
Abstract
The slow pace of new/improved materials development and deployment has been identified as the main bottleneck in the innovation cycles of most emerging technologies. Much of the continuing discussion in the materials development community is therefore focused on the creation of novel materials innovation ecosystems designed to dramatically accelerate materials development efforts, while lowering the overall cost involved. In this paper, it is argued that the recent advances in data science can be leveraged suitably to address this challenge by effectively mediating between the seemingly disparate, inherently uncertain, multiscale and multimodal measurements and computations involved in the current materials’ development efforts. Proper utilisation of modern data science in the materials’ development efforts can lead to a new generation of data-driven decision support tools for guiding effort investment (for both measurements and computations) at various stages of the materials development. It should also be recognised that the success of such ecosystems is predicated on the creation and utilisation of integration platforms for promoting intimate, synchronous collaborations between cross-disciplinary and distributed team members (i.e. cyberinfrastructure). Indeed, data sciences and cyberinfrastructure form the two main pillars of the emerging new discipline broadly referred to as materials informatics (MI). This paper provides a summary of current capabilities in this emerging new field as they relate to the accelerated development of advanced hierarchical materials (the internal structure plays a dominant role in controlling overall properties/performance in these materials) and identifies specific directions of research that offer the most promising avenues.
Materials, Manufacturing, and Informatics
Materials with enhanced performance characteristics have served as critical enablers for the successful development of advanced technologies throughout human history and have contributed immensely to the prosperity and wellbeing of various nations. A majority of the materials employed in advanced technologies exhibit hierarchical internal structures with rich details at multiple length and/or structure scales (spanning from atomic to macroscale). Collectively, these features of the material internal structure are here simply referred to as the structure and constitute the central consideration in the development of new/improved hierarchical materials. Indeed, the existence of a causal relationship between the material structure and its properties is the central tenet in the field of materials science and engineering. It should be noted that the word structure is used very broadly in these statements (and in this paper) to include and refer to any of the details of the material internal structure (spanning all relevant length or structure scales involved).
Indeed, the mathematical description of the material internal structure in its entirety, in any selected material system, is unimaginably complex and demands very high dimensional representation. For example, most materials being explored for structural applications (e.g. Ti alloys in jet engines and advanced high strength steels, Mg alloys in lightweight automobiles, Al alloys in aerospace frames, and Zr alloys in nuclear industry) exhibit polycrystalline microstructures at the mesoscale. 1–4 As an example, Fig. 1 shows details of the mesoscale structure in such materials. A rigorous representation of the hierarchical structure in such materials should also include details at other relevant length/structure scales (e.g. point defects, dislocations, grain boundaries, phase boundaries). Although the above discussion was framed in the context of a crystalline material, similar considerations exist in most other material classes. For example, the hierarchy in polymer structures 5 includes details of monomers and their spatial arrangements into blocks and branches at the molecular or macromolecular level, micro-fibrils and crystallites at the nanoscale, and spherulites at the microscale. The hierarchy in most biological materials is indeed much richer. For example, the hierarchy in bone structure includes details of collagen molecules and mineral crystals, collagen fibrils, collagen fibre, lamella, osteons and macrostructure (e.g. cancellous or cortical). 6–8 Furthermore, most materials of interest in advanced technologies actually tend to be composites comprising multiple material classes.
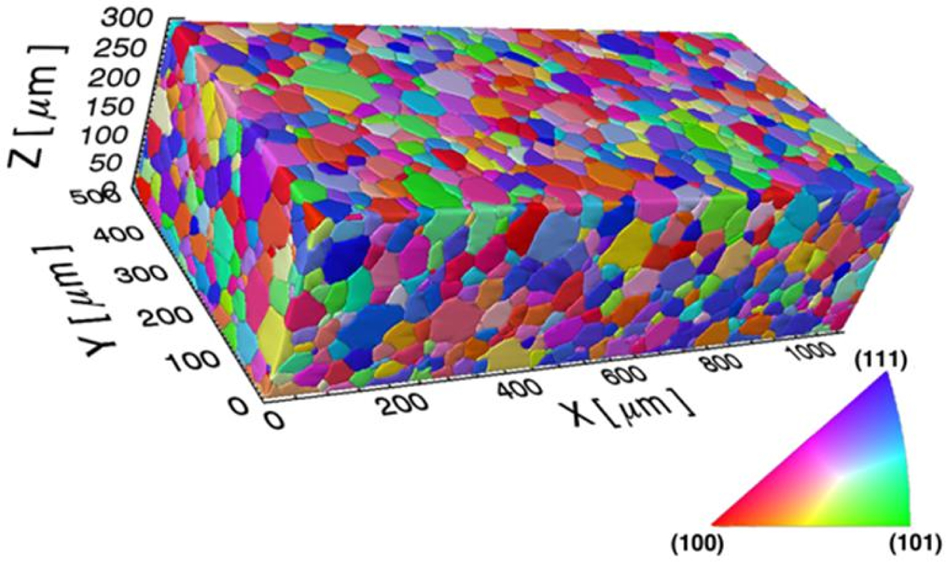
Mesoscale internal structure of beta-stabilised polycrystalline titanium containing 4300 crystals (or grains) taken from Ref. 4. This experimental dataset was generated by a three-dimensional (3-D) reconstruction that entailed the use of serial sectioning, optical microscopy with intermittent electron backscatter diffraction (EBSD), and image segmentation and processing algorithms. The sample size is 1·115×0·516×0·3 mm3 (1670×770×200 voxels). The 3-D crystal lattice orientation in each voxel is included in this experimental dataset. The colour key corresponds to the stereographic projection of the crystallographic orientation parallel to the Z-axis, shown in bottom left
It is emphasised again that the discussion in this paper is exclusively focused on hierarchical materials. In other words, the simplest of these materials exhibits at least two distinct well separated length or structure scales (e.g. the macroscale and the microscale). It should also be noted that the description of the structure in such hierarchical materials implicitly includes a full description of the chemical compositions of all distinct microscale constituents (called local states) present in the material system, in addition to their relative spatial placement in the internal structure. In other words, the information included in the description of the material structure is orders of magnitude more detailed than the simple overall chemical composition typically used to identify or label a material system.
Based on the above description, it should be clear that a vast number of tiered spatial distributions have to be quantified to faithfully represent the complex hierarchical structure of advanced material systems. It is obvious that such an effort would result in an extremely large and unwieldy representation. Fortunately, the field of materials science and engineering has already empirically discovered that only certain salient features of the material structure dominate the macroscale performance characteristics of interest for any selected application. Therefore, the main challenge in the development of materials with enhanced properties reduces to identifying and tracking the salient structure features that are important to a specific engineering or technology application. In other words, the core knowledge needed to guide the materials’ development efforts can be sought and expressed as reduced-order process–structure–property (PSP) linkages that capture the roles of different unit manufacturing (or processing) steps on the salient structure features that control the property combinations (or performance characteristics) of interest. It is important to recognise that these linkages represent reduced-order models as they utilise reduced-order representations of the material structure. Historically, such efforts have been largely guided by the scientific approach that entails formulating a fundamental hypothesis and then validating it with carefully designed experiments conducted in highly controlled environments. Such science-driven approaches for establishing PSP linkages have been expensive and slow, 9–11 because their focus has been to isolate and study each physical mechanism (i.e. cause) and its associated effect in a highly systematic manner.
From a data science perspective, one can formalise the discussion above in terms of the fundamental data transformations involved, as summarised in Fig. 2. Raw data related to materials phenomena of interest is usually generated by some combination of experiments, models, and simulations. Recent years have witnessed an explosion in the ability of materials experts to generate data from novel experiments and simulations. For example, the 3-D experimental dataset shown in Fig. 1 can now be generated using mostly automated protocols. 12,13 In spite of this automation, this technique incurs a substantial amount of time (of the order of several days). An exciting development in this field is the use of a femto-second laser for fast serial sectioning of the sample, 14 as opposed to the conventional mechanical approaches used in the earlier studies. This new technique has the potential to dramatically reduce the time required to obtain a 3-D structure dataset. It has also been demonstrated that a focused ion beam attached to a scanning electron microscope can be used for serial sectioning the samples and reconstructing a 3-D material structure dataset (e.g. Refs. 15 and 16). However, this technique is ideal only for studies of very small volumes of material (with length scales of the order of a few micrometres). While the approaches mentioned earlier are all destructive (they ablate the material to expose new surfaces of the sample), there are also a number of non-destructive techniques that rely on the use of X-rays. When the X-ray techniques are combined with computed tomography techniques, it is possible to produce reconstructions of a broad range of 3-D material datasets including porous structures (e.g. Refs. 17–19), mapping of defects (e.g. Refs. 20–22) and polycrystal microstructures (e.g. Refs. 23 and 24). In fact, it is now possible to obtain 4-D (three spatial dimensions and time) reconstructions using data gathered from high energy X-rays. 25 At the finest spatial resolution, it is also possible to obtain 3-D and 4-D structure datasets at the atomic scales using techniques such as transmission electron microscopy 26 and atom probe microscopy (e.g. Refs. 27 and 28). In parallel, there have also been tremendous advances in the ability to generate simulation datasets from computations at multiple length/structure scales (e.g. Refs. 29–43). The volume of this data (from both experiments and models) can be very large ushering the materials community into the materials big data era.
