
Abstract
Image matching plays an important role in Augmented Reality, Simultaneous Localization and Map ping (SLAM), and unmanned. The key issue of image matching is the accuracy of feature matching between adjacent images. Due to the complicated environment, matching between images through geometry feature runs into bottlenecks. In this paper, we focus on improving the accuracy of feature matching by incorporating instance-aware semantic segmentation into Oriented FAST and Rotated BRIEF (ORB) feature matching, which is broadly utilized in image registration and Visual SLAM. We segment the objects between the adjacent images on pixel level and qualify the features matching procedure using the semantic information. Experiment results show that our novel proposed method increases the accuracy of feature matching.
Introduction
Image matching is the foundation of many computer vision applications, such as Augmented Reality, Visual Odometry, Simultaneous Localization and Mapping, Object Tracking, and unmanned, etc. Augmented Reality needs to combine the virtual objects with the real one which is based on the feature matching to estimate pose of the equipment. Visual Odometry measures the distance through the visual information. Visual SLAM deals with the location issue of the moving camera and in the mean time mapping the surroundings. Object tracking detects and matches the similar features between the objects and the images. Like Self-Driving technology, visual SLAM needs to calculate the location of the car and remember the surroundings along the route. Image matching is widely used in the automatic applications.
There are some kinds of feature matching methods, such as Scale-Invariant Feature Transform (SIFT), Speeded Up Robust Features (SURF), ORB, etc. All of them have strengths and weaknesses, and they adapt to different application environment.
SIFT algorithm is one of the most famous image registration method based on features, which was first presented by Lowe [1] in the ICCV 1999 conference. It aims at detecting the invariant feature points, which also provides some message on the object recognition. In 2004, the most complete SIFT feature detector was granted by Lowe [2]. Due to the most attractive advantage on invariance to image transformation, SIFT has been widely researched in the pass few years.
Herbert et al. [3] presented SURF in 2008, which depended on Gaussian scale space analysis of images. SURF algorithm is based on the determinant of Hessian Matrix and it made use of integral images to increase feature-detection efficiency. The 64 bin descriptor of SURF describes each detected feature with a distribution of Haar wavelet responses within certain neighborhood. Features of SURF are invariant to scale and rotation but not on affine transformation. However, the SURF descriptor can be extended to 128 bin values for the larger viewpoint changes. The main ascendancy of SURF over SIFT is its low computational cost.
Rublee et al. [4] presented Oriented FAST and Rotated BRIEF (ORB) in 2011. ORB algorithm is a mixture of modified FAST (Features from Accelerated Segment Test) [5] detection and direction-normalized BRIEF (Binary Robust Independent Elementary Features) [6] description algorithm. FAST corners are detected in each layer of the scale pyramid and the detected points’ corners are assessed using Harris Corner score to filter off the top quality feature points. The BRIEF description algorithm is unstable rotation, it employed a modified version of BRIEF descriptor. ORB features are limited affine changes and invariant to rotation and scale.
Yang et al. [7] proposed a method to get high accuracy as well as maintain a good efficiency. The features are extracted in the low frequency image and matched by using the closest and the second closest neighbor feature points. Finally, RANSAC is used for refining the matching, and its performance is better than the traditional SIFT and SURF.
Sharma [8] proposed a method that using a graphics processing unit (GPU) to optimize the feature matching and He et al. [9] gave a improved SIFT algorithm by using line-scanning ophthalmoscope. There are also some other feature matching methods, such as BRISK [10], AKAZE [11], KAZE [12], S-AKAZE [13], etc. They have different performance on accuracy and efficiency. Maybe some applications should have ideal accuracy while some applications strongly demand high efficiency .
Khan and Shaharyar [14] and Hu et al. [15] had done some experiments on the comparation about the efficiency and accuracy of the state-of-the-art feature image matching algorithm . The generic order of feature-detector-descriptors for their ability to detect high quantity of features is:
The generic order of feature-detector-descriptors for their efficiency to detect features is:
It seems that high accuracy and high efficiency is difficult to coexist, it needs to choose the appropriate image matching method which is suitable to the applications.
