
Abstract
Background
Large language models are increasingly used to obtain health information, but their quality in pediatric anesthesia remains insufficiently evaluated. This study aimed to assess the reliability and readability of four widely used AI chatbots in this context.
Methods
This cross-sectional observational study developed 18 pediatric anesthesia-related questions using Medical Subject Headings terms, online search trend analysis, and commonly queried topics reflecting parental information needs. Each question was submitted under standardized conditions to four generative AI-driven chatbots: OpenAI’s GPT-5.1 Thinking, Google’s Gemini 3 Pro, Anthropic’s Claude Opus 4.5 Extended Thinking, and DeepSeek-V3.2-Speciale. Models were accessed in their vendor-deployed configurations without task-specific fine-tuning. The generated responses were evaluated for information reliability using the Ensuring Quality Information for Patients (EQIP) instrument, DISCERN tool, Global Quality Score (GQS), and Journal of the American Medical Association (JAMA) benchmark criteria. Readability was assessed using seven validated indices including Flesch Reading Ease Score, Flesch–Kincaid Grade Level, Gunning Fog Index, Simple Measure of Gobbledygook, Coleman–Liau Index, Automated Readability Index, and Linsear Write Formula.
Results
A total of 72 chatbot-generated responses were included for analysis. Significant between-model differences were observed in DISCERN, EQIP, and GQS, while JAMA benchmark scores were consistently low across all models. DeepSeek and Gemini showed higher median reliability scores across several instruments, although significant pairwise differences mainly involved ChatGPT. None of the evaluated models achieved the recommended sixth-grade readability level across any index. Correlations between reliability and readability were non-significant, suggesting that these represent independent dimensions of information quality.
Conclusions
Current LLM-based chatbots provided pediatric anesthesia information with variable reliability and consistently suboptimal readability. Although certain models demonstrated relatively higher information quality, limited transparency and excessive reading complexity may restrict their suitability for public-facing educational use. These findings highlight the need for improved quality control, enhanced transparency, and readability-focused optimization in pediatric perioperative education.
Keywords
1. Introduction
Pediatric anesthesia is a highly specialized domain of anesthesiology that provides perioperative care for neonates, infants, children, and adolescents undergoing surgical, diagnostic, or therapeutic procedures. 1 Owing to substantial differences in anatomical structure, physiological function, and pharmacological responses between pediatric and adult populations, as well as the ongoing maturation of organ systems in children, anesthesia management in this group presents unique risks and challenges.2,3 In high-income countries such as the United States and the United Kingdom, millions of children undergo anesthesia annually for surgical procedures.1,4 Notably, approximately 65% to 80% of pediatric patients experience significant perioperative anxiety.5,6 This anxiety may not only increase psychological distress among parents but has also been associated with adverse postoperative outcomes in children, including emergence delirium, increased pain perception, and maladaptive behavioral changes. 7
In response to these concerns, parents increasingly seek health-related information through digital platforms prior to hospital admission. A recent survey reported that 74.3% of caregivers of children undergoing surgery searched online for procedural information before their hospital visit. 8 While digital information sources have the potential to support informed decision-making and improve perioperative preparation, the quality of publicly accessible online health content remains highly variable. Inaccurate, incomplete, or overly technical information, especially regarding the effects of anesthetic agents on pediatric neurodevelopment, may increase caregiver anxiety and lead to misconceptions. 9 Such misinformation may reduce adherence to perioperative recommendations, delay necessary treatment, or undermine trust in clinical guidance, thereby posing potential risks to perioperative safety in children. 10
Recent advances in artificial intelligence, particularly the development of large language models (LLMs), have introduced new forms of consumer-facing digital health information systems. 11 Leveraging natural language processing capabilities, LLM-based conversational agents are increasingly used by the public to obtain personalized health-related explanations and procedural guidance. 12 In the context of pediatric anesthesia, these tools have the potential to improve caregivers’ understanding of anesthesia-related risks, facilitate preoperative preparation, and support postoperative recovery through accessible, on-demand information delivery. However, LLMs generate responses based on probabilistic language modeling rather than explicit fact verification, which may result in factual inaccuracies or so-called “hallucinations”. 13 In the perioperative context, inappropriate or misleading information regarding fasting protocols, anesthesia induction, or postoperative medication may adversely affect recovery trajectories and, in extreme cases, compromise patient safety. Moreover, excessive linguistic complexity in generated responses may hinder caregivers’ comprehension and implementation of recommended care strategies.
Previous evaluations across clinical domains including oncology, hepatology, musculoskeletal medicine, and urology suggest that LLM-generated health information may achieve moderate to high content quality but frequently demonstrates limited readability, insufficient transparency, and occasional factual inconsistency.14–17 More recent studies have also begun to examine the use of LLMs for anesthesia-related patient education, including adult anesthesia, obstetric anesthesia, and pediatric dental sedation.18–20 However, evidence remains limited on how multiple widely used chatbots perform when answering caregiver-facing pediatric anesthesia questions. This represents a critical gap, given the need for such information to be accurate, clear, and safe for perioperative guidance. Accordingly, the present study conducted a systematic comparative evaluation of four widely used large language models, namely ChatGPT, Claude, DeepSeek, and Gemini, in the context of pediatric anesthesia information provision. Using standardized quality and readability assessment frameworks, this study aimed to characterize the reliability and accessibility of LLM-generated health information for parents and caregivers, thereby informing the responsible integration of generative AI–driven tools into pediatric perioperative education and digital health communication strategies. No formal hypothesis was prespecified.
2. Materials and methods
2.1. Study design
This study was designed as a cross-sectional observational analysis and was reported in accordance with the Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) guidelines. 21 The STROBE framework provides standardized guidance for the transparent reporting of observational research, including study objectives, methodology, results, and limitations. Because this study specifically evaluated generative AI-driven chatbots as sources of health advice, we also followed the Chatbot Assessment Reporting Tool (CHART) guideline. 22 The completed STROBE and CHART checklists are provided in the Supplementary Materials.
The study systematically assessed a total of 72 responses generated by four widely used LLM-based chatbot systems—OpenAI’s GPT-5.1 Thinking, Google’s Gemini 3 Pro, Anthropic’s Claude Opus 4.5 Extended Thinking, and DeepSeek-V3.2-Speciale—in response to pediatric anesthesia scenario-based questions from caregivers. The number of responses was determined by the predefined set of prompts and the number of evaluated platforms, enabling comparative assessment across systems under standardized conditions. Given the observational and system-performance–oriented nature of the study, a formal statistical sample size calculation was not performed. The evaluation covered multiple dimensions, including readability, informational reliability, and overall quality of responses.
2.2. Search strategy and data collection
Standardized pediatric anesthesia–related search terms were initially identified using the Medical Subject Headings (MeSH) database and further explored via Google Trends to capture temporal search interest. To further reflect real-world information-seeking behavior, commonly searched terms were collected from major Chinese search engines (Baidu and Sogou) and health information platforms (e.g., Dingxiang Doctor), as well as consultation records from professional medical forums including Dingxiangyuan and Haodf Online. Through this process, 28 search terms were initially identified. After removing irrelevant or duplicate items, 18 unique and relevant search terms were finalized (eTable 1), covering common caregiver concerns such as modality selection, neurodevelopmental safety, preoperative preparation, postoperative management, and anesthesia-related risks.
