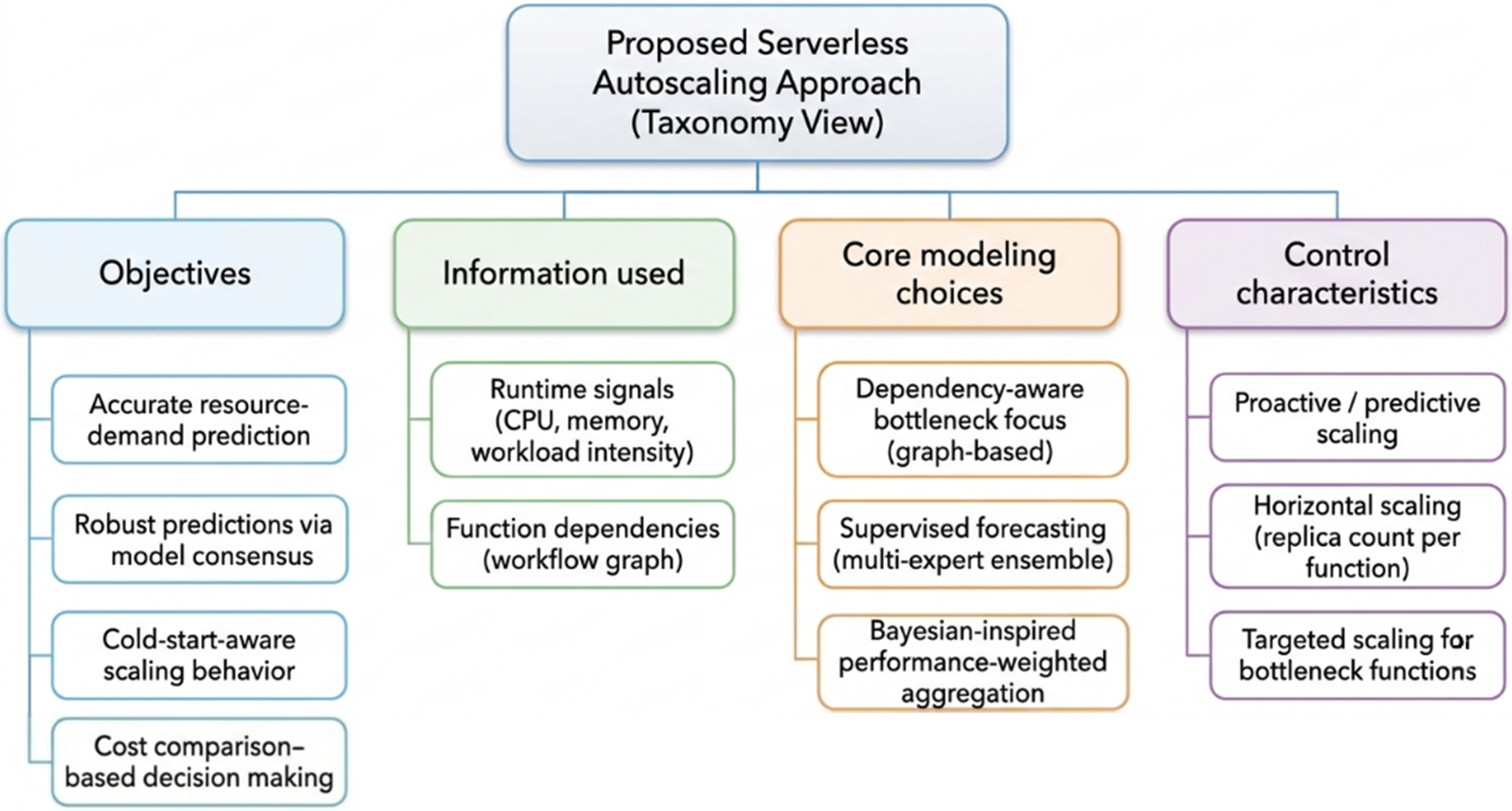
Taxonomy view of the proposed serverless autoscaling approach.
Autoscaling approaches are commonly categorized by how decisions are generated. Threshold-based approaches trigger scaling when monitored metrics exceed predefined limits (Dashtbani and Tahvildari, 2025). Control-theoretic methods regulate system outputs toward target values using feedback mechanisms (Al-Dulaimy et al., 2022). Learning-based approaches use supervised prediction or reinforcement learning to select scaling actions (Ginarsa and Santoso, 2025; Robino et al., 2025; Santos et al., 2025; Valkenborg et al., 2023). Queueing-based models estimate delay and required capacity from traffic characteristics (Jafarnejad Ghomi et al., 2019; Pandey, 2025). Time-series forecasting methods predict short-horizon demand from historical observations (Ding et al., 2025; Fog et al., 2025). Although these categories differ in modeling assumptions and responsiveness, serverless environments introduce additional constraints, including cold-start latency and inter-function dependencies. These characteristics motivate autoscaling designs that integrate predictive modeling with structural awareness, as reflected in the proposed framework.
Ensemble methods combine predictions from multiple models to improve robustness and generalization performance (Wang et al., 2023). Unlike methods that select a single best model, Bayesian Model Averaging (BMA) accounts for model uncertainty by forming a probabilistic weighted ensemble (Bazrafshan et al., 2022; Zhang et al., 2023). BMA has been successfully applied in regression, classification, and time-series forecasting tasks. In this study, BMA is used to produce consensus resource-demand predictions. Let
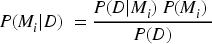
Where
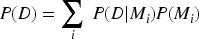
The BMA prediction is obtained as the posterior-weighted average of individual model predictions, as shown in Equation (3):
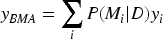
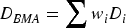
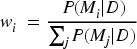
Where the probability
This section situates our work within serverless autoscaling research. We organize prior studies by decision scope (placement vs. scaling), decision mechanism (rules, control, or learning), and use of structural information. We then highlight recurring limitations that motivate our framework.
Placement vs. scaling decisions
Several studies focus on execution placement, determining where function invocations execute. Weighted scheduling and multi-objective optimization improve throughput, latency, and energy efficiency by assigning requests to suitable nodes, particularly in heterogeneous or edge environments (Aslanpour et al., 2024; Chitsaz et al., 2023). Platform-level designs such as OpenWhisk, OpenFaaS, and Fission introduce schedulers, admission control, and monitoring to enhance dispatch efficiency and reduce local queuing (Govindarajan and Tienne, 2023; Han et al., 2012; Koperek and Funika, 2012). These efforts primarily optimize where requests execute rather than how much capacity should be allocated to each function. They do not explicitly address scaling decisions when requests traverse multiple dependent functions along a call graph. Our work complements placement strategies by directing scaling and pre-warming toward structurally critical functions that bound end-to-end performance.
Cold-start mitigation
Cold starts remain a major source of latency under bursty demand and scale-to-zero behavior. Stochastic optimization has been used to determine pre-spawning policies that balance responsiveness and energy cost (Anselmi et al., 2025). However, many pre-warming approaches treat functions independently and do not exploit the dependency structure to prioritize which functions should be warmed first. In contrast, our framework leverages a dependency graph to identify bottleneck functions and target scaling and pre-warming accordingly.
Rule-based and control-theoretic approaches
Rule-based autoscaling remains widely adopted due to its simplicity and low overhead. Dynamic thresholds, escalation policies, mixed-resource rules, and deadline-aware schemes improve responsiveness relative to static policies (Lorido-Botran et al., 2013; Mampage et al., 2021; Maurer et al., 2011). Nevertheless, such approaches are typically reactive, sensitive to parameter tuning, and applied independently to each function. Control-theoretic and queueing-based methods regulate delay, utilization, or queue length under bursty workloads (Dutreilh et al., 2010; Gambi and Toffetti, 2012; Lim et al., 2010; Roy et al., n.d). While these approaches offer stability guarantees, they generally operate at the service tier and rarely incorporate invocation-graph structure when allocating capacity. As a result, scaling decisions may not prioritize functions that dominate end-to-end latency.
Learning-based autoscaling
Learning-based methods enable proactive scaling through demand forecasting or policy learning. Reinforcement learning has been applied to elasticity control in systems such as Knative under non-stationary workloads (Rao et al., 2009; Schuler et al., 2020; Zhang et al., 2022). Supervised predictors, including LSTM, CNN, and MLP models, forecast workload or resource utilization to reduce service violations under dynamic traces. Additional approaches employ profit-oriented provisioning or Markov models to estimate required instance counts (Anonymous, 2016; Kumar et al., 2018; Salah et al., 2016; Villela et al., 2004). Although these methods improve proactive decision-making, many rely on a single predictor and primarily use local signals. This can reduce robustness under workload drift, noise, and short-lived bursts. Hybrid controllers combining rules, prediction, and control have also been proposed (Almeida et al., 2002; Fang et al., 2012; Golshani and Ashtiani, 2021; Khatua et al., 2010; Nadjaran Toosi et al., 2019; Sfakianakis et al., 2022; Zhao et al., 2021), yet explicit dependency-aware prioritization and structured cold-start reasoning are often absent. Recent work explores multi-model forecasting to improve prediction accuracy. For example, Taha et al. (2024) propose an MLP–LSTM hybrid, Javeed et al. (2025) combines SVM, random forest, and deep neural networks, and investigates ensemble learning with hyperparameter tuning. Approaches such as (Ouhame et al., 2021) and (Sabyasachi et al., 2024) integrate CNN–LSTM architectures and vector autoregression for enhanced time-series prediction. While these models report improved forecasting accuracy, they typically focus on prediction alone and do not integrate scaling control, dependency-aware bottleneck targeting, or probabilistic consensus for model fusion.
