
Abstract
Background
With the increasingly widespread application of artificial intelligence technology, generative artificial intelligence has become an important tool for people to obtain health information due to its convenience and flexibility in health education or health promotion. However, the readability and accuracy of such AI-generated materials still need to be evaluated.
Objective
To comprehensively evaluate and compare the quality and readability of health education texts about diabetes generated by different generative artificial intelligence (AI) models.
Methods
We followed a fixed list of ten questions without modifications, systematically presenting the same inquiries to seven generative AI models and exporting their results into defined forms in the text generation process. Five experts were invited to evaluate the texts based on five criteria. The readability index, a readability formula, was used to evaluate the text’s readability. Kendall’s coefficient of concordance was employed to assess inter-rater reliability. The linear mixed model was used to compare the differences in five dimensions and readability among the health education texts generated by different AI models.
Results
Kimi-K1.5 and Doubao attained the highest overall scores in scientific accuracy, whereas iFlytek Spark-V3.5 received lower scores compared to other models. In terms of practical value and logical clarity, Kimi-K1.5 received the highest scores, while iFlytek Spark-V3.5 scored the lowest. In the dimension of reference basis, Kimi-K1.5 and ERNIE Bot-3.5 received relatively high scores, while iFlytek Spark-V3.5 and Doubao scored lower. In the assessment of text readability, higher R-value scores indicate poorer readability. The health education text generated by Doubao had the highest R-value, while iFlytek Spark-V3.5 had the lowest R-value.
Conclusions
Kimi-K1.5 performed better across multiple assessment parameters in the overall evaluation of diabetes-related health education texts created by different generative AI models. Notably, among all the models tested, iFlytek Spark-V3.5 showed the best readability.
Introduction
Diabetes mellitus (DM), including both type 1 and type 2 diabetes, is widely recognized as a threat to public health worldwide due to the huge disease burden.1,2 It was reported that the number of adults with diabetes worldwide reached approximately 589 million in 2024. Without effective prevention, this number is projected to reach 853 million by 2050, with over 90% of affected individuals estimated to have type 2 diabetes. 3 In China, the number of people with diabetes already exceeds 118 million, representing 22% of the global total. 4 In addition, the limited public awareness of diabetes also increased the difficulties of prevention and control of DM.5,6 Therefore, increasing the diabetes-related literacy of the public is crucial for diabetes prevention.
With the continuous advancement of artificial intelligence (AI), its applications in healthcare have become increasingly widespread, spanning areas such as early disease diagnosis and medical image analysis.7–9 In recent years, the application scope of AI has gradually expanded from clinical practice to health education, with generative AI emerging as an important tool for disseminating medical knowledge.10–12 More and more people are using generative artificial intelligence to access and share relevant health information, leveraging their advanced learning abilities.13,14 Healthcare professionals can utilize these tools to systematically organize knowledge pertaining to specific diseases, whereas non-specialists may gain preliminary insights into medical conditions through interactive dialogues. The use of Generative AI in health education not only enhances efficiency but also increases accessibility and equity in information dissemination.15,16 Several studies have assessed the quality and readability of health education materials produced by generative AI on cardiac disease. And the results showed that the texts produced by generative AI were either overly complex or varied in quality.17–19 Although some studies have assessed the readability and quality of generative artificial intelligence in producing health education texts for specific diseases, existing research predominantly focuses on individual models or limited comparisons among a few mainstream models. It lacks systematic evaluation across multiple models, particularly in the Chinese-language context. Given the rapid evolution of generative AI models and the ongoing need for extensive research across diverse medical themes,20–22 coupled with the expanding influence of these models, the systematic evaluation of health education texts generated by such technologies remains of critical importance.
Currently, few studies have systematically evaluated the generative AI-produced health education texts from medical professionalism, factual accuracy, logical coherence, readability, and alignment with user needs. Most existing research focuses either on model generation capabilities or isolated quality features,17,18 lacking a comprehensive assessment framework that integrates multiple metrics such as the reliability of scientific evidence, clarity of expression, potential biases, and ethical standards. Hence, a comprehensive evaluation of the quality and readability of artificial intelligence-generated health education texts is imperative. Additionally, different generative AI models varied significantly in the accuracy of specialized knowledge and application skills. A systematic assessment focusing on the accuracy, professionalism, and readability of health education texts produced by different AI models could help the public to recognize the differences and limitations among these models and facilitate the selection of appropriate models based on individual needs. As a consequence, this research not only guides users in selecting more appropriate AI tools but also provides constructive feedback to developers, ultimately enhancing the value of AI in promoting health literacy.
Hence, this study chose diabetes as a representative case and systematically evaluated the quality of diabetes education texts generated by various generative artificial intelligence models, employing the multi-dimensional evaluation framework for AI-generated health education content developed by Yang X et al. 23 and the text readability calculation formula. The findings aim to furnish practical guidance for both professionals and non-specialists in selecting appropriate models, while also providing critical insights for optimizing model performance and effectively utilizing such tools to produce high-quality, highly accurate, and easily comprehensible health education texts.
Methods
Selection of generative AI large models
This study selected seven generative AI large models that were widely used: ERNIE Bot-3.5, iFlytek Spark-V3.5, Kimi-K1.5, ChatGPT-4o, Tiangong-AI2.2.0, Doubao Large Model, and Deepseek-R1. All of these models have received official approval and were accessible to users freely. To ensure objectivity and reliability and reduce potential subjective bias, this study adopted a blinding process, numbering the selected models sequentially as Model 1 to Model 7.
Generation of diabetes-related health education texts
Inter-rater reliability of expert assessments.
