
Abstract
In this work, several of the most popular and state of the art classification methods are compared as pattern recognition tools for classification of resistance spot welding joints. Instead of using the result of a non-destructive testing technique as input variables, classifiers are trained directly with the relevant welding parameters, i.e. welding current, welding time and the type of electrode (electrode material and treatment). The algorithms are compared in terms of accuracy and area under the receiver operating characteristic curve metrics, using nested cross-validation. Results show that although there is not a dominant classifier for every specificity/sensitivity requirement, support vector machines using radial kernel, boosting and random forest techniques obtain the best performance overall.
Keywords
Introduction
Resistance spot welding (RSW) is a simple and cost effective manufacturing process 1 that is extensively used for joining sheet steel in the automobile industry due to its high speed and adaptability for automation. 2
The number of RSW joints per vehicle is very high (usually varying between 3000 and 7000), 3 and the tendency in the highly competitive automobile industry is to reduce it as much as possible. Thus, the development of decision support tools that can assist in a fast, flexible and efficient procedure to classify RSW joints according to their quality level can be of great interest.4, 5 More specifically, the aim of the present work is to identify, among several options, the method that gives the best results in predicting the quality level of RSW joints directly from welding parameters,6, 7 such as welding time, welding current, electrode material and treatment applied to electrode material. 8 Such a prediction tool could be used to identify optimal values of the welding parameters and, consequently, to reduce the workload and the cost of post-production quality controls significantly.
In this work, classifiers are compared from different perspectives. Initially, a single measure of accuracy (i.e. the classification rate) is calculated for every classifier. However, there are two types of errors that a predictive tool can produce: false positives (type I errors) and false negatives (type II errors). Thus, as pointed out by Bradley, 9 misclassification rate – which confounds both types of errors – is not necessarily the objective function to minimise, but rather misclassification cost, which gives a different weight to the different types of errors. In the automobile industry, a satisfactory RSW joint wrongly classified as deficient will make monetary costs increase, but a deficient joint wrongly classified as acceptable will compromise safety. Consequently, classifiers in this paper have been analysed taking both types of errors into account, using the receiver operating characteristic (ROC) curve together with the area under the curve (AUC) measure. This approach gives a general perspective of the performance of the classifier for the complete range of operational points or decision thresholds taking into account the trade off between the two types of errors. Additional comparisons are also offered for fixed values of specificity and sensitivity. The analysis is completed using statistical tests [analysis of variance (ANOVA), Duncan's new multiple range test and Waller–Duncan's] to compute the significance of the results.
Experimental
Materials and equipment
The material welded by the RSW process is sheet steel, whose chemical composition is shown in Table 1. The thickness of the sheet steel is 1 mm.
Chemical composition of sheet steel/wt-%
The steel sheets are welded in a single phase alternating current 50 Hz equipment using water cooled truncated cone electrodes with 5 mm face diameter.
Welding conditions
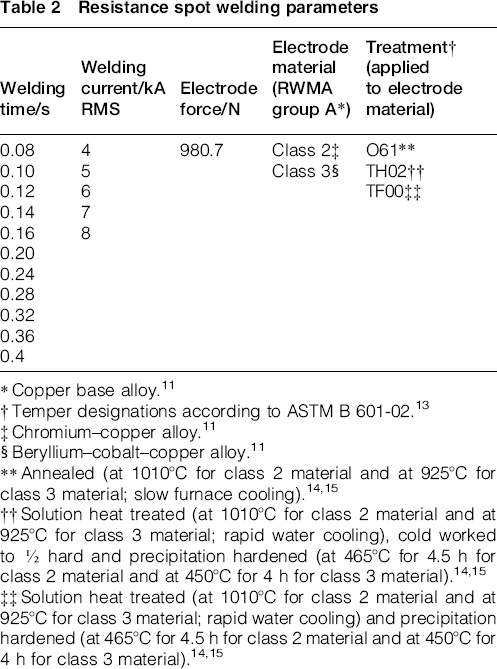
A total of 330 joints are obtained by the RSW process. Among the different RSW parameters,5, 10 welding time, welding current, electrode force, electrode material and treatment applied to electrode material were considered. The values recommend by McCauley et al. 11 are taken as reference for the first three parameters (see Table), electrode force is kept constant for all RSW joints, while welding time and welding current take different values avoiding disturbances such as expulsion.5, 12 The different electrode materials and treatments are also shown in Table 2.