In this article, a novel feature matching method will be presented, which combines the ORB algorithm and instance-aware semantic segmentation to achieve the compromise between accuracy and efficiency. The new attempt can also bring the semantic information of the scenes, which is significant to the approaching semantic maps.
This paper is organized as follows: Section 2 gives the overview of the algorithm. Section 3 introduces the architecture including the instance-aware semantic segmentation FCIS [16] algorithm and the traditional ORB algorithm. Section 4 shows the experiments and analysis and the final is the conclusions of this paper.
In this paper, we propose an algorithm which combines ORB feature matching and instance-aware semantic segmentation to boost the performance of image matching. With the help of instance-aware semantic segmentation, the image matching procedure is able to narrow the matching region between the adjacent images and reduce the mismatching points. Figure 1 is a brief presentation of this system.
Global structure chart of designed system.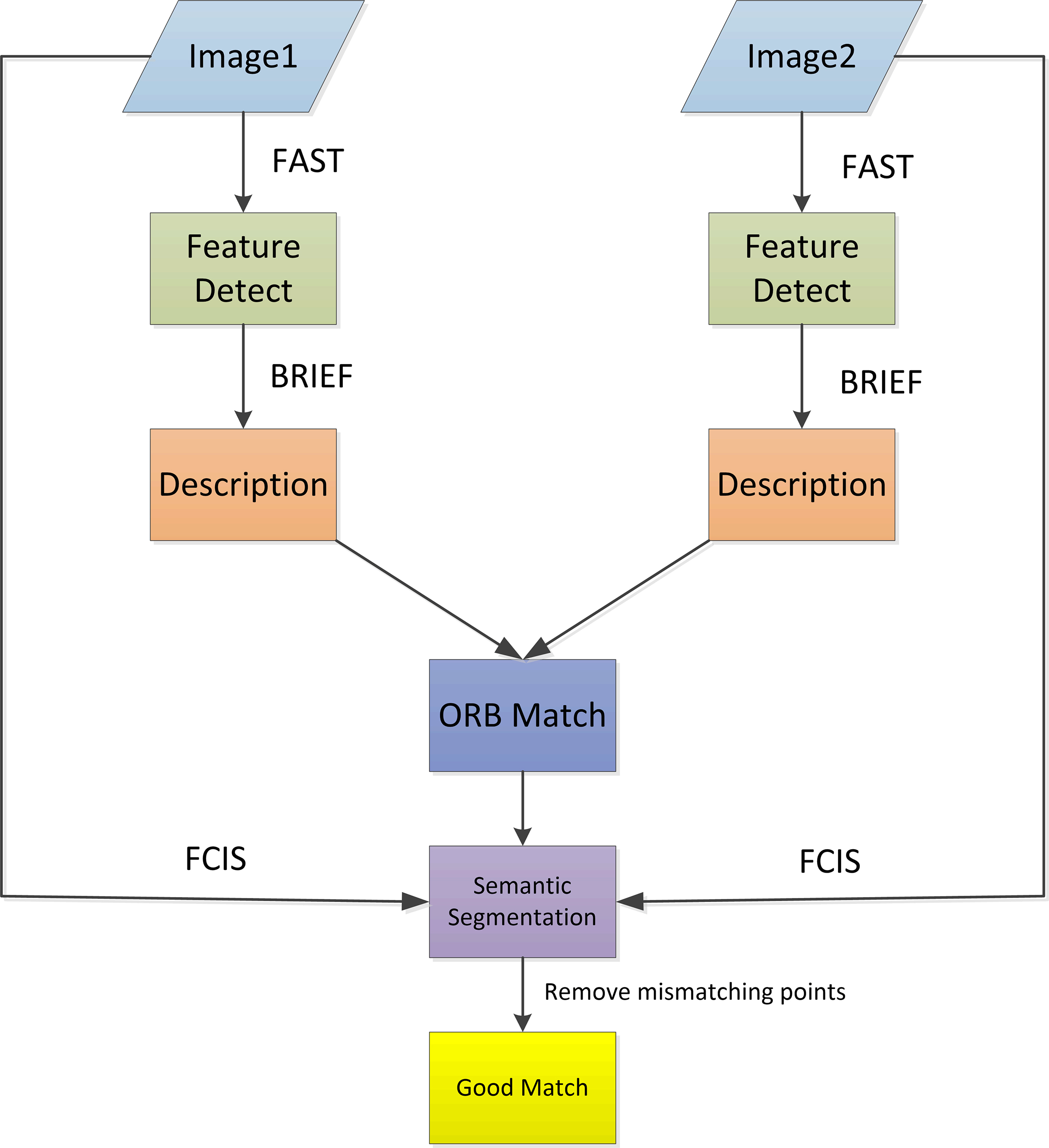
As shown in the Fig. 1, the feature points are extracted as traditional feature detector, and the feature mismatching points are reduced by adopting limited pixel region which is segmented by the FCIS (Fully Convolutional Instance-aware Semantic Segmentation) algorithm. More concretely, the matched points are not belong to the same semantic objects in the adjacent images.
