
Abstract
Machine learning (ML) has evolved rapidly over recent years with the promise to substantially alter and enhance the role of data science in a variety of disciplines. Compared with traditional approaches, ML offers advantages to handle complex problems, provide computational efficiency, propagate and treat uncertainties, and facilitate decision making. Also, the maturing of ML has led to significant advances in not only the main-stream artificial intelligence (AI) research but also other science and engineering fields, such as material science, bioengineering, construction management, and transportation engineering. This study conducts a comprehensive review of the progress and challenges of implementing ML in the earthquake engineering domain. A hierarchical attribute matrix is adopted to categorize the existing literature based on four traits identified in the field, such as ML method, topic area, data resource, and scale of analysis. The state-of-the-art review indicates to what extent ML has been applied in four topic areas of earthquake engineering, including seismic hazard analysis, system identification and damage detection, seismic fragility assessment, and structural control for earthquake mitigation. Moreover, research challenges and the associated future research needs are discussed, which include embracing the next generation of data sharing and sensor technologies, implementing more advanced ML techniques, and developing physics-guided ML models.
Keywords
Introduction
Machine learning (ML) has played a pivotal role in many areas of science, finance, and engineering. By definition (Samuel, 1959), ML is a field of study that gives computers the ability to learn without being explicitly programmed. ML algorithms can be divided into two main types: supervised learning and unsupervised learning. Supervised learning uses prior knowledge of the labeled data set to learn a function that best approximates the relationship between input and labeled output in the data. In contrast, unsupervised learning aims to infer the natural structure present with a set of data points that have no target labels. Depending on the data characteristics (i.e. discrete or continuous) and task goals, supervised learning can be further subdivided into classification and regression, while unsupervised learning comprises clustering and dimensionality reduction. Figure 1 summarizes the two types of ML and some commonly used ML algorithms (Kong et al., 2018).
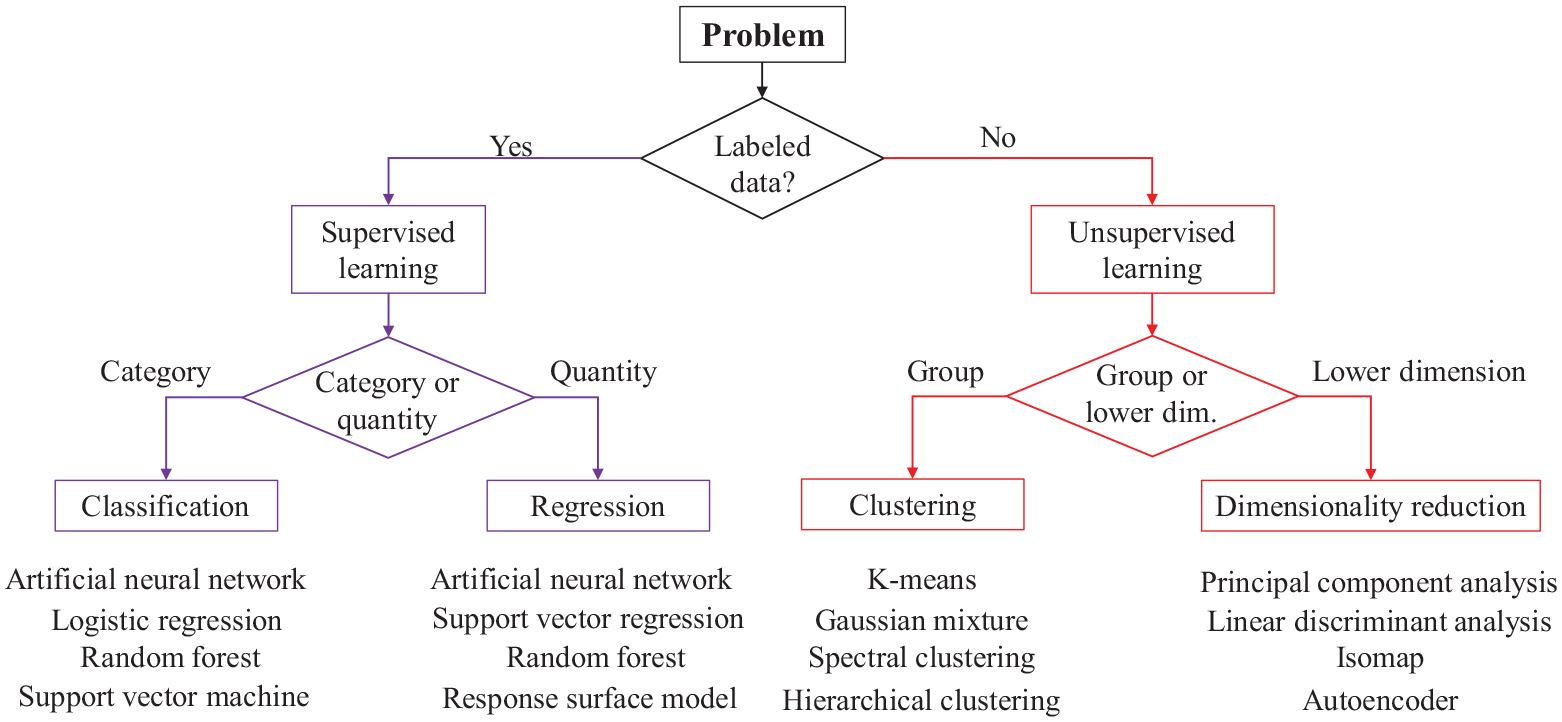
ML types and some commonly used ML algorithms (Kong et al., 2018).
Previous studies have surveyed the applications of ML and other advanced soft computing tools in civil engineering. Adeli (2001) reviewed the works on the integration of artificial neural networks (ANNs) with different computing paradigms, such as genetic algorithm (GA), fuzzy logic, and wavelet analysis, to enhance the application of ANNs in civil/structural engineering. An extensive literature study of evolutionary computation in the context of structural design, such as topological optimum design, has been conducted by Kicinger et al. (2005). In a separate review, Liao et al. (2011) demonstrated the soundness of employing metaheuristics in addressing optimization problems in project and construction management, where metaheuristics involve high-level procedures designed to find, generate, or select heuristics for optimization. Thereafter, a similar study by Saka and Geem (2013) has reviewed different mathematical modeling schemes on the optimum design of steel frames. A general review has been made by Lu et al. (2012) to examine various artificial intelligence (AI) algorithms in solving civil engineering issues. The stochastic nature of soil behavior in geotechnical engineering has also attracted the significant use of AI techniques, where review studies have been conducted on both shallow foundations (Shahin, 2014) and pile foundations (Shahin, 2016). Following Adeli’s (2001) study, a review of the recent applications of ANNs on civil infrastructure has been performed by Amezquita-Sanchez et al. (2016), where several topics have been covered, including structural system identification, structural health monitoring, structural vibration control, structural design and optimization, prediction applications, construction engineering, and geotechnical engineering. Recently, Salehi and Burgueño (2018) summarized the involvement of ML, pattern recognition (PR), and deep learning (DL) in structural engineering, whereas an overview of the ML applications in seismology was provided by Kong et al. (2018) who discussed the benefits of practicing ML algorithms in earthquake detection and phase picking, earthquake early warning, ground motion prediction, seismic tomography, and earthquake geodesy.
Although some of the review works have touched on a few of the ML applications in earthquake engineering, a comprehensive review is lacking in this area. As such, it is unclear to what extent ML has permeated the earthquake engineering domain, enabling and advancing research or supporting decision makers to reduce the effects of seismic hazards on civil structures. Earthquake engineering is an interdisciplinary engineering branch that describes earthquake hazard at the source, characterizes site effects and structural response, evaluates seismic risk and vulnerability, as well as assesses seismic protection measures. Within each subfield, ML algorithms indeed have been implemented in numerous circumstances. Prominent academic databases, such as Web of Science, Engineering Village, and Wiley Online Library, were used to search and select the publications that have titles or keywords consisting of ML algorithms in an earthquake engineering context. The search results indicate that nearly 200 relevant publications are now available, with a clear exponential growth in publications that intersect these two fields. A survey of this work is of interest to systematically present theoretical background of the commonly used ML methods, historical context on their use, state-of-the-art of research developments, potential challenges, as well as future promises.
The body of knowledge of the reviewed publications can be categorized according to four traits in the field, such as ML method, topic area, data resource, and scale of analysis. The available research is designated to different sets of attributes grouped by these four traits. Table 1 provides a portion of the attribute matrix for some example studies, while the complete list of studies and the description of the column headings (e.g. 1a) can be found in the Appendix (provided as a supplementary file). As illustrated in Table 1, a hierarchical structure is formed to explore the literature related to each attribute and its relation with other attributes. Such a structure makes clear the linkages across all studies that can facilitate implementation of research outcomes; improve data generation, sharing, and collection; provide reference work for model validation and comparison; and assist in identifying long-term future work.
