
Abstract
In the intelligent age, computers are required to help people complete simple daily work. Among them, computer voice databases and systems occupy a very important position in the field due to their wide application. In order to optimize the system design method, the application of IGA algorithm is proposed, and the performance of the model under the algorithm is compared and tested. The algorithm experiment shows that when the IGA objective function value is 34.4, there is no change, and the number of iterations is 100; Compared with the traditional genetic algorithm, the value of the optimal solution is always the minimum. Then the error of the optimal solution under different algorithms is compared and analyzed. It is found that the error of the optimal solution under IGA operation has the minimum value of 0.0079; The experiment of speech recognition efficiency shows that the speech recognition rate under the intervention of IGA algorithm has increased by 8%, and the overall efficiency is higher than 95%. It can be seen from the above results that IGA is helpful to the acquisition of voice database data, and improves the recognition efficiency. The feasibility of the method is high, which is of great significance to the development of China’s intelligent system industry. But at present, the overall progress of the voice system is still limited, so expanding research methods to apply to the field of voice system is still the next research direction that can be explored.
Introduction
In recent years, the development of technology has led to the development of human-computer interaction [1]. The use of computers to use speech signals to convey information is one of the ways in which humans carry out the communication of ideas and feelings [2]. However, the recognition rate of speech signals is always neglected or underestimated when data are collated and collected in traditional speech database system design, and the factors affecting him are not fully explored [3]. In order to solve the problems that may be encountered in the design of speech database systems and the current status of the problem of speech database recognition rate, a series of institutional and policy measures have been taken in China [4]. The study proposes a method for designing a speech database system based on an improved genetic algorithm, and experiments and results are analyzed to combine the characteristics of the algorithm for optimal design of the speech database in response to the lack of search capability of the traditional genetic algorithm and the lack of finding optimal parameters when many data are available. The speech database proposed in the study can extend the sources of speech information and improve the efficiency of speech recognition and synthesis system construction. And at the same time improved genetic algorithms are entering the field of computer science and technology as a new research method to help the design of speech databases and the improvement of recognition rate [5].
Related works
With the development of computer science and the information society, the ideal of a more natural interaction of humans and machines together is becoming more and more urgent to be realized. Dawid and Kopel [6] used genetic algorithms (GAs) to simulate the learning behavior of a population of interacting adaptive and finite rational subjects in an economic system. Simulations of different coding schemes are presented and the surprising differences between the results of different settings, and also the relationship between coding and genetic algorithm convergence, are explained by using a mathematical theory of gases with state-dependent fitness functions. Rovithakis et al. [7] proposed a hybrid neural network/genetic algorithm technique that aims to design a feature extractor that produces highly differentiable classes in the feature space. The application on which the system is based is to identify the state of human peripheral vascular tissue (i.e. normal, fibrous and calcified). To distinguish normal cells from those affected by acute lymphoblastic leukemia, the system was further tested on spectral classification of cells measured from nuclei in blood samples. Chen [8] proposed an improved genetic algorithm based solution to the green cold chain logistics site selection path optimization problem to urgently improve the distribution efficiency and cost of fresh produce cold chain logistics from a low carbon and environmental perspective. The research content uses actual cold chain logistics and distribution data, and the proposed method is validated based on Matlab platform. The final results were obtained to effectively accelerate the convergence speed, reduce the distribution cost and achieve low carbon economy. Zou et al. [9] crowd proposed an improved genetic algorithm (IGA-NCM) using novel crossover and variation to solve the cogeneration economic dispatch problem. The basic genetic algorithm (GA) was enhanced in three aspects. And a new constraint handling method is proposed to fix the variant offspring to make it easier to enter the feasible domain. Experimental results show that the proposed IGA-NCM algorithm outperforms other algorithms in terms of computational accuracy and running time, which means it is a potential alternative to the CHPED problem with or without the forbidden operation area. Yin et al. [10] proposed a microblog opinion prediction method based on the proposed improved genetic algorithm based IGABP algorithm under to deal with the large amount of data generated by registered users of microblogging platforms, and it is urgent to use genetic algorithms to overcome the problems of BP algorithm’s vulnerability to initial weights and slow convergence speed. The metropolitan acceptance criterion is used to improve the local search capability of the genetic algorithm. The effectiveness of the IGABP algorithm is verified by extracting and normalizing the microblogging data. The experimental results show that the IGABP algorithm is feasible in microblog opinion prediction with better generalization ability and higher accuracy rate.
Zhang et al. [11] used an improved genetic algorithm to introduce transportation time and processing time as independent times into the flexible job shop scheduling problem to establish a mathematical model of the flexible job shop scheduling problem with transportation time. The improved genetic algorithm is then used to solve the optimal value. In the decoding process, the operation left shift insertion method is proposed to decode the chromosome according to the problem characteristics to obtain the active scheduling solution. The actual arithmetic cases were solved by adding Matlab software. In order to study the behavior of economic chaos dynamics, instead proposed a method that combines the decision tree model optimized by improved genetic algorithm and BP neural network model to solve the problem of large number of small samples of economic chaos generated in real production activities [12]. The rough prediction is achieved by prioritizing features through decision tree classification, and then the combined model under BP neural network algorithm is optimized using genetic algorithm, which can effectively improve the model fitting ability. Chen and Gao [13] proposed to apply genetic algorithm to the robot route planning in football field in view of the changes in the competition form of the football field, so as to realize the path with shorter time and shorter distance to achieve the ultimate goal. Based on the comparison with other algorithms, an adaptive genetic algorithm is proposed, which innovatively changes the crossover probability and mutation probability in the operation process. It can effectively save individuals, improve the convergence speed, and obtain the optimal individuals under the same conditions and backgrounds. The final result also proves that the path under the genetic algorithm can achieve the goal. Zhang and Zhuan [14] proposed an improved genetic algorithm based on a variable chromosome length coevolutionary approach to improve the vibration isolation performance of a parallel electromagnetic vibration isolation system. The two problems of reducing the parametric trial and error of the Q and R matrices in the control objective function as well as solving the computationally intensive problem in the model predictive control method. In the study, a parallel electromagnetic isolation system with two electromagnetic isolation units was designed and the dynamics equations and state equations of the parallel electromagnetic isolation system were established, which finally showed that the vibration isolation performance obtained by the method was good. Zhao et al. [15] proposed to use genetic algorithm to determine the optimal current consumption and control gain for motor current determination. This ensures the overall operation of the machine. The simulation results show that the proposed control strategy can improve the performance of the controller under different conditions. And it can achieve the goal of high efficiency and low cost.