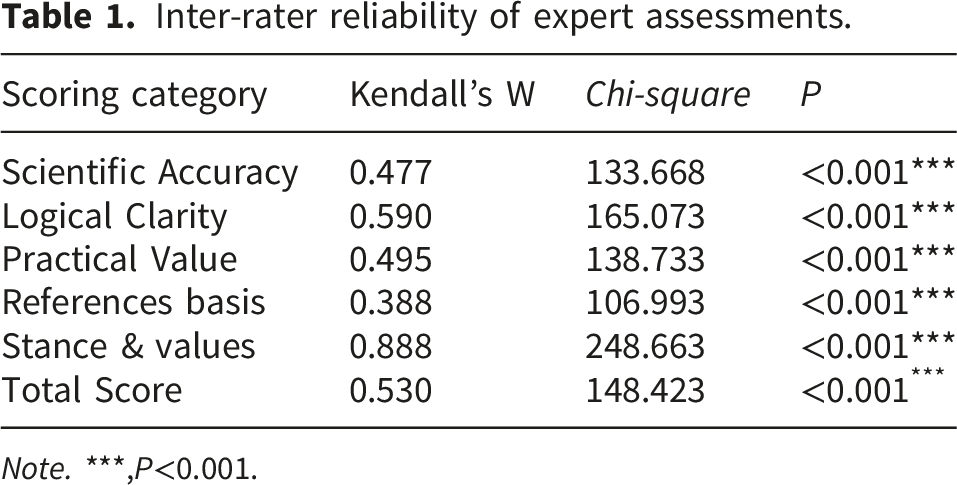
Note. ***,P<0.001.
Quality evaluation of the generated diabetes-related health education texts
Five experts were invited to evaluate the quality of the generated texts, including one chief nurse and one chief physician from the endocrinology department of a tertiary hospital, two registered staff nurses, and one PhD in Nursing Science. All experts had more than five years of clinical experience and professional background in diabetes health education and clinical practice guidelines. During the evaluation, assessors were blinded to the model sources and conducted independent evaluations without consultation. Five criteria, including scientific accuracy, logical clarity, practical value, quality of references, and stance & values, were assessed. Each criterion was scored on a scale of 1 to 20 points, 23 with specific evaluation criteria presented in Supplemental Table 2.
Readability evaluation of the generated diabetes-related health education texts
Text readability denotes the degree to which a text can be easily read and comprehended. This serves as a fundamental metric for evaluating the complexity of a text and is a primary focus in graded reading research. 25 This study used the formula R = 17.5255 + 0.0024X1 + 0.04415X2 − 18.3344(1 − X3) to calculate readability, 26 where X1 is the total number of characters in the text, excluding punctuation; X2 is the average sentence length (X2 = total number of characters/number of sentences); X3 represents the proportion of medical professional terms (X3 = total number of professional terms/total number of characters). A smaller R value indicates that the text is easier to read, and the range of R values corresponds to the required grade level for reading. This readability formula was created by Jing for evaluating the readability of textbook texts. Li adapted it and applied it to the field of company financial statements. Subsequently, it gradually expanded to the evaluation of readability in health education texts. 27 This study used the readability formula adapted by Li. The total character count and sentence number were counted in WPS documents. Chinese medical terms were identified using exact string matching with forward maximum matching to prevent redundant counting from partial substrings. English terms and abbreviations were extracted using case-insensitive regular expression matching with word boundary constraints to ensure whole-word recognition. All terms were matched against the Common Clinical Medical Terms (2023 Edition) and SinoMed Medical Subject Headings. The extracted terms were subsequently manually reviewed to exclude common daily health expressions (e.g., diabetes, malnutrition, infection) based on team consensus. Although these terms appear in medical dictionaries, they were classified as plain health vocabulary suitable for readers with primary school-level education. 28
Statistical analysis
Statistical analyses were performed using R software (version 4.3.1) and SPSS statistical software (version 27.0). Residuals of the linear mixed-effects models were approximately normally distributed, supporting the validity of parametric analyses. Linear mixed-effects models were used to compare expert ratings across 5 dimensions and readability scores of texts generated by different AI models. For expert ratings, dimension scores were set as dependent variables, with AI models as fixed effects (main effect) and questions/experts as crossed random intercepts. For text readability analysis, the readability R value served as the dependent variable, AI models as fixed effects, and questions as random effects. Post-hoc pairwise comparisons for statistically significant results were conducted using Bonferroni-corrected P-values. Statistical significance was defined as P < 0.05 for all analyses. Forest plots were generated using the ‘ggplot2’ package in R to visualize the estimated marginal means (EMMs) and 95% confidence intervals (CIs) of each AI model across different dimensions, with error bars representing 95% CIs for intuitive comparison. Inter-rater reliability of expert evaluations was evaluated using Kendall’s coefficient of concordance (W) with SPSS statistical software.