Matrix of attributes for sample studies reviewed in this article

ML: machine learning.
This article focuses on reviewing the literature using the first two traits, namely, ML method and topic area. As shown in Figure 2, seven classes of ML methods have found the most use to date in four topic areas in earthquake engineering. The seven classes of ML methods are ANN, support vector machine (SVM), response surface model (RSM), logistic regression (LR), decision tree (DT) and random forest (RF), hybrid methods that couple two or more soft computing algorithms, and all other methods (e.g. evolutionary computing (EC) and genetic expression programming (GEP)) that are not significant in number of applications. The four topic areas include (1) seismic hazard analysis, (2) system identification and damage detection, (3) seismic fragility assessment, and (4) structural control for earthquake mitigation. These four topics are defined to be extensive enough to capture the full range of ML applications in earthquake engineering, but simple enough such that each topic represents a generally distinct area of research. First, seismic hazard analysis consists of the studies that predict the level of ground shaking and its associated uncertainty at a given site or location. Also, the use of ML tools to evaluate soil liquefaction potential and predict the liquefaction-induced lateral spread displacement is considered within this area. The second topic is a twofold area where system identification comprises a collection of studies that utilize ML to emulate a structural system and predict its deterministic seismic response, and damage detection is broadly defined as the use of ML models to recognize, classify, and assess seismic damage to civil structures. Third, seismic fragility assessment that incorporate various sources of uncertainties has shown to be a promising and popular field to practice ML techniques, where ML methods have been employed to develop probabilistic seismic demand models (PSDMs) and parameterized fragility functions. The fourth topic area lies in ML-equipped active and semi-active control of structures that mitigate the adverse effects of earthquake hazards. As is depicted in Figure 2, ANN gains the highest total number of applications, reflecting its robustness of tackling various types of problems in earthquake engineering. Conversely, the most popular method in seismic fragility assessment turns out to be RSM, which has been more frequently implemented than other ML methods. Examples of ML applications in these four topic areas are provided in Figure 3.
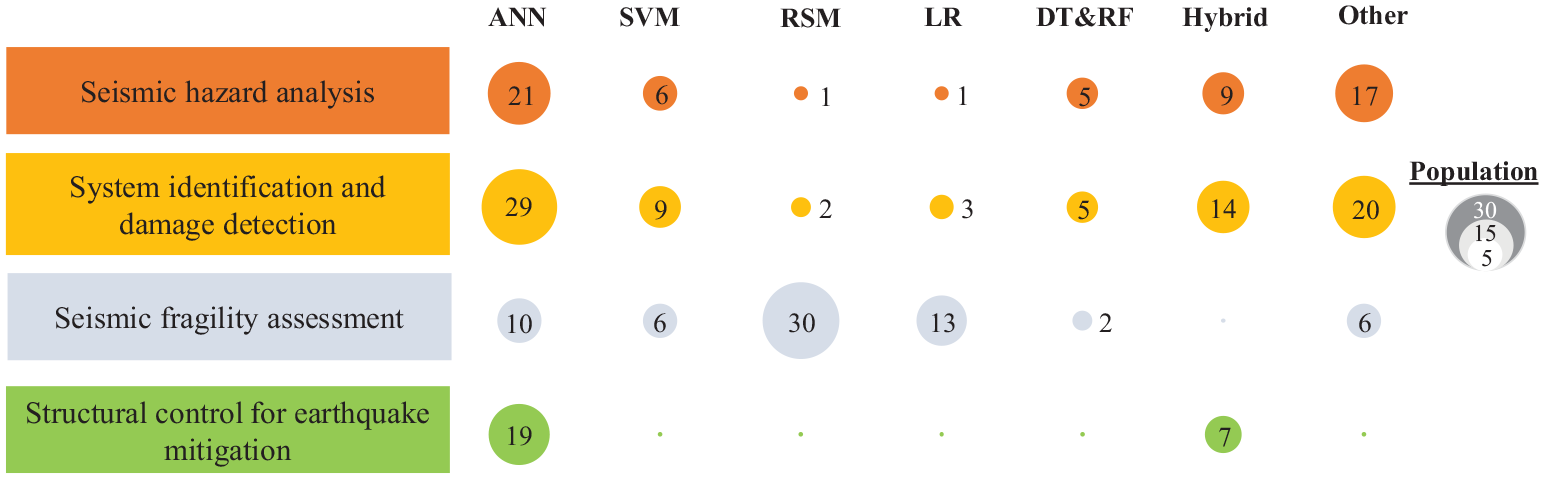
Applications of seven classes of ML methods in four topic areas in earthquake engineering.
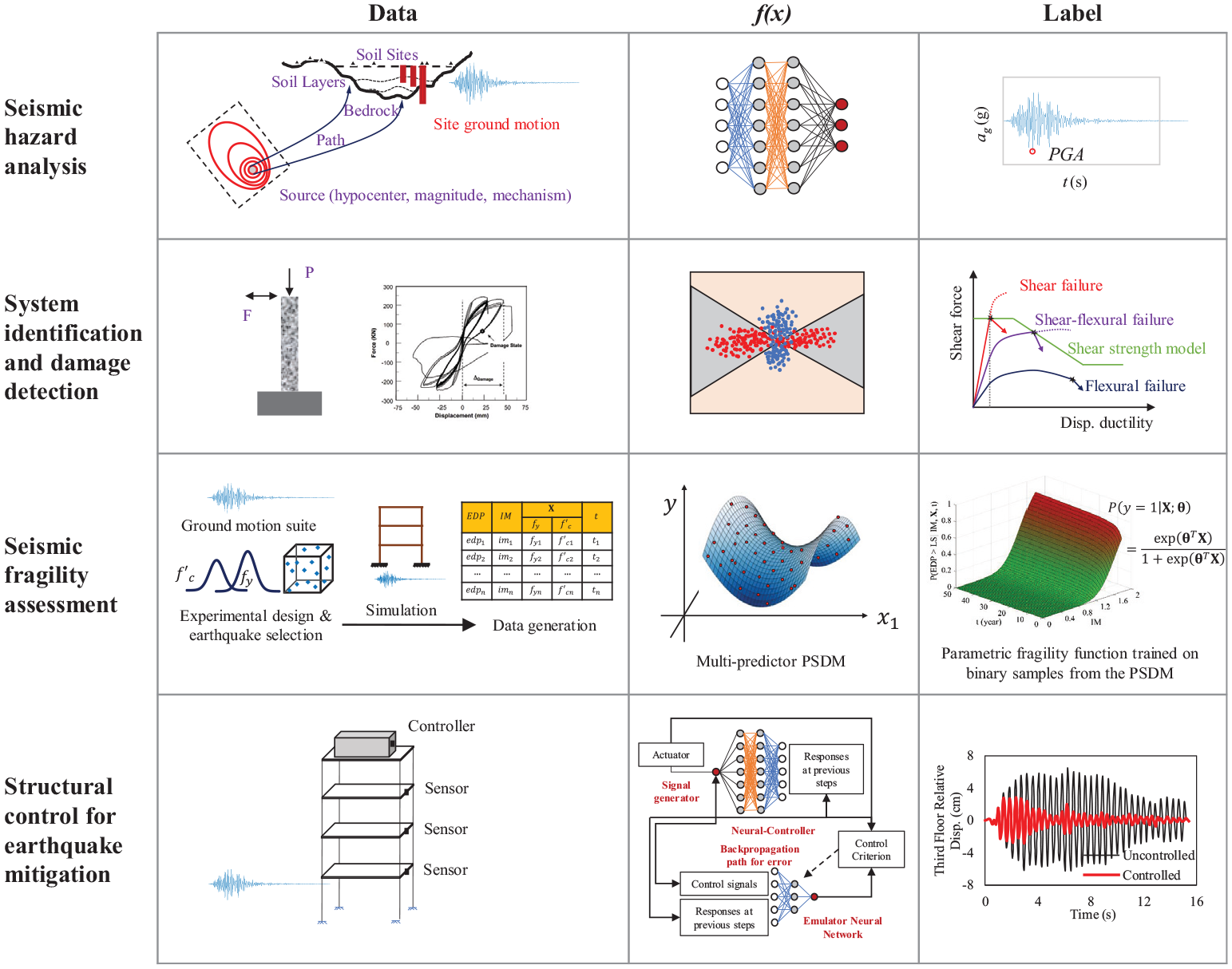
Example ML applications in earthquake engineering: The top row shows training an ANN to predict the PGA of ground motions using strong motion databases; the second row shows predicting the column failure mode by applying a quadratic discriminant analysis approach to laboratory data; the third row shows the development of multi-predictor PSDM and multidimensional fragility model through RSM and LR; the fourth row shows the results from coupling ANNs with active control to mitigate seismic response of the building.