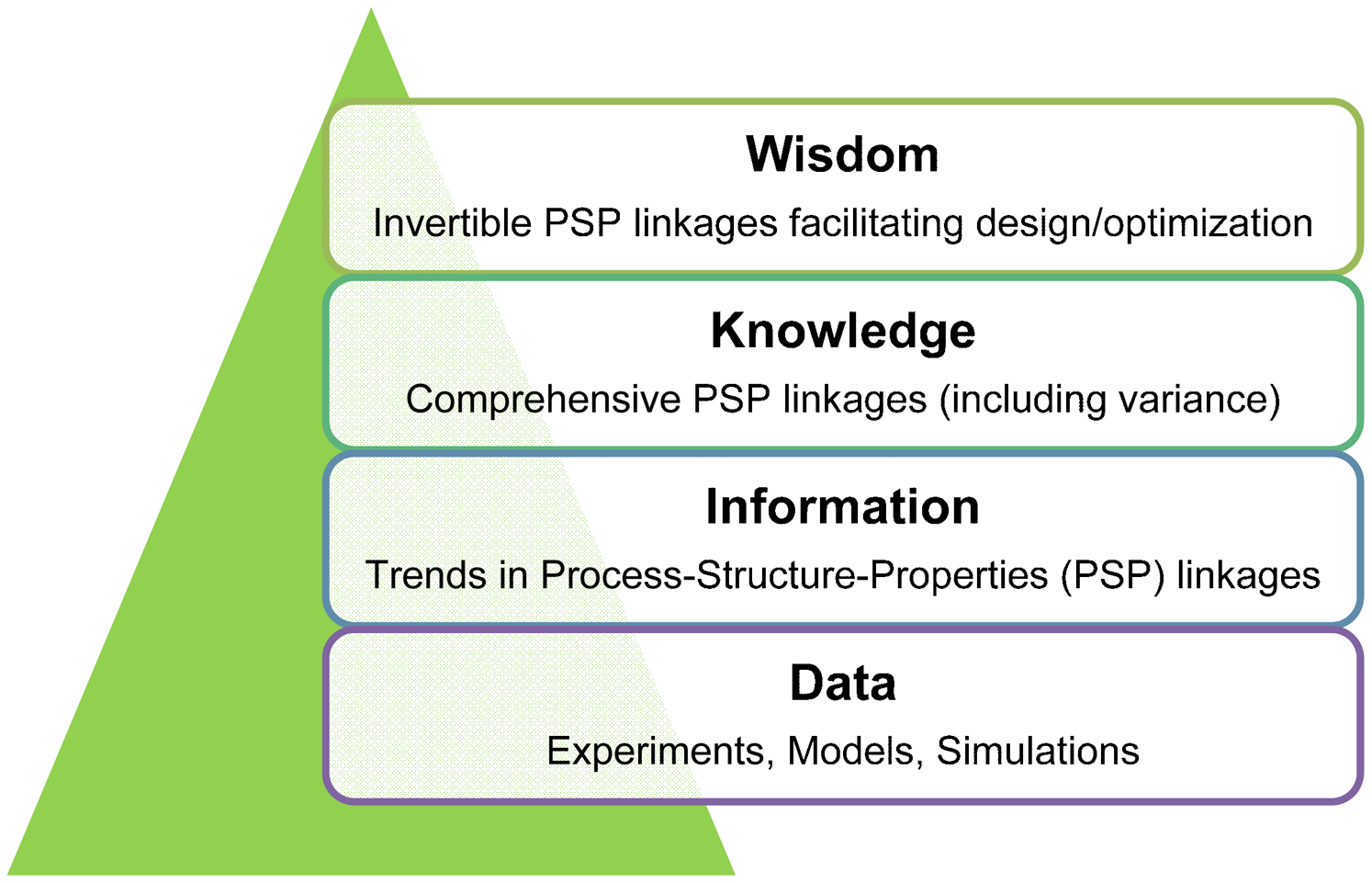
Schematic description of the envisioned transformations for materials data
The main purpose of the structure datasets is that they allow the materials specialists to extract trends on the evolution of selected salient structure features during a given manufacturing route and study how these details affect certain effective properties/performance characteristics of interest for the material. For example, considerable prior effort in the development of structural metals has been spent on correlating the average grain size in the final metal product to the various thermo-mechanical deformation histories applied during the manufacture of metal alloys. This is because the average grain size is generally observed to strongly influence the overall mechanical properties of the metal product in service (e.g. Refs. 44–49), although it is not the only factor influencing the final performance. However, this approach of salient structure parameter identification and exploration has provided tremendous new insights (higher value information) to improve the performance of many structural material systems of interest. In the data science formalism, one might characterise these higher value descriptions (identifying specific trends between selected parameters as opposed to comprehensive multivariate linkages) of PSP linkages as information (see Fig. 2). This is mainly because, at this stage, not all the dominant features in the PSP linkages of interest have been identified in a comprehensive manner. At the next higher level, one can aim to extract much more rigorous, reliable, and complete PSP linkages from all the available data; this information could then be characterised as materials knowledge. One of the central goals of the emerging field of materials informatics (MI) is to introduce novel data-driven approaches for mining materials knowledge from the large collections of experimental, modelling and simulation datasets available (and/or being produced) today. Furthermore, the comprehensive PSP linkages available at this stage should allow a rigorous quantification of the inherent uncertainty. At this level of knowledge, the available PSP linkages can be successfully employed in simulating manufacturing processes of interest and predicting performance of the final product. However, the main focus in the data transformations at the knowledge level continues to be in the forward direction (process→structure→properties). At the final stage of data transformation, effort would be focused on establishing invertible PSP linkages that allow customised process and materials design for targeted applications (i.e. address inverse problems). This highest level of the understanding of PSP linkages can then be characterised as wisdom. The primary focus in this paper will be on data analytics needed to extract materials knowledge from the ensembles of materials structure and performance datasets being produced by the materials experts, with an eye towards attaining wisdom in the future.
In order to realise the goals stated above for efficiently transforming materials data into knowledge and wisdom, and dramatically lowering the cost and time involved in materials development efforts, it is imperative to develop novel protocols that fully exploit the large data generation capabilities made possible through the recent advances in multiscale measurements 12–28 and simulations of materials phenomena (e.g. Refs. 34–42). The central challenge is that in spite of the many advances there remain a large number of unknowns or gaps in capturing the underlying physics (at the different length scales). These critical gaps hinder the development of fully predictive PSP linkages for most hierarchical materials of interest to advanced technologies. The only practical way forward for the foreseeable future is to formally treat the hierarchical material as a complex system, 50 which by definition is not yet amenable to predictive models. If one embraces the premise that a certain degree of uncertainty is inevitable in the formulation of the desired PSP linkages for hierarchical material systems, the focus could then be shifted to managing the uncertainty (i.e. complexity). In other words, the effort could be focused on the design, development, and validation of decision support systems that will leverage the best available understanding (with its uncertainties) and provide objective guidance on future effort investment (e.g. what combination of experiments and simulations are needed to reduce the uncertainty).
Given the high cost of the multiscale measurements, it is also obvious that the desired protocols for establishing materials knowledge and wisdom (see Fig. 2) will have to rely on a limited number of experimental investigations. However, these experiments have to be specifically designed to efficiently cross-feed multiscale structure-sensitive materials models. The central considerations for these new protocols should be:
model maturity
model interoperability
model inversion. Briefly, model maturity quantifies the reliability (or the uncertainty) of the predictions of any given model over a prescribed window on the input ranges.
The focus here is largely on multiscale physics-based models (these are critical for achieving adequate accuracy over sufficiently large windows on the input ranges) for predicting either the structure–property relationships or the manufacturing process–structure evolution relationships. Consequently, protocols are critically needed for robust evaluation of the model maturity over any selected range of initial structures and boundary conditions (defining either the manufacturing process conditions or the in service loading conditions). The main impediments for establishing these protocols are:
lack of a broadly adopted framework for rigorous quantification of the material structure
lack of validated experimental protocols for direct measurement of the various materials’ parameters introduced in the multiscale models and/or the ‘at-scale’, full-field, measurements of response variables predicted by the multiscale models (needed for the critical validation of the models).