Resistance spot welding parameters
Copper base alloy. 11
Temper designations according to ASTM B 601-02. 13
Chromium–copper alloy. 11
Beryllium–cobalt–copper alloy. 11
Annealed (at 1010°C for class 2 material and at 925°C for class 3 material; slow furnace cooling).14, 15
Out of the five RSW parameters that are controlled, the electrode force is not regarded as a predictive parameter because its value is kept constant for all RSW joints. Hence, each of the considered classifiers predicts the quality level of RSW joints from four RSW parameters: (i) welding time, (ii) welding current, (iii) electrode material and (iv) treatment applied to electrode material.
Quality levels
The training of the predictive tools employs the 330 joints obtained by RSW process. For each of the RSW joints, the values of the four predictive parameters, which are shown in Table 2, and the quality level, assigned to the RSW joint by a human operator, are used. The quality level may be (i) ‘acceptable’ or (ii) ‘unacceptable’.
The quality level is assessed by ultrasonic testing, except for the cases in which electrode sheet sticking occurs (in 40 out of the 330 total RSW joints); in these cases, the RSW joints are directly considered as ‘unacceptable’ (Fig. 1).
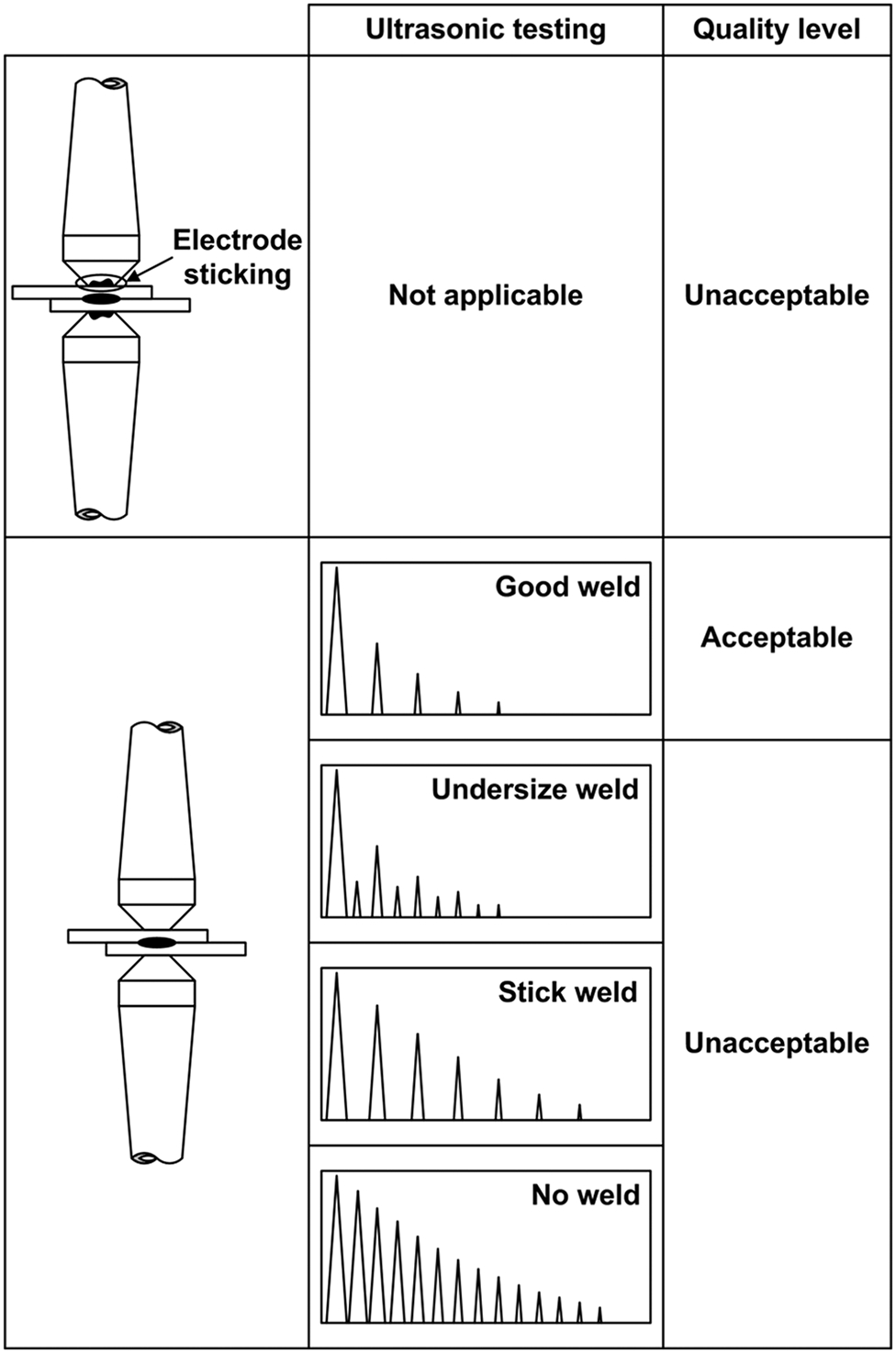
Assessment of quality level of RSW joints by human operator
Since the weld nugget size is the most important parameter among those that determine the mechanical behaviour of the RSW joint,16, 17 the quality level assessed by ultrasonic testing must be determined by the size of the weld nugget. 18 The nugget is formed from the solidification of the molten metal and has a cast microstructure with coarse and columnar grains.4, 19
The human operator uses the ultrasonic testing to classify the 330 RSW joints into four categories (Fig. 1) according to the effect of the weld nugget on the ultrasonic beam4, 19: (i) good weld (acceptable quality level): 123/330; (ii) undersize weld (unacceptable quality level): 86/330; (iii) stick weld (unacceptable quality level): 13/330; (iv) no weld (unacceptable quality level): 68/330.
