
Abstract
This paper merges two isolated bodies of literature: the Markov chain model with macro data, formally described in detail by MacRae in 1977, and the Ecological inference model, the pitfalls of which were discussed by Robinson in 1950. Both are choice models. They have the same likelihood function and the same regression equation.
Decades ago, this likelihood function was computationally demanding. This has led to the use of several approximate methods, in particular with the Ecological inference model. Due to the improvement in computer hardware and software since Macrae (1977), the exact maximum likelihood should now be the preferred estimation method.
Introduction
This paper merges two isolated bodies of literature: respectively about the first order Markov chain model with macro data and about the Ecological inference model. They contain very few references to each other, while in fact they are equivalent in the sense that they have the same likelihood function and the same regression equation.
Moreover, this paper disproves the general opinion that the computational burden of this likelihood function is still so large that one should rather use an approximation, or a subsample of the data.
In Sections 2 and 3, the two models are described with their respective typical examples, followed by a common notation in Section 4. In Sections 5 and 6 the likelihood function and the regression equation are given.
In Section 7 a numerical example is given, followed by the conclusions in Section 8.
All discussions below are limited to binary classifications. This is sufficient for the purpose. In fact, most of the Ecological literature is (double) binary.
The Markov chain model with macro data
A Markov chain model is a time series model for panels with discrete data. We consider the first-order model, with lags of only one time period.
In the binary case, at each time period the individuals in the panel are in one of two states. For instance, employed or unemployed: the probability for an individual to be employed in a given time period depends on being employed or not in the previous time period.
With the original micro panel data, these probabilities can be estimated easily, based on (for each time period except the first) the cross tabulation of the state in that time period against the state in the previous time period. With aggregated panel data this tabulation is not available; only the marginal frequencies are available and estimation of the probabilities is harder.
A short review of the subject’s history over the past four decades is as follows. [1, 2] are forerunners, discussing mainly regression analysis. They also discuss an approximate likelihood function where the data are assumed to be multinomially distributed (which they are not). In the seminal [3], regression analysis and exact maximum likelihood are compared. She concludes:
While it is possible to develop computational algorithms to search for a maximum [likelihood], the iterative generalized least squares estimator may represent a better combination of numerical and statistical efficiency.
In [4] the combined use of micro and macro data is discussed, with a large list of references. In [5] the history of theoretical and applied work on the subject is reviewed (though not including [3]) with the conclusion that the computation of the exact likelihood function is “unfeasible” (p. 3202).
The Ecological inference model
Here, the word “Ecological” (capitalized) has little to do with subjects like pollution, growing crops without chemicals, etcetera. Rather, as the title of [6] indicates, it is about “reconstructing individual behavior from aggregate data”; compare with the title of [3].
Hence, by definition in an Ecological inference model the data are aggregated. Time usually does not play a role and instead of time periods we usually have regions. In the 2
The standard example of this dichotomy is race, where the other dichotomy is political preference: the probability of having a given political preference depends on one’s race. The data consist of the two marginal frequency distributions, concerning race and political preference respectively, for multiple regions. Naturally, where political preferences are expressed by some secret ballot, the results are only available in this form.
The seminal paper is [7]. In [8] the background and the state of the research at the time is discussed. It is noted that the exact likelihood “has rarely been explicitly considered in the Ecological inference literature” (top of p. 391). See also the introductory chapter in [9]. To the best of my knowledge, the authors of [10] were the first to apply the exact likelihood, though only to a small part of their data.
A common notation
The Markov chain model
In the Markov chain model, we have
Note that we have no initial conditions problem here, such as in a time series regression model with a lagged error term.
The symbol
Ignoring panel attrition, the
Here, typically the units are regions, without inherent ordering, indexed by
Hence
The relations between the frequencies
Table 1 shows the frequencies. Since the data are aggregated, only the totals are observed; the remaining four numbers are not observed. However, if any one of these four numbers would be known then the other three would also be known. Without loss of generality I choose
The frequencies in unit
, with the index frequency
The frequencies in unit
Notes. Only totals are observed. The word “state” does not refer to the states of the United States.