Model interoperability ensures that the distinct components of a hierarchical multiscale model chain that typically address specific materials phenomena at selected length/structure scales are able to exchange the high value information with the other components of the model chain seamlessly with manageable (quantifiable) loss of accuracy. 50 For example, in modelling the plastic response of polycrystalline metals, 51 it is not yet clear what information about the dislocation structure needs to be communicated from dislocation dynamics simulations to crystal plasticity simulations. As a simple approach, one might decide to just communicate only the average dislocation density. However, if one is interested in understanding and predicting strain hardening and damage initiation/evolution, it would be necessary to communicate information on the higher moments of the dislocation field (or equivalently higher-order spatial correlations in the dislocation networks) to the crystal plasticity models operating at the next higher length/structure scale. The third key capability listed earlier, model inversion, is necessitated by the need to drive materials development efforts from considerations of performance requirements (i.e. invert the current ‘cause and effect’ approach to a transformative ‘goal-means’ approach articulated by Olson 42,52 ). A major impediment in model inversion arises from the simple fact that most currently used approaches in computational materials modelling have not been designed with invertibility in mind. For example, numerical approaches such as the finite element methods or the finite volume methods have been designed to study effects of imposed loading or boundary conditions on a selected initial microstructure. They are completely ill-equipped for tackling inverse problems such as identifying the set of material structures that are expected to meet or exceed a specified set of property/performance requirements. Model invertibility in most cases needs formulation of simplified, but sufficiently accurate, metamodels (also referred to as surrogate models) that cover the desired space of material structures and loading/processing conditions. In general these approaches demand compact, simple (e.g. algebraic), and sufficiently accurate representations of the PSP linkages 1,42,50,52–54 to be of practical utility in providing critical decision support in the materials development efforts.
The above discussion should make clear the critical need and potential for the utilisation of modern data sciences (including advanced statistics, dimensionality reduction and formulation of metamodels) and cyberinfrastructure (including integration platforms, databases and customised tools for enhancement of collaborations among cross-disciplinary team members) in overcoming the impediments described above. These have been identified as the critical enablers for the emerging materials innovation ecosystems in many national and international strategic initiatives. 9,55–60 In fact, data sciences and cyberinfrastructure have already been successfully employed in a broad range of other application domains. Examples include recommendation systems (e.g. Amazon 61 ), personal informatics (e.g. Ref. 62), drug discovery (e.g. Ref. 63), decision systems (e.g. Ref. 64), and healthcare (e.g. Ref. 65).
Data sciences and cyberinfrastructure are the foundational pillars of the emerging field broadly referred to as Materials Informatics (MI). 66–76 This emerging new field has thus far focused largely on materials discovery through combinatorial chemistry and variations of crystal structures at a single length/structure scale. In this paper, the focus will remain on hierarchical materials, where microstructural features at different length/structure scales play important roles in controlling the macroscale properties/performance characteristics of interest. Consequently, major emphasis is placed on first identifying and then communicating the high value information among the constituent length scales for a hierarchical material system. Furthermore, because the governing physics at different length/structure scales vary dramatically, and because of the highly localised nature of the knowledge and expertise of such phenomena, realisation of the goals articulated earlier is critically dependent on the availability of suitably designed cyberinfrastructure that will facilitate and enhance cross-disciplinary collaborations.
Extensible Framework for Structure Quantification
The lack of an extensible framework for material structure quantification, which is broadly applicable to the wide range of hierarchical materials of interest to emerging advanced technologies, is the central impediment in ushering materials science and engineering into the big data age. Rigorous structure quantification is also foundational to the critically needed advances in development of novel data-driven protocols for model maturation, model interoperability, and model inversion. In spite of the central role structure plays in establishing core materials knowledge expressed as PSP linkages, it has eluded a broadly accepted quantitative definition. For example, although the American society for testing of materials (ASTM) standards are widely adopted by the multiple stakeholders in the manufacturing value chain (including materials producers, product designers and original equipment manufacturers), there is no ASTM standard yet for a comprehensive quantification of the material structure. At best, the current standards only address quantification of very primitive structure measures such as the average grain size 77,78 in relatively simple material systems. Measures such as the average grain size should be considered primitive because it is easy to envision multiple hierarchical material structures that have the same exact values for such primitive measures while exhibiting dramatically different macroscale properties/performance characteristics.
Core knowledge needed for the development of advanced hierarchical materials is best archived, curated and visualised in the higher dimensional space of variables used to represent the material structure. 54,67 This is because structure evolution during processing can be represented as a distinct pathline in the structure space and each point in this space can be associated with a single value of property combinations of interest. 79 Therefore, it would be possible to visualise the salient PSP linkages in a suitably defined low-dimensional projection of the structure space. The central challenge therefore is to define a practically useful structure space. When the structure space is defined using very primitive measures, it would not be able to distinguish between structures that exhibit very distinct performance characteristics. On the other hand, if the structure space is defined to account for every minute detail of the structure (implicitly demanding a high dimensional representation), it would not be amenable to a comprehensive exploration (e.g. for the optimisation of performance characteristics of interest for a selected application). This is precisely where a data-driven approach offers many advantages. In a data-driven approach, the decision on exactly what constitutes the set of important salient features is not taken in a static manner – instead it is taken objectively based on the actual available data. It is continuously refined as more data becomes available. Therefore, the emerging interdisciplinary MI field focuses mainly on computational algorithms and tools designed to extract and curate the embedded materials knowledge in an objective (data-driven) and dynamic manner. This is accomplished using a combination of advanced statistics, applied mathematics and modern cyberinfrastructure.
The above discussion should make clear that an extensible framework for material internal structure quantification is the central starting point in formulating a data-driven approach to hierarchical materials development. Only an extensible framework would permit automated and efficient evaluation of multiple choices one faces in this daunting task. Moreover, only an extensible framework will allow automated documentation of the novel integrated workflows that are yet to be explored and evaluated in pursuit of the grand challenges identified earlier. When such a framework is implemented on a broadly accessible cyberinfrastructure, it will allow identification of the best integrated workflows (integrating experiments and models, materials and manufacturing, etc.) based on the experience accumulated from the broader community. The desired requirements laid out above can be satisfied by seeking a digital signal representation of the material structure
80
as 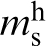
Because of the absence of a natural origin from where one might start indexing the spatial bins, only the relative placement of local states in the material structure contains meaningful information. An extensible framework for rigorous quantification of spatial correlations in the material structure is available in the form of n-point spatial correlations (or n-point statistics).
1,67,81,82,93,94
Although a number of other ad hoc measures of material structure are possible, only the n-point spatial correlations provide the most complete set of measures that are naturally organised by increasing amounts of structure information. For example, the most basic of the n-point statistics are the 1-point statistics and they reflect the probability density associated with finding a specific local state of interest at any randomly selected single point (or voxel) in the material structure. In other words, they essentially capture the information on volume fractions of the various distinct local states present in the material system. The next higher level of structure information is contained in the 2-point statistics, denoted as 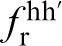
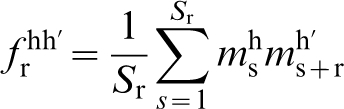
It should be noted that there is a tremendous leap in the amount of structure information contained in the 2-point statistics compared to the 1-point statistics. Higher-order correlations (3-point and higher) are defined in a completely analogous manner. The relationships between these microstructure measures and several of the classically defined ones are summarised in several books. 53,93 An implicit benefit of treating the material structure in a statistical framework is that it naturally leads to a quantification of the variance associated with the structure. 30,53,96–100 The variance in structure can then be combined appropriately with the other uncertainties in the process (for example, those associated with the measurements and those associated with the models used to predict overall properties or performance characteristics of interest in an engineering application) to arrive at the overall variance in the component performance. Lack of tight variances on the performance characteristics of the final product is often cited as one of the main reasons for the inability to scale a process from the laboratory scale to the manufacturing environment. As these variances can be traced to variances in material structure (produced by variances in processing), it is imperative to track the variances in the material structure using a practical approach. Once again data-driven approaches provide a way forward to addressing this challenging task. 88,96
The strongest support for the choice of n-point spatial correlations as the most appropriate measures of material structure comes from the pioneering work of Kroner, 101 who has taught us that the effective properties of composite material systems can be conveniently expressed as a series sum with the structure details entering this series explicitly in the form of n-point spatial correlations. These composite theories have been generalised to a broad range of materials phenomena and have been summarised in several books. 53,93,102 There are also several reports in literature, where they have been successfully applied to estimate effective properties (both linear and non-linear) of a broad range of materials with complex structures. 103–109 Physically, the n-point spatial correlations are very effective in rigorously quantifying the local neighbourhoods in the complex internal structure of most advanced materials. As the local neighbourhoods control the local response, it is only logical that the n-point spatial correlations are the ideal measures of the material structure in formulating PSP linkages of interest in designing high performance engineering components.
