
Abstract
This article extends the ordered weighted average operator (OWA) in the linguistic Z-number (LZN) environment, increasing attention to the distribution of data itself, and this idea can also be combined with other operators. Specifically, for the weight of data, this paper gives consideration to both the preference of attributes and the distribution of data itself, gives the interval distribution induced OWA operator (IDIOWA), and combines the weight of attributes to obtain the LZN interval distribution induced hybrid weighted average operator (LZIDIHWA) in LZN environment. Then, it introduces some good properties of this operator. At the same time, the LZN interval distribution induced weighted Maclaurin symmetric means operator (LZIDIWMSM) is obtained by combining LZN interval distribution induced OWA operator (LZIDIOWA) with the LZN weighted Maclaurin symmetric means operator (LZWMSM), which makes up for the defect that LZWMSM cannot be used for data integration alone. Finally, the two operators are used for multi-attribute group decision-making (MAGDM), and their effectiveness is verified by comparative analysis.
Keywords
Introduction
When dealing with decision-making problems, we often face two problems: the form of evaluation information and the integration of data. Since Zadeh first proposed the concept of fuzzy set [1], there have been many fuzzy environments, and more choices have been made for the form of experts giving evaluation information. Among them, the linguistic Z-number [2], which combines the Z-number [3] and the linguistic term set [4], is obviously a good choice. It not only retains the original evaluation value and confidence of the Z-number, but also gives it in the form of linguistic terms, making the evaluation information given by experts more accurate and flexible. At the same time, compared with others, LZN is simple and easy to operate, which is more in line with the needs of the public. In view of these advantages of LZN, this paper adopts LZN as the decision-making environment.
During data integration, a very important link is the determination of weight. In the past, weight determination was mostly based on attributes. The weight of evaluation data under the same attribute for each alternative is the same. In this way, only the influence of attributes is considered, but the distribution of these data itself is ignored. At this time, OWA operator [5] has a place. Although OWA operator considers the distribution of data, it does not consider the influence of attributes. Finally, HWA operator [6] with both attribute preference and data distribution appears. The weight of the HWA operator is mainly divided into two parts, one is the weight of the attribute, and the other is the weight of the OWA operator, which are often fixed.
So far, there have been some operators [7, 8, 9, 10, 11] in the LZN environment, and it must be said that these operators do have excellent performance. However, it should be clarified that these operators often focus on attribute weights or fixed ordered positional weights. On the other hand, we focus on the characteristics of LZN, such as (good, sure) and (good, common). Although their confidence levels are inconsistent, the evaluation values are the same, and we seem to be able to categorize them into one category. Given this, we consider determining the ordered position weights of the data based on its distribution, and we also hope that this idea can be extended to other operators.
What this paper considers is that the attribute weight is fixed, while the weight of OWA operator is completely determined by the distribution of data. In other words, for different data groups, the approximate rate of weight given by OWA operator is different, which depends entirely on the distribution of this group of data itself. At the same time, this paper also considers combining this method with MSM operator [12] to reduce the original computation while absorbing the advantages of MSM operator. Moreover, it can not only be used for decision-making, but also be used separately as data integration.
In other words, in this article, data aggregation focuses more on the degree of concentration of the data itself, and this idea can also be combined with other operators. Overall, this article has the following innovative points:
Determine ordered position weights based on the distribution of data. Apply this idea to the LZN environment to obtain the LZIDIOWA and LZIDIHWA operator. Combining with the MSM operator to obtain the LZIDIWMSM operator, while retaining the advantages of the MSM operator and overcoming the shortcomings of the original operator’s inability to aggregate data separately.
For more clarity and convenience, this article will be divided into the following parts: Section 2 briefly introduces the research status of LZN, OWA and MSM operators; Section 3 gives some basic knowledge that needs to be used in the subsequent content of this article; In the fourth section, several operators given in this paper are described in detail; Section 5 gives the specific operation steps of these operators used in MAGDM; Section 6 gives an example for verification and analysis; Section 7 conclusion and outlook.
