
Abstract
The production rate, quality and cost of hot metal production through the blast furnace route depend mainly on the quality of the metallurgical coke. Coke reactivity index and coke strength after reaction (CSR) are the most important parameters used for the assessment of the high temperature properties of coke. Many coke plants and blast furnaces around the world use CSR as a specification just as important as cold strength, size and chemistry. The present work aims to fulfil the need for a model that will predict the coke CSR from coal blend characteristics. In this work, the functional relationship between the coal blend properties (ash, volatile matter, average vitrinite reflectance, crucible swelling number, total reactives, vitrinite distribution V 9–V 13 and basicity index) and the corresponding coke CSR has been mapped using an adaptive neurofuzzy inference system (ANFIS). The ANFIS model is formulated with different sets of coal blend properties as input variable, and the singular value decomposition and QR factorisation based techniques have been employed for model reduction. It has been found that the developed ANFIS model predicts the CSR with reasonable accuracy.
Introduction
The hot metal quality and blast furnace operation depend mainly on the quality of raw materials fed into the blast furnace. Among all the raw materials, coke is considered to be the most important as it serves as a fuel, a reducing agent and a supporting material for the burden. It is a well known fact that the role of metallurgical coke as a permeable support cannot be replaced by any other material, even though it can be substituted by oil, coal and gas to suffice the purpose of fuel and reducing agent. Furthermore, feeding high quality coke to a blast furnace will ensure lower coke rate, higher productivity and lower hot metal cost.
Good quality coke is made generally by carbonisation of good quality coking coals in terms of rank, maceral composition, ash content and ash composition. It is evident that very few individual coals possess all the requisite properties for making a coke of good quality. However, the deficiency of any particular property of a coal can often be supplemented by blending it with other compatible coals. In addition, the coke properties are also influenced by the carbonisation conditions such as bulk density, temperature, oven width and coking time. Even though the coke quality is attributed by both carbonisation condition and coal blend composition, it has been reported1 that the coal blend composition plays a predominant role (∼70%) than the carbonisation condition in fixing the coke property.
At present, the coke quality is widely assessed through the hot strength parameters, coke strength after reaction (CSR) and coke reactivity index (CRI), introduced by Nippon Steel Corporation in the 1970s. In this method, 200 g coke sample with a size range from −21mm to +19 mm is heated at 1100°C under 1 atm pressure of CO2 for 2 h. The percentage weight loss is known as the CRI. The reacted coke is placed in an ‘I’ drum and subjected to 600 revolutions. The material removed from the drum passes through a +10 mm square hole. The percentage of material remaining on the top of the +10 mm screen is known as CSR.
In order to optimise the coal blend composition and to incorporate the new source of coal into the blend that produces the required quality (CSR/CRI) of coke, it is important to have a mathematical model. Keeping in view the strong correlation existing between CSR and CRI, usually knowing the value of CSR, the coke CRI can be estimated.2 Since all the properties of coal are not additive in nature and also carbonisation itself is a very complex and highly non-linear phenomenon, most of the existing models are based on data driven regression models.3 – 5 In general, these models involve the mapping of coal blend properties with coke strength parameters.
Owing to the emergence of computational power and the development of artificial intelligence based algorithms, knowledge extraction from data has become a distinct possibility. In this connection, the coke CSR had been predicted from coal blend properties using artificial neural network (ANN).6 – 8
However, since the ANN models have poor interpretability due to the ‘black box’ structure, it is often merged with the transparent and more interpretable fuzzy logic to form neurofuzzy inference systems. Among the various neurofuzzy models existing in the literature, adaptive neurofuzzy inference system (ANFIS)9 has been found to possess an excellent ability to learn from the available information.10 – 13
The adaptive network based fuzzy inference system is a mathematical representation of fuzzy rule base, which maps the relationship between the input and output variables utilising the excellent learning ability of ANNs. Owing to these advantages, ANFIS based models are presently gaining importance. The ANFIS model has been found successful in predicting the properties of polymer blend made at different operating conditions with fixed blend composition.14 Similarly, Khorami et al. 15 employed ANFIS to predict the free swelling index of coal.