Computational experiments
When a classifier is trained with a given data set, it often overfits the data, especially when using highly flexible models. This means that the classifier learns peculiarities of the training dataset, which are not useful (and may even be detrimental) to predict in a general setting (i.e. when applied to another data set).
A sophisticated family of strategies to conduct model assessment (the evaluation of a model's performance) and model selection (selecting the model with the appropriate balance between flexibility and generalisation ability) is cross-validation (CV). The k fold CV option involves randomly partitioning the original data set into k subsets of approximately equal size, called folds, and use k − 1 of these subsets as training set and the remaining subset as independent test set. This process is then rotated k times, and the results are averaged over the rounds.20, 21 This approach is useful because it allows estimating the test error of the classifiers, computing additional measures about the dispersion of the performance and reducing the influence of a particular training/test division in the results. In practice, values of k = 5 and k = 10 have been shown to provide an adequate bias variance trade off without requiring excessive computational power. 21
It is important to notice that even though CV can be used for model selection and model assessment, some caveats must be considered. 22 Several studies23, 24 have recently warned against using the error obtained in the selection phase as an estimate of the test error of the selected model (i.e. the error that the model will have on new data). Using several parametric configurations of a classifier and computing the error using CV is adequate to select the right parameters to use, but this error might be too optimistic if reported as an estimate of the performance of the selected model. The estimated errors of the different classifiers analysed in this work have been obtained using a CV scheme suggested as an unbiased estimate of the true performance error of the method. This approach is called nested CV,23, 24 although it is also known with other names. 22
Nested CV uses two nested loops: the inner loop is used as model selection in which the parameters are estimated and tested without using all the available data; the outer loop employs the data that have not been used in the inner loop to compute an unbiased estimate of the performance of the model selected in the inner loop. Specifically, the inner loop uses as data the k − 1 folds used as training in the outer loop. These data are in turn used in a k fold analysis for every combination of parameters. For each fold in the outer loop, the model is trained with the combination of parameters with lower error in the inner fold.
In order to compare different classifiers, a performance evaluation metric is required. The most common measure used to assess the performance of a classifier is the percentage of correctly classified data, aka maximum classification rate or accuracy. 25 This metric is the proportion of correctly classified data instances in the test sets. Although informative, accuracy is not always the most appropriate measure for comparing classifiers. Among several problems,9, 25, 26 perhaps the most relevant in the context at hand is the implicit assumption of equal misclassification costs for false positives and false negatives. When this is not appropriate, the objective function should be a misclassification cost, which weighs false positives and false negatives differently.
In this work, unacceptable RSW joints are considered positive cases and acceptable joints are considered negative cases. A true positive is an unacceptable joint predicted by the classifier as unacceptable, a true negative is an acceptable joint predicted as acceptable, a false negative is an unacceptable joint predicted as acceptable and a false positive is an acceptable joint predicted as unacceptable. Thus, a high rate of false negative joints can lead to safety problems, while a high rate of false positives can increase the monetary costs of manufacturing and production unnecessarily.