All prompts were entered verbatim as single-turn queries to simulate typical user interactions with publicly available chatbot interfaces. Queries were conducted by a single researcher with a clinical background in anesthesiology to ensure consistency in data entry procedures. No iterative refinement, follow-up prompting, or patient/public involvement was applied.
Data collection was performed on December 1, 2025, from Nanjing, China, via publicly available web-based interfaces for OpenAI’s GPT-5.1 Thinking (released November 12, 2025; knowledge cutoff September 30, 2024), Google’s Gemini 3 Pro (released November 18, 2025, knowledge cutoff January, 2025), Anthropic’s Claude Opus 4.5 Extended Thinking (released November 24, 2025, knowledge cutoff March, 2025), and DeepSeek-V3.2-Speciale (released December 1, 2025, knowledge cutoff July, 2025). The majority of the evaluated systems were proprietary chatbot models accessed in their vendor-deployed form, while DeepSeek represented an open-source alternative and was assessed in its publicly released configuration. All models were evaluated in their default configurations as deployed through the official chatbot platforms. The investigators did not apply task-specific fine-tuning, parameter optimization, retrieval-augmented generation, or external post-processing. Each query was entered into a new chat session following browser cache clearance to minimize potential contextual carryover effects.
For proprietary models, detailed disclosures regarding training corpora and internal architectures were not publicly available, and performance evaluation was therefore based on the functionality described in official vendor documentation. DeepSeek was assessed in its publicly released form without modification, ensuring consistency with its standard community-distributed implementation.
As this study did not involve human participants, there was no recruitment, exposure period, or follow-up period. Each prompt was processed twice per model to assess response stability, resulting in 144 raw outputs. Paired outputs were reviewed qualitatively for consistency in core medical content, key recommendations, safety-relevant information, and qualitative error-relevant content. Most paired outputs showed no substantive difference, and the remaining outputs showed only minor wording, organizational, or level-of-detail differences. No clinically meaningful differences were identified that would alter reliability scoring or qualitative error classification. Therefore, one complete run comprising 72 responses was used as the formal dataset for scoring and analysis.
All chatbot responses were recorded verbatim and stored in their original form without modification. Before expert assessment, all chatbot responses were de-identified and assigned numerical codes to mask model identity. Evaluators were blinded to the chatbot systems during both quantitative scoring and qualitative error analysis. No personal or identifiable information was involved in the dataset. The complete set of chatbot responses is provided in the Supplementary Material. All responses obtained from the chatbots were subsequently subjected to reliability and readability assessments.
2.3. Inclusion and exclusion criteria
Responses were eligible for inclusion if they were generated by one of the four predefined chatbot systems (GPT-5.1 Thinking, Gemini 3 Pro, Claude Opus 4.5 Extended Thinking, and DeepSeek-V3.2-Speciale) in response to one of the 18 predefined pediatric anesthesia prompts and were provided in text format.
Responses were excluded if the model failed to generate a valid answer, such as returning an error message or experiencing a network interruption. Responses that were completely unrelated to the question were also excluded, as were non-text outputs, including responses consisting solely of images or hyperlinks.
2.4. Reliability assessment scales
Informational reliability was evaluated using four established health information quality assessment instruments: DISCERN, the Ensuring Quality Information for Patients (EQIP) tool, the Global Quality Score (GQS), and the Journal of the American Medical Association (JAMA) benchmark criteria.
DISCERN is a standardized instrument for assessing the quality of written health information.14,23 It consists of 16 questions, divided into three sections: reliability of the publication (questions 1-8), quality of treatment information (questions 9-15), and overall assessment (question 16). Each question is scored on a 1-5 Likert scale, with a total score ranging from 16 to 80. A higher score indicates better information quality.
The EQIP tool is commonly used to assess the quality of written patient information available to the public.24,25 In this study, we used the expanded 36-item EQIP scale, which evaluates three domains: content, identification data, and structure. Each applicable item was rated as “Yes” or “No,” and items deemed not applicable were excluded from the denominator. The EQIP score was calculated as the proportion of applicable items rated “Yes” and expressed as a percentage, with higher scores indicating better information quality.
The GQS is a holistic quality assessment tool that requires evaluators to rate the content based on its comprehensiveness, accuracy, practicality, and objectivity.26,27 This study employed a 5-point Likert scale, 1 point very poor, 2 points poor, 3 points fair, 4 points good and 5 points excellent quality.
JAMA benchmark criteria are commonly used to evaluate the transparency and reliability of health information sources.28,29 The instrument assesses four key domains: authorship, attribution, disclosure, and timeliness. Each domain is scored from 0 to 1, with the total score ranging from 0 to 4, where higher scores indicate greater transparency and adherence to reporting standards.
These scales are shown in eTables 2-5.
2.5. Readability assessment tools
A readability application (https://readabilityformulas.com) was used to assess the reading ease of each response, utilizing seven indices: Flesch Reading Ease Score (FRES), Flesch-Kincaid Grade Level (FKGL), Gunning Fog Index (GFI), Simple Measure of Gobbledygook (SMOG), Coleman-Liau Index (CL), Automated Readability Index (ARI), and Linsear Write Formula (LWF). 30
These indices evaluate text readability based on distinct criteria. FRES calculates readability by considering sentence length and word count, with higher scores indicating easier comprehension. 16 FKGL determines the U.S. school grade level at which a text can be understood. 31 GFI evaluates sentence length and multisyllabic word frequency, while SMOG assesses the educational level required to understand health-related documents. 32 CL is based on sentence length and average letter count, commonly applied in medical texts. 33 The ARI and LWF provide readability scores that reflect the suitability of a text for the reader based on word and sentence structure.34,35 Calculation formulas were presented in eTable 6.
A decrease in FRES and an increase in ARI, FKGL, GFI, SMOG, CL, and LWF indicate lower readability.36,37 The readability threshold was set at 80.0 for FRES, while a grade level of 6 was the threshold for the remaining six formulas. Readability scores for 72 chatbot-generated responses were calculated, and the mean and standard deviation were compared against the sixth-grade readability level recommended by the American Medical Association and NIH.38,39
2.6. Scoring process
All chatbot-generated responses were independently evaluated by two senior physicians with more than 10 years of clinical experience using de-identified, numerically coded response files. Prior to the formal assessment, both reviewers underwent standardized training in the application of DISCERN, EQIP, GQS and JAMA criteria, including calibration using a pilot sample of 10 responses.
Discrepancies of one point or greater between reviewers were resolved through consensus discussion. In cases where agreement could not be reached, a third senior clinician with more than 25 years of experience served as an adjudicator to determine the final score.
2.7. Statistical analysis
Descriptive statistics were used to summarize all variables. The normality of data distribution was assessed using the Shapiro–Wilk test. Data with a normal distribution were presented as mean ± standard deviation (SD), while data not following a normal distribution were presented as median (IQR), and categorical variables were presented as frequencies and percentages.