Reduced-order representations of microstructure
For most structural material systems of interest in advanced technologies, the set of n-point statistics is an extremely large unwieldy set even for n = 2. Rigorous analyses and mining of these datasets are only possible with the application of data science tools. For example, it was recently demonstrated that techniques such as principal component analysis (PCA) 110–112 can be used to obtain objective low dimensional representations of the 2-point statistics. 67,96 Principal component analysis provides a linear transformation of high dimensional data in a new orthogonal frame where the axes are ordered according to the observed variance among the elements of the dataset. Consequently, a truncated PCA representation provides an objective (data-driven) reduced-order representation of the original data. It is emphasised here that although PCA dimensionality reduction techniques have been explored in materials problems in prior literature, 69,113 they have only recently been employed on 2-point spatial correlations of microstructure in attempts to successfully extract high fidelity structure–property linkages. 67,88,96,114
As an example, let 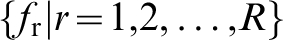
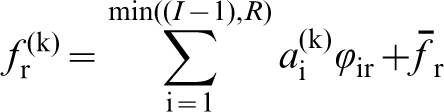
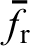
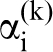
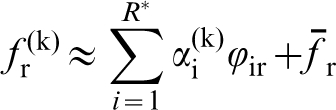
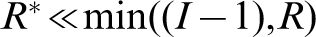
The PCA representations of the n-point statistics have been successfully used in automated and efficient classification of various ensembles of structures. 67,88 An example is reproduced here in Fig. 3. Although only the first three dimensions are plotted in Fig. 3 (i.e. R * = 3), it should be noted that this approach yields data-driven reduced-order representations for structure ensembles to arbitrary truncation levels selected by the user. As noted earlier, PCA provides guidance regarding the significance of each principal component (b i) through which the user can make an objective decision regarding the acceptable truncation level for a specific application.
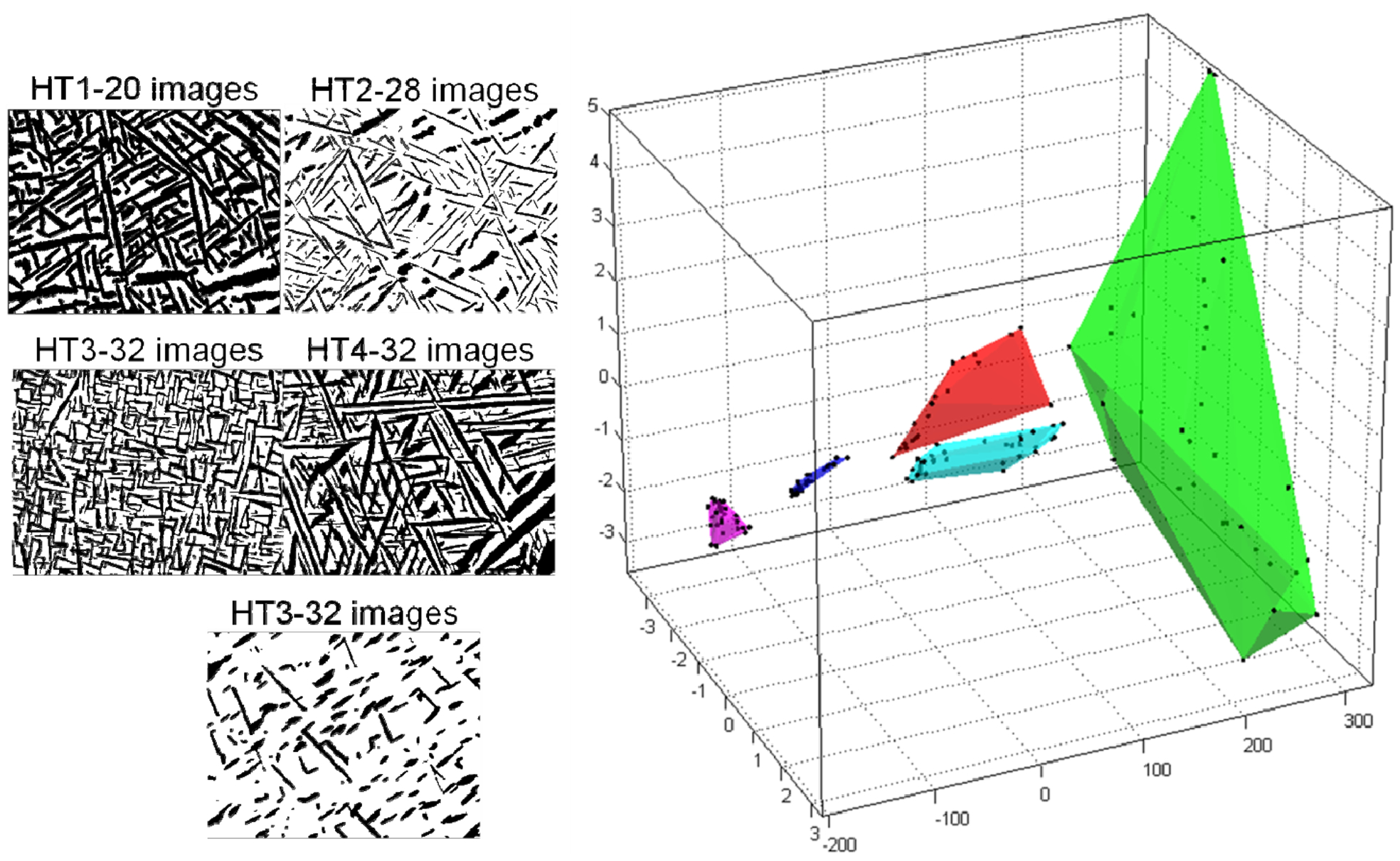
Visualisation of an ensemble of material structures, taken from Ref. 67. Each point in the reduced-order three-dimensional PCA space represents a micrograph (examples shown on left) and each coloured volume represents a structure class. The size of each coloured region reflects the variance within the class. The axes in the 3-D plot correspond to the αi in equation (3). The colour key for the different heat treatments is as follows: HT1 = Red, HT2 = Blue, HT3 = Green, HT4 = Cyan, HT5 = Magenta
One of the benefits of the PCA representations shown in Fig. 3 is that it also quantifies the inherent variance in a given class of structures. For example, it is clear from Fig. 3 that the structures in HT3 exhibited the highest variance, whereas those in HT2 produced the lowest variance, among the five heat treatments studied. Although quantitative values of the variance were not reported in this specific study, they were explored in great detail in a subsequent study that used the same foundational concepts. 96
In the examples presented above, the local state was defined at the continuum scale and identified the specific phase found in the micrograph. However, the same methodology can be applied to a broad range of other material structures at other length scales. In a recent paper, this approach was successfully applied to quantify the semi-crystalline polymer structure datasets produced by MD simulations. 115
Structure measurements and reconstructions
The discussion above raises an important question: exactly what should we be measuring when we desire to extract the important PSP linkages needed for materials development efforts? The conventional approaches in materials science and engineering are generally focused on mapping contiguous volumes of the material internal structure in two or three dimensions at various length scales of interest. If indeed only a finite set of spatial correlations is needed in formulating PSP linkages of interest (as suggested by the PCA example presented earlier), it should be possible to develop customised protocols that focus exclusively on the important statistics and produce the required information in a cost-effective manner. This is especially true, when the characterisation technique involves probing the material structure voxel-by-voxel and each measurement incurs a significant cost (e.g. measurement of crystal lattice orientations by electron back-scattered diffraction 116 and measurement of local mechanical properties using nanoindentation 117–119 ). For example, Adams and co-workers 53,100,120 have demonstrated that it is much easier to recover 2-point and 3-point spatial correlations in three dimensions in polycrystalline samples, when compared to the effort involved in measuring the material structure in 3-D contiguous volumes in the same class of samples. 4,14,121–123 These authors have also demonstrated that it is often possible to recover distribution functions quantifying structure in 3-D using information gathered on 2-D sections using theories from stereology. 124,125 While these prior studies demonstrate tremendous potential for dramatically reducing the cost incurred in structure quantification, they are still very much in a nascent stage of development. Much future work is needed to further refine and critically validate these approaches and their ability to produce robust and reliable PSP linkages for a broad range of materials being developed for emerging technologies.
After deciding what should be measured, the next question to address is how much data are needed. The goal of structure measurement, in general, should be to quantify not only the expected values of the structure measures of interest, but also their variance. It is well known that control of the structure variance is the best means to control the variance in the properties/performance of the final product. When using the framework of the n-point statistics along with the PCA representations in an orthonormal frame (in the space of statistics) described earlier, the variance can be related to the eigenvalues computed as a part of the PCA decomposition. 88,96 Roughly speaking, the variance can be mathematically related to the volumes of the regions occupied by the members of the ensemble of structures extracted from the sample (or multiple samples subjected to nominally the same processing history), as depicted in Fig. 3. Consequently, it is possible to establish a data-driven process that will objectively decide how much data are adequate to reliably estimate (to within a set accuracy limit) the distribution of the selected structure measures in any given sample.
In addition to the amount of data, one also needs to decide on a scan size in structure measurements. Within the framework of n-point statistics, the relevant length to consider in deciding on the scan size is the coherence length, 53,93 defined as the length beyond which the n-point statistics (obtained on an ensemble of structures taken from a given sample) are completely uncorrelated. This length therefore depends on the specific sample being studied. For example, in a perfectly disordered structure, the coherence length is of the order of the individual spatial bin size. However, perfectly disordered structures are seldom realised in practice. As one does not a priori know the coherence length in a given sample, one needs a few preliminary measurements (for example, these could be long line scans) to establish the coherence length and then ensure that the scan size is larger than the coherence length of the structure in the given sample. Generally speaking, if the scan sizes are of the order of the coherence length, one needs to acquire a sufficiently large number of scans in order to establish reliably the variance in the desired subset of spatial correlations, as discussed earlier. The general practice in the field, however, has been to obtain very large scans (as large as practically feasible within available resources) and use a small number of these large scans instead of a large number of smaller scans from different locations in the physical sample. This practice is tantamount to sub-dividing the large scan into smaller regions and treating each smaller scan as an independent measurement (although in reality it is not!). From a statistics viewpoint, the preferred practice would be to obtain a large number of adequately sized scans (each approximately about twice the coherence length) from randomly selected regions in the physical sample.