This article serves as the first comprehensive survey on the applications of ML in earthquake engineering, attempting to be comprehensive of the primary themes in the literature to date. The common classes of ML methods and their four areas of applications are investigated in detail in order to understand the current state of the field, elucidate connections across existing literature, and pave the path to promote broader and more fundamental ML advances in solving related research issues in earthquake engineering. In the next section, this article presents the technical background for commonly used ML methods to provide context and foundation for discussing their application in earthquake engineering. Subsequently, the history and state-of-the-art applications of various ML algorithms in each of four topic areas within earthquake engineering are reviewed, shedding light on what subfields of earthquake engineering have benefited (or are benefiting) from the promise of ML methods. Moreover, a discussion of existing challenges and future opportunities concludes the article in anticipation of the future growth of ML applications in the earthquake engineering domain.
ML methods used in earthquake engineering
The theoretical background of ML methods is discussed in this section. As shown in Figure 2, representative ML methods are considered as ANN, SVM, RSM, LR, DT&RF, and Hybrid methods that couple ANN with other soft computing algorithms, such as fuzzy logic and wavelet analysis. It is worth mentioning that there exist other ML methods that have a limited number of applications. These ML methods, which are listed in the “Other” category in Figure 2, are not discussed in this section because of the limited space.
Artificial neural network
First developed by McCulloch and coworkers (Perlovsky, 2000), a “shallow” ANN typically consists of three layers: the input layer, hidden layer, and output layer. In particular, model variables in the input layer are weighted and fed into the hidden layer that consists of a series of nonlinear relationships such as sigmoidal functions, which are further weighted and fed into the output layer to provide a regression or classification model. Connection weights are learned in the forward propagation and updated through a training process that minimizes the prediction error, which is typically propagated in the backward direction. The classic ANN can be extended to be a deep neural network (DNN), or DL, that incorporates multiple hidden layers (LeCun et al., 2015). The deep architecture in a DNN consists of multiple processing layers and nonlinear transformations, enabling superior model performance without requiring well-selected features as inputs. The structure of ANNs is especially suited for modeling the behavior of ill-posed problems with nonlinear and intricate patterns. However, finding the optimal structure and tuning the model parameters could be challenging, potentially producing over-fitted models if not trained carefully. Additional information on ANN is available in the literature, such as Bishop (2006) and Murphy (2012).
Support vector machine
SVM is a binary classification algorithm that uses kernel functions to enable an implicit mapping of the data into a high-dimensional feature space. For separable data shown in Figure 4(a), an optimum margin classifier is carried out to construct a separating hyperplane that maximizes the margin between the hyperplane and the support vectors, which comprise the data points that lie closest to the hyperplane. Note that the incorporation of slack variables
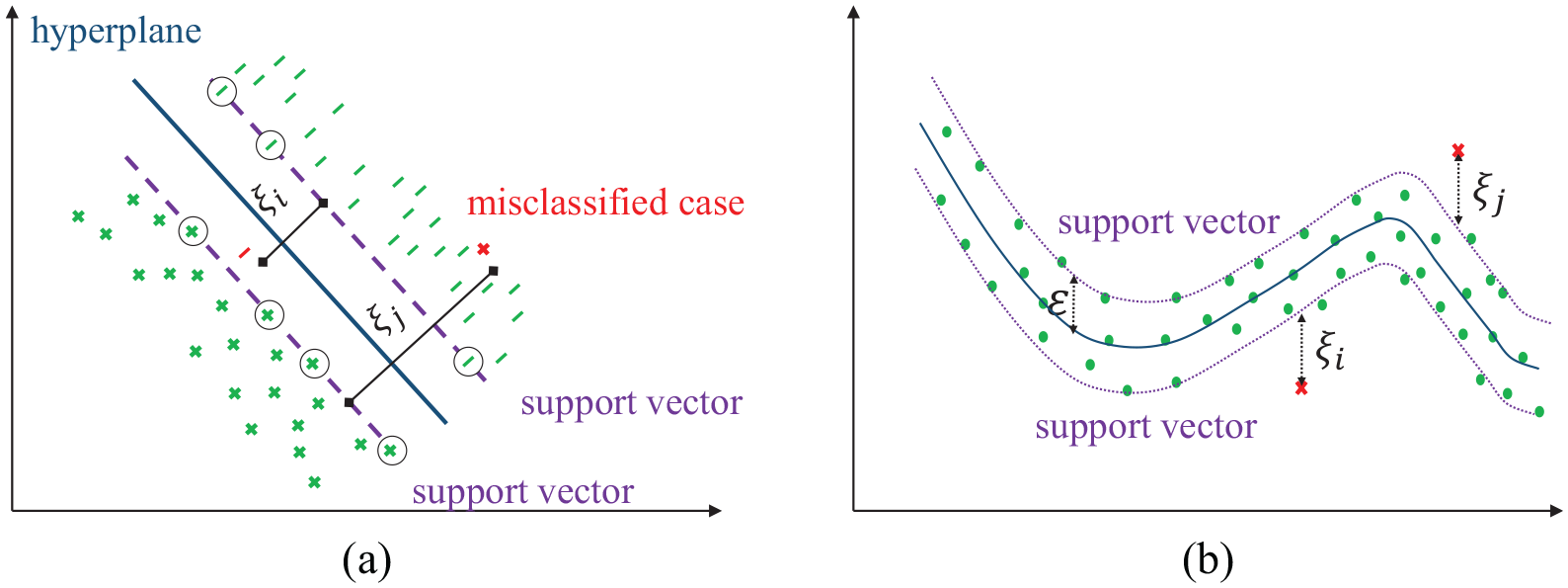
SVM for (a) classification and (b) regression.
SVM can also be used as a regression method, named as support vector regression (SVR) in this study, by maintaining the main features that characterize the algorithm (e.g. the maximal margin concept) and applying a few minor changes. In analogy with SVM, SVR is realized through a loss function that defines an ε-insensitive region around the true responses of the training points (Vapnik, 1998). As shown in Figure 4(b), the errors are considered zero for all points that are inside the ε-insensitive region. Through nonlinear kernel mapping, SVR performs linear regression in the high-dimensional feature space, while slack variables are incorporated to measure the deviation of training samples outside the ε-insensitive zone (Figure 4(b)) (Bishop, 2006; Murphy, 2012).
Response surface model
Originally developed as a statistical method that explores the relationship of explanatory variables of a system and its responses (Box and Hunter, 1957), RSM has been commonly applied in various areas because of its simplicity, transparency, and transferability features. RSM estimates the responses using a series of basis functions. While high-order polynomials can be used as the basis functions for an RSM, first- and second-order polynomials are preferable in most of the cases. Note that the prediction error of an RSM is assumed to hold a normal distribution with mean zero and a variance value.
Two types of statistical methods can be used to improve an RSM. First, feature selection techniques can be applied to identify the most influential variables because not all of them may act as good predictors. For instance, stepwise algorithms determine the best fitting subset of the predictor variables by sequentially adding and removing terms from the proposed RSM based on a given statistical criterion, such as F-statistics or goodness of fit (Rawlings et al., 1998). Second, regularization techniques can be used to add a penalty term in the loss function to control the model size. Relevant methods include the least absolute shrinkage and selection operator (LASSO) algorithm (Tibshirani, 1996) and the elastic net (Zou and Hastie, 2005).
Logistic regression
Although many more complex extensions exist, LR in its basic form measures the relationship between the categorical dependent variable and one or more independent variables through a logistic distribution function. Namely, the sigmoid function is used to estimate the probability that a new data point belongs to one of the two classes. Additional information about LR is available in the literature (Hosmer and Lemeshow, 2000).
Decision tree and random forest
DT, also named as classification and regression tree (CART), is an ML algorithm that recursively partitions the input space and defines a local model in each resulting region of the input space. As shown in Figure 5(a), a simple regression model can be fit to each subspace in case of regression, while a class can be assigned to each subspace in case of classification. A cost function is applied together with a greedy construction procedure to find the optimal partitioning of the data. To overcome the potential overfitting and instability issues associated with a single tree, RF constructs a multitude of DTs at training and outputs the mean predictions of individual trees (Ho, 1995) (Figure 5(b)). The training algorithm generates RFs by bootstrap aggregating or bagging. In order to keep uncorrelated predictors in the final model, RF uses a randomly selected subset of the problem variables in the DTs (Murphy, 2012).