LZN
In dealing with decision-making problems, it is inevitable to provide evaluation information for alternatives. At this time, a tool that can express evaluation is needed. The famous Zadeh [3] creatively put forward the concept of Z-number. Z-number can indicate the evaluation value and also the confidence of the given evaluation value. Because of this, the Z-number has been widely used in decision-making since it was proposed. Wu et al. [13] asked experts to give evaluation information in the form of Z-number, and successfully applied it to medical problems through a series of other operations. Saeid Jafarzadeh Ghoushchi et al. [14] put forward a new method based on Z-number to deal with the defects of FMEA method. Rao et al. [15] put forward the method of selecting green suppliers under the uncertain environment based on Z-number, and successfully applied it in an example. Peng et al. [16] used the projection measure of Z-number to give a MCDM method and used it in hotel selection. Peng et al. [17] developed a simple method to calculate the Z-number to deal with the MCDM problem, and achieved success. The results of the example application are relatively more scientific. Namakin et al. [18] used the advantage of Z-number to carry out envelopment analysis on full fuzzy data, and proposed a new method to overcome some defects of previous methods. There are many examples of successful use of Z-number, which will not be repeated here.
After the Z-number was proposed, it has experienced a series of development and derivation, resulting in many Z-number based on fuzzy information. According to Zadeh’s Z-number [3] and linguistic term set [4], Wang et al. [2] put forward the concept of linguistic Z-number by combining them. Compared with the original Z-number, the fuzzy evaluation value and confidence degree of LZN are given by linguistic terms, which greatly increases the accuracy of the evaluation information given by experts. It is precisely in view of the advantages of LZN that it has been widely used. Liu et al. [19] combined LZN and cloud model weighted ranking technology, applied it to the information axiom concept evaluation, and verified it in the conceptual design evaluation of ink pen, which is superior to other methods. On the basis of LZN, Tao et al. [20] considered risk preference, combined TOPSIS method and Choquet integral, solved the MCGDM problem, and was verified in the example of supplier selection, which can effectively and scientifically solve the MCGDM problem. Based on LZN and evidence theory, Liu et al. [21] proposed a generalized TODIM-ELECTRII method, which was applied to the selection of terminal wastewater solidification technology. Song et al. [22] used the linguistic Z-number to propose a new framework for the development of quality functions, which proved its effectiveness and reliability in the case of logistics services. Duan et al. [7] used AQM method to select green suppliers and allocate orders in LZN environment, and successfully applied it in an example. Huang et al. [23] analyzed the derailment of railway trains in combination with LZN and improved Group 2.
At present, there are many good decision-making methods in the LZN environment, and of course, there are also some aggregation operators [7, 8, 9, 10, 11]. However, it should be noted that these operators almost do not pay attention to the distribution of the data itself.
OWA operator
OWA operator was originally proposed by Yager [5] as a tool for data integration. Later, with the further development of relevant research, OWA operators are also constantly enriched and improved. Jin et al. [24] gave discrete and continuous recursive forms of OWA operator. Maldonado et al. [25] redefined the support vector machine by using OWA operator. Of course, OWA operators are often used for integrated data in decision-making problems. Zhou et al. [26] proposed continuous generalized OWA operator and applied it to group decision making with interval arguments. Tian et al. [27] proposed a Z-number generation method using OWA weight and maximum entropy, and verified its effectiveness and flexibility in an example. Merigó and Casanovas [28] proposed the fuzzy generalized OWA operator and used it in strategic decision-making. Finally, an example is given to illustrate the use. Chen et al. [29] proposed a group recommendations autocratic decision-making method using OWA operator. Wang et al. [30] used OWA operator in infinite sequence environment. Zhou et al. [31] developed the generalized ordered weighted exponential multiple average operator. Liang et al. [32] proposed the intuitionistic fuzzy weighted OWA operator to integrate intuitionistic fuzzy information and finally apply it to multi-attribute group decision-making.
It should be noted that when using the OWA operator, it is important to determine the weight. Emrouznejad [33] gave a method to determine the weight considering the preference of alternatives. Liu et al. [34] gave an interval neutrosophic prioritized OWA operator, and then used it to make multi-attribute decision-making. Chang et al. [35] proposed a dynamic fuzzy OWA operator based on situation model to make multi-attribute group decision, and compared two examples to get the final effect. Yager [36] gave the concept of parameter uncertainty advantage based on measurement, used it for OWA aggregation, and embodied it in an example. Li et al. [37] proposed a method to induce the weight of OWA operator by the competitive behavior of alternatives, and gave some properties of this operator and illustrated it with practical examples.
