
Abstract
We present the extended NeOn-GPT pipeline, an LLM-powered, domain-agnostic ontology learning framework grounded in the NeOn methodology. The pipeline comprises two components: (i) ontology draft generation through multi-step prompting—covering requirement specification, competency questions, conceptualization, formal modeling, population, and documentation—and (ii) automated verification and repair through orchestrated calls to third-party tools complemented by LLM-suggested fixes. The extended pipeline introduces an explicit ontology reuse step to guide LLMs toward more consistent modeling decisions. We evaluate NeOn-GPT across four domains (Wine, Cheminformatics, Environmental Microbiology, and Sewer Networks) using both proprietary (GPT-4o) and open-source (Mistral, Llama-4, DeepSeek) models. Gold-standard alignment is assessed via structural metrics (class, property, and axiom profiles), lexical metrics, and semantic metrics based on sentence embeddings. Results show that LLMs consistently generate ontologies with rich relational structures and meaningful semantic alignment, with most entity and triple similarities falling in the 0.5–0.8 range. This study provides a comprehensive, cross-domain evaluation of NeOn-guided LLM ontology learning, clarifying its capabilities and limitations.
Introduction
Ontologies are formal and explicit specifications of shared conceptualizations, structured representations of the entities, properties, and rules that define a domain (Guarino et al., 2009; Hogan et al., 2021). They provide a semantic foundation for data integration, interoperability, and reasoning in domains such as product design and production, biomedicine, environmental modeling, and intelligent decision-making support (Buttigieg et al., 2013; Casanovas et al., 2009; Hofmann et al., 2024; Schriml et al., 2012; Smith et al., 2007). The construction of high-quality ontologies, however, remains labor-intensive, requiring domain expertise, methodological rigor, and significant manual effort.
Recent advances in large language models (LLMs) offer a promising opportunity to alleviate this bottleneck. LLMs are increasingly used to transform natural language descriptions into structured representations, raising the question of whether they can support or even automate ontology-engineering pipelines. This challenge is both practically important and scientifically significant: a reliable LLM-assisted pipeline would reduce development time, broaden accessibility, and strengthen ontology reuse across domains.
However, automating ontology engineering with LLMs remains difficult. Naïve prompting strategies often produce incomplete conceptual models, missing axioms, or logically inconsistent structures. Moreover, LLMs struggle to reuse existing ontologies, leading to hallucinated entities or incorrect reuse of vocabulary. These limitations make end-to-end automation challenging, despite the impressive generative capabilities of current models.
Existing approaches have attempted to leverage LLMs for isolated ontology learning tasks, such as entity extraction, triple generation, and ontology validation (Alharbi et al., 2024a, 2024b; Amini et al., 2024; Giglou et al., 2023; Hu et al., 2024; Llugiqi et al., 2025; Norouzi et al., 2025; Wei et al., 2023; Zhao et al., 2024), but they do not provide a methodology-driven, end-to-end ontology construction process with robust verification and resolution. In particular, existing LLM-based methods often overlook systematic syntax checking, logical consistency verification, and modeling quality assessment, leading to ontologies that are invalid or unusable in downstream reasoning tasks.
Our earlier work, NeOn-GPT (Fathallah et al., 2024a, 2024b), introduced a prompt-engineered ontology construction pipeline grounded in the NeOn methodology (Suárez-Figueroa et al., 2015) and coupled with a verification-and-resolution stage that integrates third-party tools (RDFLib (Krech et al., 2023), HermiT (Glimm et al., 2014), Pellet (Sirin et al., 2007), OOPS! ( OEG(2024), OEG; Poveda-Villalón et al., 2014)) with LLM-guided repairs. This combination enabled the automatic detection and correction of syntax errors, logical inconsistencies, and modeling pitfalls, producing draft ontologies that were consistently valid, unlike the outputs of prior LLM-based approaches (da Silva et al., 2024).
The contributions of the original NeOn-GPT (Fathallah et al., 2024a) paper are: Implementation of a prompt pipeline grounded in the NeOn methodology. NeOn-GPT, an LLM-driven ontology generation pipeline including a multi-step ontology draft generation phase and an extensive validation phase encompassing syntax, consistency, and modeling pitfalls check of the generated ontology. An empirical evaluation of NeOn-GPT using a single gold-standard ontology, the Stanford Wine Ontology, and a single LLM, GPT-3.5, comparing zero-shot prompting, a prompt pipeline derived from the Ontology Development 101 methodology (Noy & McGuinness, 2001), and the NeOn-GPT pipeline across structural metrics, hierarchy depth, axioms, properties, individuals, and inference behavior.
Our work (Fathallah et al., 2024a, 2024b) showed that LLM-generated ontologies differ from expert-curated gold standard ontologies, particularly in the depth of hierarchies and the coverage of domain-specific concepts. Expert-curated ontologies outperform LLM-generated ones not only because they are grounded in expert knowledge (Kampars et al., 2025), but also because ontology engineers reuse existing domain knowledge, both ontological and non-ontological resources, during construction (Kotis et al., 2020; Sowiński et al., 2022).
Moreover, our prior evaluation was limited to the Wine ontology, which may have been influenced by the fact that such domains are well represented in publicly available corpora and benchmarks and are therefore likely included in LLM training data (Brown et al., 2020; Mai et al., 2024; Petroni et al., 2019). To meaningfully assess LLM capabilities, a broader evaluation across domains with varying degrees of representation, including sparsely modeled domains, is required.
This article presents an enhanced version of NeOn-GPT. 1 We integrate a reuse stage of ontological and non-ontological resources in accordance with the NeOn methodology guidelines. We broaden the evaluation to assess LLM capability across heterogeneous domains, ranging from well-established ontologies to sparsely modeled knowledge areas.
This article makes the following contributions: We incorporate the reuse stage into the NeOn-GPT pipeline, allowing the identification, evaluation, and incorporation of expert-curated relevant ontology fragments during conceptual modeling (Section 3.1.4). We expand the empirical evaluation to four different domains (wine, sewer networks infrastructure, cheminformatics, and environmental microbiology), demonstrating the generality of the approach (Sections 5 and 6). We compare multiple LLMs, including GPT-4o and open-source models such as Mistral, LLama, and Deepseek, to assess model dependence and robustness (Section 5). We develop and apply a comprehensive evaluation framework for LLM-generated ontologies that assesses structural, lexical, and semantic alignment with gold-standard ontologies, enabling a multi-dimensional analysis of ontology quality beyond surface-level checks (Section 4).
The article is structured as follows: Section 2 reviews related literature. Section 3 presents our methodology. Section 4 outlines the evaluation metrics. Section 5 describes the experimental setup and Section 6 presents results and discussions. Section 7 presents the ablation study to assess the contribution of individual components of our approach and to analyze their impact on overall performance. Section 8 discusses the limitations of our approach. Finally, Section 9 concludes with a summary of contributions and presents directions for future work to address the limitations.
Related Work
Ontology Learning From Text
Ontology learning from text refers to the automatic or semi-automatic process of acquiring ontologies from unstructured textual data to construct them. This task has been a long-standing goal in the Semantic Web community, aiming to reduce the cost and complexity of manual ontology engineering while improving scalability and domain coverage (Biemann, 2005; Wong et al., 2012). Early approaches used rule-based and statistical methods; a prominent example is Hearst patterns, a rule-based method that identifies taxonomic relations such as hyponymy—the relation between a general entity and its more specific instances (e.g., ”animal” and ”dog”)—using lexico-syntactic cues, that is, fixed linguistic patterns like ”X is a type of Y” that signal hierarchical relationships in text (Hearst, 1998). Aussenac-Gilles et al. (2000) proposed a semi-automatic approach for constructing ontologies from domain-specific corpora by identifying relevant terms and extracting semantic relations such as synonymy, hypernymy, and meronymy through linguistic and contextual analysis. Maedche and Staab (2001) proposed a semi-automatic ontology learning framework that integrates natural language processing (NLP) to extract ontological structures from unstructured and semi-structured web data. Their approach involves multiple stages, including ontology import, entity and relation extraction, pruning, refinement, and evaluation, with an emphasis on human-in-the-loop guidance to enhance accuracy and domain relevance. The Text2Onto framework (Cimiano & Völker, 2005) introduces a probabilistic ontology model, which assigns confidence values to extracted elements such as concepts, taxonomic relations, and non-taxonomic relations. The framework supports incremental updates and user feedback, enabling continuous refinement of ontologies and enhanced uncertainty management in learned structures. Al-Aswadi et al. (2020) reviewed the transition from shallow learning techniques—such as association rule mining and clustering—to deep learning architectures capable of capturing richer semantic patterns. More recent efforts leverage neural networks and pre-trained language models to extract ontological components from large corpora with minimal supervision (Lourdusamy & Abraham, 2020).
Ontology Engineering Methodologies
Ontology engineering methodologies provide structured processes and best practices for developing, maintaining, and reusing ontologies. These methodologies guide developers through stages such as requirements specification, conceptualization, formalization, evaluation, and deployment, aiming to ensure both the semantic quality and practical utility of the resulting ontologies (Corcho et al., 2006; Fernández-López et al., 1997).
One of the earliest and most widely adopted methodologies is METHONTOLOGY, which defines a waterfall-like process encompassing specification, conceptualization, integration, implementation, and maintenance. It also emphasizes supporting activities such as knowledge acquisition and evaluation (Fernández-López et al., 1997). Pinto et al. (2004) proposed DILIGENT, a collaborative ontology development in distributed environments, offering mechanisms for managing user feedback and reconciling conflicting edits. SAMOD (Simplified Agile Methodology for Ontology Development) (Peroni, 2016) is an agile methodology that promotes ontology development through small, iterative steps. It emphasizes the use of exemplar domain descriptions and real-world data to create ontologies. This approach facilitates the early detection of inconsistencies, ensuring that the ontology remains aligned with practical use cases. RapidOWL (Auer, 2006) is another agile methodology for collaborative and iterative development of ontologies. RapidOWL’s agile paradigm relies on iterative refinement, annotation, and structuring of a knowledge base, allowing for the selective addition, removal, or annotation of information chunks. This methodology is suitable for scenarios that require lightweight, easy-to-implement solutions for spatially distributed, highly collaborative environments. eXtreme Design (XD)(Presutti et al., 2009) is a collaborative, iterative methodology that emphasizes the use of Ontology Design Patterns (ODPs) to address recurring modeling problems. XD adopts agile software engineering practices, such as test-driven development, pair programming, and modularization, and applies them to ontology engineering. The methodology guides developers through identifying relevant ODPs, adapting them to specific use cases, and integrating them into the ontology, thereby promoting reusability and consistency across ontology projects. Modular Ontology Modeling (MOMo) (Shimizu et al., 2023) is a modular, diagram-first ontology engineering methodology that builds on XD and emphasizes self-contained modules, curated ODP reuse, collaborative modeling with domain experts, and late-stage OWL generation. Its workflow covers use-case description, CQs, identification of key notions, selection of ODPs, creation of module diagrams, documentation, ontology composition, and final OWL formalization.