The research on genetic algorithms and improved genetic algorithms by domestic and foreign scholars shows that there are many studies on the use of improved genetic algorithms for agricultural crops, transportation systems and electric power systems, etc., but there are few studies on speech data systems and computer databases. Therefore, this study focuses on adding improved genetic algorithms to speech data systems and computer databases to investigate the contribution to the design of computer databases.
Improved genetic algorithm for voice database system design
Initial framework of speech system and improvement of genetic algorithm
The speech database system in the study was designed using C/S architecture, which decomposes the software task into Client (Client) and Server (Server) [16]. The speech system as a whole as a computer application is able to be divided into three parts, which are composed of three structures: visual layer, logical layer and data layer. The system architecture diagram is shown in Fig. 1.
System architecture.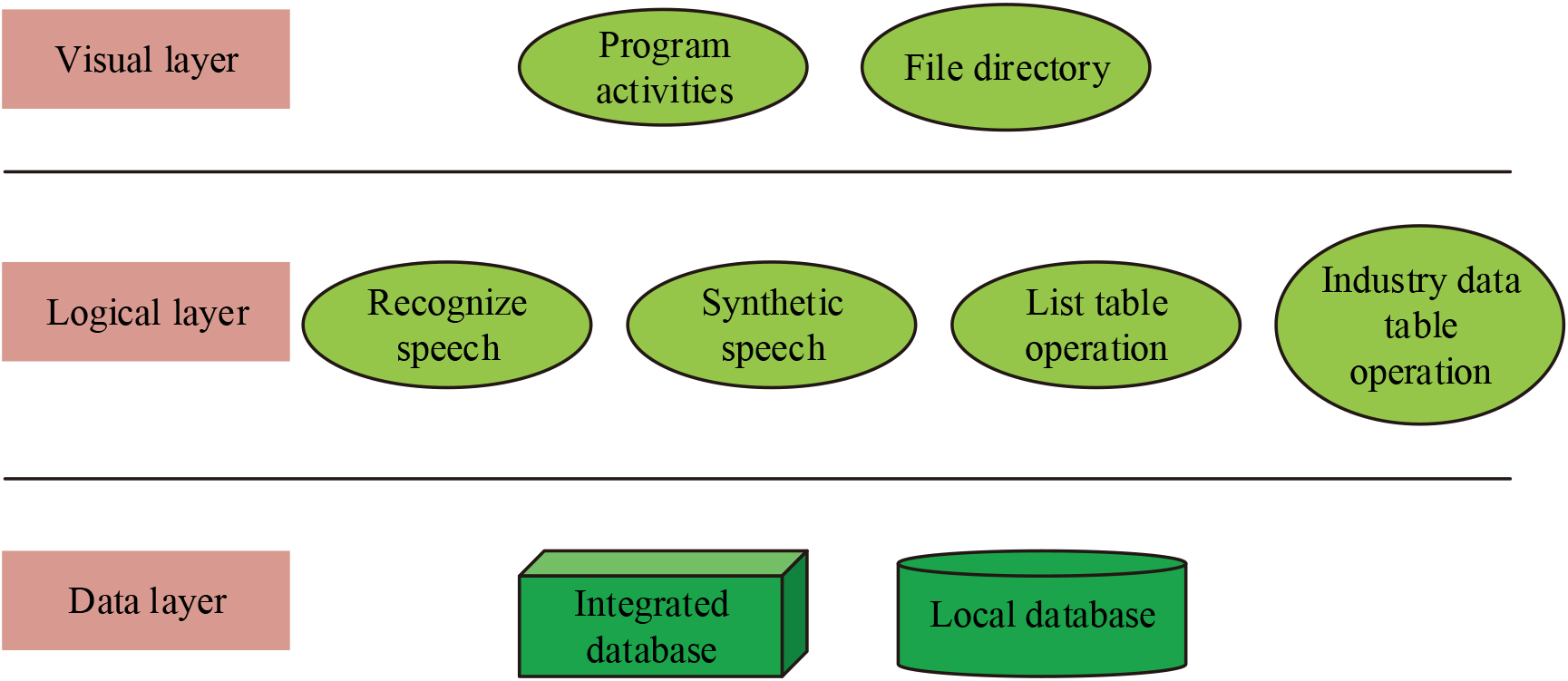
As can be seen in Fig. 1, the visual layer is mainly composed of two parts: the program activity and the file directory, and the Activity component is controlled using the coding program; the logic layer provides the functional modules required by the system, mainly composed of speech recognition, speech synthesis, table list operation and industry data table operation, where the logic plays a major role in this step; finally, the data level is reached, composed of the integrated speech The final data level is composed of the integrated speech database and the local database and realize the operation. The design of the database system is extremely important in the whole speech system design process, which determines the administrator’s perspective in designing the database and also determines the user’s usage of the data system. The specific database framework relationship diagram is shown in Fig. 2.