We hope to determine the ordered position weights based on the distribution of the data itself, reflecting the role of the data itself, which can also be considered as an OWA operator.
MSM operator
MSM operator is a classical data integration operator, and with the continuous expansion of decision-making environment, MSM operator has also been applied in different environments. Qin et al. [38] used MSM operator to make multi-attribute decision under the hesitation fuzzy environment, and verified it in an example. Ali [39] developed the partitioned MSM operator under the hesitation fuzzy environment for the first time, and considered its weighted case, which was successfully used in hospital location. Qin et al. [40] used MSM operator to make multi-attribute decision-making under intuitionistic fuzzy environment, and also gave some properties of MSM operator under intuitionistic fuzzy environment. Bai et al. [41] used the partitioned MSM operator to make decision-making under q-rung orthopair fuzzy information. Liu et al. [42] used MSM operator in the fuzzy environment of probabilistic linguistic and considered the weighted form. Finally, its advantages are reflected in the example. Liu et al. [43] used MSM operator and entropy weight to make multi-attribute group decision under neutrosophic linguistic number environment. Shi et al. [44] proposed the reducible weighted MSM operator under the intuitionistic fuzzy environment, and then applied it to multi-attribute decision-making. Wang et al. [45] used MSM operator to make multi-attribute decision-making under single-valued neutrosophic linguistic environment and tested its effectiveness in an example. Liu et al. [8] first extended MSM operator to LZN environment and used it in decision-making. Garg and Arora [46] proposes MSM operator based on t-norm under dual hesitant fuzzy soft set.
Due to the excellence of the MSM operator itself, we consider combining the ideas of the LZIDIHWA operator with the MSM operator to obtain a new LZWMSM operator, indicating that our ideas can also be combined with other operators.
Preliminaries
This section will introduce some basic knowledge to facilitate your subsequent reading.
Linguistic term set (LTS)
LTS is an ordered: Negation operator:
Since LTS is discontinuous, it is often impossible to find the corresponding linguistic item after data integration. In view of this, Xu [47] proposed the concept of continuous linguistic term set on the basis of Definition 1.
Generally, a virtual linguistic term is only used to save information, and has no practical significance.
Where
In other words, LSF is a monotone increasing function. There are some common LSFs:
The
In MAGDM problem, in order to make experts more flexible and accurate to give evaluation information, Wang et al. [2] proposed the linguistic Z-number.
Where
Where
the accuracy function
Where
Here, three important correlation coefficients will be introduced to illustrate the similarity of results obtained by different decision-making methods.
Where
If there are multiple decision methods, the total similarity between each decision method and other methods can be calculated, which is:
Where
Where
If there are multiple decision methods, the total similarity between each decision method and other methods can be calculated, which is:
Where
Where
If there are multiple decision methods, the total similarity between each decision method and other methods can be calculated, which is:
Where
LZIDIHWA operator
First, we consider integrating a set of data in the context of real numbers. When the weights of these data are unknown, the common method is to use the OWA operator for integration. The weights given to these data generally show a state of large and small on both sides, and in most cases, the weight of each data is different. It seems out of place for some extreme cases, such as:
1 2 1 1 1 3 1 1 1 6 3 4 5 1 7 8 1.
In this set of data, there are obviously a lot of 1s, and other data appear almost only once. If the weight is given according to the appeal method, 1 is obviously not dominant. Therefore, an OWA operator that depends on the number of occurrences of a single data as the weight criterion is needed. At the same time, considering that the data is exactly the same, it is harsh, and the data with little difference can be regarded as the same data calculation times. This set of data is divided into several intervals from the minimum value to the maximum value. The weight of the data in each interval is the same, and the weight distribution is determined by the number in the interval. For example, the
So we can get
where
In practice, some intervals do not contain data. At this point, we only need to delete these intervals. This will not affect the results. For convenience, this article assumes that each interval has at least one data.
Now, we use the IDIOWA operator in LZN. Thanks to the comparison rule of LZN proposed by Wang et al., we can divide the interval according to
where
According to the algorithm of LZN, it is easy to obtain Theorem 1.
where
At the same time, we know that each data weight in
So the data integration result of the
According to the operation rules of LZN. The following conclusions can easily be drawn:
Now for the second round of integration to get the final result:
In this way, the theorem is proved.
In addition, the LZIDIOWA operator also has the following properties and characteristics.