The NeOn methodology defines ontology development through a set of concrete activities and artifacts organized into nine development scenarios (Haase et al., 2008; Suárez-Figueroa et al., 2015). A scenario in NeOn represents a typical project situation, for example, building an ontology from scratch, reusing existing ontologies, reengineering non-ontological resources (e.g., XML schemas or databases), or integrating several ontologies into a network. Each scenario specifies the operational steps involved, such as drafting an Ontology Requirements Specification Document, identifying and evaluating candidate ontologies for reuse, extracting or restructuring modules, aligning heterogeneous resources, documenting modeling decisions, and performing evaluation. Rather than enforcing a fixed sequence, NeOn allows these steps to be combined and repeated as needed, enabling both iterative–incremental and waterfall-style execution. More recently, the Linked Open Terms (LOT) methodology (Poveda-Villalón et al., 2022) streamlines ontology development by adopting a lightweight set of steps focused on reuse, interoperability, and Web publication. LOT inherits NeOn’s reuse orientation but simplifies the process by emphasizing minimal documentation, agile iteration, and a web-first deployment approach.
To systematically select an appropriate methodological basis for an LLM-driven ontology engineering pipeline, we compared methodologies using evaluation criteria adapted from prior comparative studies (Sattar et al., 2020; Stadlhofer et al., 2013). These criteria cover the following methodological capabilities:
Our comparison in Table 1 shows that, unlike METHONTOLOGY and Ontology 101, NeOn supports collaborative ontology design by structuring how domain experts and ontology engineers contribute domain descriptions, examples, and reuse resources. This aligns well with LLM-based pipelines, where coordinated inputs can help reduce scope drift. DILIGENT focuses on governance and conflict resolution in distributed settings, but does not address reuse. Agile and lightweight approaches, including SAMOD, RapidOWL, and XD, emphasize rapid iteration and minimal documentation; while effective for small or well-bounded ontologies, their limited support for documentation and integration can be problematic in LLM-based pipelines and lead to modeling inconsistencies. MOMo offers stronger modular conceptualization and documentation, but lacks an explicit evaluation phase and does not treat integration/merging as a core methodological capability, making it less suitable than NeOn as the primary scaffold.
Comparison of Ontology Engineering Methodologies Using Criteria Adapted From (Sattar et al., 2020; Stadlhofer et al., 2013).

Comparison of Ontology Engineering Methodologies Using Criteria Adapted From (Sattar et al., 2020; Stadlhofer et al., 2013).
NeOn and LOT provide support for all criteria in Table 1; both are therefore reasonable candidates as methodological scaffolds for LLM-assisted ontology engineering. While both methodologies offer comprehensive support, they differ in how they operationalize reuse. NeOn provides scenario-specific procedures for identifying, evaluating, adapting, and integrating existing ontologies, ontology design patterns (ODPs), and non-ontological resources, including steps for module extraction, reengineering, combining multiple ontologies, and reusing ontology modules. LOT adopts a lightweight, implementation-oriented reuse strategy in which reuse occurs at the level of individual terms or modules from existing ontologies. It does not provide guidelines for identifying and evaluating candidate ontologies, reusing non-ontological resources, or combining multiple ontologies during development. In an LLM-based setting, NeOn’s procedural treatment of reuse is advantageous because it provides constraints for grounding LLM-generated content in established resources, thereby reducing the likelihood of hallucinated terms or unsupported modeling choices. In this work, we adopt the NeOn methodology as the basis for structuring our LLM-driven ontology generation pipeline.
The application of LLMs to ontology engineering has evolved through distinct phases, from automating discrete tasks (Alharbi et al., 2024; Allen et al., 2023; Kommineni et al., 2024b; Xu et al., 2024) toward systems that aim for full ontology generation (Giglou et al., 2023; Kommineni et al., 2024a; Mateiu & Groza, 2023; Saeedizade & Blomqvist, 2024; Zhang et al., 2024). Analysis of this progression reveals common limitations related to methodological grounding, verification, and scalability, which our work on NeOn-GPT directly addresses.
The first line of work examines the basic ontology-generation capabilities of LLMs across different prompting techniques. A representative example of this line of work is the study by da Silva et al. (2024), which evaluates zero-shot, one-shot, and few-shot prompting for generating capability ontologies from natural-language descriptions. The study assesses the outputs through OWL syntax checks, reasoning, and constraint validation. Their results show that few-shot prompting substantially improves structural correctness and completeness, whereas zero-shot prompting often yields incomplete or syntactically invalid axioms. In several cases, the generated ontologies required manual correction to resolve syntax errors and logical inconsistencies before they could be used. Moreover, ontology creation is treated as a single-step generation task tied to a fixed schema: the process does not incorporate requirements analysis, conceptualization, reuse of existing ontologies, or integration stages, nor does it support extending beyond the predefined structure.
The second line of work explores advanced prompting strategies. A representative of this paradigm is Ontogenia (Lippolis et al., 2024), which employs an advanced prompting technique, Metacognitive Prompting, to guide the LLM through a self-reflective process for creating an ontology grounded in the XD methodology. Its multi-stage process involves decomposing competency questions to identify entities and properties, followed by enrichment of axioms. However, its foundation in XD limits its reuse mechanism primarily to a static, pre-selected set of ODPs. This makes it less domain-agnostic, as it cannot function effectively where relevant ODPs are unavailable. In contrast, NeOn’s broader reuse guidelines can leverage ODPs when they exist, but are not dependent on them; they can alternatively incorporate ontologies or non-ontological resources. A further consequence of the XD methodology is its lack of documentation guidelines, as noted in Section 2.2, which is critical in LLM-based pipelines for traceability and mitigating scope drift. This limitation is directly evidenced in their results, where all generated ontologies consistently lack annotations, as flagged by the OOPS! Pitfall Scanner (P08). Their evaluation also reveals persistent modeling errors, such as incorrect domain/range assignments (P19) and missing inverse relationships (P13). The NeOn-GPT pipeline addresses these issues: it includes a dedicated formal modeling phase that prompts for property characteristics, such as inverses, and its integrated verification loop uses OOPS! to detect and correct critical pitfalls, such as P19, through iterative refinement.
The third line of work investigates LLM fine-tuning to internalize principles of ontology engineering. A representative of this paradigm is the work by Doumanas et al. (2025), which investigates the fine-tuning of LLMs on foundational ontology engineering textbooks to internalize syntactic and conceptual knowledge. Their approach relies on a single-stage, one-shot generation process in which a fine-tuned model is prompted to produce a complete ontology in a single step. While this approach enhances the model’s understanding of general principles of ontology engineering, it also reveals key limitations. The one-shot generation conflates the distinct, sequential stages of ontology engineering into a single, opaque transformation, which inherently constrains the scale and complexity of the output. This is evidenced by their results, which show that the generated ontologies remain much smaller than expert-curated benchmarks. Furthermore, the technique’s effectiveness was highly model-dependent; notably, the fine-tuned Mistral 7B struggled with syntactic precision, suggesting that smaller models did not benefit robustly from their approach. In contrast, the NeOn-GPT pipeline is a multi-stage, iterative process that decomposes ontology creation into well-defined phases, enabling systematic ontology construction.
The fourth line of work explores agentic AI systems for ontology engineering through interactive, human-in-the-loop workflows. Recently, such an approach has been implemented in metis, an AI agentic platform developed by Metaphacts (Aung et al., 2025). Its Semantic Modeling Assistant supports collaborative ontology development by guiding users through a structured modeling process based on the Linked Open Terms (LOT) methodology and metaphacts’ Semantic Modeling Guidelines. 2 The assistant helps formulate competency questions, supports reuse via the metaphacts Ontology Repository, 3 and assists with conceptualization, encoding, and evaluation through user-facing guidance, SPARQL-based checks, and LLM-based critique. While metis provides interactive guidance, implementation, and validation during the modeling process, NeOn-GPT differs in that it systematically prompts the LLM to generate and enrich formal ontology axioms—including object properties, inverse properties, and other property-level axioms—and integrates external OWL reasoners and modeling-pitfall detection tools to iteratively verify and repair these generated artifacts.
The novelty of NeOn-GPT does not lie in introducing new individual ontology learning techniques, but in the methodology-driven orchestration of existing LLM capabilities—spanning requirements specification, reuse, multi-stage generation, and integrated verification and repair—into a single, end-to-end pipeline whose outcome is a directly usable, verified ontology artifact. Finally, existing work treats syntactic validation, logical consistency checking, and modeling pitfall detection as isolated or post hoc checks rather than integrating them into a unified ontology-generation process that systematically produces verified and repaired ontology artifacts. Furthermore, the impact of applying a single methodology-guided pipeline across ontology domains with substantially different structures and complexities has not been systematically investigated. In this work, we address these gaps by applying the NeOn-GPT pipeline to four heterogeneous domains: wine, sewer networks infrastructure, cheminformatics, and environmental microbiology.
Prompt Engineering for Knowledge Engineering Tasks
LLMs exhibit significant variability in output quality depending on how prompts are formulated. Subtle changes in wording, structure, or context can lead to different responses. As a result, prompt engineering has emerged as a critical practice for guiding LLMs toward producing accurate, coherent, and context-aware outputs, particularly in complex tasks such as ontology engineering (Sahoo et al., 2024; White et al., 2023). Prompt engineering involves systematically designing instructions and examples that shape the model’s reasoning process and output format to align with task-specific requirements.
The remainder of this subsection reviews the four prompting techniques adopted in NeOn-GPT: few-shot prompting, role-play prompting, chain-of-thought prompting, and iterative prompting with feedback.
Methodology
In this section, we present the NeOn-GPT methodology, which is organized into two parts, as illustrated in Figure 1: The first part, ontology draft generation (Sections 3.1–3.1.7, Figure 1(a), Figure 2: Steps 1-7), operationalizes NeOn’s activities for requirements specification, conceptualization, reuse, implementation, formal modeling, and population to produce a Turtle ontology draft. In this extended version, these stages differ from the original NeOn-GPT pipeline (Fathallah et al., 2024a, 2024b, 2025b) through the inclusion of an explicit NeOn-guided reuse stage, as described in Section 3.1.4 (Figure 2: Step 4 in green). The second part, ontology verification and resolution (Section 3.2, Figure 1(b),(c),(d), (e)), relies on third-party tools for automated verification, with the LLM used to iteratively repair issues surfaced during verification.