The discussion above naturally leads to the oft-debated question of how should one produce a RVE of the material structure. In the present context, it is highly desired that the RVE reflects the expected values of the important structure measures. It is noted here that most commonly adopted definitions of RVE in current literature 102,126–138 focus largely on the convergence in the prediction of selected macroscale (effective) properties and do not explicitly consider whether or not the RVE has captured the structure details to sufficient accuracy. Incidentally, the classical definition of RVE provided by Hill 139 requires the RVEs to capture both the representative structure and its homogenised effective properties. In the present discussion, authors will focus first on the structure aspects and then address later the predictions of macroscale properties. Within the framework of the n-point statistics presented earlier, in order to faithfully capture the material structure, the RVE should reflect as closely as possible the expected values of the salient set of n-point statistics. Given the very high dimensional representations of n-point statistics, the only practical approach to this task is through the use of reduced-order representations such as those described earlier. For example, looking at Fig. 3, the goal would be to construct an RVE for any of the ensemble of structures (from any one of the heat treatments) in such a manner that the n-point statistics of the RVE would correspond to the centre of the volume of interest shown in this figure. Herein lies the main challenge of constructing RVEs that faithfully capture the main features of an ensemble of measured structures – it is often not easy to construct such structures from a prescribed set of spatial correlations.
One trivial solution to the RVE construction described above is to think of the RVE as an equally weighted representation of all the members of the selected ensemble of structures. If one were to use this approach, each member of the ensemble would represent a statistical volume element (SVE). 98,99,140,141 In fact, if one were to follow this approach, the size of the SVEs can be significantly smaller than that of the RVE. The use of a set of SVEs of smaller volumes (instead of a single RVE) offers tremendous computational savings, especially when the macroscale properties need to be evaluated using sophisticated physics-based numerical simulations. The main disadvantage of using the equally weighted set of SVEs is simply the fact that one typically needs a fairly large number of SVEs to approximate the RVE, 132 especially when SVEs are selected to be of relatively small volumes.
An alternate approach was recently presented by Niezgoda et al., 84 who introduced the concept of weighted sets of Statistical Volume Elements (WSVEs). In this approach, the identification of a WSVE is approached as an optimisation problem that searches through all weighted combinations of the available SVEs and minimises the difference between the spatial statistics of the constructed WSVE and the ensemble averaged spatial statistics from all available SVEs, while being subjected to the following constraints: (i) the number of SVEs used to build the WSVE is limited to the number prescribed by the user and (iii) the weights assigned to the individual members of WSVE have to be positive and sum up to one. In other words, WSVE approximates the RVE as a set of optimally selected and weighted SVEs (from the available ensemble of SVEs) with the weights essentially representing the volume fractions of the selected SVEs in the RVE (see Fig. 4). It was demonstrated that the WSVEs established using the concepts described above automatically approximated well the effective properties associated with the larger structure datasets, while providing major computational advantages because of the dramatic reduction in the sizes and numbers of the volume elements. 3,15 This is mainly because the WSVEs efficiently capture the spatial statistics in the ensemble of SVEs (or the RVE). The computational advantages of the WSVEs were particularly impressive when computationally expensive models (e.g. coupled multiscale models, crystal plasticity) were used to estimate the effective properties or performance associated with a given microstructure. 3
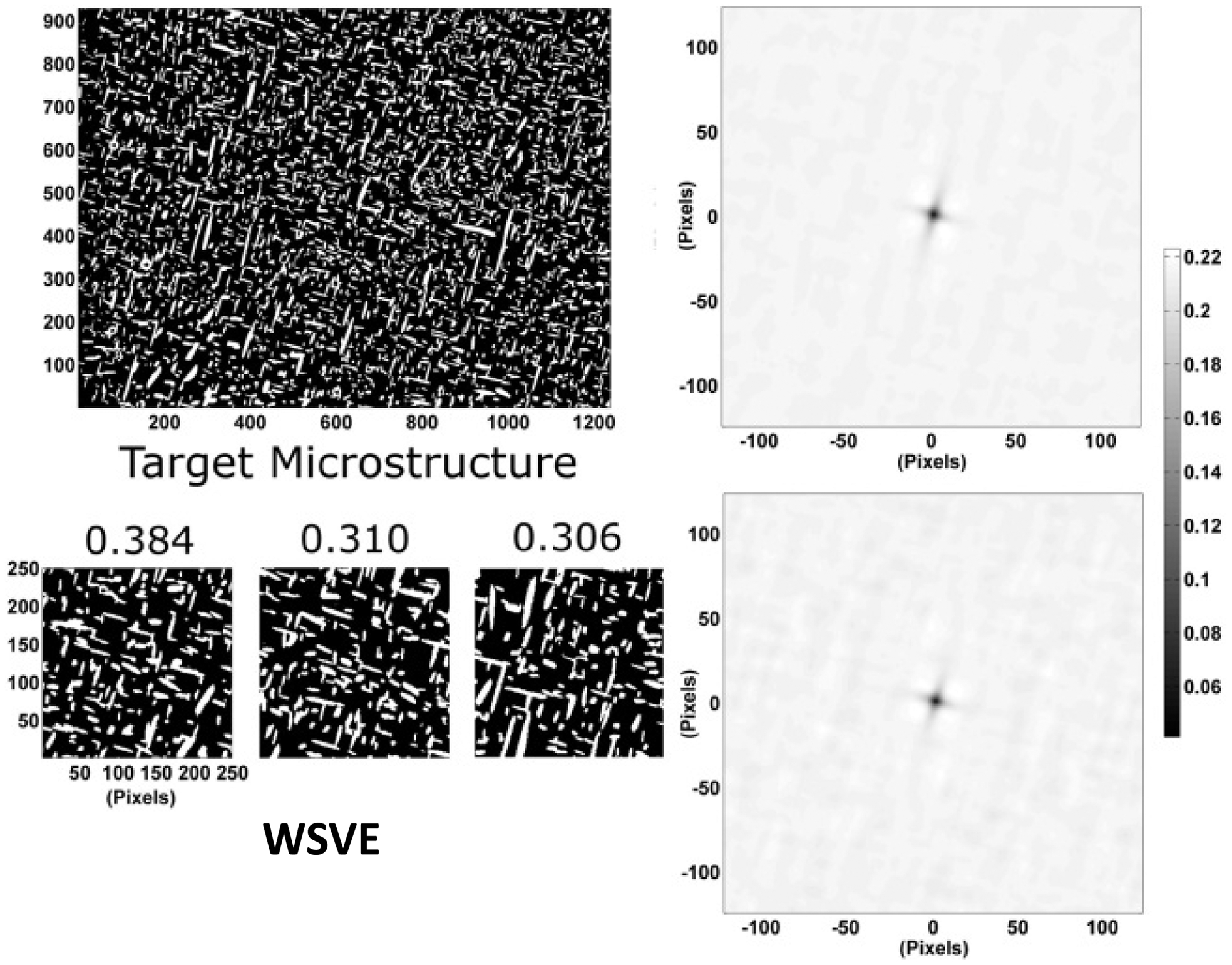
Illustration of the construction of a weighted set of statistical volume element (WSVE) comprised of three weighted optimally selected statistical volume elements (SVEs) for an experimentally characterised precipitate structure. The corresponding plots of 2-point statistics are shown on the right
Automated mining of process–structure–property linkages
The structure information gathered from protocols described above has very little intrinsic value. High value (both scientific and economic) is usually derived from these structure datasets when they can be associated with appropriate information on either the properties exhibited by them or the manufacturing processes employed to modulate them (into new structures with better final properties). This additional and crucial information is typically gathered through multiscale measurements and/or execution of physics-based numerical simulation tools. It should be noted that this task usually requires allocation of significant resources and time and therefore presents a major risk to those who undertake materials development activity. The ensuing risk from such effort and time consuming tasks can be mitigated to a large extent if suitable core knowledge is mined through such activities in automated, cost-effective, ways and successfully transferred to subsequent related tasks. This can be accomplished through the mining and establishment of reliable PSP linkages that can be applied to a broad range of structures (much broader than those used to establish the linkages themselves).
As discussed earlier, PSP linkages needed for the development of advanced hierarchical materials are best archived in a suitably defined low-dimensional projection of the structure space. 54,67,79 In some cases, it is possible to establish such linkages using intuitive selection of structure measures (e.g. Hall–Petch relations 142,143 ). However, given the large dimensional representations demanded by the complex structures in most hierarchical material systems, it is highly desirable to explore such relationships through DATA-driven approaches. These novel approaches offer many benefits: (i) they allow for automation in evaluating the multiple options one faces invariably in mining the salient PSP linkages of interest from the available experimental and simulation datasets. (ii) These approaches often cast the PSP linkages as simple metamodels (also referred as surrogate models) that require significantly lower computational cost (when compared to the physics-based multiscale models and experiments that generated the raw data used to establish these linkages) and are potentially invertible. This feature is of significant value to the engineering design/manufacturing stakeholders in the advanced technology sectors.