In the present work, an ANFIS based structure has been selected to relate the coal blend properties with the coke CSR. The training algorithm used is based on the Levenberg–Marquardt method.16 A schematic representation of the present work is illustrated in Fig. 1.
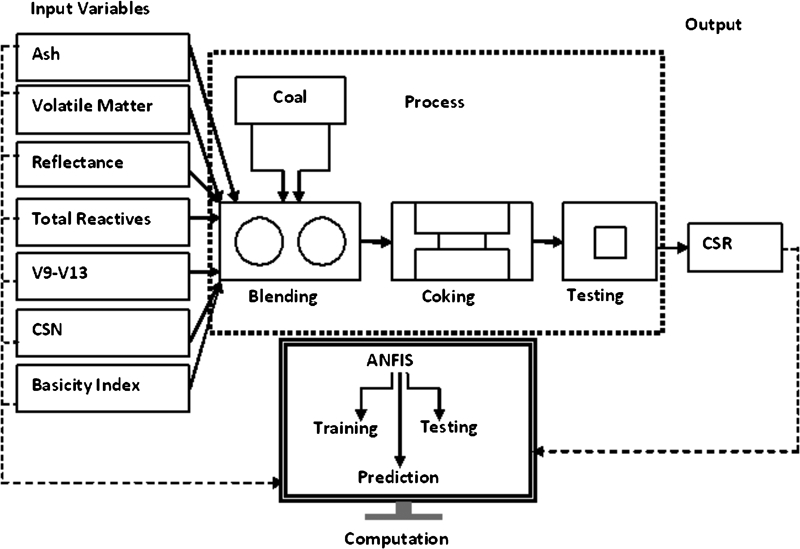
Schematic representation of coke property prediction using ANFIS model
Experimental
Materials used
In this work, a total of 13 coals from different sources have been used. These coals are blended in different combinations and compositions in order to formulate 67 coal blends. Each blend is characterised using standard methods for properties such as ash, volatile matter (VM), average vitrinite reflectance Ro, total reactives, total inerts, vitrinite distribution V 9–V 13, crucible swelling number (CSN) and basicity index (BI).
Carbonisation process
The carbonisation tests have been performed under stamp charging conditions in a 7 kg electrically heated laboratory scale test oven.7 The construction and operation of the 7 kg electrically heated test oven are based on the recommendations of the British Carbonisation Research Association. The operating parameters, like bulk density, oven temperature, moisture, granulometry and carbonisation time, are maintained constant for all the tests. For each experiment, the coke CSR and CRI have been recorded. In this manner, the total number of data sets generated is 67.
Model formulation
Input selection
It is considered that coal properties such as ash content, VM, ash composition, maceral composition and coal rank have influence on the coke property. The parameters average vitrinite reflectance and V 9–V 13 distribution are incorporated to represent the coal rank. The ash composition is represented by incorporating the BI. Maceral composition is considered through total reactives, total inerts and vitrinite distribution. Similarly, CSN includes the caking and swelling properties of the coal for coke making application. The total reactives and total inerts are linearly dependent on each other as their summation is always equal to 100. Hence, the variable total inerts are not included in the input model set. The data range of the coal blend properties generated is tabulated in Table 1.
Minimum and maximum ranges of coal blend properties
Data preprocessing and clustering
All the input and output variables are normalised between 0 and 1 using ‘min.–max.’ normalisation technique. Using statistical indices such as mean and standard deviation, the outlier data sets have been removed and brought down the total number of data set to 62. The performance of data driven models like ANFIS depends not only on the quality of data but also on the distribution of data between training and test sets. The presence of data covering the entire range of variables in both training set as well as test set further improves the prediction capability of the model. In order to achieve this, the available number of data is classified into different groups using a clustering technique.17 In the present work, fuzzy C-means program of the fuzzy toolbox of Matlab 7·0 has been used for clustering. After clustering the entire data set into eight groups, 17 data sets were uniformly picked up from the eight groups as a test set, and the remaining 45 constitute the training set.