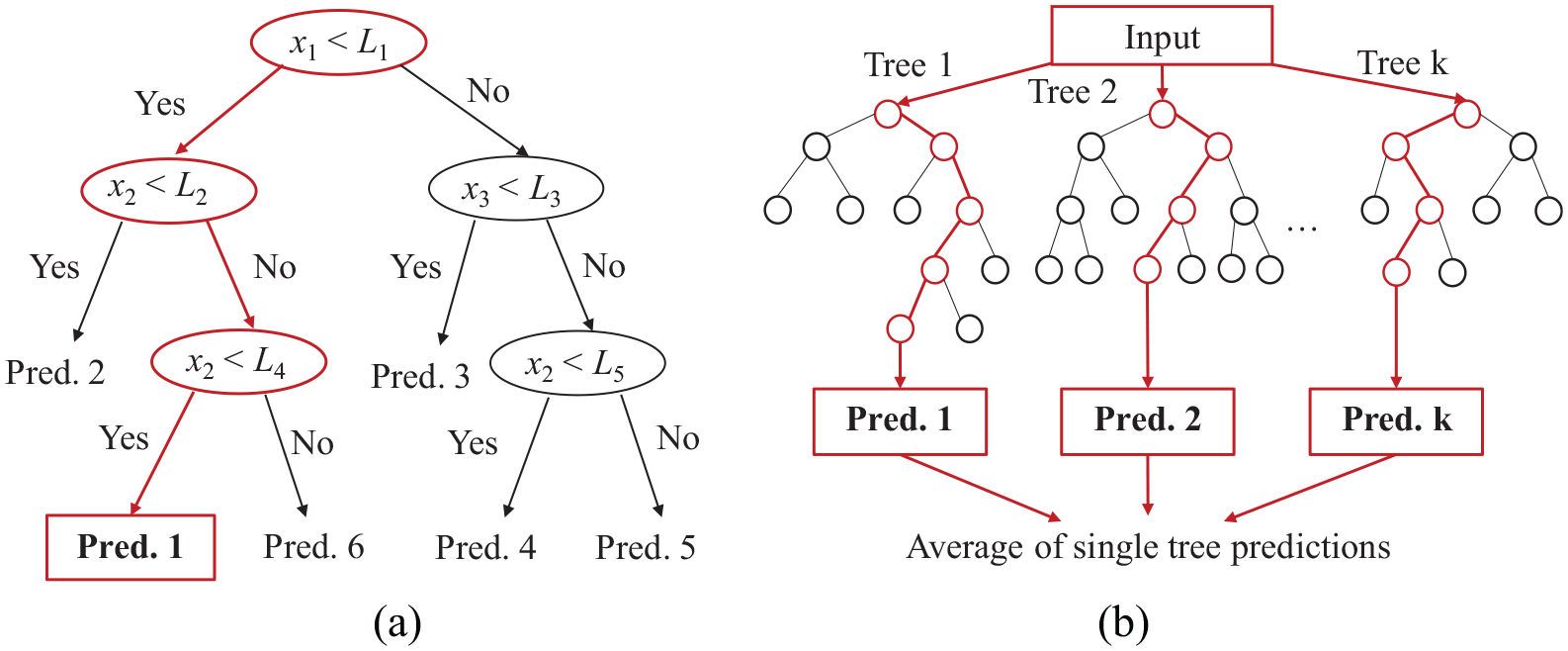
Illustration of (a) binary DT and (b) RF.
Hybrid methods
ML methods, particularly ANNs, can be combined with other soft computing techniques to deal with the complexity and ambiguity in earthquake engineering problems. Such a combination provides a promising integrated system to overcome the inherent limitations of individual techniques. ANNs can be coupled with fuzzy logic algorithms to take advantage of the computational capabilities from both algorithms in a complimentary way. For instance, imprecise data information, such as linguistic statements, can be transformed into numerical data through a fuzzy logic interface for an ANN to train and make decisions (Alvanitopoulos et al., 2010). GAs can interact with an ANN in various steps to improve its performance (Adeli, 2001). Moreover, wavelet transform can analyze the different frequency components of an earthquake signal with varying levels of details, which has emerged as an effective technique that can be embedded in an ANN for system identification and damage detection (Adeli and Jiang, 2006; Hung et al., 2003). Technical background of these soft computing techniques and their combinations with ANNs can be found in relevant studies (Fuller, 1995; Wallen, 2004; Whitley et al., 1990).
Seismic hazard analysis
Ground motion prediction and generation
Ground motion prediction and generation form an essential part in seismic hazard analysis of civil structures. Conventional empirical methods relied on regression analyses to derive attenuation equations for different intensity measures of ground motions as functions of the source, path, and site parameters (Boore and Atkinson, 2008; Boore et al., 2014; Douglas, 2003). A typical ground motion prediction equation (GMPE) for predicting peak ground acceleration (PGA) has the following form:

where FM, FD, and FS represent functions to quantify the influences from magnitude, distance, and site effects, respectively, and ε is the error term. Selection of a proper functional form for FM, FD, and FS is not straightforward as it requires not only appropriate identification and inclusion of significant independent variables but also a reasonable parametric quantification of the relationship between these input variables and the output. In this regard, the recent implementation of ML methods can eliminate the constraints from this predefined mathematical structure, where either parametric or nonparametric models can be derived.
ML studies in predicting GMPEs benefited from the availability of the strong motion database in Taiwan, Turkey (Gülkan and Kalkan, 2002), Iran (Amiri et al., 2010), Europe (Akkar et al., 2014), western United States (i.e. the NGA and NGA-West2 database (Ancheta et al., 2014; Chiou et al., 2008)), and central America for induced earthquakes (Khosravikia et al., 2018). A group of three to five independent parameters was typically identified as significant predictors to predict time-domain intensity measures, such as PGA, peak ground velocity (PGV), and peak ground displacement (PGD), and frequency-domain measures such as pseudo-spectral acceleration (PSA). The identified significant predictors are moment magnitude of the earthquake, source-to-site distance, the average shear-wave velocity of the site, faulting mechanism, and focal depth. The ML tools utilized in GMPEs include the ANN (the top row in Figure 3) (Bakhshi et al., 2014; Derras et al., 2014; Dhanya and Raghukanth, 2018; Güllü and Erçelebi, 2007; Kerh and Ting, 2005; Khosravikia et al., 2019), genetic programming (GP) (Cabalar and Cevik, 2009), multi-expression programming (MEP) (Alavi et al., 2011), SVR (Tezcan and Cheng, 2012; Thomas et al., 2017), GEP (Güllü, 2012; Javan-Emrooz et al., 2018), Lagrange equation discovery (ED) system (Markič and Stankovski, 2013), conic multivariate adaptive regression splines (CMARS) (Yerlikaya-Ozkurt et al., 2014), randomized adaptive neuro-fuzzy inference system (RANFIS) (Thomas et al., 2016), M5’ model tree and CART (Hamze-Ziabari and Bakhshpoori, 2018; Kaveh et al., 2016), DNN (Derakhshani and Foruzan, 2019), and hybrid methods such as the coupling of GP and orthogonal least squares (OLS) (Gandomi et al., 2011), the combination of ANN and simulated annealing (SA) (Alavi and Gandomi, 2011), the coupling of GP and SA (Mohammadnejad et al., 2012), and the coupling of GA, ANN, and regression analysis (RA) (Akhani et al., 2019).
Significant improvements have been achieved in various aspects to enhance the accuracy and the generalization capability of the ML models in GMPEs. For instance, earlier studies have developed almost “perfect” ANN models for the whole data set (with close-to-one R2 values) but failed to carry out necessary procedures to avoid overfitting. Some studies lack a well-established testing step, while others have shown a substantial accuracy mismatch between the training and testing data sets. These issues have been tackled when a comprehensive ground motion database became available, namely, the NGA project strong motion database (Chiou et al., 2008), which contains 3551 recorded motion data from 173 shallow crustal earthquakes, ranging in magnitude from 4.2 to 7.9. The following enhancements have been made using the NGA motion database: (1) a well-constructed learning, validation, and testing structure to avoid overfitting (Alavi et al., 2011; Alavi and Gandomi, 2011); (2) a separate testing procedure on a different motion database to verify the generalization capability of the model (Gandomi et al., 2011; Thomas et al., 2016, 2017); (3) a hybrid framework that couples two or three ML tools to significantly improve the model performance (Akhani et al., 2019; Alavi and Gandomi, 2011; Gandomi et al., 2011; Hamze-Ziabari and Bakhshpoori, 2018; Mohammadnejad et al., 2012; Thomas et al., 2016). Moreover, the newly compiled NGA-West2 strong motion database (Ancheta et al., 2014), consisting of 21,336 recordings from 599 shallow crustal earthquakes, has provided a promising resource for developing more complex soft computing models. To this end, Derakhshani and Foruzan (2019) employed a DNN approach to construct more reliable predictive models for estimating the site PGA, PGV, and PGD based on earthquake magnitude, rake angle, source to site distance, and soil shear-wave velocity. Their DNN models, with correlation coefficients of around 0.9, have shown to be able to outperform other existing models.