Recurring limitations
Across the literature, two limitations recur. First, inter-function dependencies are frequently ignored or handled indirectly, even though a small subset of functions along critical invocation paths can dominate tail latency and cost. Second, scaling decisions often rely on a single predictive model, reducing robustness under workload uncertainty and drift. The proposed framework addresses these gaps by modeling function interactions as a directed call graph, identifying bottleneck functions using graph-based measures, forecasting near-term demand with complementary lightweight models MLP, CNN, and LSTM, and combining predictions through Bayesian-inspired model averaging. This produces a dependency-aware, model-robust autoscaler that focuses scaling actions on functions with the greatest end-to-end impact. Table 1 summarizes the differences between our approach and representative learning-based methods.
Comparison with related learning-based methods.
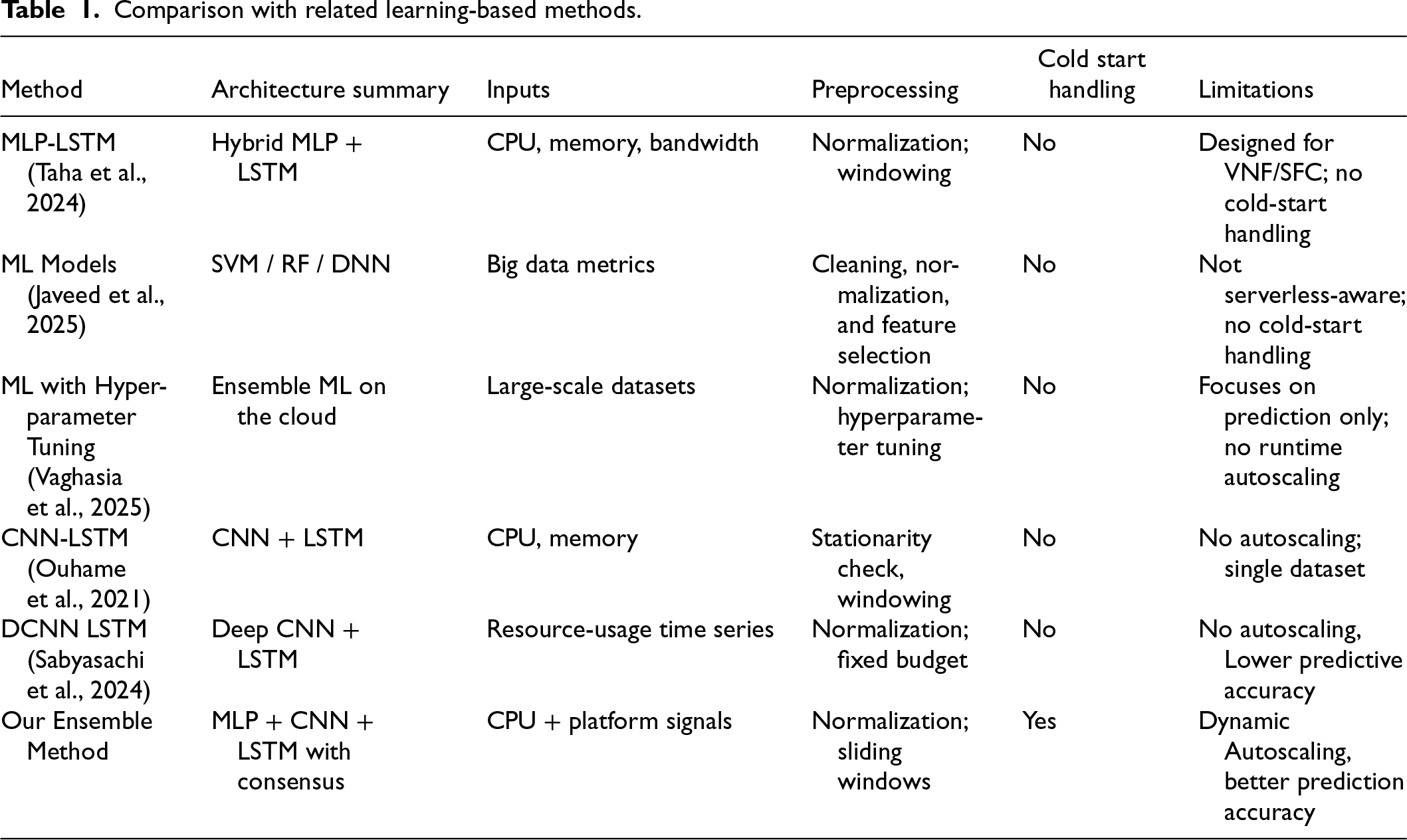
Comparison with related learning-based methods.
This section presents the proposed dependency-aware autoscaling framework for serverless applications, illustrated in Figure 3. The framework integrates structural analysis, runtime monitoring, predictive modeling, and consensus-based decision logic into a unified control pipeline. Specifically, dependency analysis constructs a watch set of high-impact functions; resource modeling generates runtime signals and action labels; supervised models forecast next-step demand for the watch set; the consensus module fuses predictions; and the cost-comparison module filters the proposed action before execution. The pipeline begins with Bottleneck Analysis, where the function dependency graph is analyzed using degree centrality to identify structurally critical functions. A watch set is constructed to prioritize monitoring and scaling decisions for these bottleneck candidates. In the Resource Modeling stage, runtime signals including CPU utilization, memory usage, and execution time are continuously monitored. Percentile-based adaptive thresholds generate baseline scaling indicators and detect high or low resource pressure. Next, scalability modeling predicts near-term resource demand for the watch set. Supervised learning models, LSTM, MLP, and CNN, provide complementary forecasts, while unsupervised techniques, SOM, K-means, and PCA, are included solely for comparative evaluation. Predictions from supervised models are aggregated in the consensus module. Model performance weighting and Bayesian-inspired model averaging produce a robust consensus estimate. At this stage, cost comparison and cold-start awareness are incorporated to stabilize scaling decisions. Finally, the Scaling Decision module issues one of three actions: scale up, scale down, or hold, based on the consensus output. By combining dependency-aware prioritization, multi-model forecasting, probabilistic aggregation, and cost comparison, the framework enables targeted and stable horizontal scaling under dynamic workloads.
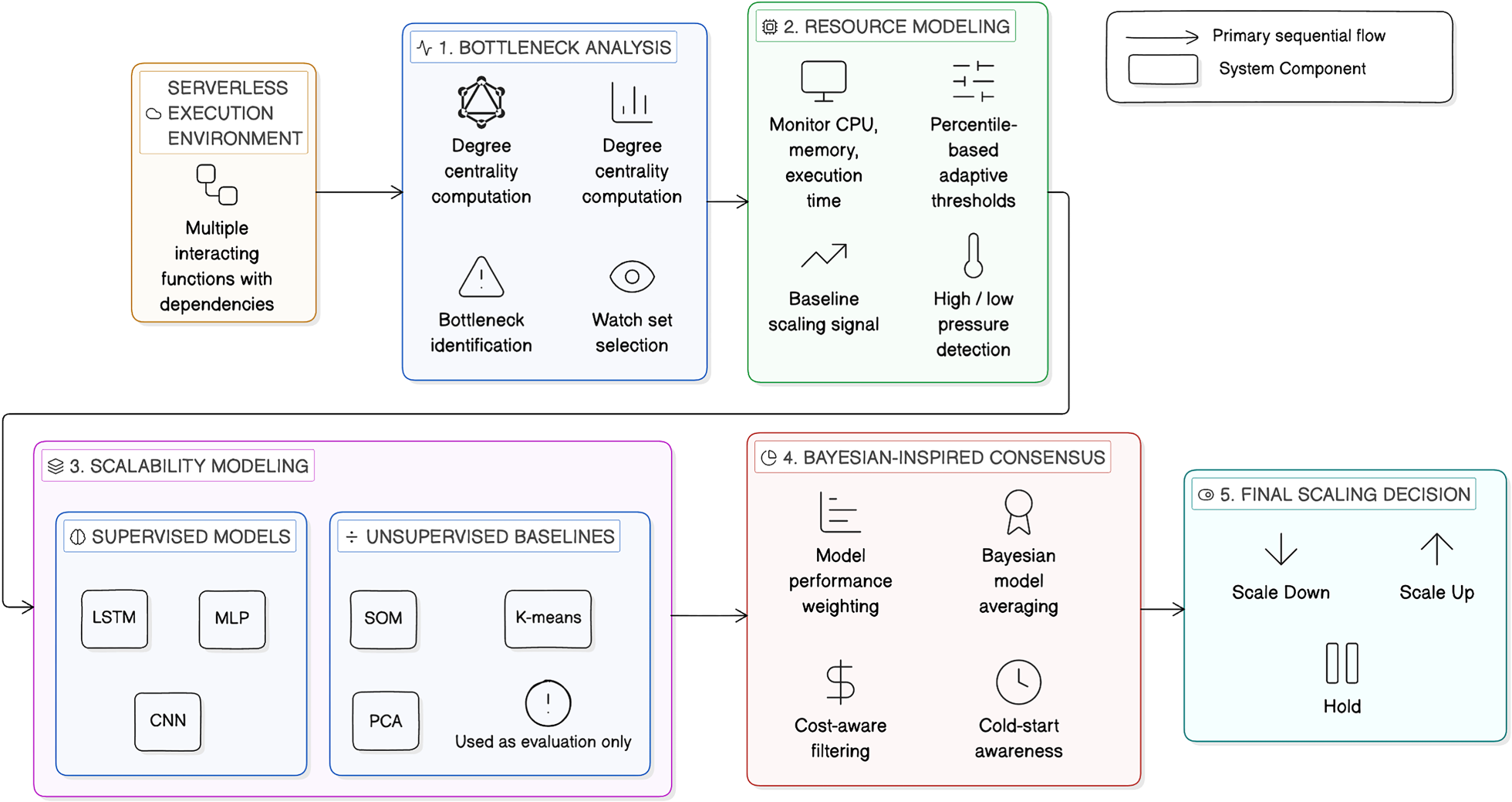
Dependency-aware multi-expert autoscaling framework architecture, illustrating bottleneck analysis, resource monitoring, predictive modeling, consensus, and final scaling decision.