Model configuration
In the present work, the first order Sugeno type based ANFIS structure has been used to predict the CSR. Figure 2 illustrates the ANFIS model architecture for two number of fuzzy rules. The number of neurons in the input and output layers are fixed based on the number of input (i.e. 7) and output (i.e. 1) variables respectively. The number of neurons in the in between layers is fixed by the number of fuzzy rules used in the rule base. It consists of six layers in which each node performs a particular function on incoming signals.
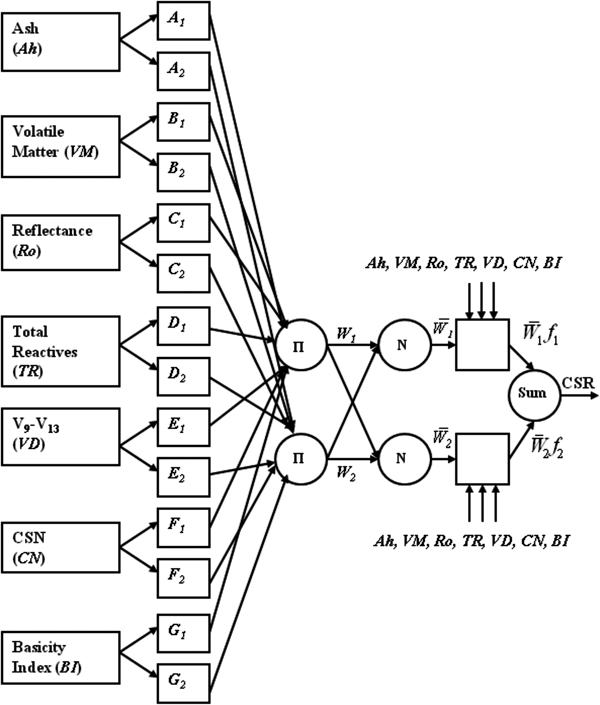
Adaptive neurofuzzy inference system model structure for prediction of CSR
On the basis of earlier studies, the coal blend properties, such as ash, VM, average vitrinite reflectance, total reactives, vitrinite distribution V 9–V 13, CSN and BI, have been considered as input variables, and the coke CSR has been fixed as an output variable. These input variables are related to the output variable through fuzzy rules.
Fuzzy rules
The following fuzzy rules are framed to relate the input and output variables:
Rule 1: if (Ah is A 1) and (VM is B 1) and (Ro is C 1) and (TR is D 1) and (VD is E 1) and (CN is F 1) and (BI is G 1), then f 1 = p 1 Ah+q 1 VM+r 1 Ro+s 1 TR+t 1 VD+u 1 CN+v 1 BI+z 1
Rule 2: if (Ah is A 2) and (VM is B 2) and (Ro is C 2) and (TR is D 2) and (VD is E 2) and (CN is F 2) and (BI is G 2), then f 2 = p 2 Ah+q 2 VM+r 2 Ro+s 2 TR = t 2 VD+u 2 CN+v 2 BI+z 2
Rule 3: if (Ah is A 3) and (VM is B 3) and (Ro is C 3) and (TR is D 3) and (VD is E 3) and (CN is F 3) and (BI is G 3), then f 3 = p 3 Ah+q 3 VM+r 3 Ro+s 3 TR+t 3 VD+u 3 CN+v 3 BI+z 3
Rule 4: if (Ah is A 4) and (VM is B 4) and (Ro is C 4) and (TR is D 4) and (VD is E 4) and (CN is F 4) and (BI is G 4), then f 4 = p 4 Ah+q 4 VM+r 4 Ro+S 4 TR+t 4 VD+u 4 CN+v 4 BI+z 4
Rule 5: if (Ah is A 5) and (VM is B 5) and (Ro is C 5) and (TR is D 5) and (VD is E 5) and (CN is F 5) and (BI is G 5), then f 5 = p 5 Ah+q 5 VM+r 5 Ro+s 5 TR+t 5 VD+u 5 CN+v 5 BI+z 5
where Ah, VM, Ro, TR, VD, CN and BI represent percentage ash content, VM, average vitrinite reflectance, total reactives, vitrinite distribution V 9–V 13, CSN and BI respectively. A i, B i, C i, D i, E i, F i and G i are fuzzy sets of the ith fuzzy rule, which are characterised by the membership function that is of sigmoidal type. In addition, p, q, r, s, t, u, v and z are termed as consequent parameters.