Because
If
If
Thus:
If
If
According to the LZN comparison rule, we can get:
So far, the LZIDIOWA operator has not considered the objective weight of the data itself, but in practical problems, these data will have objective weight. The next method is the LZIDIHWA operator obtained by adding the objective weight of the data according to the LZIDIOWA operator.
Or
where
In the 18th century, Maclaurin proposed the famous Maclaurin operator. It is now used in decision-making problems. In 2021, Liu et al. used the Maclaurin operator in the LZN environment for the first time and used it to solve the MADM problem. It is undeniable that the Maclaurin operator has great advantages and can integrate data in a more objective and fair manner, but there are also small defects, such as a large amount of calculation-
Liu et al. gave the LZWMSM operator after considering the weight of the data.
Where
Let
Considering the interval weight, the weight of
Where
Next calculate
Then calculate
Finally, we can get the final result:
Next, we will solve the MAGDM problem with the LZIDIHWA operator and the LZIDIWMSM operator. Now assume that there are a total of
The specific operation steps are as follows:
Experts give assessment information. Normalize the decision matrix. In general, attributes are generally divided into two types: profitability and cost. Considering that we are used to the concept of “bigger is better”, we can use the negative rate of LZN to convert cost attributes into profitable attributes. In this way, we can get the final decision matrix
Use the LZIDIHWA operator (or LZIDIWMSM operator) to aggregate the evaluation data set
or
Calculate the final score for each alternative by the following equation:
Rank the alternatives on the basis of
Background
Under the current environment of “energy saving and emission reduction”, almost all industries are undergoing upgrades, which have achieved the goal of reducing costs and increasing profits on the premise of reducing pollution. However, heavy industry, an important pillar of the national economy, has a long transition period due to its unique existence. In particular, there are some highly polluting heavy industries, which will have adverse effects on the environment and society, and then cannot be separated from it now. The location of such factories has become a problem, not only to protect the environment, but also to consider the production capacity of the factory itself to maintain the development of other related industries.
After the second industrial revolution, electricity gradually entered thousands of households, and now many things need electricity to drive. At present, it mainly relies on thermal power stations, wind power stations, hydropower stations, etc. to generate electricity. Although hydropower is environmentally friendly, it is greatly affected by the season. For the continuous supply of electricity, although thermal power stations pollute the environment, they also have a certain scale.
Now, country C plans to build a thermal power station to meet the electricity consumption in a certain area of the country. After many investigations, 5 construction sites
Among them,
Decision-making
4 experts gave the evaluation information respectively, and obtained the following 4 evaluation information tables respectively. Evaluation information given by the first expert
Evaluation information given by the second expert
Evaluation information given by the third expert
Standardize decision information
Since the above properties are all benefit types, they do not need to be converted and can be used directly.
Using the LZIDIHWA operator for data aggregation, and considering that
Evaluation information given by the fourth expert
Ranking by different
The final score is calculated as follows:
The alternatives are ranked according to
So,
As we can see, the LZIDIHWA operator have a parameter
Integrated data from different
values
Integrated data from different
According to Table 5 above, we can draw the following conclusions:
In general, the change of With the constant change of When By observing Fig. 1, we can see that the overall distribution of It is worth noting that when the value of