Serverless workflows typically consist of multiple interacting functions connected through invocation dependencies. Congestion in a single function can propagate along critical execution paths, significantly affecting end-to-end latency and cost. Rather than detecting overload reactively based solely on runtime metrics, the proposed framework proactively identifies structurally influential functions using dependency analysis. The application is represented as a directed dependency graph, where nodes correspond to functions and edges represent invocation relationships. Degree centrality is computed for each node to quantify its structural influence. This measure is selected for its low computational overhead and suitability for dynamic environments that require frequent updates. Functions with high degree centrality interact with many other components and are therefore more likely to amplify workload pressure across execution paths. The framework constructs a watch set consisting of the highest-ranked nodes. Subsequent monitoring, forecasting, and scaling decisions are prioritized for this reduced set of structurally critical functions.
Degree centrality on the dependency graph
Bottleneck identification begins by constructing a weighted, directed dependency graph from the dependency dataset D with columns { 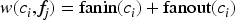
If multiple records exist for the same class–file pair, weights are accumulated to reflect repeated interactions. The resulting graph is defined as 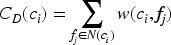
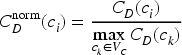
The bottleneck score is defined directly as the normalized degree centrality as defined in Equation (9).
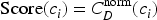
Nodes are ranked in descending order of

After identifying bottleneck functions, the resource modeling component derives adaptive scaling thresholds from historical runtime behavior to support stable control decisions. Let

Scalability component
The scalability component produces short-horizon demand predictions that enable proactive scaling decisions. To evaluate learning paradigms under a consistent decision framework, both unsupervised and supervised methods are implemented and compared. However, only supervised models are used to drive the final autoscaling decisions. Unsupervised methods identify latent structure in normalized runtime metrics without access to scaling labels. We consider three clustering strategies: K-Means, PCA followed by K-Means, and SOMs. Let X denote the normalized feature matrix constructed from runtime metrics. Each method produces cluster assignments

In contrast, supervised learning directly models the mapping from runtime metrics to scaling actions. The problem is formulated as a three-class classification task with inputs derived from CPU utilization, memory usage, and execution time features. We evaluate three lightweight neural architectures selected for complementary modeling capabilities while maintaining low inference overhead: The MLP model captures nonlinear relationships among aggregated features, the CNN extracts localized patterns within sliding windows of resource metrics, and the LSTM captures temporal dependencies across short look-back windows. Time-series samples are constructed using a fixed look-back window ℓ. Features are standardized prior to training. Each model outputs class probabilities through a softmax layer. Model configurations are intentionally compact to preserve online feasibility. The MLP uses one hidden layer with 64 units and ReLU activation, followed by dropout (0.2) and a softmax output. The LSTM model uses a single LSTM layer with 64 units, dropout (0.2), and softmax output; to limit inference latency, inputs are provided as a short sequence window. The CNN applies a one-dimensional convolution with 32 filters of width three, global max pooling, a dense layer with 64 units, and a softmax output. All models are trained using the Adam optimizer with categorical cross-entropy loss and early stopping to prevent overfitting. Time-series cross-validation is applied to preserve temporal structure. Algorithm 4 summarizes the supervised training procedure. Performance is evaluated with accuracy, precision, recall, and F1-score, as well as mean absolute error (MAE), mean squared error (MSE), averaged across time-series cross-validation folds.

Consensus component
Relying on a single predictor can make scaling decisions sensitive to workload drift, noise, or transient bursts. The consensus component addresses this by combining predictions from the MLP, CNN, and LSTM using a performance-weighted probabilistic ensemble inspired by Bayesian model averaging principles. Let 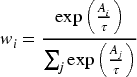
This formulation ensures higher-performing models receive greater influence, all weights remain positive and 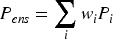
Final scaling decisions are obtained via Equation (12).
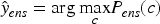
This performance-weighted probabilistic aggregation reduces dependence on any single model while preserving complementary predictive information. Algorithm 5 details the complete consensus procedure.

The cost comparison component ensures that consensus-driven scaling actions remain economically justified by estimating their projected operational impact before execution. While overprovisioning increases direct resource expenditure, underprovisioning increases latency and may lead to SLA violations; therefore, scaling decisions must balance cost efficiency and performance reliability. Operational cost at time t is modeled as the sum of three components: base resource cost, waste cost, and overload cost. The base cost represents pay-per-use charges proportional to the number of allocated replicas. Waste cost captures overprovisioning when allocated capacity exceeds actual utilization, reflecting underutilized resources. Overload cost models underprovisioning penalties when demand exceeds capacity, and this is amplified when SLA violations occur. In particular, SLA violations are detected through latency thresholds, and the overload penalty is increased accordingly. This mechanism implicitly incorporates cold-start effects, since scale-down decisions that increase predicted latency beyond SLA thresholds raise the overload cost, discouraging aggressive deprovisioning. Algorithm 6 formalizes the computation of these cost terms and derives the projected total cost.

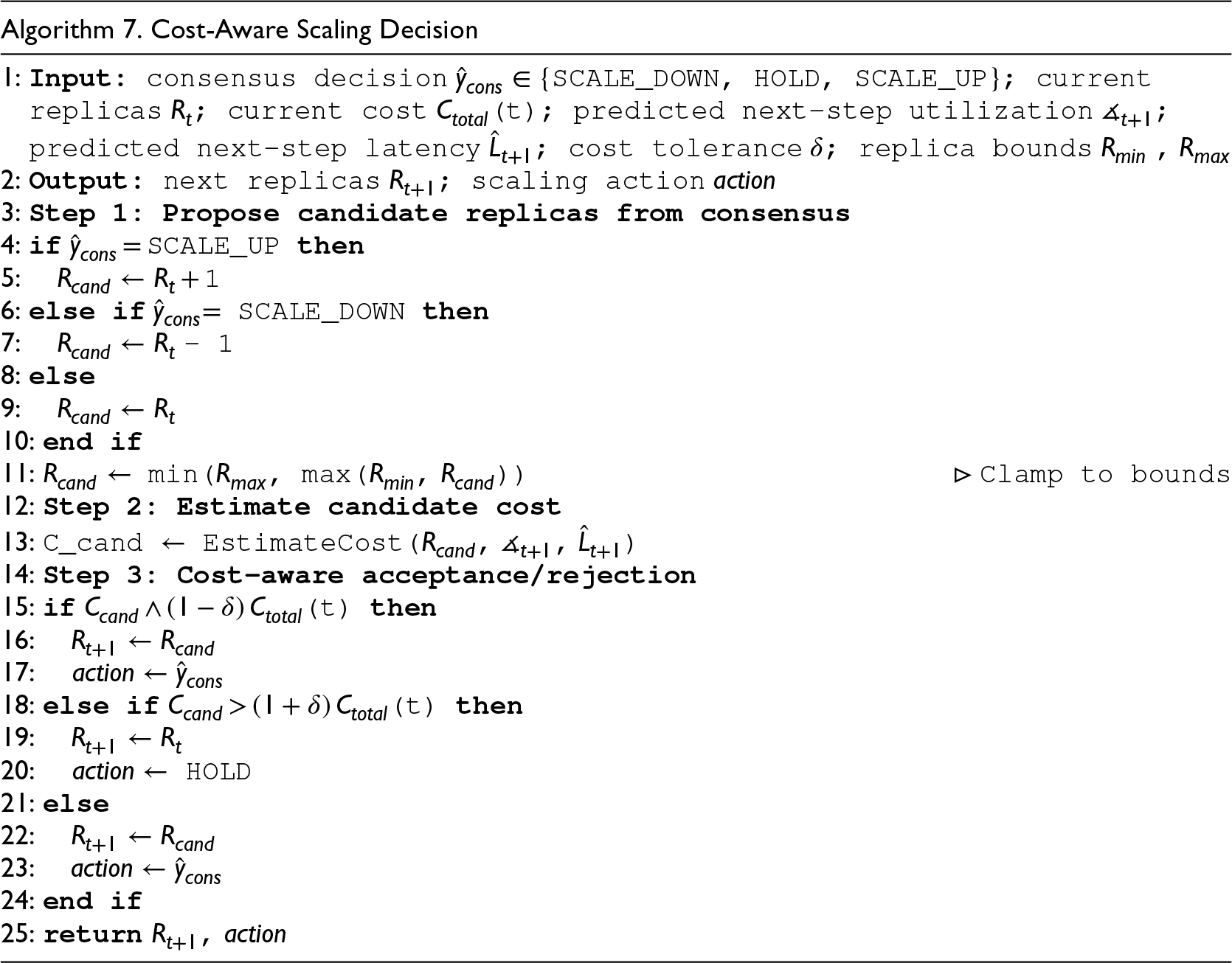
Given a consensus scaling decision, the controller proposes a candidate replica configuration subject to replica bounds. The projected cost of the candidate configuration is then estimated using predicted next-step utilization and latency. Algorithm 7 performs cost-aware acceptance or rejection using a tolerance margin δ. If the candidate cost is sufficiently lower than the current cost, the scaling action is accepted; if it exceeds the allowable tolerance, the action is rejected, and the system holds the current allocation. This comparison-based filtering prevents economically unjustified scaling, particularly scale-down actions that could trigger cold-start latency or SLA degradation. To ensure runtime feasibility, the overall framework remains computationally lightweight. Degree centrality is computed in linear time with respect to the number of dependency edges and can be updated incrementally. The supervised models are intentionally shallow, and inference requires only a small number of matrix operations per control interval. Retraining is performed periodically using a sliding window of recent observations rather than at every step, limiting overhead while preserving adaptability.