The computational procedure of each layer for two inputs (x, y) and two numbers of fuzzy rules is explained as follows.
Layer 1
Calculation of membership value using sigmoid membership function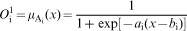
Layer 2
Calculation of the firing strength of a fuzzy rule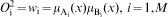
Layer 3
Calculation of the normalised firing strength of a fuzzy rule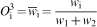
Layer 4
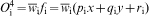
Layer 5
Calculation of overall output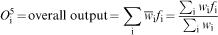
Model reduction using singular value decomposition (SVD)
It is a fact that an increase in the number of fuzzy rules in the rule base increases the model complexity, and the model becomes more specific to the training data set. However, the model becomes incapable of predicting the untrained (test) data set due to poor generalisation. In this work, the SVD technique18, 19 has been employed to select the optimum number of fuzzy rules from a given rule base. Subsequently, QR with a column pivoting factorisation algorithm has been applied to select the most important fuzzy rules that are contributing a higher extent to model prediction.
Results and discussion
The first part of this section involves the multivariable linear regression of the coal blend properties with coke CSR. The next section shows the ANFIS model performance in CSR prediction before and after model reduction using SVD. In addition, simulation experiments are conducted to study the effect of various combinations and numbers of input variables (i.e. coal blend properties) on the coke CSR using ANFIS. Statistical indices like correlation coefficient R 2, root mean square error (RMSE) and standard deviation have been used to quantify the model performance.
Multivariable linear regression
In this section, using the Levenberg–Marquardt method, seven input variables such as ash, VM, Ro, TR, V
9–V
13, CSN and BI have been correlated with coke CSR. In this case, the normalised data sets have been used in order to study the extent of contribution of each input variable in predicting the CSR. The resultant linear relation between the input and output variables is shown in the following equation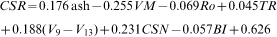
Input variables sorted in descending order of contribution towards CSR prediction
Furthermore, equation (7) shows the correlation of CSR with input variables for the original data (i.e. not normalised) set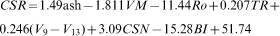
The scatter plot in Fig. 3 presents the comparison of model CSR estimated from equation (7) against the experimentally measured CSR. The normal distribution of difference between experimental CSR and predicted CSR from equation (7) is shown in Fig. 4.
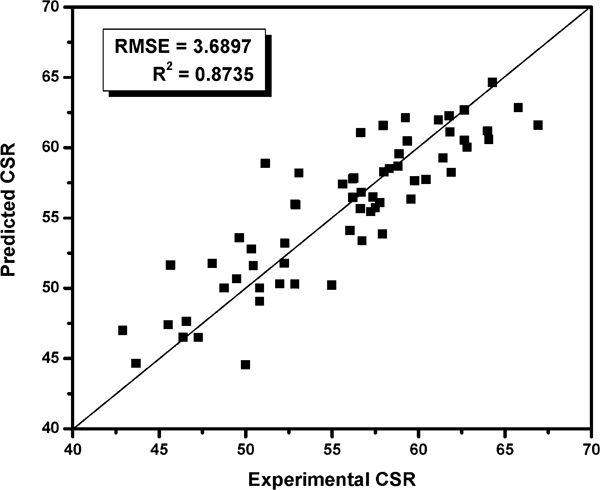
Comparison of CSR measured against CSR estimated through multivariable regression equation (7)
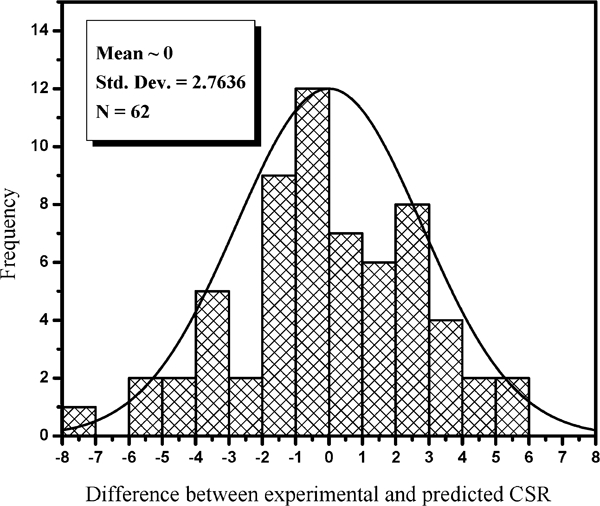
Normal distribution of difference between experimentally measured CSR and estimated CSR from multivariable regression analysis
Adaptive neurofuzzy inference system