Generally speaking, the final ranking result of the scheme is mainly affected by the distribution of
Comparative analysis of LZIDIHWA operator
In order to verify the accuracy and effectiveness of LZIDIHWA operator in decision-making, we now compare it with other decision-making methods. To ensure the scientific comparison, we adopt the LZ-EDAS method in LZN environment proposed by Mao et al. [52] and the LZ-TODIM method in LZN environment proposed by Wang et al. [2] At the same time, Let the weight of the
Comparison table of LZIDIHWA operator
Comparison table of LZIDIHWA operator
Raw data distribution map.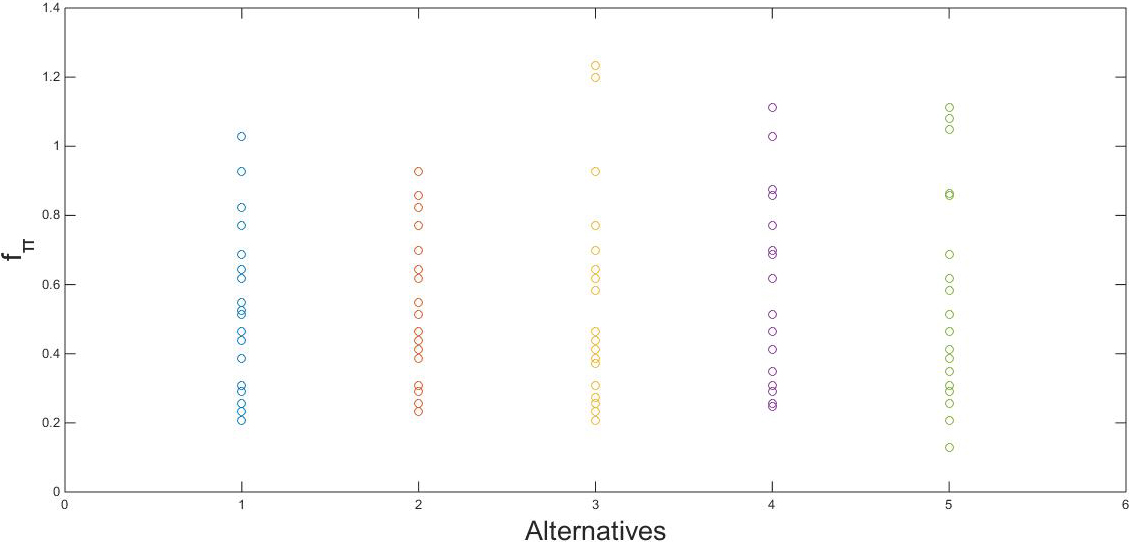
In this way, we can draw the following conclusions:
In general, the final results are basically the same. There is no doubt about the advantages of LZ-EDAS method and LZ-TODIM method. However, it can also be seen that the results of these two methods are somewhat different. When using the LZ-EDAS method, the best alternative is It can be seen from Fig. 1 that the data distribution of
At the same time, we can also calculate the similarity coefficients of the results obtained by different methods. Using Eqs (10) and (11), Spearman’s rank coefficient can be obtained. Similarly, using Eqs (12) and (13) to obtain Weighted Spearman’s rank coefficient, and using Eqs (14) and (15) to obtain WS rank similarity coefficient, their specific results are as follows:
Correlation coefficient table
From Table 8, it can be seen that the correlation coefficients of several methods are very high, indicating a high degree of similarity in the results obtained.
According to the above comparison, it is sufficient to illustrate the effectiveness of LZIDIHWA operator. At the same time, the LZIDIHWA operator determines the weight according to the degree of data concentration, reducing human intervention, making the integrated results more objective.
This part mainly compares LZIDIWMSM operator with LZWMSM operator proposed by Liu et al. [8], to verify that LZIDIWMSM operator absorbs the advantages of LZWMSM operator and reduces the original computation. The final sorting results obtained according to different values of parameters are shown in Table 9.
Ranking comparison of LZIDIWMSM operators
Ranking comparison of LZIDIWMSM operators
Data integration comparison of LZIDIWMSM operators
According to Table 9, we can see that the overall ranking trend is stable, and the slight fluctuations are also consistent with the previous description. This verifies that the LZIDIWMSM operator absorbs the advantages of the LZWMSM operator and reduces the computational complexity. In some cases, it can be used instead of the LZWMSM operator.
It should be noted that the LZWMSM operator proposed by Liu et al. [8] has no problem in sorting alternatives, but it is defective if it is only used for data integration. Taking
The LZIDIHWA operator in LZN environment proposed in this paper considers both the preference of attributes and the distribution of data itself, which can be used not only in decision-making, but also in data integration alone. At the same time, the LZIDIWMSM operator combined with the MSM operator absorbs the advantages of the MSM operator, and makes up for the deficiency that the LZWMSM operator cannot be used for data integration alone.
In addition, these two operators also have some shortcomings: in some cases, the data weight advantage of the centralized region is too large; Data distribution and attributes are treated independently.
It should be clarified that the aggregation operators proposed in this article is more used for data aggregation than directly for decision-making. In other words, the operators proposed in this article can solve some simple decision-making problems, while for more complex problems, it needs to be combined with necessary decision-making methods, such as TOPSIS, EDAS, etc. Therefore, we will next consider combining operators with classical decision methods.
Footnotes
Funding
The work was supported by the Sichuan Province Social Development Key R&D Projects under Grant No. 2023YFS0375.