Evaluations
The proposed framework is evaluated to assess prediction accuracy, decision stability, and cost impact under dynamic workload conditions. Section 5.1 describes the experimental environment. Section 5.2 details the datasets used for dependency modeling and resource-consumption forecasting. Subsequent sections analyze bottleneck identification, threshold-based scaling behavior, unsupervised baselines, supervised prediction performance, consensus aggregation, and cost-aware decision outcomes.
Environment and implementation
The framework is implemented in Python. TensorFlow and Keras are used to train the supervised learning models, and Pandas supports preprocessing and feature construction. Experiments are conducted in the Google Colab environment.
The implementation follows the modular architecture described in Section 4, including dependency analysis, percentile-based thresholding, supervised forecasting, performance-weighted ensemble aggregation, and cost-aware decision filtering.
Dataset preparation
Overview of the dependency analysis dataset.
Overview of the dependency analysis dataset.

Sample records from the dependency analysis dataset.
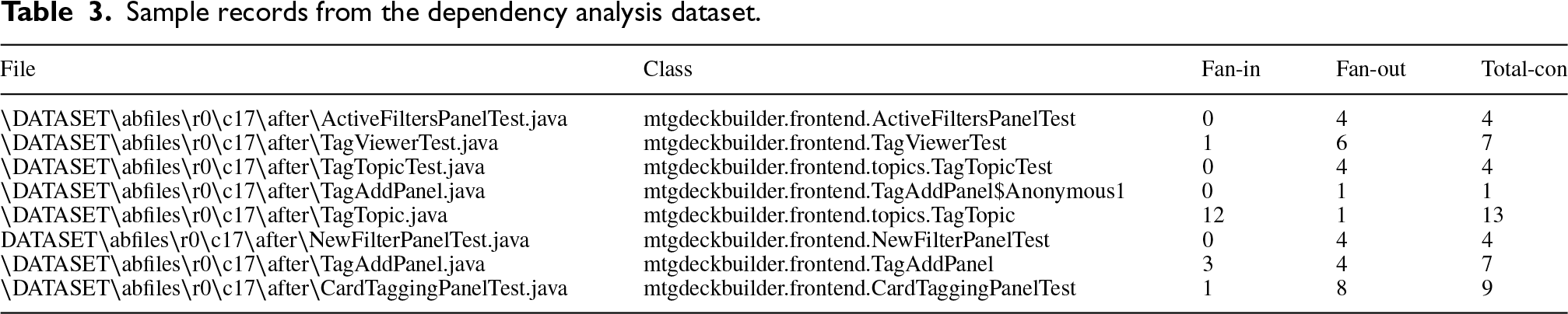
For workload modeling, resource consumption data are obtained from real hardware performance traces collected using OpenHardwareMonitor (Madsen, 2022). The dataset consists of time-series measurements of CPU utilization, per-core CPU usage, memory utilization, and execution time. These traces serve as workload inputs for demand forecasting and autoscaling evaluation. Before analysis, both datasets undergo cleaning and normalization. The dependency dataset is used exclusively to compute centrality scores and identify structurally high-impact nodes. To evaluate bottleneck-aware scaling under realistic workload dynamics, we select representative bottleneck targets based on structural ranking and treat each selected target as the monitored function whose resource time series drives forecasting and scaling decisions. This design isolates the structural prioritization mechanism from workload generation, allowing the dependency-aware control logic to be evaluated using real performance traces without requiring proprietary serverless call-graph data. Table 3 presents representative sample records from the dependency analysis dataset, illustrating the file and class identifiers along with their associated dependency metrics.
The dependency graph constructed from the structural dataset is analyzed to identify high-impact nodes using weighted degree centrality. Figure 4 presents the top bottleneck candidates ranked by normalized centrality score. The most connected node exhibits 224 total dependency connections, followed by nodes with 196 and 137 connections. These nodes interact with a large number of components and therefore are structurally positioned to influence multiple execution paths. In the evaluation pipeline, the highest-ranked node is selected as the bottleneck watch target. Its associated resource time series is used for subsequent forecasting and scaling experiments. To generate baseline scaling decisions, runtime metrics of the selected bottleneck are compared against percentile-based thresholds derived from historical behavior. Upper thresholds correspond to the 95th percentile for CPU utilization, memory usage, and execution time, while available memory uses the 5th percentile to detect critically low capacity. Lower thresholds are defined at the 70th percentile for CPU and memory utilization and the 10th percentile for available memory, introducing hysteresis to reduce oscillatory behavior. Scaling actions are produced using the three-way logic defined in Section 4.3: scale-up is triggered if any metric exceeds its upper bound, scale-down occurs only when all metrics fall below their lower bounds, and hold is issued otherwise. Grounding thresholds in empirical distributions reduces sensitivity to transient fluctuations while preserving responsiveness to sustained load increases. In addition to serving as a baseline controller, this threshold mechanism provides consistent action labels for supervised model training and for mapping unsupervised clusters to discrete scaling decisions.

Bottleneck candidates ranked by normalized degree centrality.
We evaluate K-Means, SOM, and PCA-based clustering to assess whether unlabeled grouping of resource traces can recover scaling decisions without supervision. Cluster assignments are post-processed using majority voting to map each cluster to one of the three scaling actions (scale-down, hold, scale-up), ensuring comparability with supervised classifiers. Figure 5 presents K-Means clustering visualized using t-SNE. While the projection reveals partially distinguishable groups, the clusters do not align consistently with scaling labels, resulting in an accuracy of 49.5%. Figure 6 shows SOM-based clustering. The resulting clusters exhibit substantial overlap between scaling categories, and decision alignment accuracy drops to 21.6%. Figure 7 presents K-Means clustering applied after PCA dimensionality reduction. The projection fails to meaningfully separate scaling behaviors, producing near-random performance with an accuracy of 0.6%. These results demonstrate that unsupervised pattern discovery, even when visually separable in reduced-dimensional space, does not reliably recover the control logic required for autoscaling. Structural grouping alone is insufficient to capture the directional decision boundaries needed for scale-up and scale-down actions.
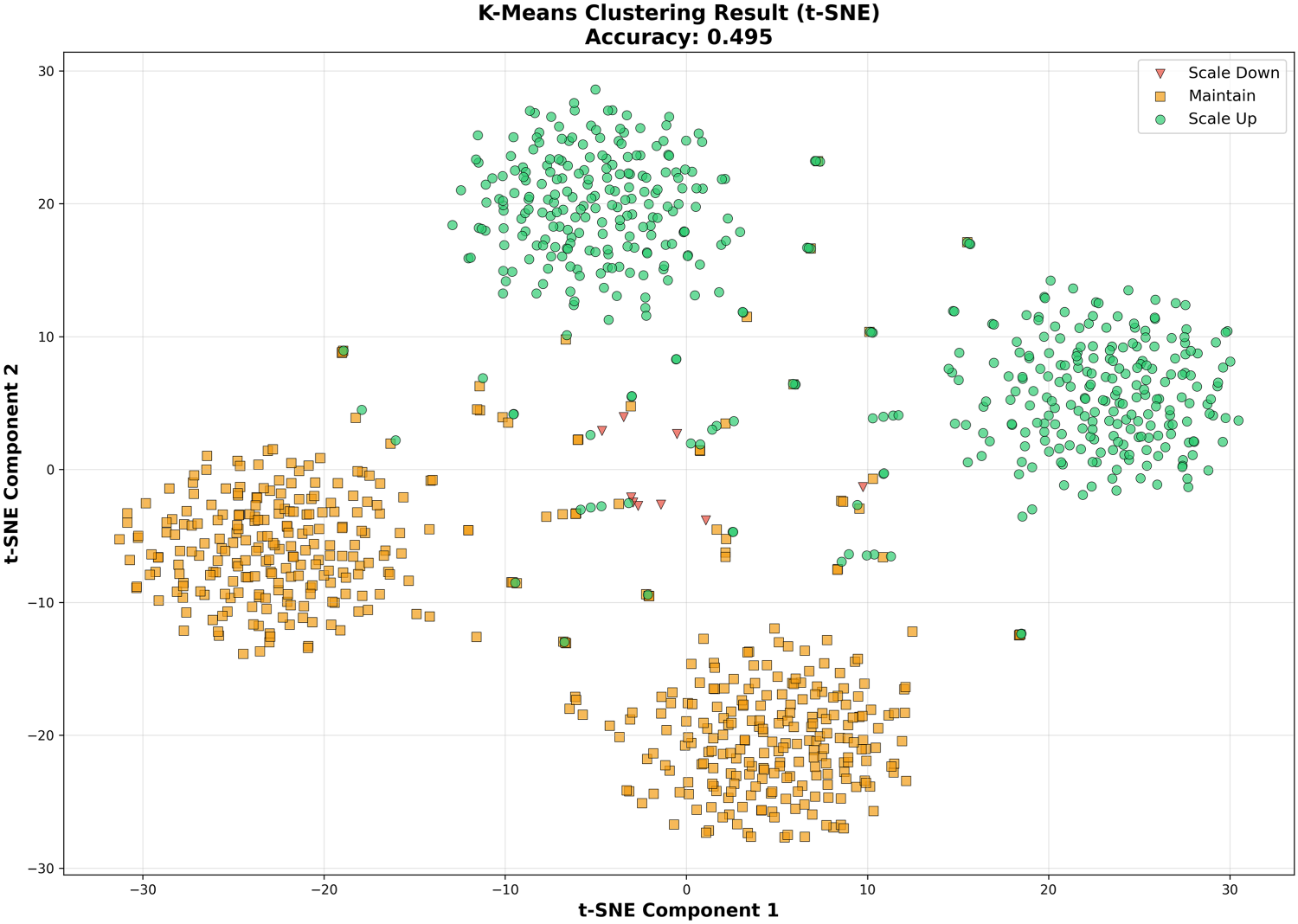
K-Means clustering results visualized with t-SNE.