However, there exist additional factors that are known, in a physical sense, to affect ground motion estimations. Factors such as stress drop and directivity effects have been neglected in most of the studies mentioned above, resulting in large variance or bias embedded in the derived models. This issue has been partially recognized and addressed by Trugman and Shearer (2018) who applied an RF algorithm to correlate earthquake stress drop with PGA for earthquakes in the San Francisco Bay Area. Their study has verified that ML techniques can produce more precise ground motion estimates if new independent features are included in the predictors.
Other than GMPEs, relatively few studies have focused on using ML algorithms for probabilistic seismic hazard analysis. Alimoradi and Beck (2015) used principal component analysis (Jolliffe, 2002) to extract a set of orthonormal basis vectors that capture the predominant variations in the time histories of earthquake waves. A Gaussian process procedure was subsequently used in their study for regression to generate a probabilistic target hazard spectrum under a given scenario event. The optimal linear combination of the orthonormal basis vectors to match the target spectrum was then identified through a genetic optimization process. Their study avoided the typical questions associated with the selection and scaling of recorded ground motions in the seismic analysis and design of civil structures.
Soil liquefaction potential and liquefaction-induced lateral spread
Historical earthquake events have witnessed significant structural damage caused by soil liquefaction (Bird et al., 2006; Cubrinovski et al., 2014). The application of ML tools in soil liquefaction research is twofold: (1) the use of PR tools to classify the occurrence versus non-occurrence of soil liquefaction (i.e. the assessment of liquefaction potential), and (2) the use of regression procedures to predict the liquefaction-induced lateral spread over a free face or gentle-slope condition.
Based on Cone Penetration Test (CPT) and Standard Penetration Test (SPT) databases, empirical approaches utilized two-dimensional graphs to visually identify the boundary curve that separates liquefaction and non-liquefaction (Boulanger and Idriss, 2014; Idriss and Boulanger, 2006; Moss et al., 2006). To this end, ML techniques outperform these empirical studies in more objectively capturing the nonlinear and multidimensional relationship between the critical inputs and the triggering of soil liquefaction. Significant studies in this area include the implementations of SVM (Goh and Goh, 2007; Pal, 2006), ANN (Goh, 1994, 1996; Hanna et al., 2007; Juang and Chen, 1999; Ramakrishnan et al., 2008; Ülgen and Engin, 2007), a combination of kernel Fisher discriminant analysis (KFDA) with SVM (Hoang and Bui, 2018), a combination of ANN and RSM (Pirhadi et al., 2018), RF (Kohestani and Ardakani, 2015), stochastic gradient boosting (SGB) (Zhou et al., 2019), generalized linear model (GLM) (Zhang et al., 2013), and evolutionary polynomial regression (EPR) (Rezania et al., 2010, 2011).
Prediction of the amount of lateral displacement under soil liquefaction is a complex problem. Liquefaction-induced lateral spreads involve a large number of influential factors, including earthquake magnitude, fault-to-site distance, and local soil profile information such as the slope of the ground and the fine content and particle sizes of liquefiable sediments (Bartlett and Youd, 1995). Pioneered by the studies from Youd and his coauthors (Bartlett and Youd, 1995; Youd et al., 2002), who used multilinear regression (MLR) to develop predictive equations against a case history database, various ML models have been developed to improve the lateral displacement prediction. These models consist of the use of the ANN (Baziar and Ghorbani, 2005; Chiru-Danzer et al., 2001; Wang and Rahman, 1999), a hybrid neuro-fuzzy procedure (García et al., 2008), SVR (Oommen and Baise, 2010), multivariate adaptive regression splines (MARS) (Goh and Zhang, 2014), RF (Liu and Tesfamariam, 2012), GP and EC (Javadi et al., 2006; Rezania et al., 2011), and multilayer perceptrons (MLPs) and the adaptive neuro-fuzzy inference system (ANFIS) (Kaya, 2016).
These ML methods have provided feasible solutions to tackle soil liquefaction problems. However, most methods somewhat possess their inherent challenges for practical applications, including, for instance, the determination of the architecture for ANN and the hyperparameters for SVM. A majority of the studies failed to carry out the cross-validation (CV) process, which makes the overall model performance questionable. Moreover, the abovementioned studies are purely driven by case histories with discrete data points. As a result, it remains unclear whether the derived models will still be valid when interpolating within or extrapolating beyond the range of conditions constrained by the database. In particular, most of the lateral spread regression models have a prediction accuracy within 200%; namely, the predicted displacements vary from 50% to 200% of the observed values. Such a significant level of uncertainty is mainly caused by the imperfect quality of the case history data sets, which contain considerable subjective information that inevitably prevents an explicit mapping between the inputs and the lateral displacement outputs.
System identification and damage detection
The area of system identification and damage detection consists of a wide array of studies that tackle a mixed collection of problems, ranging from classification of component failure modes using laboratory tests, to the detection of region-wide structural damage using satellite imageries. As such, the aforementioned attribute matrix table is utilized herein to disclose the overall literature structure and the interconnections among all relevant studies. Note that the literature in this topic area is selected to be strictly constrained by the keywords of “machine learning” and “earthquake engineering.” Resultantly, many other studies (e.g. Sen et al., 2019; Yang et al., 2017) that develop data-driven models to identify and infer the health conditions of civil structures agnostic to the triggering event are not included in this review.
System identification
The topic area of system identification comprises a broad branch of studies that develop ML-based models to emulate a structural system and predict its downstream seismic response. Table A3 in the Supplemental appendix lists all relevant studies and their associated attribute matrix. As is seen, the existing literature apply various ML methods (1a to 1g) on data sets from both laboratory tests (3a) and numerical simulations (3b) to identify the seismic behavior for both structural components (4a) and individual structural systems (4b). For clarification purpose, these studies are subdivided into two groups based on the trait of data resources.
First, laboratory tests on reinforced concrete (RC) structures have provided one source of data that enable ML methods to identify their failure modes, strength, capacities, and constitutive behaviors. In this regard, a handful of studies focused on predicting failure modes and shear strength for beam-column joints (Jeon et al., 2014; Mangalathu and Jeon, 2018; Mitra et al., 2011; Naderpour and Mirrashid, 2019; Yaseen et al., 2018). For instance, Mitra et al. (2011) used LR to categorize the non-ductile joint shear failure versus the ductile beam yielding failure for interior beam-column joints. Mangalathu and Jeon (2018) applied a group of ML tools, that is, LR, LASSO, discriminant analysis, K-nearest neighbors, naïve Bayes classification, SVM, DT, RF, and extreme learning machine (ELM) for classification, and stepwise, ridge, LASSO, elastic net, and RF for regression, to realize failure mode classification and shear strength prediction together. A similar group of ML tools have been utilized by Mangalathu and Jeon (2019a) to predict the flexural, flexural-shear, and shear failure modes of bridge columns (the second row in Figure 3). Computer vision algorithms that incorporate image segmentation, feature extraction, and nonlinear regression analysis were developed by Lattanzi et al. (2015) to estimate peak drift of bridge columns using lateral-load test data. Recently, a multi-output least-squares support vector machine (MLS-SVMR) algorithm was implemented by Luo and Paal (2018) to construct bilinear force-displacement constitutive relationships for RC columns. A similar study has been conducted by Luo and Paal (2019) to predict the drift capacity of RC columns using a locally weighted least square SVR approach. Also, a group of six ML algorithms has been utilized by Huang and Burton (2019) to classify the in-plane failure modes of RC frame structures with masonry infill panels, and 114 test results from infill frame specimens were investigated. Other than RC structures, Farfani et al. (2015) employed the centrifuge test data of a soil-pile-structure system to train, test, and validate the ANN and SVM models in predicting the dynamic characteristics and seismic response of the pile structure. Data sets from dynamic cyclic tests and shaking table tests have been used to develop ML models for an actively controlled frame (Bani-Hani et al., 1999a), a full-scale nonlinear viscous damper (Yun et al., 2008), and a five-floor structure (Zhang et al., 2008). Hybrid methods that couple ANN with wavelet analysis and fuzzy logic have also been examined to simulate the seismic behavior of building frames (Adeli and Jiang, 2006; Hung et al., 2003).