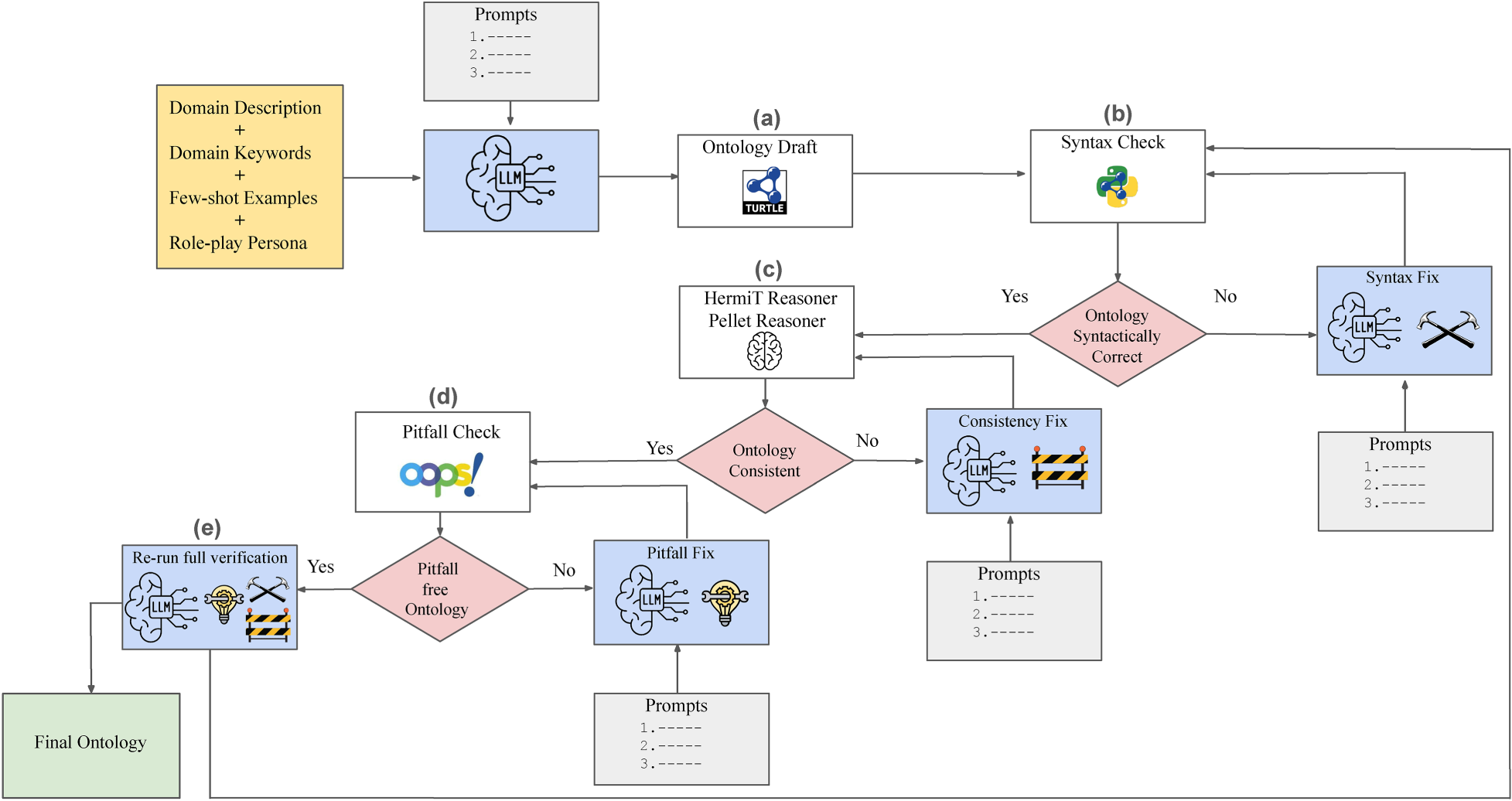
NeOn-GPT pipeline for ontology learning and verification. The pipeline consists of two components: (i) ontology draft generation (Section 3.1) and (ii) ontology verification and resolution (Section 3.2). Domain-specific inputs (domain description, domain keywords/key phrases, few-shot examples, and role-play personas) prompt the LLM to generate an ontology draft in Turtle syntax. The draft then undergoes a three-stage verification and resolution process: syntax checking with RDFLib, logical consistency checking with OWL reasoners (HermiT and Pellet), and pitfall detection with OOPS! service. Identified issues trigger corrective re-prompting cycles to fix syntax errors, logical inconsistencies, and common modeling pitfalls. This figure is adapted from our original NeOn-GPT architecture introduced in Fathallah et al. (2024a, 2024b).

Overview of the NeOn-GPT ontology draft generation stages. The process begins with the specification of requirements, then the generation of competency questions (CQs), conceptual modeling, and the reuse of existing knowledge resources. The pipeline proceeds through implementation, formal modeling (axiom enrichment), and documentation, and concludes with ontology population, resulting in a serialized ontology draft in Turtle syntax. Step 4 (Reuse, highlighted in green) represents the newly incorporated stage in this extended version of the pipeline, distinguishing it from the original NeOn-GPT architecture introduced in Fathallah et al. (2024a).
Our original NeOn-GPT pipeline (Fathallah et al., 2024a) performed well in domains such as Wine, where a compact, well-structured reference ontology is available, but it struggled in sparsely modeled domains, most notably in the life sciences (Fathallah et al., 2024b). In such settings, the LLM often lacked sufficient grounding to generate coherent conceptual models, resulting in shallow hierarchies, inconsistent terminology, and missing domain-specific relationships. These limitations motivated the introduction of the reuse stage in this extended methodology (Section 3.1.4), in which curated fragments of expert-maintained ontologies are incorporated in accordance with NeOn’s reuse guidelines. Inspired by earlier ontology engineering work on reusing legacy resources such as technical texts, textbooks, and existing databases (Staab et al., 2001; Sure et al., 2004), this stage is adapted to the LLM setting by selecting compact, high-value fragments that respect context-window constraints and demonstrate correct formalization, including valid syntax, logical consistency, and sound modeling practices. This addition strengthens the conceptual model and improves the reliability of ontology drafts, especially in domains with limited lexical or structural coverage.
The ontology draft generation part takes the following elements as input: a natural-language domain description (120-150 words), domain-expert-curated few-shot examples, the role-play persona, and 10-15 domain-specific keywords/key phrases, as shown in Figure 2. These inputs initiate the stepwise execution of the NeOn-aligned (Suárez-Figueroa et al., 2015) stages described in Section 2.2: requirement specification, competency-question generation, conceptual modeling, reuse, implementation, formal modeling, and enrichment & population. The output of this part is an ontology draft in Turtle syntax, including classes, properties, axioms, and named individuals.
Specification of Ontology Requirements
As shown in
This produces the requirement specifications that serve as the foundation for all subsequent steps in ontology draft generation. The prompt template is shown in Appendix A.2: Listing 1.
Competency Questions Generation
Following the requirements specification, we prompt the LLM to generate a set of competency questions (CQs) based on the requirements defined in
To support domain relevance, the prompt also includes a curated list of 10–15 domain-specific keywords/key phrases (e.g., Atom, Chemical Bond, Molecular Entity). These keywords/key phrases serve as semantic anchors, encouraging the model to generate CQs centered on the concepts important in the target domain.
As shown in
A few-shot CQ example used in the cheminformatics domain is:

Ontology Conceptualization
According to the NeOn methodology, the next stage involves ontology conceptualization, where entities and properties (or relations) are extracted and structured into a coherent model that reflects the domain’s semantics (
In our pipeline, this is operationalized by prompting the LLM to translate the CQs generated in
The prompt templates are shown in Appendices A.2: Listing 3, A.2: Listing 3.1, and A.2: Listing 3.2.



The output of this step is a conceptual model expressed as a set of subject–predicate–object triples that define the ontology’s core structure.
Ontology Reuse
The NeOn methodology emphasizes ontology reuse, incorporating existing knowledge resources (e.g., domain ontologies, vocabularies) or non-ontological resources (e.g., thesauri, taxonomies, structured datasets) to support the construction of new ontologies. NeOn prescribes a sequence of reuse activities: (i) identifying candidate ontologies and other knowledge resources, (ii) evaluating them with respect to coverage, quality, and license constraints, (iii) selecting appropriate resources or modules, and (iv) extracting and adapting relevant fragments.
Our empirical analysis revealed that supplying large ontology fragments directly to the LLM prompt for reuse reduced the model’s ability to follow the instructions, producing irrelevant or inconsistent output. Relying on the LLM’s pre-trained knowledge of existing ontologies for reuse led to hallucinated or nonexistent classes and relations. These limitations motivated the inclusion of a reuse stage in the pipeline, enabling the controlled incorporation of curated ontology fragments (Fathallah et al., 2024a, 2024b).
In this extended version of the pipeline, we incorporate a dedicated NeOn-guided reuse stage (Figure 2: Step 4 in green). Ontology engineers identify, evaluate, and extract suitable fragments from expert-curated ontologies, which are then injected into the prompt as few-shot examples. This ensures that reuse is performed systematically and that the incorporated fragments provide reliable, domain-accurate guidance during ontology draft generation. Ontology engineers draw on broader domain ontologies to extract elements for reuse in accordance with NeOn’s reuse activities. These include:
For instance, in the cheminformatics domain, ontology engineers extract fragments from the Environmental Ontology (ENVO) to introduce environmental and biological concepts. An example snippet is:

The prompt first introduces the concept of reuse to the LLM, explaining that selected ontology fragments and structural metadata will be incorporated into the conceptual model. The reuse materials are provided as few-shot examples, followed by the previously generated conceptual model in
Ontology Implementation
Following the NeOn methodology, once the conceptual model has been established, the next step involves implementing the ontology in a formal representation language (
Implementation prompts include cautionary guidance to avoid syntax errors, logical inconsistencies, and common modeling pitfalls (e.g., Wrong inverse relationships, Cycles in a class hierarchy, Multiple domains or ranges, and Wrong transitive relationships). They also instruct the model to enclose its output between predefined delimiters (e.g.,
Ontology Formal Modeling
As shown in
For each subtask, the LLM is prompted to analyze the ontology draft generated in

For each axiom type, the LLM is instructed with the axiom type and a usage example. The model is then instructed to analyze the ontology draft and add an axiom of that type, with suitable domain and range, only when semantically appropriate. For example, the prompt for inverse object properties explicitly states: “An inverse property expresses a two-way relationship between two concepts. If the ontology contains a property
This instruction follows the prompt template provided in Appendix A.2: Listing 6.2. The example below, drawn from the Cheminformatics domain, illustrates how the LLM generates an inverse property for an existing object property in the ontology draft.

To ensure format compliance, the prompt provides guidance to prevent both syntactic and modeling errors, maintain logical consistency, and instructs the LLM to place all generated properties between predefined markers (e.g.,
In this stage of the draft generation part, the LLM is prompted to analyze the ontology draft and populate it with
We use
To ensure correct integration into the ontology, the prompt includes cautionary instructions to avoid syntax and modeling errors, maintain logical consistency, and require the LLM to output individuals between predefined delimiters (e.g.,

Ontology Documentation
In the final stage of the draft-generation part (Figure 2: Step 8), the LLM is instructed to analyze the ontology draft and enhance it with documentation and metadata (e.g., ontology IRI, ontology label, version information) that improve interpretability and reuse. The model is prompted to add
Additionally, the LLM is prompted to generate standard metadata elements such as labels, IRIs, and versioning information. The output of this step is appended to the existing
Ontology Verification and Resolution
The second part of the methodology takes the ontology draft as input and performs verification and resolution using the third-party tools outlined in Figure 1(b),(c),(d),(e). In this stage, the draft undergoes multi-layered verification to identify errors related to syntax, logical consistency, and modeling quality. We adopt an iterative prompting-with-feedback strategy, in which diagnostic messages generated by these tools are incorporated into LLM prompts to guide error correction.
We use ROBOT as an explanation engine for logical inconsistency detected by the Hermit and Pellet reasoners. When ROBOT reports an inconsistency or unsatisfiable class, we invoke its
The LLM is prompted to propose a repair (add, delete, or replacement). The proposed patch is applied to the ontology, after which the Hermit and Pellet reasoners are re-run to assess whether the inconsistency has been resolved. This diagnosis-repair cycle repeats until Hermit reports no remaining inconsistencies or a maximum of 25 iterations is reached.