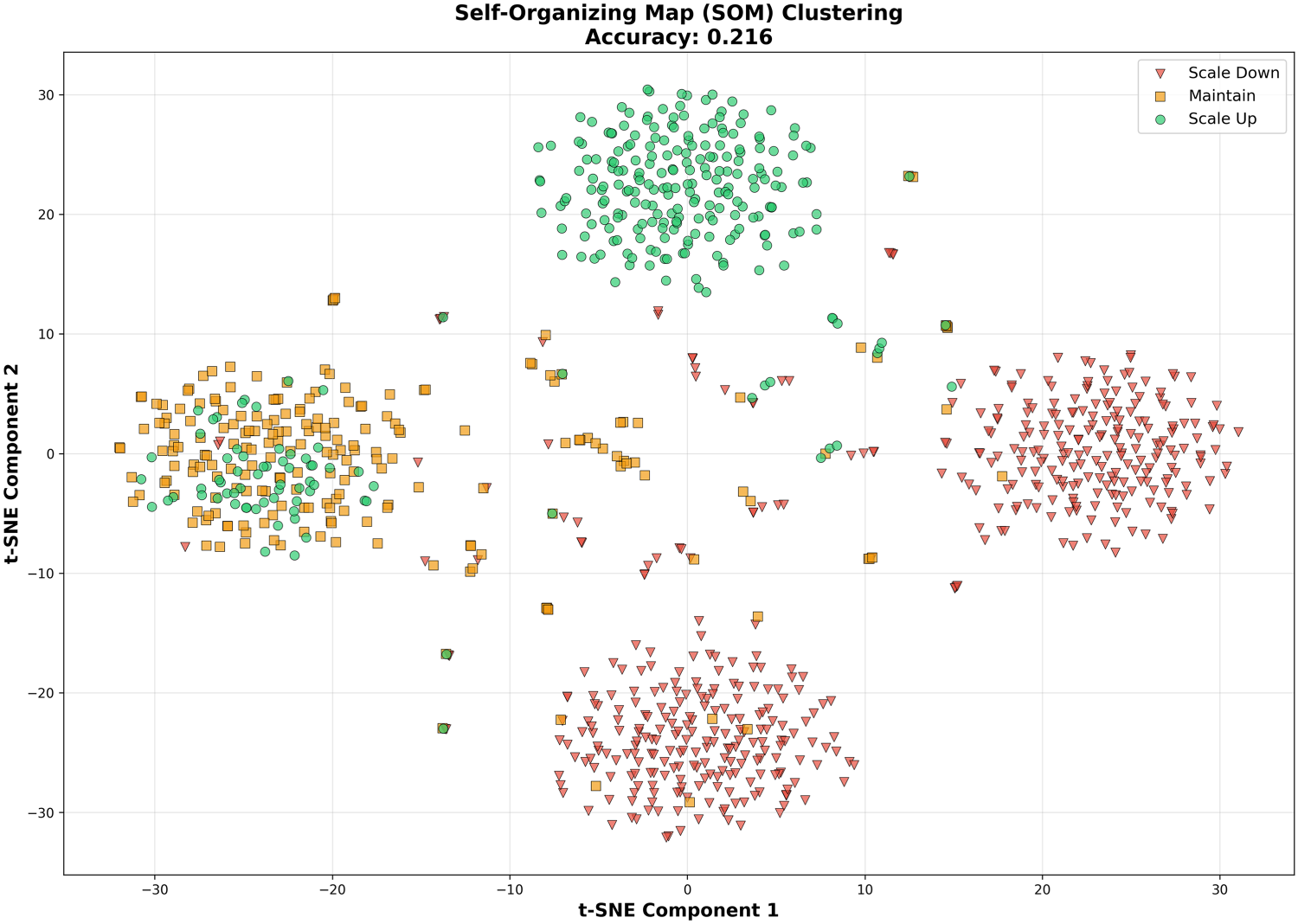
SOM clustering visualized with t-SNE.
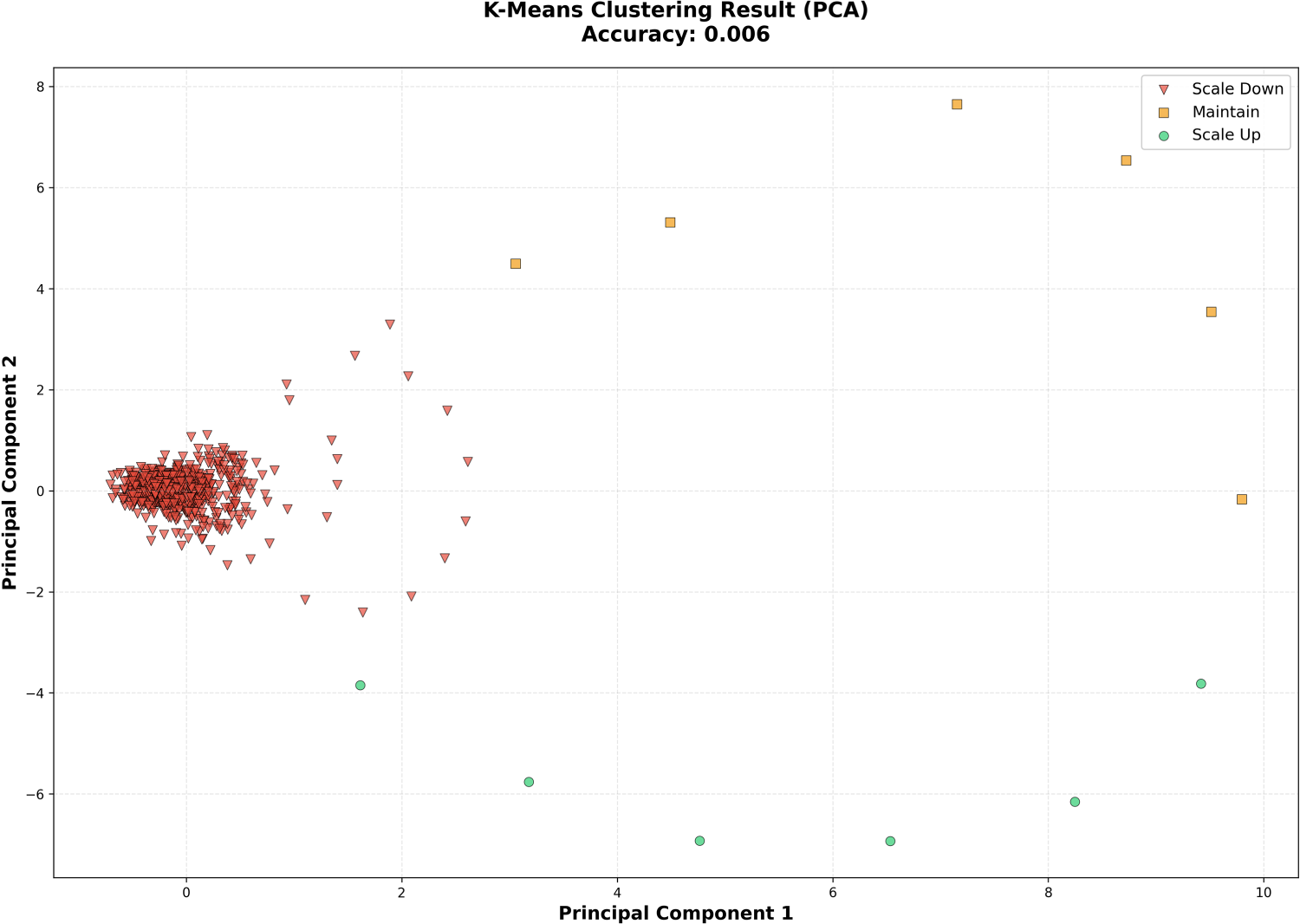
K-Means clustering results visualized with PCA.
Table 4 compares unsupervised clustering approaches with supervised neural models (MLP, LSTM, and CNN) under identical input features. The supervised models achieve consistently high predictive performance. The LSTM obtains the highest average accuracy (99.06%), followed by MLP (98.75%) and CNN (98.50%). Precision, recall, and F1-scores exceed 0.98 across models, indicating stable classification across scaling categories. Error metrics (MAE and MSE) are correspondingly low.
Comparative performance analysis of supervised and unsupervised approaches for autoscaling decision prediction.