Results
Overall evaluation of diabetes-related health education texts generated by AI models
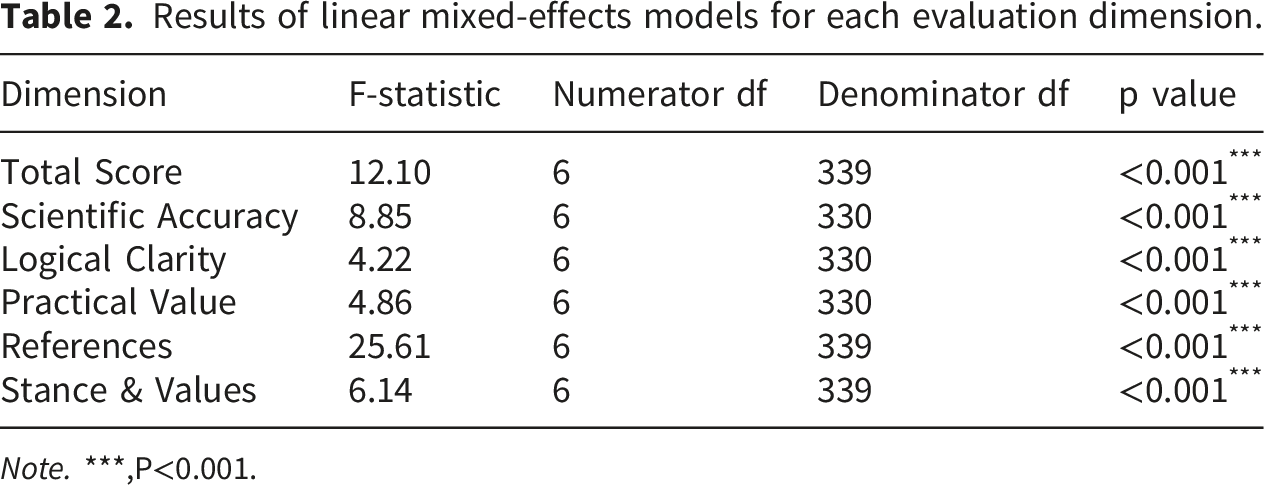
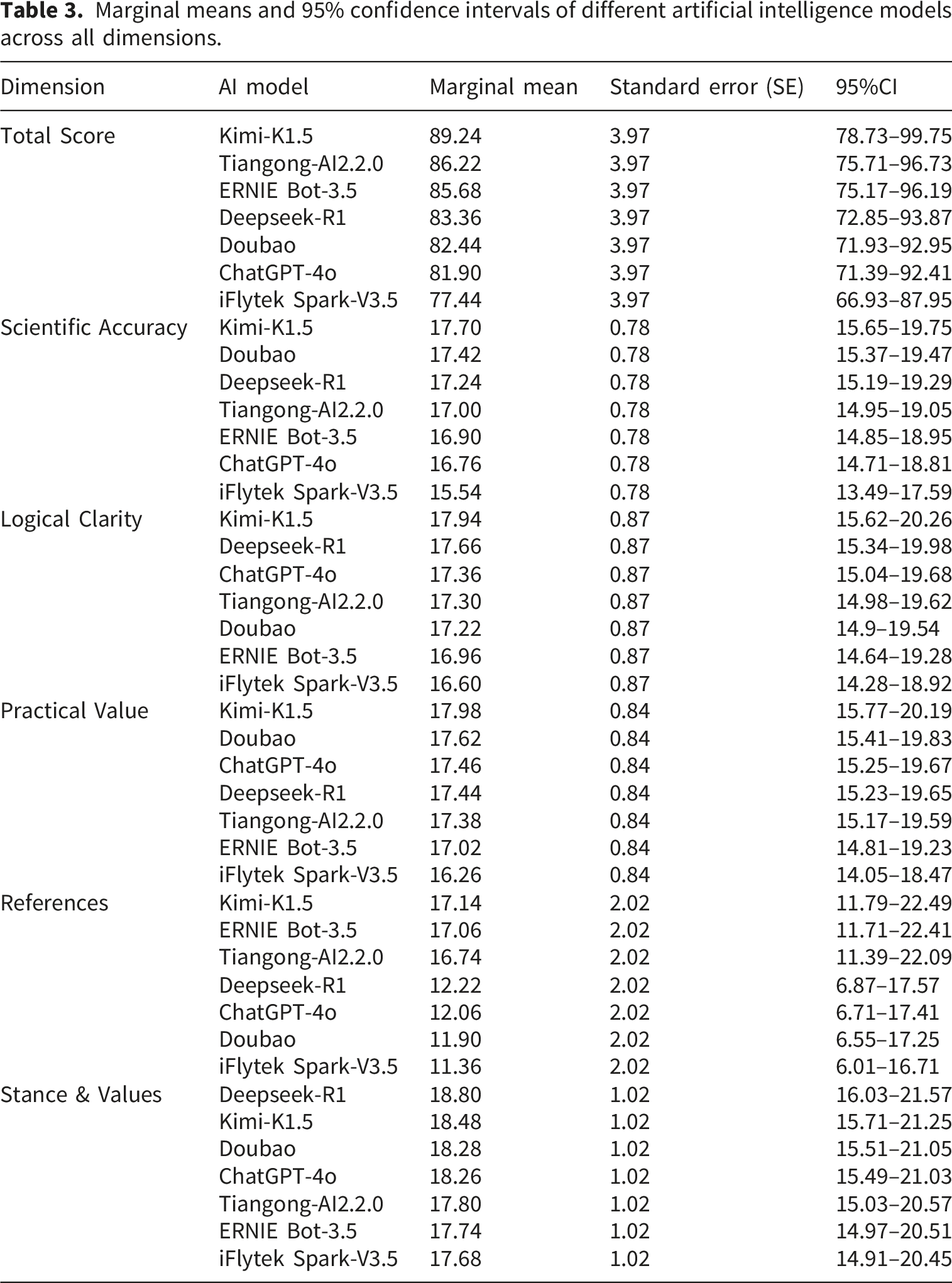
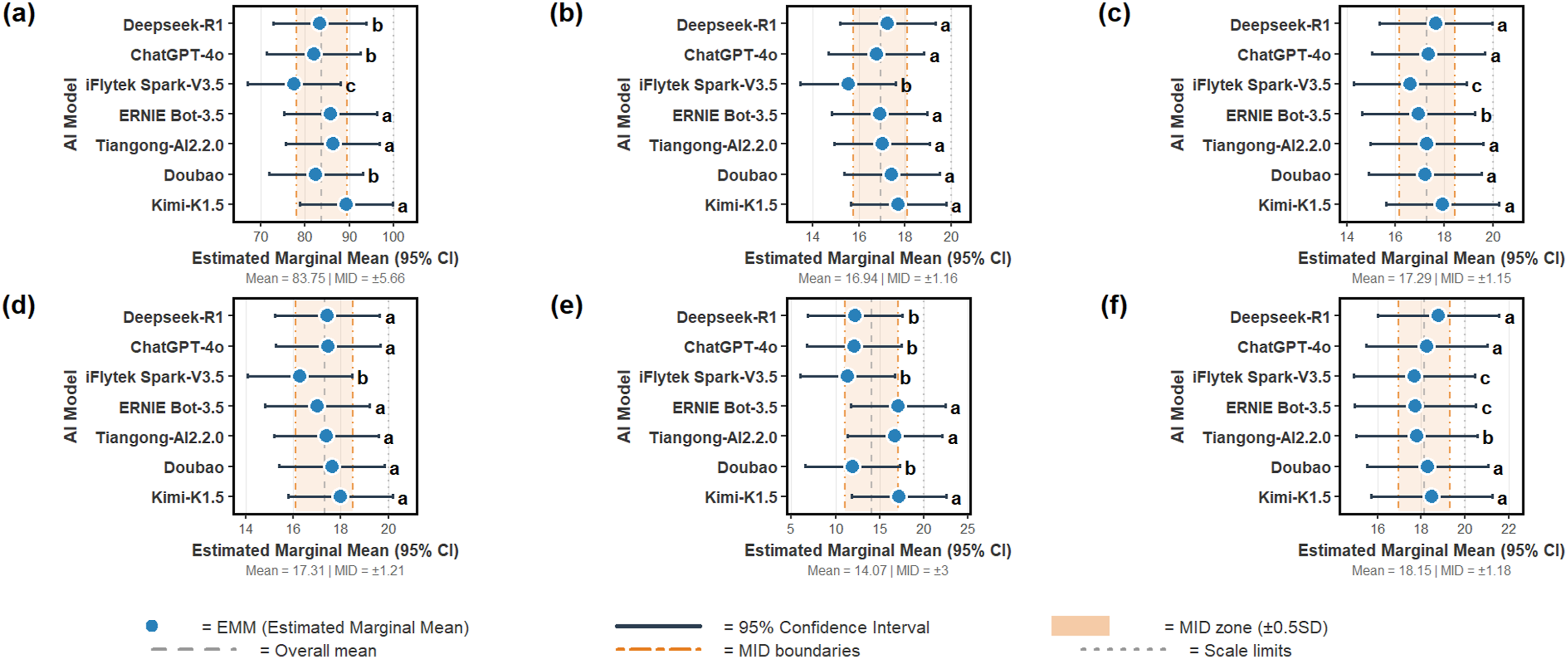
The Cronbach’s alpha coefficient for these 5 rating dimensions was 0.601. The educational texts generated by the seven models were assessed by five experts. Kendall’s W coefficient was 0.530 for the total score, respectively (P < 0.001). Detailed results were presented in Table 1. A graphical representation of the mean score given by five experts for each generative AI model across different dimensions was shown in Figure 1. For the total score, linear mixed-effects models revealed a significant main effect of AI model (F = 12.10, df = 6, 339, P < 0.001). Detailed results were presented in Table 2. Among all AI models, Kimi-K1.5 achieved the highest estimated marginal mean total score of 89.24, while iFlytek Spark-V3.5 obtained the lowest score of 77.44. The detailed marginal means and 95% confidence intervals were shown in Table 3. Post hoc pairwise comparisons with Bonferroni correction showed that Kimi-K1.5, Tiangong-AI2.2.0, and ERNIE Bot-3.5 scored significantly higher than iFlytek Spark-V3.5 (P < 0.05). Similarly, Doubao, ChatGPT-4o, and Deepseek-R1 also exhibited