When OOPS! reports a pitfall that points to specific erroneous axioms, such as P03 (”Creating the relationship ’is’ instead of using
For pitfalls that do not correspond to specific axioms, such as P10 ”Missing disjointness,” where the ontology lacks any
Finally, once all syntax, logical consistency, and critical pitfall repairs have been applied, the ontology is subjected to a final verification pass in which syntax validation, logical reasoning, and critical pitfall detection are executed again. This final check ensures that repairs introduced at one stage do not reintroduce errors at another (e.g., logical repairs that introduce syntax errors, or pitfall corrections that introduce logical inconsistencies), and that the resulting ontology satisfies all verification criteria simultaneously. The prompt template is shown in Appendix A.3
Evaluation
To assess the LLM’s ability to represent internal parametric domain knowledge as formal knowledge representations, we compare the generated ontologies with gold-standard benchmarks using structural analysis, lexical similarity, and semantic similarity as outlined in Figure 3. Our analysis does not aim to measure the completeness of the generated model; rather, it uses these expert-curated references (gold-standard ontologies) to diagnose the typology of knowledge gaps inherent to models operating without domain-specific corpora. Gold-standard evaluation is widely used to assess automatically constructed ontologies, in which the generated model is compared with an expert-curated reference to quantify its structural and semantic quality (Maedche & Staab, 2002; Ponzetto & Strube, 2007; Zavitsanos et al., 2010). However, we do not treat the gold standard as a replication target, but rather as a baseline for distinguishing between simple omissions and fundamental representational domain-knowledge deficits in parametric memory.
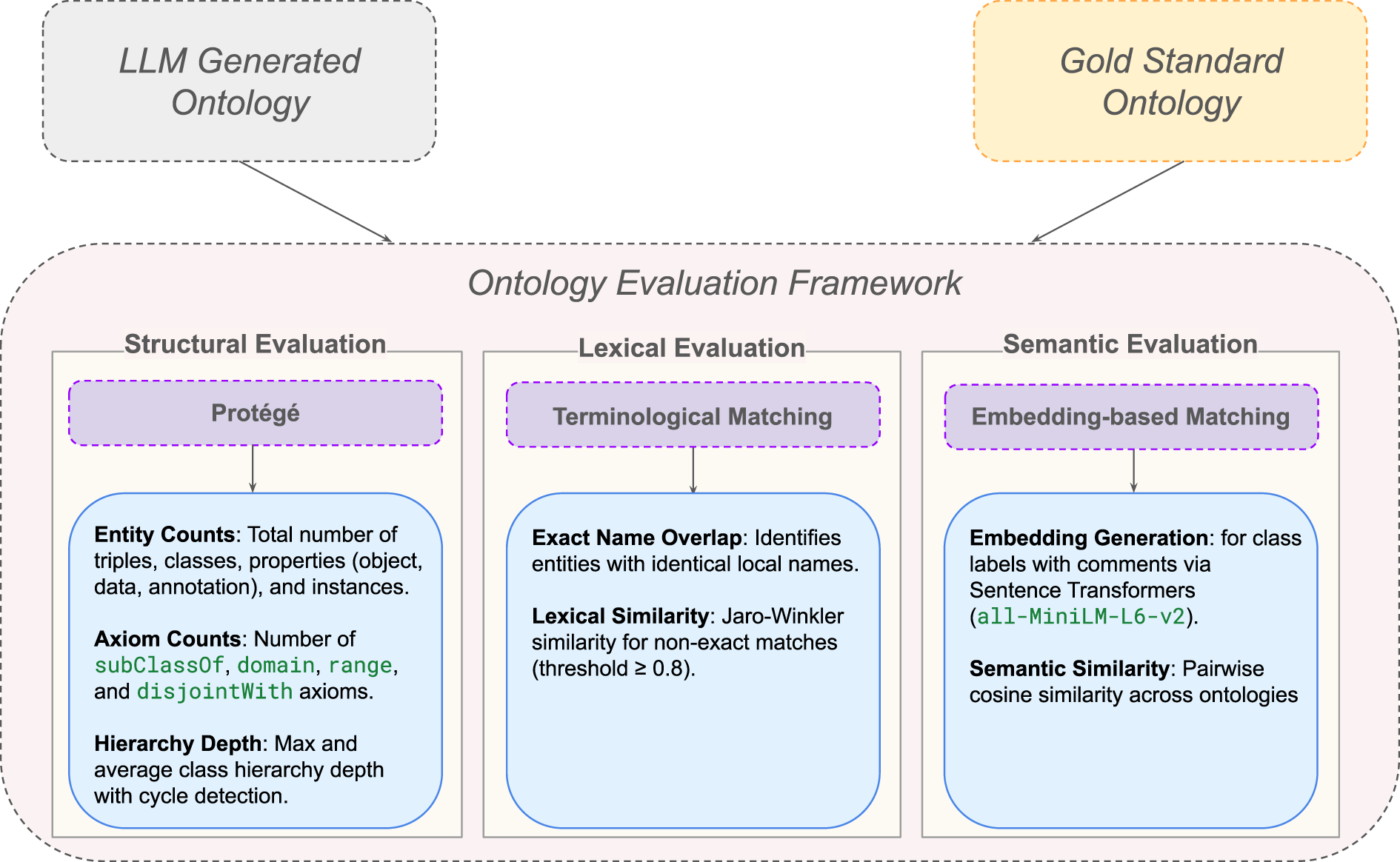
Overview of the ontology evaluation framework used to assess LLM-generated ontologies against expert-curated gold standards. The two ontologies serve as inputs to the evaluation framework. Within each module, the indicated tool or matching method is applied to derive the corresponding evaluation metrics. Solid arrows denote input/output flow, dashed boxes indicate tools or methods, and blue rounded boxes summarize the extracted metrics. The framework comprises three core modules: structural evaluation via Protégé (Musen, 2015), lexical evaluation using terminological matching, and semantic evaluation based on embedding similarity. Each component applies techniques and metrics to quantify structural fidelity, lexical similarity, and semantic similarity.
Our evaluation metrics follow established practices in ontology quality assessment.
Structural Evaluation
Structural evaluation examines the ontological structures produced during NeOn-GPT’s Ontology Draft Generation (Figure 2: Steps 1–8) and assesses how LLM-generated ontologies organize classes, properties, constraints, individuals, and documentation relative to expert-curated ontologies. All metrics are extracted using Protégé’s ontology metrics and property panels (Musen, 2015).
However, structural evaluation captures only the size and organization of an ontology; it does not assess whether the generated terminology aligns with domain vocabulary, motivating the complementary lexical evaluation that follows.
Lexical Evaluation
Lexical evaluation investigates the degree of terminological overlap and similarity between the LLM-generated and gold standard ontologies.
Yet lexical similarity remains sensitive to naming variation and cannot capture semantically equivalent concepts expressed with different labels, motivating the semantic evaluation layer introduced next.
Semantic Evaluation
Semantic evaluation measures the conceptual correspondence between the LLM-generated ontology and the gold-standard ontology using dense vector embeddings and cosine similarity, following the evaluation approach introduced in our prior work (Fathallah et al., 2025b).
To obtain semantic representations, we use the SentenceTransformer model
The evaluation consists of two complementary components:
Together, these two measures capture semantic correspondence at both the entity and relational levels, allowing us to assess whether the generated ontology encodes concepts and schema patterns that are semantically compatible with those in the gold standard ontology, even when lexical forms or structural patterns differ.
Experiments
To evaluate the effectiveness and adaptability of the extended NeOn-GPT pipeline, we conduct experiments across four domains using four LLMs. We aim to assess how well the pipeline generalizes across knowledge domains of varying complexity and how its performance varies with the underlying LLM.
Domains
We select four domains that reflect a spectrum of structural depth and the varying levels of domain expertise required for ontology construction:
Gold Standard Ontologies
The ontologies used in the assessment across all domains are as follows:
LLMs
We apply the NeOn-GPT pipeline using four pretrained LLMs. They were selected for their demonstrated effectiveness in knowledge extraction and ontology engineering tasks such as triple generation, schema induction, and concept hierarchy construction (Meyer et al., 2023; Polat et al., 2025). Their inclusion also supports a comparative analysis between proprietary and open-source models, which differ in their reasoning capacities and deployment constraints.
Experiment Setup
Each run begins with a domain description (120-150 words), a curated list of 10–15 domain-specific keywords/key phrases, a few-shot examples, and a domain-specific persona (See Figure 1). The LLM is then guided through all NeOn-GPT stages described in Section 3. This process is repeated independently for each of the four selected domains, using the four language models, resulting in sixteen ontologies (four domains
Results and Discussion
Structural Analysis
The structural evaluation examines how effectively NeOn-GPT guides LLMs in constructing ontologies with coherent size, organization, and semantic structure, relative to established gold-standard ontologies. Since LLMs were not provided with the same datasets or expert resources used to build the gold ontologies, the goal is not to reproduce them. Rather, this evaluation assesses whether the ontologies generated through our methodology exhibit appropriate scale and structural patterns characteristic of mature domain ontologies. It is essential to note that this evaluation examines how LLMs structure the ontology without making claims about correctness or fidelity to a gold standard; that is, structural analysis does not assess whether the specific classes, properties, axioms, or constraints generated by the LLMs match those defined in the gold standard ontologies.
Structural Size
This subsubsection examines the TBox-level footprint generated during
Comparison of Structural Size, Coverage, and Hierarchy of Gold-Standard and NeOn-GPT-generated Ontologies Across Four Domains, Generated Using GPT-4o, Mistral Large (123B), Llama 4 Maverick (17B active/400B total), and DeepSeek V3.2 Exp (671B). GPT-4o’s (Parameter Count not Publicly Disclosed). Subclasses Correspond to the Number of SubClassOf Axioms; Metrics Were Extracted using Protégé (Musen, 2015).

Comparison of Structural Size, Coverage, and Hierarchy of Gold-Standard and NeOn-GPT-generated Ontologies Across Four Domains, Generated Using GPT-4o, Mistral Large (123B), Llama 4 Maverick (17B active/400B total), and DeepSeek V3.2 Exp (671B). GPT-4o’s (Parameter Count not Publicly Disclosed). Subclasses Correspond to the Number of
Across all four domains, LLM-generated ontologies are smaller than their gold-standard counterparts, yet the relative ordering of domains by scale is preserved: Environmental Microbiology consistently yields the largest LLM outputs and Sewer Networks are the smallest.
In moderately scaled domains, class counts show mixed alignment with the gold standard. For Wine, Mistral-large (144 classes) and DeepSeek (267) closely bracket the gold (138), while GPT-4o (55) and Llama-4 (51) substantially under-generate. For Sewer Networks, three of the four models generate class counts close to the gold (115), with GPT-4o at 110, Llama-4 at 114, and DeepSeek at 130; Mistral slightly over-generates at 141. In Cheminformatics, all models fall significantly short of the gold’s 349 classes, with DeepSeek performing best at 163 (47% of gold). Mistral produces only 70 classes — 20% of the gold standard—yielding an ontology that is substantially below the gold standard, not only in scale but also in conceptual coverage.
Axiom and logical-axiom counts exhibit a more nuanced pattern. In smaller and medium-sized domains (Wine, Cheminformatics, Sewer Networks), LLM-generated ontologies are generally of the same order of magnitude as the gold standards and in some cases exceed them. In Cheminformatics, Mistral and DeepSeek match or surpass the gold in logical axioms (496 and 695 vs. 494). In Sewer Networks, DeepSeek produces 1,686 axioms and 642 logical axioms against the gold’s 951 and 249. Environmental Microbiology is a clear outlier: the gold ontology’s 78,840 axioms and 16,303 logical axioms are entirely out of reach, with the best-performing model (DeepSeek) producing only 2,028 axioms and 494 logical axioms—approximately 2.6% and 3.0% of the gold values, respectively. This reflects the inability of current LLMs to represent the deeply nested terminological structure of large biological knowledge systems solely from a brief natural-language description.