Database framework diagram.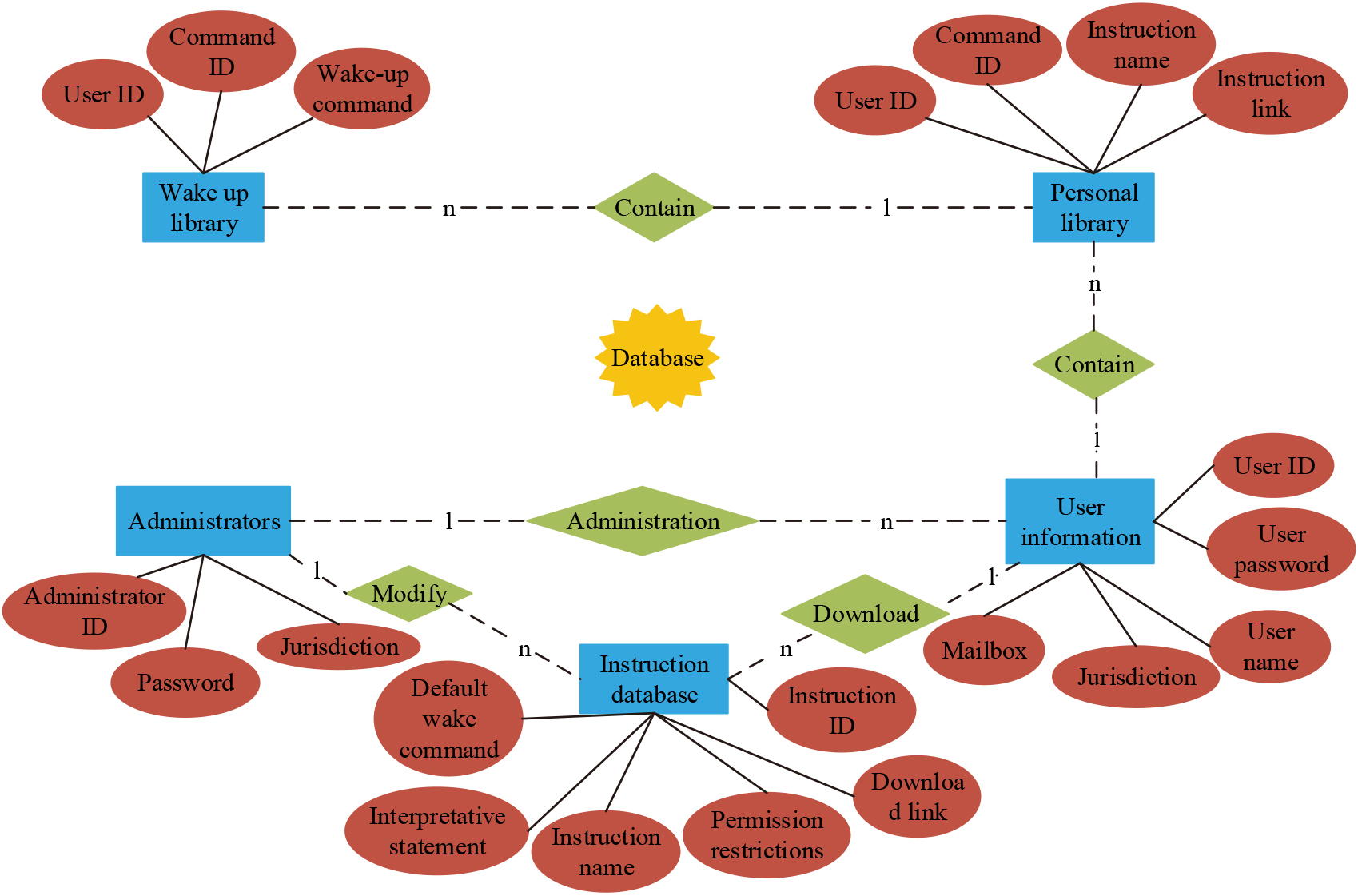
In Fig. 2, it is found that the personal library, wakeup library, user information, administrator and command library together form and manage the framework and relationship affecting the database. User ID, user password, user name, permission and mailbox together constitute user information; administrator manages user information through ID, password and management permission; user can use the link to download the information in the command library, and administrator can also modify the commands in the command library through permission, and each command is interlocked to realize the operation. The implementation of the operation must depend on the support of computer algorithms.
The basic operations of traditional genetic algorithms have the following key steps: initialization, individual evaluation, selection operation, crossover operation, variation operation, and termination condition judgment. There are also many biological concepts such as chromosomes, genes, populations and fitness [17]. Among them, chromosome can be seen as a whole symbolic code and its biological concept is shown in Eq. (1).
In Eq. (1),
In Eq. (2),
In Eq. (3),
In Eqs (4) and (5),
Variation probability
In Eqs (6) and (7),
Variation probability
In Eqs (8) and (9),
In Eq. (10),
In Eq. (11),
In Eq. (12),
Genetic algorithms operate by crossover operators in order to maintain the diversity of the population and care should be taken when designing crossover operators: the new genetic information generated should be able to retain well the dominant genes of both parents [18]. Considering the case where the parents are consanguineous, SEC crossover was chosen for the study, the difference of this algorithm is that only the chromosome is selected on
In Eq. (13),
Variation operation.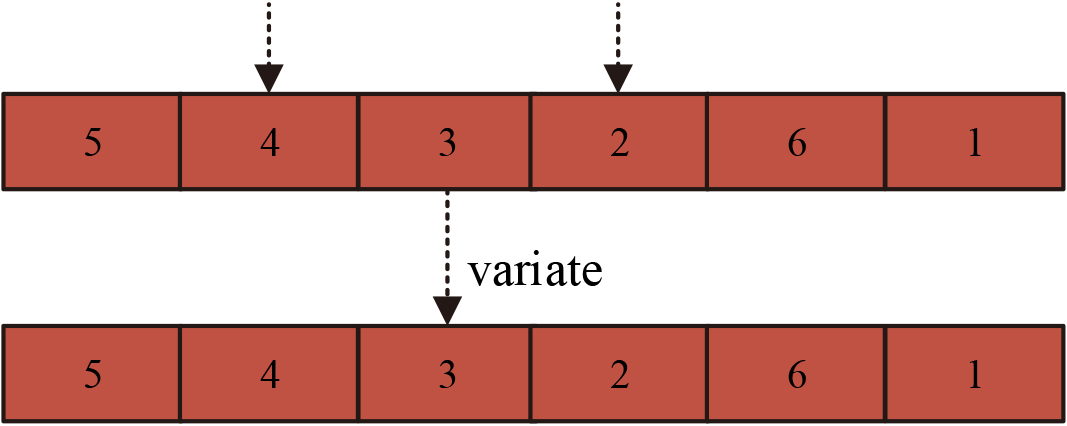
In Fig. 3, the chromosome fragment is changed by mutation. During the mutation process it is not clear whether the mutation result is better compared to the previous one, so it is necessary to compare the size of the adaptation of the chromosome after the mutation with that before the mutation, and if the former adaptation is greater than the latter, the mutation has to be abandoned, and the opposite is accepted. The speed of convergence was found to increase significantly after adding the operational judgment.
After years of development genetic algorithm has matured and has become a popular research direction in important disciplines such as computer science, information science, etc. The operation steps of the final improved genetic algorithm are illustrated in Fig. 4.