The probabilities may depend on macro exogenous variables as follows. For all
where the
The function
The unconditional distribution of
taking into account Eq. (2). The B indicates the binomial probability with
The
where the range of the summation is
The likelihood function is:
For the first order Markov chain model, see [3], with the general case, not limited to binary choice. For the Ecological model, see for instance [8]Eq. (4), discussed at the top of page 391 (as noted above) and [11] Eq. (1.6). In [10] the first order derivatives of the loglikelihood and the Fisher information matrix are given, with a numerical application.
This likelihood is computationally more demanding than ordinary binary choice models: the computing time of Eq. (6) is roughly equal to the computing time of an ordinary binary choice model, times the sum over the units
In order to distinguish between this likelihood and its approximations,2 in the binary case this likelihood is often called the convolution likelihood, named after the convolution sum in discrete form in the right-hand side of Eq. (4).
With Eq. (5) we have:
With constant
In words: the difference between the two probabilities is a reflection of the correlation over the regions between
Equation (7) is a regression equation with the following error variance:
Hence Eq. (7) can be estimated with nonlinear Feasible Generalized Least Squares (FGLS) by minimizing
See [3, p. 189/190].
Unlike the maximum likelihood estimate, this regression estimate is independent of the sample size, in the following sense. Replacing all
This expression has its minumum at the same parameter values as Eq. (10). This is illustrated in Section 7; with increasing sample size, the maximum likelihood estimate converges to the constant least squares estimate.3
Percentage employment among women
Percentage employment among women
Source: [12].
In order to study computing times and to illustrate some other issues, I computed the exact likelihood, with a Markov chain model, using the times series data of [12]. Although that paper is not about panels, the data come from a panel. The panel contains women who are either employed or unemployed. The percentages are in Table 2. The first nine percentages are the