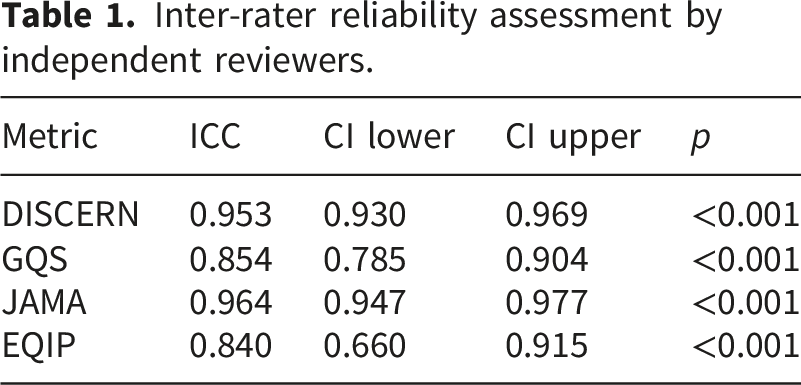
Between-group comparisons were conducted using one-way analysis of variance (ANOVA) with Tukey’s HSD post hoc test for normally distributed variables, and the Kruskal–Wallis test followed by Bonferroni-adjusted Mann–Whitney U tests for non-normally distributed variables. Interrater agreement for quantitative scoring instruments, including DISCERN, EQIP, GQS, and JAMA, was assessed using the intraclass correlation coefficient (ICC). ICC values were interpreted as follows: values below 0.50 indicated poor reliability, 0.50–0.75 indicated moderate reliability, 0.75–0.90 indicated good reliability, and values above 0.90 indicated excellent reliability. For qualitative error classification, Cohen’s kappa was calculated for each predefined error category and overall category-level agreement.
Spearman’s correlation analysis was used to examine associations between reliability and readability metrics. A p-value< 0.05 was considered statistically significant. All statistical analyses and plots were performed using R version 4.5.2.
3. Results
A total of 72 chatbot-generated responses were obtained from 18 predefined pediatric anesthesia prompts across four chatbot systems, and all were included in the final analysis.
3.1. Interrater reliability
Inter-rater reliability assessment by independent reviewers.
3.2. Reliability of LLM-Generated information
Reliability scores across LLMs.
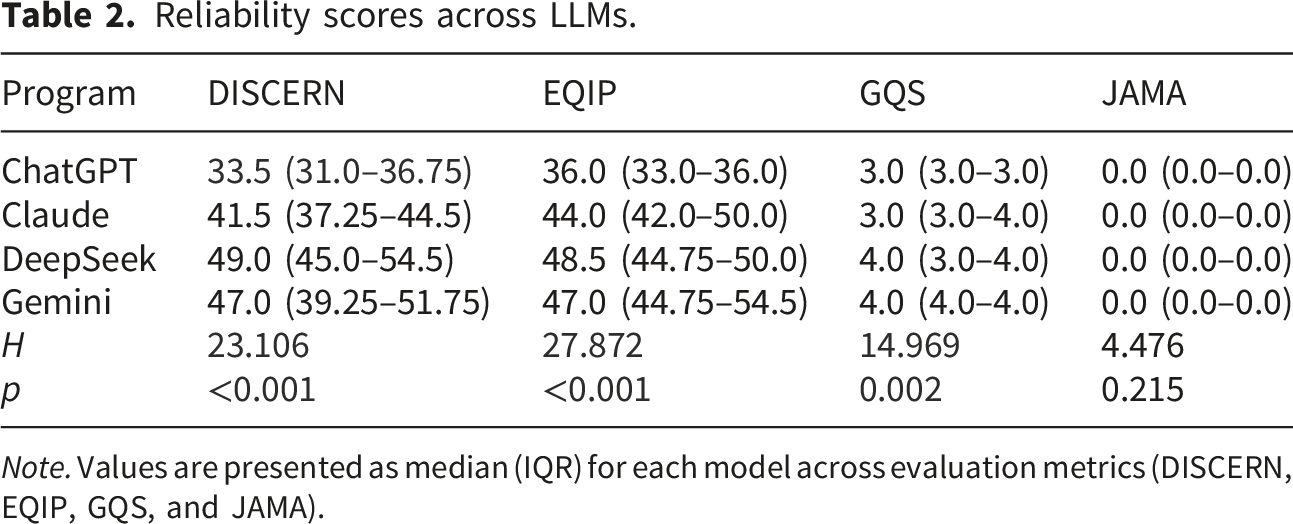
Note. Values are presented as median (IQR) for each model across evaluation metrics (DISCERN, EQIP, GQS, and JAMA).
DeepSeek and Gemini demonstrated higher median DISCERN scores, with median values of 49.0 (45.0–54.5) and 47.0 (39.25–51.75), whereas ChatGPT had a lower median score of 33.5 (31.0–36.75). A similar pattern was seen in EQIP scores, with Gemini and DeepSeek showing higher median scores of 47.0 (44.75–54.5) and 48.5 (44.75–50.0), respectively. For GQS, both Gemini and DeepSeek achieved median scores of 4.0, with IQRs of 4.0–4.0 and 3.0–4.0, respectively.
In contrast, JAMA benchmark scores remained uniformly low across all evaluated systems, with a median value of 0.0 (IQR: 0.0–0.0), suggesting limited transparency and authorship attribution.
Distributional analysis (Figure 1) further depicted that ChatGPT showed narrower distributions with consistently lower central values for both DISCERN and EQIP, whereas DeepSeek and Gemini demonstrated broader distributions with higher upper ranges, indicating overall superior performance despite greater variability. Claude generally exhibited intermediate distributions overlapping with higher-performing models but without comparable central tendencies. Reliability scores across LLMs. Violin plots with embedded boxplots show score distributions for DISCERN, EQIP, GQS, and JAMA; brackets indicate pairwise comparisons.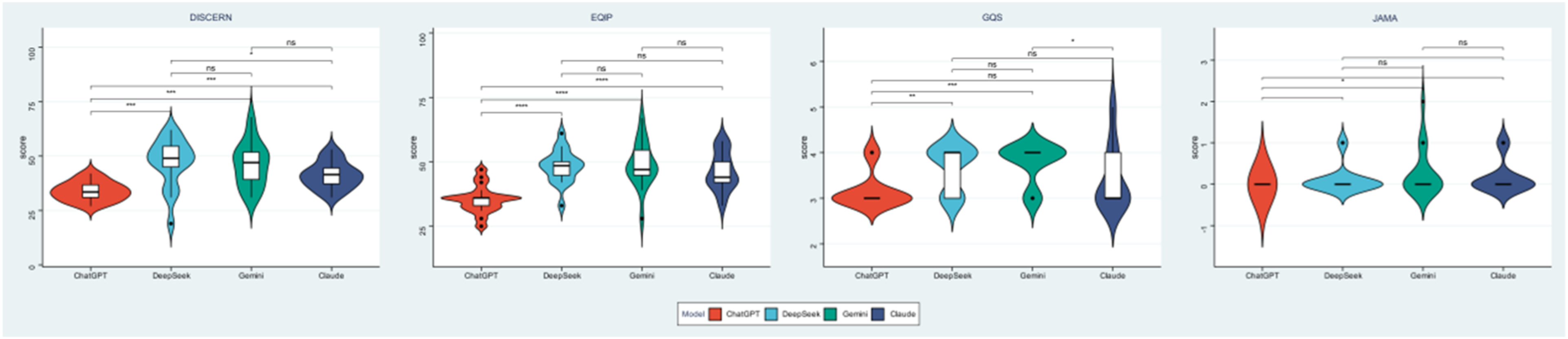
For GQS, score variability was less pronounced across models; however, DeepSeek and Gemini remained concentrated toward higher values. Claude showed wider dispersion, suggesting greater inconsistency in global quality, while ChatGPT scores clustered at lower levels.