significantly higher total scores than iFlytek Spark-V3.5 (P < 0.05), but no significant differences were observed among these three models, nor between them and Kimi-K1.5, Tiangong-AI2.2.0, or ERNIE Bot-3.5 (P > 0.05). The specific differences between models were visualized in Figure 2(a). Radar charts of expert ratings for health education texts generated by each model. Results of linear mixed-effects models for each evaluation dimension. Note. ***,P<0.001. Marginal means and 95% confidence intervals of different artificial intelligence models across all dimensions. Performance comparison of generative AI models across different dimensions and total scores.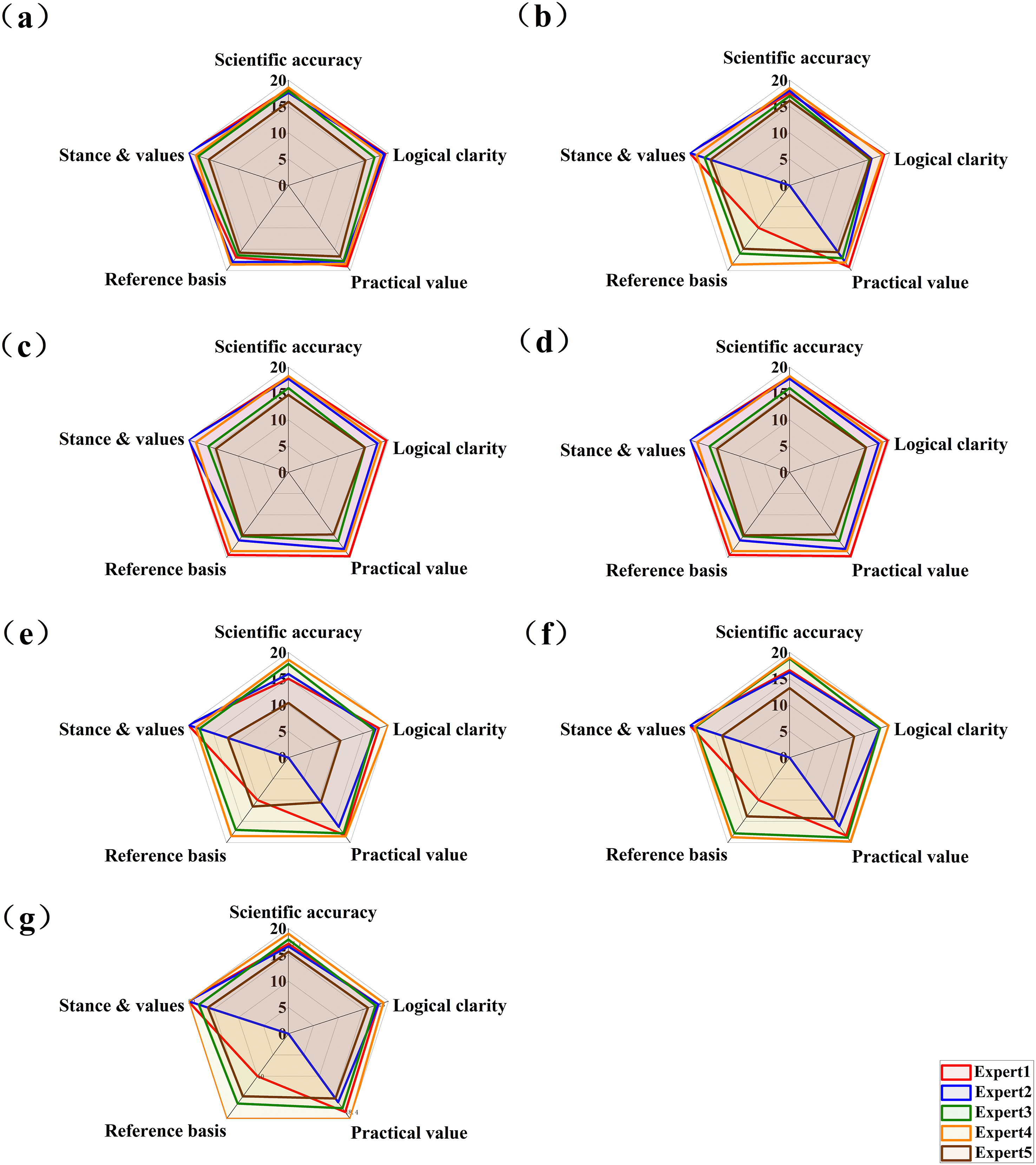
Scientific accuracy of diabetes-related health education texts generated by AI models
Significant differences were also observed among models in scientific accuracy (F = 8.85, df = 6, 330, P < 0.001). Kimi-K1.5 again achieved the highest score of 17.70, while iFlytek Spark-V3.5 scored the lowest at 15.54. Post hoc tests confirmed that all models performed significantly better than iFlytek Spark-V3.5 (P < 0.05), as shown in Figure 2(b).
Logical clarity of diabetes-related health education texts generated by AI models