Estimates of probabilities for the Pelzer data
Note: when employed:
The estimates are in Table 3, with simulated sample sizes. As discussed above: unlike the maximum likelihood estimate, the least squares estimate does not change with the sample size.4 The difference between the two decreases with increasing sample size.
Figure 1 shows a contour map of the loglikelihood over the (
Contour plot of the log likelihood for 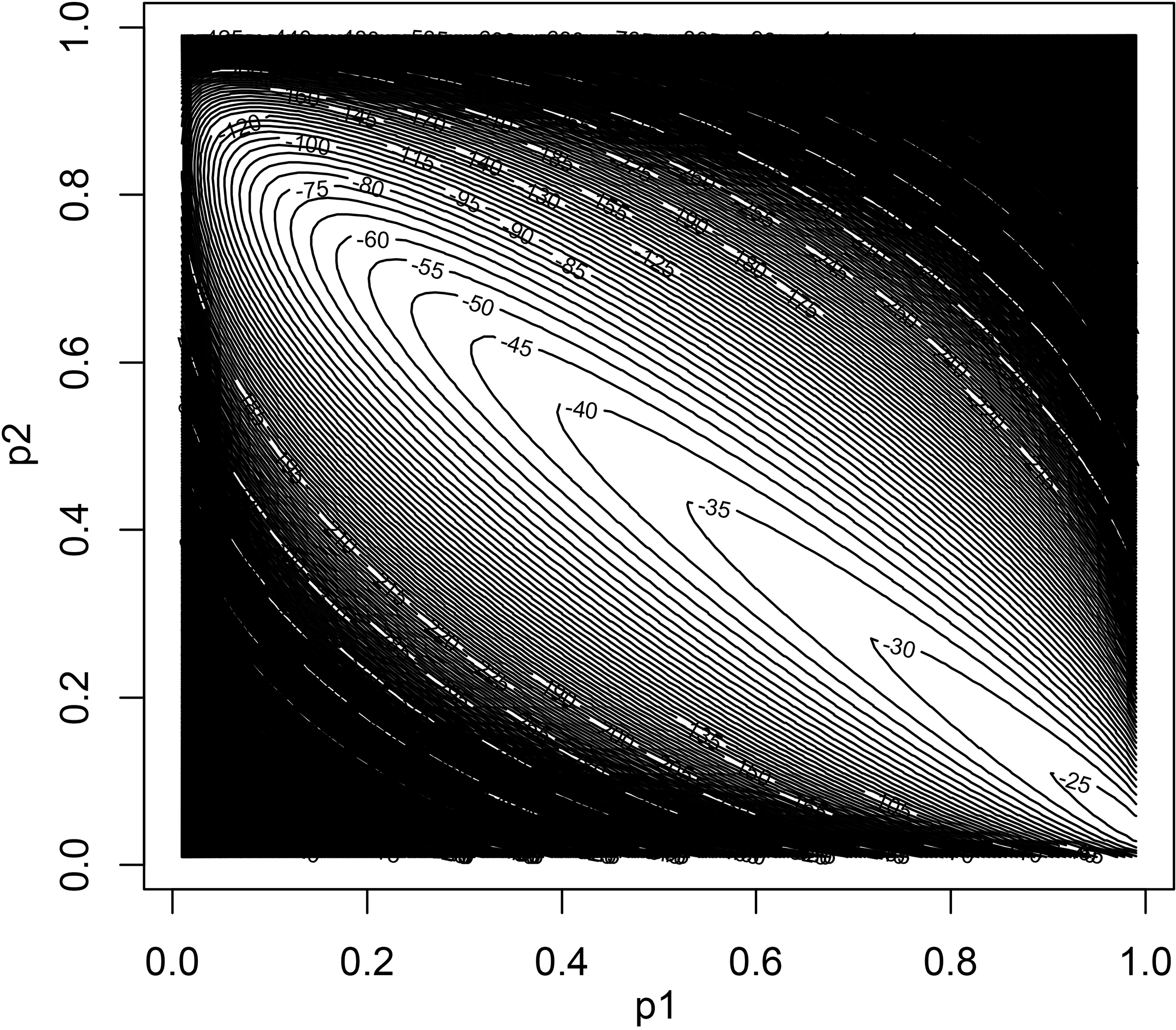
I saw no need to use here the EM algorithm, which is slower (though more robust) than the Newton algorithm. See [13], Section 3.2 for the EM algorithm applied to this likelihood function.
For the largest sample size (22000), the computing time (without a contour plot) was slightly under ten seconds on a laptop PC with an 1.7 GHz Intel processor and 4 GB RAM. I used the built-in array facilities of the R language (version 3.0.0, Windows 8, 64 bits) with the nlm function.
The first order Markov chain model with macro data can be considered as a special case of the Ecological inference model, with the two classifications of the Ecological model being the same, recorded at two subsequent time periods. Students of this Markov model might consult [10] for details of the exact likelihood function, which can be translated to the Markov model using the current paper.
Students of Ecological inference might have benefited from reading [3] at that time. Both might do well no longer to dismiss out of hand the exact likelihood as unfeasible.
The maximum likelihood estimate differs most from the least squares regression in small samples, where the computation of the likelihood function is less of a problem.
Remaining work: find out more about the possibility of multiple likelihood maxima. Note: in the case of one unit (
Footnotes
For brevity I write for example
Loosely speaking this convergence follows from: (a) with increasing ![]() , p. 20/21].
, p. 20/21].
Acknowledgments
The author thanks Stefan Boeters and Sander Muns and Marno Verbeek for their comments on earlier versions and Gary King for his willingness to reply to my questions about his book and his data.
Supplementary data
The supplementary files are available to download from http://dx.doi.org/10.3233/ JEM-452.