Improve the operation process of genetic algorithm.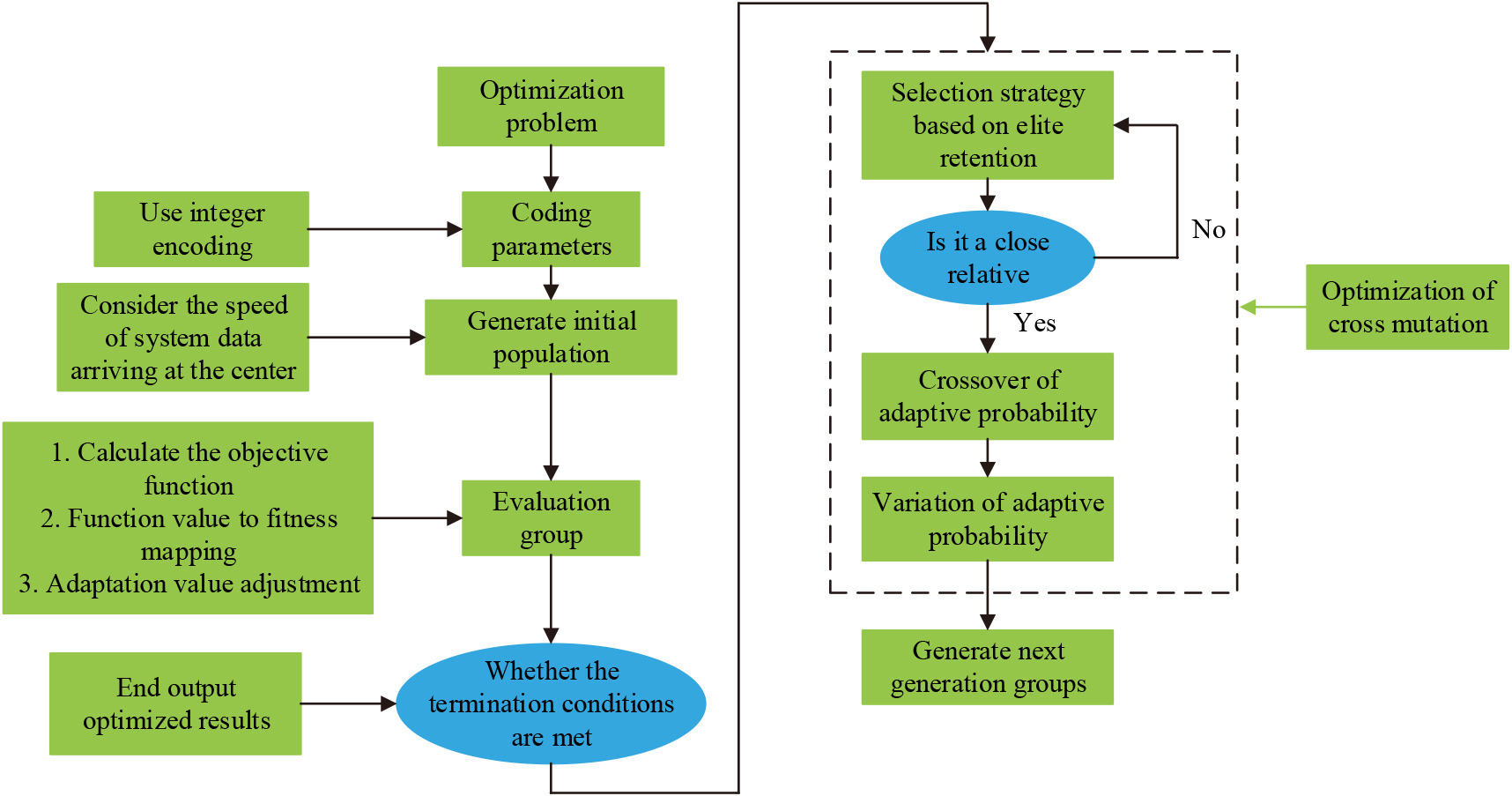
As can be seen in Fig. 4, the basic step of the improved genetic algorithm has the optimization problem and encodes the parameters after the population initialization, by evaluating the individuals to see if they meet the termination conditions, using the elite retention strategy to select the best individuals, and so on and so forth, and finally get the optimal solution under the algorithm. Recognition techniques are used throughout the design of speech databases, and researchers have long studied recognition techniques for speech data systems, although in open environments with clouds of noise, the effect of noise always leads to a significant reduction in recognition rates [19]. For this reason, the study applied the improved genetic algorithm in HMM model training and used the Empirical Model Decomposition (EMD) based EEMD and CEEMD models, which are urgently needed to improve the speech recognition rate and establish the speech data system. The overall design block diagram of the recognition system is shown in Fig. 5.
System design framework.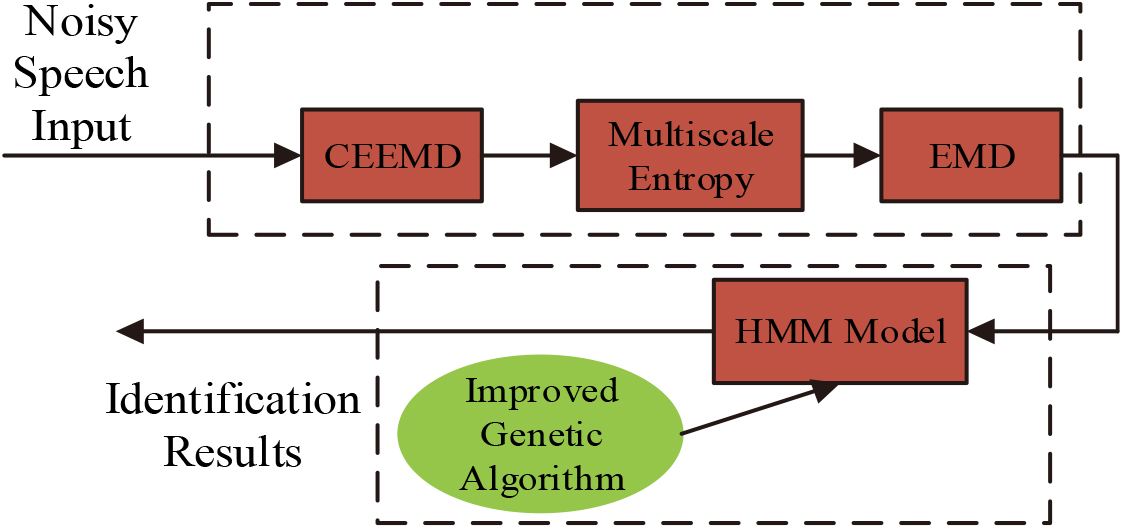
As can be seen in Fig. 5, after the system acquires the speech signal, it first uses CEEMD for modal decomposition, and then uses MSE for signal randomness detection, and after detecting the abnormal components, it separates them from the original signal and performs EMD decomposition on the remaining signal to obtain a nearly pure speech signal. This speech signal is used as the input of the HMM model, and during the training process, the improved genetic algorithm is introduced into the reconstruction of the model parameters, and the revaluated model is used to match the model of the unknown speech to achieve the purpose of speech recognition. Among them, multi-scale entropy is a method that can analyze the complexity of the signal. Using this method to build a new coarse-grained vector based on the original signal sequence is shown in Eq. (14).