Our method has two major parts, the first one is the feature matching and the other is the instance-aware semantic segmentation. In this article, Oriented FAST and rotated BRIEF is used for feature extracting and matching while the FCIS is used for instance-aware semantic segmentation. The introduction of ORB and FCIS is as follow.
ORB
Oriented FAST (features from accelerated segment test) and rotated BRIEF is a fusion of the FAST key point detector and BRIEF descriptor with some modifications which is a fast robust local feature detector. It is first presented by Rublee et al. (2011). The feature points of the image can be simply understood as the significant points, such as the corner points, the light points in dark and the dark points in light, etc. To extract the feature points, it uses FAST which is based on the gray value around the feature points, if there are enough pixels around the candidate point which gray value is differ greatly, it is confirmed as a feature point. It is a summary in Eq. (3).
In Eq. (3),
To achieve better performance, there are some skills to shorter the detecting time. There should be at least 3 points’ gray value large enough to the 4 tested points at every 90 degree angle around the candidate points, or it is not the feature point. That is FAST – N and N is determined by how many pixel on circumference to compare and we choose FAST – 12 in this paper, as is shown in Fig. 2.
Schematic of ORB feature extraction.
FAST does not calculate the orientation and it is rotation variant. Direction of the vector from the corner point to centroid gives the orientation. Moments are computed to improve the rotation invariance. ORB uses BRIEF as the descriptor. In ORB, the matrix of rotation is computed by the orientation of patch and then the BRIEF descriptors are steered according to the orientation.
Because of its fast feature detection and matching, ORB is widely applied in computer vision tasks like visual SLAM (ORB-SLAM2 [17]), object recognition, Augmented Reality, 3D reconstruction and unmanned.
The main idea of our research is to narrow the feature matching pixel region by segment the image with semantic information. With the rapid development of deep learning, there are many outstanding semantic segmentation algorithm and the performance of classify and segmentation is getting better and better. Because our goal is to reduce the mismatching between different object in images, we employ the algorithm FCIS to segmented the pictures in pixel level, which is presented by Yi in CVPR 2017. They first proposed the end-to-end fully convolutional method for instance-aware semantic segmentation and examination shows that the approach is state-of-the-art for object mask proposal task. The system framework of FCIS is shown in Fig. 3.