The clarity of logic also varied significantly across AI models (F = 4.22, df = 6, 330, P < 0.001). Kimi-K1.5 and Deepseek-R1 achieved relatively high scores of 17.94 and 17.66, respectively, while iFlytek Spark-V3.5 scored the lowest at 16.96. Post hoc pairwise comparisons with Bonferroni correction revealed that Kimi-K1.5, Deepseek-R1, ChatGPT-4o, Tiangong-AI2.2.0, and Doubao all scored significantly higher than iFlytek Spark-V3.5 (P < 0.05). ERNIE Bot-3.5 also scored significantly higher than iFlytek Spark-V3.5 (P < 0.05). No significant differences were observed among Kimi-K1.5, Deepseek-R1, ChatGPT-4o, Tiangong-AI2.2.0, and Doubao (P > 0.05). These differences were visualized in Figure 2(c).
Practical value of diabetes-related health education texts generated by AI models
Practical value also differed significantly across AI models (F = 4.86, df = 6, 330, P < 0.001). Kimi-K1.5 achieved the highest score of 17.98, while iFlytek Spark-V3.5 scored the lowest at 16.26. Post hoc pairwise comparisons with Bonferroni correction revealed that Kimi-K1.5, ERNIE Bot-3.5, Tiangong-AI2.2.0, Doubao, ChatGPT-4o, and Deepseek-R1 all scored significantly higher than iFlytek Spark-V3.5 (P < 0.05). No significant differences were observed among Kimi-K1.5, ERNIE Bot-3.5, Tiangong-AI2.2.0, Doubao, ChatGPT-4o, and Deepseek-R1 (P > 0.05). These differences are visualized in Figure 2(d).