To investigate the internal composition of logical axiom counts, we decompose them into four accountable components:
Comparison of Structural Property Characteristics and Detailed Object Property Characteristics (Inverse, Functional, Transitive, Symmetric, and Reflexive) for Gold-Standard and NeOn-GPT-Generated Ontologies Across Four Domains, using GPT-4o, Mistral Large (123B), Llama 4 Maverick (17B active/400B total), and DeepSeek V3.2 Exp (671B); Metrics Were Extracted using Protégé (Musen, 2015).

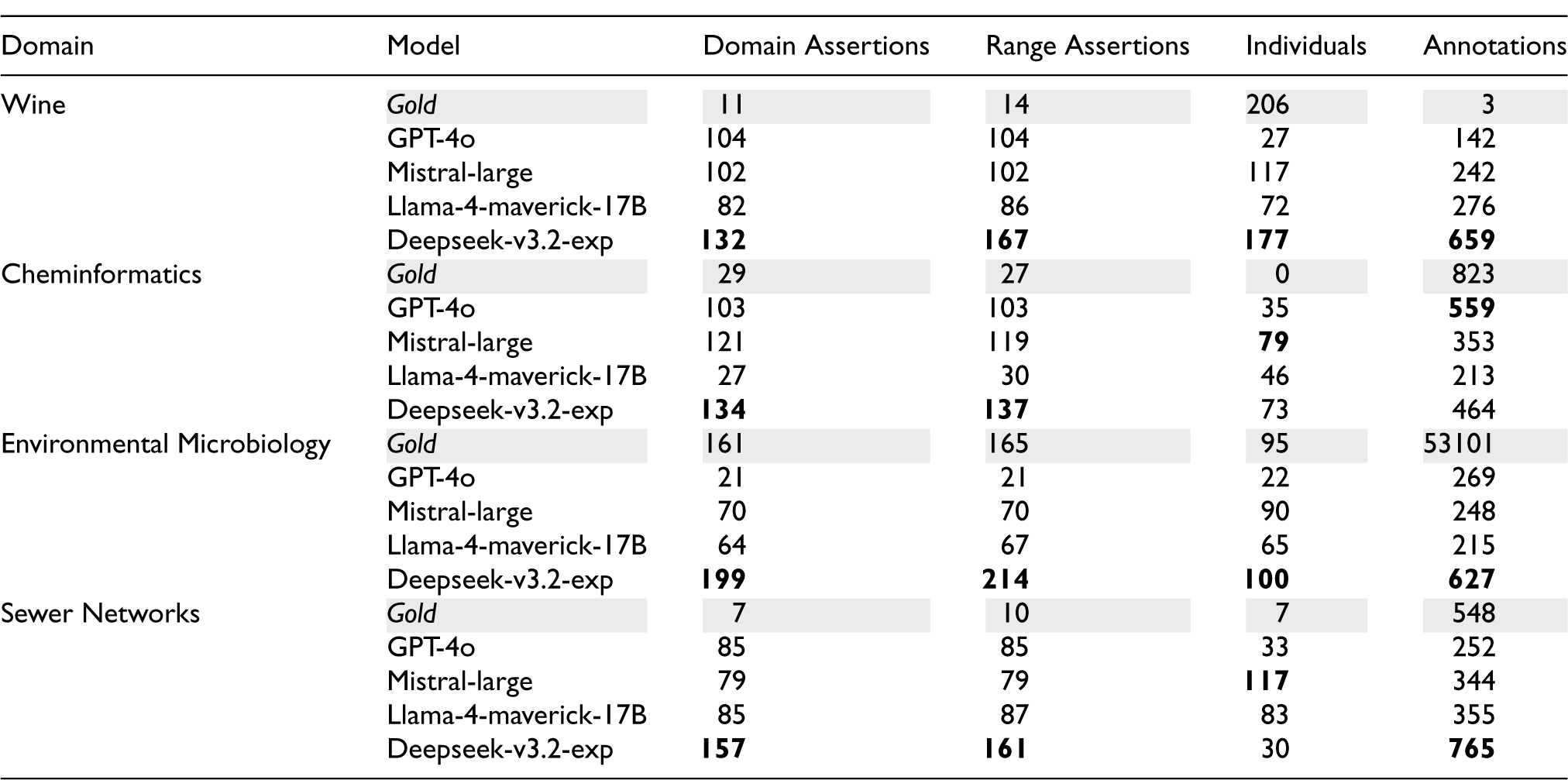
Comparison of Schema-Level Domain and Range Axioms, Individuals, and Annotation Assertions (Including Labels, Comments, and Other Metadata Annotations) for Gold-Standard and NeOn-GPT-Generated Ontologies Across Four Domains, using GPT-4o, Mistral Large (123B), Llama 4 Maverick (17B active/400B Total), and DeepSeek V3.2 Exp (671B); Metrics Were Extracted using Protégé (Musen, 2015).
Key Observations: Structural Size results
LLMs preserve relative domain complexity ordering but cannot reproduce an absolute axiomatic scale, especially in large scientific domains. In small-to-medium domains, axiom counts are within the same order of magnitude as gold standards; Environmental Microbiology is a clear outlier. Logical axioms are disproportionately concentrated in the RBox over the TBox—LLMs favor relational expressivity over taxonomic depth. DeepSeek produces the richest structures overall; Mistral is the Most variable; Llama-4 generates broad, but poorly organized, schemas. High logical axiom counts do not imply rich TBox structure—The GPT-4o Wine result illustrates how restriction axioms can inflate counts independently of the named-class hierarchy.
This subsubsection examines the hierarchy-building output of
Raw depth metrics alone do not fully characterize hierarchy structure. A complementary indicator is the
In Wine, Cheminformatics, and Sewer Networks, maximum depth values are generally within one to two levels of the gold standard. DeepSeek matches the gold depth in Wine (3) and Sewer Networks (4), and achieves the greatest depth in Cheminformatics (3 vs. gold 5). However, depth alone does not characterize hierarchy quality: Mistral in Cheminformatics reaches depth 1 with only 9 SubClassOf axioms across 70 named classes, indicating that virtually all classes are positioned as direct children of the root with no intermediate conceptual structure.
Environmental Microbiology presents a qualitatively distinct and more challenging pattern. The gold ontology reaches a maximum depth of 27, reflecting the fine-grained taxonomic refinement characteristic of biological classification systems. All LLM-generated ontologies are capped at a maximum depth of 3, regardless of class count (which ranges from 92 to 342 across models). Crucially, this three-level ceiling is
Key Observations: Structural Hierarchy
Gold ontologies exhibit pervasive multiple inheritance (subclass-to-class ratio In simpler domains, LLM-generated hierarchy depth approximates the gold within one to two levels; DeepSeek consistently achieves the greatest depth. In Environmental Microbiology, all models, regardless of architecture are capped at depth 3 against a gold depth of 27—a systematic generative limitation, not a model-specific one.
Structural Property Characteristics
Table 3 presents a detailed
Key Observations: Property Characteristics
Inverse property assignment is the least reliably reproduced characteristic—LLMs over-generate in simple domains and under-generate in complex ones. Functional properties are consistently under-produced, mirroring expert practice of using strict cardinality constraints sparingly. LLMs assign reflexive properties in domains where the gold has none, reflecting a tendency to over-apply property characteristics.
Schema-Level Domain and Range Assertions
Schema-level constraints generated in
A further structural regularity worth noting is that in Wine and Environmental Microbiology, most LLMs produce nearly identical domain and range counts (e.g., GPT-4o Wine: 104 domain, 104 range; Mistral Wine: 102 domain, 102 range), whereas the gold standards show modest asymmetry (Wine: 11 domain, 14 range). This symmetry is unusual in expert practice, where some properties are intentionally left unconstrained on one side and are consistent with templated prompt-driven generation rather than case-by-case semantic judgment.
Key Observations: Schema Constraints
Domain and range generation scales reliably with the property generation, confirming that NeOn-GPT prompts effectively elicit schema constraints alongside properties. Near-identical domain and range counts per model—unlike the modest asymmetry seen in gold standards — suggest templated rather than semantically reasoned constraint assignment.
Instance Population Characteristics
Annotation and Documentation Characteristics
The gold Environmental Microbiology ontology is a notable outlier with 53,101 annotation assertions—roughly two orders of magnitude above any LLM output and all other gold ontologies. This count reflects the gold Environmental Microbiology ontology’s extensive reuse of externally annotated vocabularies, and should not be interpreted as a direct annotation target for LLM-generated outputs, which operate from a brief natural-language description.
Key Observations: Instances and Annotations
Instance and annotation counts scale proportionally with the ontology size, indicating consistent adherence to the NeOn-GPT population and documentation prompts. LLMs introduce individuals even in schema-only gold ontologies, reflecting a tendency to generate illustrative examples. LLMs consistently produce a higher ratio of annotation axioms to logical axioms than gold standards, reflecting a tendency to prioritize natural-language descriptions alongside formal structure.
Model-Specific Structural Tendencies
The four models exhibit distinct and complementary structural tendencies. GPT-4o favors broad relational schema construction with shallow hierarchies, making it well-suited for early-stage domain exploration. DeepSeek consistently generates the richest structures in absolute terms across all metrics, though it remains far below expert-curated density in large scientific domains. Llama-4 produces broad but weakly organized schemas with disproportionately few SubClassOf axioms relative to its class count. Mistral is the most variable, performing near gold-standard scale in some domains while substantially under-generating in others. Taken together, the results indicate that different models emphasize different aspects of ontology structure, including relational schema construction, instance population, and lightweight conceptual modeling, rather than exhibiting uniform behavior across all modeling tasks.