In Eq. (14),
In Eq. (15),
HMM frame diagram based on Improved Genetic Algorithm.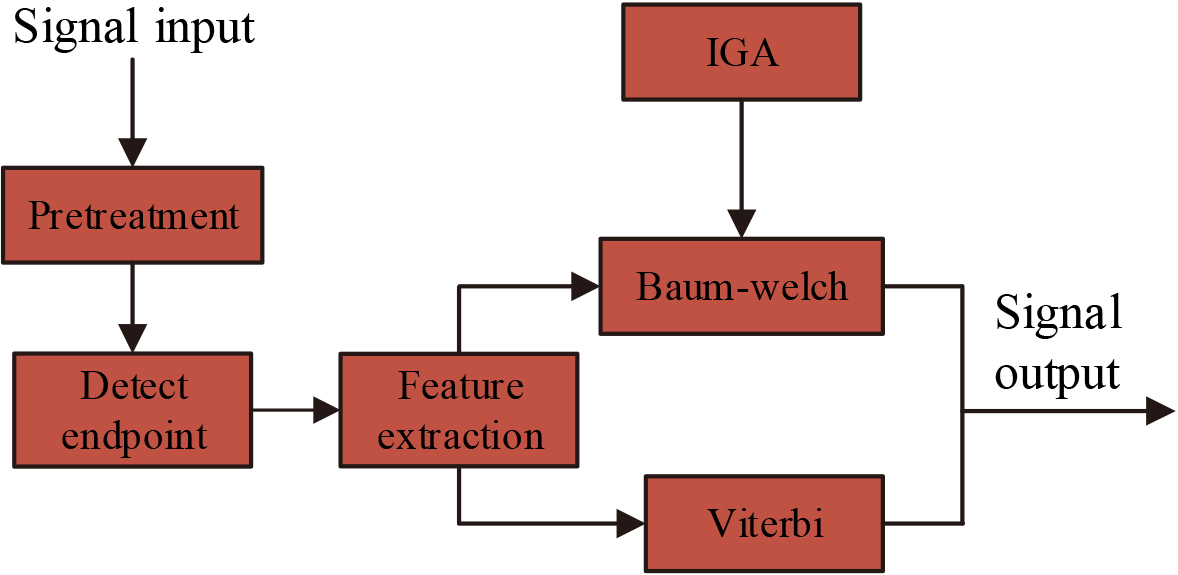
In Fig. 6, the input signal must first be pre-processed before the signal, that is, framed; the method of detecting endpoints is used to extract the effective part of the speech; and the large amount of information is analyzed and processed for the speech signal to select the useful information. The improved genetic algorithm is used in the training process to reconstruct the model parameters, combining different known and unknown conditions with different model parameters, and studying the use of the Wetherby algorithm to solve the decoding problem and the Baum-welch algorithm to solve the training problem.
Comparative analysis of optimal solutions based on IGA
After determining the value of the fitness function, the improved genetic algorithm was compared with Neural network algorithm, fuzzy neural network algorithm and Traditional genetic algorithm for optimal solution [20]. The fitness evolutionary objective curve is shown in Fig. 7.
Fitness evolution target curve.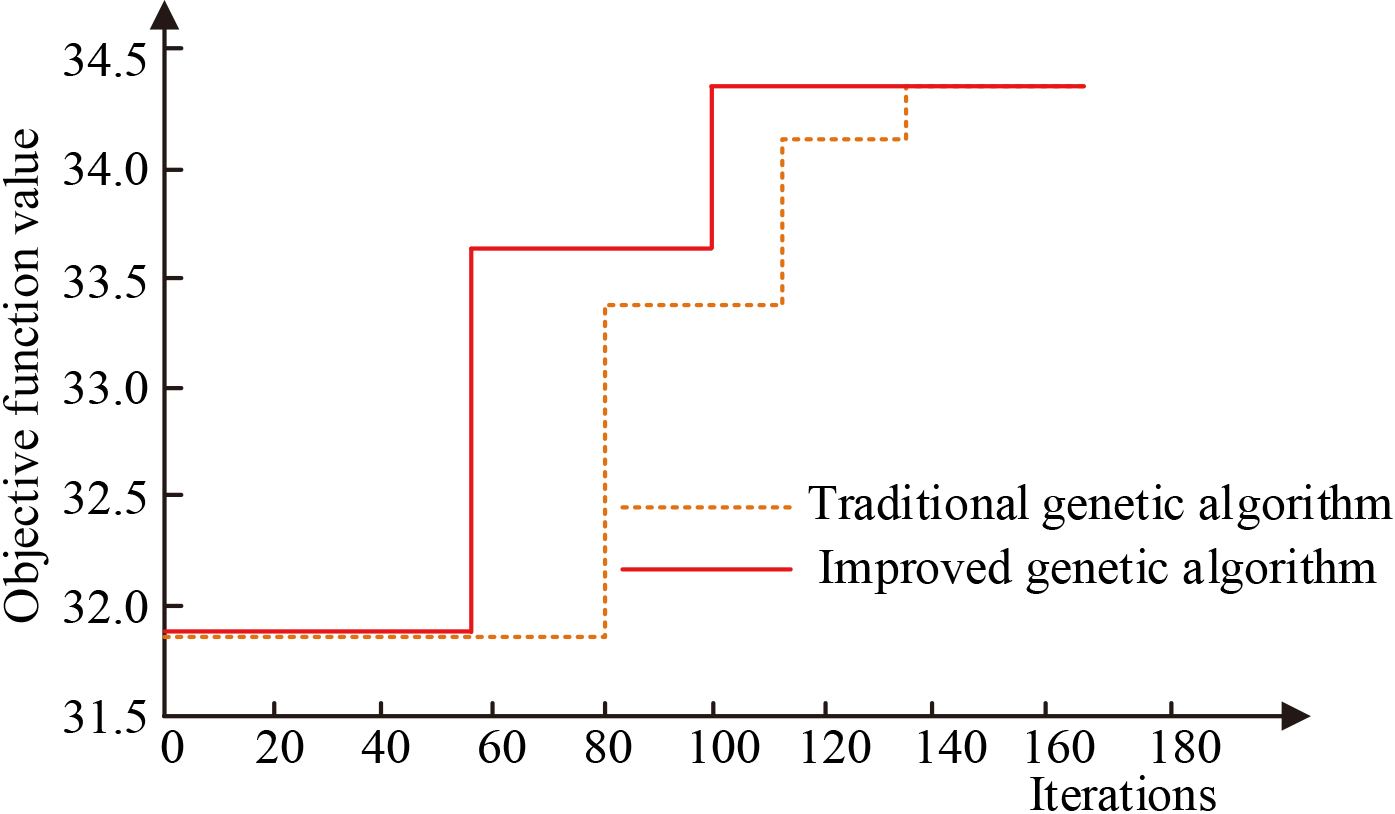
In Fig. 7, it can be seen that during the period when the number of iterations increases from 0 to 60, there is no significant change in the objective function value, which is at 31.8; when the number of iterations gradually increases until 100, the objective function value makes a big leap up from 31.8 to 33.6; after that, when the number of iterations increases to 140 or even higher, the objective function value is stable at 34.4 and remains constant. It can be concluded that the best results of the interaction between the two are obtained when the adaptation degree of the research speech database design is 34.4 and the number of iterations is 100.