Reference basis of diabetes-related health education texts generated by AI models
Significant differences in reference quality were also detected across AI models (F = 25.61, df = 6, 339, P < 0.01). Kimi-K1.5 achieved the highest score of 17.14, while iFlytek Spark-V3.5 scored the lowest at 11.36. Kimi-K1.5, ERNIE Bot-3.5, and Tiangong-AI2.2.0 all scored significantly higher than iFlytek Spark-V3.5, Doubao, ChatGPT-4o, and Deepseek-R1 (P < 0.05). No significant differences were observed among iFlytek Spark-V3.5, Doubao, ChatGPT-4o, and Deepseek-R1 (P > 0.05), nor between Kimi-K1.5, ERNIE Bot-3.5, and Tiangong-AI2.2.0 (P > 0.05). These differences are visualized in Figure 2(e).
Stance & values of diabetes-related health education texts generated by AI models
“Stance & Values” refers to the model’s ability to avoid subjective or commercial biases, as well as exaggerated praise or criticism. AI models also varied significantly in stance and values (F = 6.14, df = 6, 339, P < 0.001). Deepseek-R1 and Kimi-K1.5 achieved the highest scores of 18.80 and 18.48, respectively, while iFlytek Spark-V3.5 and ERNIE Bot-3.5 scored the lowest at 17.68. Pairwise post hoc analyses with Bonferroni correction revealed that Kimi-K1.5, Doubao, Deepseek-R1, and ChatGPT-4o all scored significantly higher than iFlytek Spark-V3.5 and ERNIE Bot-3.5 (P < 0.05). Tiangong-AI2.2.0 also scored significantly higher than iFlytek Spark-V3.5 and ERNIE Bot-3.5 (P < 0.05), but did not differ significantly from Kimi-K1.5, Doubao, Deepseek-R1, or ChatGPT-4o (P > 0.05). No significant differences were observed between iFlytek Spark-V3.5 and ERNIE Bot-3.5 (P > 0.05). These differences are visualized in Figure 2(f).
Readability of diabetes-related health education texts generated by different models
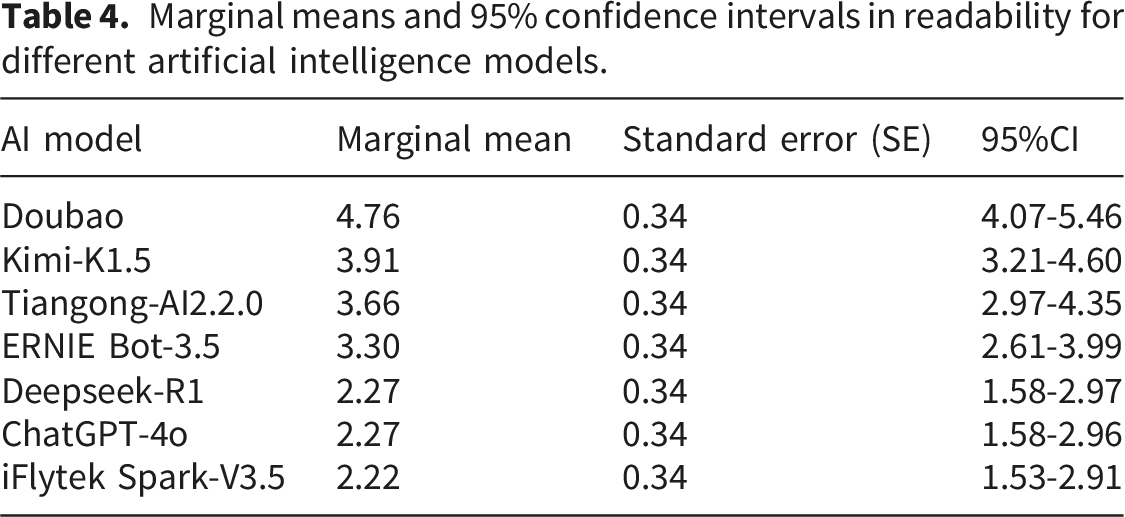
Marginal means and 95% confidence intervals in readability for different artificial intelligence models.
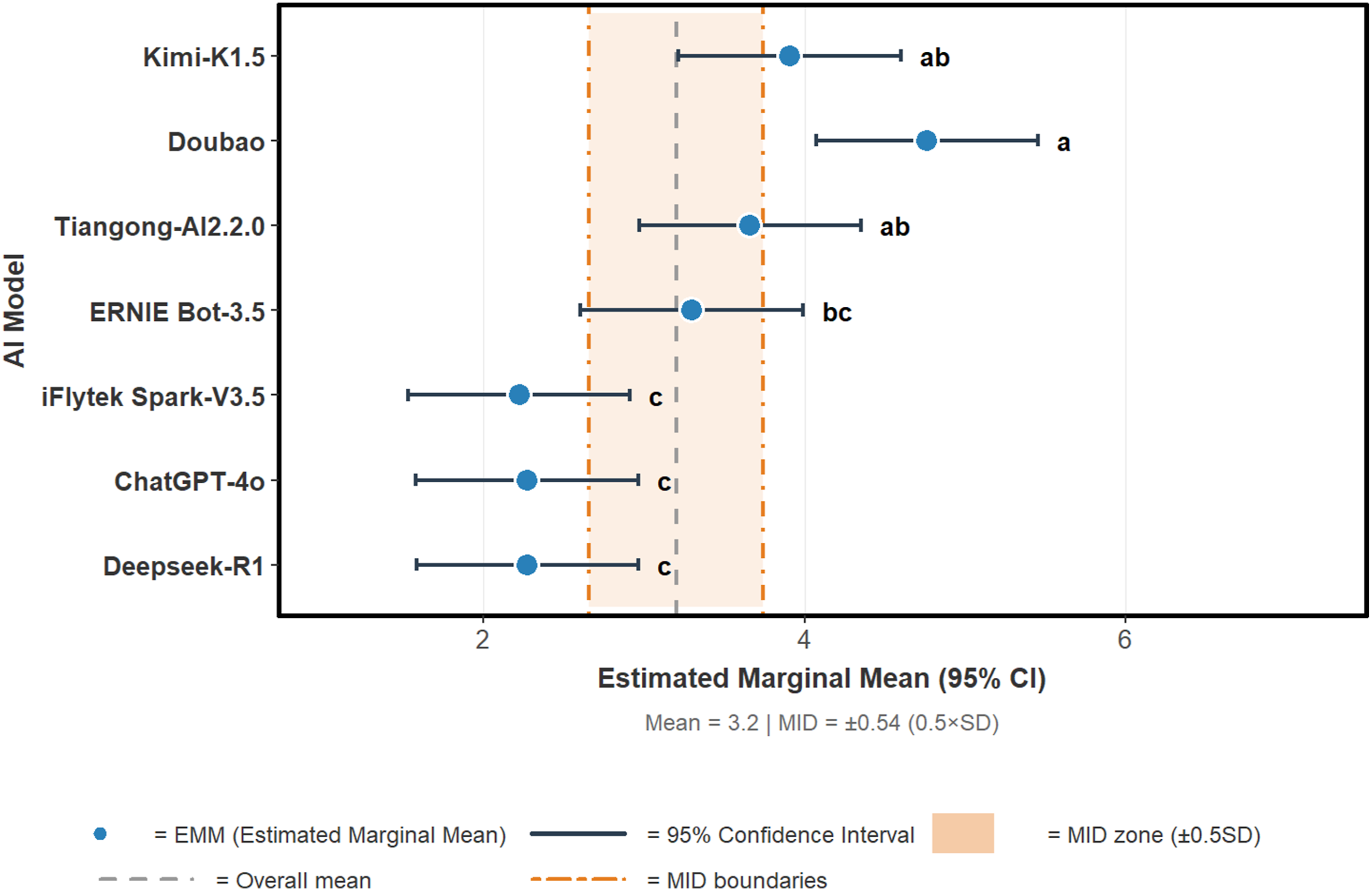
Readability and parameter comparison of health education texts generated by the seven models.
Discussion
This study thoroughly assessed the quality and readability of diabetes education materials produced via interactive conversations with seven popular generative AI models. Significant differences were found across several aspects, including scientific accuracy, logical clarity, practical value, reference basis, and stance & values, even if the overall quality of the texts generated by these models was typically satisfactory. Nonetheless, notable differences in readability were also discovered between the health education texts.
The accuracy and completeness of diabetes-related health education texts generated by generative AI models still need to be improved