Misclassification costs are often unknown or difficult to estimate, since they depend on the specific industrial objective and are often subject to change. Consequently, comparison among classifiers taking into account both types of errors is decomposed in two complementary performance measures, i.e. sensitivity (the proportion of positive samples that the classifier has correctly identified, equation (1)) and specificity (the fraction of negatives that the classifier has correctly identified, equation (2)), formally defined as
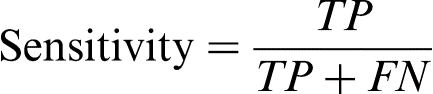
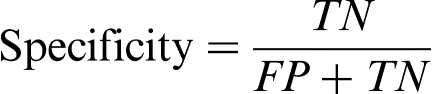
Implicitly or explicitly, most classifiers contain a discrimination threshold (e.g. the minimum probability required to classify a sample as positive) that allows them to glide up and down the sensitivity–specificity trade off. A common approach to assess binary classifiers accounting for this degree of freedom is the ROC curve. 27 The ROC curve of a classifier shows its true positive rate (or sensitivity) against its false positive rate [i.e. the fraction of misclassified negatives, aka fall out, equal to (1 – specificity)] for different threshold values. The range of possible threshold values is chosen to include both the extreme classifier that classifies all data as negatives (false positive rate = 0, but true positive rate = 0) and the extreme classifier that classifies all data as positives (true positive rate = 1, but false positive rate = 1). The information contained in the ROC curve is often reduced to one single number by computing the area under the (ROC) curve (AUC). The ideal classifier would have a true positive rate equal to one and a false positive rate equal to zero, so the larger the AUC, the better the classifier. An advantage of ROC curves is that they are insensitive to changes in class distribution; hence, this metric has no class skew. 27
Classification techniques
In this work, we have compared the performance of seven classifiers, shown in Table 3, together with the R packages used in the computational experiments. A detailed description of the classification techniques and the parameters used can be found in Supplementary Material 1.
Classification algorithms and R packages used

Results and discussion
The predictive power of the classifiers has been compared from different perspectives. Nested 10-fold CV has been used to compare the accuracy of the different methods. Table 4 shows the average maximum classification rate of each classifier with its standard error.
Duncan's multiple range test and Waller–Duncan's multiple range test for accuracy (α: 0.05)*
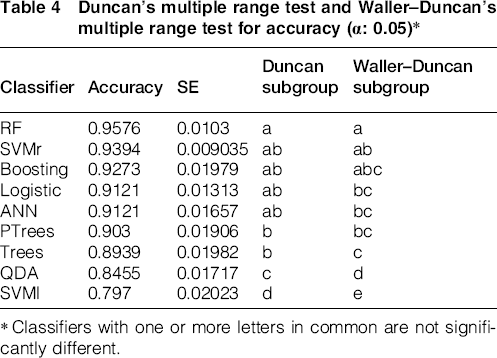
Classifiers with one or more letters in common are not significantly different.
Analysis of variance is used to test the differences in classifier performance. Note that although the accuracy results depicted in Table 4 seem to show differences between classifier performances, these ones could be due to randomness in the training and CV data sets. Table 5 shows the ANOVA results and confirms the statistical difference between classifiers.
Analysis of variance of accuracy classifier performance
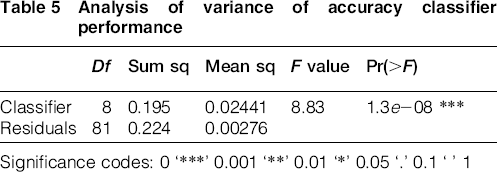
Significance codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
In order to figure out which classifiers are significantly different from each other, Duncan's multiple range test, 35 popular in machine learning, 9 is applied. Apart from using a popular stepwise test such as Duncan's multiple range, we have complemented the comparison using a test that follows a different approach (Bayesian) to determine the significance of the differences: the Waller–Duncan k ratio test. 36 This method has good properties from both the Bayesian and frequentist points of view. 37 Table 4 shows the classifier performance accuracy sorted in descending order, and grouped into subsets in which performance differences are not significant. Results obtained using Waller–Duncan k ratio test show that the accuracy obtained in previous research using ANN8, 19 is outperformed by random forests. However, results from Duncan's multiple range test are not discriminating enough, and the most significant conclusion is that support vector machines using linear kernels exhibit the worst performance. Clearer differences among classifiers are found using AUC performance (Table 8).
As previously discussed, accuracy is not an appropriate performance measure when the cost of a prediction failure – false negative or false positive – is not equivalent. Consequently, the analysis has been complemented comparing the techniques in a wider range of situations using ROC curves and AUC performance. Calculations have been performed with the R package ‘ROCR’, from Sing et al. 38 using again a nested 10-fold CV for each classifier. Figure 2 shows the mean ROC curve obtained averaging the 10 folds. Curves intersect, indicating the absence of a dominant classifier for every situation. For instance, Fig. 3 shows that the sensitivity of a gradient tree boosting classifier for a fixed specificity of 75% is similar to a neural network classifier, but is higher when the specificity is fixed to 90% (numeric results can be found in Table 6).