JAMA benchmark scores were uniformly low across all models, with minimal dispersion and no meaningful between-model differences, indicating consistently limited transparency and authorship disclosure.
3.3. Qualitative error analysis
Final consensus classification of qualitative content-related deficiencies across 72 chatbot responses.
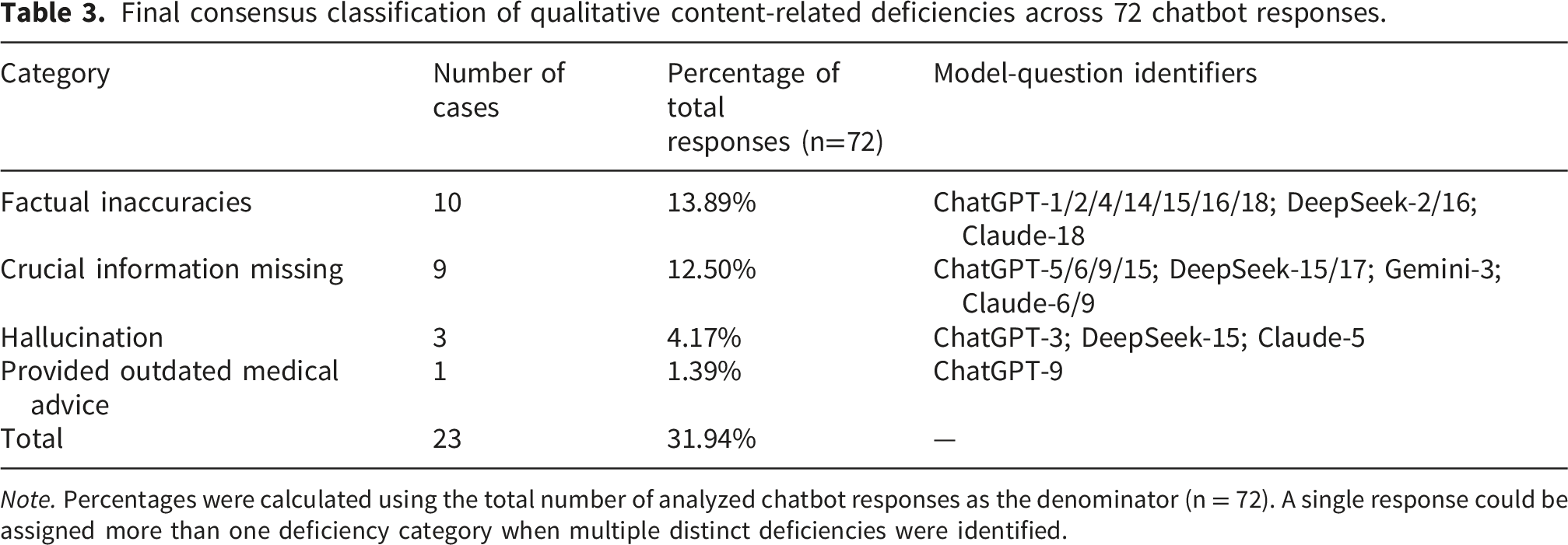
Note. Percentages were calculated using the total number of analyzed chatbot responses as the denominator (n = 72). A single response could be assigned more than one deficiency category when multiple distinct deficiencies were identified.
The frequency and proportion of each error type are illustrated in Figure 2. After consensus discussion, factual inaccuracies were the most frequent error category, accounting for 10 responses (13.89%). These cases originated from ChatGPT (questions 1, 2, 4, 14, 15, 16, and 18), DeepSeek (questions 2 and 16), and Claude (question 18). Distribution of qualitative content-related deficiencies across 72 chatbot-generated responses. Bars show the number of deficiencies in each category, with percentages calculated using all analyzed responses as the denominator (n = 72). A single response could be assigned more than one deficiency category when multiple distinct deficiencies were identified.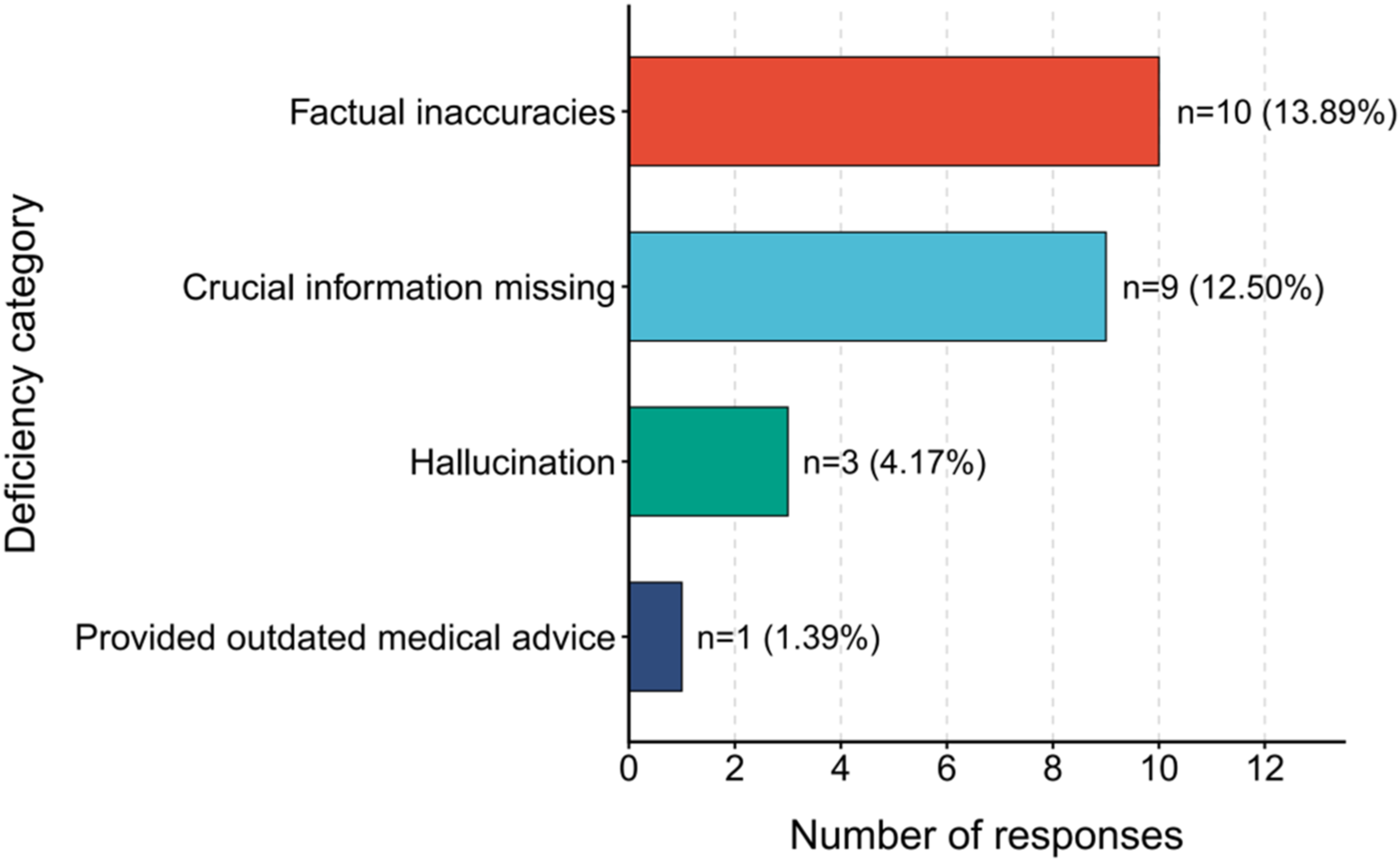
Crucial information missing was identified in nine responses (12.50%). These cases were observed in outputs from ChatGPT (questions 5, 6, 9, and 15), DeepSeek (questions 15 and 17), Gemini (question 3), and Claude (questions 6 and 9).