Naturally, the ANFIS model is capable of mapping the highly non-linear functionality between input and output variables. However, special care needs to be taken in order to fix the number of fuzzy rules and the number of input variables. First, the SVD and QR factorisation methods have been employed to remove the redundant fuzzy rules and to retain the minimum number of fuzzy rules that have higher contribution in estimating the output. Moreover, it is also important to have as minimum as possible number of input variables in the model in order to reduce the model complexity and to increase the generalisation capability of the model. In this connection, based on the multivariable regression results (see Table 2) and self-intuition, three different input sets [model a: VM, CSN, V 9–V 13 distribution and ash content (i.e. first four most influencing inputs variables); model b: VM, CSN, V 9–V 13 distribution, ash content and Ro (i.e. first five most influencing inputs variables); and model c: all seven coal blend properties] have been formulated to predict coke CSR (Table 3). In this work, the sigmoidal function has been chosen as a membership function after studying the performance of the model with bell shape and Gaussian membership functions.
Input sets for ANFIS model prediction
Selection of fuzzy rules
In this section, model a is trained and tested with five numbers of fuzzy rules. Subsequently, the singular values of firing strength matrix are estimated using the SVD method, as tabulated in Table 4. From the singular values, it is identified that three numbers of rules itself can constitute a model with significant accuracy. Since the SVD method always gives the singular values in descending order, the QR method is further employed to position the best three numbers of rules in the rule base. The permutation matrix generated using the QR method is shown in Table 5. From the matrix, it is observed that fuzzy rules 2, 3 and 4 occupy the first three places. Then, the model is formulated with this reduced number of rules and again further fine tuned for best test set performance. The performance of model a in the prediction of CSR before and after model reduction is shown in Table 6. It is interesting to note from Table 6 that after model reduction, the test set performance (in terms of RMSE and R 2) improves, whereas the training set performance declines compared to the original rule base. It clearly shows that the generalisation capability of the model improves after model reduction. The similar model reduction procedure is also applied for models b and c.
Singular values of firing strength matrix for model a
Permutation matrix formulated using QR method for model a
Effect of model reduction on model performance for CSR prediction
Prediction of CSR
After applying model reduction, the ANFIS performance in the prediction of CSR for models a–c is presented in Fig. 5, and the corresponding statistical performance indices are listed in Table 7. The training of ANFIS is stopped at the epoch, in which the best performance of the test set is achieved. The RMSEs for models a–c are 2·1077, 2·6902 and 2·3653 respectively. The R 2 obtained for models a–c are 0·9349, 0·8896 and 0·9222 respectively. It is observed from the results that model a, which included only four inputs, performs better than model c, which included all the seven input variables. It can be inferred that due to the less number of input variables, thereby less complex structure, model a performs better than models b and c. However, the same trend is not observed when comparing the performance of models b and c. It can be due to the fact that the average reflectance Ro provides also the same information as that of vitrinite distribution V 9–V 13, and hence, it becomes a redundant input variable. Therefore, the addition of Ro only adds the model complexity without increasing the prediction capability of the model.