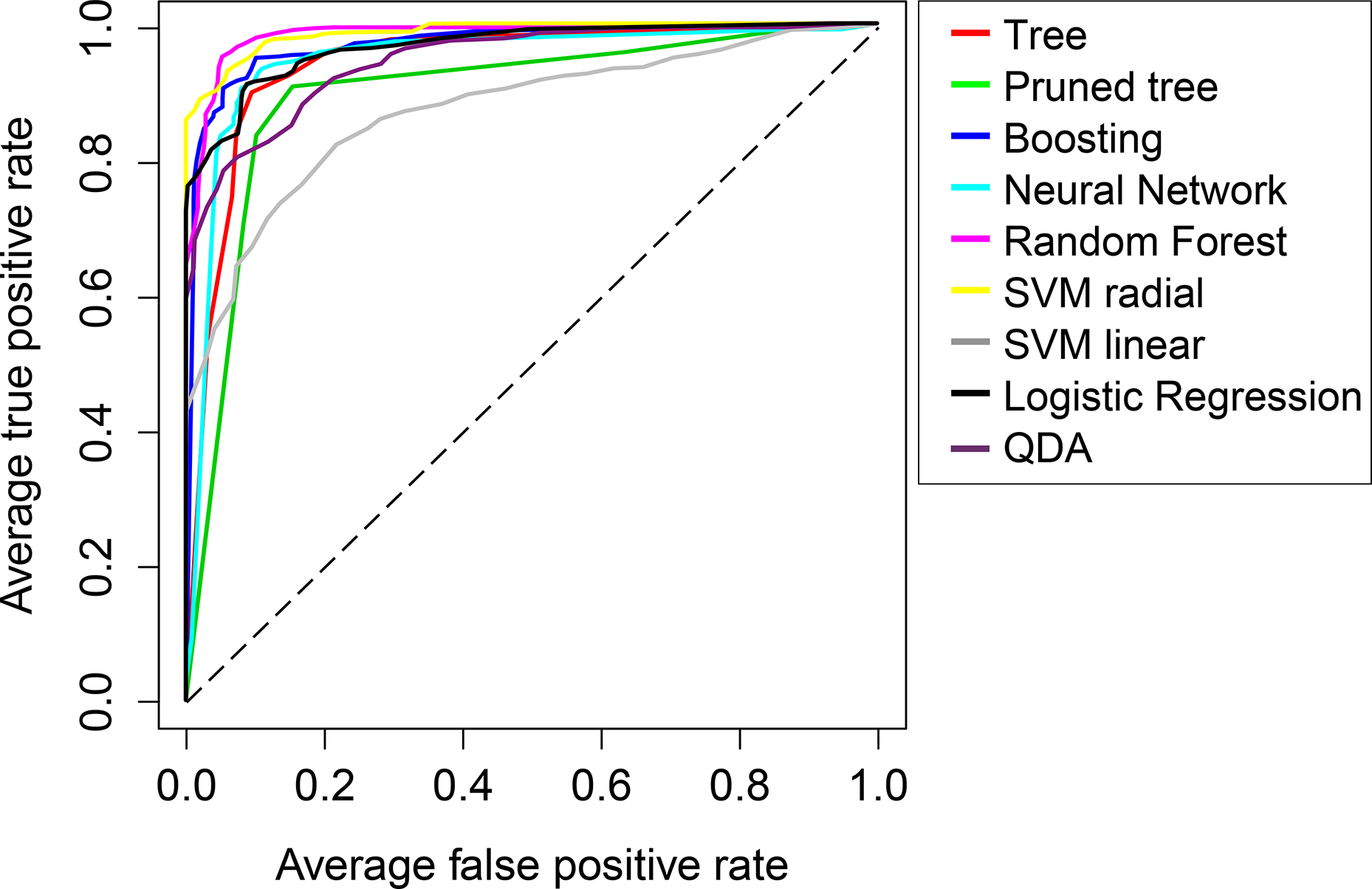
Receiver operating characteristic curve for each tested classifier; dotted diagonal represents random guessing
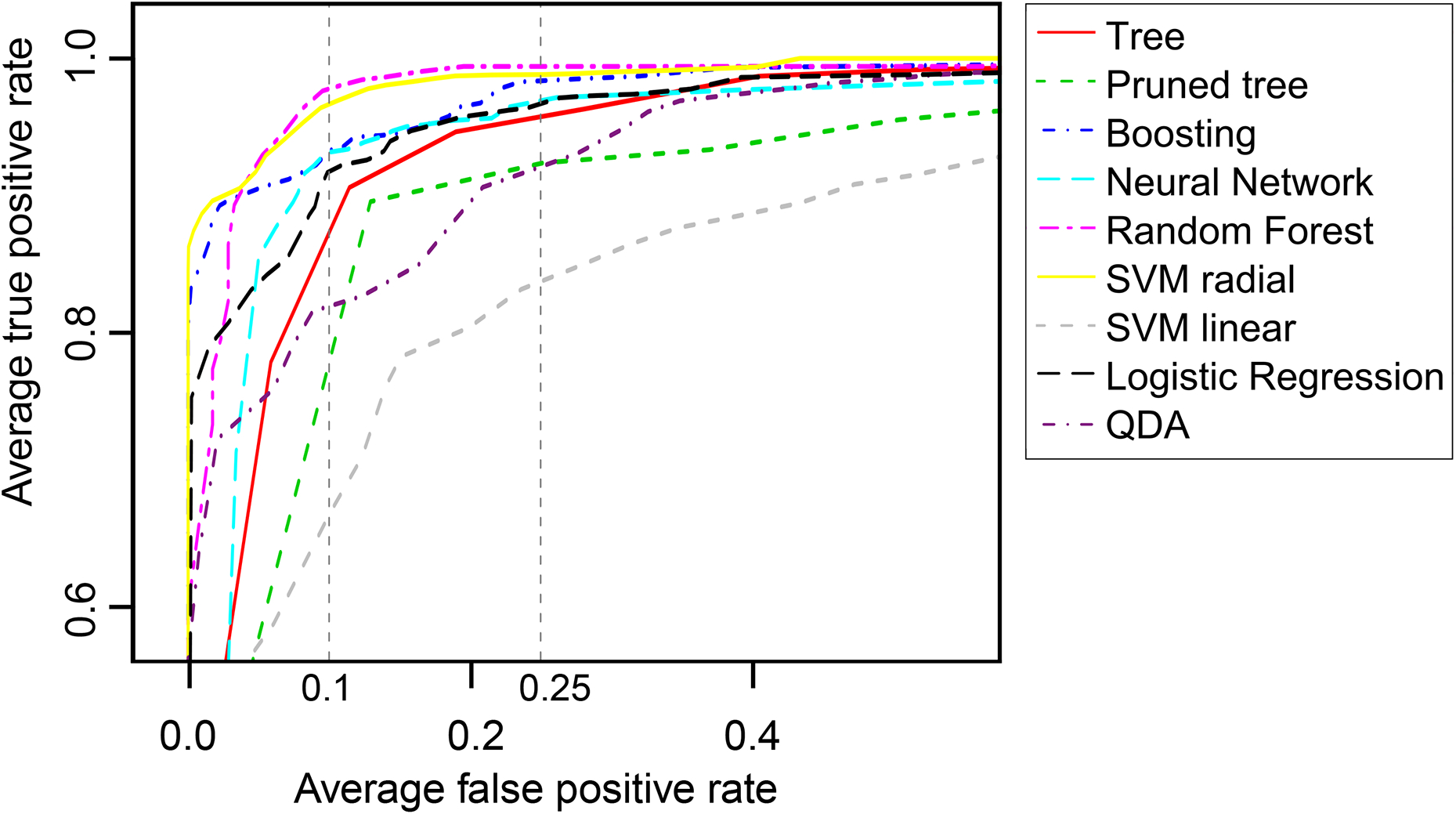
Enlargement of plot in Fig. 2 to show ROC curve for each tested classifier and sensitivity when specificity of 75% or specificity of 90% is required
Average AUC, standard error and the sensitivity performance of classifiers when level of specificity is fixed to 75 or 90%
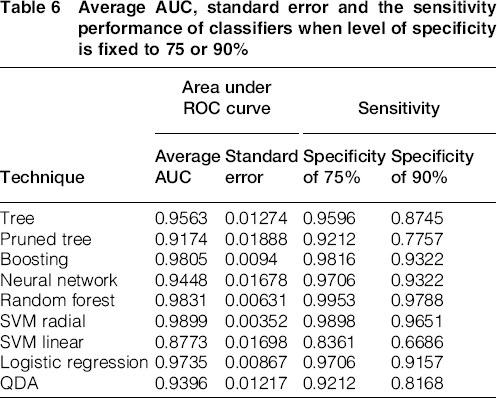
Summarises the average AUC, standard error and the sensitivity performance of the classifiers when a level of specificity is fixed.