Lexical Analysis
The lexical evaluation described in Section 4.3 assesses the extent to which NeOn-GPT guides LLMs to generate terminology that aligns with the conceptual vocabulary of gold-standard ontologies. We measure (i) exact lexical matches (see Appendix B.2, where Table 6 reports the detailed results) and (ii) high-similarity matches using Jaro–Winkler similarity
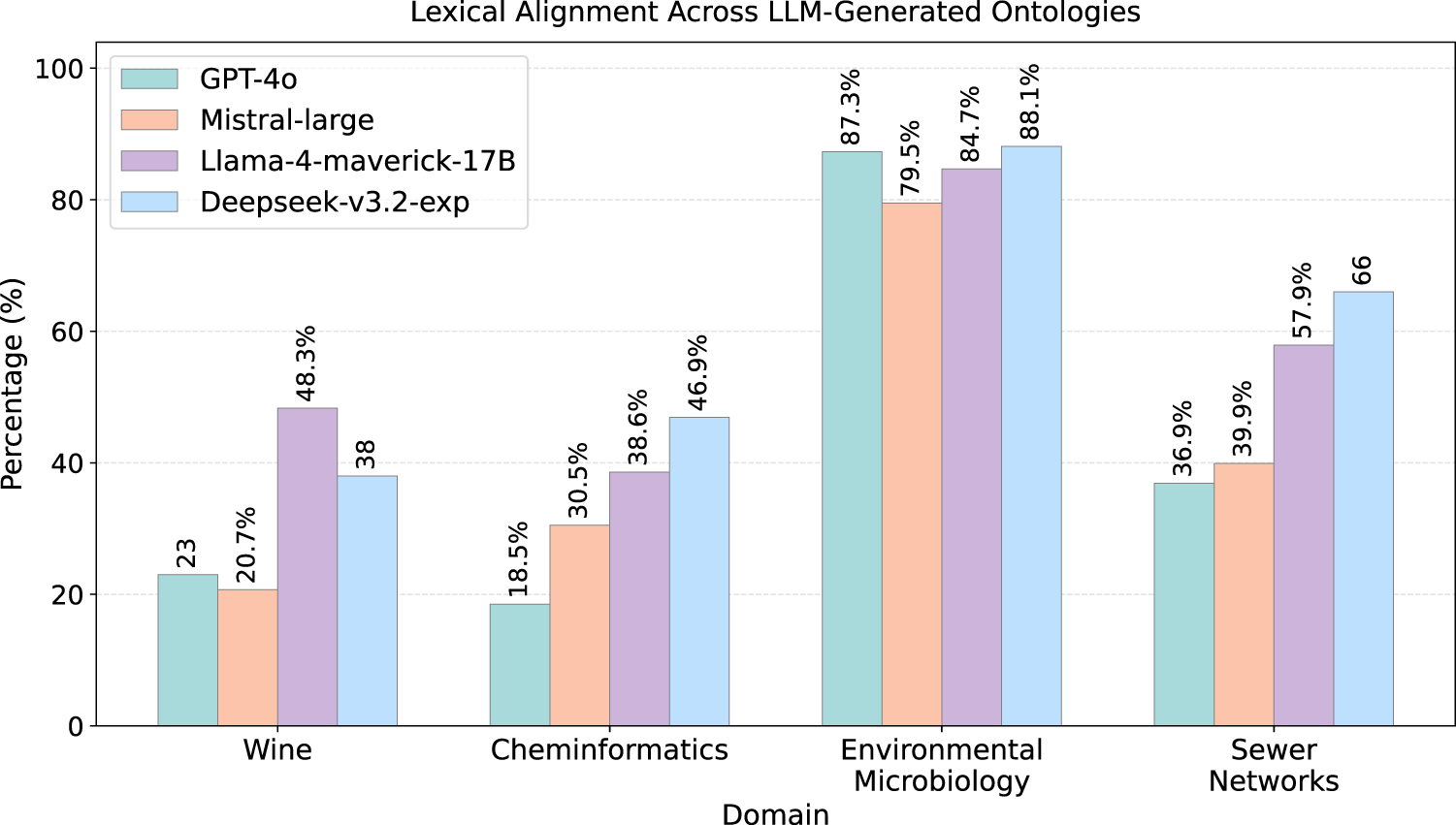
Environmental Microbiology exhibits the strongest lexical alignment, driven by widely used scientific terminology (e.g.,
Cheminformatics consistently yields the weakest lexical overlap. The absence of exact matches across all models reflects the highly specialized nature of CHEMINF terminology, which uses formal identifiers (e.g.,
Wine and Sewer Networks show intermediate alignment, supported by domain vocabulary that is broadly represented in general-purpose training corpora. In Wine, Llama-4 and DeepSeek achieve the highest similarity (see Figures 13 and 16), supported by exact matches such as
At the model level, DeepSeek achieves the highest lexical similarity in three of four domains; GPT-4o produces conservative but coherent vocabularies; Mistral is the most variable, performing well in Environmental Microbiology but substantially lower in Wine and Cheminformatics.
Key Observations: Lexical Alignment Lexical alignment is strongly conditioned on whether the gold ontology uses natural-language-proximate labels or formalized ones, as well as naming conventions. Domains with broadly used vocabularies enable strong alignment; formalized identifier-based domains (Cheminformatics) do not. DeepSeek achieves the highest lexical similarity in most domains; GPT-4o produces conservative but coherent vocabularies; Mistral is the most variable.
Semantic evaluation measures the extent to which NeOn-GPT-generated ontologies capture conceptual rather than lexical correspondence with gold-standard ontologies. Using the entity- and triple-level embedding framework described in Section 4.4, we assess whether LLMs reproduce domain semantics through structurally meaningful and contextually aligned concepts and relations.
The results show that the majority of entity and triple similarities cluster in the 0.5–0.8 cosine-similarity range across all domains and models (see Figures 5 to 8), indicating stable partial alignment rather than random correspondence. Although very high-similarity matches (
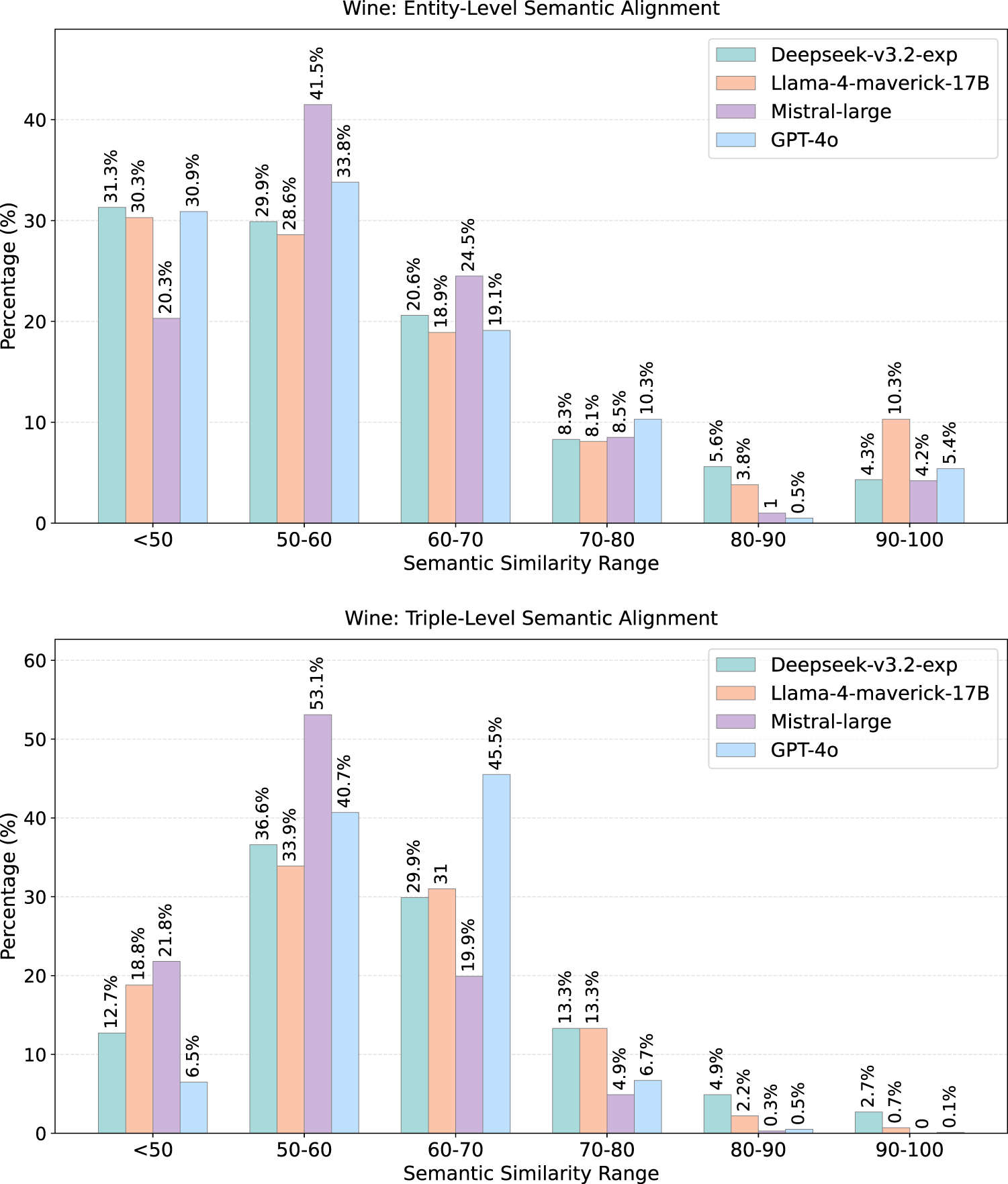
Entity-level (top) and triple-level (bottom)
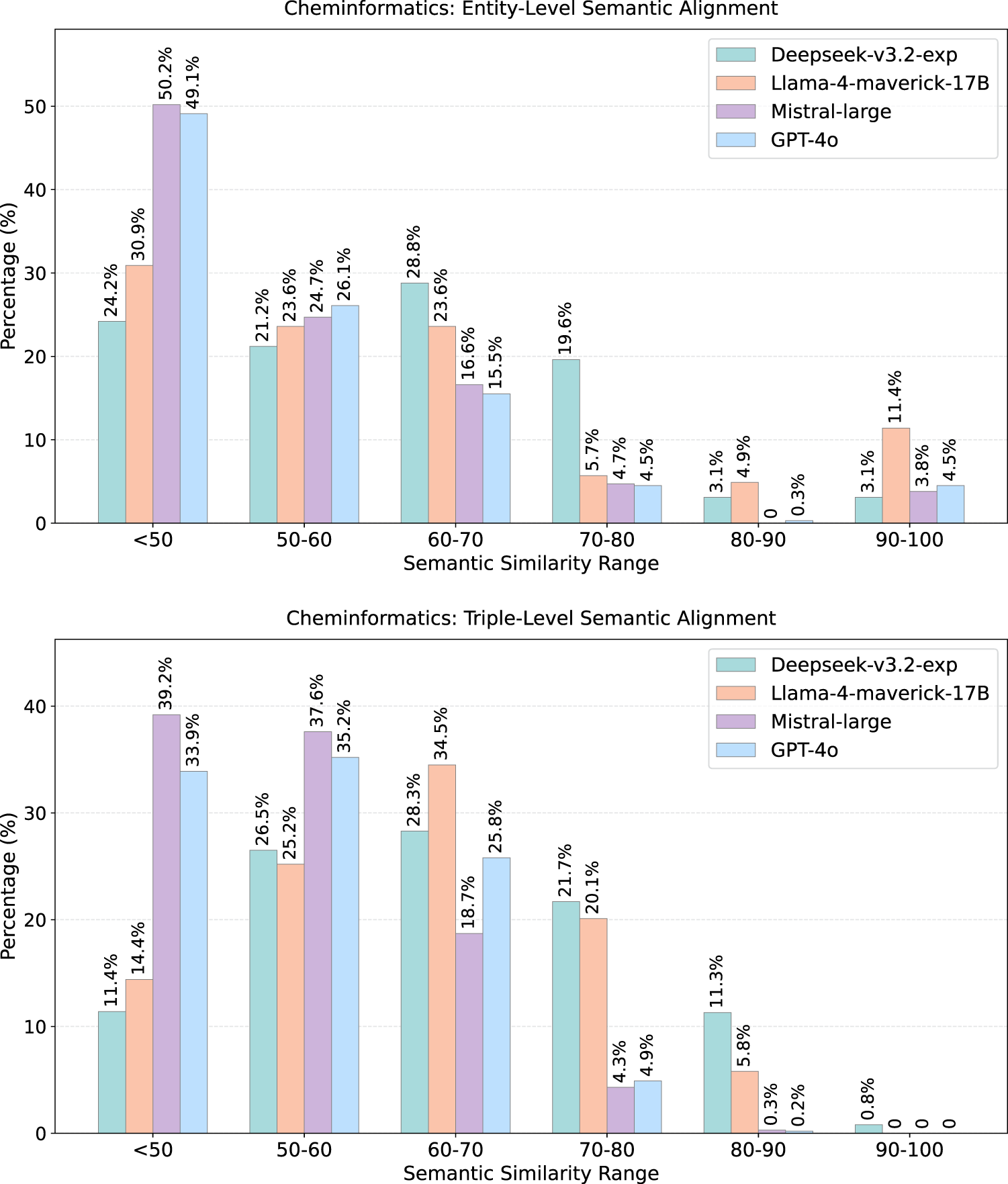
Entity-level (top) and triple-level (bottom)
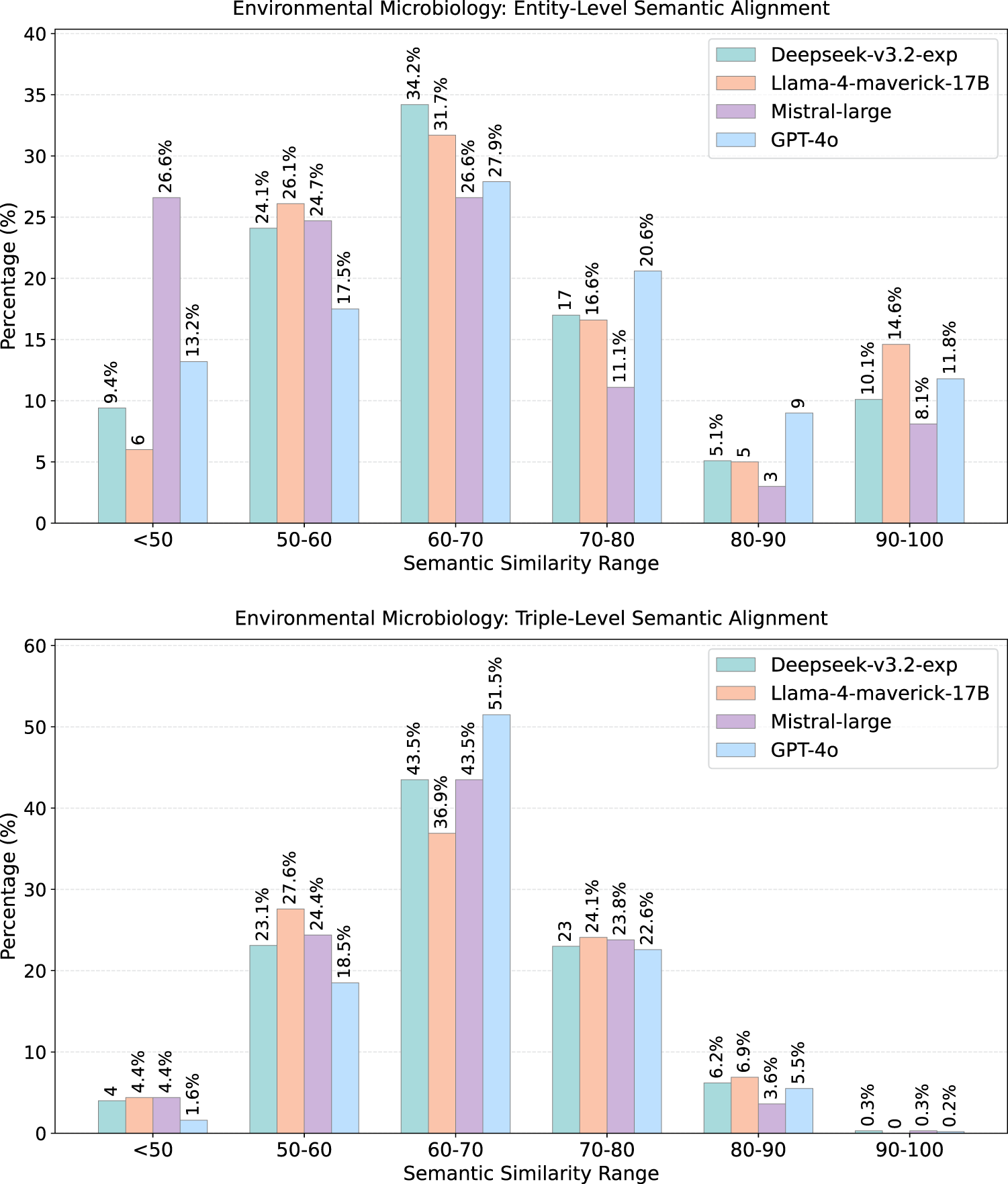
Entity-level (top) and triple-level (bottom)
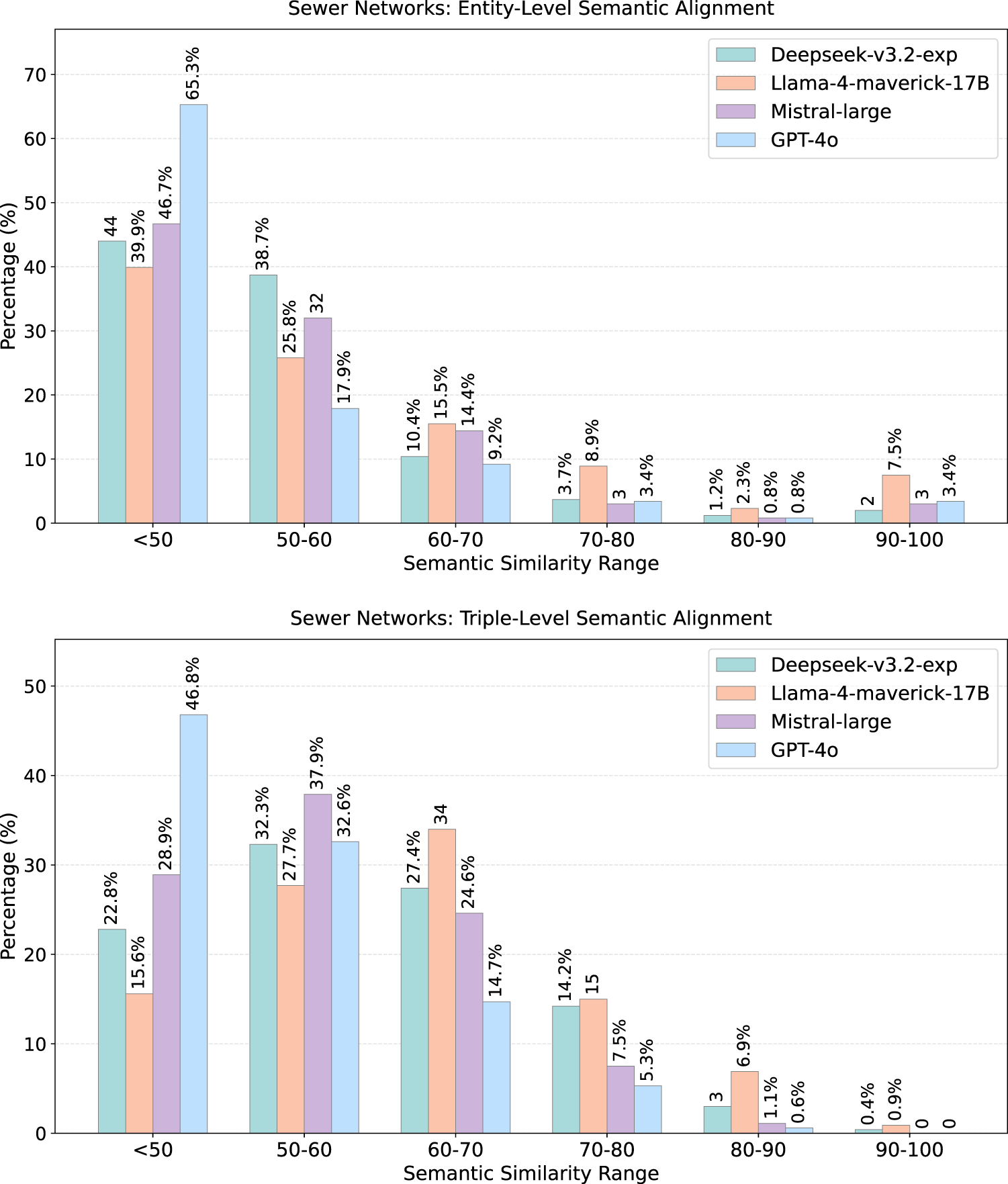
Entity-level (top) and triple-level (bottom)
Domain-level trends mirror those observed in lexical alignment. Environmental Microbiology exhibits the strongest semantic alignment, reflecting the broad representation of biological and environmental terminology in LLM training corpora. Wine and Sewer Networks show moderate alignment, consistent with domains grounded in widely documented real-world concepts. Cheminformatics yields the weakest semantic similarity: its reliance on formal identifiers and chemistry-specific constructs leads to widespread low-similarity matches despite otherwise coherent generated terminology.