The reduced-order representations of the spatial correlations in the microstructure (see equation (3)) are foundational to a new data-driven framework
67,114,144
for establishing reliable low-cost structure–(homogenised) property metamodels from ensembles of experimental and/or simulation datasets. Although the establishment of the PSP linkages in this manner incurs a one-time cost, it is expected that this effort will lead to major savings in future tasks where the low-cost metamodels can be substituted for the more expensive experiments and/or simulations. For illustration of this approach, let 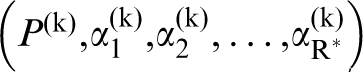
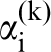
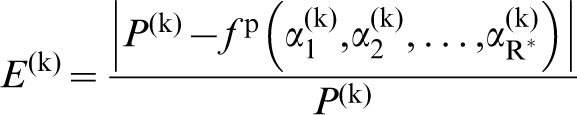
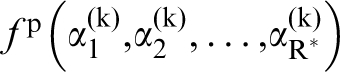
The data-driven approach described above offers many advantages: (i) the process of establishing the PSP linkages can be largely automated with a comprehensive exploration of different error measures, different functions for capturing the linkages, and different techniques for quantifying the degree of over-fit. (ii) The established PSP linkages can often be dynamically modified with only an incremental effort (requires cleverly designed algorithms) when additional data become available. (iii) The error distributions computed as a part of these protocols also quantify the inherent uncertainty of the mined PSP linkages. Figure 5 depicts an example from our recent work, 144 where the focus was on establishing structure–property linkages that could guide the design of the optimal processing path in a class of steels with inclusions.
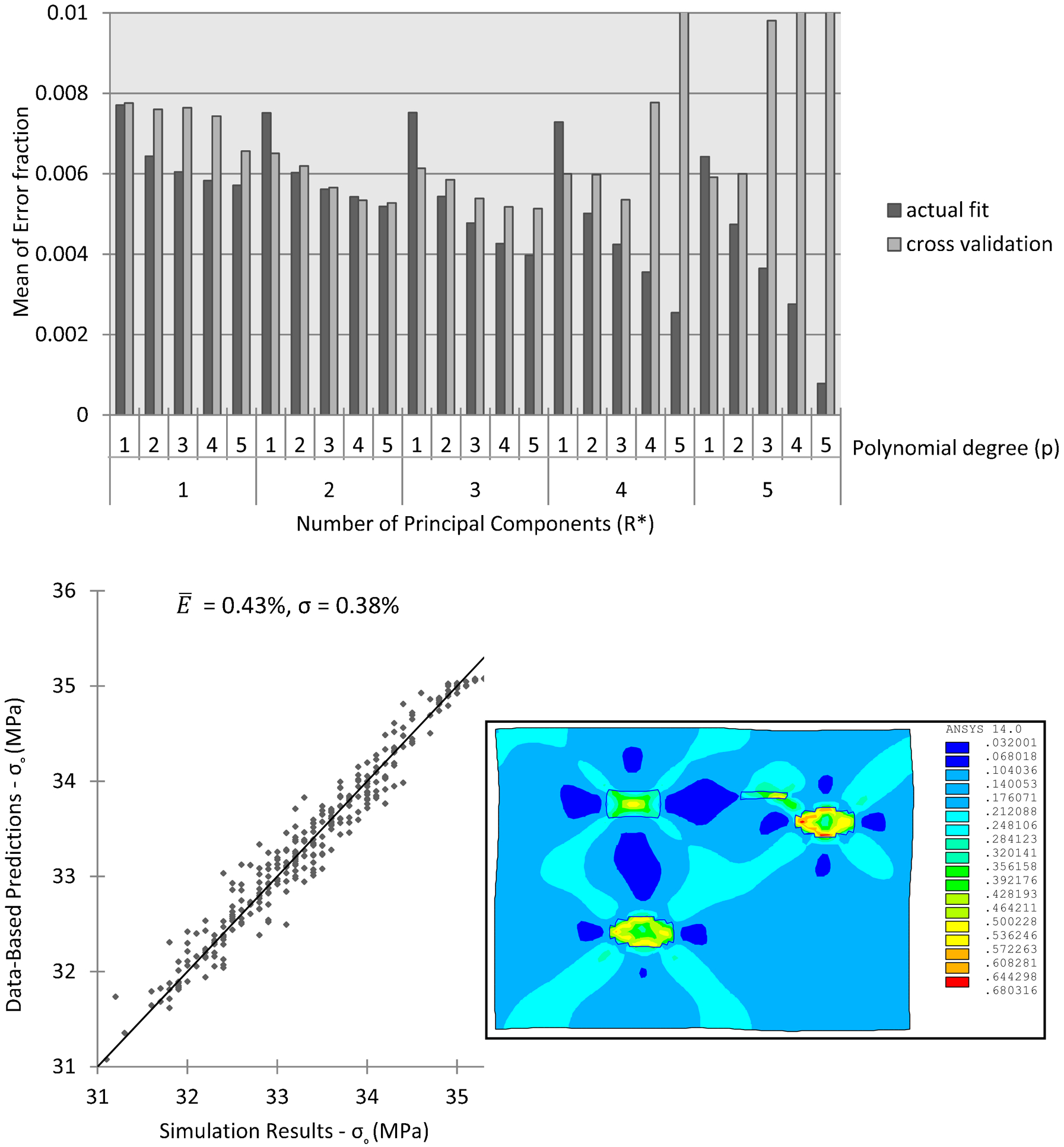
Variation of the error from the regression analyses and the cross-validation for different truncation levels in the reduced-order quantification of the spatial correlations in a class of two-phase material structures and their linkage to macroscale yield properties. 145 Examination of these errors indicates that R * = 3 and p = 4 and presents the best compromise between a good fit and the risk of over-fitting. The plot on the bottom left shows the match between the original data (gathered from finite element simulations of the type shown on bottom right) and the predictions of the metamodel mined from the data. A total of 400 data points were generated using finite element model simulations on an ensemble of material structures with a range of precipitate volume fractions, precipitate shape and size distributions to establish this structure–property linkage
In another variation of the data science approach, the computational cost of solving the numerically stiff non-linear constitutive laws of crystal plasticity theory was reduced by about two orders of magnitude. 145–149 This was accomplished through the use of a compact database of DFTs to efficiently reproduce the solutions from the physics-based model for the main functions of the crystal plasticity theory for any given crystal orientation subjected to arbitrary deformation mode. As with the earlier example, a special advantage of the database approaches suggested here is that trade-offs can be made by the user in terms of the desired accuracy and computation speed in any simulation through the selection of the truncation levels in the metamodel (in the case of crystal plasticity simulations this is controlled by the number of dominant DFTs retained in the metamodel).
The structure–property linkages described earlier are aimed at passing the salient information from lower length scales to the higher length scales. However, in certain situations, it becomes necessary to simulate coupled phenomena at two well-separated length scales. As an example, consider the simulation of a complex processing operation where different macroscale spatial locations in the workpiece experience different thermal histories (often an unavoidable consequence of the boundary conditions imposed at the macroscale). Consequently, strong variations in the material structure should be expected at different locations in the workpiece. In other words, it is not enough to track the evolution of a single representative material structure for the entire workpiece. The development of such structure heterogeneities can be expected to influence the macroscale simulation by altering the local effective properties at different locations in the workpiece. In such a situation, it is necessary to track independently material structures at multiple macroscale locations in the workpiece, and pass high value information in both directions (between the constituent length scales). Accomplishing this task within the currently employed computational frameworks requires executing a very large number of numerical simulations at the lower length scale within simulations executed at a higher length scale (e.g. multilevel finite element method 150 ). This is extremely difficult, if not impossible, to address real-world hierarchical materials design and development problems using any of the currently employed computational strategies.