System Framework of FCIS [16].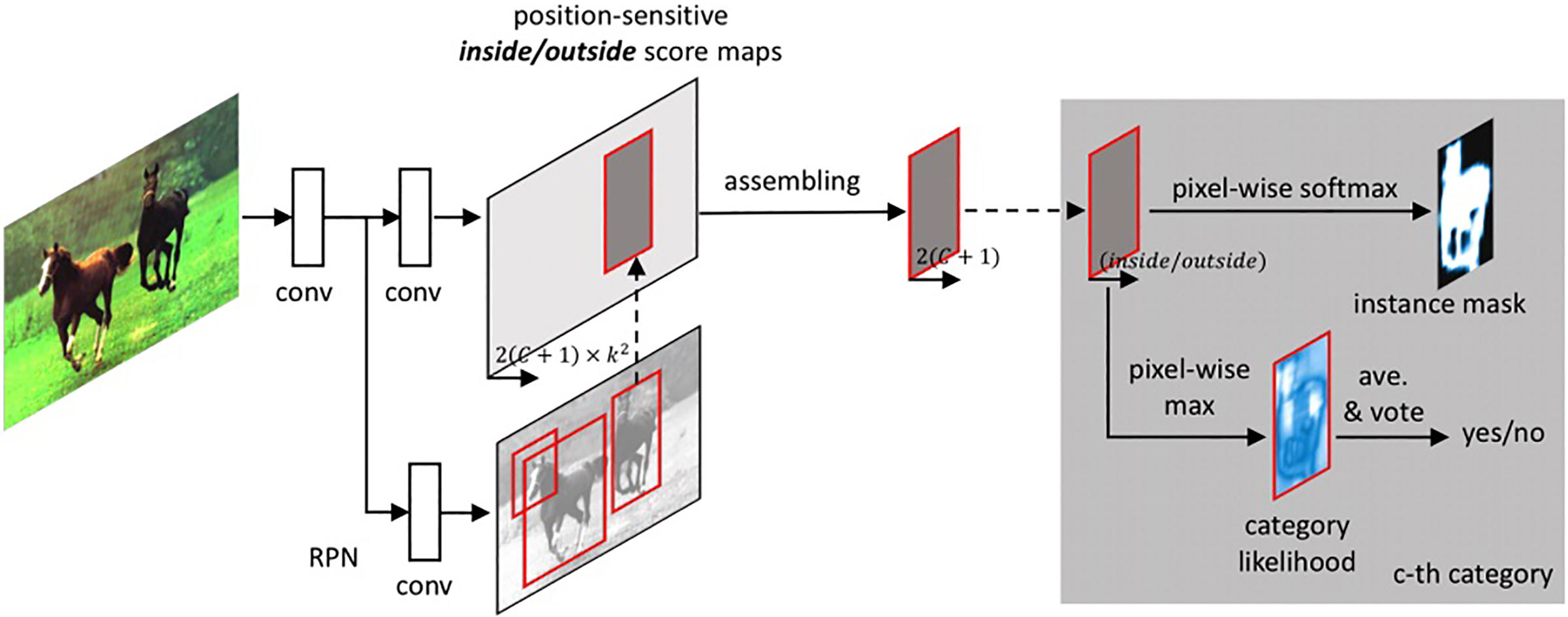
There is a region proposal network (RPN) [18] which shares the maps of convolutional feature with FCIS. And the region-of-interests (ROIs) proposed by the RPN are applied on the score maps for combining the instance mask prediction and object classification. The learnable weight layers are fully convolutional and computed on the whole image. The pre-ROI computation cost is negligible. Yi’s method proposed the position-sensitive inside/outside score maps which is used to perform semantic segmentation and instance classification. The inside is used to extract the features of the objects and segments objects while outside applies feature outside the objects, and picks the max value of each pixel and judge the category of objects by mean voting. The performance of segmentation and object classification is as Fig. 4 shows.
It is excellent and its algorithm won the first place with a significant advantage in the COCO 2016 split contest. The source code of FCIS is put on the “Github” by the author for free download, and we modify the source code to adapt our ORB algorithm based on semantic segmentation. It is mainly based on the following Eq. (4).
Where vector
In this section, the performance of semantic segmentation based Oriented FAST and rotated BRIEF is given and experimental results are presented under some pairs of images. Images for experiment are picked from KITTI Dataset [19], TUM Dataset [20] and NYUv2 Dataset [21] which are widely applied for visual SLAM and semantic segmentation. The performance results are implemented on Intel(R) Core(TM) i7 CPU and NVIDIA’s GeForce1070 with Ubuntu16.04 LTE. The FCIS is based on GPU using CUDA-9.1 SDK.