To verify the effectiveness of the improved algorithm, the study uses the optimal solution obtained by the improved genetic algorithm and the optimal solution obtained by using the traditional genetic algorithm to make a longitudinal comparison. If the comparison results show that the former optimal solution value is smaller than the latter, then it can be obtained that the improved genetic algorithm has a better convergence performance and can be utilized. The comparison of the optimal solution of the traditional algorithm and the improved algorithm is shown in Fig. 8.
Comparison of optimal solution between improved algorithm and traditional algorithm.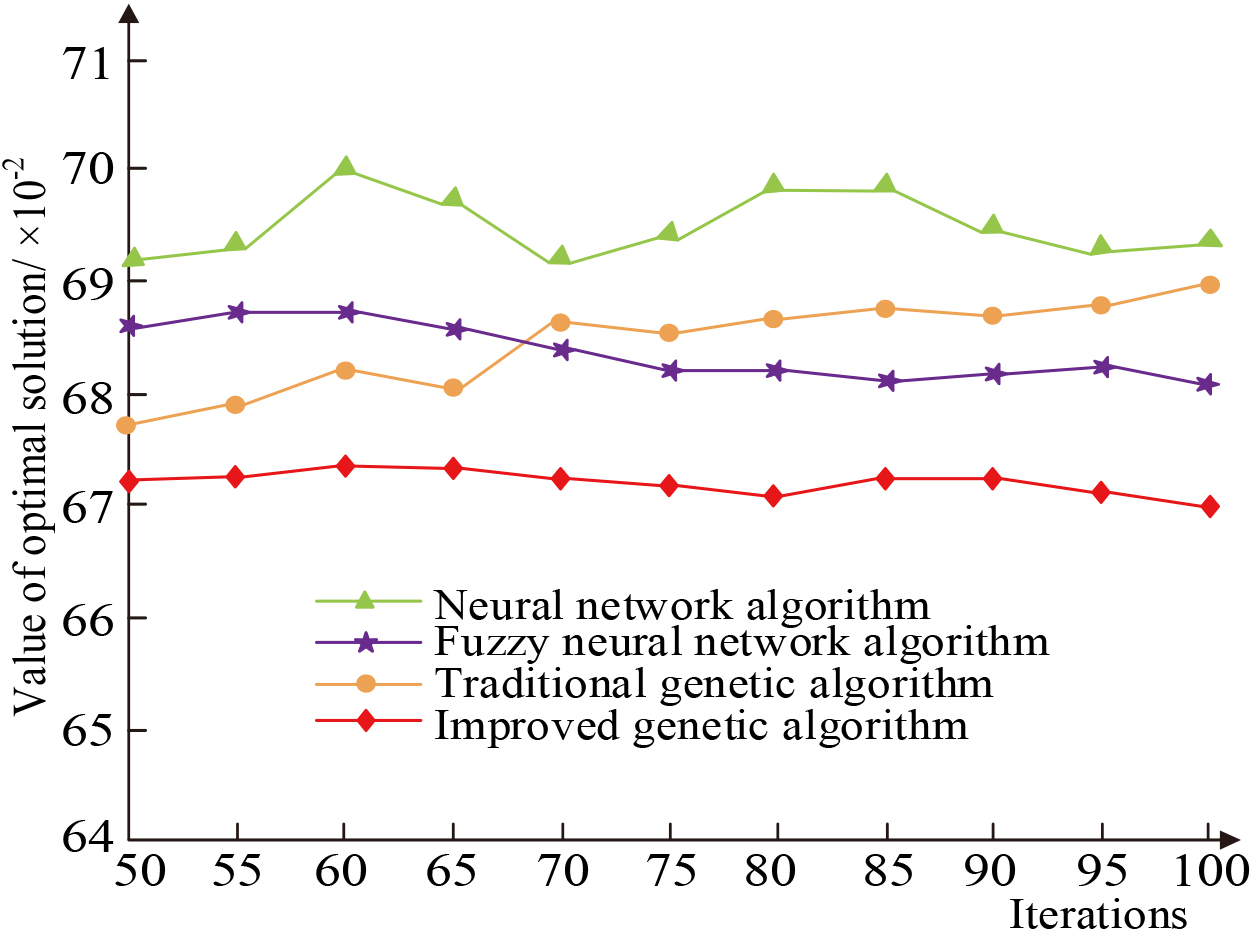
It can be seen in Fig. 8 that the values of the optimal solutions under the neural network algorithm, the fuzzy neural network algorithm and the traditional genetic algorithm are larger than the values of the optimal solutions under the improved genetic algorithm regardless of the increase in the number of iterations. And as the number of iterations increases, the improved genetic algorithm shows a small wave-shaped change, i.e., the value of the optimal solution is first larger and then smaller, and the smallest optimal solution value appears when the number of iterations reaches 100, which means the best convergence effect of the improved genetic algorithm on the speech database at this time. The error plots of the optimal solution values under different algorithms are shown in Fig. 9.