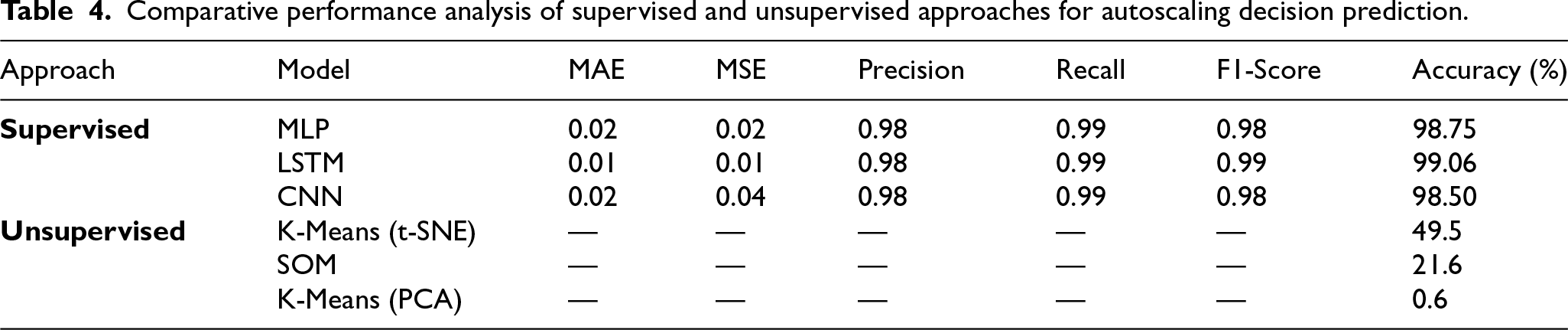
In contrast, the strongest unsupervised baseline (K-Means with t-SNE visualization) achieves only 49.5% accuracy, while SOM and PCA-based clustering perform substantially worse. The large performance gap of nearly 50% points indicates that labeled supervision is critical for accurate autoscaling decision generation. These findings confirm that clustering-based pattern discovery cannot substitute for predictive modeling in time-sensitive scaling control. Consequently, the final controller relies on supervised forecasting combined with consensus aggregation rather than unsupervised grouping.
In the supervised phase, autoscaling is formulated as a three-class classification problem using labels generated by the adaptive threshold mechanism described in Section 4.3. The dataset is divided into 80% training, 10% validation, and 10% for testing. To assess generalization, five-fold cross-validation is performed. Model performance is evaluated using accuracy, precision, recall, F1-score, MAE, MSE, and RMSE. Figure 8 represents the training and validation curves for the MLP, LSTM, and CNN models over 100 epochs. All three architectures converge rapidly during early training and stabilize thereafter. Training and validation curves remain closely aligned across accuracy, MAE, and MSE, indicating minimal overfitting. Among the models, the LSTM exhibits the most stable convergence with consistently smooth validation curves. The MLP shows slightly greater variability, while the CNN maintains stable behavior but with marginally higher final error values. These learning dynamics indicate that all models are well-regularized and suitable for real-time inference.
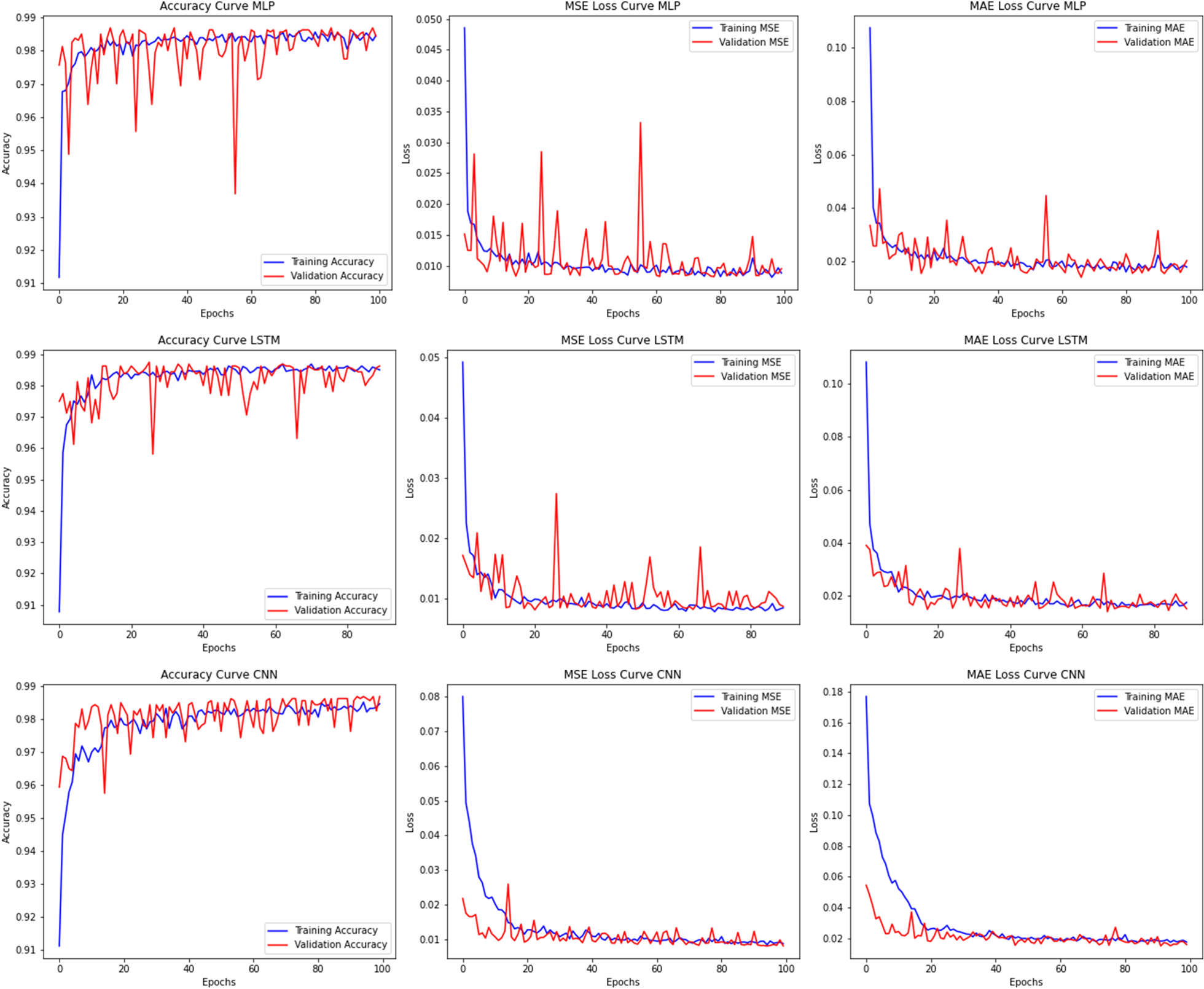
Training and validation performance of the supervised learning models (MLP – first row, LSTM – second row, CNN – third row) over 100 epochs. The columns report classification accuracy, MSE, and MAE. All models demonstrate stable convergence with closely aligned training and validation curves, with the LSTM exhibiting the most consistent and robust performance.
Figure 9 compares final error metrics across models. The LSTM achieves the lowest MAE, MSE, and RMSE values, confirming its strong temporal modeling capability. The MLP demonstrates competitive performance with slightly higher error values. The CNN performs well overall but exhibits higher variability in certain folds. The five-fold cross-validation results in Tables 5–7 further support these findings. The LSTM consistently achieves the lowest error and highest stability across folds. Although all supervised models outperform unsupervised baselines by a large margin, the LSTM provides the strongest standalone predictor.
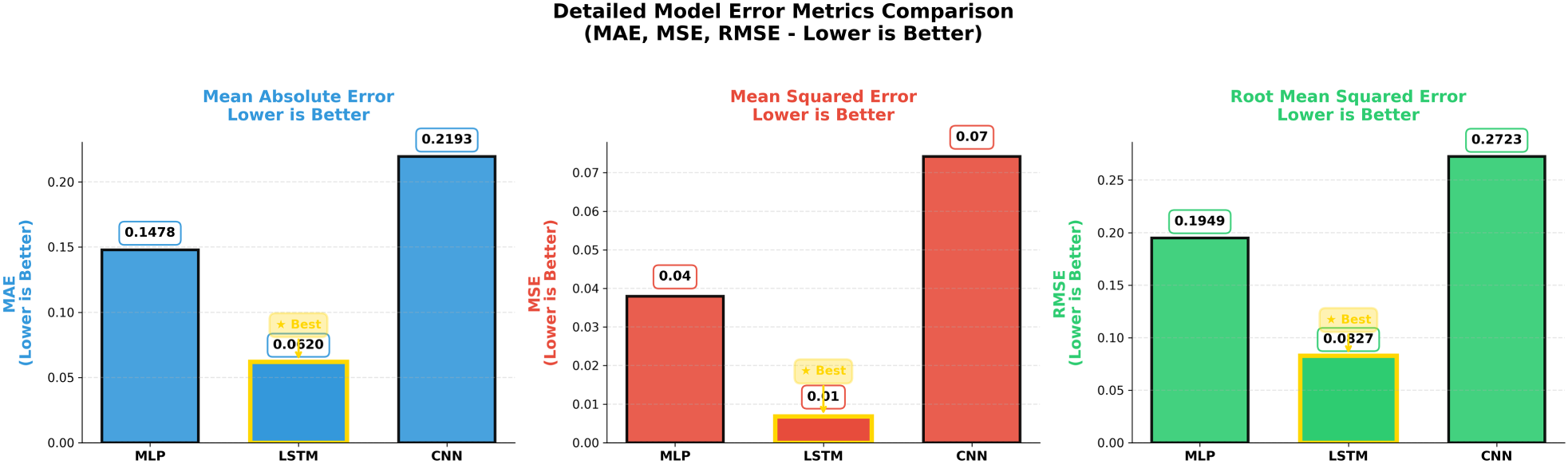
Comparative evaluation of prediction error metrics for the MLP, LSTM, and CNN supervised models. The models are assessed using MAE, MSE, and RMSE, where lower values indicate better performance.
Five-fold cross-validation performance of the MLP model, including MAE, MSE, F1-score, recall, precision, and accuracy across folds and averaged results.