Quantitative comparison of feature matching with/without FCIS – The first image pair
Quantitative comparison of feature matching with/without FCIS – The first image pair
The semantic segmentation performance of FCIS.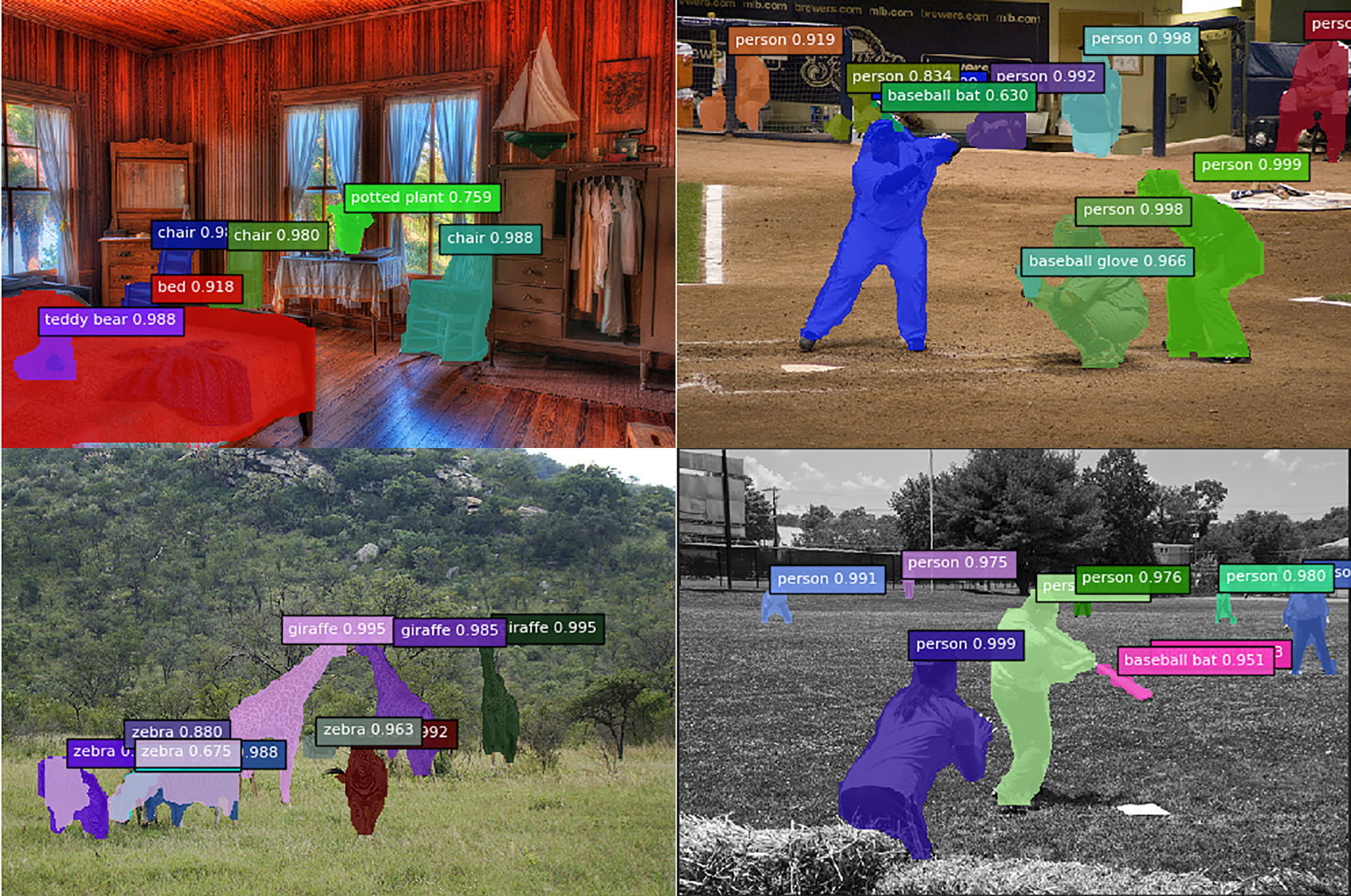
There are 5 couple images for testing our algorithm. Firstly, the pictures is segmented using FCIS algorithm, the object categories and the pixel region are also obtained. Secondly, ORB algorithm is applied to extract the image features and the BRIEF descriptors are computed. Finally, the feature points are matched under related pixel region in the images of related object categories. Examination shows that the mismatching ration can be reduced by narrowing the matching region. The performance of instance-aware semantic segmentation is shown Fig. 5. The first column and the third column are the origin adjacent images, and the second and fourth columns are the result of semantic segmentation with FCIS. Different color represents different instances, it obviously shows that the pixel-wise segmentation is excellent. Besides, there are some objects which can not be identified, so the performance of semantic based feature matching will be optimized with the progress of semantic segmentation algorithm.