Entity embeddings consistently achieve higher similarity than triple embeddings across all domains. This indicates that LLMs capture the conceptual meaning of individual classes and properties more reliably than the relational structures linking them. Triple-level similarity exhibits a spread toward lower similarity buckets, reflecting the greater difficulty of reconstructing schema-level relations such as subclass paths and domain–range patterns.
At the model level, DeepSeek achieves the strongest alignment across all domains; Mistral is the most variable; GPT-4o shows stable but conservative alignment; Llama-4 performs comparably to DeepSeek in linguistically accessible domains, but lags in more technical ones.
Key Observations: Semantic Alignment Most entity and triple similarities fall in the 0.5-0.8 cosine-similarity range, indicating stable partial alignment, not random correspondence. Entity-level similarity consistently exceeds triple-level similarity: LLMs capture concept meaning more reliably than relational structure. Semantic alignment follows the same domain ordering as lexical alignment, confirming that training corpus coverage is the primary driver. DeepSeek leads across all domains; Mistral is the most variable; GPT-4o shows stable but conservative alignment.
We conducted an ablation study of the NeOn-GPT pipeline to assess the contribution of the verification and resolution stage to the generation of syntactically valid and logically consistent ontologies. This stage comprises (i) Turtle syntax validation using RDFLib, (ii) logical consistency checking using OWL reasoners, and (iii) modeling-pitfall detection using OOPS! (See Figure 1(b),(c),(d),(e)). The goal of this ablation is to quantify the effect of removing this stage on syntactic validity, logical consistency, and the presence of critical modeling pitfalls, while keeping all other components of the pipeline unchanged.
Ablation Setting
We compare two configurations: Full NeOn-GPT: the complete NeOn-GPT pipeline, including ontology draft generation followed by validation and resolution using RDFLib, OWL reasoners, and OOPS!. NeOn-GPT (–Verification/Resolution): an ablated variant in which the verification and resolution stage is entirely removed. In this configuration, the ontology produced at the end of the ontology draft generation stage is considered final, without undergoing detection or resolution of syntax errors, logical inconsistencies, or modeling pitfalls.
All other aspects of the pipeline are held constant across configurations, including prompts, domain descriptions, few-shot examples, ontology reuse strategies, and LLM settings.
The ablation is evaluated on the full set of 16 generated ontologies (4 domains
Syntax errors: whether the ontology contains Turtle syntax errors when parsed. Logical inconsistencies: whether the ontology is reported as inconsistent by OWL reasoners. Critical modeling pitfalls: the number and type of critical pitfalls detected by OOPS!.
Each indicator is measured independently for the Full and Validation/Resolution configurations. No additional filtering, repair, or post-processing is applied in the ablated setting.
Ablation Results
Table 5 summarizes the impact of removing the verification and resolution stage across all sixteen ontologies. The results reveal systematic differences between ontology drafts produced without this stage and the final validated ontologies, across all three evaluated dimensions.