The challenge described above can be addressed with modest computational resources using a data science approach called materials knowledge systems (MKS). 90–92,151–155 In the MKS framework, the focus is on localisation (i.e. opposite of homogenisation) relationships that capture the spatial distribution of the response field of interest (e.g. stress or strain rate fields) at the microscale (on a RVE) for an imposed loading condition at the macroscale. In this approach, the localisation relationships are expressed as calibrated metamodels, whose specific forms are inspired by rigorously established composite theories called as statistical continuum theories. 81,101,156–158 More specifically, these localisation linkages are expressed as a simple algebraic series sum those terms that capture systematically the individual contributions from a hierarchy of local structure descriptors. Each term in this series expansion is expressed as a convolution of the appropriate local structure descriptor and a physics-capturing kernel. A salient feature of the MKS appfroach is that the physics-capturing kernels are calibrated to results from previously validated numerical models for the multiscale phenomena being studied (for example, in studies of stress or strain localisation in a composite materials system, the MKS linkages would be calibrated to results obtained from execution of validated micromechanical finite element models on a selected ensemble of material structures). The most impressive benefit of the MKS approach lies in the dramatic reduction of the computational cost, often by several orders of magnitude compared to numerical approaches typically employed in material structure design problems. In various preliminary demonstrations, the MKS methodology has been successfully applied to capturing thermo-elastic stress (or strain) distributions in composite RVEs, 90,92,152 rigid-viscoplastic deformation fields in composite RVEs, 89 and the evolution of the composition fields in spinodal decomposition of binary alloys. 91
Let 〈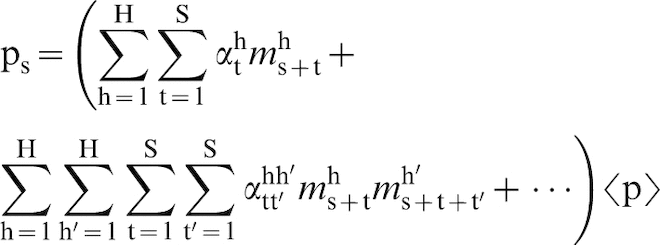
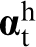
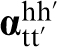
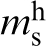
The calibration of the first-order term in the MKS series is made possible by the fact that equation (5) takes a much simpler form when transformed into the DFT space, which can be expressed as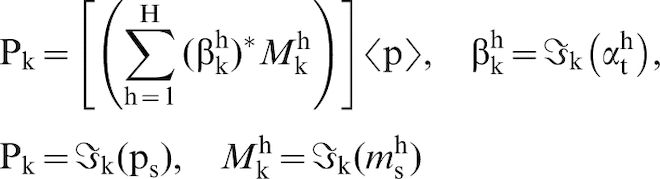
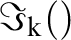
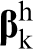
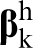
The details of the calibration procedures for the influence coefficients have been discussed in detail in prior publications. 90,92 Briefly, the influence coefficients were calibrated using digitally created microscale volume elements (MVEs) subjected to selected periodic boundary conditions in finite element simulations. In prior work, periodic boundary conditions were utilised, 90,92,160–162 as they are particularly well suited for DFT representations. It should also be noted that the selection of the size of the MVE can have a significant influence on the calibrated values of the influence coefficients. As the influence coefficients are expected to decay to zero values for increasing values of t, the localisation captured by equation (5) is associated with a finite interaction zone or finite memory. In order to capture the spatial characteristics of localisation accurately, it is recommended that the MVE size used for generating the calibration datasets be at least twice the size of the interaction zone. Since the size of the interaction zone is not known a priori, a few trials are typically needed to establish a suitable MVE size for a given material system and a selected physical phenomenon. Finally, it is also important to ensure that the MVEs are large enough that the boundary conditions do not significantly impact the calibrated values of the influence functions.
The influence functions established on smaller spatial domains (MVEs) can be easily extended and applied to significantly larger spatial domains such as those needed to represent RVEs. 92 As the influence functions decay sharply with increasing t (just like Green's functions), they can be extended to larger spatial domains by simply padding the functions with zeros. It was demonstrated 92 that the trivially extended influence coefficients accurately reproduced the microscale spatial distribution of the desired field on the larger MVEs with about the same accuracy that was realised for the smaller MVEs.
Figure 6 demonstrates the accuracy of the MKS approach for predicting the local rigid-perfectly plastic response in an example material structure with two isotropic phases. 89 The error between the MKS predictions and the FEM analysis was quantified in each spatial bin and the average error in the MKS predictions was noted to be only 2·2%. More importantly, the FE analyses using 93×93×93 3-D elements could not be performed on a regular desktop PC. It was executed on an IBM e1350 supercomputing system (part of The Ohio Supercomputer Centre) and required 94 processor hours. In contrast, the MKS method took only 32 s on a regular laptop (2 GHz CPU and 2 GB RAM).
Comparison of the contour maps of the local
Integration and collaboration platforms
The data science tools described earlier are aimed at mining the low-dimensional representations of the important PSP linkages critically needed to dramatically accelerate the rate at which new materials are designed, developed, and deployed in new high performance products introduced in the market place. However, to fully realise these ambitious goals, it is imperative to develop and validate suitable protocols for effective integration of the core materials knowledge (i.e. PSP linkages) in manufacturing process simulation and product design tools. Historically, this integration has not been easy (see Fig. 7). There exists a fundamental disconnect between how knowledge is sought and expressed in the materials and manufacturing fields. Experts in materials science often express the knowledge they accumulate from their experiments and models as highly simplified PSP linkages. Their desire to seek simplified PSP linkages is largely a byproduct of the usage of simplified intuitive measures for the quantification of the complex hierarchical material structure. However, these PSP linkages are rarely cast in a form suitable for the formulation of the internal state variable theories used widely in the manufacturing process simulation tools (same with product design tools) to describe the material constitutive response. This is because most internal state variable theories use sophisticated tensorial descriptors of the material internal state, which do not necessarily connect directly with the physical quantities measured and modelled by the materials experts. As a consequence of this fundamental disconnect in the practices in these two fields, integration of the materials knowledge into broadly used manufacturing simulation and product design tools continues to experience major hindrances.
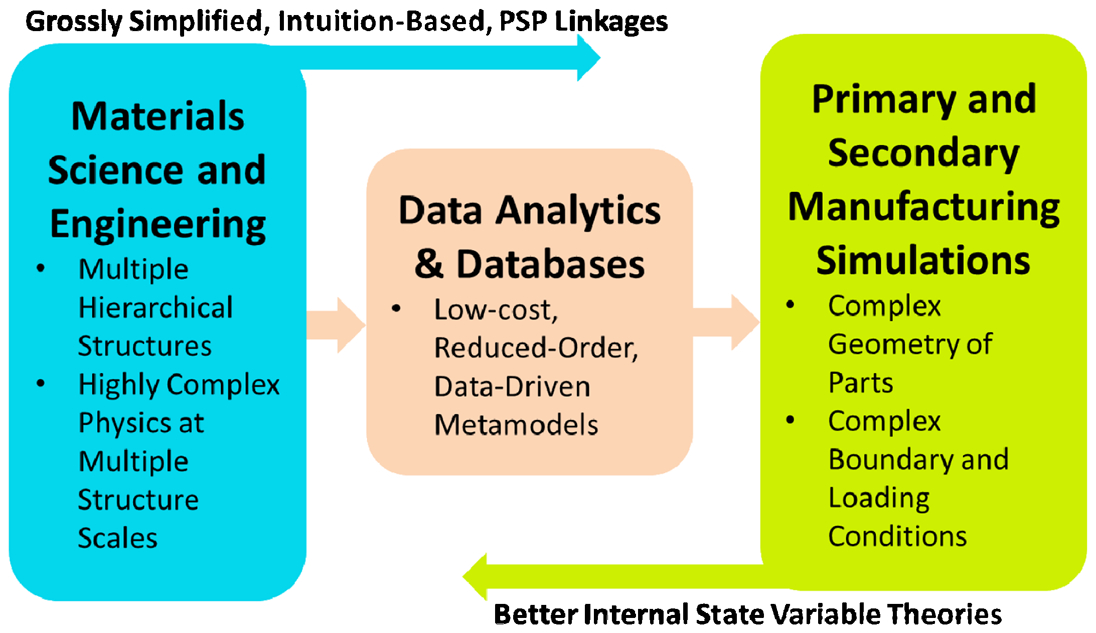
Schematic depiction of the current and proposed protocols for integration of high value materials knowledge into manufacturing process and product design simulation tools
The data-driven approaches described in this paper offer an alternative approach that might address the challenge described above. The approaches described earlier are capable of organising the core materials knowledge (i.e. PSP linkages) as either low-cost metamodels or easily accessible databases that can be directly integrated into manufacturing simulation and product design tools (see Fig. 7). Preliminary examples of such integration are demonstrated in recent work 145,151 and have identified major computational advantages. In other words, data sciences can serve as an effective and direct integrator of the core materials knowledge into various components of the product design and manufacturing value chain. This would, however, be possible only through an intimate cross-disciplinary collaboration between materials experts, design/manufacturing experts, and data scientists. Because of the many barriers that currently exist between these fields (e.g. differences in approaches, terminology used), it is imperative to design and build novel integration platforms (i.e. cyberinfrastructure) that are specifically designed to enhance and accelerate such collaborations. Some of the desired components of this supporting cyberinfrastructure include (i) automated protocols for capturing and tracking data provenance through its many adaptations by the collaboration team members, (ii) automated protocols for the identification of the salient aspects of the data (i.e. metadata) and sharing them with cross-disciplinary team members, (iii) community building of ontologies and domain lexicons that enable and promote meaningful exchange of ideas, data, tools, and knowledge between cross-disciplinary team members, and (iv) a code repository with versioning. In essence, the approach described here can be referred to as DC-MGI or DC-ICME, and encompasses a data science and cyberinfrastructure supported approach to practical realisation of the materials genome initiative (MGI) 9 and integrated computational materials engineering (ICME) 10 visions (see Fig. 8).