Hallucinations were detected in three responses (4.17%), including one generated by ChatGPT (question 3), one by DeepSeek (question 15), and one by Claude (question 5).
Provided outdated medical advice was identified in one response (1.39%), generated by ChatGPT (question 9).
These findings suggest that although LLM-based chatbots are capable of generating contextually relevant responses, clinically important informational gaps and inaccuracies remain present across platforms. Detailed examples of these errors and expert annotations are provided in eTable 7.
3.4. Pairwise comparison of reliability metrics
Pairwise comparison of reliability (p-values).
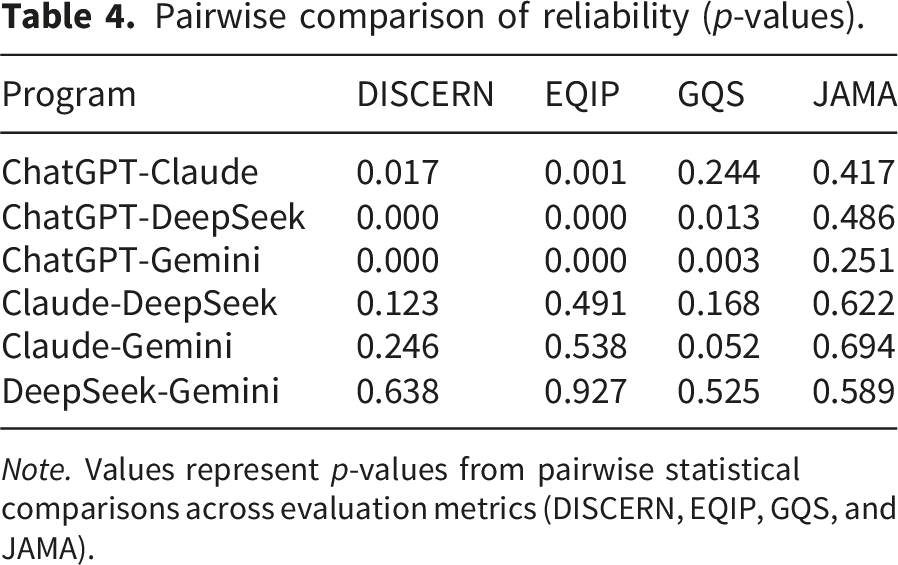
Note. Values represent p-values from pairwise statistical comparisons across evaluation metrics (DISCERN, EQIP, GQS, and JAMA).
3.5. Readability of LLM-Generated responses
Readability scores of LLMs.
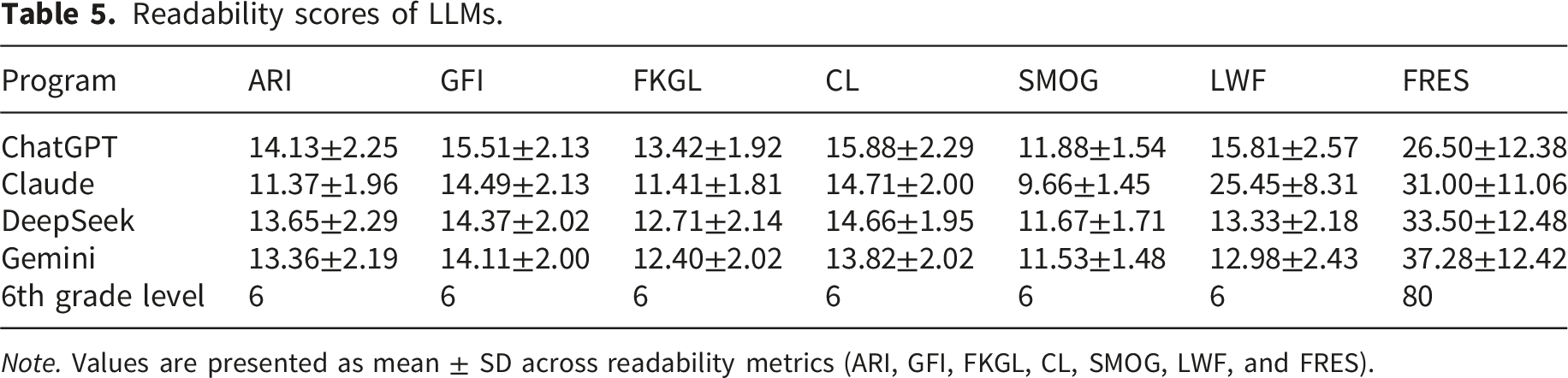
Note. Values are presented as mean ± SD across readability metrics (ARI, GFI, FKGL, CL, SMOG, LWF, and FRES).