The second group of studies in system identification deals with the data sets from numerical simulations, where data inputs (structural parameters and ground motions) and outputs (structural responses) enable ML methods to build a relationship mapping that emulates a civil structure. To this end, ML methods, particularly ANNs, have been verified to be effective in replacing finite element modeling of civil structures because of their adaptability to approximate complex structures without being constrained by any specific forms. Starting from Conte et al. (1994) who used ANN to learn and simulate the linear elastic behavior of multi-story buildings, ANNs have been implemented in identifying a variety of structures, including building frames (Joghataie and Farrokh, 2008; Xu et al., 2004), concrete gravity dams (Karimi et al., 2010), a prestressed concrete bridge (Jeng and Mo, 2004), a typical embankment (Tsompanakis et al., 2009), and column splices in low-, medium-, and high-rise steel moment frames (Akbas et al., 2011). Moreover, ANNs have been combined with other soft computing algorithms to minimize the prediction error, increase the training speed, and improve the generalization capability. For instance, a dynamic time-delay fuzzy wavelet ANN model was developed to (1) create a PR model that captures the time series data accurately and efficiently and (2) handle two types of imprecision in the measured data: fuzzy information and measurement uncertainties (Jiang and Adeli, 2005; Jiang et al., 2017). A multi-branch ANN model that separates the structural state variables and seismic inputs was developed to identify a frame structure (Li and Yang, 2007). An intelligent neural system, which combines competitive ANNs and radial basis function ANNs, was developed to enhance accuracy, generality, and speed (Gholizadeh et al., 2009). A functional link ANN that incorporates polynomial functions was also developed by Sahoo and Chakraverty (2018) for improved accuracy and efficiency. Recently, a DL approach, named as the long short-term memory (LSTM) network, was proposed by Zhang et al. (2019b) to model and predict the seismic responses of a nonlinear hysteretic system, a real-world building with field sensing data, and a steel moment resisting frame.
Damage detection
The topic area of damage detection is broadly defined as a group of studies that develop ML models to recognize, classify, and assess seismic damage of civil structures. As shown in Table A4 in the Supplemental appendix, the existing literature in this area possess a large range of attributes in ML method (1a to 1g), data resource (3a to 3c), and analysis scale (4a to 4c). To be consistent, data resource is used as the main trait to subdivide the relevant studies herein.
First, several studies relied on post-earthquake linguistic or photographic records to predict seismic damage. A major challenge in this area lies in the addressment of damage information in linguistic forms. To this end, De Stefano et al. (1999) used ANN and Bayesian classification to predict seismic damage mechanisms of historic churches. Fuzzy logic models have been utilized in a collection of studies that transform physical descriptions of seismic damage into mathematical model parameters (Allali et al., 2018; Alvanitopoulos et al., 2010; Carreño et al., 2010; Demartinos and Dritsos, 2006; Elwood and Corotis, 2015; Silva and Garcia, 2001). Recently, the linguistic damage records from the 2014 South Napa earthquake have been used to develop a DL-based method that classifies the building damage (Mangalathu and Burton, 2019). On the contrary, the damaged RC column images collected after the 2010 Haiti earthquake have been used by German et al. (2012) to develop a procedure that automatically detects spalled regions on the column surface and measures the properties of the spalling. The multi-step procedure measures the area of spalled concrete, the area of the reinforcement, as well as the sizes of exposed reinforcing bars. This damage detection procedure was further incorporated into a comprehensive framework that links the column damage with the residual drift capacity and post-earthquake fragility curves of RC structures (German et al., 2013; Paal et al., 2014). Besides, ML methods have been implemented in dealing with satellite imageries and digital maps to detect and classify building damage (Gong et al., 2016; Peyk-Herfeh and Shahbahrami, 2014). Gao and Mosalam (2018) have also constructed an image database called “Structural ImageNet,” from which two DL technologies such as transfer learning (TL) and visual geometry group (VGGNet) were applied to recognize structural damage caused by earthquakes and other natural hazards.
A large part of the existing literature uses simulated and test data to detect the seismic damage of building structures. In particular, an ANN model is first trained with respect to the reference system in its undamaged state, whereas the response data from the damaged state of the same system are fed into the same model. As a result, the variation in the level of prediction error between the two states can serve as a reference to quantify the structural damage in a nonparametric manner (Huang et al., 2003; Nakamura et al., 1998). Similar studies have considered using innovative metrics such as Bayes factors, natural modes, and coefficients of autoregressive models for damage detection (De Lautour and Omenzetter, 2010; González and Zapico, 2008; Jiang and Adeli, 2007; Jiang and Mahadevan, 2008). Following the same logic, a couple of studies have improved the approach to enable parametric quantification of structural damage (e.g. damage quantified through the change of stiffness values) (Wu et al., 2002; Xu et al., 2005). In a broader context, ANN models have been developed to predict the seismic response for a variety of structures so as to infer their damage conditions. Related studies in this area include (1) quick earthquake damage estimation on ordinary wooden framed houses in Japan (Molas and Yamazaki, 1995); (2) seismic vulnerability assessment of chemical industrial plants with various topologies (Aoki et al., 2002); (3) damage index prediction of RC frames (De Lautour and Omenzetter, 2009; Morfidis and Kostinakis, 2017, 2018); (4) seismic damage evaluation of concrete shear walls (Vafaei et al., 2013) and cantilever structures (Vafaei et al., 2014); and (5) global damage classification of RC slab-column frames by combining ANN with SVM (Kia and Sensoy, 2014). ML has also been utilized by Burton and his coworkers (Burton et al., 2017; Zhang and Burton, 2019; Zhang et al., 2018) to link the seismic damage patterns of buildings to the residual structural capacity indices (i.e. the median capacity ratio between the intact and damaged buildings). Their proposed framework integrates seismic demand analysis, component damage simulation, and residual collapse capacity estimation on both intact and damaged structures. The applied ML algorithms involve CART and RF for safety classification, and LASSO and SVM for capacity index prediction.
Seismic fragility assessment
Performance-based earthquake engineering (PBEE) is a multi-step framework that employs seismic hazard analysis, structural analysis, damage assessment, and risk assessment to provide scientific estimates of the structural performance in terms of metrics such as casualties, repair cost, and downtime (Porter, 2003). In this framework, PSDMs capture the relationships between the structural responses (quantified by engineering demand parameters (EDPs)) and the IMs of earthquake motions. By combining the demand models with capacity limit states, fragility functions are developed to estimate the damage probability of the structure given earthquake IM and other potential predictors of the system. Moreover, the rate of limit state exceedance at a site-specific structure can be calculated by convolving the fragility model with the seismic hazard curve at the site or region. These components in the PBEE have been utilized in numerous studies to investigate the seismic vulnerability and mitigation schemes for individual structures, where earthquake hazard is the primary source of uncertainty (Xie et al., 2019b; Xie and Zhang, 2016, 2018).
Fragility models are one of the critical components in PBEE frameworks. The first class of seismic fragility models provides an estimate of the probability of limit state exceedance in terms of a single variable, the earthquake IM (Cornell et al., 2002), often for structure specific analysis. When considering portfolios of structures with significant variations in the structural parameters, work has considered analysis of archetype structures or groups of representative structures to derive class fragilities. Recent work supporting fragility and risk modeling of regional portfolios of structures considers PSDMs with multiple predictors that reflect the variation across a portfolio and consequently multidimensional fragility models (Ebad Sichani et al., 2018; Jeon et al., 2019; Kameshwar and Padgett, 2014; Mangalathu et al., 2018a; Xie et al., 2019a; Zhang et al., 2019a). Namely, the demand and fragility models can be tailored to structures across a region since they are dependent on not only earthquake IMs but also other significant uncertain parameters such as material, geometric, and aging parameters of the structure. As shown in the third row of Figure 3, procedures to develop multi-predictor PSDMs and multidimensional fragility models include (1) design an experiment that captures the variations of all uncertain parameters; (2) generate a group of motion-structure samples for seismic demand analysis; (3) develop multi-predictor PSDMs using surrogate metamodeling; and (4) apply Monte Carlo simulation or other applicable tools to generate multidimensional fragility models. In this process, ML methods have exhibited significant promises in facilitating the development of both PSDMs and fragility functions.
First, the high-dimensional nonlinear relationship between the predictors and the EDPs of concern can be efficiently quantified through ML methods. Regression-based surrogate metamodeling can be coupled with efficient statistical sampling to develop multi-predictor PSDMs, which can provide approximate estimates of EDP distributions. As a result, time and efforts can be saved since fewer numerical simulations are needed to cover the dispersion ranges for a large number of uncertain parameters. In this regard, multi-predictor PSDMs have been prevalently derived using RSMs, including the response surface with random block effects (Buratti et al., 2010), dual response surface (Perotti et al., 2013), and RSM with polynomial basis functions (De Felice and Giannini, 2010; De Grandis et al., 2009; Liel et al., 2009; Pan et al., 2007; Park and Towashiraporn, 2014; Rajeev and Tesfamariam, 2012; Ravi Kiran et al., 2019; Ricci et al., 2013; Saha et al., 2016; Seo et al., 2012; Seo and Linzell, 2010, 2012, 2013; Seo and Park, 2017; Verderame et al., 2014). Stepwise regression and other regularization algorithms have been used along with RSMs to identify the most informative predictors for developing PSDMs. For instance, Ebad Sichani et al. (2018) employed a stepwise RSM to establish a two-layer PSDM of concrete dry cask structures that are vulnerable to sliding, wobbling, and rocking in seismic events. Xie and DesRoches (2019) tested stepwise and LASSO regression models for probabilistic seismic demand analysis of California highway bridges. Other than RSMs, multi-predictor PSDMs have been developed using ANN (Calabrese and Lai, 2013; Lagaros et al., 2009; Lagaros and Fragiadakis, 2007; Liu and Zhang, 2018; Mitropoulou and Papadrakakis, 2011; Pang et al., 2014; Wang et al., 2018), bootstrapped ANN (Ferrario et al., 2017), SVM (Ghosh et al., 2018; Hariri-Ardebili and Pourkamali-Anaraki, 2018; Huang et al., 2017; Mahmoudi and Chouinard, 2016), kriging metamodeling (Gidaris et al., 2015), GLM (Xie et al., 2019a), MARS (Kameshwar and Padgett, 2014), K-nearest neighbor (Hariri-Ardebili and Pourkamali-Anaraki, 2018), naïve Bayes classifier (Hariri-Ardebili and Pourkamali-Anaraki, 2018), high-dimensional model representation (Sahu et al., 2019), and RF (Mangalathu and Jeon, 2019b).