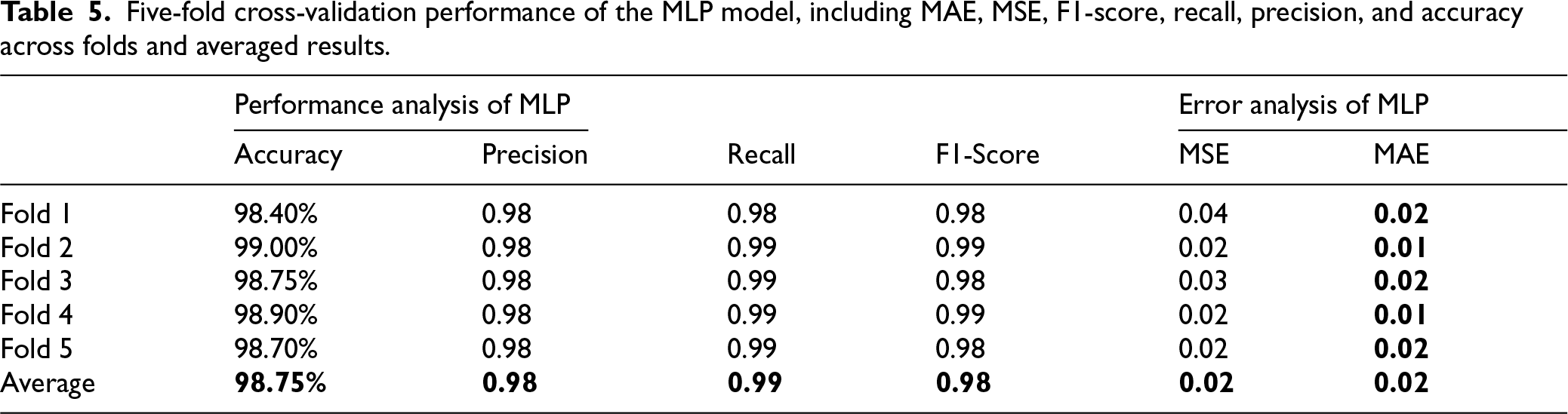
Five-fold cross-validation performance of the LSTM model, including MAE, MSE, F1-score, recall, precision, and accuracy across folds and averaged results.
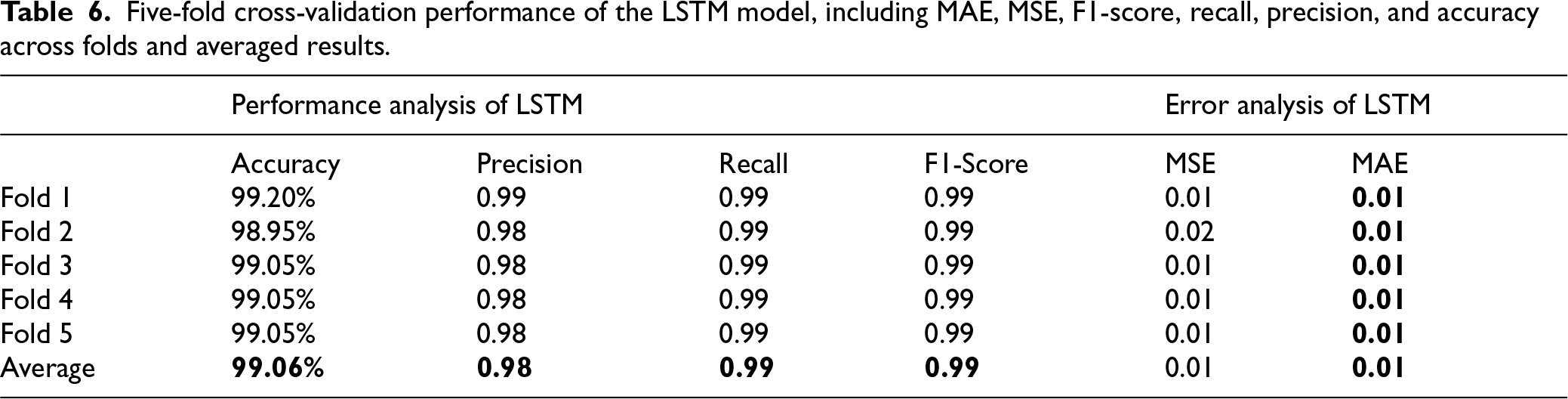
Five-fold cross-validation performance of the CNN model, including MAE, MSE, F1-score, recall, precision, and accuracy across folds and averaged results.
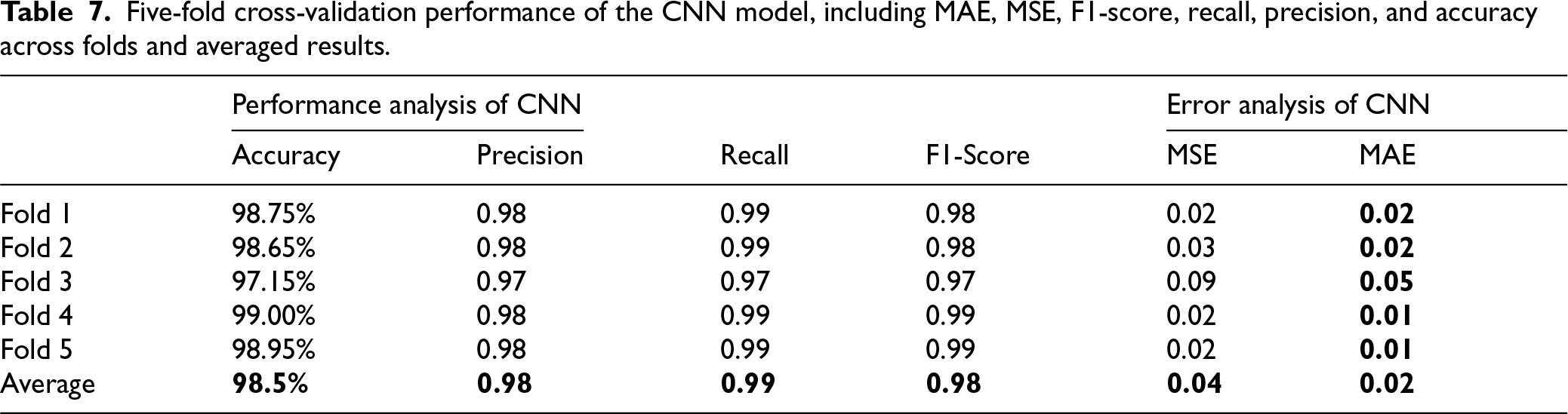
Tables 8 and 9 compare individual model predictions with the performance-weighted probabilistic ensemble for representative samples at time t and one-step-ahead forecasts t + 1. While individual predictors occasionally deviate from actual values, the ensemble consistently reduces extreme deviations by weighting model outputs according to validation performance. When a single model underestimates or overshoots resource demand, the aggregated prediction moderates the error through probabilistic averaging. This behavior demonstrates that consensus aggregation reduces reliance on any single model and improves stability under workload variability. The ensemble prediction tracks actual resource values more consistently than individual models, supporting the design choice of performance-weighted fusion in the final controller.
Comparison of actual and predicted resource values at the current time step (t) using MLP, LSTM, CNN, and Bayesian-inspired model averaging.

Comparison of actual and predicted resource values at the next time step (t + 1) using MLP, LSTM, CNN, and Bayesian-inspired model averaging.
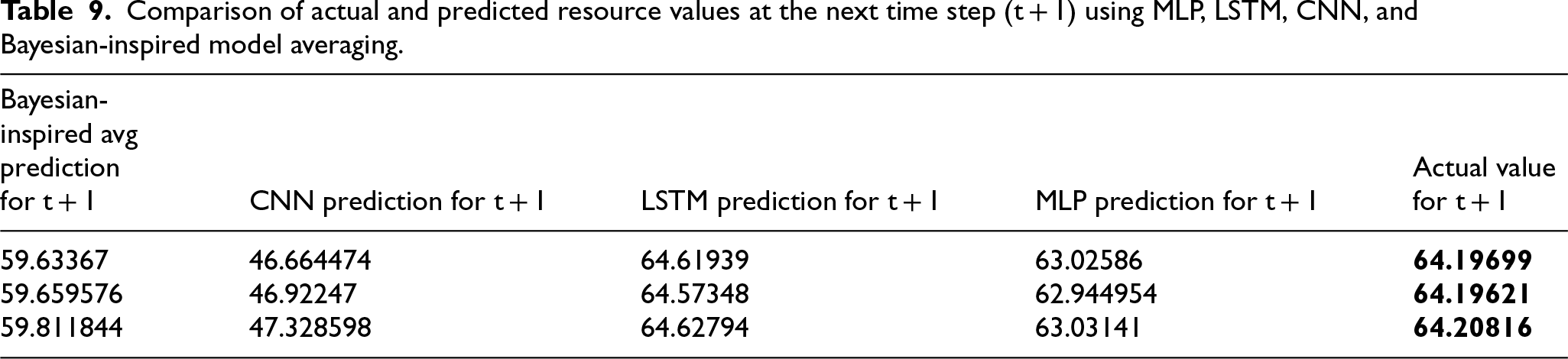
To position the proposed framework within the current literature, we compare it against recent neural forecasting architectures, including hybrid and ensemble approaches (Javeed et al., 2025; Ouhame et al., 2021; Sabyasachi et al., 2024; Taha et al., 2024; Vaghasia et al., 2025). All methods are evaluated using the same workload traces and performance metrics to ensure a fair comparison. Unlike hybrid architectures that merge multiple networks into a single composite predictor (e.g., CNN–LSTM or MLP–LSTM), the proposed framework maintains model diversity by training independent predictors and aggregating their outputs using a performance-weighted probabilistic ensemble. This design preserves complementary signal representations while reducing sensitivity to noise, local minima, and workload drift. Table 10 summarizes the comparative results. The proposed approach achieves the highest overall accuracy and the lowest MAE, MSE, and RMSE among all evaluated methods. In comparison, the closest competing hybrid model (CNN–LSTM Ouhame et al., 2021) achieves 99.85% accuracy with a higher MSE (0.0060). Deep CNN–LSTM (Sabyasachi et al., 2024) reports 99.62% accuracy and higher error values across all metrics. The MLP–LSTM hybrid (Taha et al., 2024) achieves 99.49% accuracy but exhibits nearly four times higher MSE than the proposed approach. Traditional machine learning models (Javeed et al., 2025) achieve substantially lower accuracy (75.03%) and significantly higher error rates. The proposed framework improves accuracy by up to 4.85% points over traditional ML baselines and achieves substantial reductions in MSE relative to hybrid deep models. In addition to predictive accuracy, the proposed method explicitly incorporates cold-start awareness within its cost-aware control logic, whereas the compared forecasting models focus solely on prediction performance without integrating scaling control or SLA-aware filtering. These results demonstrate that separating model expertise and reconciling predictions via performance-weighted aggregation yields both improved quantitative accuracy and greater robustness than monolithic hybrid architectures.