FRES scores were markedly below the target range of 80–90 for texts intended for a sixth-grade reading level (Figure 3). Complementary indices, including ARI, GFI, FKGL, CL, and SMOG similarly indicated that the linguistic complexity exceeded what is considered appropriate for a general audience. Readability scores of LLM-generated responses across seven indices. Bar charts show mean scores for each model. The dashed reference line (for FRES) or horizontal line at grade level 6 indicates the recommended readability threshold.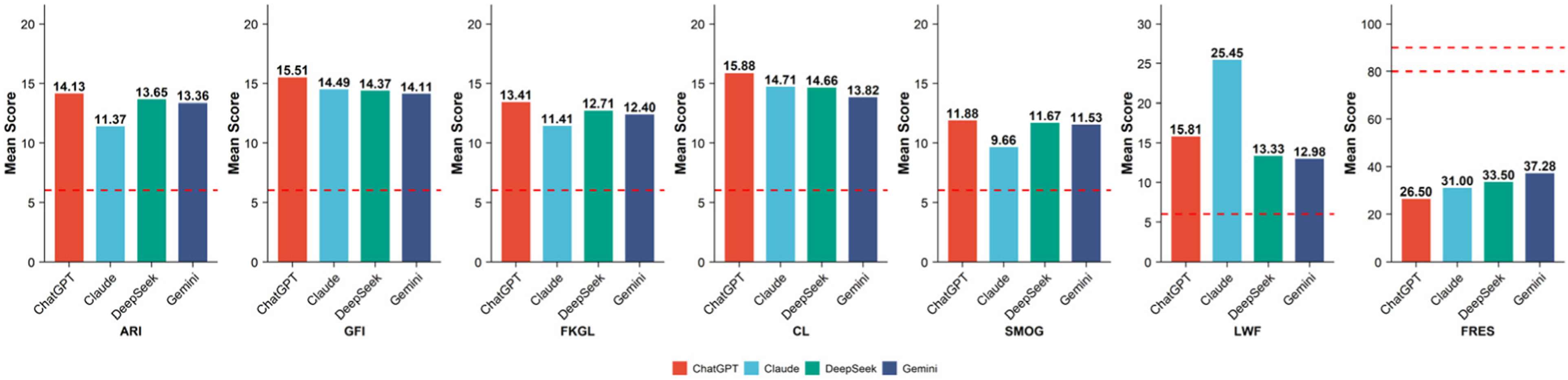
Collectively, these findings suggest that the responses generated by all four LLMs were written at a level too complex, which may limit comprehension among caregivers without medical training.
3.6. Correlation between readability and reliability
Spearman correlation analysis demonstrated no strong associations between reliability indicators and readability measures (Figure 4), suggesting that information quality and textual accessibility represent largely independent dimensions of chatbot-generated health content. Spearman correlation between reliability and readability metrics for LLM-generated pediatric anesthesia responses. Circle size indicates correlation strength, with red for positive and blue for negative correlations. Selected correlations are reported in text.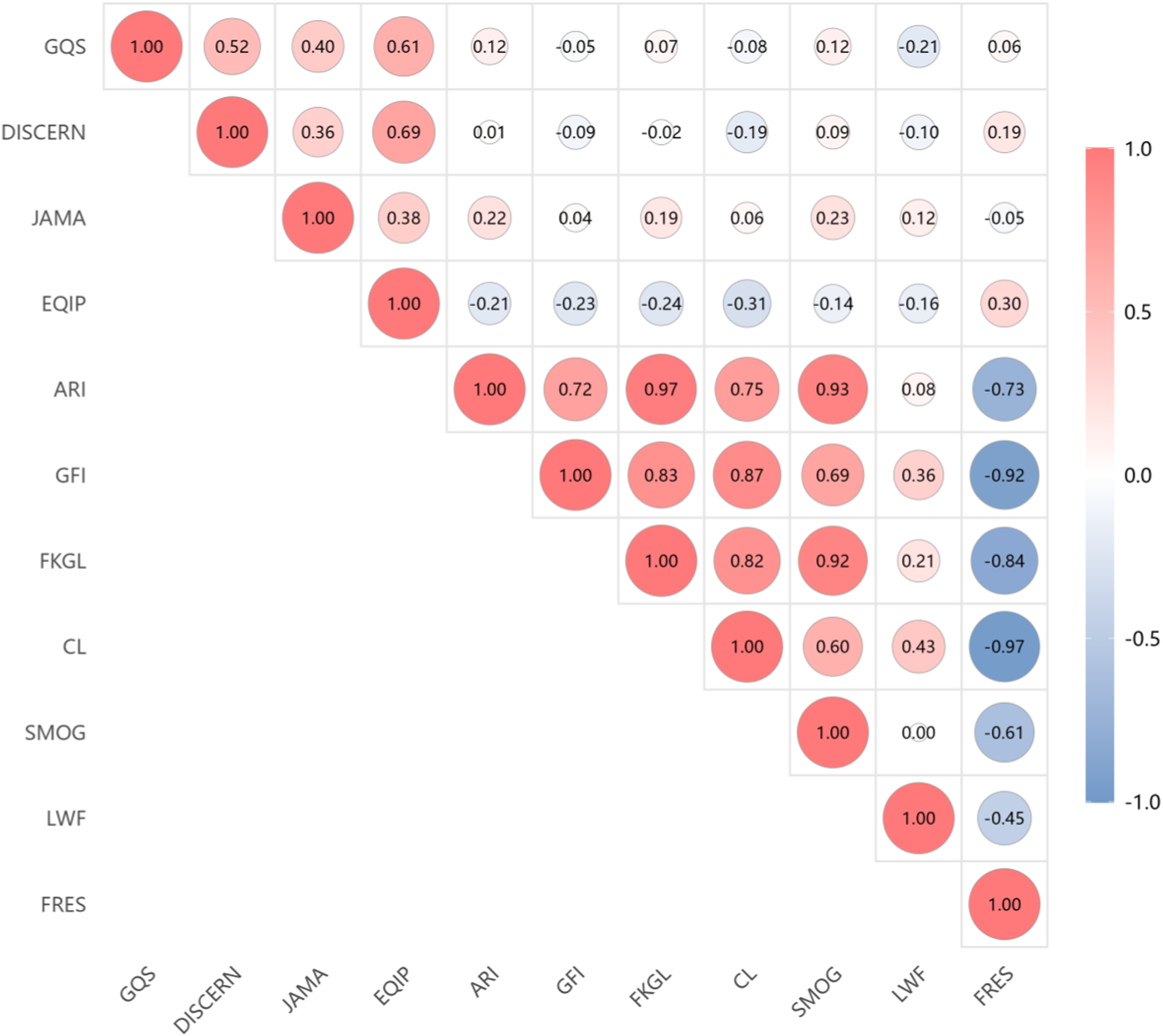
Strong positive correlations were observed among the readability metrics, with FKGL demonstrating high correlations with ARI (r= 0.97), SMOG (r= 0.92), GFI (r= 0.83), and CL (r= 0.82). Similarly, GFI showed strong positive associations with CL (r= 0.87) and FKGL (r= 0.83). As expected, FRES was negatively correlated with the other readability indices, including CL (r= -0.97), FKGL (r= -0.84), and GFI (r= –0.92), reflecting inverse scale directions.
Regarding reliability measures, GQS showed a moderate positive correlation with DISCERN (r= 0.52) and EQIP (r= 0.61), while JAMA demonstrated weaker associations with readability metrics overall. EQIP displayed weak correlations with readability indices, including FKGL (r= -0.24), CL (r= -0.31), FRES (r= 0.30), SMOG (r= -0.14), and LWF (r= -0.16). No strong negative correlations were observed between reliability and readability metrics, suggesting largely independent constructs.