The accuracy of health education texts is very important to the audience. In this study, although all AI-generated texts showed high accuracy, the fact that the accuracy rate did not reach 100% and that such responses may potentially mislead the inquirers was a concern. The findings were also in line with those of Giuliano Lo Bianco et al., 29 who assessed ChatGPT’s responses to 13 health-related questions about spinal cord stimulation and found that 95% of answers were sufficiently accurate. At the same time, we observed that some models had shortcomings in knowledge accuracy and completeness. For example, when offering dietary advice for diabetics, the ERNIE Bot-3.5 model listed foods to avoid but did not stress the importance of managing total calorie intake. Similarly, the Doubao model, when recommending fruits for diabetics, did not classify them based on glycemic index levels. Aside from ERNIE Bot-3.5, all other models failed to account for special situations (like hypoglycemia or post-medication adjustments) when explaining home blood glucose monitoring, missing key details about timing and technique. Additionally, some models’ responses to certain questions did not align with the existing guidelines. For instance, when answering the question “How do diabetic patients test their blood sugar at home?”, the partial response given by ERNIE Bot-3.5, “Before blood collection, wash your hands with water and soap, and disinfect the blood collection area with an alcohol cotton ball or alcohol swab, etc.”, did not emphasize that the fingers should be dried before blood collection. This might affect the accuracy of the blood sugar results. When answering “What should diabetic patients pay attention to when injecting insulin?”, ERNIE Bot-3.5’s response regarding the storage environment of insulin was: “Insulin should be stored in a refrigerated environment, avoiding freezing and high temperatures. Before use, check the expiration date and appearance of the insulin to ensure the drug has not expired.” This response differed from the requirements for insulin storage environment proposed in the latest Chinese Diabetes Drug Injection Technology Guidelines, 30 which stated: Opened vials of insulin or insulin pen cartridges could be stored at room temperature for up to 1 month after opening, and must not exceed the expiration date.
Regarding practical value, all generative AI models provided exercise recommendations that lacked specificity, failing to clarify necessary precautions and conditions for physical activity. This finding aligned with the research of John Grundy et al 31 and Gokbulut et al. 32 who also identified accuracy and personalization limitations in ChatGPT’s handling of diabetes-related health inquiries. This might also be related to how we pose questions to generative AI. Some researchers have pointed out that adding certain qualifiers when asking AI-related questions might help us get the answers we want. 33 However, when we added specific requirement qualifiers, and it still could not find answers that meet our standards, it might still generate inaccurate responses for us. 34
The logicality of diabetes-related health education texts generated by generative AI
Clear logic helps people better understand the content of a text. We found that both Kimi-K1.5 and Deepseek-R1 received high scores in logical clarity, indicating that they possess strong logical reasoning abilities. In contrast, iFlytek Spark-V3.5 scored lower in this dimension, possibly because it excelled more in linguistic expression. These differences also reflected the inherent characteristics and strengths of each model.