Error of optimal solution under different algorithms.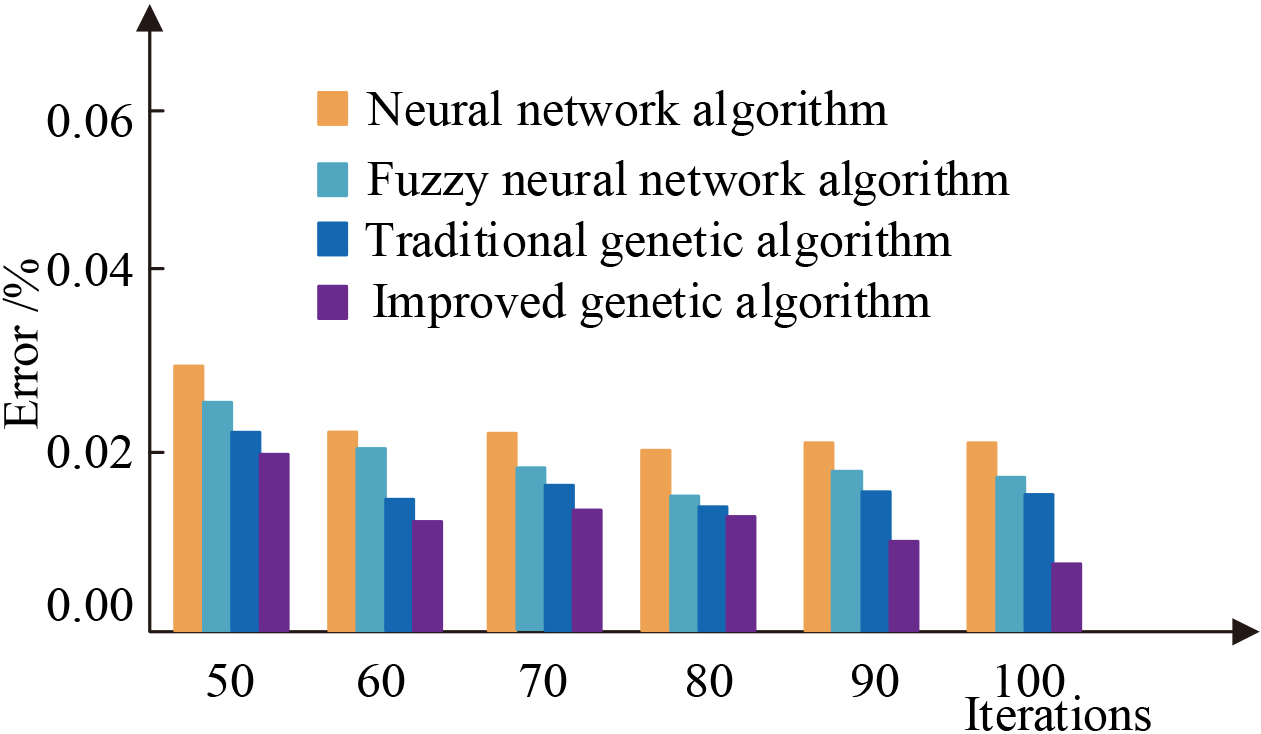
The comparison experiment in Fig. 9 shows that the proposed improved genetic algorithm outperforms the other three algorithms under the same index. Even though the number of iterations operation keeps increasing, the error of the optimal solution obtained by the neural network algorithm, the fuzzy neural network algorithm and the traditional genetic algorithm is greater than the error under the improved genetic algorithm in any case. With the increase of the number of iterations, the error of the algorithms taken for comparison in the study all appeared to decrease, but the error of the optimal solution under the improved genetic algorithm was always the smallest and had the smallest error of 0.0079 when the number of iterations reached 100, which means that the improved genetic algorithm has the highest accuracy in collecting and calculating the data of the speech database and the feasibility of the method.
For the performance analysis of the algorithm, most notably by analyzing the processing effect of the algorithm in signal processing, the improved genetic algorithm is used in this study to process an analog noise signal, see Fig. 10.
Improved genetic algorithm denoising rendering.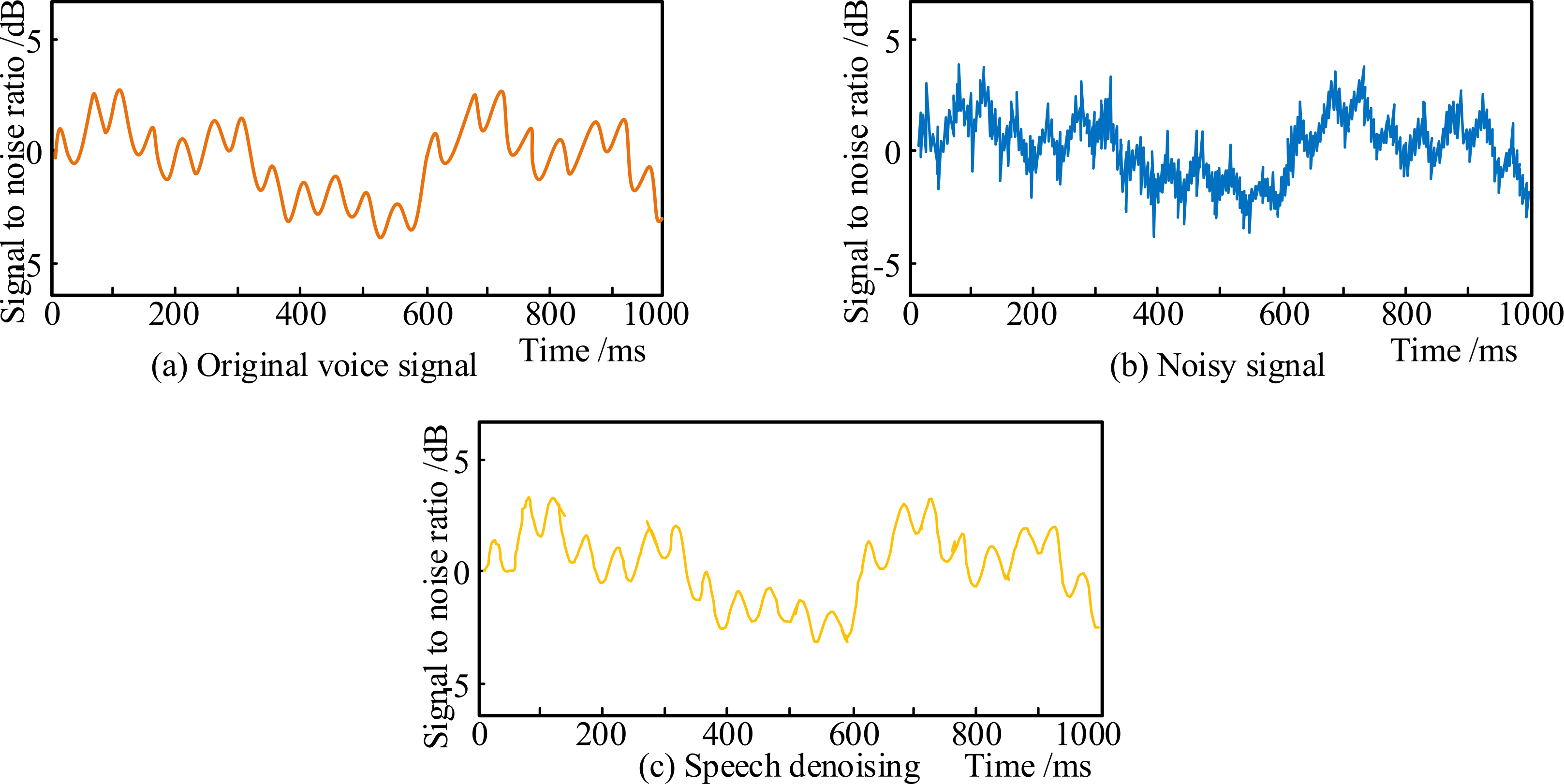
As shown in Fig. 10, the original speech output signal is a smooth curve. After adding the noise content, the signal generates many burrs. For the analog signal with burrs, an improved genetic algorithm is used to reduce the effect of noise. The waveform of the noise-cancelled signal shows that the edges on the curve are significantly reduced. The results show that the algorithm does not affect the overall trend of the signal, i.e., the algorithm used in the study eliminates the effect of signal noise to some extent and does not change the information contained within the original signal. Speech acquisition is an important part of speech database design, and speech acquisition requires accurate speech recognition rate, for which the study investigates the analysis of recognition rate obtained by improved genetic algorithm for speech recognition techniques. According to the researcher’s known research results the most influential factor on the speech recognition technology in the speech database is the influence of noise from the external environment. The office area is selected for the study to analyze and the speech recognition rate changes with the change of sound as shown in Fig. 11.