Figure 6 shows the feature matching result which is matching without FCIS on the left column and matching with FCIS on the right column. We utilize OPENCV 3.20 SDK for ORB feature extracting and BRIEF descriptors. When matching without FICS, the matching points, whose matching distance is greater than 3 times minimal distance, are removed to reduce mismatching preliminarily. When matching with FCIS, ORB algorithm of OPENCV is used to extract feature points and compute descriptors which is similar to matching without FCIS. However, when it matches with adjacent images, it should compare the matched feature points which are in the same object categories by the RGB value. The same objects have the same color as the code of mask showing of FCIS is modified.
Quantitative comparison of feature matching with/without FCIS – The second image pair
The performance of instance-aware semantic segmentation.
Quantitative comparison of feature matching with/without FCIS – The third image pair
Quantitative comparison of feature matching with/without FCIS – The fourth image pair
Quantitative comparison of feature matching with/without FCIS – The fifth image pair
Feature matching results.
In the pictures of matching result, the matched features of adjacent images are connected with lines, it shows that the matched images of matching with FCIS is a little more sparse than that of matching without FCIS. There are some tables to illustrate the quantitative evaluation between them. Table 1 is the first pair of adjacent images, Table 2 is the second pair of adjacent images, Table 3 is the third pair of adjacent images, Table 4 is the fourth pair of adjacent images, Table 5 is the fifth pair of adjacent images. Under the same conditions, the RANSAC algorithm is as a criterion for judgment which computes the inliers points and counts each pairs images’ inliers ratio.
Because we apply the same ORB algorithm in OPENCV to extract feature points in both algorithm with and without FCIS, the numbers of “AllDetectPoints” are the same. The “FeatureMatchedPoints” of method with FCIS is a bit more less than method without FCIS while the “InliersRatio” are in contrast. This means that the proposed method that instance-aware semantic segmentation based ORB has better results. Experiment result shows that the feature matching with semantic segmentation has a better accuracy than the traditional one, regrettably, it costs a little more times. However, in some case, applications pay more attention on accuracy rather than efficiency likes 3D reconstruction of Augmented reality. Our method provides the more accuracy location information and in the mean time, it offers the meaningful semantic surroundings which is significant to the construction of semantic maps in the feature.
In this article, we present a novel method to improve the accuracy of feature matching by combining instance-aware semantic segmentation with ORB, the feature matching is limited to the pixel region of the same objects in the adjacent images which reduces the mismatching points. Experiment results show that the novel method increases the matching accuracy. There is no doubt that, the ability of semantic segmentation still has room for improvement. With the rapid development of deep learning and the hardware computing power, semantic segmentation and feature matching may have a breakthrough and semantic SLAM will come true which helps to strengthen the human-computer interaction of AR, and self-driving, etc.
In this article, we present a novel method to improve the accuracy of feature matching by combining instance-aware semantic segmentation with ORB, the feature matching is limited to the pixel region of the same objects in the adjacent images which reduces the mismatching points. Experiment results show that the novel method increases the matching accuracy. There is no doubt that, the ability of semantic segmentation still has room for improvement. With the rapid development of deep learning and the hardware computing power, semantic segmentation and feature matching may have a breakthrough and semantic SLAM will come true which helps to strengthen the human-computer interaction of AR, and self-driving, etc.
Footnotes
Acknowledgments
This work was supported by the Science and Technology Project of Guangdong (No. 2016A040403 108) and the Science and Technology Project of Guangzhou (No. 201704020110).