Reference basis for diabetes-related health education texts generated by generative AI
When a generative AI model produces relevant text and lists the webpages or literature it used as references, readers can assess the professionalism of the content by examining the credibility of those sources. However, significant disparities emerged in the reference basis dimension, where Doubao, iFlytek Spark-V3.5, ChatGPT-4o, and DeepSeek-R1 provided no supporting references for their answers. These findings aligned with prior research, which reported that both ChatGPT-4o and DeepSeek-R1 lacked relevant references in generating patient education materials for spinal surgery. 35 Furthermore, the references cited by other models predominantly originated from platforms such as Weibo, Quark, and Baidu, whose credibility remains unverified.
The readability of diabetes-related health education texts generated by generative AI
The readability of health education texts plays a critical role in how people access and utilize health information. In this study, the generated texts generally demonstrated good accessibility. This finding was consistent with the study by Luo Y et al 28 and Ozduran et al. 36 However, it was inconsistent with the results of Stephenson-Moe et al., 37 who compared patient education materials generated by different artificial intelligence models. They found that the overall readability of all AI-generated texts reached the reading level of college graduates. This discrepancy can be attributed to the varying tools employed for measuring readability. This study identified that specific models produced texts with disproportionately high reading scores for certain questions. Doubao’s response to the question, “How can diabetic patients self-monitor their blood glucose at home?” achieved a readability level of 8, suitable for an audience with higher education. This was similar to the results observed by Ozcivelek et al 38 when comparing different artificial intelligence models in responding to prosthodontic patient inquiries, where AI-generated texts required a reading level equivalent to 8th-9th grade or higher, potentially hindering comprehension among elderly patients. The science education texts generated by Kimi-K1.5, Doubao, Tiangong AI2.2.0, and ERNIE Bot-3.5 tended to be excessively lengthy. While detailed explanations can enhance understanding, excessive verbosity may negatively impact reading engagement and effectiveness. 39 Additionally, Doubao incorporated recommendations for related health videos on Douyin, though the quality of these videos required further verification. In contrast, ERNIE Bot-3.5 enhanced its texts with colorful supplementary pages, which might stimulate reading interest and improve knowledge comprehension. Kimi-K1.5 and DeepSeek-R1 are more suitable for medical professionals, while iFlytek Spark-V3.5 and DeepSeek-R1 are more suitable for non-professionals.
Implications
Although generative AI models can deliver highly accurate responses to certain health-related inquiries, the absence of cited sources frequently undermines their perceived reliability. Therefore, we suggested that large language models integrate references to authoritative web resources. When providing health-related information, these models should explicitly indicate the specific sources consulted, enabling users to evaluate the credibility of the content by examining the original materials. Furthermore, users engaging with such models may benefit from specifying their identity, and for example, indicating whether they are healthcare professionals or lay individuals. In the initial stage of our study design, given the diverse user demographics, we did not predetermine user roles or include specific qualifiers in the prompts. Consequently, the model-generated responses tend to be generalized and tailored to a broad, non-specialist audience. Regardless of the specific large language model employed, prompt formulation constitutes a critical skill. Variations in how a question is phrased can lead to substantially different outputs. Thus, it is imperative to enhance public awareness and understanding of effective strategies for interacting with generative AI systems.
Strengths and limitations
We assessed the comprehensive scientific accuracy, logical clarity, practical value, quality of references, stance & values, and readability of diabetes-related health education texts created by several popular generative AI models. First, we calculated the inter-rater agreement coefficient for the assessments of the seven models because, although all five assessors had extensive experience, human judgments could still be subject to bias. Second, there was a delay between text generation and final evaluation, despite professionals being asked to analyze the texts immediately after they were generated. Some of the models might have been updated over time, which could have affected our findings. However, even after introducing new versions, the older models are still likely to continue being used in practical applications. Finally, this study explored the quality and readability of health education texts generated by different AI models in the Chinese context. Further research is needed to investigate the quality and readability in other languages.
Conclusion
This study employed seven widely used generative artificial intelligence models to generate health education texts on diabetes through interactive dialogues to answer common questions and evaluated the results. The findings indicated that the overall quality of the health education texts generated by these models was moderate. Among the quality assessment results, Kimi-K1.5 scored significantly higher, while iFlytek Spark-V3.5 performed notably worse. In terms of readability, the health education texts generated by iFlytek Spark-V3.5 and Deepseek-R1 had higher readability, while those generated by Doubao had the lowest overall readability. The Kimi model was more suitable for healthcare professionals, while iFlytek Spark-V3.5 and Deepseek-R1 models were more suitable for non-professionals or those with limited reading ability.
Supplemental material
Supplemental material - Quality evaluation of AI-generated diabetes-related health education texts from different generative models
Supplemental material for Quality evaluation of AI-generated diabetes-related health education texts from different generative models by Xueping Jiao, Xingyu Liu, Shuhan Yang, Yueting Wang, Chenxia Wang, Yunfang Wang, Fanghong Yan, Yuhuan Xie, Yufang Guo, Yuxia Ma, Yanan Zhang in DIGITAL HEALTH
Footnotes
Ethical considerations
As this study does not involve any material or data related to human participants or animals, ethical approval is not required and applicable.
Author contributions
YZ conceived the study. YZ and XJ designed the study and drafted the manuscript. XJ, XL, and SY collected all relevant data and assisted in results interpretation. XJ and YW carried out data analysis. YW, CW, YG, YX, FY, and YM participated in the design and coordination. All authors contributed to the article and approved the submitted version.
Funding
The 2025 Research Project of the Chinese Nursing Association [No. ZHKYQ202516] and The General Project of the Gansu Provincial Department of Science and Technology [No. 26JRRA195].
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The datasets generated or analyzed during this study are available from the corresponding author on reasonable request.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.