Change diagram of speech recognition rate under the influence of sound.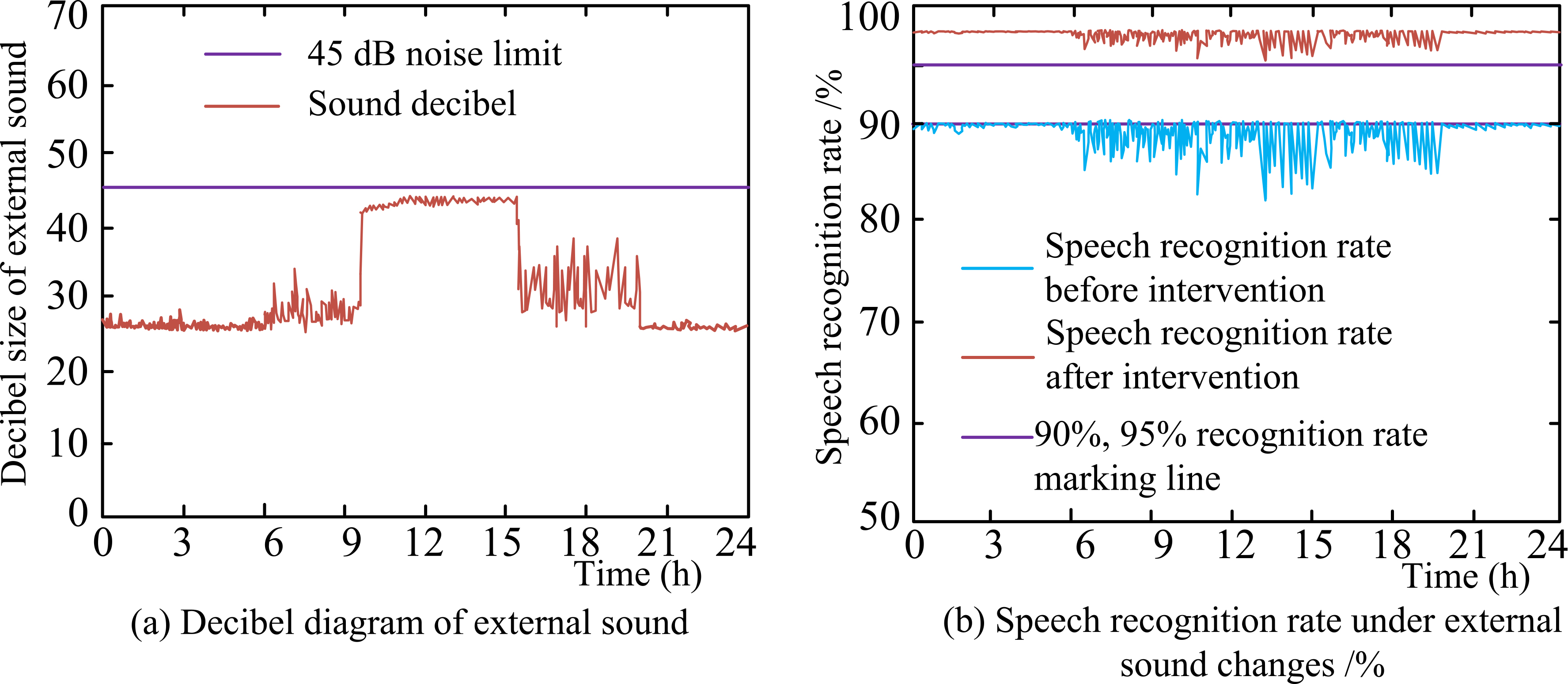
As can be seen from Fig. 11, Fig. 11a from 22:00 at night until 6:00 in the morning, because of the noise standard control, the outside noise decibels do not exceed 35 dB, until 6:00 later, people began to activities sound decibels began to rise. From 9:00 to 15:00 pm, the sound decibels are always intensive, and the decibels are concentrated above 40 dB, especially between 9:00 and 12:00, when the sound decibels tend to be closer to the 45 dB noise limit. The speech recognition rate before and after the intervention in Fig. 11b shows a certain decline between 6:00 am and 22:00 pm, and the decline curve of the recognition rate before the intervention is sharper. Using the improved genetic algorithm to intervene in the speech recognition rate under the influence of external sound, the speech recognition rate after the intervention increased by about 8% compared with the recognition rate obtained before the intervention, and the overall speech recognition rate was higher than 95%. The results demonstrate that the improved genetic algorithm has a significant positive impact on improving the speech recognition rate in speech database design.
The intelligent era requires computers to help humans to perform simple daily activities, and computerized speech database systems occupy an important position in the middle of it. In order to improve the speech database system design method and the efficiency of speech recognition, the improved genetic algorithm is proposed to be applied in the database design research. The experimental results show that compared with the traditional genetic algorithm, the objective function value of the improved algorithm no longer changes at 34.4, and then the number of iterations increases again and continues to be smooth, and the number of iterations is 100 at this time; the value of the optimal solution is always smaller than other algorithms when the improved genetic algorithm is compared with other algorithms, which means that the convergence effect of the improved genetic algorithm on the speech database is better than other algorithms; the value of the optimal solution under the various algorithms is compared with the error of The error of the optimal solution under various algorithms is compared, and it is obtained that the error of the optimal solution under the improved genetic algorithm is always the smallest and has the smallest value of 0.0079 at the number of 100 iterations; there is also an improvement for the speech recognition efficiency, and the speech recognition rate under the algorithm intervention in the study increases by 8% and the efficiency is higher than 95% overall. This all indicates that the improved genetic algorithm helps the data collection and recognition efficiency of the speech database, and the method is highly feasible. However, the overall advancement of speech systems is still limited, so expanding the research area is still the next research direction that can be explored.