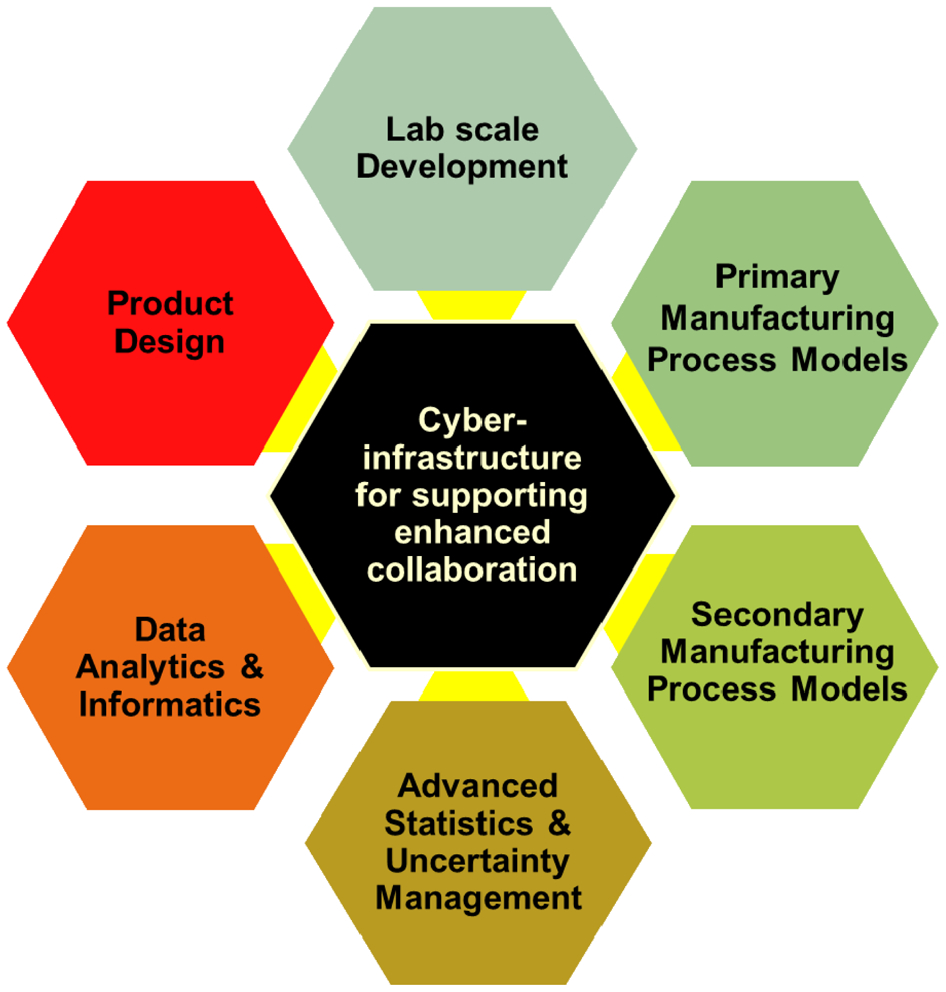
Schematic depiction of the DC-materials genome initiative/integrated computational materials engineering (DC-MGI/ICME) approach
Summary and outlook
This paper has summarised the current status of an emerging framework for accelerating the development of new/improved hierarchical materials on the foundations of data sciences and cyberinfrastructure, while fully leveraging the recent advances in both experimental and computational sciences. Although the initial results described above are very promising, it should be clear that they represent the very early stages of this nascent new field. The framework described above needs several extensions before it can be applied to a large number of complex material systems explored in advanced technologies. In the results presented here, the local states of the materials were considered to be relatively simple and the materials phenomena explored were also relatively simple. Furthermore, most of the case studies completed to date considered mainly meso-length scales. It is therefore necessary to extend the framework and tools presented here to more realistic material systems where the material structure definitions demand the use of continuous state variables (e.g. polycrystalline materials where the local state description requires the specification of some combination of composition, phase identifier, and crystal lattice orientation) and span multiple length scales (from atomistic to the macroscale). Such extensions will in turn allow exploration of more complex materials phenomena encountered in typical manufacturing process routes (e.g. thermo-mechanical treatments) and in service conditions (e.g. fatigue).
As a simple example, consider a materials system where the local state in the material structure requires the description of the chemical composition (i.e. the structure description requires specification of the spatial distribution of the chemical composition). Let c
s denote the average chemical composition in the spatial bin s (suitably defined at the hierarchical length scale of interest). In prior work,
91
this structure description was converted to a digital signal 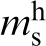
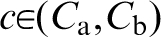
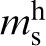
A second critically needed extension to the framework presented here for the computations of the n-point statistics may focus on the treatment of point cloud datasets such as those produced in MD simulations. As these datasets do not typically provide data on a uniform spatial grid, the techniques described here need further refinement to be computationally efficient for such datasets. One possible direction would be to develop efficient computational protocols to convert point cloud datasets into digital microstructure signals described on a uniform spatial grid. Another option is to explore the use of special algorithms that compute Fourier transforms efficiently for data on a non-uniform grid. It is also possible that sometimes the microstructure information cannot be expressed as point data. This might happen in describing complex defect structures (e.g. dislocation structures). Further enhancements to the framework are needed to address such situations.
The reconstruction of the microstructure from spatial correlations represents a major gap at this time. Although it is possible to reconstruct a specific image from a knowledge of the complete set of its 2-point statistics, 81 there is hardly any reason or motivation to do so. Instead, the desire is to reconstruct RVEs from an ensemble of microstructures. Although this paper presented one approach to this problem, there is a clear need for much more future work in this direction. Furthermore, the more useful reconstructions of very high practical value are the reconstructions from partial datasets. For example, one often might have only a partial set of experimentally measured spatial correlations (e.g. 2-D scans on specific sections into the sample). Also, one might be interested in reconstructing microstructures from the reduced-order PCA representations to make physical connections between the PCs and specific microstructural features. All these problems are likely to be of high value to future work in ICME and MGI efforts.
As noted earlier, it is anticipated that most advanced materials used in emerging technologies will demand a tiered description to address the hierarchical material internal structure (spanning multiple length scales). In this paper, the assumption of well separated length scales was implicitly invoked, as is routinely done in working with most composite theories. In other words, it is assumed that the same overall philosophy can be applied repeatedly, as many times as needed, in describing materials whose structures exhibit salient features at multiple well separated length scales. In practice, there might be several situations where the separation of length scales is not achieved. In such situations, one is forced to employ the spatial resolution of the smaller length scale involved and extend the RVEs to obtain a statistically meaningful representation of the spatial correlations for the larger length scale. In such situations, RVEs can become extremely large. Furthermore, the use of the RVE concept itself can encounter additional limitations in practice. For example, in thin films or graded materials, the assumption of statistical homogeneity might fail. Another example would be in applications where the structure features of interest are rare occurrences (e.g. features responsible for fatigue damage initiation), where extremely large RVEs might be needed; these might even be as large as the entire sample.
Multiscale measurements play an important role in the realisation of the goals articulated in this paper as they provide the critical data needed to improve and validate the material structure-sensitive models (i.e. model maturity). In particular, new measurement protocols are critically needed for combinatorial synthesis and/or high throughput processing and characterisation (structure and response) aimed at rapid exploration of the multiscale PSP linkages in hierarchical materials. For example, traditional approaches that combine material structure characterisation and standard mechanical testing (using simple tension or simple compression) evaluate material responses one material structure at a time and therefore produce relatively low volume of high quality data at a relatively high cost. However, this may not present the best strategy for accelerated development of new/improved materials. It might be more cost-effective to pursue testing protocols that allow high throughput material structure prototyping (e.g. single or double cone tests, Jominy bars) to be combined with fast quantification of structures (e.g. customised protocols for the direct measurement of salient spatial correlations in the structure) along with local evaluation of mechanical properties (e.g. indentation methods). Such new protocols that can provide the critical data at the requisite speed, cost and accuracy, needed to support objective decision making in the materials development efforts, present an exciting new direction for research in support of MGI and ICME.
As a final note, it is emphasised here that the data-driven approaches described here for establishing the materials core knowledge (i.e. PSP linkages or metamodels) are ideally suited for incorporation into multiscale robust design approaches such as inductive design exploration method (IDEM). 40,50,164 Implementation of IDEM requires formulation of PSP metamodels at various levels of material hierarchy, along with a rigorous quantification of the associated uncertainty. Integrating the PSP metamodels with the robust design framework of IDEM represents an exciting new direction for research that can provide a practical pathway for addressing the grand challenges described in this paper.
Footnotes
Acknowledgement
The author acknowledges funding from the Office of Naval Research (ONR) award N00014-11-1-0759 (Dr William M. Mullins, program manager). The author also acknowledges numerous discussions with colleagues Professor David McDowell and Dr Tony Fast on the various concepts presented and discussed in this paper.
<?ENTCHAR ast?>
Crystal plasticity theories are widely used to predict the plastic anisotropy of polycrystalline materials by accounting for the fundamental mechanism of plastic deformation at the scale of the constituent single crystals by taking into account the details of slip system geometry in each individual crystal.