Again, results of classifiers using AUC performance are different. An ANOVA has been conducted to test differences in performance (Table 7). Differences are again significant.
Analysis of variance of AUC classifier performance
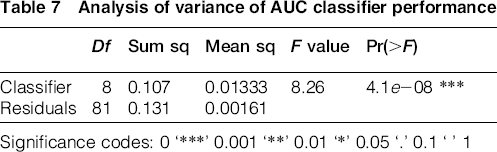
Significance codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Support vector machines using radial kernel, random forests and boosting obtain again the best overall results (Table 8). Waller–Duncan k ratio test shows that the differences with ANN or QDA are statistically significant; however, the differences obtained with logistic regression or trees are not enough to be considered significant with any of the used tests.
Duncan's multiple range test and Waller–Duncan's multiple range test for AUC (α: 0.05)*
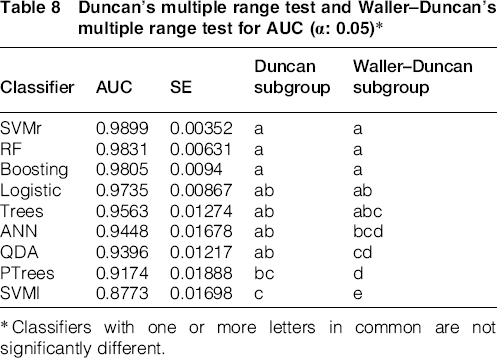
Classifiers with one or more letters in common are not significantly different.
In order to better interpret the effect of the different welding variables in the quality of the RSW joints, the different decision boundaries proposed by the best classifiers – boosting, random forests and SVM radial – are compared in Fig. 4. An analysis quantifying the relative effect of each one of the variables considered for classification can be found in Supplementary Material 2, and a multiclass analysis estimating the types of errors depending on the region can be found in Supplementary Material 3.
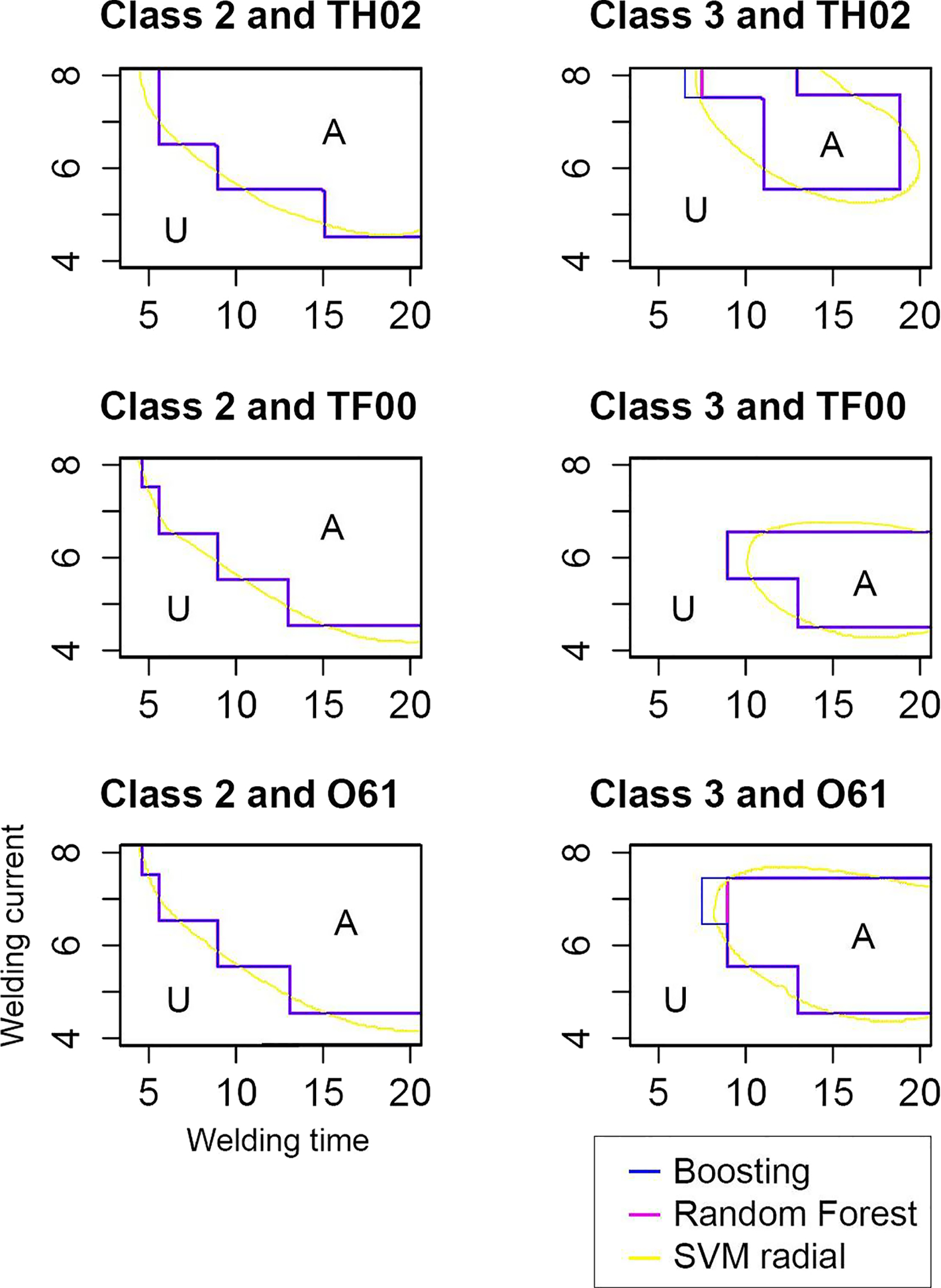
Decision boundaries computed by boosting, random forest and SVM radial algorithms. “A” represents acceptable region, and “U” represents unacceptable region. Welding current, welding time and electrode effects are considered
Class 2 electrode is less sensitive to treatment effects and offers better results than class 3 electrode since it has higher thermal and electrical conductivities. 11 On the other hand, class 3 electrode offers better mechanical properties 11 that prevent the electrode tip deformation (associated with the increase in the electrode contact face and the consequent current density decrease), which occurs after a prolonged and continuous use. Nevertheless, this better behaviour of class 3 is not shown in results because, in this work, the electrodes are subject to less demanding conditions than those used in automotive industry when high productivity is sought.
In RSW processes, electrodes must have a good combination of (i) sufficiently high thermal and electrical conductivities (to prevent electrode sheet sticking) and (ii) adequate strength (to avoid deformation at high pressures and temperatures). 