Ablation Study Results for NeOn-GPT on 16 Ontologies (4 Domains
4 LLMs). Results are Reported Before (w/o) and After (w/) the Validation and Resolution Stage. For Critical Modeling Pitfalls, we Report Both the Total Number of Detected Critical Pitfalls (#) and the Corresponding OOPS! Pitfall Codes (Types). C and I Indicate Consistent and Inconsistent Ontologies, Respectively.
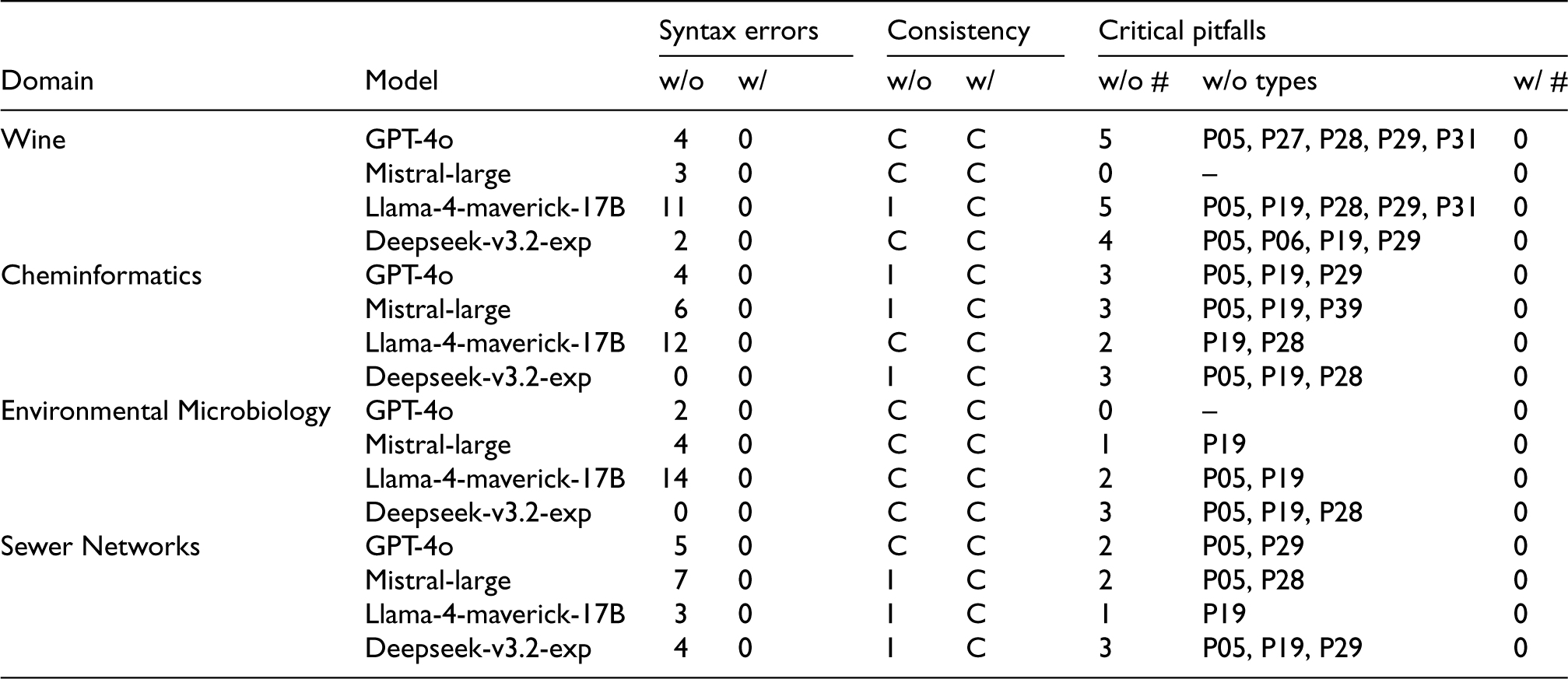
Ablation Study Results for NeOn-GPT on 16 Ontologies (4 Domains
In terms of syntactic validity, ontology drafts generated without verification and resolution exhibit non-trivial numbers of Turtle syntax errors across most domain–model combinations. The number of syntax errors ranges from 2 to 14 in three of the four domains, with the highest counts observed for Llama-4-maverick-17B in Environmental Microbiology (14 errors) and Cheminformatics (12 errors), and for Mistral-large and GPT-4o in Sewer Networks (up to 7 and 5 errors, respectively). After applying the verification and resolution stage, syntax errors are fully eliminated in all cases, yielding syntactically valid ontologies for all domains and models.
Logical consistency shows a similarly clear separation between the two configurations. Without verification and resolution, logical inconsistencies occur in 7 out of the 16 generated ontologies, spanning all domains except Environmental Microbiology. These inconsistencies are not confined to a single model or domain, appearing, for example, in Cheminformatics and Sewer Networks across multiple models, and in the case of Wine, for Llama-4-maverick-17B. Following validation and resolution, all ontologies are reported as logically consistent, indicating that the resolution stage systematically addresses reasoning-level violations introduced during the draft generation stage.
The most pronounced differences appear in the analysis of critical modeling pitfalls. In the ablated configuration, critical pitfalls are detected in 13 out of the 16 ontologies, with counts ranging from 1 to 5 per ontology. These pitfalls span multiple OOPS! categories, most frequently including P05 (inverse relationships not explicitly declared), P19 (missing domain or range), and P28/P29 (incorrect or missing property constraints), with additional domain- and model-specific occurrences such as P06, P27, P31, and P39. Notably, even when no logical inconsistency is reported, critical modeling pitfalls remain, indicating that syntactic and logical validity alone are insufficient to guarantee modeling quality. Formal definitions of all critical OOPS! pitfalls referenced in this analysis are provided in Appendix C.
After applying the verification and resolution stage, no critical modeling pitfalls are detected in any of the final ontologies. This holds across all domains and models, including cases where multiple distinct pitfall types co-occur in the ablated setting. Taken together, these results indicate that the verification and resolution stage plays a decisive role not only in enforcing syntactic correctness and logical consistency but also in systematically eliminating high-severity modeling defects that persist across domains and language models.
A first limitation of the NeOn-GPT pipeline concerns the nature and scope of the inputs provided to the LLMs. For each domain, the models receive only a concise natural-language description (120–150 words), a short list of 10–15 domain-specific vocabulary terms, at most six few-shot examples, and, along with the extracted fragments of existing ontologies relevant to the domain for reuse (See Section 3.1 and Figure 2). This input is substantially more limited than the resources typically available to ontology engineers when constructing gold-standard ontologies, which often include extensive domain corpora, controlled vocabularies, user stories, detailed requirement specifications, and multi-source documentation. Consequently, the LLM-generated ontologies tend to underperform on structural metrics, producing smaller schemas, fewer axioms, and hierarchies with limited depth, because the models are not exposed to the full depth of domain knowledge used to create the reference ontologies.
A second limitation is the reliance on manual effort to prepare domain descriptions, few-shot examples (including fragments extracted from domain-relevant ontologies for reuse), and domain-specific keywords/key phrases. While these inputs are comparatively lightweight, they may increase configuration overhead, hindering scalability.
A third limitation concerns reproducibility under stochastic generation. In our experiments, we report one ontology per model and domain, generated with fixed prompts and deterministic verification tools. While this supports the reproducibility of the pipeline execution, it does not quantify run-to-run variance in the generated ontologies.
Finally, our verification-and-resolution loop (syntax parsing, consistency checking, and pitfall detection) ensures that evaluated ontologies are syntactically valid, logically consistent, and free of Critical pitfalls. However, these checks do not guarantee conceptual completeness or agreement with all expert modeling choices, especially in large domains with deep taxonomic structures. We also acknowledge potential bias or ontology drift from LLM pretraining data and reused material; grounding and validation can mitigate, but not eliminate, these effects. Moreover, LLM-based repair may follow an Occam ’s-razor-like strategy, removing problematic elements rather than repairing or replacing them (Fathallah et al., 2025a), so an ontology may become correct or consistent while losing domain coverage.
Conclusion and Future Work
The combined structural, lexical, and semantic analysis demonstrates that LLMs can generate ontologically relevant concepts and properties. However, they do not reliably replicate the size, hierarchical depth, or specific naming conventions of established expert-curated ontologies. They tend to produce smaller structures but often generate richer properties. These findings and limitations suggest several directions for advancing LLM-based ontology engineering.
First, the current pipeline relies on expert-crafted examples for few-shot prompting and domain-specific natural language descriptions, which can increase the manual effort required to adapt the pipeline to new domains. With recent advances in LLM retrieval and agent-based systems, future work could integrate retrieval-augmented generation (RAG) to automatically source relevant few-shot examples and candidate reuse fragments from curated knowledge bases, domain corpora, or ontology repositories. Alternatively, a multi-agent architecture could delegate few-shot example generation and LLM-generated persona validation to specialized agents, reducing the dependency on human experts while maintaining domain alignment.
Second, future work should evaluate robustness under stochastic generation by performing multi-run experiments per model and domain. This requires reliable ontology-level alignment, consolidation, and conflict resolution across independent runs.
Third, quantitative assessment of practitioner-level impact remains an open step. While prior user studies on LLM-assisted ontology engineering (e.g., OntoChat Zhang et al., 2024) suggest that engineers may prefer delegating early-stage tasks, such as requirements elicitation and competency question generation, to LLM-based systems, we do not measure time or effort reductions in this work. A controlled user study across both simple and complex domains is an important next step in evaluating whether NeOn-GPT accelerates or simplifies ontology construction in practice.
Fourth, the analysis of model-specific tendencies (Section 6.1.7) reveals that different LLMs exhibit complementary strengths and weaknesses, including variation in structural coverage, property richness, and hierarchy construction. This suggests that future ontology generation systems could benefit from ensemble or mixture-of-experts architectures, in which specialized models are dynamically selected or combined for different stages of ontology construction (e.g., conceptual modeling, hierarchy refinement, or property generation). Such systems could exploit model diversity by combining structurally conservative models with those that generate richer semantic relations, thereby improving overall ontology quality and robustness.
Finally, extending evaluation beyond single gold standards is a promising direction. Comparing generated ontologies against multiple expert-curated ontologies per domain would enable analysis of inter-expert variation and perspective-dependent modeling choices, and would clarify how LLM-generated artifacts align with alternative expert conceptualizations. We also emphasize that deployment in sensitive domains (e.g., biomedical or environmental knowledge) should remain expert-supervised, and future work should further investigate risks of bias, drift, and attribution in AI-assisted ontology generation.
Footnotes
Acknowledgements
Work by N. Fathallah and S. Staab was supported by the German Research Foundation (DFG)—SFB 1574—471687386. Work by A. Algergawy was partially supported by German Federal Ministry of Education and Research (BMBF) through the project Innovation-Platform MaterialDigital (project funding FKZ no 13XP5094F).
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the German Research Foundation (DFG) through SFB 1574 (grant no. 471687386). The work of A. Algergawy was partially supported by the German Federal Ministry of Education and Research (BMBF) through the project Innovation-Platform MaterialDigital (grant no. 13XP5094F).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Notes
Appendix
Detailed Evaluation Results
Critical OOPS! Pitfalls Detected in the NeOn-GPT-Generated Ontologies
This section provides the definitions of the critical modeling pitfalls reported in Table 5. All definitions correspond to the official OOPS! catalog and are listed in numerical order for reference.