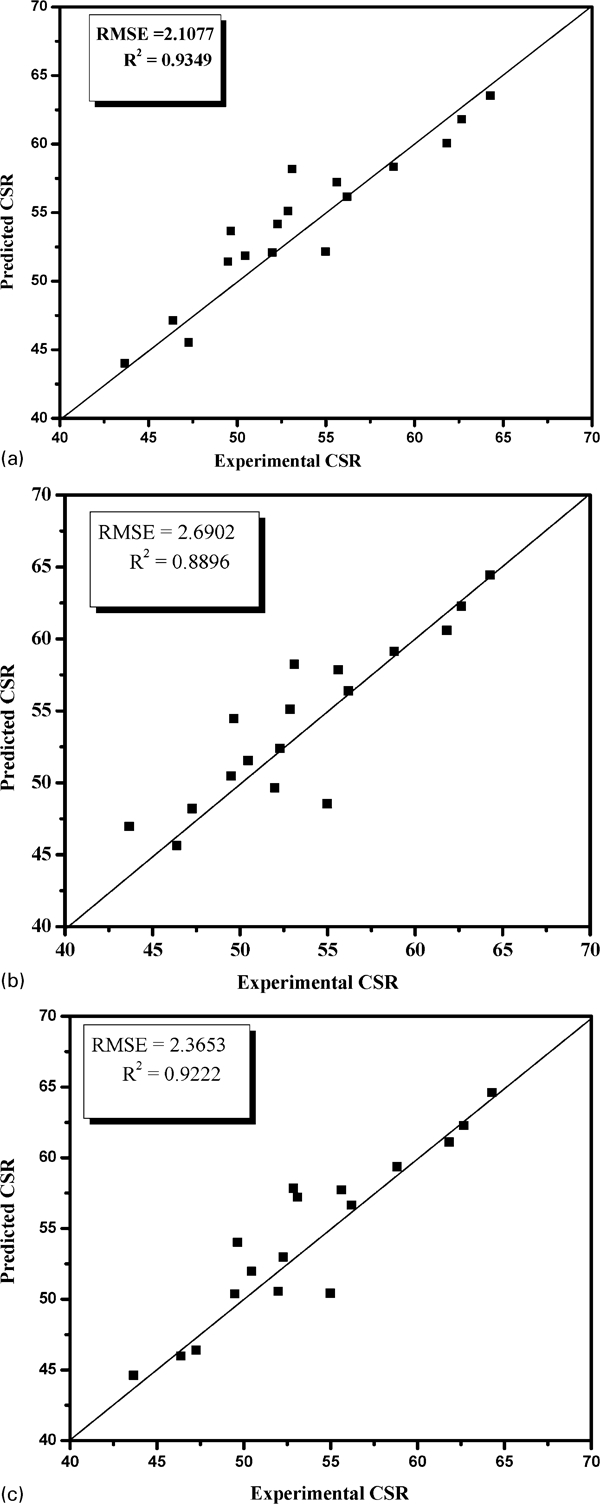
Prediction of CSR for a model a, b model b and c model c
Effect of input variables on model performance for CSR prediction
The normal distribution of difference between experimental and predicted CSR from the ANFIS model is shown in Fig. 6, and the corresponding statistical parameters, such as mean and standard deviation, are shown in Table 8. It can be concluded from the results that model a performs better than models b and c. Figure 7 shows the graphical comparison of ANFIS model performance in CSR prediction among models a–c.