4. Discussion
The increasing deployment of large language model (LLM)–based conversational agents has expanded the ways in which caregivers access perioperative health information through digital platforms. These systems are progressively being integrated into routine health information–seeking behavior and may influence decision-making prior to clinical encounters.40–42 However, evaluations of the quality of pediatric anesthesia information generated by LLMs remain limited. In this study, we evaluated the performance of four mainstream large language models, including ChatGPT, Claude, DeepSeek, and Gemini, in the pediatric anesthesia domain. Overall, the quality and reliability of the generated information were suboptimal. DeepSeek and Gemini demonstrated relatively higher median reliability scores overall; however, pairwise comparisons showed that differences between Claude and either DeepSeek or Gemini did not reach statistical significance. Nevertheless, none of the evaluated models achieved a readability level equivalent to the recommended sixth-grade standard, and no significant correlation was identified between information reliability and readability. These findings provide an overview of the current capabilities and limitations of widely used LLMs in addressing pediatric anesthesia–related questions and offer preliminary insights for improving both the reliability and accessibility of health information in this field.
4.1. Reliability of LLM-Generated information
Using multiple established quality assessment instruments, this study found that the overall reliability of LLM-generated pediatric anesthesia information was moderate. This observation is consistent with recent research evaluating LLM responses to cancer-related queries, which reported acceptable accuracy but highlighted limitations such as poor readability, limited practical applicability, and a lack of cited sources. 17 Notably, significant performance differences were observed among models, with DeepSeek and Gemini showing higher median scores across DISCERN, EQIP, and GQS metrics, although pairwise superiority over Claude was not statistically established. Similar patterns have been reported in prior studies, including research on exercise rehabilitation recommendations for ankylosing spondylitis, where DeepSeek-V3 demonstrated superior performance in modified DISCERN, reliability, and usefulness compared with ChatGPT-4, 43 as well as studies evaluating responses to frequently asked pain-related questions, in which Gemini achieved significantly higher GQS scores than ChatGPT. 44 Together, these findings reinforce the notion that model selection substantially influences the assessed quality of AI-generated medical information.
A notable and consistent finding in this study was the uniformly low JAMA scores across all evaluated models, indicating widespread deficiencies in transparency-related criteria. The JAMA benchmark emphasizes elements such as authorship, information sources, references, and content currency. In contrast, LLM-generated responses typically draw on aggregated knowledge from association websites, hospital pages, scientific literature, and general written materials intended for public dissemination, which rarely include explicit author attribution or publication dates. This pattern is consistent with previous research examining LLM responses to cardiopulmonary resuscitation–related questions. 45 In high-risk domains such as pediatric anesthesia, expert human review therefore remains essential. These limitations may reflect the fact that current LLMs primarily generate responses based on learned language patterns rather than direct information retrieval, resulting in challenges related to traceability and limited integration with high-quality, domain-specific medical knowledge bases. To address these issues, the adoption of retrieval-augmented generation (RAG) approaches is increasingly advocated, as they link generated content to verifiable sources and enable explicit disclosure of knowledge cutoffs and limitations. Accumulating evidence suggests that RAG can reduce hallucinations, improve factual accuracy, and enhance transparency.46–48
4.2. Qualitative error analysis
Qualitative analysis of erroneous responses indicated that factual inaccuracies and omission of crucial information were the two dominant error patterns across models, accounting for most identified errors. Factual inaccuracies occurred predominantly in ChatGPT outputs, with occasional instances in DeepSeek and Claude. These inaccuracies mainly involved ambiguous descriptions of timing or dosing, oversimplified clinical recommendations, insufficient differentiation among related perioperative concepts, and use of nonstandard terminology, which may not be readily apparent to non-expert users. In parallel, omission of crucial information was observed across all four platforms, including ChatGPT, DeepSeek, Gemini, and Claude, suggesting a systematic tendency of LLMs to generate incomplete yet superficially coherent responses to complex perioperative questions.
Missing key information is of particular concern in pediatric anesthesia. In this study, omissions involved pediatric-specific fasting distinctions, age-related pharmacological and physiological considerations, antiemetic strategies for postoperative nausea and vomiting, and risk differentiation in perioperative counseling. Such omissions may limit caregivers’ understanding of anesthesia-related risks and contribute to misjudgment.
Hallucinations represent another important challenge and refer to the generation of factually incorrect, fabricated, or unsupported content. 49 In this study, DeepSeek inappropriately extrapolated adult evidence on posterior neck cooling for postoperative nausea and vomiting to pediatric patients (Question 15), and Claude suggested a minimum interval of 2–4 weeks between anesthetic exposures despite the absence of authoritative guidance (Question 5).
Outdated medical advice represented the smallest proportion of identified errors and was observed exclusively in ChatGPT outputs. Specifically, in response to Question 9, ChatGPT provided outdated recommendations regarding anesthetic medication use. Such obsolete guidance may lead to inappropriate perioperative preparation and underscores the importance of continual data updating for LLM-based systems.
To further contextualize these errors from a patient-safety perspective, we examined two representative examples informed by the approach of Kuo et al. 50 DeepSeek-2 incorrectly described caudal block as applicable to upper limb surgery, which could mislead caregivers regarding regional anesthesia indications. DeepSeek-15 recommended applying a cool towel to the forehead or back of the neck for postoperative nausea and vomiting (PONV). This intervention is unsupported by established guidelines and could potentially delay evidence-based symptom management.51,52 In terms of potential harm severity, both examples were judged to carry moderate clinical significance, as they could distort caregiver understanding or delay appropriate care, but neither was considered likely to cause death or severe harm in the context of caregiver education alone. These examples represent potential rather than realized harm, as no actual patients or clinical interventions were involved. The occurrence of such errors across multiple platforms suggests that this vulnerability is inherent to current LLM architectures rather than confined to a specific model.
4.3. Readability assessment
Our results indicate that the readability of content generated by all evaluated LLMs substantially exceeded the sixth-grade level recommended by the American Medical Association, thereby posing a barrier to public comprehension. Across grade-level–based indices (ARI, GFI, FKGL, CL, SMOG, and LWF) and reading ease metrics (FRES), the generated texts consistently corresponded to secondary school or higher reading levels. Although Gemini and DeepSeek exhibited relatively lower grade-level scores and greater reading ease than ChatGPT and Claude, none of the models produced content that met readability standards appropriate for general caregivers. These findings align with prior studies demonstrating that AI-generated medical information frequently exceeds recommended readability thresholds for public-facing health materials.45,53 Collectively, these results suggest that current LLMs tend to rely heavily on technical terminology and complex sentence structures when conveying medical knowledge.
Effective health communication depends on information being understandable and usable by its intended audience. Excessive linguistic complexity may reduce acceptability, limit usability, and adversely affect caregivers’ engagement and decision-making, potentially increasing anxiety or misinterpretation of risk. While between-model differences suggest that newer models such as Gemini may incorporate incremental improvements in linguistic accessibility, reliance on model selection alone is unlikely to resolve readability challenges. From a development perspective, simplifying language should be treated as a core design objective for health-focused LLMs, for example by incorporating high-quality science communication materials during training or enabling adaptive language-level adjustment based on user input. From a user perspective, parents or caregivers of pediatric patients may improve comprehension by explicitly specifying target reading levels within prompts when seeking pediatric anesthesia information.