Once the PSDMs are obtained, Monte Carlo simulations can be used to convolve the PSDMs with the capacity models to develop multidimensional fragility functions. Such fragility models typically have no explicit mathematical expression and cannot be easily reproduced. To address this issue, researchers have used an alternative approach to compare the demand versus capacity and generate binary survival-failure samples, from which additional models are trained (often adopting the LR model) to develop a parameterized fragility model. Relevant studies in this area have developed LR-based fragility models for highway bridges (Dukes et al., 2018; Ghosh et al., 2013, 2014; Ghosh and Sood, 2016; Jeon et al., 2019; Kameshwar and Padgett, 2014, 2018; Mangalathu et al., 2018a, 2018b), single-degree-of-freedom structures on liquefiable sand deposit (Koutsourelakis, 2010), rigid blocks installed with safety devices (Contento et al., 2017), and RC shear walls (Yazdi et al., 2016). In particular, the LR-based fragility models feature logistic expressions that explicitly quantify the influences of the earthquake IM and any other significant structure parameters, enabling the fragility analysis across multiple scales.
Research advances can be further pursued on this portfolio of work to leverage the full capability and efficiency of available ML methods. For example, despite that one structure may have multiple EDPs of interest, most of the existing work develops separate PSDM for each EDP. To this end, multivariate PSDMs that incorporate all EDPs in a single model can not only save multiple rounds of model calibration but also capture the correlation among different EDPs in the same structure, resulting in more realistic demand models (Du and Padgett, 2019; Goda and Tesfamariam, 2015; Luco et al., 2005). Also, alternative ML methods should be explored to avoid using too many correlated predictors in one PSDM. Recent studies have shown promise in developing sparse PSDMs that consist of a small subset of uncorrelated predictors for better accuracy and generalization capability (e.g. Mangalathu et al., 2018b). Moreover, parameterized fragility models have been primarily developed through LR, while it remains unclear whether there exist other models that can provide significant advantages over existing LR models.
Structural control for earthquake mitigation
Previous studies have demonstrated the effectiveness of utilizing active control methods and semi-active control devices in attenuating earthquake-induced structural vibrations (Housner et al., 1997). In essence, structural control requires the identification and analysis of various components in the controlled system, including actuator dynamics, nonlinear structures, and real-time measurements. Compared with conventional control methods that are programmed to perform a specific task, the incorporation of ML in the control loop allows the controllers to learn the task, either in a supervised or unsupervised manner (Ghaboussi and Joghataie, 1995). Such adaptive learning mechanism has provided inherent capability to handle nonlinear mapping, incorporate delays, and recover from partial system failure (Wen et al., 1995), all of which make ML-based structural control more effective in mitigating the adverse effects of earthquake hazards.
Active control using ANN
Considerable studies have explored the soundness of engaging ANN in designing active control schemes to alleviate the seismic impacts on buildings. Developed by Ghaboussi and coworkers, the neural-controller (i.e. the actuator controlled by the neural network instead of an ad hoc control algorithm) is trained with the aid of the emulator neural network, which learns the transfer function between the actuator signal and the output of the sensors measuring the response of the structure (Bani-Hani et al., 1999a, 1999b; Bani-Hani and Ghaboussi, 1998; Ghaboussi and Joghataie, 1995; Wen et al., 1995). It is worth mentioning that the emulator not only learns the structural behavior but also incorporates the effects of the actuator dynamics and sampling period. The neural-controller was trained in an iterative process to make sure the controlled outputs are within a specified tolerance when compared with the structural responses from the emulator neural network (Bani-Hani et al., 1999b). As an example shown in the fourth row of Figure 3, the neuro-control training scheme is composed of the following steps: (1) send a random control signal to the actuator when the structure is subjected to the base excitation; (2) collect the structural responses and send them to the control criterion box; (3) simultaneously feed the control signal to the emulator neural network and send the output to the control criterion box; (4) calculate the error between the two outputs and back-propagate it through the emulator neural network and the neuro-controller; and (5) modify the connection weights of the neuro-controller until the control criterion is satisfied (Bani-Hani and Ghaboussi, 1998). After the neural-controller is well trained, it can generate appropriate signals to the actuator based on the feedback signal from the sensors.
The neuro-controller concept was further developed in several studies that enhance the efficiency and robustness of the active control scheme (Brown and Yang, 2001; Khodabandolehlou et al., 2018; Rao and Datta, 2006; Subasri et al., 2014; Yakut and Alli, 2011). Improvements have been made in the following studies: (1) the use of a cost function to train the ANN (Kim et al., 2000); (2) the use of a sensitivity evaluation algorithm to replace the emulator neural network for saving the training time (Kim and Lee, 2001); (3) the development of a counter propagation network (CPN) to realize unsupervised learning (Madan, 2005); (4) the use of lattice forms in the training pattern to save the calculation efforts and accelerate the training process (Kim et al., 2008); (5) the utilization of an extended minimal resource allocation network to accomplish real-time online adaptation of the ANNs (Suresh et al., 2010). Recently, a fuzzy wavelet neuro-emulator model was developed by Jiang and Adeli (2008a) that can predict the nonlinear structural response in future time steps only from the immediate past structural response and actuator dynamics. This model was further combined with the floating point GA in a companion study by the authors (Jiang and Adeli, 2008b), which identified the optimum control forces at any time step.
Semi-active control using ANN
Semi-active control devices have the capability of adapting to the changes in earthquake loading conditions, similar to the fully active systems, yet without requiring access to large power supplies. In this regard, interest in the use of ANN has grown remarkably, particularly for structures that are designed with magnetorheological (MR) dampers. Contributions in relevant studies include (1) an ANN model to represent the nonlinear differential equations and simulate the dynamic behavior of the MR damper (Chang and Roschke, 1998); (2) an inverse optimal ANN model to predict the required voltage given the desired force of the MR damper (Xia, 2003); (3) the use of ANN to replicate the damper’s dynamics and induce the MR damper in controlling the seismic shaking of non-isolated and isolated structures (Bani-Hani and Sheban, 2006; Xu et al., 2003). In a study by Lee et al. (2006), the neuro-controller was trained to minimize a cost function that includes both structural responses and control signals, and a clipped algorithm was employed to actuate the damper and generate the desired control force. This work has been modified to use modal coordinates as the neuro-controller inputs, which facilitated the controller design (Lee et al., 2008). Moreover, a hybrid neuro-fuzzy control strategy for MR dampers was proposed by Xu and Guo (2008), who tackled the time-delay issue using the ANN and reduced the responding time of the control currents through the fuzzy control. Control efficiency and robustness of implementing neuro-controllers for MR dampers were further verified by Bozorgvar and Zahrai (2019) by combining the fuzzy inference system with ANN and GA. Other than the MR damper, the ANN has been utilized in modeling the MR elastomer isolator (Fu et al., 2016) and actuating the variable orifice fluid damper to control the response of a structure isolated by a device named as curved surface slider (Krishnamoorthy et al., 2017).
The existing literature focuses on developing ANN models in active and semi-active control, while more advanced learning algorithms, such as reinforcement learning (Khalatbarisoltani et al., 2019), should be explored to realize robust control in tackling various sources of uncertainties simultaneously, including seismic uncertainties and time delays. Meanwhile, the promise of implementing ML in structural control can be enhanced if other forms of control devices are investigated, such as active tuned mass damper, distributed actuators, and semi-active stiffness dampers (Fisco and Adeli, 2011). Although theoretical studies and experimental campaigns have verified its effectiveness, structural control is facing cost and reliability issues that limit its real-world applications (Casciati et al., 2012). In this regard, ML-based structural control should also provide viable solutions for easier implementation and maintenance of control systems.