11 TF00 temper can achieve this good combination of physical and mechanical properties because the formation and growth of the strengthening precipitates also reduce the contents of solute atom in matrix, and, hence, the electrical conductivity increases.39, 40 This effect is accentuated in TH02 temper where the cold work before precipitation hardening gives rise to dislocations that provide additional nucleation sites at which heterogeneous nucleation can occur. The consequent increase in the density of precipitates for a given time of aging41, 42 not only enhances the strengthening but also increases the electrical conductivity. O61 temper, although leads to low mechanical properties, offers good results because, in the present work, the electrodes are not subject to demanding conditions that may cause the electrode tip deformation and the consequent current density decrease.
Conclusions
In this work some of the most relevant and popular pattern recognition techniques have been compared for classification of RSW joints using the welding parameters as inputs. The major conclusions are the following.
The analysis confirms that knowing the welding time, the welding current and the type of electrode (electrode material and treatment) is sufficient to obtain classification rates almost comparable with those obtained using non-destructive testing. Additional causes of disturbance can appear during and after the welding process (e.g. electrode degradation, expulsion, current shunting, greasy surface…) but the use of a direct controlling process can reduce significantly the workload of a subsequent quality control. The proposed methodology could be used to implement an anomaly detection algorithm that can warn in real time about potentially detrimental drifts in the welding process. Thus, problematic welding parametric regions could be detected before unacceptable RSW joints appear as a consequence of the direct set-up. According to Waller–Duncan k ratio test, random forests significantly improve the classification performance (accuracy) obtained by previous research.
8
These results suggest their use as effective decision support tools to assist directly in quality control of the RSW process, reducing post-welding testing. The differences among random forests, support vector machines using radial kernel and boosting are not found significant. Results show that for this problem there is not a dominant classifier for every possible pair specificity/sensitivity. An algorithm can perform better than others depending on the industrial context that determines the different cost of a prediction error. Notwithstanding, in an aggregated way, the analysis of the AUC performance measure shows that support vector machines using radial kernel, boosting, random forest and logistic regression using cubic terms or even decision trees are better candidates.
Acknowledgements
The authors would like to thank Dr L. R. Izquierdo for some advice and comments on this paper. The authors acknowledge support from the Spanish MICINN Project CSD2010-00034 (SimulPast CONSOLIDER-INGENIO 2010) and by the Junta de Castilla y León GREX251-2009.