4.4. Relationship between reliability and readability
This study found no strong associations between reliability metrics and readability indices, indicating that these dimensions function largely independently. This observation is consistent with prior multimetric evaluations showing that AI-generated patient education materials may score well for quality yet remain difficult to read, suggesting that quality and accessibility do not necessarily improve in parallel. 54 Reliability appears to be primarily influenced by the quality and scope of underlying knowledge exposure, whereas readability is shaped by learned linguistic patterns and stylistic preferences. In the context of pediatric anesthesia, where information is frequently accessed by parents and caregivers, a mismatch between content quality and readability may limit the educational value of LLM-generated materials. These findings carry important implications for both users and developers: ease of understanding should not be equated with informational accuracy, and health-oriented LLMs should be evaluated using integrated frameworks that simultaneously consider content quality and communicative clarity to achieve a balance between accuracy and interpretability.
4.5. Practical implications for caregivers
From a practical perspective, caregivers should regard LLM-generated pediatric anesthesia information as supplementary educational material rather than as a substitute for professional medical advice. Clinically actionable information should be verified with an anesthesiologist or perioperative care team, particularly when questions involve preoperative fasting, medication use, anesthesia-related risks, neurodevelopmental concerns, postoperative symptom management, or the timing of repeated anesthetic exposures. These question types may carry higher risk if incomplete or inaccurate responses are accepted without professional confirmation.
4.6. Limitations
Several limitations should be acknowledged. First, the number of questions differed across clinical domains. Although this distribution reflects areas of greater patient concern, it may influence domain-specific comparisons of statistical significance. Second, this study focused on commonly encountered questions, resulting in a relatively small overall sample size. To reduce subjectivity in the qualitative error analysis, all chatbot responses were independently reviewed by two experts using de-identified materials, and discrepancies were resolved through consensus discussion. Nevertheless, some residual expert judgment may remain; therefore, the qualitative findings should still be interpreted as exploratory in nature. Third, all responses were generated using a predefined, standardized single-turn question set, and neither patients nor caregivers were directly involved in the evaluation. While this approach enhances comparability across models, it does not capture the interactive characteristics of real-world caregiver-LLM communication, in which users may ask follow-up questions, seek clarification, or refine prompts over multiple turns. In addition, the relatively long responses generated from one-turn questions may be atypical of natural user interactions and may have influenced readability and perceived information quality. Fourth, all chatbot responses were collected on a single day to ensure synchronous comparison across models; however, LLMs may undergo updates or temporal drift, and their outputs may change over time. Therefore, the findings should be interpreted as a time-specific assessment of the evaluated model versions. Although paired duplicate outputs were reviewed qualitatively for response stability, formal quantitative variability analysis across repeated queries was not performed. Finally, readability was assessed using established formula-based indices. Although these metrics estimate textual complexity, they do not directly reflect actual comprehension, contextual interpretation, or the influence of cultural and educational factors on understanding. Future studies should include larger and more diverse expert panels, incorporate direct participation from patients and caregivers, evaluate multi-turn interactions, and achieve a more balanced distribution of questions across clinical domains. In addition, including responses from human anesthesiologists as a comparator would provide a clinically meaningful benchmark for interpreting LLM performance and help determine whether LLM-generated information is comparable to, or potentially better than, clinician-generated caregiver education in specific scenarios.
5. Conclusion
In summary, widely used large language model-based chatbot systems currently demonstrate several limitations when applied as sources of pediatric anesthesia information for caregivers. Informational reliability remains variable, transparency regarding content sourcing is limited, and the linguistic complexity of generated responses frequently exceeds recommended readability thresholds for public-facing health communication. These factors may constrain the suitability of LLM-generated content for supporting caregiver understanding within digitally mediated perioperative care environments.
By systematically evaluating these performance dimensions, this study clarifies the current role and limitations of large language models as sources of pediatric anesthesia information. Our findings offer evidence-based insights to support the development of more reliable and accessible health information for the public and provide practical considerations for improving the application of large language models in the medical and health communication domains.
Supplemental material
Supplemental material - Large language model chatbots as sources of pediatric anesthesia health advice: An evaluation of reliability and readability
Supplemental material for Large language model chatbots as sources of pediatric anesthesia health advice: An evaluation of reliability and readability by Xue Zhang, Yuchen Dai, Xin Zhao, Lin Wu, Boming Shao, Xisheng Shan, Fuhai Ji, Runzhi Deng, Baojian Zhao in DIGITAL HEALTH.
Supplemental material
Supplemental material - Large language model chatbots as sources of pediatric anesthesia health advice: An evaluation of reliability and readability
Supplemental material for Large language model chatbots as sources of pediatric anesthesia health advice: An evaluation of reliability and readability by Xue Zhang, Yuchen Dai, Xin Zhao, Lin Wu, Boming Shao, Xisheng Shan, Fuhai Ji, Runzhi Deng, Baojian Zhao in DIGITAL HEALTH.
Footnotes
Acknowledgements
The authors would like to thank the expert reviewers for their contributions to the assessment of chatbot-generated responses.
Ethical considerations
This study did not involve human participants, clinical datasets, laboratory animals, or histological specimens. All materials analyzed in this research were derived exclusively from publicly accessible large language models. No private, sensitive, or personally identifiable information was collected, accessed, or processed at any stage of the study, and there was no direct interaction with end users of these systems. Under these circumstances, formal ethical approval was not required.
Author contributions
Xue Zhang: Methodology; Formal analysis; Writing – Original Draft. Yuchen Dai: Investigation; Project administration; Review & Editing. Xin Zhao: Supervision; Project administration; Review. Lin Wu: Investigation; Supervision; Project administration; Xisheng Shan: Conceptualization; Investigation; Review & Editing. Boming Shao: Conceptualization; Investigation; Review & Editing. Fuhai Ji: Review & Editing. Runzhi Deng: Methodology; Project administration; Review. Baojian Zhao: Methodology; Review & Editing. All authors have read and approved the final version of the manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The main data supporting the findings of this study, including the complete set of chatbot-generated responses and supplementary tables, are provided in the Supplementary Materials. Additional analysis files are available from the corresponding author upon reasonable request.
Use of assessment tools and permission statement
All tools, questionnaires, scales, and assessment instruments used in this study were reviewed for copyright and permission requirements. The DISCERN, EQIP, GQS, JAMA benchmark criteria, and standard readability indices were used as established academic evaluation tools for assessing chatbot-generated health information, and their original sources were appropriately cited. No proprietary patient questionnaire, restricted-use clinical scale, or copyrighted instrument requiring separate permission was administered to participants or reproduced in full as a primary data-collection instrument.
Supporting information
The Supplementary Materials include the completed STROBE and CHART checklists, supplementary tables, and the complete set of chatbot-generated responses analyzed in this study.
Patient and public involvemen
Patients and/or the public were not involved in the design, conduct, reporting, or dissemination plans of this research.
Guarantor
Baojian Zhao is the corresponding author of this article. Runzhi Deng is the co-corresponding author. Both authors take full responsibility for the integrity of the research and data, have full access to all data, and had the final decision-making authority regarding publication.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.