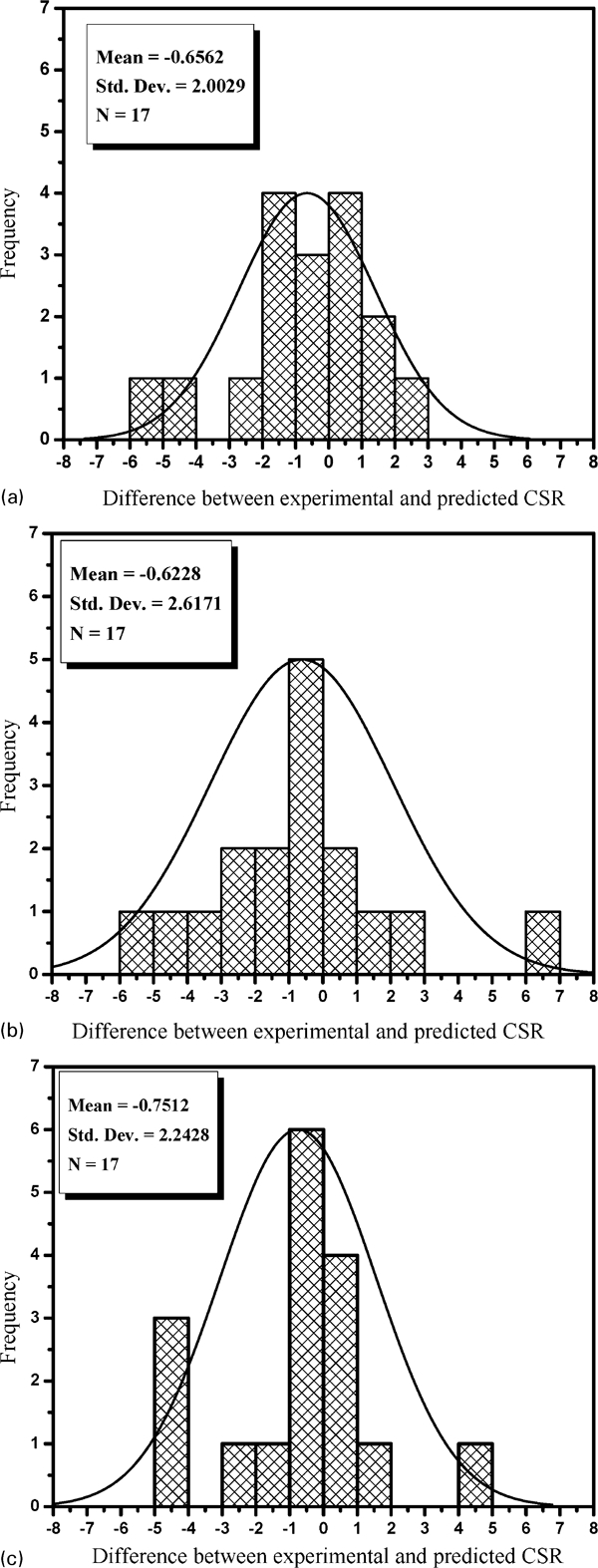
Normal distribution of difference between experimentally measured CSR and predicted CSR from ANFIS
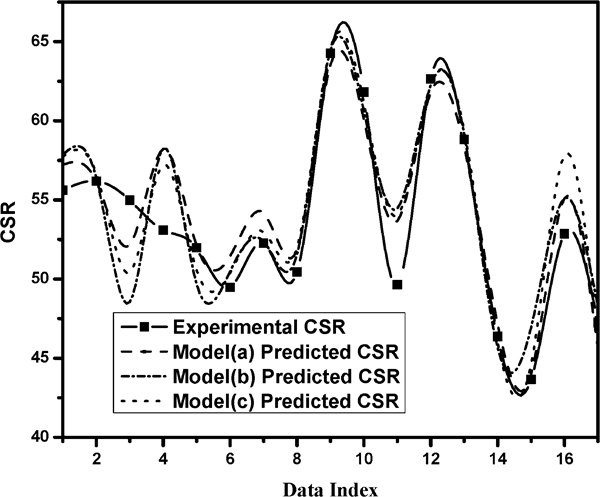
Comparison between predictions of CSR from models a–c
Statistical parameters for normal distribution of difference between experimentally measured CSR and predicted CSR by ANFIS
Conclusions
The developed ANFIS model predicts the coke CSR from the coal blend properties with reasonable accuracy when compared to the multivariable linear regression method. The ANFIS model with input variables, such as VM, CSN, V 9–V 13 distribution and ash content (i.e. model a), exhibits better prediction capability when compared to models b and c. This model can be utilised in selecting different types of coal sources for coal blending in coke making applications. In addition, the optimisation of coal blend properties for maximising the coke CSR can very well be achieved with this model. However, the developed model application is limited only for the coal from the same geographical origin and similar carbonisation conditions. Efforts can be made to extend the model to include various other coal properties and different carbonisation conditions, like bulk density, oven temperature, carbonisation time, etc., for improving the predictability.