Performance comparison of the proposed ensemble approach with representative baseline methods. The proposed method achieves superior predictive accuracy and error reduction while explicitly addressing cold-start effects.
Performance comparison of the proposed ensemble approach with representative baseline methods. The proposed method achieves superior predictive accuracy and error reduction while explicitly addressing cold-start effects.
We evaluate the economic impact of the proposed controller while maintaining response latency near the target SLA. The controller forecasts near-term demand at one-minute intervals and converts predictions into discrete scaling actions. A cooldown mechanism limits oscillatory behavior, and scale-down decisions are issued only when predicted demand remains low and latency stays within a guard band. Scale-to-zero is applied selectively based on projected economic benefit and anticipated cold-start impact. At each decision step, the total cost is computed using platform-specific pricing models. For function-based services, cost includes request charges and memory-time billing, whereas container-based services use vCPU- and memory-second pricing. The cost formulation incorporates overload penalties and SLA violation indicators. Cold-start effects are modeled indirectly: scale-down actions that increase predicted latency beyond the SLA threshold incur additional penalty, reflecting the expected delay when insufficient warm capacity is available. This penalty discourages aggressive deprovisioning that could otherwise produce economically unfavorable latency spikes.
Figure 10 reports total infrastructure cost and corresponding savings relative to a reactive threshold-based baseline. Across all evaluated platforms, the predictive controller consistently reduces total cost while preserving performance targets. On AWS Lambda, the cost decreases from $0.70 to $0.47. On Google Cloud Run, the cost decreases from $9.48 to $6.36. On Azure Functions, the cost decreases from $0.68 to $0.45. Under a generic container pricing model, the cost decreases from $6.01 to $4.03. The aggregated savings across platforms amount to $5.55 relative to the reactive baseline. These savings result from two complementary effects. First, proactive scale-up mitigates prolonged latency excursions that would otherwise trigger delayed and excessive reactive scaling. Second, controlled scale-down reduces idle replica time while avoiding SLA violations and cold-start penalties. Together, these mechanisms demonstrate that dependency-aware predictive autoscaling can achieve economically efficient resource allocation without compromising responsiveness or stability.
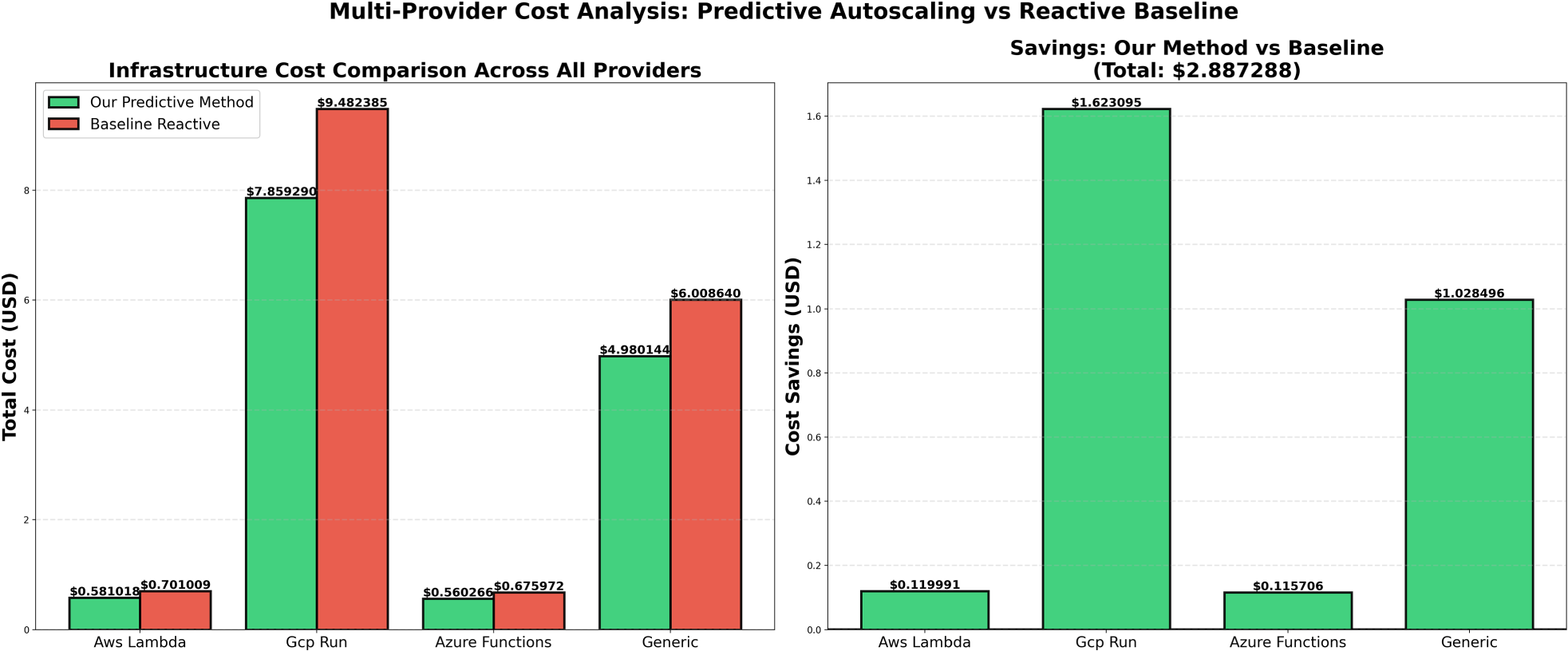
Total infrastructure cost and corresponding savings achieved by the proposed predictive autoscaling method.
This paper presents a dependency-aware autoscaling framework for serverless environments that addresses structural, predictive, and economic limitations of existing approaches. By modeling function interactions as a directed dependency graph and identifying structurally influential bottlenecks using degree centrality, the framework prioritizes scaling actions on components with the greatest end-to-end impact. Near-term resource demand is predicted using lightweight supervised models (MLP, LSTM, and CNN), and their outputs are reconciled through a performance-weighted probabilistic ensemble to improve stability and reduce sensitivity to model-specific bias. Our approach incorporates cold-start awareness and cost-comparison logic to balance latency guarantees with operational efficiency. Experimental results demonstrate that supervised learning substantially outperforms unsupervised clustering for autoscaling decision generation. The proposed ensemble approach achieves higher predictive accuracy and lower error than representative hybrid forecasting models while maintaining stable training dynamics. End-to-end experiments across multiple pricing models show consistent cost reductions, without compromising SLA targets. Overall, this work shows that integrating dependency-aware bottleneck targeting, supervised multi-model forecasting, and cost-aware control yields a robust and economically efficient solution for practical serverless autoscaling.
Future work
Although the proposed framework advances dependency-aware and ensemble-based autoscaling, several directions remain for further improvement in adaptability, scalability, and interpretability. These extensions aim to evolve the framework from predictive autoscaling toward more adaptive and intelligent resource management in next-generation serverless systems.
Federated learning may enable collaborative model training across multiple serverless platforms without sharing raw workload data. This approach would allow platforms to benefit from shared knowledge while preserving privacy. Open challenges include handling workload heterogeneity, personalizing global models to local behavior, and ensuring secure and stable aggregation of distributed updates. Deploying the proposed framework on real FaaS platforms such as AWS Lambda or Knative would enable evaluation under fully operational conditions. Integrating dependency inference, workload forecasting, and actuation within live systems would support analysis of long-term stability, convergence behavior, and tail latency performance under bursty and non-stationary demand. Quantum-inspired optimization offers a potential avenue for improving scalability in large dependency graphs. By formulating scaling decisions as multi-objective optimization problems, such heuristics may provide efficient approximations for jointly optimizing latency, cost, and resource utilization in complex systems. Graph neural networks (GNNs) could extend the framework to dynamic dependency modeling. Unlike static graph metrics, temporal GNNs may learn evolving interaction patterns and detect emerging critical paths, enabling earlier bottleneck identification and more proactive resource allocation. Incorporating causal inference into the autoscaling logic may enhance both robustness and interpretability. By identifying which factors directly cause latency or overload, rather than relying only on correlated signals, the controller can make more reliable scaling decisions when workload patterns change and provide clearer explanations for its actions.
Footnotes
Ethical approval and consent to participate
This article does not contain any studies with human participants or animals performed by any of the authors.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Availability of data and material
Derived data supporting the findings of this study are publicly available in a GitHub repository and can be shared upon request.