Discussions and conclusion
This article reviewed the significance of various ML techniques for earthquake engineering applications. Four topic areas of ML implementations include seismic hazard analysis, system identification and damage detection, seismic fragility assessment, and structural control for earthquake mitigation. Although limited in number of data for some cases, data sets collected from laboratory and field tests, previous earthquake events, and numerical simulations have enabled researchers to practice a collection of advanced ML tools. Technical background of some commonly used ML methods was presented, whereas the adaptation and application of these tools in each of the four topic areas were discussed in detail. The study revealed that ML techniques have the capability to learn and infer complicated interrelations among the contributing parameters, and thus allow tackling diverse problems in earthquake engineering that are challenging, or not possible, to solve using traditional methods. As observed during the review process, the cross field of ML and earthquake engineering is a new, but increasingly dynamic area for high impact research, where a vast breadth and depth of topics can be investigated. For the purpose of further promoting ML applications in earthquake engineering, the potential challenges and associated research needs are discussed herein.
Data quantify and quality
ML typically requires large amounts of high-quality data for learning to be effective. Data availability has become less an issue in the field of GMPE, in which tens of thousands of input motion data sets are available in the newly developed NGA-West2 strong motion database (Ancheta et al., 2014). However, for some areas that require high-fidelity computational analyses or large-scale field tests, high-quality data points are often limited to hundreds or fewer. As is expected, ML in these areas is facing a strong challenge. For instance, numerous existing RC frame buildings and bridges in seismic active regions were constructed prior to the implementation of modern seismic design provisions, leaving the RC columns susceptible to brittle shear failures in these structures. Recently, ML has been utilized to predict the displacement capacity of RC columns, where input data that are available for shear-critical columns are much fewer than those for flexure-critical columns. Consequently, ML models for shear-critical columns do not perform as well as those for flexure failures (Luo and Paal, 2019). Note that such data quantity issues cannot be easily tackled by switching or developing a more advanced ML model (Domingos, 2012). Also, low data quality often leads to inferior ML models in earthquake engineering. As previously mentioned, on a separate problem of lateral spread prediction under soil liquefaction, researchers tended to acknowledge the chaotic response of liquefying soil masses to earthquakes, and most of the ML models indicated that the predicted displacements lie between one-half and twice the measured counterparts (Goh and Zhang, 2014). Although this degree of accuracy is deemed to be comparable to other geotechnical predictions, such as estimated ground settlement from consolidation tests (Youd, 2018), ML would be expected to provide much more accurate predictions should higher quality data points become accessible. To be specific, a crucial aspect that causes the inaccuracies on lateral spread predictions is the subjective information contained in the raw database. As proof, the scattering caused by the vague and subjective information in the data has been smoothed by García et al. (2008) through a fuzzy clustering technique, after which a neural network procedure was applied that substantially improved the model accuracy.
To address this data issue, research efforts are suggested in the following directions. First, more transparent, accessible, and high-quality data are needed to be compiled in a computer-readable form. As more journals in earthquake engineering encourage researchers to make the data associated with their publications available, a widely accepted platform is required to store and share such data using a standard data structure. In ML applications, although significant expertise is required and effort directed at model tuning, training, validation and interpretation, generally, the time spent running ML is much less in comparison with the time to gather data, integrate it, clean it, and pre-process it (Domingos, 2012). In this regard, it is vital that in earthquake engineering, there exists a community-driven cyberinfrastructure embraced by the community that allows researchers to share and analyze data more effectively, integrate diverse data sets, and practice and develop ML tools. One such cyberinfrastructure platform is the DesignSafe (https://www.designsafe-ci.org/) (Rathje et al., 2017) that supports natural hazards engineering research, through which various recently generated data sets have been uploaded and shared (e.g. Brewick et al., 2019; Hutchinson et al., 2019; Kameshwar et al., 2019; Mosalam et al., 2019; Stewart et al., 2016). Also, since experimental laboratory or field derived databases are limited and initiating new large-scale campaigns can be time-consuming and cost-prohibitive, researchers should be encouraged to provide more simulation-based data, especially for those that have high quality, are physics-driven, and are well-validated against existing test results. While other communities of practice embrace sharing models and output from simulations, this culture is still in its infancy in the earthquake engineering community. However, many such high-fidelity models also have great merit in providing training data for ML applications. Moreover, researchers conducting ML in earthquake engineering are expected to increasingly deal with new sources of data generated from other cutting-edge technologies, such as wireless sensing, computer vision, Internet of things (IoT), smart cities, geographic information system (GIS), and quantum computing, and so on. Once earthquakes occur, these technologies can provide new forms of data on a completely different scale. For instance, the IoT for smart cities can use real-time connected sensors to generate a large amount of spatiotemporal data about bridge networks or pipeline systems for the entire region (Salehi and Burgueño, 2018). To this end, more ambitious problems in earthquake engineering can be tackled by integrating ML with these new technologies. Such problems can be high-fidelity seismic performance prediction of a structural component at the granular level or the seismic resilience assessment of inter-connected infrastructure systems on the regional scale.
Implementation and development of ML methods
Given potential rapid data growth due to abovementioned technologies, ML is expected to provide a tremendous opportunity to systematically advance the research and practice in earthquake engineering. However, the next generation of spatiotemporal data, which tend to be large-scale, high-dimensional, nonlinear, non-stationary, and heterogeneous, are expected to challenge the capabilities of existing ML methods often adopting in the earthquake engineering domain. To this end, more advanced ML techniques, such as active learning, reinforcement learning, and deep learning (Andriotis and Papakonstantinou, 2019; Blatman and Sudret, 2010; Cadini et al., 2014; Echard et al., 2011; Kong et al., 2020; Memarzadeh and Pozzi, 2019; Nguyen and Medjaher, 2019; Schöbi et al., 2017), are needed to (1) characterize the higher-order correlation and dependencies within the data, (2) perform efficient and reliable imputation and prediction for decision making, and (3) develop scalable learning models for large-scale and time-dependent problems.
Moreover, there exists an emerging trend for a paradigm shift that requires earthquake engineering researchers to consider how to best balance the use of physics-based approaches, which are transparent, interpretable, and somewhat predictable, with the use of data-driven ML models that are not unique and sometimes hardly interpretable. Distinct from physics-based approaches, ML algorithms learn a data science model using a set of algorithms, rules, and criteria that automatically extract the relationships between input and output variables. Such relationships are entirely data-driven and cannot alone explain the physical cause–effect mechanisms between variables. To be specific, although spurious relationships can be learned for a complex problem that look deceptively accurate on training and test sets, the model may perform much worse outside the available labeled data (Karpatne et al., 2017).
A rational path forward lies in the increasing incorporation of physical knowledge into ML-based earthquake engineering studies. If the ML model fails to deliver a physical understanding of the underlying process, it hardly can be used as a generalizable solution to solve other similar problems. As previously investigated in diverse disciplines (Faghmous and Kumar, 2014; Fischer et al., 2006; Wagner and Rondinelli, 2016), theory-guided ML can be developed through a variety of approaches (Karpatne et al., 2017). Opportunities exist to accelerate work along this path. First, domain experts can take the lead in converting raw data into a new feature space that reflects better the scientific nature of the underlying problem. For example, dimensionally consistent predictors and observables make more scientific sense to form an RSM than the raw data in their original units (Xie et al., 2019a). Second, an ensemble of different ML algorithms, or similar algorithms with different values for their internal parameters, should be examined to create a more robust overall model (Butler et al., 2018). Recent works in earthquake engineering have embraced this trend to use multiple ML algorithms in solving the same problem, where the algorithm with the best performance was identified (Luo and Paal, 2019; Mangalathu and Jeon, 2018; Sichani, 2018; Thomas et al., 2017). Third, physical understanding of a problem can be increasingly used to design and learn ML models. For example, ANN can be trained to solve supervised learning tasks while respecting the physical law described by general nonlinear partial differential equations (Raissi and Karniadakis, 2018).
In summary, despite the growing number of studies every year, the implementation of ML in earthquake engineering is still in its early stage when compared with other disciplines. However, supported by the next generation of diverse data sharing and sensor technologies, ML has a great promise to revolutionize the profession of earthquake engineering. Furthermore, the earthquake engineering community has the opportunity to probe unexplored ML algorithms in various contexts, or inspire new ones driven by our application needs, while opening dialogue on best practices to integrate physics-based and data-driven methods to solve grand challenges in earthquake engineering.
Supplemental Material
ML_review_supplement – Supplemental material for The promise of implementing machine learning in earthquake engineering: A state-of-the-art review
Supplemental material, ML_review_supplement for The promise of implementing machine learning in earthquake engineering: A state-of-the-art review by Yazhou Xie, Majid Ebad Sichani, Jamie E Padgett and Reginald DesRoches in Earthquake Spectra
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.